 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SimulEval: An Evaluation Toolkit for Simultaneous Translation
Jul 31, 2020
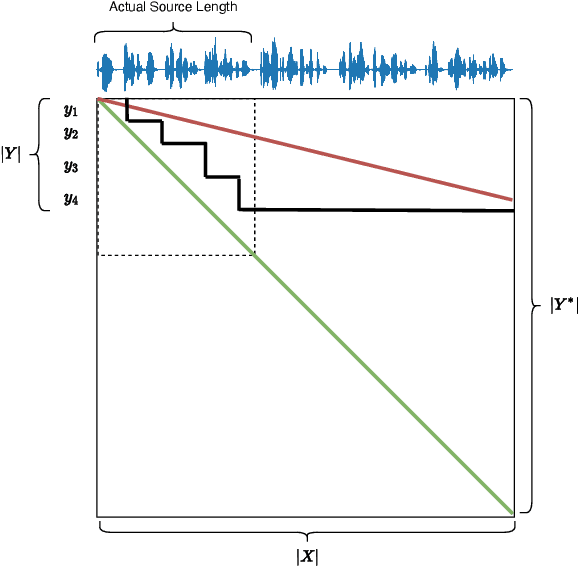

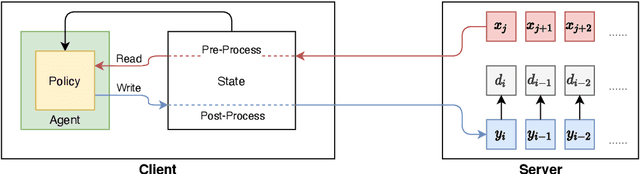
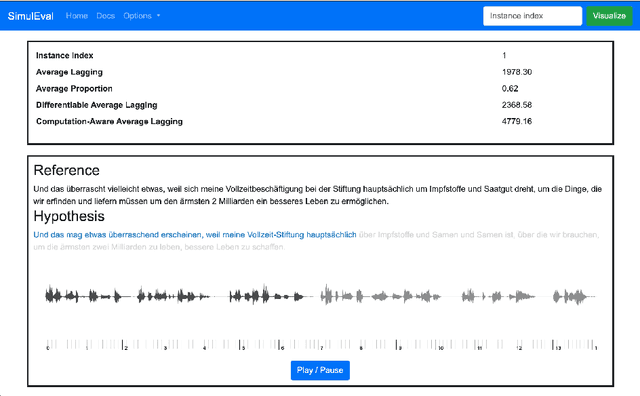
Simultaneous translation on both text and speech focuses on a real-time and low-latency scenario where the model starts translating before reading the complete source input. Evaluating simultaneous translation models is more complex than offline models because the latency is another factor to consider in addition to translation quality. The research community, despite its growing focus on novel modeling approaches to simultaneous translation, currently lacks a universal evaluation procedure. Therefore, we present SimulEval, an easy-to-use and general evaluation toolkit for both simultaneous text and speech translation. A server-client scheme is introduced to create a simultaneous translation scenario, where the server sends source input and receives predictions for evaluation and the client executes customized policies. Given a policy, it automatically performs simultaneous decoding and collectively reports several popular latency metrics. We also adapt latency metrics from text simultaneous translation to the speech task. Additionally, SimulEval is equipped with a visualization interface to provide better understanding of the simultaneous decoding process of a system. SimulEval has already been extensively used for the IWSLT 2020 shared task on simultaneous speech translation. Code will be released upon publication.
