 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LEED: Label-Free Expression Editing via Disentanglement
Jul 17, 2020
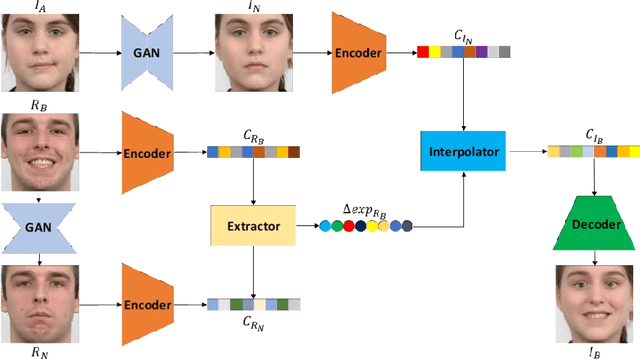

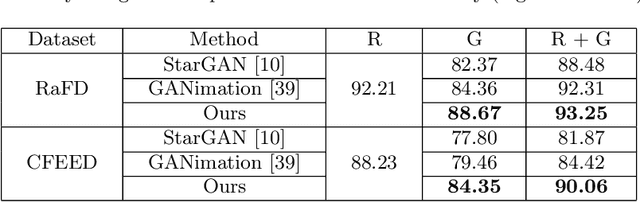

Recent studies on facial expression editing have obtained very promising progress. On the other hand, existing methods face the constraint of requiring a large amount of expression labels which are often expensive and time-consuming to collect. This paper presents an innovative label-free expression editing via disentanglement (LEED) framework that is capable of editing the expression of both frontal and profile facial images without requiring any expression label. The idea is to disentangle the identity and expression of a facial image in the expression manifold, where the neutral face captures the identity attribute and the displacement between the neutral image and the expressive image captures the expression attribute. Two novel losses are designed for optimal expression disentanglement and consistent synthesis, including a mutual expression information loss that aims to extract pure expression-related features and a siamese loss that aims to enhance the expression similarity between the synthesized image and the reference image. Extensive experiments over two public facial expression datasets show that LEED achieves superior facial expression editing qualitatively and quantitatively.
Weakly-supervised Learning of Human Dynamics
Jul 17, 2020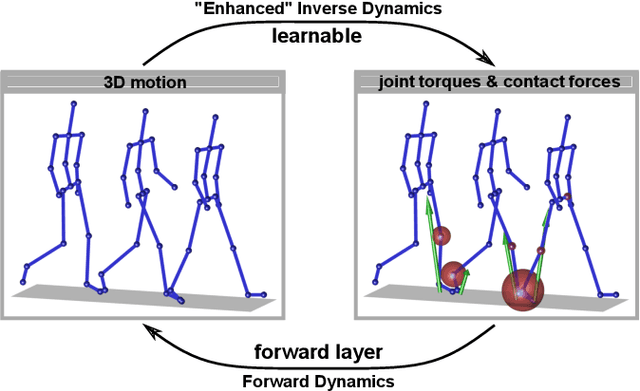
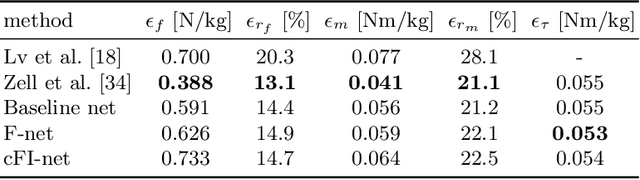
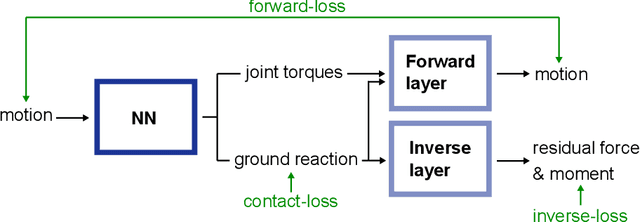
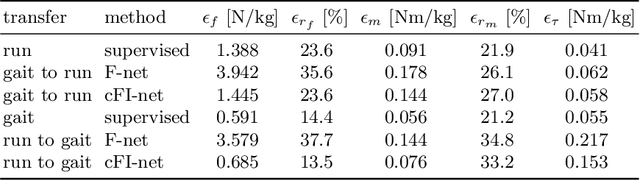
This paper proposes a weakly-supervised learning framework for dynamics estimation from human motion. Although there are many solutions to capture pure human motion readily available, their data is not sufficient to analyze quality and efficiency of movements. Instead, the forces and moments driving human motion (the dynamics) need to be considered. Since recording dynamics is a laborious task that requires expensive sensors and complex, time-consuming optimization, dynamics data sets are small compared to human motion data sets and are rarely made public. The proposed approach takes advantage of easily obtainable motion data which enables weakly-supervised learning on small dynamics sets and weakly-supervised domain transfer. Our method includes novel neural network (NN) layers for forward and inverse dynamics during end-to-end training. On this basis, a cyclic loss between pure motion data can be minimized, i.e. no ground truth forces and moments are required during training. The proposed method achieves state-of-the-art results in terms of ground reaction force, ground reaction moment and joint torque regression and is able to maintain good performance on substantially reduced sets.
