 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On $\ell_p$-norm Robustness of Ensemble Stumps and Trees
Aug 20, 2020


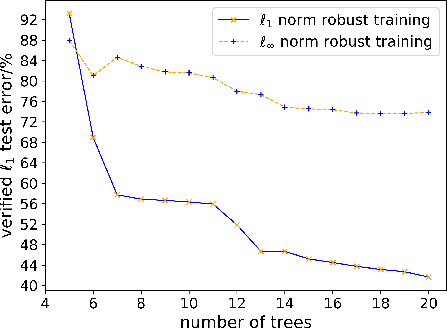
Recent papers have demonstrated that ensemble stumps and trees could be vulnerable to small input perturbations, so robustness verification and defense for those models have become an important research problem. However, due to the structure of decision trees, where each node makes decision purely based on one feature value, all the previous works only consider the $\ell_\infty$ norm perturbation. To study robustness with respect to a general $\ell_p$ norm perturbation, one has to consider the correlation between perturbations on different features, which has not been handled by previous algorithms. In this paper, we study the problem of robustness verification and certified defense with respect to general $\ell_p$ norm perturbations for ensemble decision stumps and trees. For robustness verification of ensemble stumps, we prove that complete verification is NP-complete for $p\in(0, \infty)$ while polynomial time algorithms exist for $p=0$ or $\infty$. For $p\in(0, \infty)$ we develop an efficient dynamic programming based algorithm for sound verification of ensemble stumps. For ensemble trees, we generalize the previous multi-level robustness verification algorithm to $\ell_p$ norm. We demonstrate the first certified defense method for training ensemble stumps and trees with respect to $\ell_p$ norm perturbations, and verify its effectiveness empirically on real datasets.
High-Dimensional Multivariate Forecasting with Low-Rank Gaussian Copula Processes
Oct 07, 2019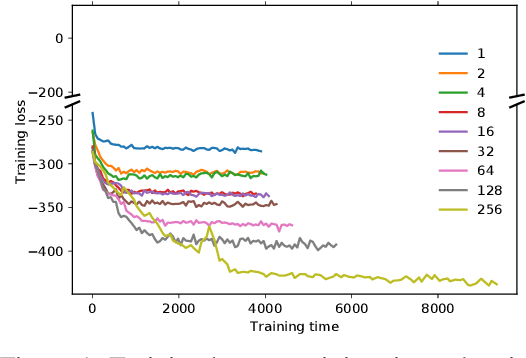

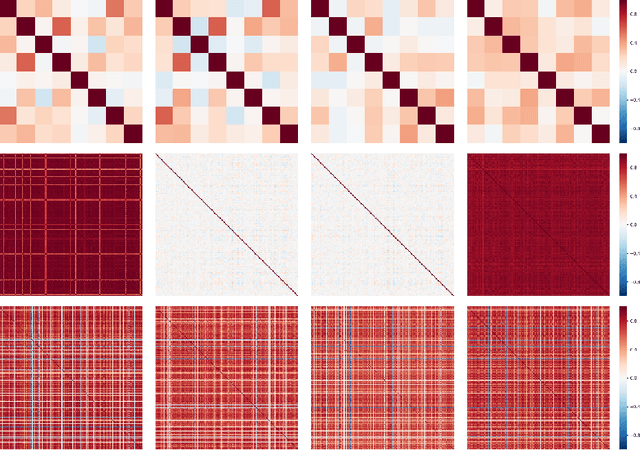
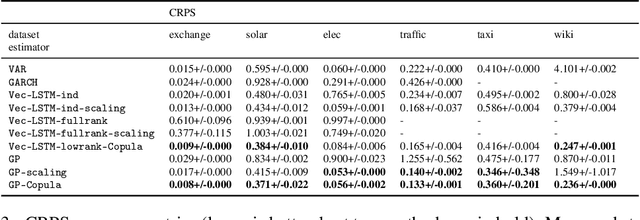
Predicting the dependencies between observations from multiple time series is critical for applications such as anomaly detection, financial risk management, causal analysis, or demand forecasting. However, the computational and numerical difficulties of estimating time-varying and high-dimensional covariance matrices often limits existing methods to handling at most a few hundred dimensions or requires making strong assumptions on the dependence between series. We propose to combine an RNN-based time series model with a Gaussian copula process output model with a low-rank covariance structure to reduce the computational complexity and handle non-Gaussian marginal distributions. This permits to drastically reduce the number of parameters and consequently allows the modeling of time-varying correlations of thousands of time series. We show on several real-world datasets that our method provides significant accuracy improvements over state-of-the-art baselines and perform an ablation study analyzing the contributions of the different components of our model.