Pedestrian Path, Pose and Intention Prediction through Gaussian Process Dynamical Models and Pedestrian Activity Recognition
Apr 30, 2020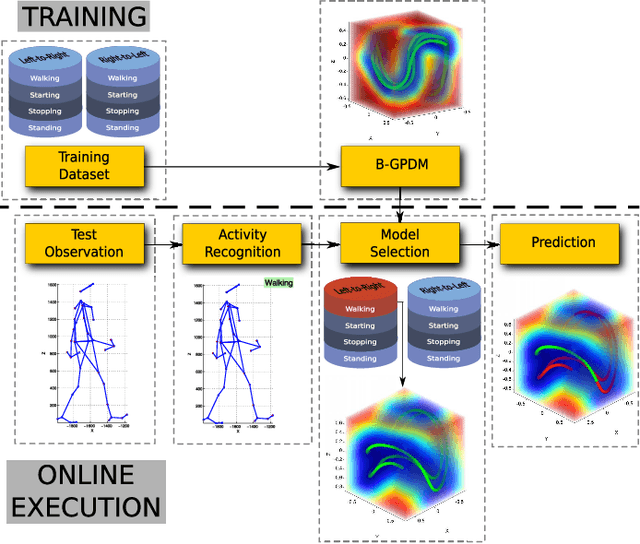
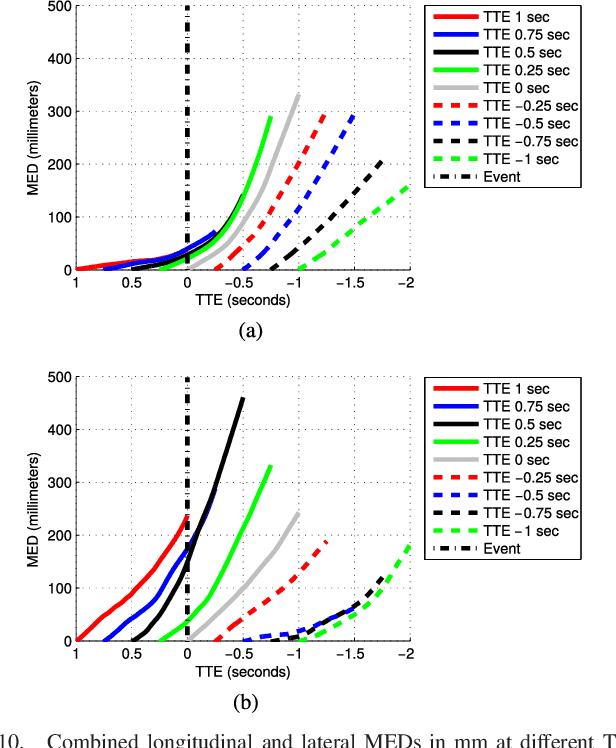
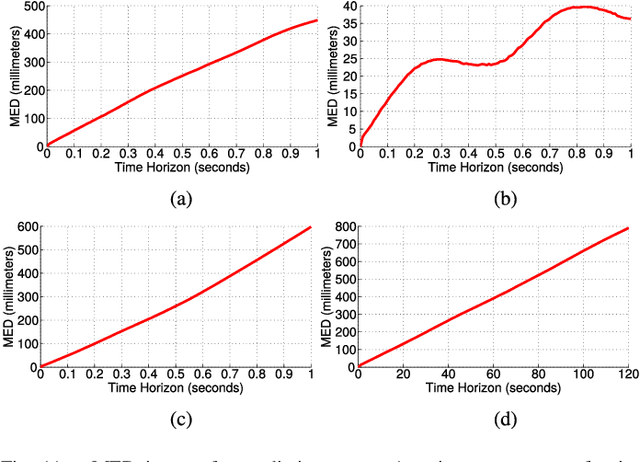
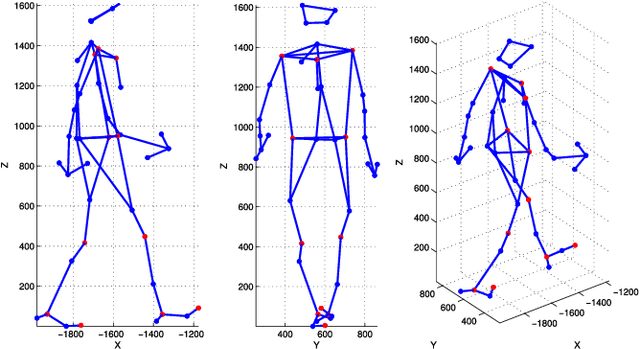
According to several reports published by worldwide organisations, thousands of pedestrians die in road accidents every year. Due to this fact, vehicular technologies have been evolving with the intent of reducing these fatalities. This evolution has not finished yet since, for instance, the predictions of pedestrian paths could improve the current Automatic Emergency Braking Systems (AEBS). For this reason, this paper proposes a method to predict future pedestrian paths, poses and intentions up to 1s in advance. This method is based on Balanced Gaussian Process Dynamical Models (B-GPDMs), which reduce the 3D time-related information extracted from keypoints or joints placed along pedestrian bodies into low-dimensional spaces. The B-GPDM is also capable of inferring future latent positions and reconstruct their associated observations. However, learning a generic model for all kind of pedestrian activities normally provides less ccurate predictions. For this reason, the proposed method obtains multiple models of four types of activity, i.e. walking, stopping, starting and standing, and selects the most similar model to estimate future pedestrian states. This method detects starting activities 125ms after the gait initiation with an accuracy of 80% and recognises stopping intentions 58.33ms before the event with an accuracy of 70%. Concerning the path prediction, the mean error for stopping activities at a Time-To-Event (TTE) of 1s is 238.01mm and, for starting actions, the mean error at a TTE of 0s is 331.93mm.