CLOCS: Contrastive Learning of Cardiac Signals
May 27, 2020

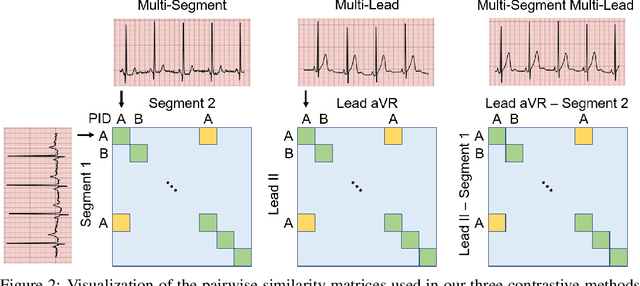
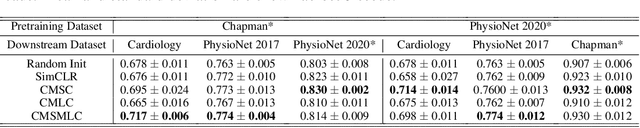
The healthcare industry generates troves of unlabelled physiological data. This data can be exploited via contrastive learning, a self-supervised pre-training mechanism that encourages representations of instances to be similar to one another. We propose a family of contrastive learning methods, CLOCS, that encourages representations across time, leads, and patients to be similar to one another. We show that CLOCS consistently outperforms the state-of-the-art approach, SimCLR, on both linear evaluation and fine-tuning downstream tasks. We also show that CLOCS achieves strong generalization performance with only 25% of labelled training data. Furthermore, our training procedure naturally generates patient-specific representations that can be used to quantify patient-similarity.
Average Case Column Subset Selection for Entrywise $\ell_1$-Norm Loss
Apr 16, 2020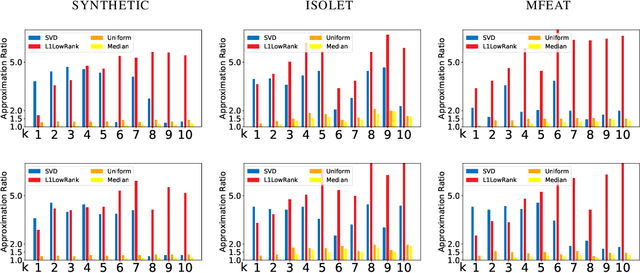
We study the column subset selection problem with respect to the entrywise $\ell_1$-norm loss. It is known that in the worst case, to obtain a good rank-$k$ approximation to a matrix, one needs an arbitrarily large $n^{\Omega(1)}$ number of columns to obtain a $(1+\epsilon)$-approximation to the best entrywise $\ell_1$-norm low rank approximation of an $n \times n$ matrix. Nevertheless, we show that under certain minimal and realistic distributional settings, it is possible to obtain a $(1+\epsilon)$-approximation with a nearly linear running time and poly$(k/\epsilon)+O(k\log n)$ columns. Namely, we show that if the input matrix $A$ has the form $A = B + E$, where $B$ is an arbitrary rank-$k$ matrix, and $E$ is a matrix with i.i.d. entries drawn from any distribution $\mu$ for which the $(1+\gamma)$-th moment exists, for an arbitrarily small constant $\gamma > 0$, then it is possible to obtain a $(1+\epsilon)$-approximate column subset selection to the entrywise $\ell_1$-norm in nearly linear time. Conversely we show that if the first moment does not exist, then it is not possible to obtain a $(1+\epsilon)$-approximate subset selection algorithm even if one chooses any $n^{o(1)}$ columns. This is the first algorithm of any kind for achieving a $(1+\epsilon)$-approximation for entrywise $\ell_1$-norm loss low rank approximation.
