 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TF-NAS: Rethinking Three Search Freedoms of Latency-Constrained Differentiable Neural Architecture Search
Aug 12, 2020
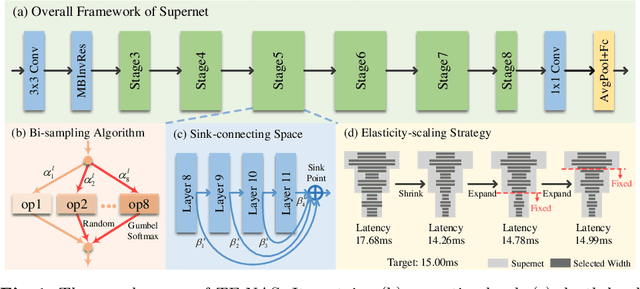

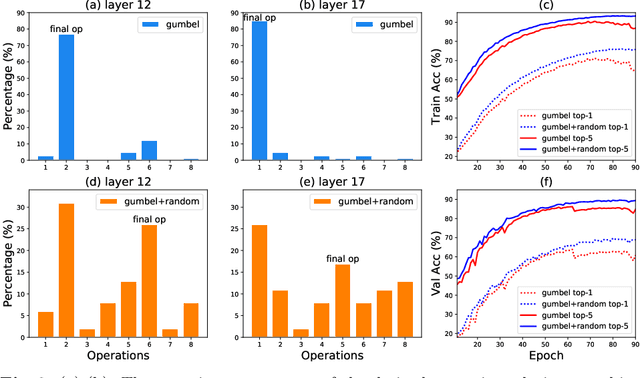
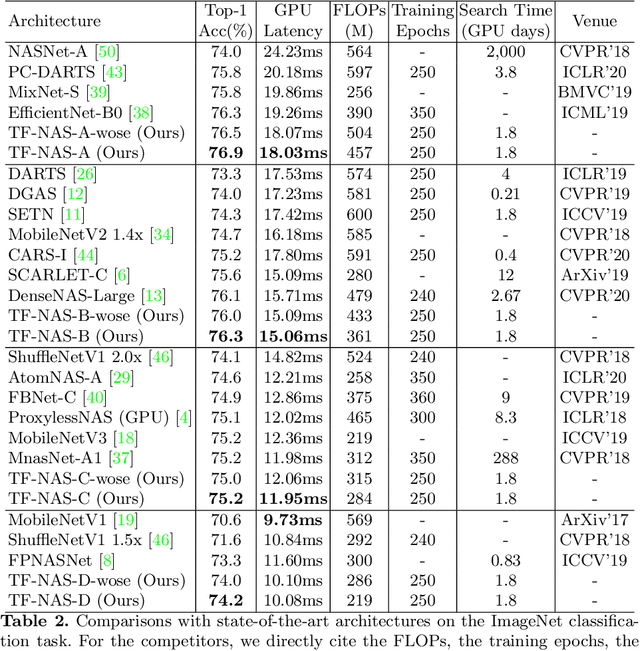
With the flourish of differentiable neural architecture search (NAS), automatically searching latency-constrained architectures gives a new perspective to reduce human labor and expertise. However, the searched architectures are usually suboptimal in accuracy and may have large jitters around the target latency. In this paper, we rethink three freedoms of differentiable NAS, i.e. operation-level, depth-level and width-level, and propose a novel method, named Three-Freedom NAS (TF-NAS), to achieve both good classification accuracy and precise latency constraint. For the operation-level, we present a bi-sampling search algorithm to moderate the operation collapse. For the depth-level, we introduce a sink-connecting search space to ensure the mutual exclusion between skip and other candidate operations, as well as eliminate the architecture redundancy. For the width-level, we propose an elasticity-scaling strategy that achieves precise latency constraint in a progressively fine-grained manner. Experiments on ImageNet demonstrate the effectiveness of TF-NAS. Particularly, our searched TF-NAS-A obtains 76.9% top-1 accuracy, achieving state-of-the-art results with less latency. The total search time is only 1.8 days on 1 Titan RTX GPU. Code is available at https://github.com/AberHu/TF-NAS.