Studying the control of non invasive prosthetic hands over large time spans
Nov 18, 2015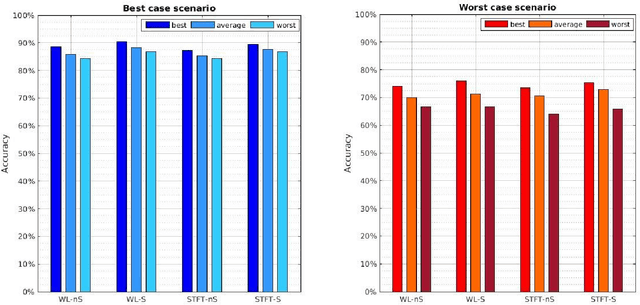

The electromyography (EMG) signal is the electrical manifestation of a neuromuscular activation that provides access to physiological processes which cause the muscle to generate force and produce movement. Non invasive prostheses use such signals detected by the electrodes placed on the user's stump, as input to generate hand posture movements according to the intentions of the prosthesis wearer. The aim of this pilot study is to explore the repeatability issue, i.e. the ability to classify 17 different hand postures, represented by EMG signal, across a time span of days by a control algorithm. Data collection experiments lasted four days and signals were collected from the forearm of a single subject. We find that Support Vector Machine (SVM) classification results are high enough to guarantee a correct classification of more than 10 postures in each moment of the considered time span.
Forced-exploration free Strategies for Unimodal Bandits
Jun 30, 2020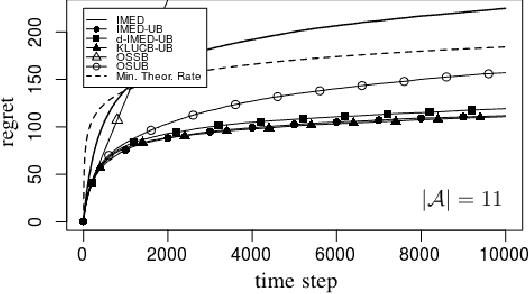
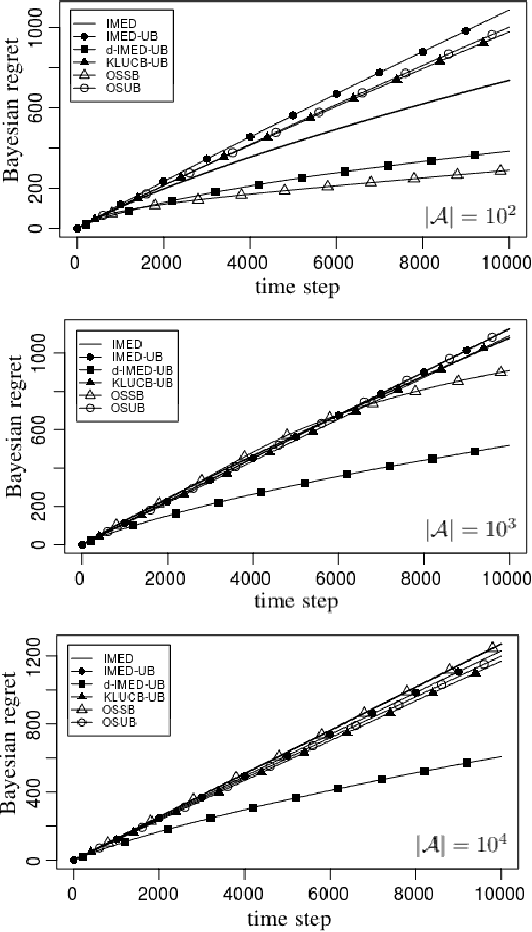
We consider a multi-armed bandit problem specified by a set of Gaussian or Bernoulli distributions endowed with a unimodal structure. Although this problem has been addressed in the literature (Combes and Proutiere, 2014), the state-of-the-art algorithms for such structure make appear a forced-exploration mechanism. We introduce IMED-UB, the first forced-exploration free strategy that exploits the unimodal-structure, by adapting to this setting the Indexed Minimum Empirical Divergence (IMED) strategy introduced by Honda and Takemura (2015). This strategy is proven optimal. We then derive KLUCB-UB, a KLUCB version of IMED-UB, which is also proven optimal. Owing to our proof technique, we are further able to provide a concise finite-time analysis of both strategies in an unified way. Numerical experiments show that both IMED-UB and KLUCB-UB perform similarly in practice and outperform the state-of-the-art algorithms.
AU-AIR: A Multi-modal Unmanned Aerial Vehicle Dataset for Low Altitude Traffic Surveillance
Feb 03, 2020



Unmanned aerial vehicles (UAVs) with mounted cameras have the advantage of capturing aerial (bird-view) images. The availability of aerial visual data and the recent advances in object detection algorithms led the computer vision community to focus on object detection tasks on aerial images. As a result of this, several aerial datasets have been introduced, including visual data with object annotations. UAVs are used solely as flying-cameras in these datasets, discarding different data types regarding the flight (e.g., time, location, internal sensors). In this work, we propose a multi-purpose aerial dataset (AU-AIR) that has multi-modal sensor data (i.e., visual, time, location, altitude, IMU, velocity) collected in real-world outdoor environments. The AU-AIR dataset includes meta-data for extracted frames (i.e., bounding box annotations for traffic-related object category) from recorded RGB videos. Moreover, we emphasize the differences between natural and aerial images in the context of object detection task. For this end, we train and test mobile object detectors (including YOLOv3-Tiny and MobileNetv2-SSDLite) on the AU-AIR dataset, which are applicable for real-time object detection using on-board computers with UAVs. Since our dataset has diversity in recorded data types, it contributes to filling the gap between computer vision and robotics. The dataset is available at https://bozcani.github.io/auairdataset.
