 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-Free Algorithm and Regret Analysis for MDPs with Peak Constraints
Mar 11, 2020
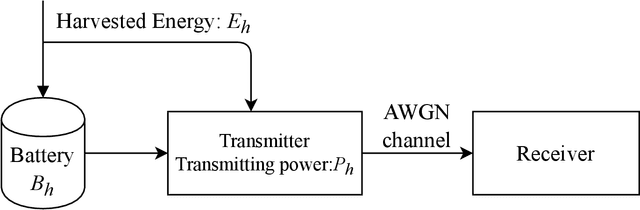
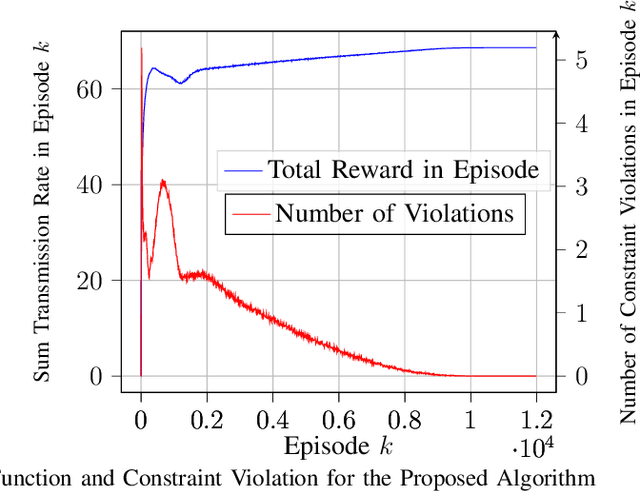
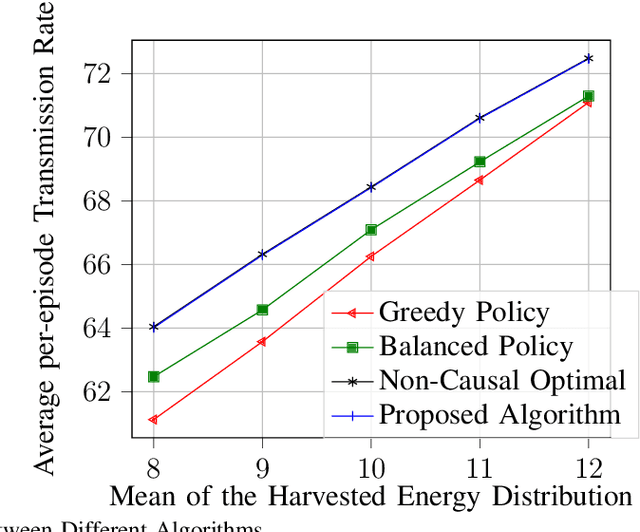
In the optimization of dynamic systems, the variables typically have constraints. Such problems can be modeled as a constrained Markov Decision Process (MDP). This paper considers a model-free approach to the problem, where the transition probabilities are not known. In the presence of peak constraints, the agent has to choose the policy to maximize the long-term average reward as well as satisfy the constraints at each time. We propose modifications to the standard Q-learning problem for unconstrained optimization to come up with an algorithm with peak constraints. The proposed algorithm is shown to achieve $O(T^{1/2+\gamma})$ regret bound for the obtained reward, and $O(T^{1-\gamma})$ regret bound for the constraint violation for any $\gamma \in(0,1/2)$ and time-horizon $T$. We note that these are the first results on regret analysis for constrained MDP, where the transition problems are not known apriori. We demonstrate the proposed algorithm on an energy harvesting problem where it outperforms state-of-the-art and performs close to the theoretical upper bound of the studied optimization problem.