Optimal to-do list gamification
Aug 12, 2020
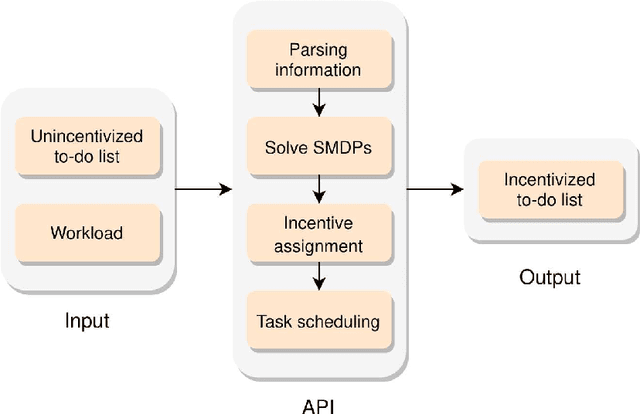
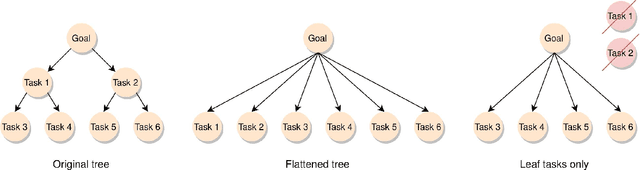

What should I work on first? What can wait until later? Which projects should I prioritize and which tasks are not worth my time? These are challenging questions that many people face every day. People's intuitive strategy is to prioritize their immediate experience over the long-term consequences. This leads to procrastination and the neglect of important long-term projects in favor of seemingly urgent tasks that are less important. Optimal gamification strives to help people overcome these problems by incentivizing each task by a number of points that communicates how valuable it is in the long-run. Unfortunately, computing the optimal number of points with standard dynamic programming methods quickly becomes intractable as the number of a person's projects and the number of tasks required by each project increase. Here, we introduce and evaluate a scalable method for identifying which tasks are most important in the long run and incentivizing each task according to its long-term value. Our method makes it possible to create to-do list gamification apps that can handle the size and complexity of people's to-do lists in the real world.
Coronavirus on Social Media: Analyzing Misinformation in Twitter Conversations
Apr 21, 2020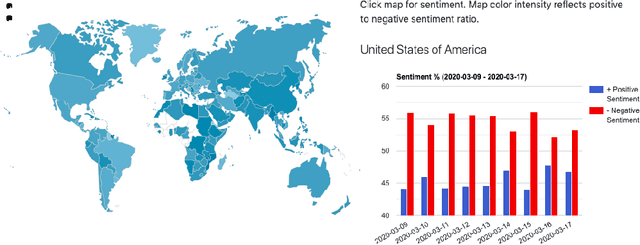
The ongoing Coronavirus Disease (COVID-19) pandemic highlights the interconnected-ness of our present-day globalized world. With social distancing policies in place, virtual communication has become an important source of (mis)information. As increasing number of people rely on social media platforms for news, identifying misinformation has emerged as a critical task in these unprecedented times. In addition to being malicious, the spread of such information poses a serious public health risk. To this end, we design a dashboard to track misinformation on popular social media news sharing platform - Twitter. The dashboard allows visibility into the social media discussions around Coronavirus and the quality of information shared on the platform, updated over time. We collect streaming data using the Twitter API from March 1, 2020 to date and identify false, misleading and clickbait contents from collected Tweets. We provide analysis of user accounts and misinformation spread across countries. In addition, we provide analysis of public sentiments on intervention policies such as "#socialdistancing" and "#workfromhome", and we track topics, and emerging hashtags and sentiments over countries. The dashboard maintains an evolving list of misinformation cascades, sentiments and emerging trends over time, accessible online at \url{https://usc-melady.github.io/COVID-19-Tweet-Analysis}.