CrossCount: A Deep Learning System for Device-free Human Counting using WiFi
Jul 07, 2020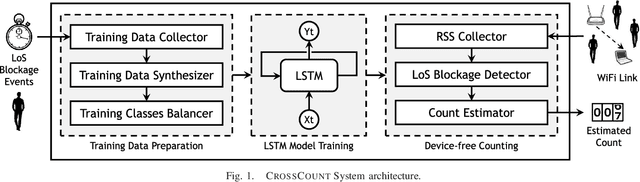
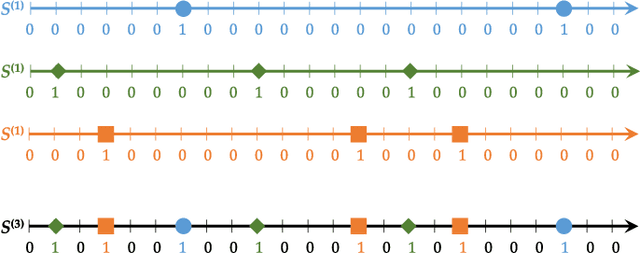
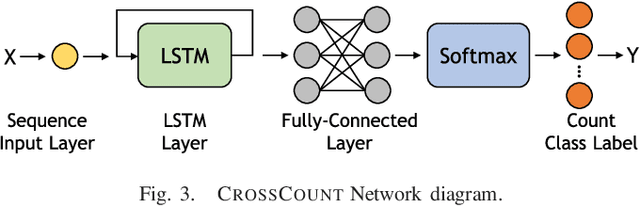
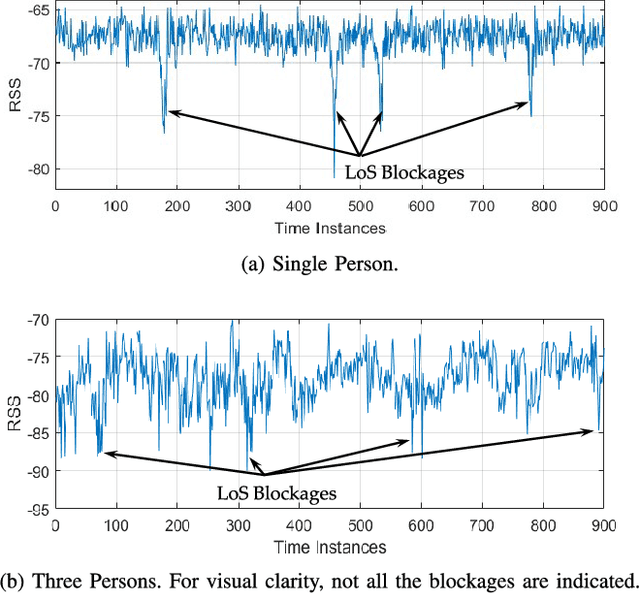
Counting humans is an essential part of many people-centric applications. In this paper, we propose CrossCount: an accurate deep-learning-based human count estimator that uses a single WiFi link to estimate the human count in an area of interest. The main idea is to depend on the temporal link-blockage pattern as a discriminant feature that is more robust to wireless channel noise than the signal strength, hence delivering a ubiquitous and accurate human counting system. As part of its design, CrossCount addresses a number of deep learning challenges such as class imbalance and training data augmentation for enhancing the model generalizability. Implementation and evaluation of CrossCount in multiple testbeds show that it can achieve a human counting accuracy to within a maximum of 2 persons 100% of the time. This highlights the promise of CrossCount as a ubiquitous crowd estimator with non-labour-intensive data collection from off-the-shelf devices.
Predicting heave and surge motions of a semi-submersible with neural networks
Jul 31, 2020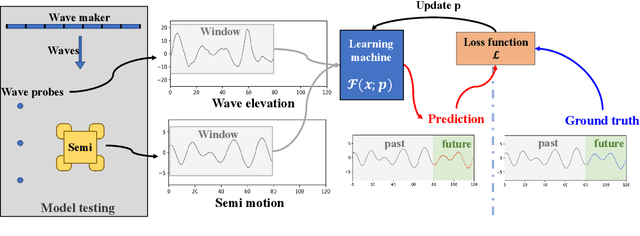