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection
Aug 08, 2020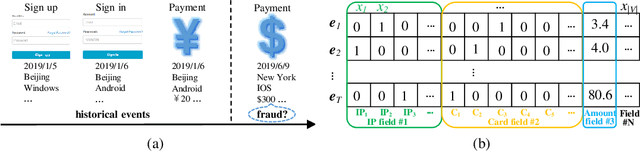
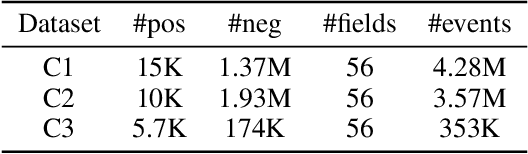
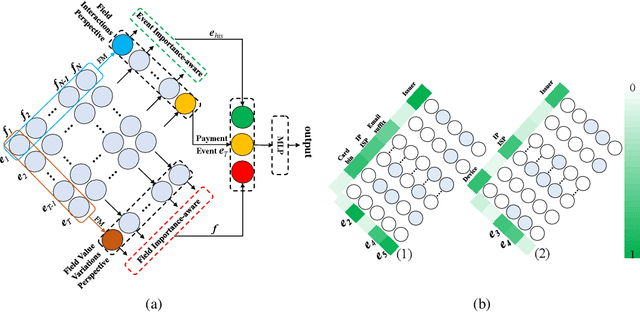
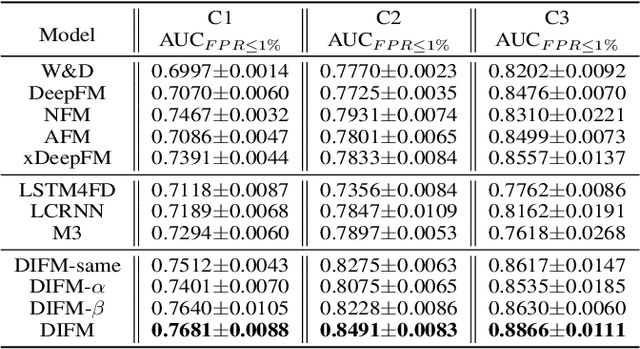
With the explosive growth of e-commerce, online transaction fraud has become one of the biggest challenges for e-commerce platforms. The historical behaviors of users provide rich information for digging into the users' fraud risk. While considerable efforts have been made in this direction, a long-standing challenge is how to effectively exploit internal user information and provide explainable prediction results. In fact, the value variations of same field from different events and the interactions of different fields inside one event have proven to be strong indicators for fraudulent behaviors. In this paper, we propose the Dual Importance-aware Factorization Machines (DIFM), which exploits the internal field information among users' behavior sequence from dual perspectives, i.e., field value variations and field interactions simultaneously for fraud detection. The proposed model is deployed in the risk management system of one of the world's largest e-commerce platforms, which utilize it to provide real-time transaction fraud detection. Experimental results on real industrial data from different regions in the platform clearly demonstrate that our model achieves significant improvements compared with various state-of-the-art baseline models. Moreover, the DIFM could also give an insight into the explanation of the prediction results from dual perspectives.
Studying the control of non invasive prosthetic hands over large time spans
Nov 18, 2015
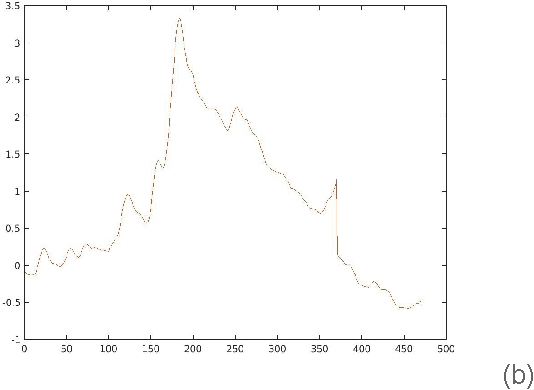

The electromyography (EMG) signal is the electrical manifestation of a neuromuscular activation that provides access to physiological processes which cause the muscle to generate force and produce movement. Non invasive prostheses use such signals detected by the electrodes placed on the user's stump, as input to generate hand posture movements according to the intentions of the prosthesis wearer. The aim of this pilot study is to explore the repeatability issue, i.e. the ability to classify 17 different hand postures, represented by EMG signal, across a time span of days by a control algorithm. Data collection experiments lasted four days and signals were collected from the forearm of a single subject. We find that Support Vector Machine (SVM) classification results are high enough to guarantee a correct classification of more than 10 postures in each moment of the considered time span.