Communication Contention Aware Scheduling of Multiple Deep Learning Training Jobs
Feb 24, 2020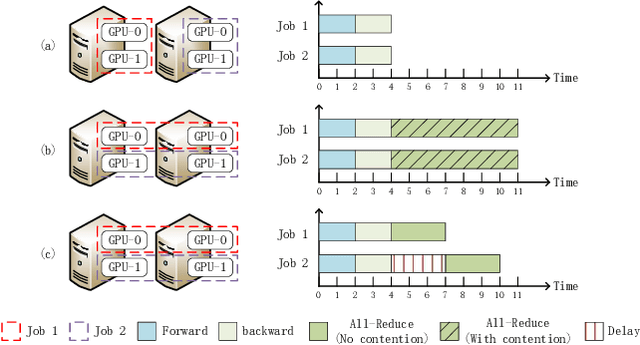
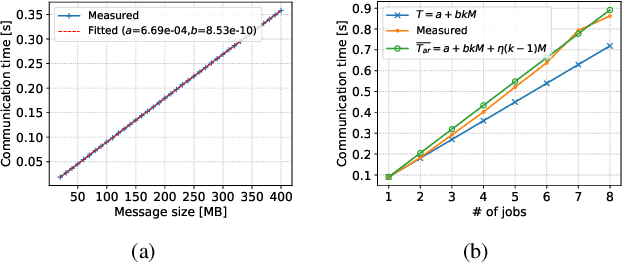
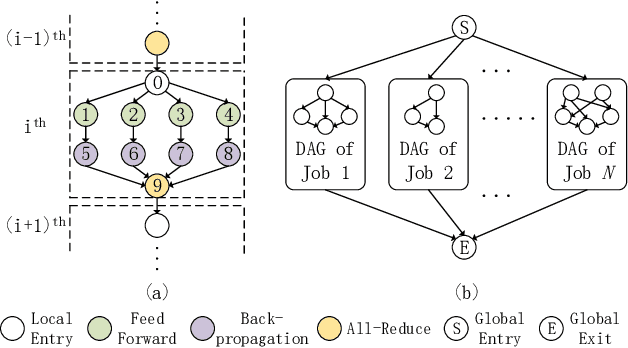
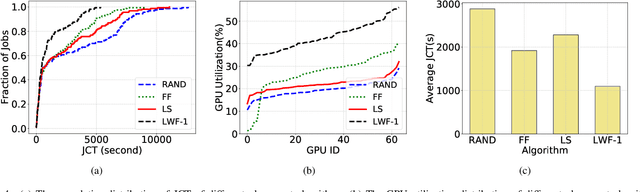
Distributed Deep Learning (DDL) has rapidly grown its popularity since it helps boost the training performance on high-performance GPU clusters. Efficient job scheduling is indispensable to maximize the overall performance of the cluster when training multiple jobs simultaneously. However, existing schedulers do not consider the communication contention of multiple communication tasks from different distributed training jobs, which could deteriorate the system performance and prolong the job completion time. In this paper, we first establish a new DDL job scheduling framework which organizes DDL jobs as Directed Acyclic Graphs (DAGs) and considers communication contention between nodes. We then propose an efficient algorithm, LWF-$\kappa$, to balance the GPU utilization and consolidate the allocated GPUs for each job. When scheduling those communication tasks, we observe that neither avoiding all the contention nor blindly accepting them is optimal to minimize the job completion time. We thus propose a provable algorithm, AdaDUAL, to efficiently schedule those communication tasks. Based on AdaDUAL, we finally propose Ada-SRSF for the DDL job scheduling problem. Simulations on a 64-GPU cluster connected with 10 Gbps Ethernet show that LWF-$\kappa$ achieves up to $1.59\times$ improvement over the classical first-fit algorithms. More importantly, Ada-SRSF reduces the average job completion time by $20.1\%$ and $36.7\%$, as compared to the SRSF(1) scheme (avoiding all the contention) and the SRSF(2) scheme (blindly accepting all of two-way communication contention) respectively.