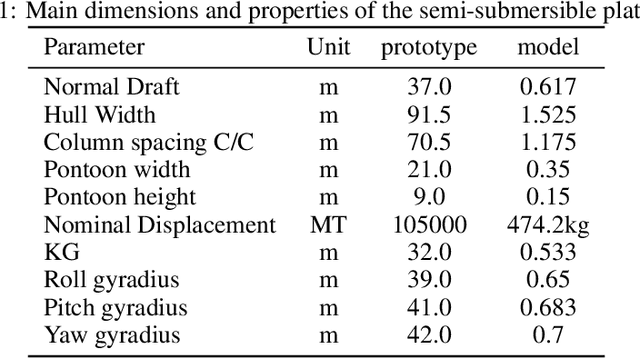
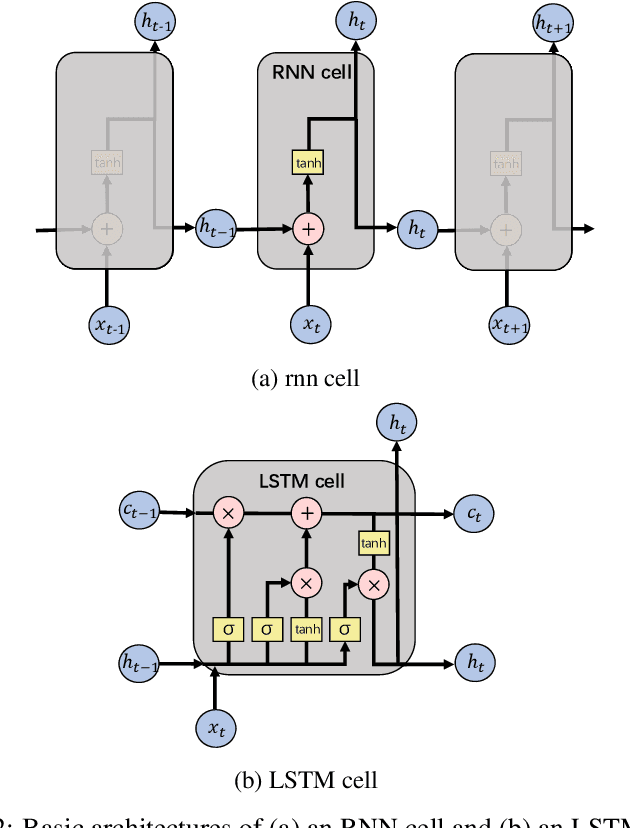
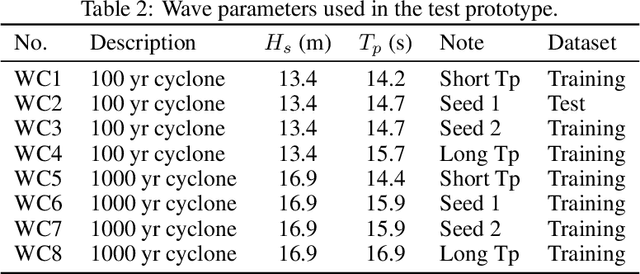
Real-time motion prediction of a vessel or a floating platform can help to improve the performance of motion compensation systems. It can also provide useful early-warning information for offshore operations that are critical with regard to motion. In this study, a long short-term memory (LSTM) -based machine learning model was developed to predict heave and surge motions of a semi-submersible. The training and test data came from a model test carried out in the deep-water ocean basin, at Shanghai Jiao Tong University, China. The motion and measured waves were fed into LSTM cells and then went through serval fully connected (FC) layers to obtain the prediction. With the help of measured waves, the prediction extended 46.5 s into future with an average accuracy close to 90%. Using a noise-extended dataset, the trained model effectively worked with a noise level up to 0.8. As a further step, the model could predict motions only based on the motion itself. Based on sensitive studies on the architectures of the model, guidelines for the construction of the machine learning model are proposed. The proposed LSTM model shows a strong ability to predict vessel wave-excited motions.