Deep Reinforcement Learning for Closed-Loop Blood Glucose Control
Sep 18, 2020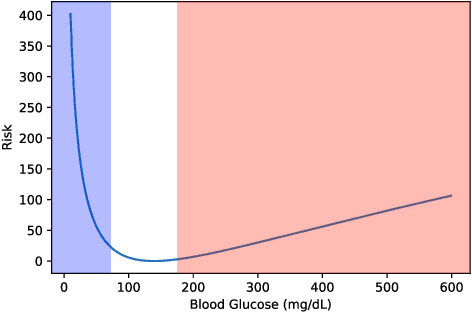
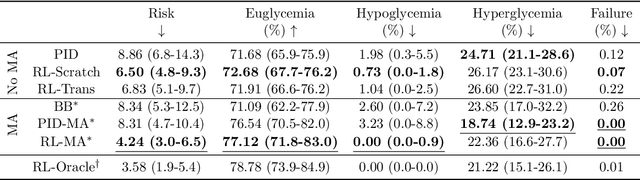
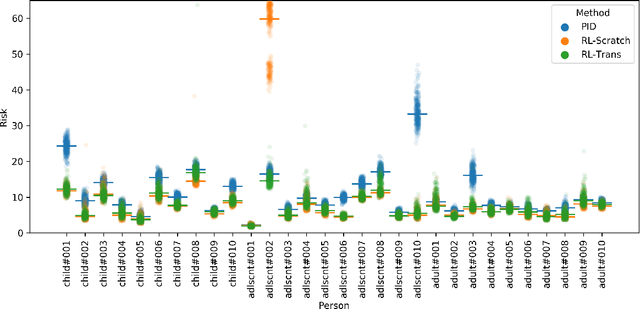

People with type 1 diabetes (T1D) lack the ability to produce the insulin their bodies need. As a result, they must continually make decisions about how much insulin to self-administer to adequately control their blood glucose levels. Longitudinal data streams captured from wearables, like continuous glucose monitors, can help these individuals manage their health, but currently the majority of the decision burden remains on the user. To relieve this burden, researchers are working on closed-loop solutions that combine a continuous glucose monitor and an insulin pump with a control algorithm in an `artificial pancreas.' Such systems aim to estimate and deliver the appropriate amount of insulin. Here, we develop reinforcement learning (RL) techniques for automated blood glucose control. Through a series of experiments, we compare the performance of different deep RL approaches to non-RL approaches. We highlight the flexibility of RL approaches, demonstrating how they can adapt to new individuals with little additional data. On over 2.1 million hours of data from 30 simulated patients, our RL approach outperforms baseline control algorithms: leading to a decrease in median glycemic risk of nearly 50% from 8.34 to 4.24 and a decrease in total time hypoglycemic of 99.8%, from 4,610 days to 6. Moreover, these approaches are able to adapt to predictable meal times (decreasing average risk by an additional 24% as meals increase in predictability). This work demonstrates the potential of deep RL to help people with T1D manage their blood glucose levels without requiring expert knowledge. All of our code is publicly available, allowing for replication and extension.