Fast Gradient Projection Method for Text Adversary Generation and Adversarial Training
Aug 09, 2020



Adversarial training has shown effectiveness and efficiency in improving the robustness of deep neural networks for image classification. For text classification, however, the discrete property of the text input space makes it hard to adapt the gradient-based adversarial methods from the image domain. Existing text attack methods, moreover, are effective but not efficient enough to be incorporated into practical text adversarial training. In this work, we propose a Fast Gradient Projection Method (FGPM) to generate text adversarial examples based on synonym substitution, where each substitution is scored by the product of gradient magnitude and the projected distance between the original word and the candidate word in the gradient direction. Empirical evaluations demonstrate that FGPM achieves similar attack performance and transferability when compared with competitive attack baselines, at the same time it is about 20 times faster than the current fastest text attack method. Such performance enables us to incorporate FGPM with adversarial training as an effective defense method, and scale to large neural networks and datasets. Experiments show that the adversarial training with FGPM (ATF) significantly improves the model robustness, and blocks the transferability of adversarial examples without any decay on the model generalization.
Randomness Evaluation of a Genetic Algorithm for Image Encryption: A Signal Processing Approach
Aug 09, 2020In this paper a randomness evaluation of a block cipher for secure image communication is presented. The GFHT cipher is a genetic algorithm, that combines gene fusion (GF) and horizontal gene transfer (HGT) both inspired from antibiotic resistance in bacteria. The symmetric encryption key is generated by four pairs of chromosomes with multi-layer random sequences. The encryption starts by a GF of the principal key-agent in a single block, then HGT performs obfuscation where the genes are pixels and the chromosomes are the rows and columns. A Salt extracted from the image hash-value is used to implement one-time pad (OTP) scheme, hence a modification of one pixel generates a different encryption key without changing the main passphrase or key. Therefore, an extreme avalanche effect of 99% is achieved. Randomness evaluation based on random matrix theory, power spectral density, avalanche effect, 2D auto-correlation, pixels randomness tests and chi-square hypotheses testing show that encrypted images adopt the statistical behavior of uniform white noise; hence validating the theoretical model by experimental results. Moreover, performance comparison with chaos-genetic ciphers shows the merit of the GFHT algorithm.
Design and Development of a Robotic Vehicle for Shallow-Water Marine Inspections
Jul 09, 2020

Underwater marine inspections for ship hull or marine debris, etc. are one of the vital measures carried out to ensure the safety of marine structures and underwater species. This work details the design, development and qualification of a compact and economical observation class Remotely Operated Vehicle (ROV) prototype, intended for carrying out scientific research in shallow-waters. The ROV has a real-time processor and controller onboard, which synchronizes the movement of the vehicle based on the commands from the surface station. The vehicle piloting is done using the onboard Raspberry pi camera and the support of some navigation sensors like Global Positioning System (GPS), inertial, temperature, depth and pressure. This prototype of ROV is a compact unit built using a limited number of components and is suitable for underwater inspection using a single camera. The developed ROV is initially tested in a pool.
