 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy-aware Scheduling of Jobs in Heterogeneous Cluster Systems Using Deep Reinforcement Learning
Dec 11, 2019
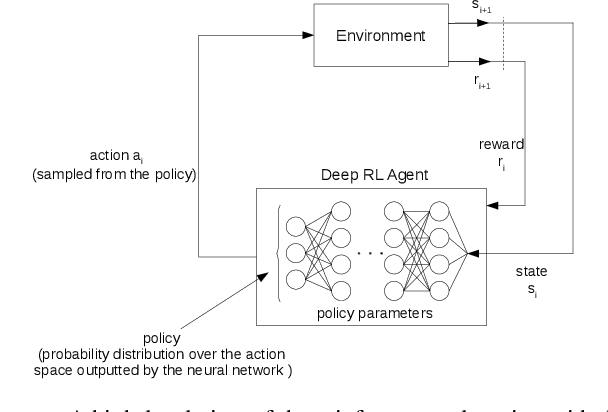

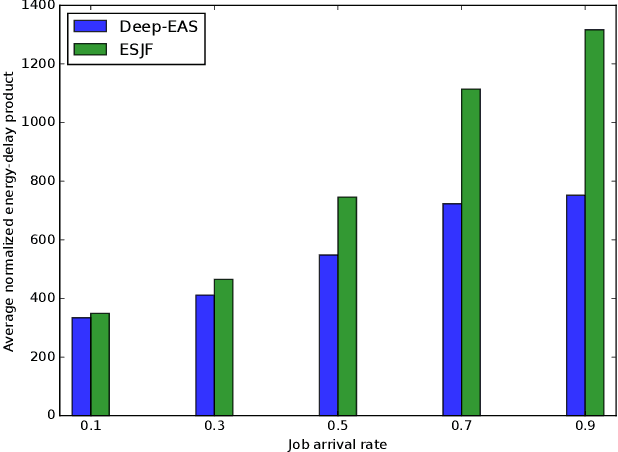
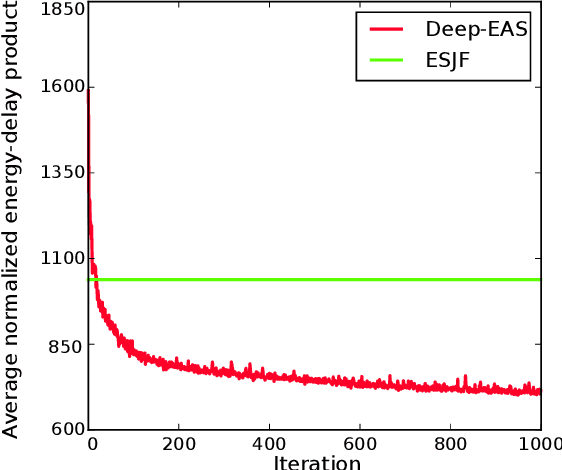
Energy consumption is one of the most critical concerns in designing computing devices, ranging from portable embedded systems to computer cluster systems. Furthermore, in the past decade, cluster systems have increasingly risen as popular platforms to run computing-intensive real-time applications in which the performance is of great importance. However, due to different characteristics of real-time workloads, developing general job scheduling solutions that efficiently address both energy consumption and performance in real-time cluster systems is a challenging problem. In this paper, inspired by recent advances in applying deep reinforcement learning for resource management problems, we present the Deep-EAS scheduler that learns efficient energy-aware scheduling strategies for workloads with different characteristics without initially knowing anything about the scheduling task at hand. Results show that Deep-EAS converges quickly, and performs better compared to standard manually-tuned heuristics, especially in heavy load conditions.