DREAM Architecture: a Developmental Approach to Open-Ended Learning in Robotics
May 13, 2020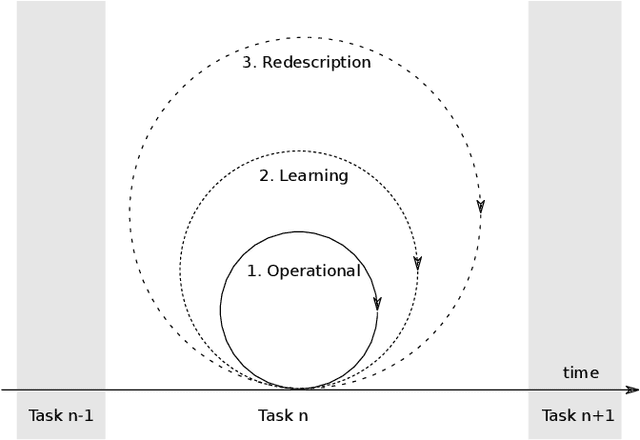
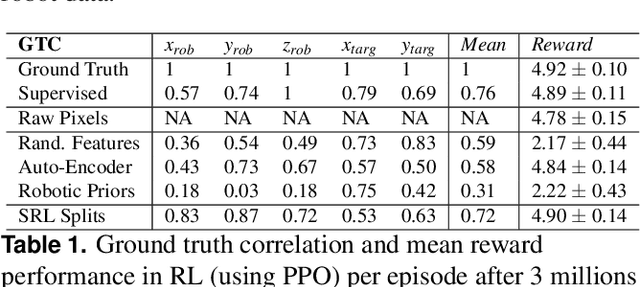
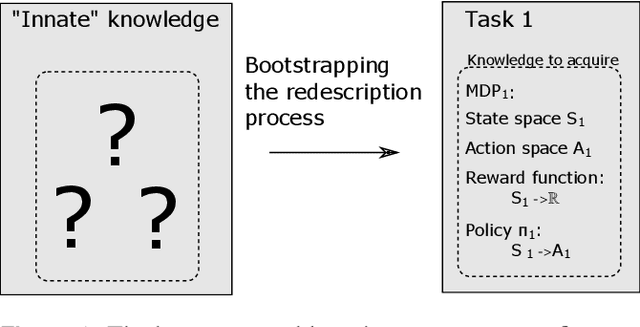
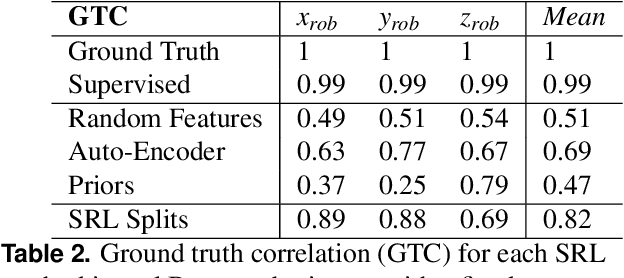
Robots are still limited to controlled conditions, that the robot designer knows with enough details to endow the robot with the appropriate models or behaviors. Learning algorithms add some flexibility with the ability to discover the appropriate behavior given either some demonstrations or a reward to guide its exploration with a reinforcement learning algorithm. Reinforcement learning algorithms rely on the definition of state and action spaces that define reachable behaviors. Their adaptation capability critically depends on the representations of these spaces: small and discrete spaces result in fast learning while large and continuous spaces are challenging and either require a long training period or prevent the robot from converging to an appropriate behavior. Beside the operational cycle of policy execution and the learning cycle, which works at a slower time scale to acquire new policies, we introduce the redescription cycle, a third cycle working at an even slower time scale to generate or adapt the required representations to the robot, its environment and the task. We introduce the challenges raised by this cycle and we present DREAM (Deferred Restructuring of Experience in Autonomous Machines), a developmental cognitive architecture to bootstrap this redescription process stage by stage, build new state representations with appropriate motivations, and transfer the acquired knowledge across domains or tasks or even across robots. We describe results obtained so far with this approach and end up with a discussion of the questions it raises in Neuroscience.
Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations
Jul 12, 2020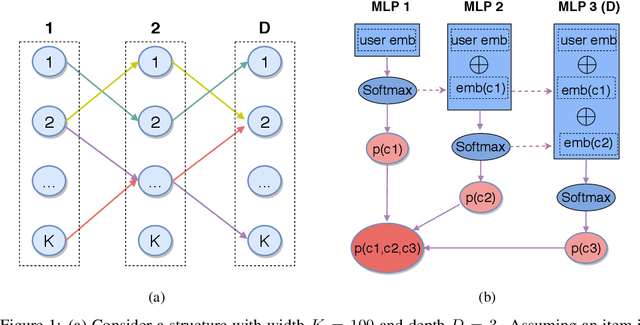
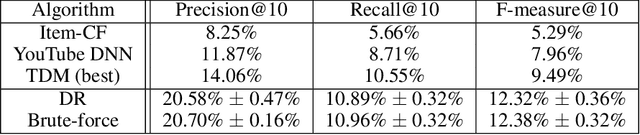
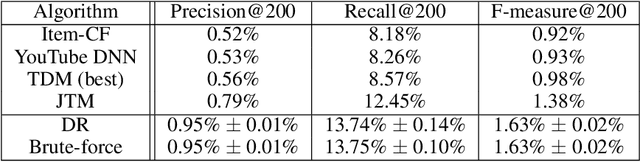
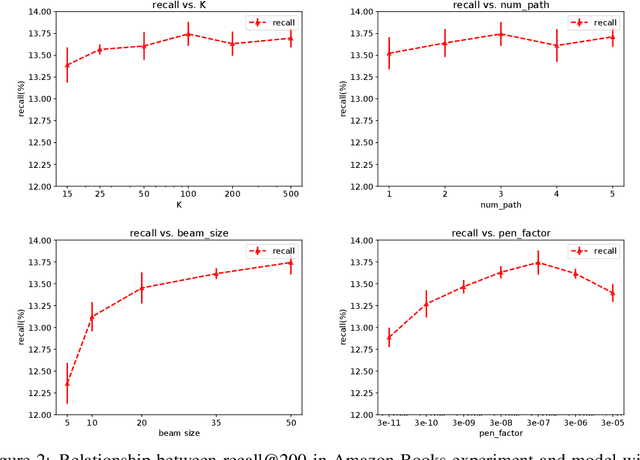
One of the core problems in large-scale recommendations is to retrieve top relevant candidates accurately and efficiently, preferably in sub-linear time. Previous approaches are mostly based on a two-step procedure: first learn an inner-product model and then use maximum inner product search (MIPS) algorithms to search top candidates, leading to potential loss of retrieval accuracy. In this paper, we present Deep Retrieval (DR), an end-to-end learnable structure model for large-scale recommendations. DR encodes all candidates into a discrete latent space. Those latent codes for the candidates are model parameters and to be learnt together with other neural network parameters to maximize the same objective function. With the model learnt, a beam search over the latent codes is performed to retrieve the top candidates. Empirically, we showed that DR, with sub-linear computational complexity, can achieve almost the same accuracy as the brute-force baseline.