COCO-FUNIT: Few-Shot Unsupervised Image Translation with a Content Conditioned Style Encoder
Jul 29, 2020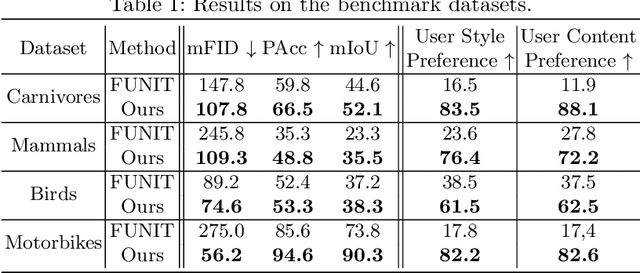
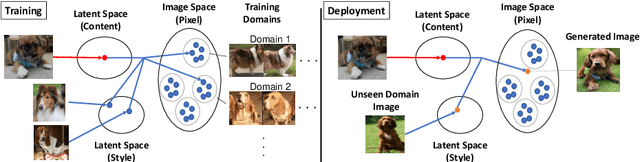
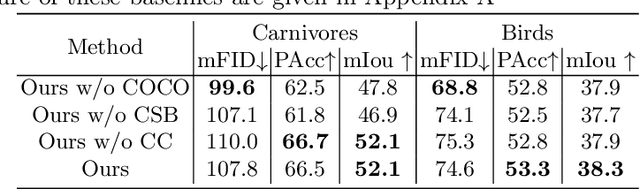

Unsupervised image-to-image translation intends to learn a mapping of an image in a given domain to an analogous image in a different domain, without explicit supervision of the mapping. Few-shot unsupervised image-to-image translation further attempts to generalize the model to an unseen domain by leveraging example images of the unseen domain provided at inference time. While remarkably successful, existing few-shot image-to-image translation models find it difficult to preserve the structure of the input image while emulating the appearance of the unseen domain, which we refer to as the content loss problem. This is particularly severe when the poses of the objects in the input and example images are very different. To address the issue, we propose a new few-shot image translation model, COCO-FUNIT, which computes the style embedding of the example images conditioned on the input image and a new module called the constant style bias. Through extensive experimental validations with comparison to the state-of-the-art, our model shows effectiveness in addressing the content loss problem. For code and pretrained models, please check out https://nvlabs.github.io/COCO-FUNIT/ .
From parameter calibration to parameter learning: Revolutionizing large-scale geoscientific modeling with big data
Aug 18, 2020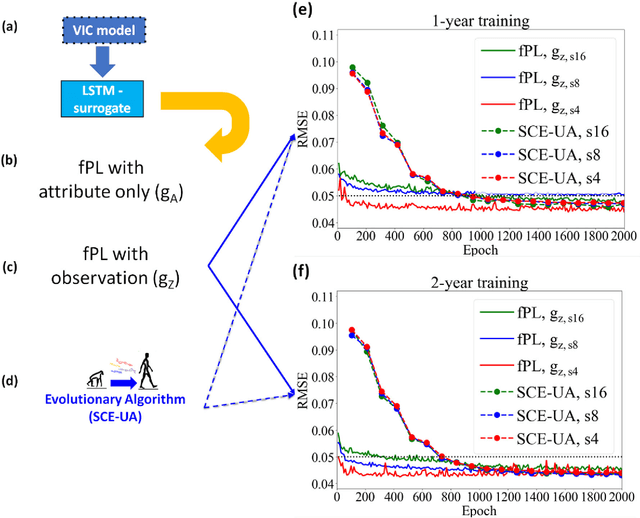
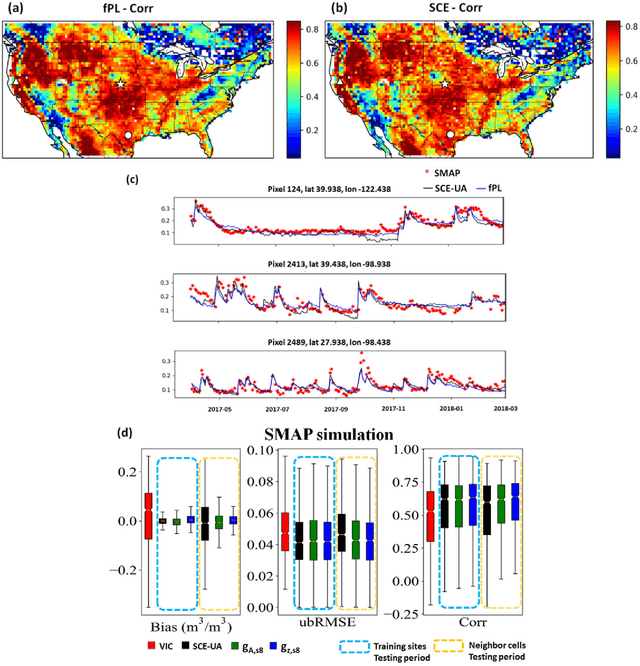
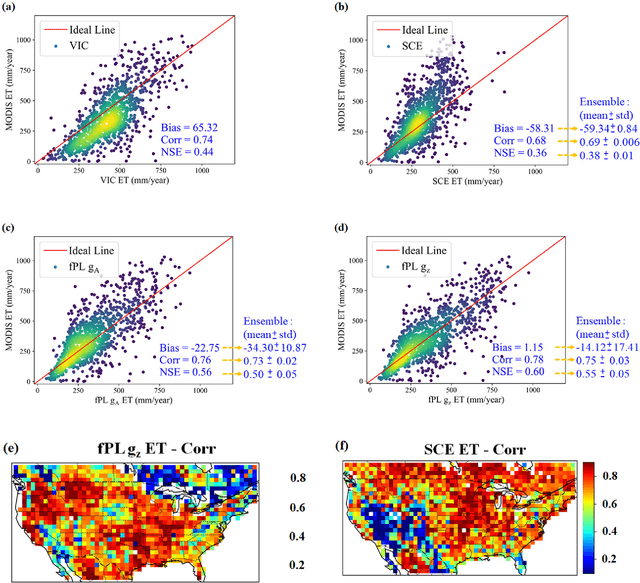
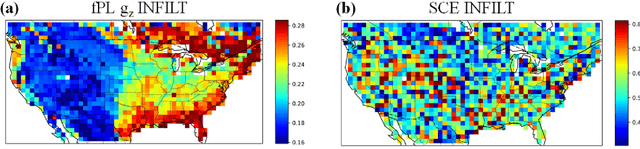
The behaviors and skills of models in many geoscientific domains strongly depend on spatially varying parameters that lack direct observations and must be determined by calibration. Calibration, which solves inverse problems, is a classical but inefficient and stochasticity-ridden approach to reconcile models and observations. Using a widely applied hydrologic model and soil moisture observations as a case