 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feasibility of Video-based Sub-meter Localization on Resource-constrained Platforms
Feb 19, 2020
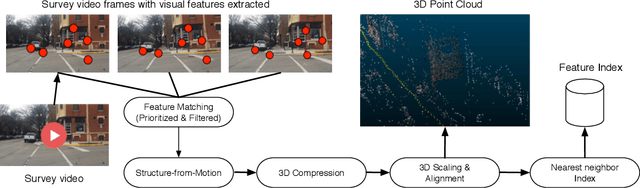

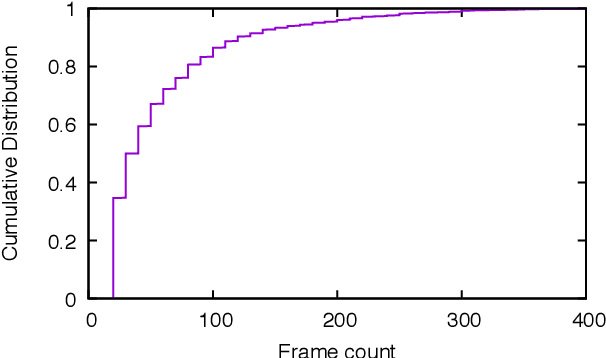
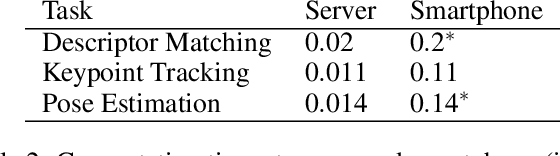
While the satellite-based Global Positioning System (GPS) is adequate for some outdoor applications, many other applications are held back by its multi-meter positioning errors and poor indoor coverage. In this paper, we study the feasibility of real-time video-based localization on resource-constrained platforms. Before commencing a localization task, a video-based localization system downloads an offline model of a restricted target environment, such as a set of city streets, or an indoor shopping mall. The system is then able to localize the user within the model, using only video as input. To enable such a system to run on resource-constrained embedded systems or smartphones, we (a) propose techniques for efficiently building a 3D model of a surveyed path, through frame selection and efficient feature matching, (b) substantially reduce model size by multiple compression techniques, without sacrificing localization accuracy, (c) propose efficient and concurrent techniques for feature extraction and matching to enable online localization, (d) propose a method with interleaved feature matching and optical flow based tracking to reduce the feature extraction and matching time in online localization. Based on an extensive set of both indoor and outdoor videos, manually annotated with location ground truth, we demonstrate that sub-meter accuracy, at real-time rates, is achievable on smart-phone type platforms, despite challenging video conditions.
Gradient Descent over Metagrammars for Syntax-Guided Synthesis
Jul 13, 2020
The performance of a syntax-guided synthesis algorithm is highly dependent on the provision of a good syntactic template, or grammar. Provision of such a template is often left to the user to do manually, though in the absence of such a grammar, state-of-the-art solvers will provide their own default grammar, which is dependent on the signature of the target program to be sythesized. In this work, we speculate this default grammar could be improved upon substantially. We build sets of rules, or metagrammars, for constructing grammars, and perform a gradient descent over these metagrammars aiming to find a metagrammar which solves more benchmarks and on average faster. We show the resulting metagrammar enables CVC4 to solve 26% more benchmarks than the default grammar within a 300s time-out, and that metagrammars learnt from tens of benchmarks generalize to performance on 100s of benchmarks.
Descent-to-Delete: Gradient-Based Methods for Machine Unlearning
Jul 06, 2020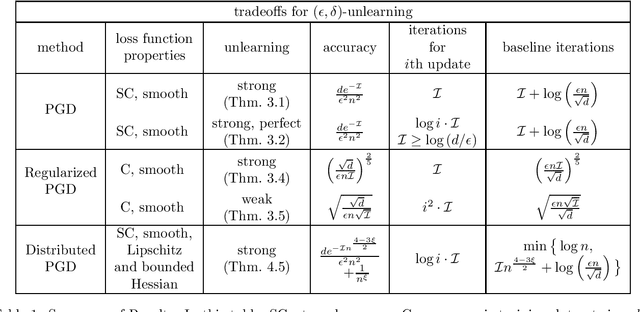
We study the data deletion problem for convex models. By leveraging techniques from convex optimization and reservoir sampling, we give the first data deletion algorithms that are able to handle an arbitrarily long sequence of adversarial updates while promising both per-deletion run-time and steady-state error that do not grow with the length of the update sequence. We also introduce several new conceptual distinctions: for example, we can ask that after a deletion, the entire state maintained by the optimization algorithm is statistically indistinguishable from the state that would have resulted had we retrained, or we can ask for the weaker condition that only the observable output is statistically indistinguishable from the observable output that would have resulted from retraining. We are able to give more efficient deletion algorithms under this weaker deletion criterion.