Topic Adaptation and Prototype Encoding for Few-Shot Visual Storytelling
Aug 11, 2020

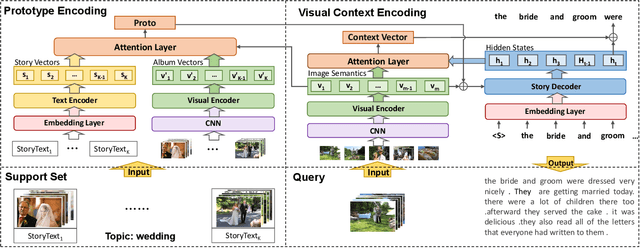
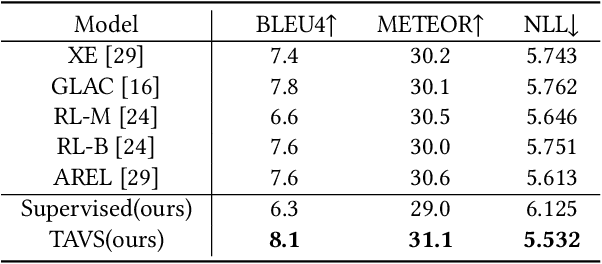
Visual Storytelling~(VIST) is a task to tell a narrative story about a certain topic according to the given photo stream. The existing studies focus on designing complex models, which rely on a huge amount of human-annotated data. However, the annotation of VIST is extremely costly and many topics cannot be covered in the training dataset due to the long-tail topic distribution. In this paper, we focus on enhancing the generalization ability of the VIST model by considering the few-shot setting. Inspired by the way humans tell a story, we propose a topic adaptive storyteller to model the ability of inter-topic generalization. In practice, we apply the gradient-based meta-learning algorithm on multi-modal seq2seq models to endow the model the ability to adapt quickly from topic to topic. Besides, We further propose a prototype encoding structure to model the ability of intra-topic derivation. Specifically, we encode and restore the few training story text to serve as a reference to guide the generation at inference time. Experimental results show that topic adaptation and prototype encoding structure mutually bring benefit to the few-shot model on BLEU and METEOR metric. The further case study shows that the stories generated after few-shot adaptation are more relative and expressive.