Counterfactual Data Augmentation using Locally Factored Dynamics
Jul 06, 2020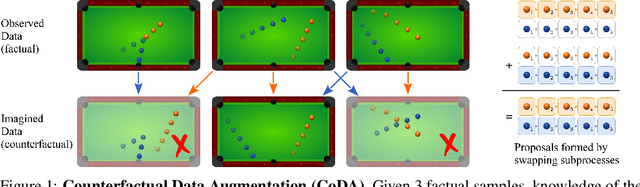
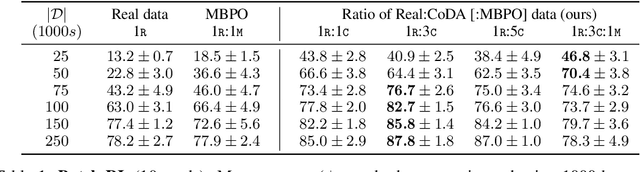

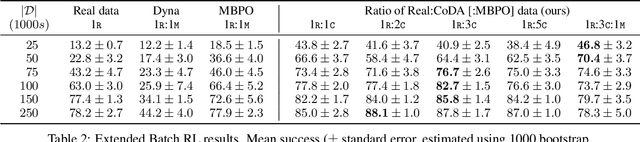
Many dynamic processes, including common scenarios in robotic control and reinforcement learning (RL), involve a set of interacting subprocesses. Though the subprocesses are not independent, their interactions are often sparse, and the dynamics at any given time step can often be decomposed into locally independent causal mechanisms. Such local causal structures can be leveraged to improve the sample efficiency of sequence prediction and off-policy reinforcement learning. We formalize this by introducing local causal models (LCMs), which are induced from a global causal model by conditioning on a subset of the state space. We propose an approach to inferring these structures given an object-oriented state representation, as well as a novel algorithm for model-free Counterfactual Data Augmentation (CoDA). CoDA uses local structures and an experience replay to generate counterfactual experiences that are causally valid in the global model. We find that CoDA significantly improves the performance of RL agents in locally factored tasks, including the batch-constrained and goal-conditioned settings.
Simultaneous Feature and Body-Part Learning for Real-Time Robot Awareness of Human Behaviors
Feb 24, 2017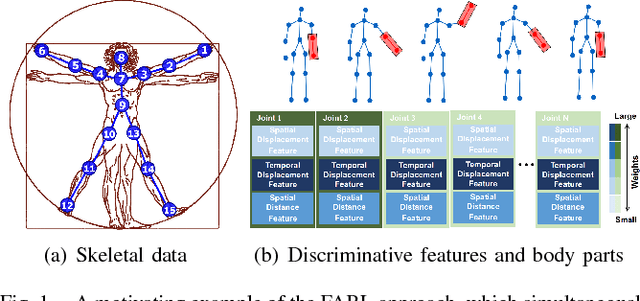
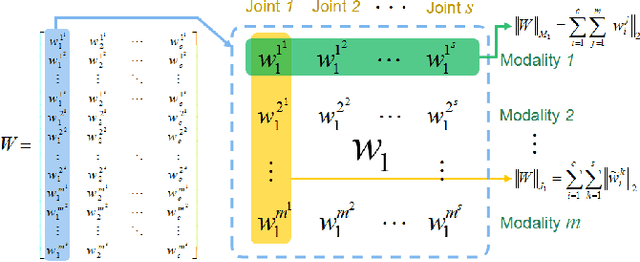
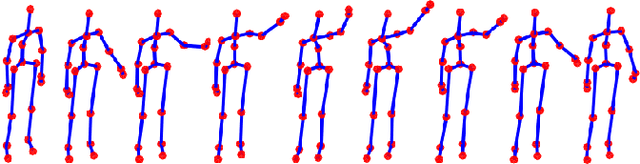
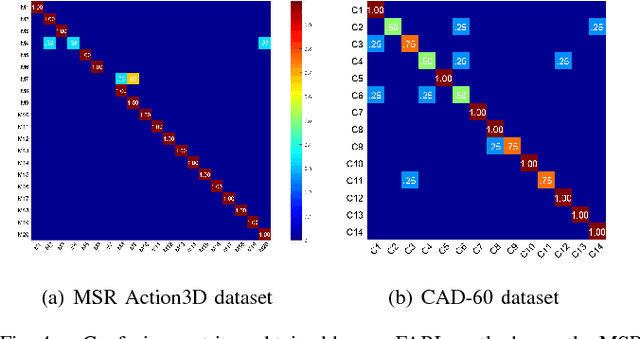
Robot awareness of human actions is an essential research problem in robotics with many important real-world applications, including human-robot collaboration and teaming. Over the past few years, depth sensors have become a standard device widely used by intelligent robots for 3D perception, which can also offer human skeletal data in 3D space. Several methods based on skeletal data were designed to enable robot awareness of human actions with satisfactory accuracy. However, previous methods treated all body parts and features equally important, without the capability to identify discriminative body parts and features. In this paper, we propose a novel simultaneous Feature And Body-part Learning (FABL) approach that simultaneously identifies discriminative body parts and features, and efficiently integrates all available information together to enable real-time robot awareness of human behaviors. We formulate FABL as a regression-like optimization problem with structured sparsity-inducing norms to model interrelationships of body parts and features. We also develop an optimization algorithm to solve the formulated problem, which possesses a theoretical guarantee to find the optimal solution. To evaluate FABL, three experiments were performed using public benchmark datasets, including the MSR Action3D and CAD-60 datasets, as well as a Baxter robot in practical assistive living applications. Experimental results show that our FABL approach obtains a high recognition accuracy with a processing speed of the order-of-magnitude of 10e4 Hz, which makes FABL a promising method to enable real-time robot awareness of human behaviors in practical robotics applications.