study, here we propose a novel, forward-mapping parameter learning (fPL) framework. Whereas evolutionary algorithm (EA)-based calibration solves inversion problems one by one, fPL solves a pattern recognition problem and learns a more robust, universal mapping. fPL can save orders-of-magnitude computational time compared to EA-based calibration, while, surprisingly, producing equivalent ending skill metrics. With more training data, fPL learned across sites and showed super-convergence, scaling much more favorably. Moreover, a more important benefit emerged: fPL produced spatially-coherent parameters in better agreement with physical processes. As a result, it demonstrated better results for out-of-training-set locations and uncalibrated variables. Compared to purely data-driven models, fPL can output unobserved variables, in this case simulated evapotranspiration, which agrees better with satellite-based estimates than the comparison EA. The deep-learning-powered fPL frameworks can be uniformly applied to myriad other geoscientific models. We contend that a paradigm shift from inverse parameter calibration to parameter learning will greatly propel various geoscientific domains.
CLOCS: Contrastive Learning of Cardiac Signals
May 27, 2020

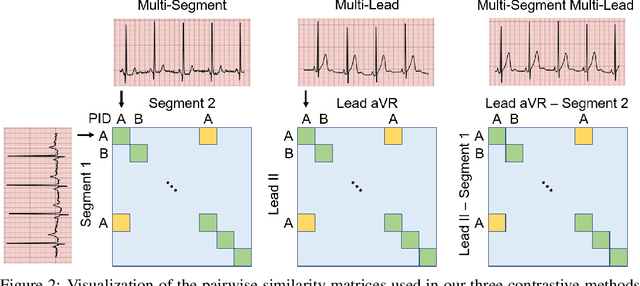
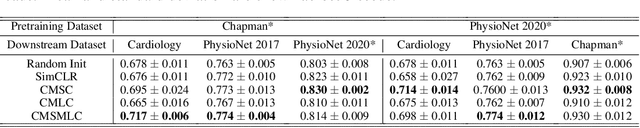
The healthcare industry generates troves of unlabelled physiological data. This data can be exploited via contrastive learning, a self-supervised pre-training mechanism that encourages representations of instances to be similar to one another. We propose a family of contrastive learning methods, CLOCS, that encourages representations across time, leads, and patients to be similar to one another. We show that CLOCS consistently outperforms the state-of-the-art approach, SimCLR, on both linear evaluation and fine-tuning downstream tasks. We also show that CLOCS achieves strong generalization performance with only 25% of labelled training data. Furthermore, our training procedure naturally generates patient-specific representations that can be used to quantify patient-similarity.