Natural Emergence of Heterogeneous Strategies in Artificially Intelligent Competitive Teams
Jul 06, 2020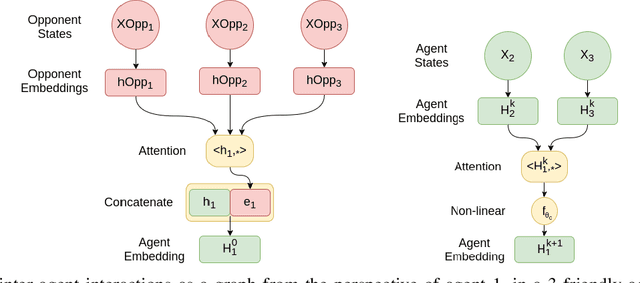
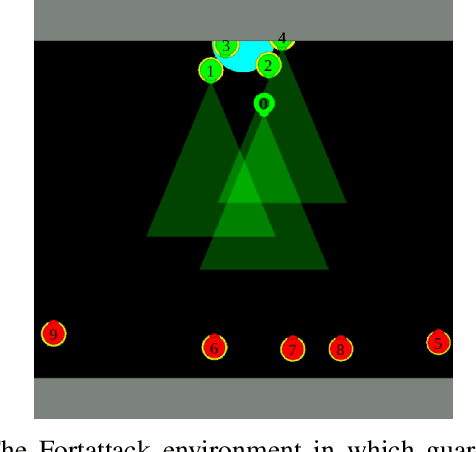
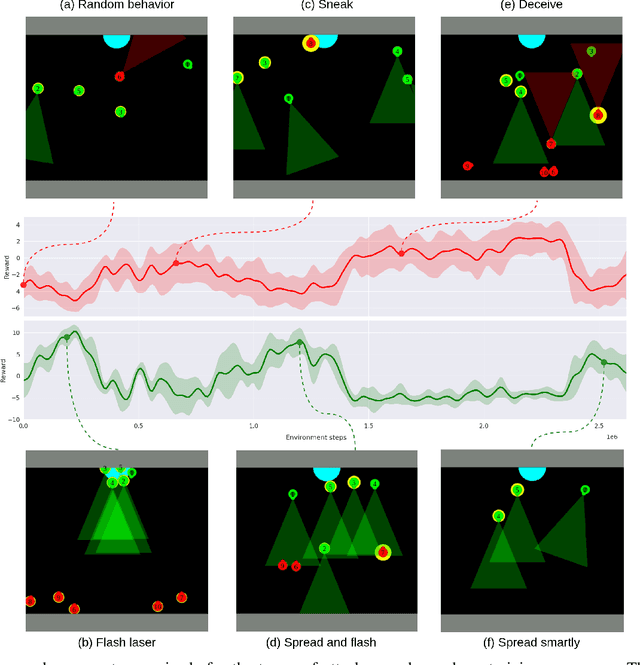

Multi agent strategies in mixed cooperative-competitive environments can be hard to craft by hand because each agent needs to coordinate with its teammates while competing with its opponents. Learning based algorithms are appealing but many scenarios require heterogeneous agent behavior for the team's success and this increases the complexity of the learning algorithm. In this work, we develop a competitive multi agent environment called FortAttack in which two teams compete against each other. We corroborate that modeling agents with Graph Neural Networks and training them with Reinforcement Learning leads to the evolution of increasingly complex strategies for each team. We observe a natural emergence of heterogeneous behavior amongst homogeneous agents when such behavior can lead to the team's success. Such heterogeneous behavior from homogeneous agents is appealing because any agent can replace the role of another agent at test time. Finally, we propose ensemble training, in which we utilize the evolved opponent strategies to train a single policy for friendly agents.
