 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Transform: Time-Domain Audio Error Correction via Probabilistic Re-Synthesis
Mar 19, 2015
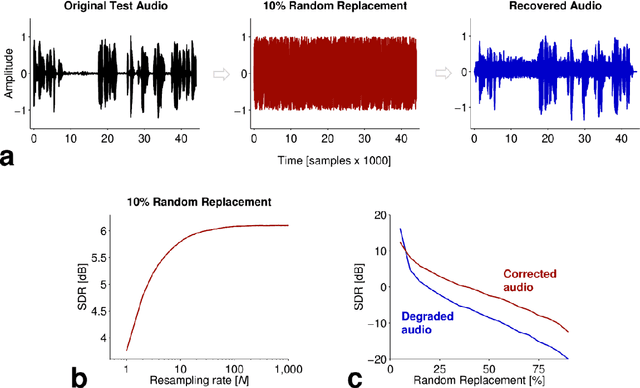
In the process of recording, storage and transmission of time-domain audio signals, errors may be introduced that are difficult to correct in an unsupervised way. Here, we train a convolutional deep neural network to re-synthesize input time-domain speech signals at its output layer. We then use this abstract transformation, which we call a deep transform (DT), to perform probabilistic re-synthesis on further speech (of the same speaker) which has been degraded. Using the convolutive DT, we demonstrate the recovery of speech audio that has been subject to extreme degradation. This approach may be useful for correction of errors in communications devices.
The Computational Capacity of Memristor Reservoirs
Aug 31, 2020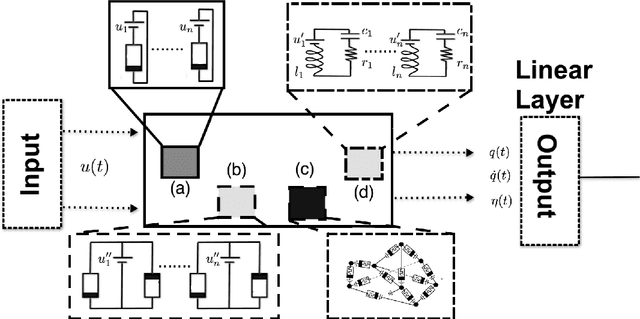
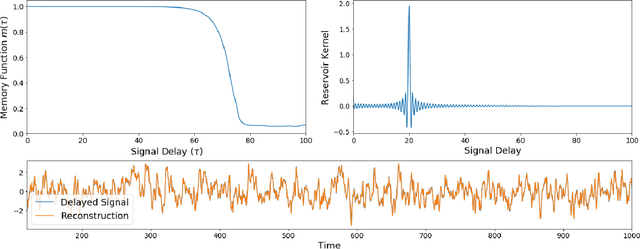
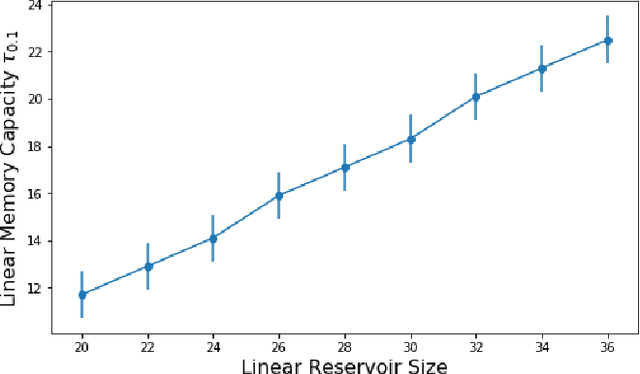
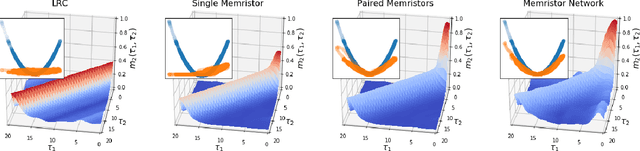
Reservoir computing is a machine learning paradigm in which a high-dimensional dynamical system, or \emph{reservoir}, is used to approximate and perform predictions on time series data. Its simple training procedure allows for very large reservoirs that can provide powerful computational capabilities. The scale, speed and power-usage characteristics of reservoir computing could be enhanced by constructing reservoirs out of electronic circuits, but this requires a precise understanding of how such circuits process and store information. We analyze the feasibility and optimal design of such reservoirs by considering the equations of motion of circuits that include both linear elements (resistors, inductors, and capacitors) and nonlinear memory elements (called memristors). This complements previous studies, which have examined such systems through simulation and experiment. We provide analytic results regarding the fundamental feasibility of such reservoirs, and give a systematic characterization of their computational properties, examining the types of input-output relationships that may be approximated. This allows us to design reservoirs with optimal properties in terms of their ability to reconstruct a certain signal (or functions thereof). In particular, by introducing measures of the total linear and nonlinear computational capacities of the reservoir, we are able to design electronic circuits whose total computation capacity scales linearly with the system size. Comparison with conventional echo state reservoirs show that these electronic reservoirs can match or exceed their performance in a form that may be directly implemented in hardware.