Robust Photogeometric Localization over Time for Map-Centric Loop Closure
Jan 30, 2019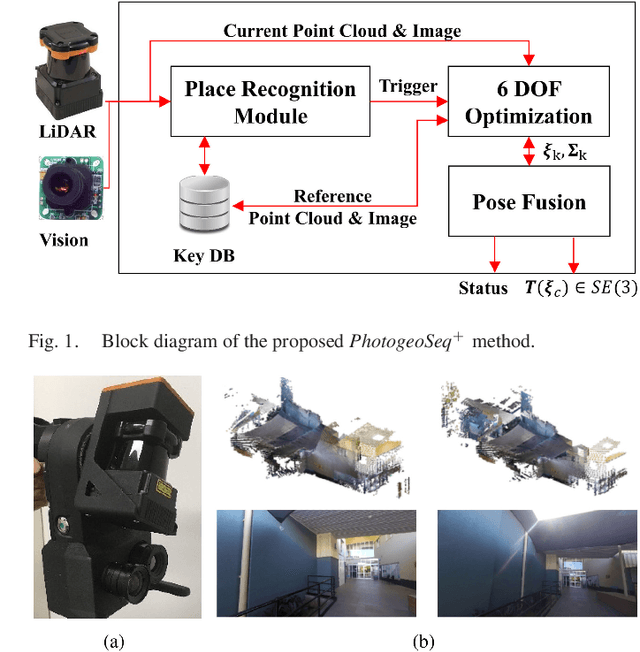
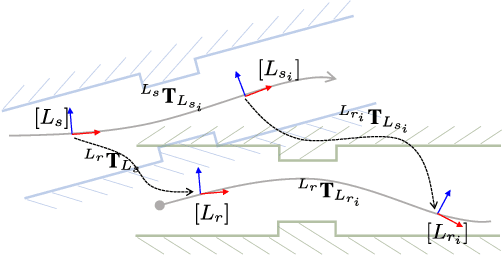
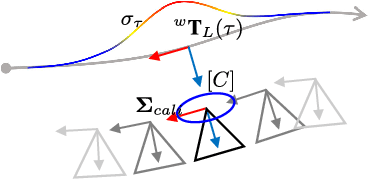
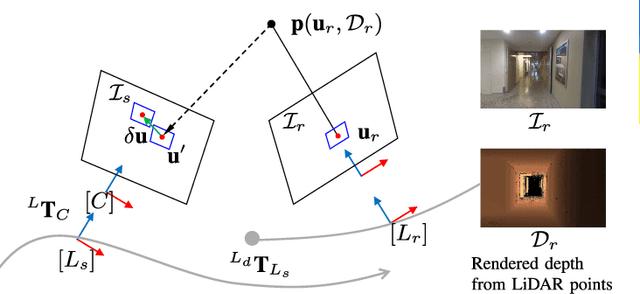
Map-centric SLAM is emerging as an alternative of conventional graph-based SLAM for its accuracy and efficiency in long-term mapping problems. However, in map-centric SLAM, the process of loop closure differs from that of conventional SLAM and the result of incorrect loop closure is more destructive and is not reversible. In this paper, we present a tightly coupled photogeometric metric localization for the loop closure problem in map-centric SLAM. In particular, our method combines complementary constraints from LiDAR and camera sensors, and validates loop closure candidates with sequential observations. The proposed method provides a visual evidence-based outlier rejection where failures caused by either place recognition or localization outliers can be effectively removed. We demonstrate the proposed method is not only more accurate than the conventional global ICP methods but is also robust to incorrect initial pose guesses.
The Influence of Global Constraints on Similarity Measures for Time-Series Databases
Dec 25, 2013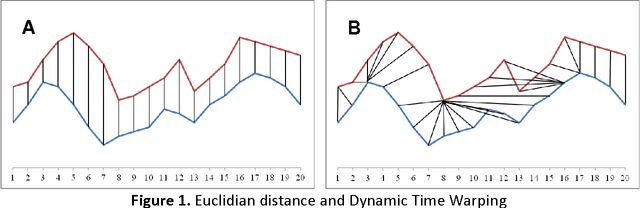
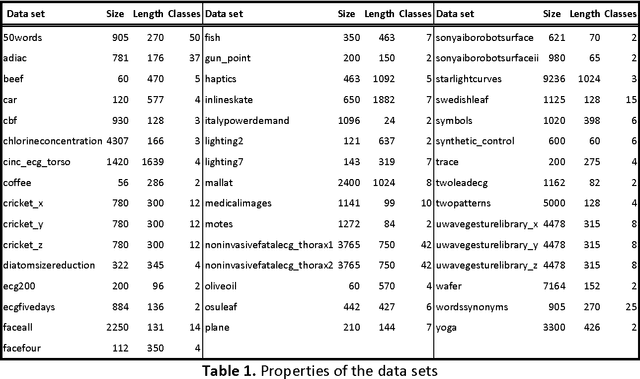

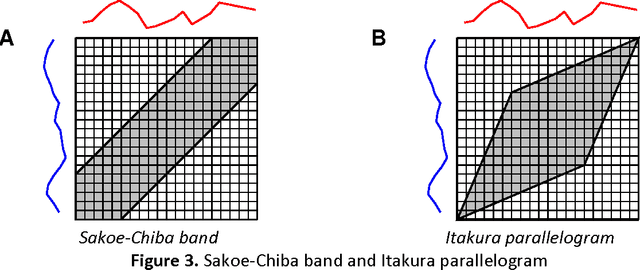
A time series consists of a series of values or events obtained over repeated measurements in time. Analysis of time series represents and important tool in many application areas, such as stock market analysis, process and quality control, observation of natural phenomena, medical treatments, etc. A vital component in many types of time-series analysis is the choice of an appropriate distance/similarity measure. Numerous measures have been proposed to date, with the most successful ones based on dynamic programming. Being of quadratic time complexity, however, global constraints are often employed to limit the search space in the matrix during the dynamic programming procedure, in order to speed up computation. Furthermore, it has been reported that such constrained measures can also achieve better accuracy. In this paper, we investigate two representative time-series distance/similarity measures based on dynamic programming, Dynamic Time Warping (DTW) and Longest Common Subsequence (LCS), and the effects of global constraints on them. Through extensive experiments on a large number of time-series data sets, we demonstrate how global constrains can significantly reduce the computation time of DTW and LCS. We also show that, if the constraint parameter is tight enough (less than 10-15% of time-series length), the constrained measure becomes significantly different from its unconstrained counterpart, in the sense of producing qualitatively different 1-nearest neighbor graphs. This observation explains the potential for accuracy gains when using constrained measures, highlighting the need for careful tuning of constraint parameters in order to achieve a good trade-off between speed and accuracy.