Facial Expression Retargeting from Human to Avatar Made Easy
Aug 12, 2020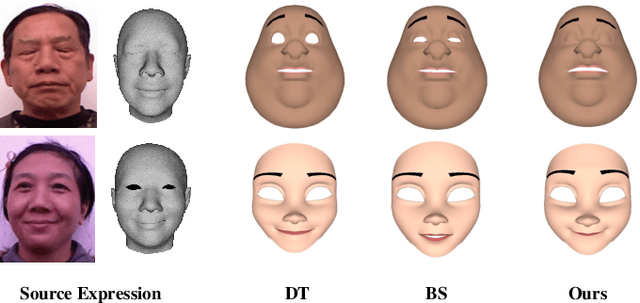

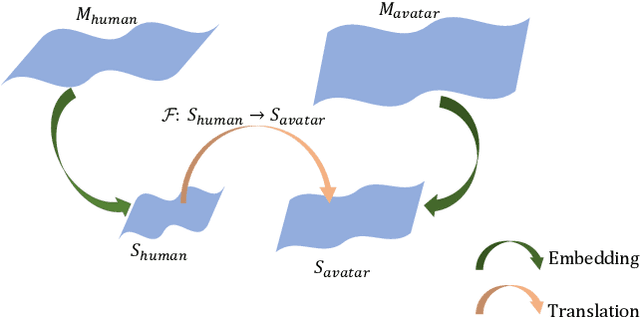
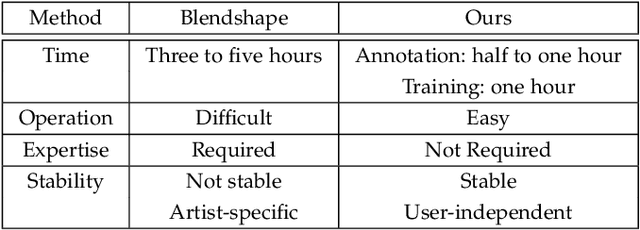
Facial expression retargeting from humans to virtual characters is a useful technique in computer graphics and animation. Traditional methods use markers or blendshapes to construct a mapping between the human and avatar faces. However, these approaches require a tedious 3D modeling process, and the performance relies on the modelers' experience. In this paper, we propose a brand-new solution to this cross-domain expression transfer problem via nonlinear expression embedding and expression domain translation. We first build low-dimensional latent spaces for the human and avatar facial expressions with variational autoencoder. Then we construct correspondences between the two latent spaces guided by geometric and perceptual constraints. Specifically, we design geometric correspondences to reflect geometric matching and utilize a triplet data structure to express users' perceptual preference of avatar expressions. A user-friendly method is proposed to automatically generate triplets for a system allowing users to easily and efficiently annotate the correspondences. Using both geometric and perceptual correspondences, we trained a network for expression domain translation from human to avatar. Extensive experimental results and user studies demonstrate that even nonprofessional users can apply our method to generate high-quality facial expression retargeting results with less time and effort.
Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Aug 12, 2020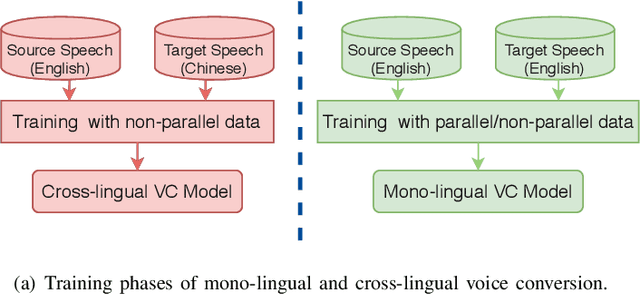
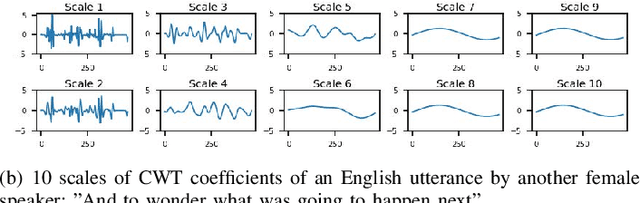
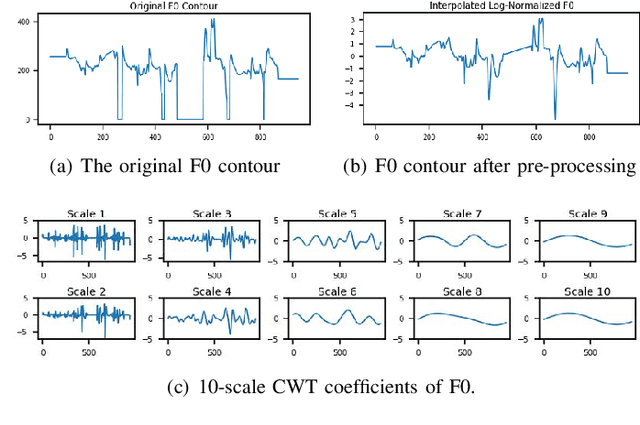
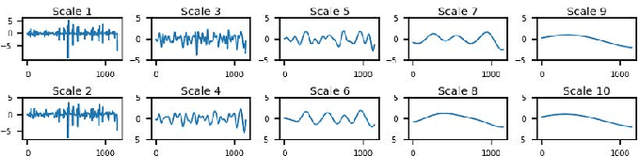
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of continuous wavelet transform (CWT) decomposition for F0 modeling. CWT provides a way to decompose a signal into different temporal scales that explain prosody in different time resolutions. We also propose to train two CycleGAN pipelines for spectrum and prosody mapping respectively. In this way, we eliminate the need for parallel data of any two languages and any alignment techniques. Experimental results show that our proposed Spectrum-Prosody-CycleGAN framework outperforms the Spectrum-CycleGAN baseline in subjective evaluation. To our best knowledge, this is the first study of prosody in cross-lingual voice conversion.