Interpretable Deep Learning Model for Online Multi-touch Attribution
Mar 26, 2020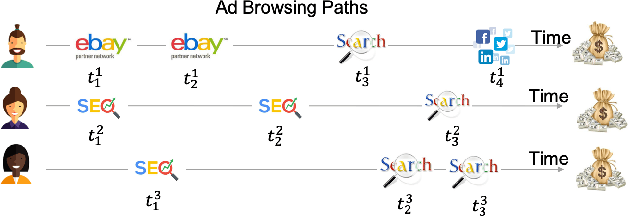
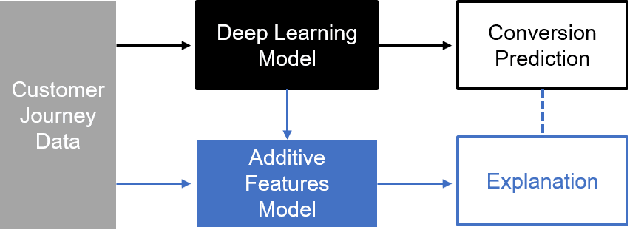
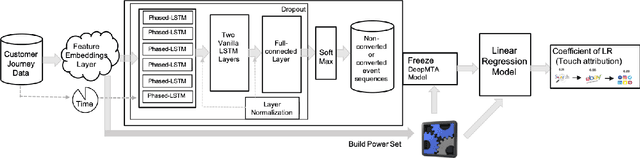
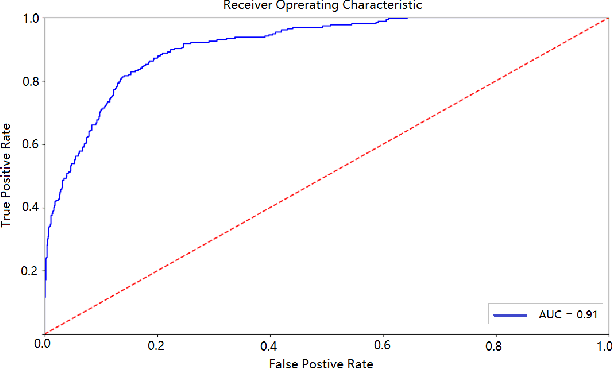
In online advertising, users may be exposed to a range of different advertising campaigns, such as natural search or referral or organic search, before leading to a final transaction. Estimating the contribution of advertising campaigns on the user's journey is very meaningful and crucial. A marketer could observe each customer's interaction with different marketing channels and modify their investment strategies accordingly. Existing methods including both traditional last-clicking methods and recent data-driven approaches for the multi-touch attribution (MTA) problem lack enough interpretation on why the methods work. In this paper, we propose a novel model called DeepMTA, which combines deep learning model and additive feature explanation model for interpretable online multi-touch attribution. DeepMTA mainly contains two parts, the phased-LSTMs based conversion prediction model to catch different time intervals, and the additive feature attribution model combined with shaley values. Additive feature attribution is explanatory that contains a linear function of binary variables. As the first interpretable deep learning model for MTA, DeepMTA considers three important features in the customer journey: event sequence order, event frequency and time-decay effect of the event. Evaluation on a real dataset shows the proposed conversion prediction model achieves 91\% accuracy.