A Sensitivity Analysis Approach for Evaluating a Radar Simulation for Virtual Testing of Autonomous Driving Functions
Aug 10, 2020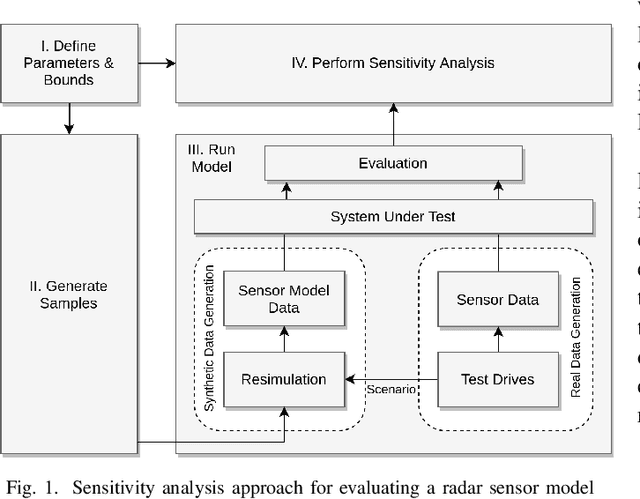
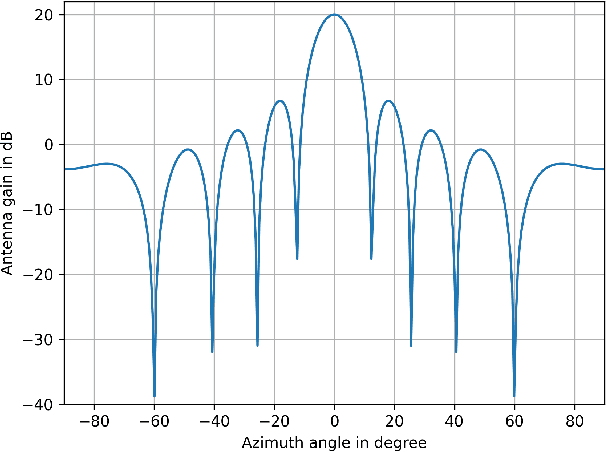
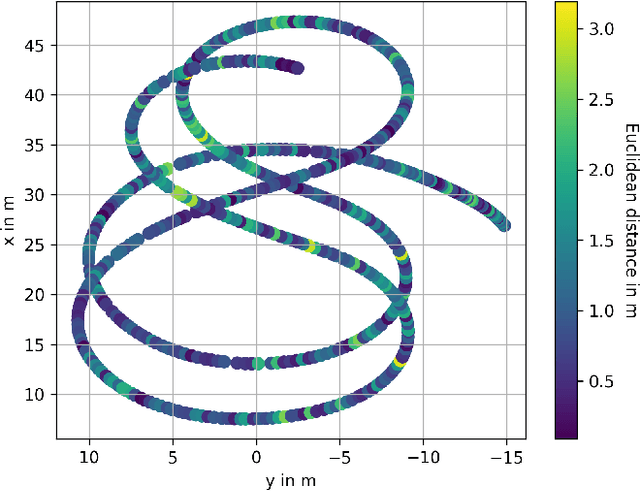
Simulation-based testing is a promising approach to significantly reduce the validation effort of automated driving functions. Realistic models of environment perception sensors such as camera, radar and lidar play a key role in this testing strategy. A generally accepted method to validate these sensor models does not yet exist. Particularly radar has traditionally been one of the most difficult sensors to model. Although promising as an alternative to real test drives, virtual tests are time-consuming due to the fact that they simulate the entire radar system in detail, using computation-intensive simulation techniques to approximate the propagation of electromagnetic waves. In this paper, we introduce a sensitivity analysis approach for developing and evaluating a radar simulation, with the objective to identify the parameters with the greatest impact regarding the system under test. A modular radar system simulation is presented and parameterized to conduct a sensitivity analysis in order to evaluate a spatial clustering algorithm as the system under test, while comparing the output from the radar model to real driving measurements to ensure a realistic model behavior. The presented approach is evaluated and it is demonstrated that with this approach results from different situations can be traced back to the contribution of the individual sub-modules of the radar simulation.