HMCNAS: Neural Architecture Search using Hidden Markov Chains and Bayesian Optimization
Jul 31, 2020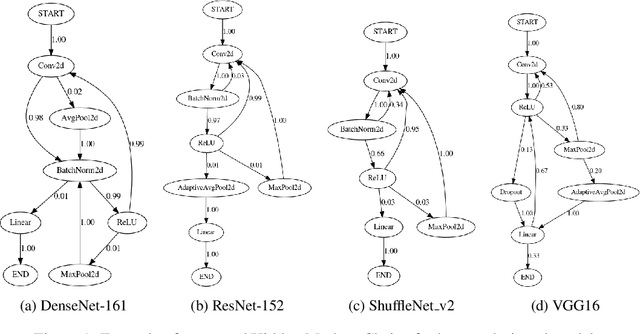
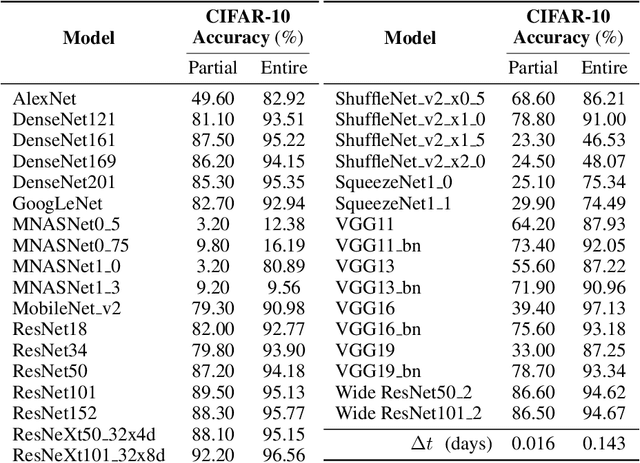
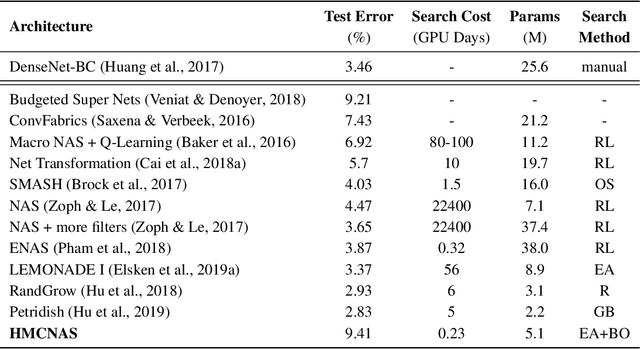
Neural Architecture Search has achieved state-of-the-art performance in a variety of tasks, out-performing human-designed networks. However, many assumptions, that require human definition, related with the problems being solved or the models generated are still needed: final model architectures, number of layers to be sampled, forced operations, small search spaces, which ultimately contributes to having models with higher performances at the cost of inducing bias into the system. In this paper, we propose HMCNAS, which is composed of two novel components: i) a method that leverages information about human-designed models to autonomously generate a complex search space, and ii) an Evolutionary Algorithm with Bayesian Optimization that is capable of generating competitive CNNs from scratch, without relying on human-defined parameters or small search spaces. The experimental results show that the proposed approach results in competitive architectures obtained in a very short time. HMCNAS provides a step towards generalizing NAS, by providing a way to create competitive models, without requiring any human knowledge about the specific task.