Sparse Systolic Tensor Array for Efficient CNN Hardware Acceleration
Sep 04, 2020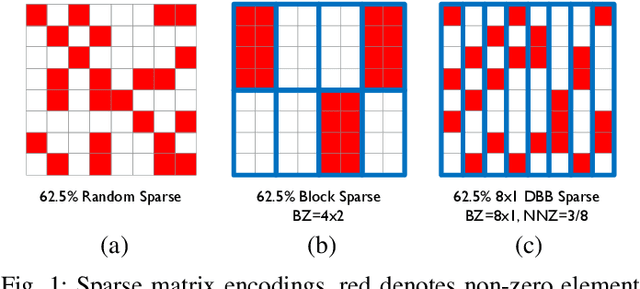
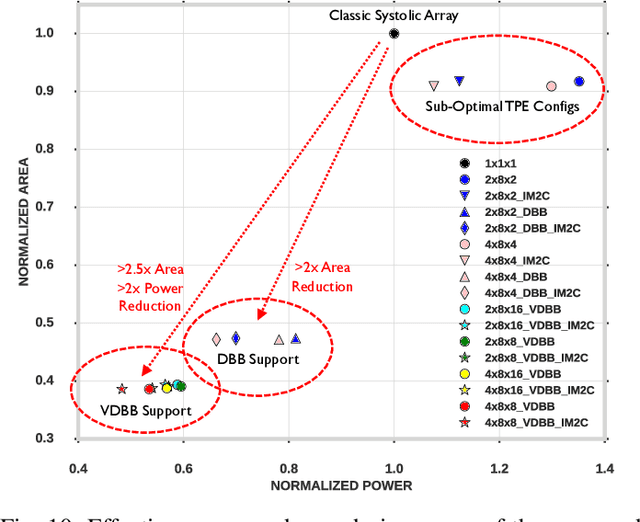

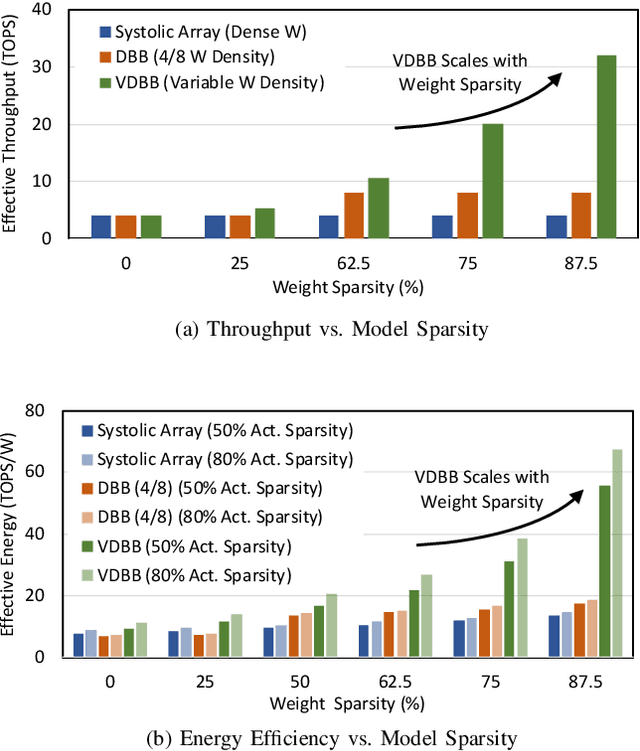
Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). Exploiting data sparsity is a common approach to further accelerate GEMM for CNN inference, and in particular, structural sparsity has the advantages of predictable load balancing and very low index overhead. In this paper, we address a key architectural challenge with structural sparsity: how to provide support for a range of sparsity levels while maintaining high utilization of the hardware. We describe a time unrolled formulation of variable density-bound block (VDBB) sparsity that allows for a configurable number of non-zero elements per block, at constant utilization. We then describe a systolic array microarchitecture that implements this scheme, with two data reuse optimizations. Firstly, we increase reuse in both operands and partial products by increasing the number of MACs per PE. Secondly, we introduce a novel approach of moving the IM2COL transform into the hardware, which allows us to achieve a 3x data bandwidth expansion just before the operands are consumed by the datapath, reducing the SRAM power consumption. The optimizations for weight sparsity, activation sparsity and data reuse are all interrelated and therefore the optimal combination is not obvious. Therefore, we perform an design space evaluation to find the pareto-optimal design characteristics. The resulting design achieves 16.8 TOPS/W in 16nm with modest 50% model sparsity and scales with model sparsity up to 55.7TOPS/W at 87.5%. As well as successfully demonstrating the variable DBB technique, this result significantly outperforms previously reported sparse CNN accelerators.
