 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Automatic Visibility Optimization for Thermal Synthetic Aperture Visualization
May 08, 2020
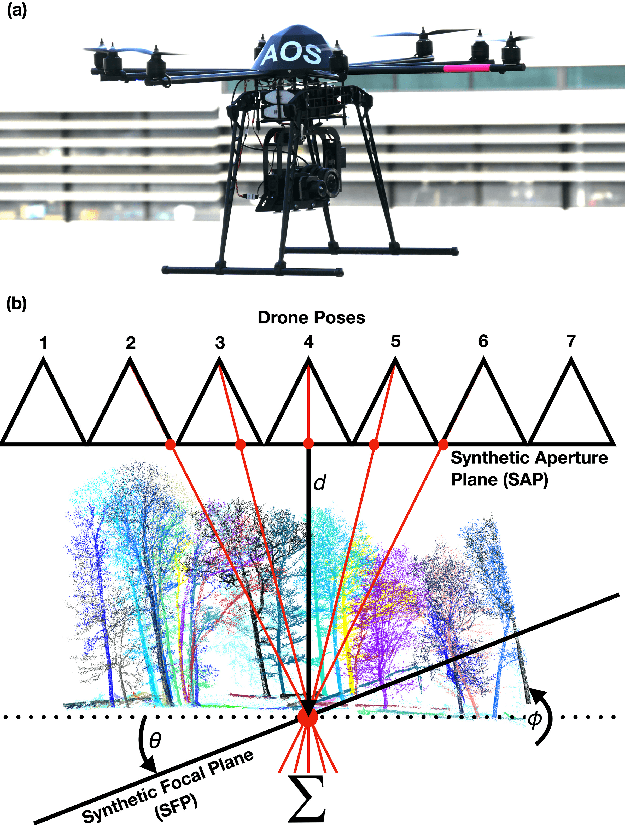

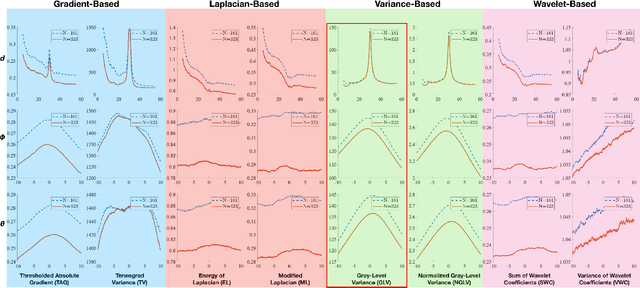
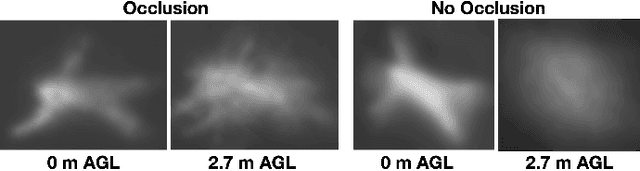
In this article, we describe and validate the first fully automatic parameter optimization for thermal synthetic aperture visualization. It replaces previous manual exploration of the parameter space, which is time consuming and error prone. We prove that the visibility of targets in thermal integral images is proportional to the variance of the targets' image. Since this is invariant to occlusion it represents a suitable objective function for optimization. Our findings have the potential to enable fully autonomous search and recuse operations with camera drones.