Improving Pixel Embedding Learning through Intermediate Distance Regression Supervision for Instance Segmentation
Jul 13, 2020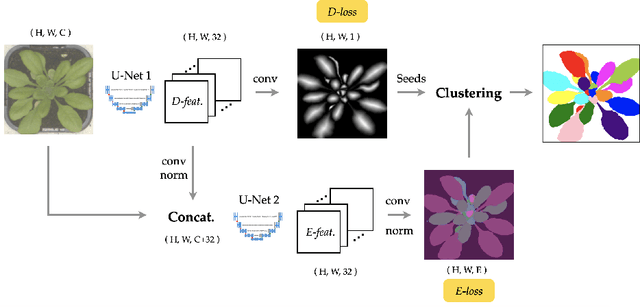

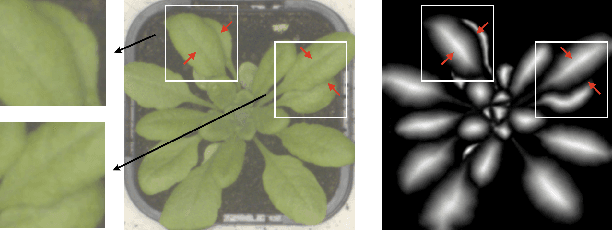
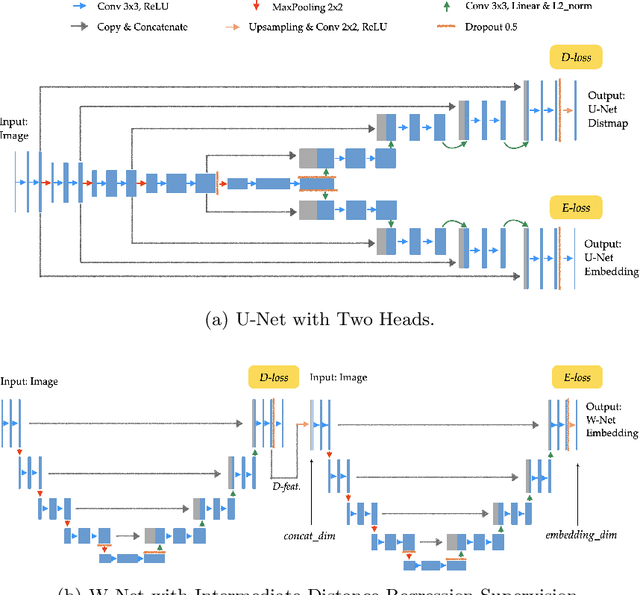
As a proposal-free approach, instance segmentation through pixel embedding learning and clustering is gaining more emphasis. Compared with bounding box refinement approaches, such as Mask R-CNN, it has potential advantages in handling complex shapes and dense objects. In this work, we propose a simple, yet highly effective, architecture for object-aware embedding learning. A distance regression module is incorporated into our architecture to generate seeds for fast clustering. At the same time, we show that the features learned by the distance regression module are able to promote the accuracy of learned object-aware embeddings significantly. By simply concatenating features of the distance regression module to the images as inputs of the embedding module, the mSBD scores on the CVPPP Leaf Segmentation Challenge can be further improved by more than 8% compared to the identical set-up without concatenation, yielding the best overall result amongst the leaderboard at CodaLab.