EllipBody: A Light-weight and Part-based Representation for Human Pose and Shape Recovery
Mar 24, 2020

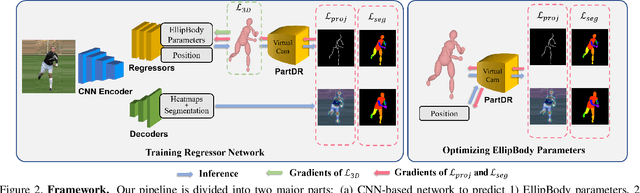
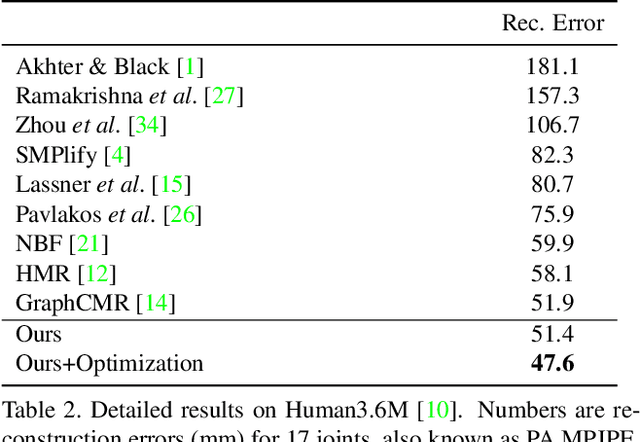
Human pose and shape recovery is an important task in computer vision and real-world understanding. Current works are tackled due to the lack of 3D annotations for whole body shapes. We find that part segmentation is a very efficient 2D annotation in 3D human body recovery. It not only indicates the location of each part but also contains 3D information through occlusions from the shape of parts, as indicated in Figure 1. To better utilize 3D information contained in part segmentation, we propose a part-level differentiable renderer which model occlusion between parts explicitly. It enhances the performance in both learning-based and optimization-based methods. To further improve the efficiency of the task, we propose a light-weight body model called EllipBody, which uses ellipsoids to indicate each body part. Together with SMPL, the relationship between forward time, performance and number of faces in body models are analyzed. A small number of faces is chosen for achieving good performance and efficiency at the same time. Extensive experiments show that our methods achieve the state-of-the-art results on Human3.6M and LSP dataset for 3D pose estimation and part segmentation.
Edge and Identity Preserving Network for Face Super-Resolution
Aug 27, 2020
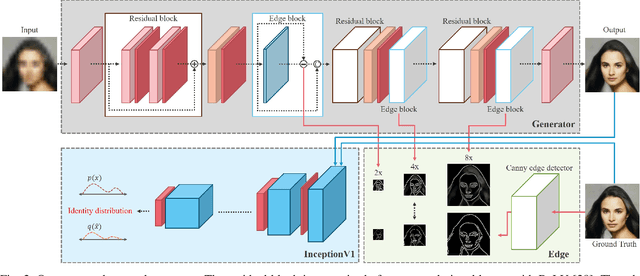
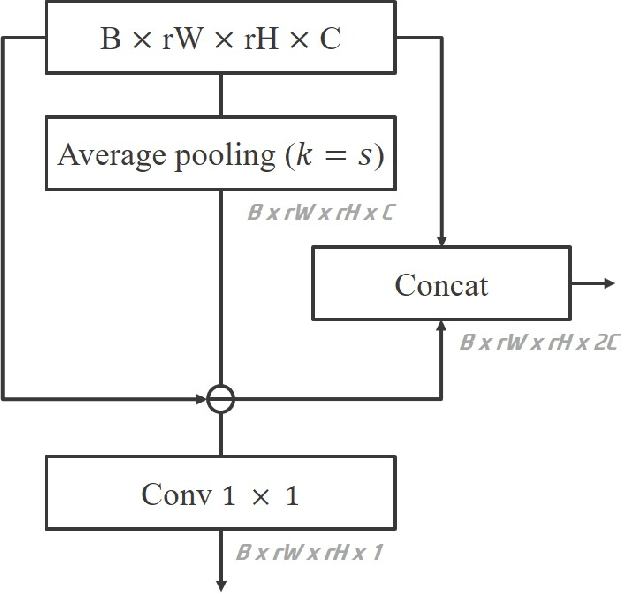
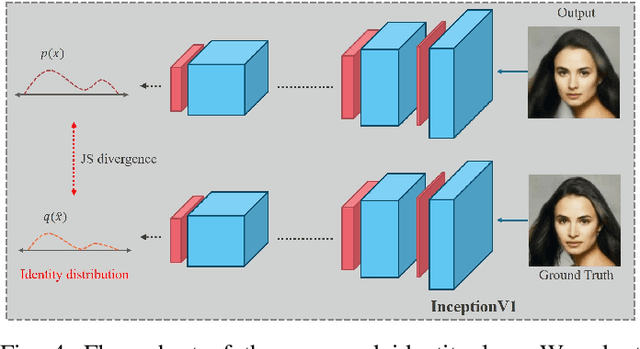
Face super-resolution has become an indispensable part in security problems such as video surveillance and identification system, but the distortion in facial components is a main obstacle to overcoming the problems. To alleviate it, most stateof-the-arts have utilized facial priors by using deep networks. These methods require extra labels, longer training time, and larger computation memory. Thus, we propose a novel Edge and Identity Preserving Network for Face Super-Resolution Network, named as EIPNet, which minimizes the distortion by utilizing a lightweight edge block and identity information. Specifically, the edge block extracts perceptual edge information and concatenates it to original feature maps in multiple scales. This structure progressively provides edge information