Towards Optimal Convergence Rate in Decentralized Stochastic Training
Jun 15, 2020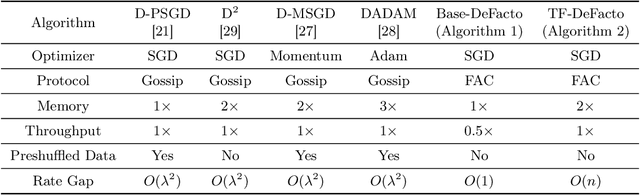
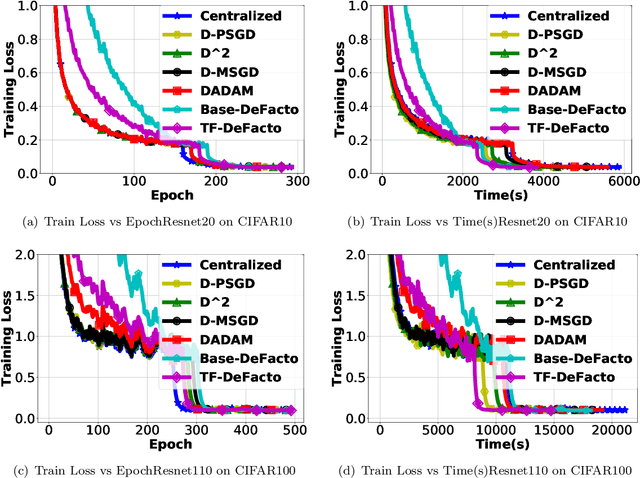

Parallel training with decentralized communication is a promising method of scaling up machine learning systems. In this paper, we provide a tight lower bound on the iteration complexity for such methods in a stochastic non-convex setting. This lower bound reveals a theoretical gap in known convergence rates of many existing algorithms. To show this bound is tight and achievable, we propose DeFacto, a class of algorithms that converge at the optimal rate without additional theoretical assumptions. We discuss the trade-offs among different algorithms regarding complexity, memory efficiency, throughput, etc. Empirically, we compare DeFacto and other decentralized algorithms via training Resnet20 on CIFAR10 and Resnet110 on CIFAR100. We show DeFacto can accelerate training with respect to wall-clock time but progresses slowly in the first few epochs.
Efficient Distance Approximation for Structured High-Dimensional Distributions via Learning
Feb 14, 2020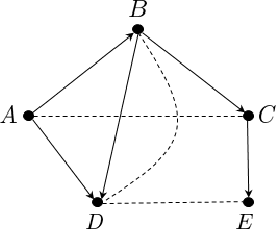
We design efficient distance approximation algorithms for several classes of structured high-dimensional distributions. Specifically, we show algorithms for the following problems: - Given sample access to two Bayesian networks $P_1$ and $P_2$ over known directed acyclic graphs $G_1$ and $G_2$ having $n$ nodes and bounded in-degree, approximate $d_{tv}(P_1,P_2)$ to within additive error $\epsilon$ using $poly(n,\epsilon)$ samples and time - Given sample access to two ferromagnetic Ising models $P_1$ and $P_2$ on $n$ variables with bounded width, approximate $d_{tv}(P_1, P_2)$ to within additive error $\epsilon$ using $poly(n,\epsilon)$ samples and time - Given sample access to two $n$-dimensional Gaussians $P_1$ and $P_2$, approximate $d_{tv}(P_1, P_2)$ to within additive error $\epsilon$ using $poly(n,\epsilon)$ samples and time - Given access to observations from two causal models $P$ and $Q$ on $n$ variables that are defined over known causal graphs, approximate $d_{tv}(P_a, Q_a)$ to within additive error $\epsilon$ using $poly(n,\epsilon)$ samples, where $P_a$ and $Q_a$ are the interventional distributions obtained by the intervention $do(A=a)$ on $P$ and $Q$ respectively for a particular variable $A$. Our results are the first efficient distance approximation algorithms for these well-studied problems. They are derived using a simple and general connection to distribution learning algorithms. The distance approximation algorithms imply new efficient algorithms for {\em tolerant} testing of closeness of the above-mentioned structured high-dimensional distributions.