Garment Design with Generative Adversarial Networks
Jul 21, 2020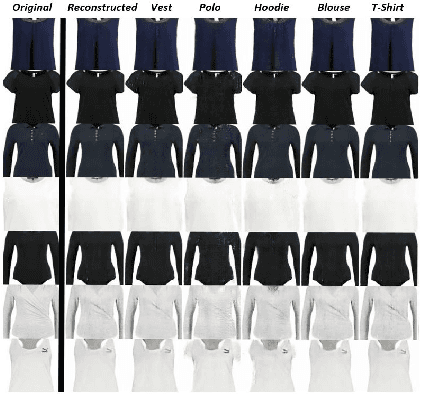



The designers' tendency to adhere to a specific mental set and heavy emotional investment in their initial ideas often hinder their ability to innovate during the design thinking and ideation process. In the fashion industry, in particular, the growing diversity of customers' needs, the intense global competition, and the shrinking time-to-market (a.k.a., "fast fashion") further exacerbate this challenge for designers. Recent advances in deep generative models have created new possibilities to overcome the cognitive obstacles of designers through automated generation and/or editing of design concepts. This paper explores the capabilities of generative adversarial networks (GAN) for automated attribute-level editing of design concepts. Specifically, attribute GAN (AttGAN)---a generative model proven successful for attribute editing of human faces---is utilized for automated editing of the visual attributes of garments and tested on a large fashion dataset. The experiments support the hypothesized potentials of GAN for attribute-level editing of design concepts, and underscore several key limitations and research questions to be addressed in future work.
Versatile Multilinked Aerial Robot with Tilting Propellers: Design, Modeling, Control and State Estimation for Autonomous Flight and Manipulation
Aug 12, 2020
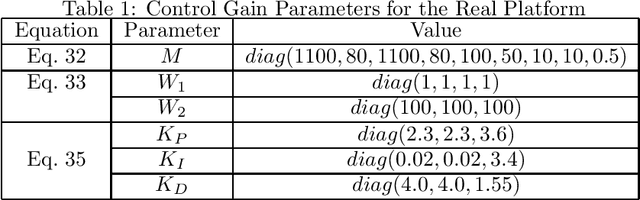
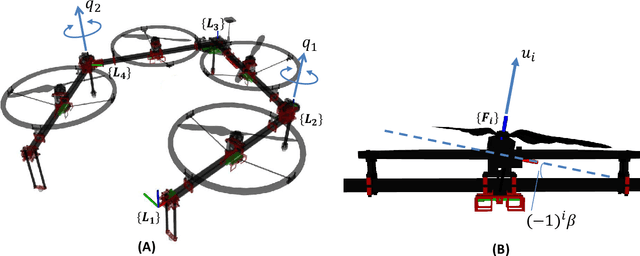
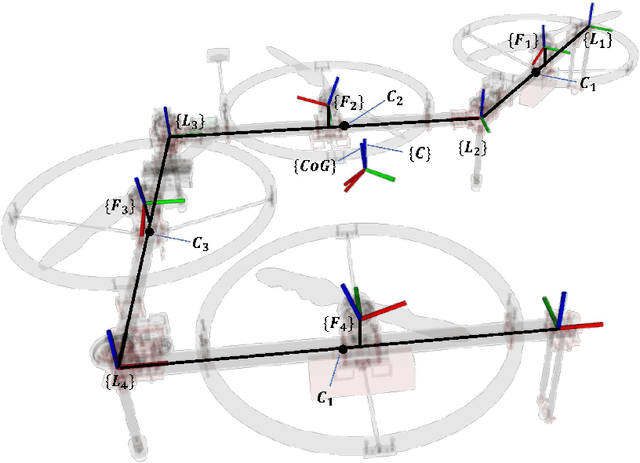
Multilinked aerial robot is one of the state-of-the-art works in aerial robotics, which demonstrates the deformability benefiting both maneuvering and manipulation. However, the performance in outdoor physical world has not yet been evaluated because of the weakness in the controllability and the lack of the state estimation for autonomous flight. Thus we adopt tilting propellers to enhance the controllability. The related design, modeling and control method are developed in this work to enable the stable hovering and deformation. Furthermore, the state estimation which involves the time synchronization between sensors and the multilinked kinematics is also presented in this work to enable the fully autonomous flight in the outdoor environment. Various autonomous outdoor experiments, including the fast maneuvering for interception with target, object grasping for delivery, and blanket manipulation for firefighting are performed to evaluate the feasibility and versatility of the proposed robot platform. To the best of our knowledge, this is the first study for the multilinked aerial robot to achieve the fully autonomous flight and the manipulation task in outdoor environment. We also applied our platform in all challenges of the 2020 Mohammed Bin Zayed International Robotics Competition, and ranked third place in Challenge 1 and sixth place in Challenge 3 internationally, demonstrating the reliable flight performance in the fields.