Impact of novel aggregation methods for flexible, time-sensitive EHR prediction without variable selection or cleaning
Sep 17, 2019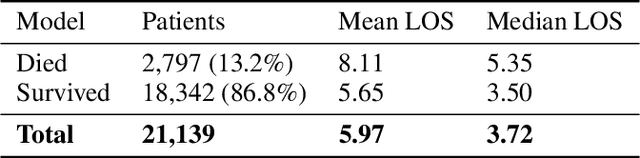
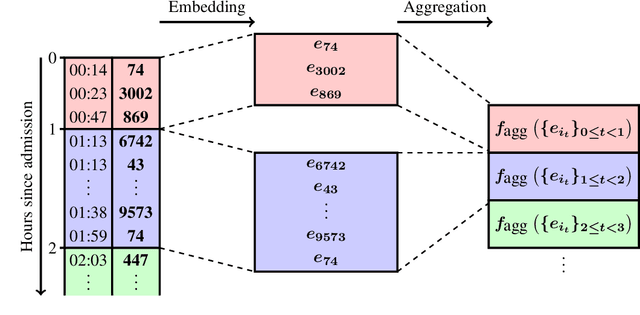

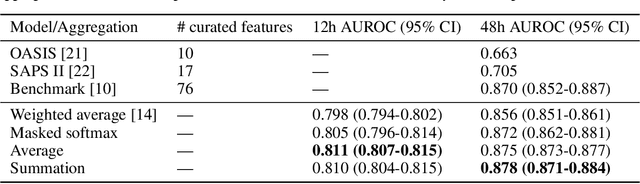
Dynamic assessment of patient status (e.g. by an automated, continuously updated assessment of outcome) in the Intensive Care Unit (ICU) is of paramount importance for early alerting, decision support and resource allocation. Extraction and cleaning of expert-selected clinical variables discards information and protracts collaborative efforts to introduce machine learning in medicine. We present improved aggregation methods for a flexible deep learning architecture which learns a joint representation of patient chart, lab and output events. Our models outperform recent deep learning models for patient mortality classification using ICU timeseries, by embedding and aggregating all events with no pre-processing or variable selection. Our model achieves a strong performance of AUROC 0.87 at 48 hours on the MIMIC-III dataset while using 13,233 unique un-preprocessed variables in an interpretable manner via hourly softmax aggregation. This demonstrates how our method can be easily combined with existing electronic health record systems for automated, dynamic patient risk analysis.
Efficient Planning under Partial Observability with Unnormalized Q Functions and Spectral Learning
Nov 22, 2019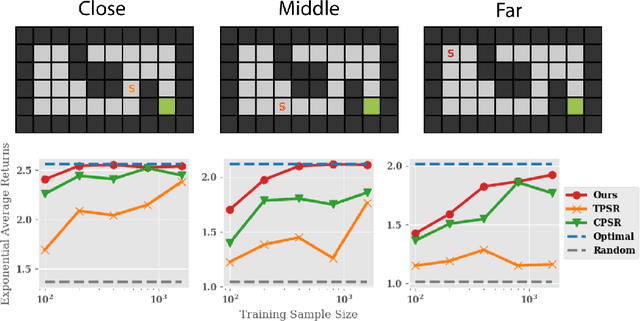
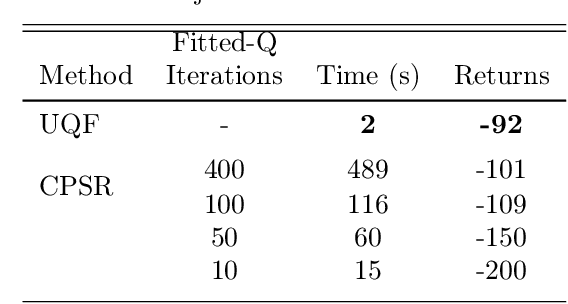
Learning and planning in partially-observable domains is one of the most difficult problems in reinforcement learning. Traditional methods consider these two problems as independent, resulting in a classical two-stage paradigm: first learn the environment dynamics and then plan accordingly. This approach, however, disconnects the two problems and can consequently lead to algorithms that are sample inefficient and time consuming. In this paper, we propose a novel algorithm that combines learning and planning together. Our algorithm is closely related to the spectral learning algorithm for predicitive state representations and offers appealing theoretical guarantees and time complexity. We empirically show on two domains that our approach is more sample and time efficient compared to classical methods.