Laser2Vec: Similarity-based Retrieval for Robotic Perception Data
Jul 30, 2020
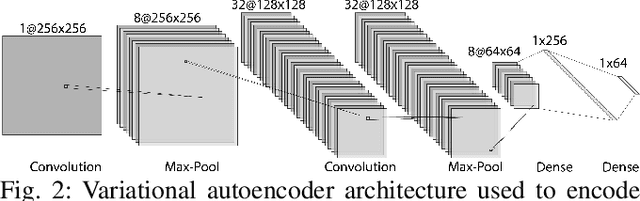
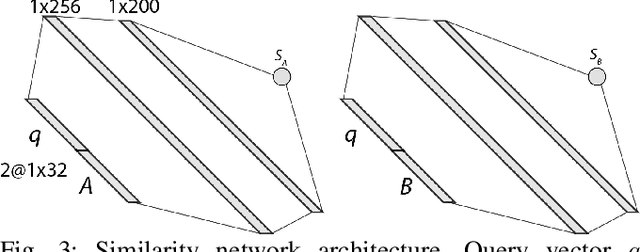
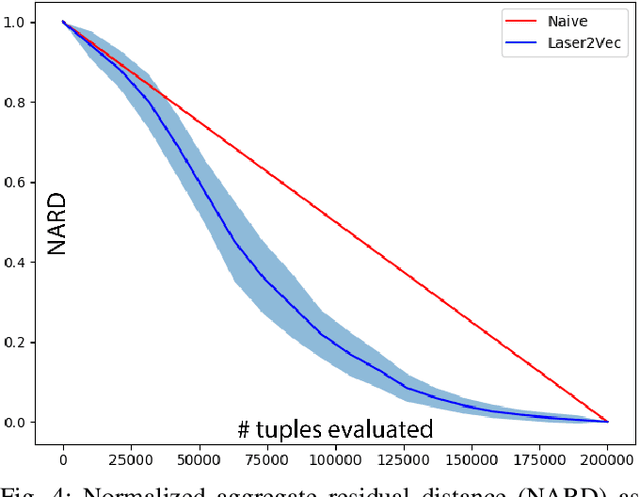
As mobile robot capabilities improve and deployment times increase, tools to analyze the growing volume of data are becoming necessary. Current state-of-the-art logging, playback, and exploration systems are insufficient for practitioners seeking to discover systemic points of failure in robotic systems. This paper presents a suite of algorithms for similarity-based queries of robotic perception data and implements a system for storing 2D LiDAR data from many deployments cheaply and evaluating top-k queries for complete or partial scans efficiently. We generate compressed representations of laser scans via a convolutional variational autoencoder and store them in a database, where a light-weight dense network for distance function approximation is run at query time. Our query evaluator leverages the local continuity of the embedding space to generate evaluation orders that, in expectation, dominate full linear scans of the database. The accuracy, robustness, scalability, and efficiency of our system is tested on real-world data gathered from dozens of deployments and synthetic data generated by corrupting real data. We find our system accurately and efficiently identifies similar scans across a number of episodes where the robot encountered the same location, or similar indoor structures or objects.