Pandora: A Cyber Range Environment for the Safe Testing and Deployment of Autonomous Cyber Attack Tools
Sep 24, 2020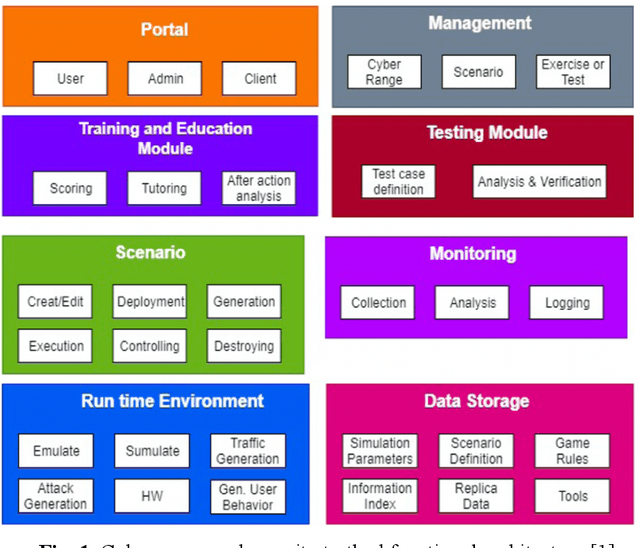
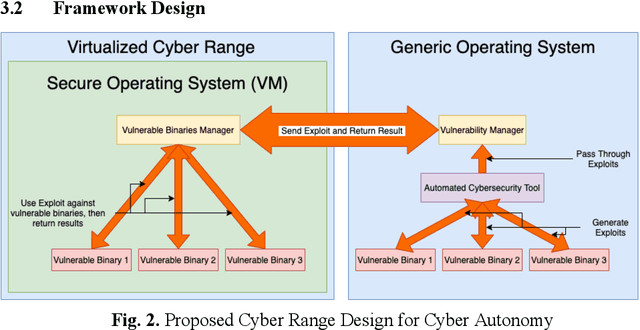
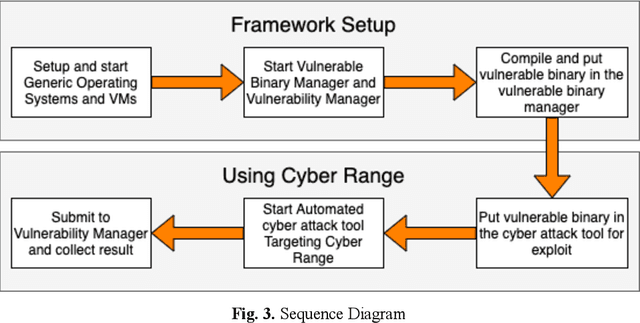

Cybersecurity tools are increasingly automated with artificial intelligent (AI) capabilities to match the exponential scale of attacks, compensate for the relatively slower rate of training new cybersecurity talents, and improve of the accuracy and performance of both tools and users. However, the safe and appropriate usage of autonomous cyber attack tools - especially at the development stages for these tools - is still largely an unaddressed gap. Our survey of current literature and tools showed that most of the existing cyber range designs are mostly using manual tools and have not considered augmenting automated tools or the potential security issues caused by the tools. In other words, there is still room for a novel cyber range design which allow security researchers to safely deploy autonomous tools and perform automated tool testing if needed. In this paper, we introduce Pandora, a safe testing environment which allows security researchers and cyber range users to perform experiments on automated cyber attack tools that may have strong potential of usage and at the same time, a strong potential for risks. Unlike existing testbeds and cyber ranges which have direct compatibility with enterprise computer systems and the potential for risk propagation across the enterprise network, our test system is intentionally designed to be incompatible with enterprise real-world computing systems to reduce the risk of attack propagation into actual infrastructure. Our design also provides a tool to convert in-development automated cyber attack tools into to executable test binaries for validation and usage realistic enterprise system environments if required. Our experiments tested automated attack tools on our proposed system to validate the usability of our proposed environment. Our experiments also proved the safety of our environment by compatibility testing using simple malicious code.