Fatigue-aware Bandits for Dependent Click Models
Aug 22, 2020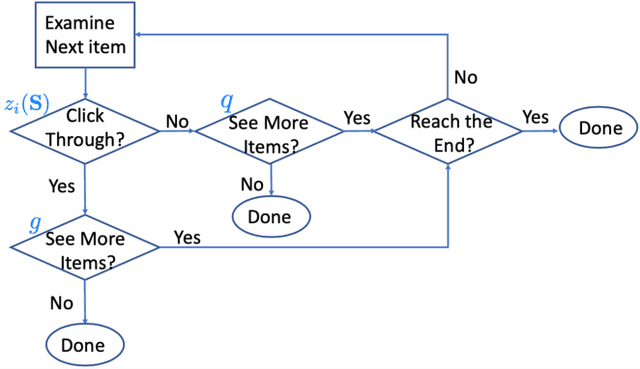
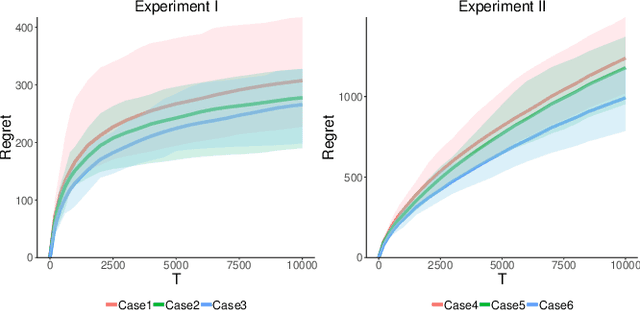
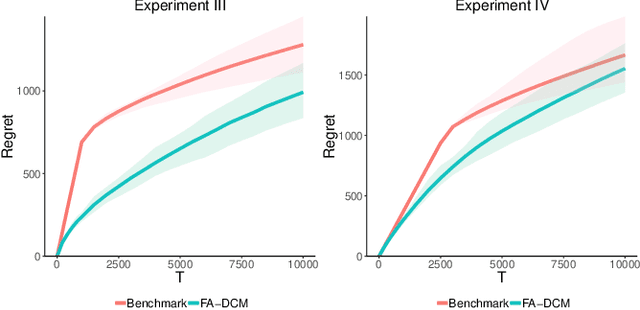
As recommender systems send a massive amount of content to keep users engaged, users may experience fatigue which is contributed by 1) an overexposure to irrelevant content, 2) boredom from seeing too many similar recommendations. To address this problem, we consider an online learning setting where a platform learns a policy to recommend content that takes user fatigue into account. We propose an extension of the Dependent Click Model (DCM) to describe users' behavior. We stipulate that for each piece of content, its attractiveness to a user depends on its intrinsic relevance and a discount factor which measures how many similar contents have been shown. Users view the recommended content sequentially and click on the ones that they find attractive. Users may leave the platform at any time, and the probability of exiting is higher when they do not like the content. Based on user's feedback, the platform learns the relevance of the underlying content as well as the discounting effect due to content fatigue. We refer to this learning task as "fatigue-aware DCM Bandit" problem. We consider two learning scenarios depending on whether the discounting effect is known. For each scenario, we propose a learning algorithm which simultaneously explores and exploits, and characterize its regret bound.
A Set-Theoretic Approach to Multi-Task Execution and Prioritization
Mar 06, 2020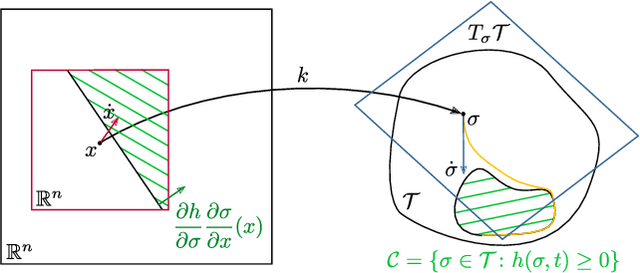
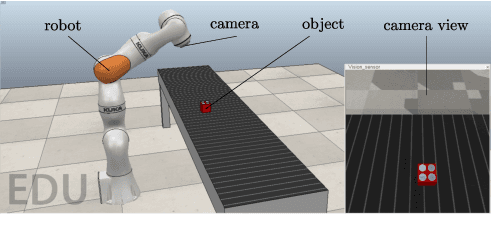
Executing multiple tasks concurrently is important in many robotic applications. Moreover, the prioritization of tasks is essential in applications where safety-critical tasks need to precede application-related objectives, in order to protect both the robot from its surroundings and vice versa. Furthermore, the possibility of switching the priority of tasks during their execution gives the robotic system the flexibility of changing its objectives over time. In this paper, we present an optimization-based task execution and prioritization framework that lends itself to the case of time-varying priorities as well as variable number of tasks. We introduce the concept of extended set-based tasks, encode them using control barrier functions, and execute them by means of a constrained-optimization problem, which can be efficiently solved in an online fashion. Finally, we show the application of the proposed approach to the case of a redundant robotic manipulator.