Translation, Sentiment and Voices: A Computational Model to Translate and Analyse Voices from Real-Time Video Calling
Sep 28, 2019
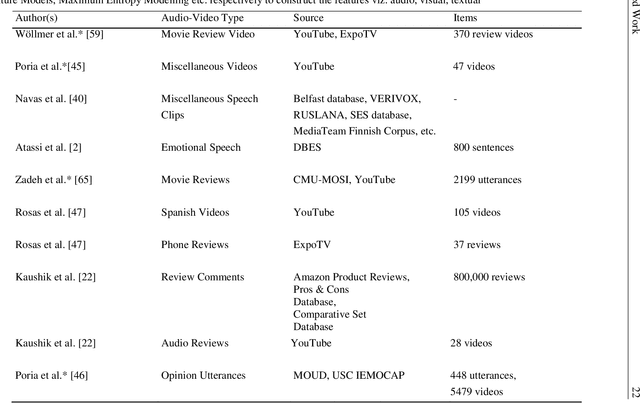
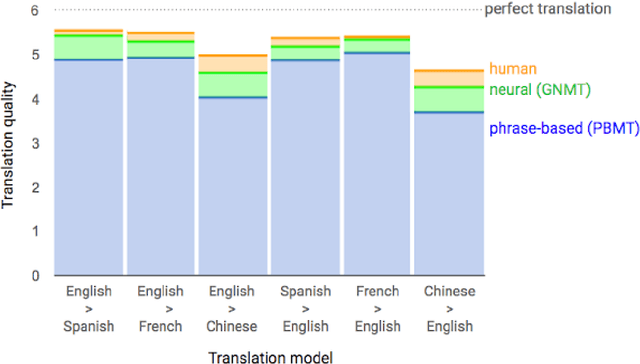
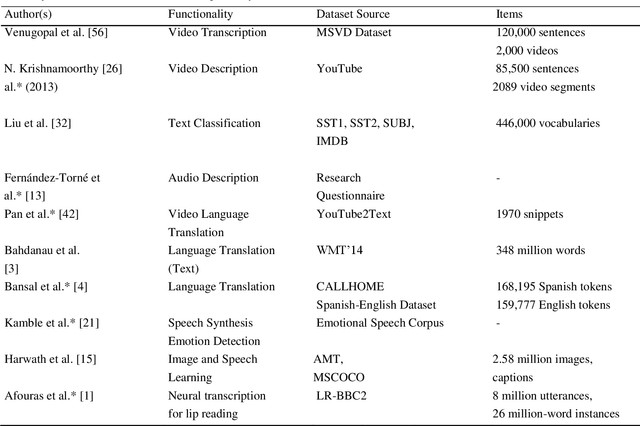
With internet quickly becoming an easy access to many, voice calling over internet is slowly gaining momentum. Individuals has been engaging in video communication across the world in different languages. The decade saw the emergence of language translation using neural networks as well. With more data being generated in audio and visual forms, there has become a need and a challenge to analyse such information for many researchers from academia and industry. The availability of video chat corpora is limited as organizations protect user privacy and ensure data security. For this reason, an audio-visual communication system (VidALL) has been developed and audio-speeches were extracted. To understand human nature while answering a video call, an analysis was conducted where polarity and vocal intensity were considered as parameters. Simultaneously, a translation model using a neural approach was developed to translate English sentences to French. Simple RNN-based and Embedded-RNN based models were used for the translation model. BLEU score and target sentence comparators were used to check sentence correctness. Embedded-RNN showed an accuracy of 88.71 percentage and predicted correct sentences. A key finding suggest that polarity is a good estimator to understand human emotion.