Prevention is Better than Cure: Handling Basis Collapse and Transparency in Dense Networks
Aug 22, 2020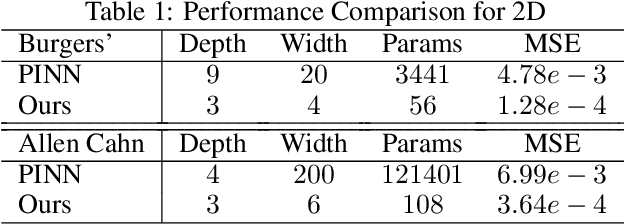
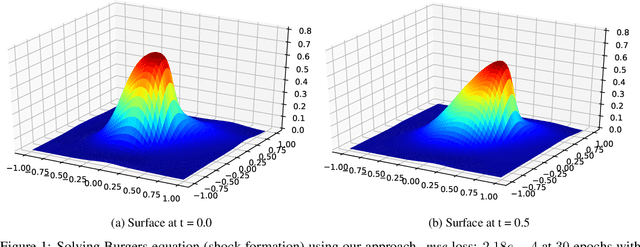
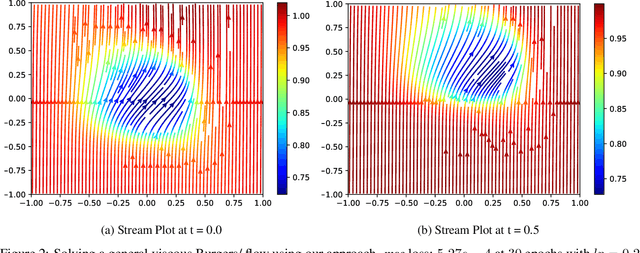
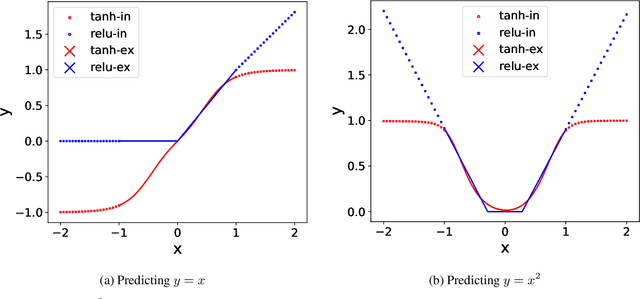
Dense nets are an integral part of any classification and regression problem. Recently, these networks have found a new application as solvers for known representations in various domains. However, one crucial issue with dense nets is it's feature interpretation and lack of reproducibility over multiple training runs. In this work, we identify a basis collapse issue as a primary cause and propose a modified loss function that circumvents this problem. We also provide a few general guidelines relating the choice of activations to loss surface roughness and appropriate scaling for designing low-weight dense nets. We demonstrate through carefully chosen numerical experiments that the basis collapse issue leads to the design of massively redundant networks. Our approach results in substantially concise nets, having $100 \times$ fewer parameters, while achieving a much lower $(10\times)$ MSE loss at scale than reported in prior works. Further, we show that the width of a dense net is acutely dependent on the feature complexity. This is in contrast to the dimension dependent width choice reported in prior theoretical works. To the best of our knowledge, this is the first time these issues and contradictions have been reported and experimentally verified. With our design guidelines we render transparency in terms of a low-weight network design. We share our codes for full reproducibility available at https://github.com/smjtgupta/Dense_Net_Regress.