Convergence of Online Adaptive and Recurrent Optimization Algorithms
May 12, 2020We prove local convergence of several notable gradient descentalgorithms used inmachine learning, for which standard stochastic gradient descent theorydoes not apply. This includes, first, online algorithms for recurrent models and dynamicalsystems, such as \emph{Real-time recurrent learning} (RTRL) and its computationally lighter approximations NoBackTrack and UORO; second,several adaptive algorithms such as RMSProp, online natural gradient, and Adam with $\beta^2\to 1$.Despite local convergence being a relatively weak requirement for a newoptimization algorithm, no local analysis was available for these algorithms, as far aswe knew. Analysis of these algorithms does not immediately followfrom standard stochastic gradient (SGD) theory. In fact, Adam has been provedto lack local convergence in some simple situations. For recurrent models, online algorithms modify the parameterwhile the model is running, which further complicates the analysis withrespect to simple SGD.Local convergence for these various algorithms results from a single,more general set of assumptions, in the setup of learning dynamicalsystems online. Thus, these results can cover other variants ofthe algorithms considered.We adopt an ``ergodic'' rather than probabilistic viewpoint, working withempirical time averages instead of probability distributions. This ismore data-agnostic andcreates differences with respect to standard SGD theory,especially for the range of possible learning rates. For instance, withcycling or per-epoch reshuffling over a finite dataset instead of purei.i.d. sampling with replacement, empiricalaverages of gradients converge at rate $1/T$ insteadof $1/\sqrt{T}$ (cycling acts as a variance reduction method),theoretically allowingfor larger learning rates than in SGD.
Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Aug 11, 2020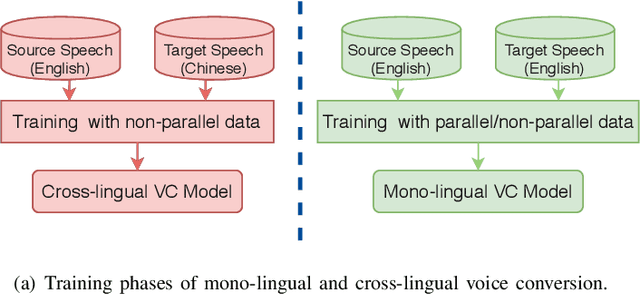
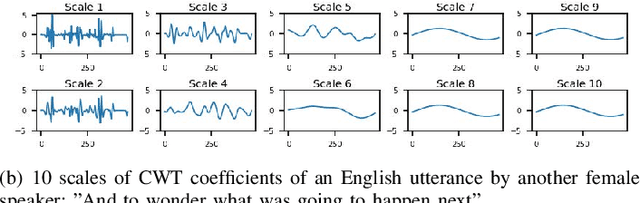
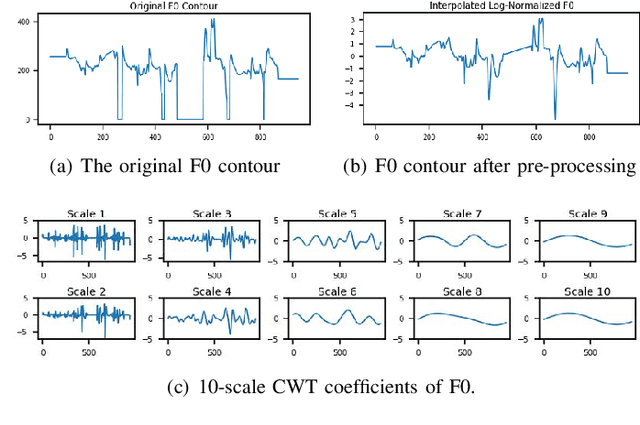
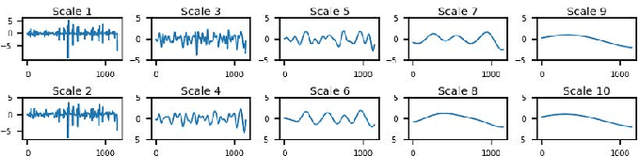
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of continuous wavelet transform (CWT) decomposition for F0 modeling. CWT provides a way to decompose a signal into different temporal scales that explain prosody in different time resolutions. We also propose to train two CycleGAN pipelines for spectrum and prosody mapping respectively. In this way, we eliminate the need for parallel data of any two languages and any alignment techniques. Experimental results show that our proposed Spectrum-Prosody-CycleGAN framework outperforms the Spectrum-CycleGAN baseline in subjective evaluation. To our best knowledge, this is the first study of prosody in cross-lingual voice conversion.