Personalized Deep Learning for Ventricular Arrhythmias Detection on Medical IoT Systems
Aug 18, 2020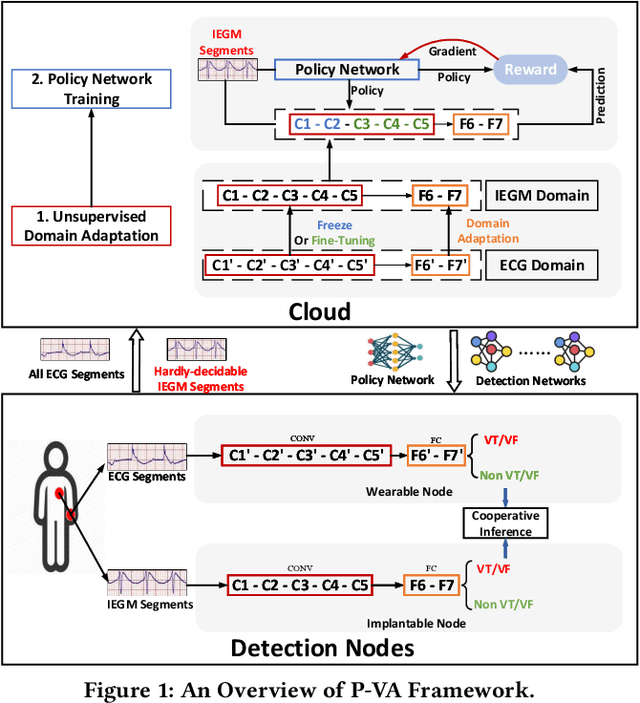
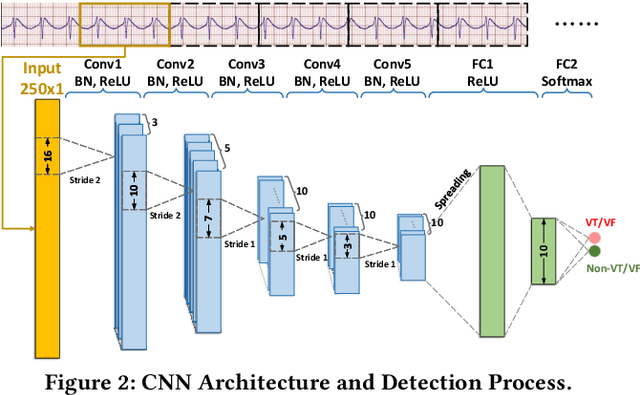
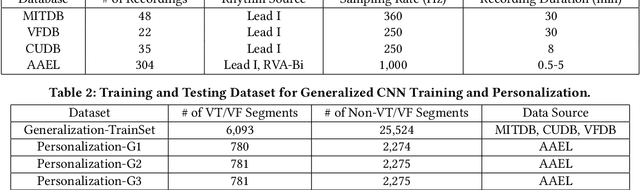
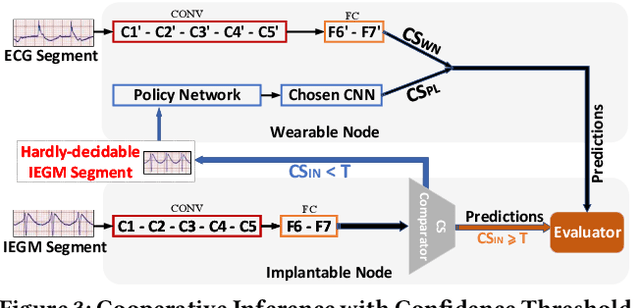
Life-threatening ventricular arrhythmias (VA) are the leading cause of sudden cardiac death (SCD), which is the most significant cause of natural death in the US. The implantable cardioverter defibrillator (ICD) is a small device implanted to patients under high risk of SCD as a preventive treatment. The ICD continuously monitors the intracardiac rhythm and delivers shock when detecting the life-threatening VA. Traditional methods detect VA by setting criteria on the detected rhythm. However, those methods suffer from a high inappropriate shock rate and require a regular follow-up to optimize criteria parameters for each ICD recipient. To ameliorate the challenges, we propose the personalized computing framework for deep learning based VA detection on medical IoT systems. The system consists of intracardiac and surface rhythm monitors, and the cloud platform for data uploading, diagnosis, and CNN model personalization. We equip the system with real-time inference on both intracardiac and surface rhythm monitors. To improve the detection accuracy, we enable the monitors to detect VA collaboratively by proposing the cooperative inference. We also introduce the CNN personalization for each patient based on the computing framework to tackle the unlabeled and limited rhythm data problem. When compared with the traditional detection algorithm, the proposed method achieves comparable accuracy on VA rhythm detection and 6.6% reduction in inappropriate shock rate, while the average inference latency is kept at 71ms.