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020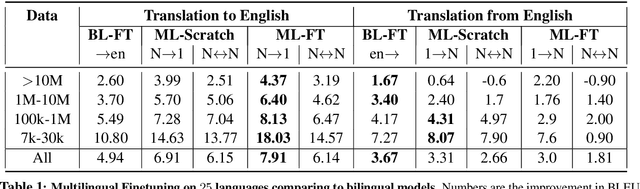
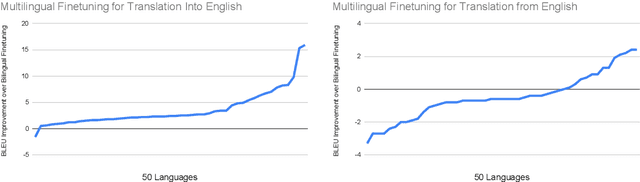
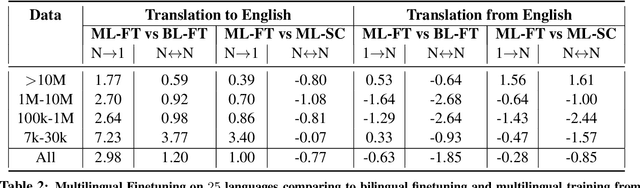
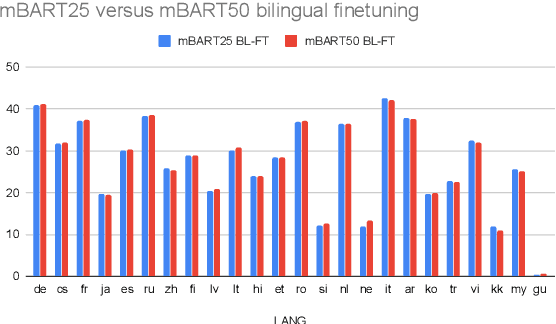
Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.
Neural Bipartite Matching
May 22, 2020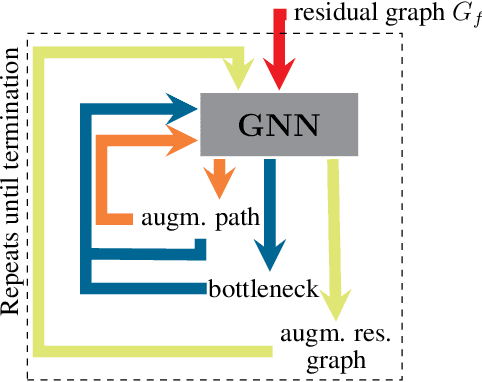

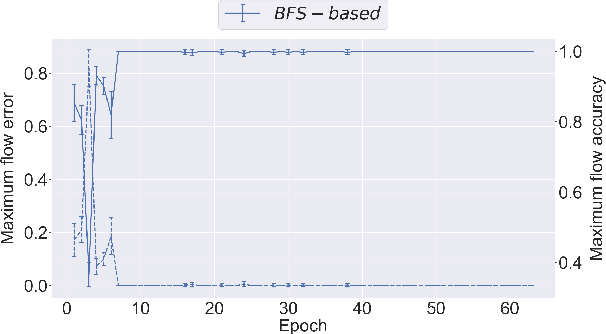
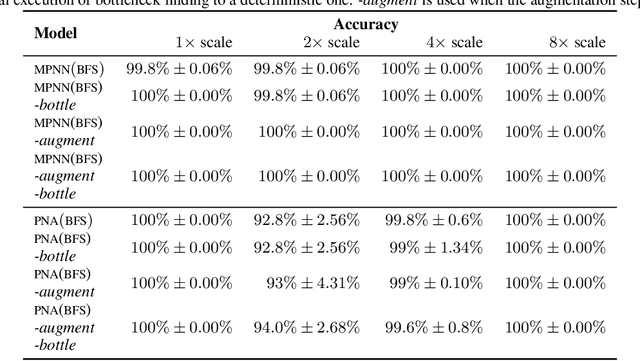
Graph neural networks have found application for learning in the space of algorithms. However, the algorithms chosen by existing research (sorting, Breadth-First search, shortest path finding, etc.) are usually trivial, from the viewpoint of a theoretical computer scientist. This report describes how neural execution is applied to a complex algorithm, such as finding maximum bipartite matching by reducing it to a flow problem and using Ford-Fulkerson to find the maximum flow. This is achieved via neural execution based only on features generated from a single GNN. The evaluation shows strongly generalising results with the network achieving optimal matching almost 100% of the time.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jun 09, 2020
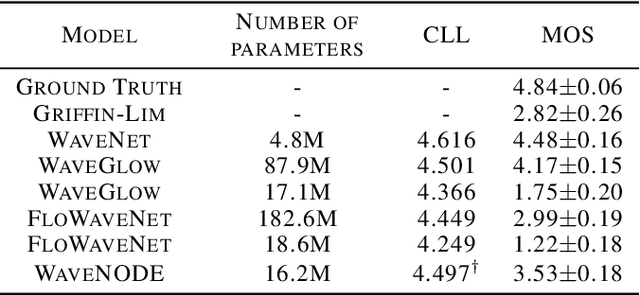
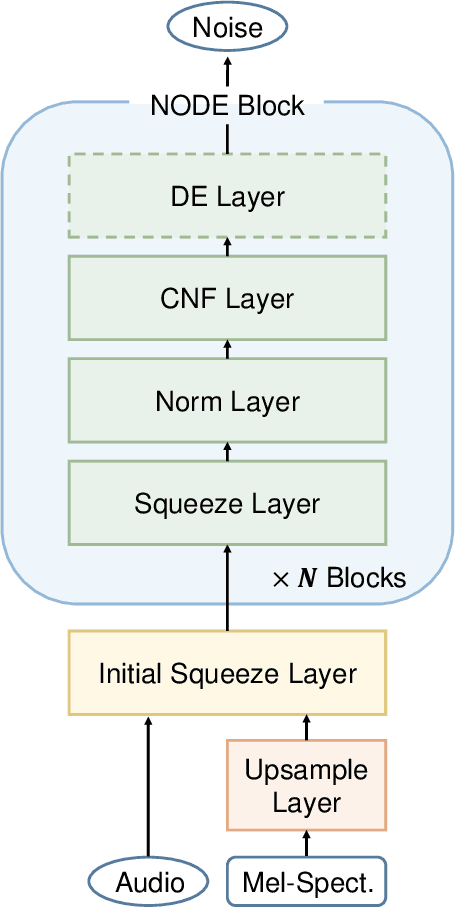

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