From A Glance to "Gotcha": Interactive Facial Image Retrieval with Progressive Relevance Feedback
Jul 30, 2020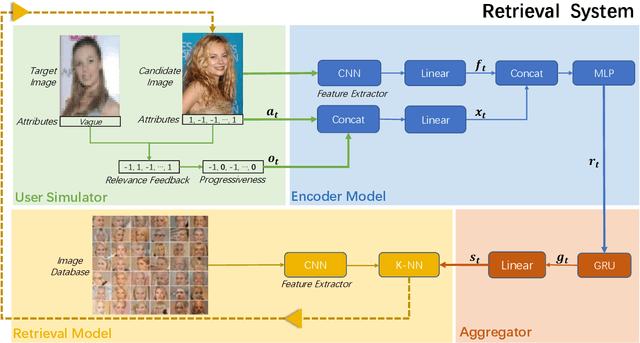


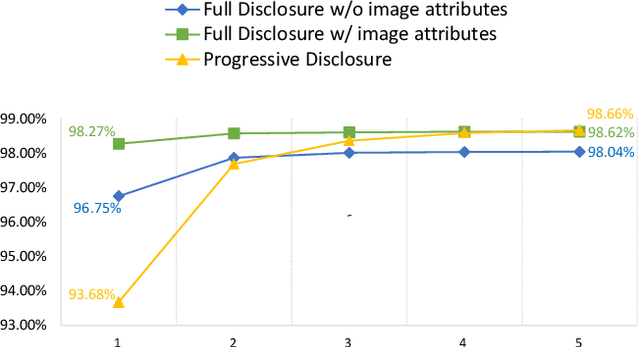
Facial image retrieval plays a significant role in forensic investigations where an untrained witness tries to identify a suspect from a massive pool of images. However, due to the difficulties in describing human facial appearances verbally and directly, people naturally tend to depict by referring to well-known existing images and comparing specific areas of faces with them and it is also challenging to provide complete comparison at each time. Therefore, we propose an end-to-end framework to retrieve facial images with relevance feedback progressively provided by the witness, enabling an exploitation of history information during multiple rounds and an interactive and iterative approach to retrieving the mental image. With no need of any extra annotations, our model can be applied at the cost of a little response effort. We experiment on \texttt{CelebA} and evaluate the performance by ranking percentile and achieve 99\% under the best setting. Since this topic remains little explored to the best of our knowledge, we hope our work can serve as a stepping stone for further research.