DeepSIP: A System for Predicting Service Impact of Network Failure by Temporal Multimodal CNN
Mar 24, 2020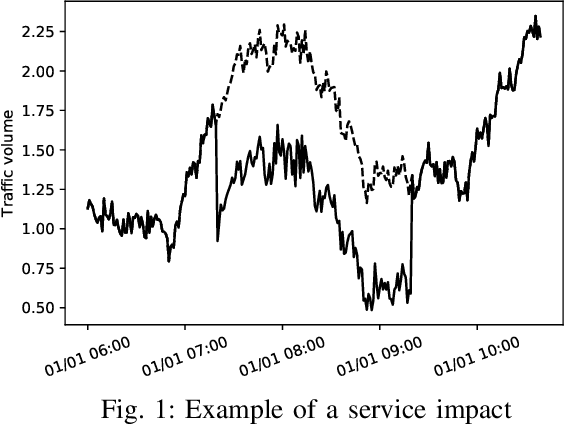
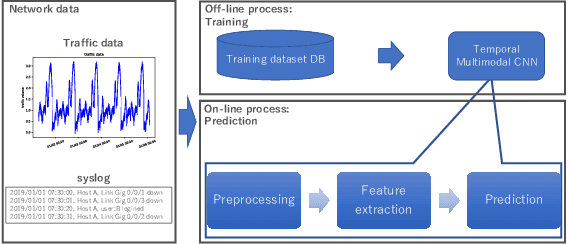
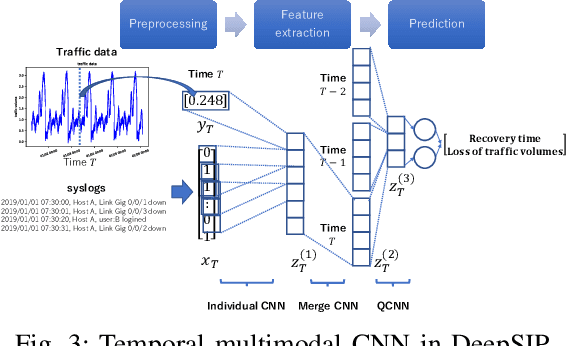
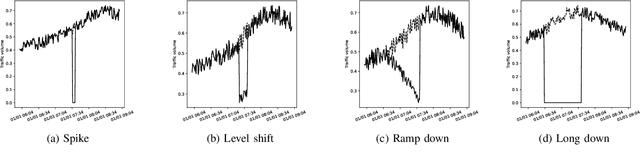
When a failure occurs in a network, network operators need to recognize service impact, since service impact is essential information for handling failures. In this paper, we propose Deep learning based Service Impact Prediction (DeepSIP), a system to predict the time to recovery from the failure and the loss of traffic volume due to the failure in a network element using a temporal multimodal convolutional neural network (CNN). Since the time to recovery is useful information for a service level agreement (SLA) and the loss of traffic volume is directly related to the severity of the failures, we regard these as the service impact. The service impact is challenging to predict, since a network element does not explicitly contain any information about the service impact. Thus, we aim to predict the service impact from syslog messages and traffic volume by extracting hidden information about failures. To extract useful features for prediction from syslog messages and traffic volume which are multimodal and strongly correlated, and have temporal dependencies, we use temporal multimodal CNN. We experimentally evaluated DeepSIP and DeepSIP reduced prediction error by approximately 50% in comparison with other NN-based methods with a synthetic dataset.