Decision Support for Intoxication Prediction Using Graph Convolutional Networks
May 02, 2020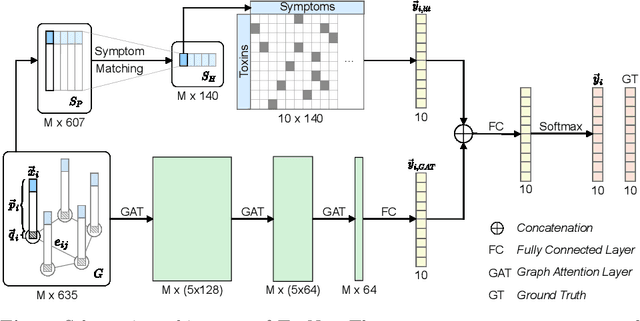
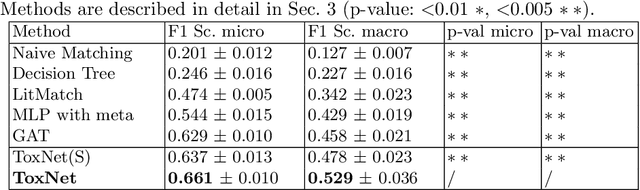
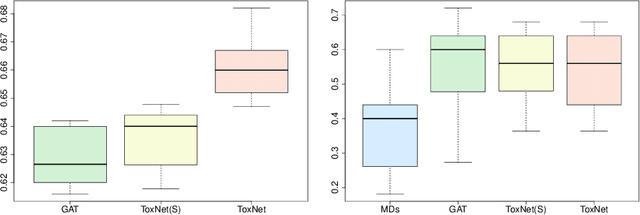
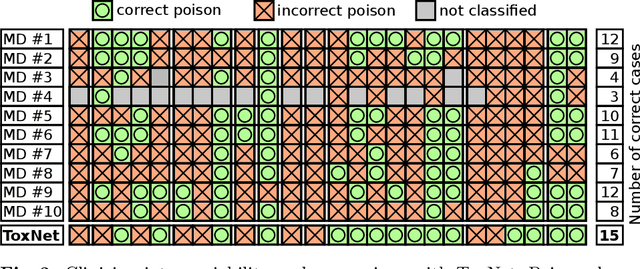
Every day, poison control centers (PCC) are called for immediate classification and treatment recommendations if an acute intoxication is suspected. Due to the time-sensitive nature of these cases, doctors are required to propose a correct diagnosis and intervention within a minimal time frame. Usually the toxin is known and recommendations can be made accordingly. However, in challenging cases only symptoms are mentioned and doctors have to rely on their clinical experience. Medical experts and our analyses of a regional dataset of intoxication records provide evidence that this is challenging, since occurring symptoms may not always match the textbook description due to regional distinctions, inter-rater variance, and institutional workflow. Computer-aided diagnosis (CADx) can provide decision support, but approaches so far do not consider additional information of the reported cases like age or gender, despite their potential value towards a correct diagnosis. In this work, we propose a new machine learning based CADx method which fuses symptoms and meta information of the patients using graph convolutional networks. We further propose a novel symptom matching method that allows the effective incorporation of prior knowledge into the learning process and evidently stabilizes the poison prediction. We validate our method against 10 medical doctors with different experience diagnosing intoxication cases for 10 different toxins from the PCC in Munich and show our method's superiority in performance for poison prediction.