Autonomous Driving with Deep Learning: A Survey of State-of-Art Technologies
Jul 04, 2020
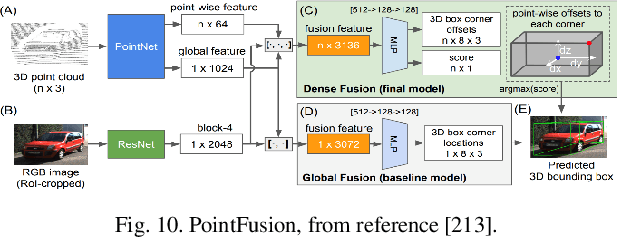
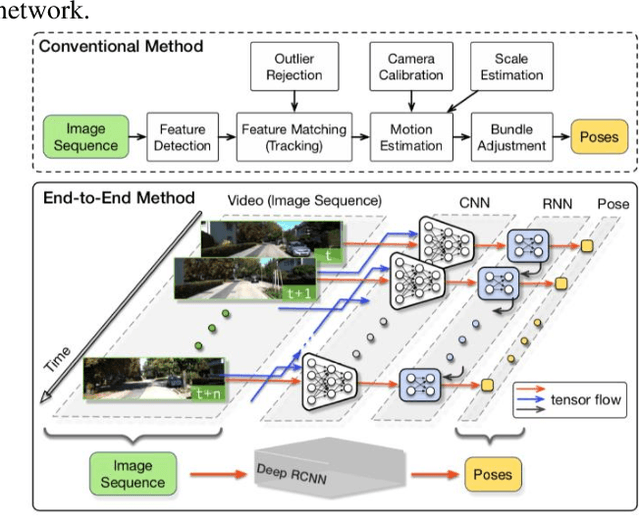
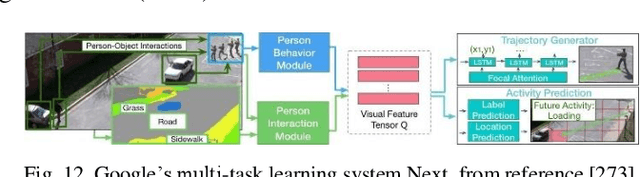
Since DARPA Grand Challenges (rural) in 2004/05 and Urban Challenges in 2007, autonomous driving has been the most active field of AI applications. Almost at the same time, deep learning has made breakthrough by several pioneers, three of them (also called fathers of deep learning), Hinton, Bengio and LeCun, won ACM Turin Award in 2019. This is a survey of autonomous driving technologies with deep learning methods. We investigate the major fields of self-driving systems, such as perception, mapping and localization, prediction, planning and control, simulation, V2X and safety etc. Due to the limited space, we focus the analysis on several key areas, i.e. 2D and 3D object detection in perception, depth estimation from cameras, multiple sensor fusion on the data, feature and task level respectively, behavior modelling and prediction of vehicle driving and pedestrian trajectories.
Contrastive Learning for Unpaired Image-to-Image Translation
Jul 30, 2020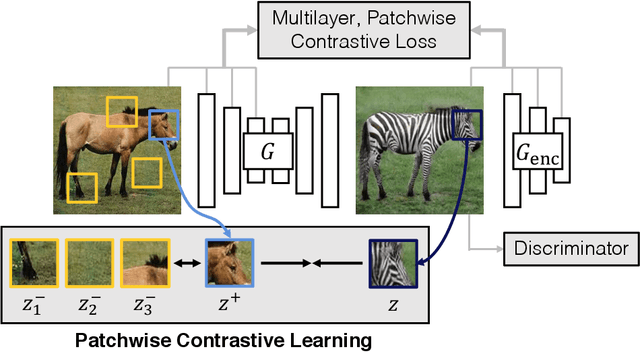
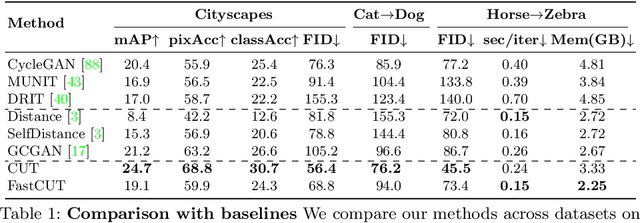
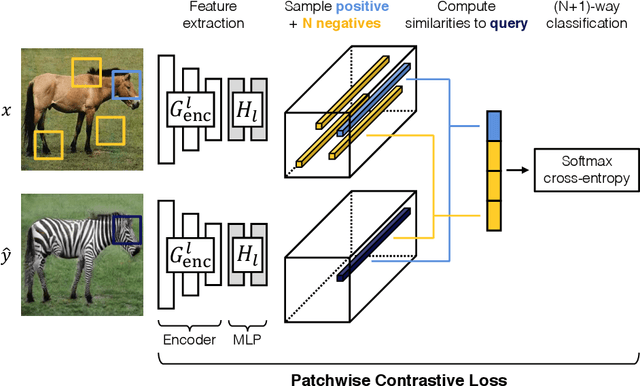