COCO-FUNIT: Few-Shot Unsupervised Image Translation with a Content Conditioned Style Encoder
Jul 29, 2020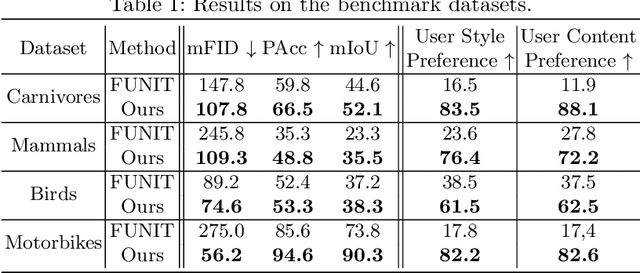
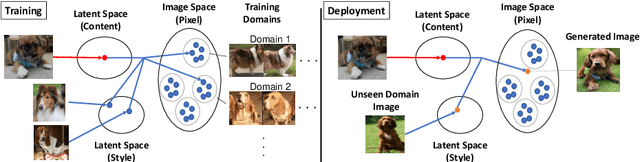
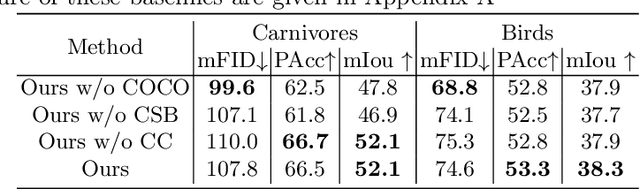

Unsupervised image-to-image translation intends to learn a mapping of an image in a given domain to an analogous image in a different domain, without explicit supervision of the mapping. Few-shot unsupervised image-to-image translation further attempts to generalize the model to an unseen domain by leveraging example images of the unseen domain provided at inference time. While remarkably successful, existing few-shot image-to-image translation models find it difficult to preserve the structure of the input image while emulating the appearance of the unseen domain, which we refer to as the content loss problem. This is particularly severe when the poses of the objects in the input and example images are very different. To address the issue, we propose a new few-shot image translation model, COCO-FUNIT, which computes the style embedding of the example images conditioned on the input image and a new module called the constant style bias. Through extensive experimental validations with comparison to the state-of-the-art, our model shows effectiveness in addressing the content loss problem. For code and pretrained models, please check out https://nvlabs.github.io/COCO-FUNIT/ .
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection
Aug 08, 2020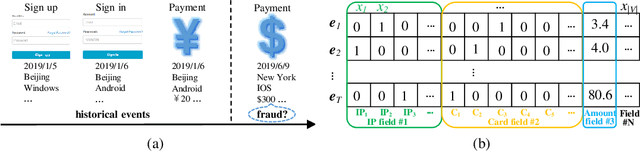
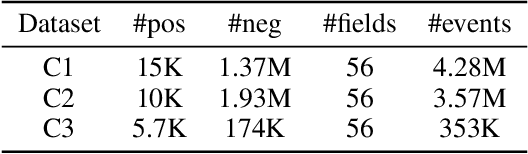
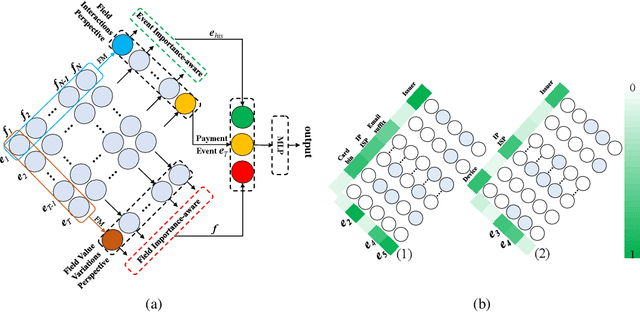
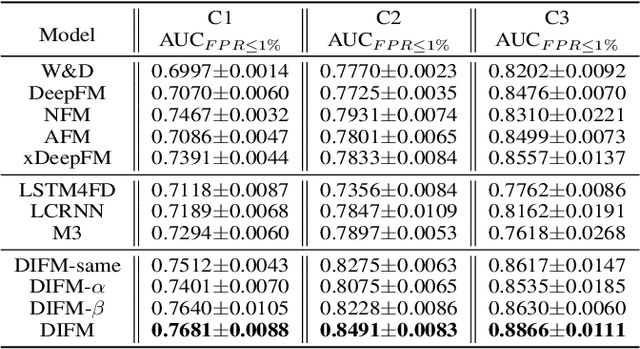
With the explosive growth of e-commerce, online transaction fraud has become one of the biggest challenges for e-commerce platforms. The historical behaviors of users provide rich information for digging into the users' fraud risk. While considerable efforts have been made in this direction, a long-standing challenge is how to effectively exploit internal user information and provide explainable prediction results. In fact, the value variations of same field from different events and the interactions of different fields inside one event have proven to be strong indicators for fraudulent behaviors. In this paper, we propose the Dual Importance-aware Factorization Machines (DIFM), which exploits the internal field information among users' behavior sequence from dual perspectives, i.e., field value variations and field interactions simultaneously for fraud detection. The proposed model is deployed in the risk management system of one of the world's largest e-commerce platforms, which utilize it to provide real-time transaction fraud detection. Experimental results on real industrial data from different regions in the platform clearly demonstrate that our model achieves significant improvements compared with various state-of-the-art baseline models. Moreover, the DIFM could also give an insight into the explanation of the prediction results from dual perspectives.