in reconstruction procedure to aggregate local and global structural information. Moreover, we define an identity loss function to preserve identification of super-resolved images. The identity loss function compares feature distributions between super-resolved images and target images to solve unlabeled classification problem. In addition, we propose a Luminance-Chrominance Error (LCE) to expand usage of image representation domain. The LCE method not only reduces the dependency of color information by dividing brightness and color components but also facilitates our network to reflect differences between Super-Resolution (SR) and High- Resolution (HR) images in multiple domains (RGB and YUV). The proposed methods facilitate our super-resolution network to elaborately restore facial components and generate enhanced 8x scaled super-resolution images with a lightweight network structure.
Average Case Column Subset Selection for Entrywise $\ell_1$-Norm Loss
Apr 16, 2020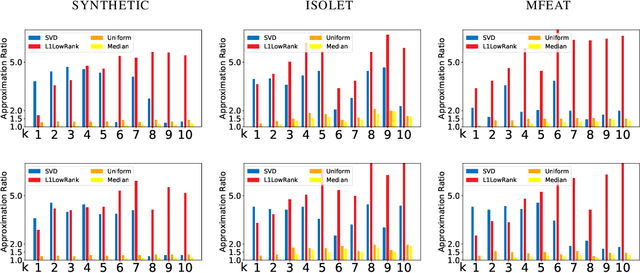
We study the column subset selection problem with respect to the entrywise $\ell_1$-norm loss. It is known that in the worst case, to obtain a good rank-$k$ approximation to a matrix, one needs an arbitrarily large $n^{\Omega(1)}$ number of columns to obtain a $(1+\epsilon)$-approximation to the best entrywise $\ell_1$-norm low rank approximation of an $n \times n$ matrix. Nevertheless, we show that under certain minimal and realistic distributional settings, it is possible to obtain a $(1+\epsilon)$-approximation with a nearly linear running time and poly$(k/\epsilon)+O(k\log n)$ columns. Namely, we show that if the input matrix $A$ has the form $A = B + E$, where $B$ is an arbitrary rank-$k$ matrix, and $E$ is a matrix with i.i.d. entries drawn from any distribution $\mu$ for which the $(1+\gamma)$-th moment exists, for an arbitrarily small constant $\gamma > 0$, then it is possible to obtain a $(1+\epsilon)$-approximate column subset selection to the entrywise $\ell_1$-norm in nearly linear time. Conversely we show that if the first moment does not exist, then it is not possible to obtain a $(1+\epsilon)$-approximate subset selection algorithm even if one chooses any $n^{o(1)}$ columns. This is the first algorithm of any kind for achieving a $(1+\epsilon)$-approximation for entrywise $\ell_1$-norm loss low rank approximation.