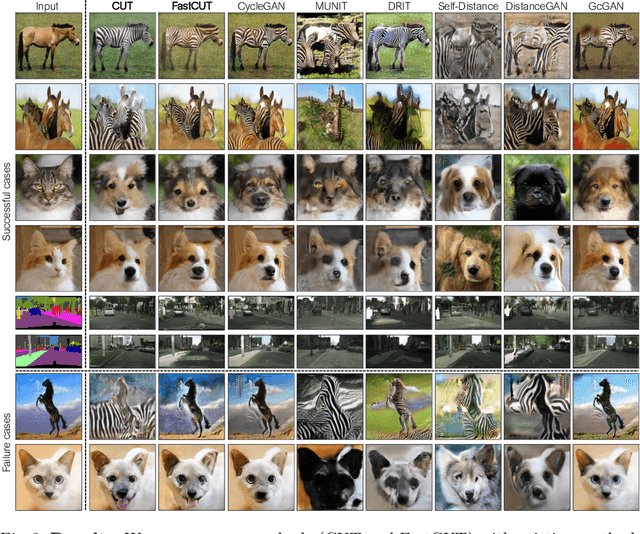
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
Recycling Randomness with Structure for Sublinear time Kernel Expansions
May 29, 2016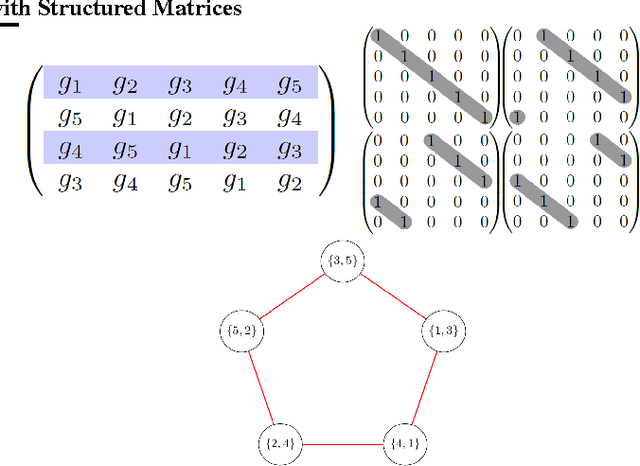
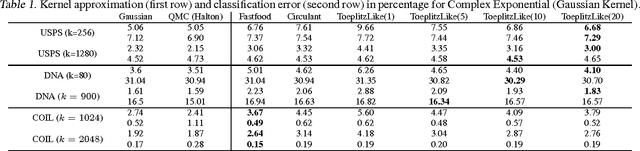
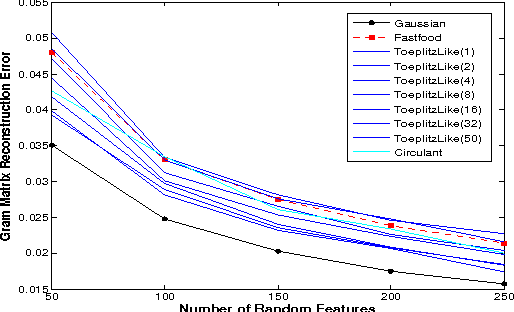

We propose a scheme for recycling Gaussian random vectors into structured matrices to approximate various kernel functions in sublinear time via random embeddings. Our framework includes the Fastfood construction as a special case, but also extends to Circulant, Toeplitz and Hankel matrices, and the broader family of structured matrices that are characterized by the concept of low-displacement rank. We introduce notions of coherence and graph-theoretic structural constants that control the approximation quality, and prove unbiasedness and low-variance properties of random feature maps that arise within our framework. For the case of low-displacement matrices, we show how the degree of structure and randomness can be controlled to reduce statistical variance at the cost of increased computation and storage requirements. Empirical results strongly support our theory and justify the use of a broader family of structured matrices for scaling up kernel methods using random features.