BBS-Net: RGB-D Salient Object Detection with a Bifurcated Backbone Strategy Network
Jul 06, 2020
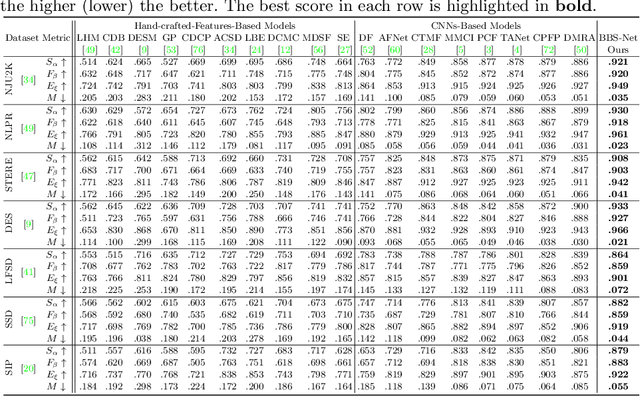

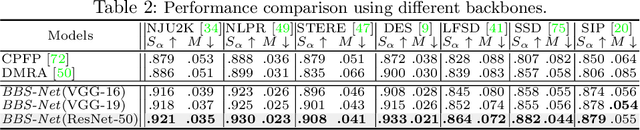
Multi-level feature fusion is a fundamental topic in computer vision for detecting, segmenting, and classifying objects at various scales. When multi-level features meet multi-modal cues, the optimal fusion problem becomes a hot potato. In this paper, we make the first attempt to leverage the inherent multi-modal and multi-level nature of RGB-D salient object detection to develop a novel cascaded refinement network. In particular, we 1) propose a bifurcated backbone strategy (BBS) to split the multi-level features into teacher and student features, and 2) utilize a depth-enhanced module (DEM) to excavate informative parts of depth cues from the channel and spatial views. This fuses RGB and depth modalities in a complementary way. Our simple yet efficient architecture, dubbed Bifurcated Backbone Strategy Network (BBS-Net), is backbone independent, runs in real-time (48 fps), and significantly outperforms 18 SOTAs on seven challenging datasets using four metrics.
HAPI: Hardware-Aware Progressive Inference
Aug 10, 2020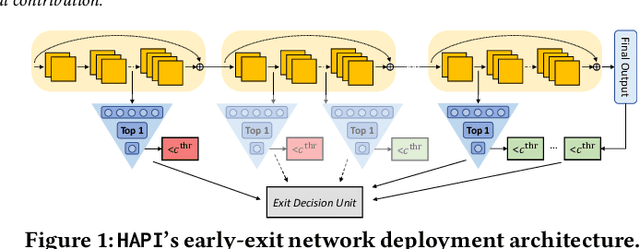

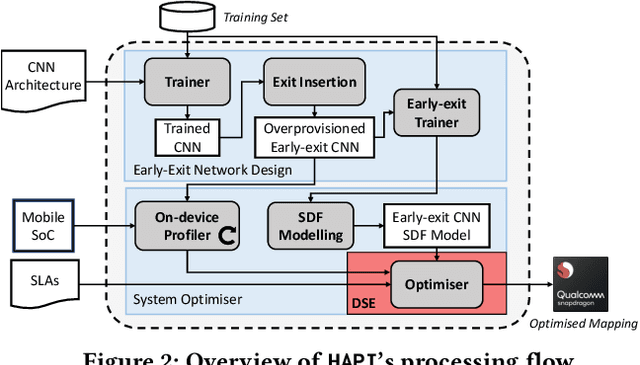
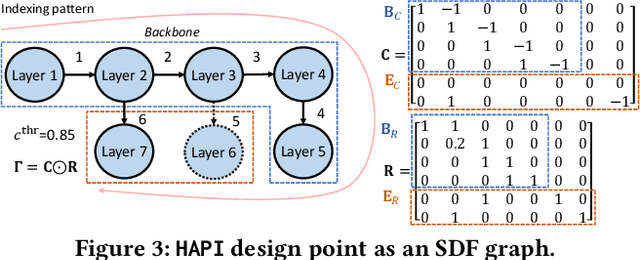
Convolutional neural networks (CNNs) have recently become the state-of-the-art in a diversity of AI tasks. Despite their popularity, CNN inference still comes at a high computational cost. A growing body of work aims to alleviate this by exploiting the difference in the classification difficulty among samples and early-exiting at different stages of the network. Nevertheless, existing studies on early exiting have primarily focused on the training scheme, without considering the use-case requirements or the deployment platform. This work presents HAPI, a novel methodology for generating high-performance early-exit networks by co-optimising the placement of intermediate exits together with the early-exit strategy at inference time. Furthermore, we propose an efficient design space exploration algorithm which enables the faster traversal of a large number of alternative architectures and generates the highest-performing design, tailored to the use-case requirements and target hardware. Quantitative evaluation shows that our system consistently outperforms alternative search mechanisms and state-of-the-art early-exit schemes across various latency budgets. Moreover, it pushes further the performance of highly optimised hand-crafted early-exit CNNs, delivering up to 5.11x speedup over lightweight models on imposed latency-driven SLAs for embedded devices.