Bayesian inference of dynamics from partial and noisy observations using data assimilation and machine learning
Jan 17, 2020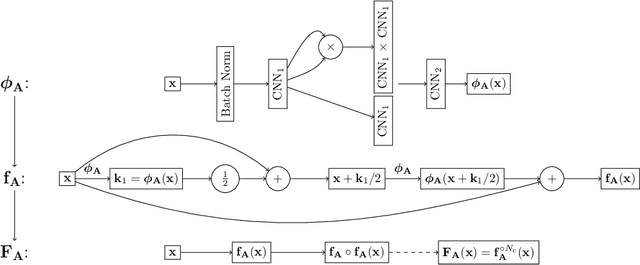
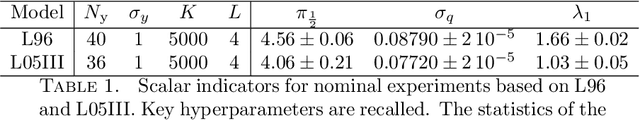
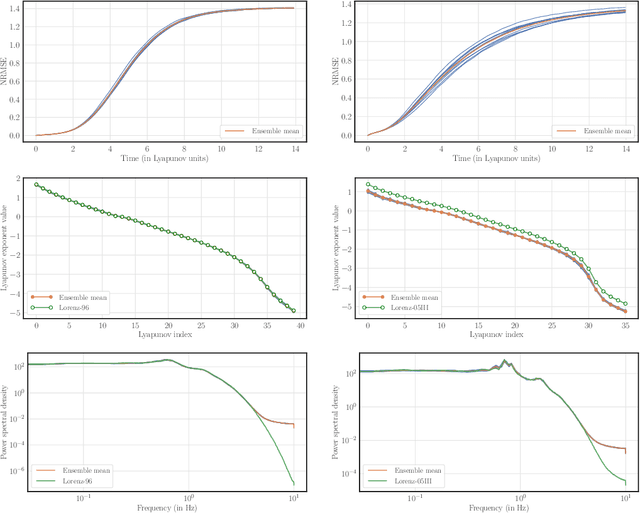
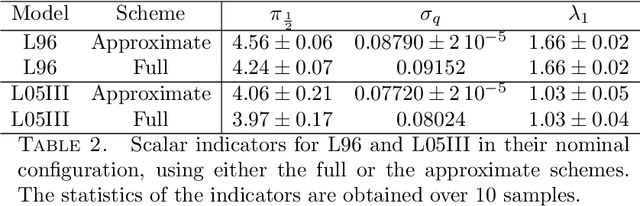
The reconstruction from observations of high-dimensional chaotic dynamics such as geophysical flows is hampered by (i) the partial and noisy observations that can realistically be obtained, (ii) the need to learn from long time series of data, and (iii) the unstable nature of the dynamics. To achieve such inference from the observations over long time series, it has been suggested to combine data assimilation and machine learning in several ways. We show how to unify these approaches from a Bayesian perspective using expectation-maximization and coordinate descents. Implementations and approximations of these methods are also discussed. Finally, we numerically and successfully test the approach on two relevant low-order chaotic models with distinct identifiability.