Congested Urban Networks Tend to Be Insensitive to Signal Settings: Implications for Learning-Based Control
Aug 21, 2020
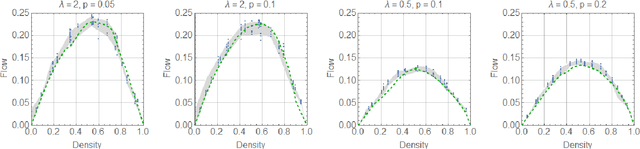
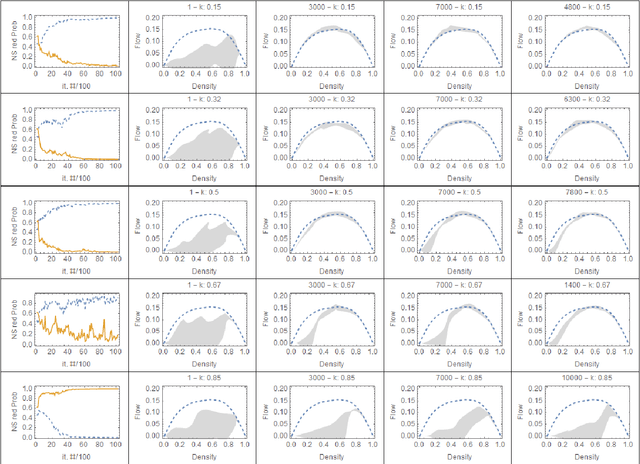
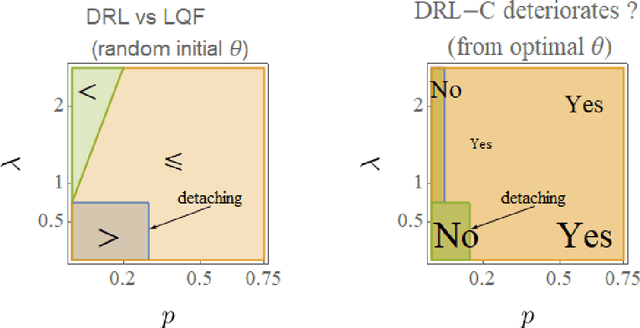
This paper highlights several properties of large urban networks that can have an impact on machine learning methods applied to traffic signal control. In particular, we show that the average network flow tends to be independent of the signal control policy as density increases. This property, which so far has remained under the radar, implies that deep reinforcement learning (DRL) methods becomes ineffective when trained under congested conditions, and might explain DRL's limited success for traffic signal control. Our results apply to all possible grid networks thanks to a parametrization based on two network parameters: the ratio of the expected distance between consecutive traffic lights to the expected green time, and the turning probability at intersections. Networks with different parameters exhibit very different responses to traffic signal control. Notably, we found that no control (i.e. random policy) can be an effective control strategy for a surprisingly large family of networks. The impact of the turning probability turned out to be very significant both for baseline and for DRL policies. It also explains the loss of symmetry observed for these policies, which is not captured by existing theories that rely on corridor approximations without turns. Our findings also suggest that supervised learning methods have enormous potential as they require very little examples to produce excellent policies.