Dynamic memory to alleviate catastrophic forgetting in continuous learning settings
Jul 06, 2020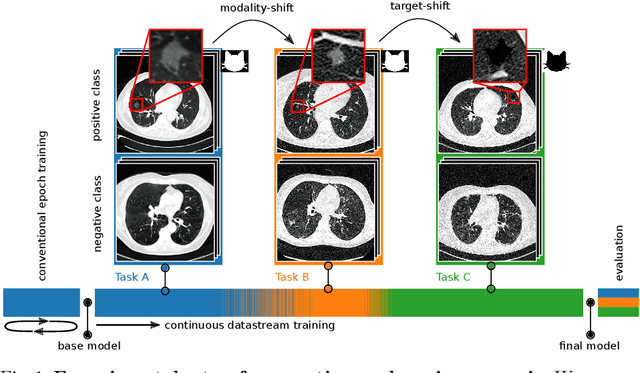
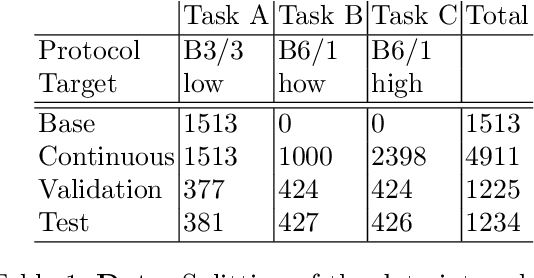
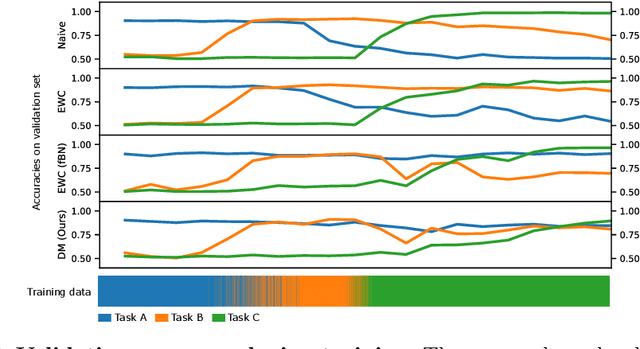
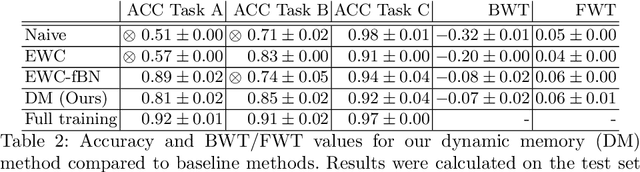
In medical imaging, technical progress or changes in diagnostic procedures lead to a continuous change in image appearance. Scanner manufacturer, reconstruction kernel, dose, other protocol specific settings or administering of contrast agents are examples that influence image content independent of the scanned biology. Such domain and task shifts limit the applicability of machine learning algorithms in the clinical routine by rendering models obsolete over time. Here, we address the problem of data shifts in a continuous learning scenario by adapting a model to unseen variations in the source domain while counteracting catastrophic forgetting effects. Our method uses a dynamic memory to facilitate rehearsal of a diverse training data subset to mitigate forgetting. We evaluated our approach on routine clinical CT data obtained with two different scanner protocols and synthetic classification tasks. Experiments show that dynamic memory counters catastrophic forgetting in a setting with multiple data shifts without the necessity for explicit knowledge about when these shifts occur.