MAGMA: Inference and Prediction with Multi-Task Gaussian Processes
Jul 21, 2020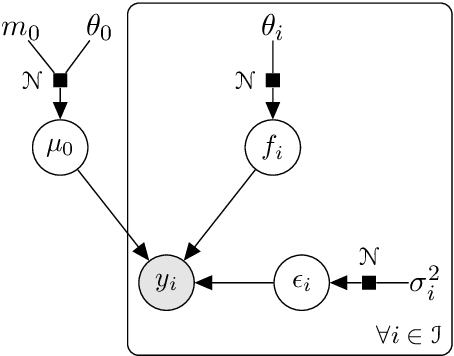
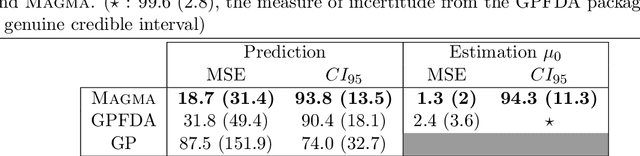
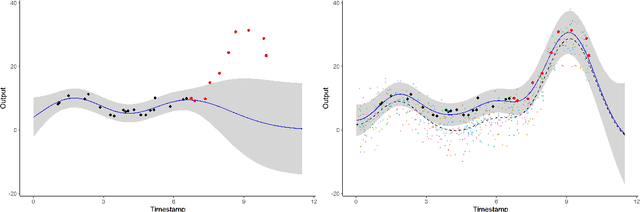
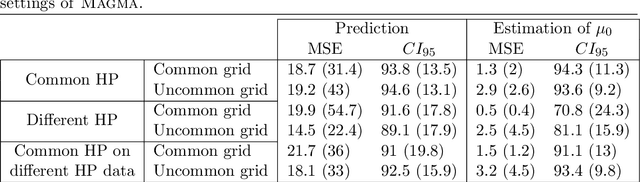
We investigate the problem of multiple time series forecasting, with the objective to improve multiple-step-ahead predictions. We propose a multi-task Gaussian process framework to simultaneously model batches of individuals with a common mean function and a specific covariance structure. This common mean is defined as a Gaussian process for which the hyper-posterior distribution is tractable. Therefore an EM algorithm can be derived for simultaneous hyper-parameters optimisation and hyper-posterior computation. Unlike previous approaches in the literature, we account for uncertainty and handle uncommon grids of observations while maintaining explicit formulations, by modelling the mean process in a non-parametric probabilistic framework. We also provide predictive formulas integrating this common mean process. This approach greatly improves the predictive performance far from observations, where information shared across individuals provides a relevant prior mean. Our overall algorithm is called \textsc{Magma} (standing for Multi tAsk Gaussian processes with common MeAn), and publicly available as a R package. The quality of the mean process estimation, predictive performances, and comparisons to alternatives are assessed in various simulated scenarios and on real datasets.