Velocity variations at Columbia Glacier captured by particle filtering of oblique time-lapse images
Nov 15, 2017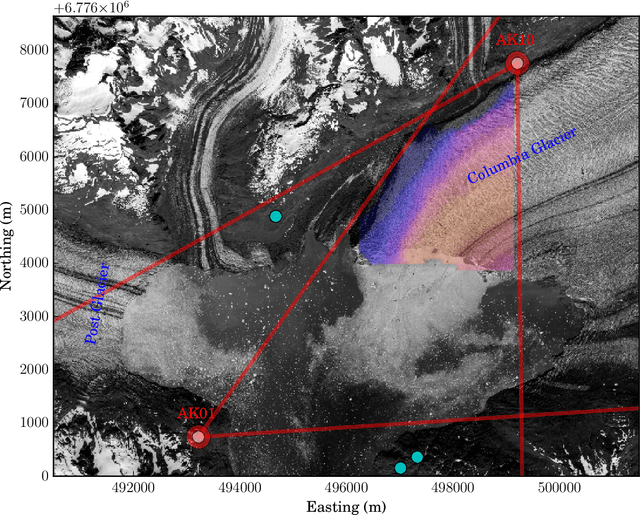
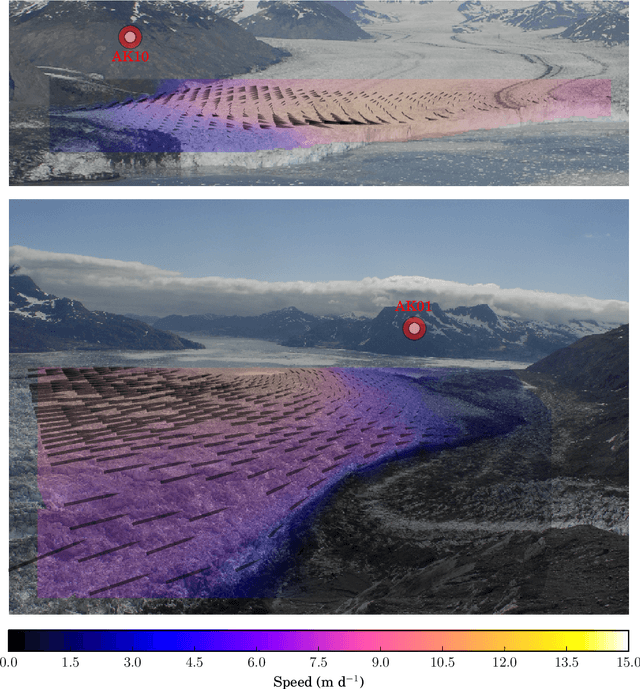
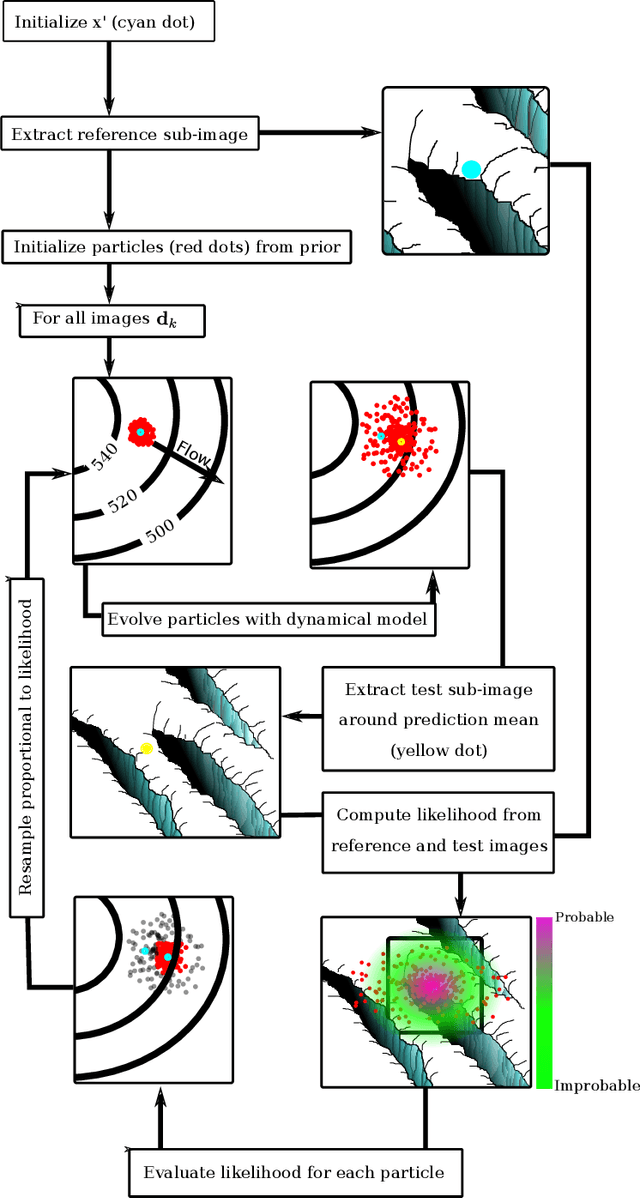
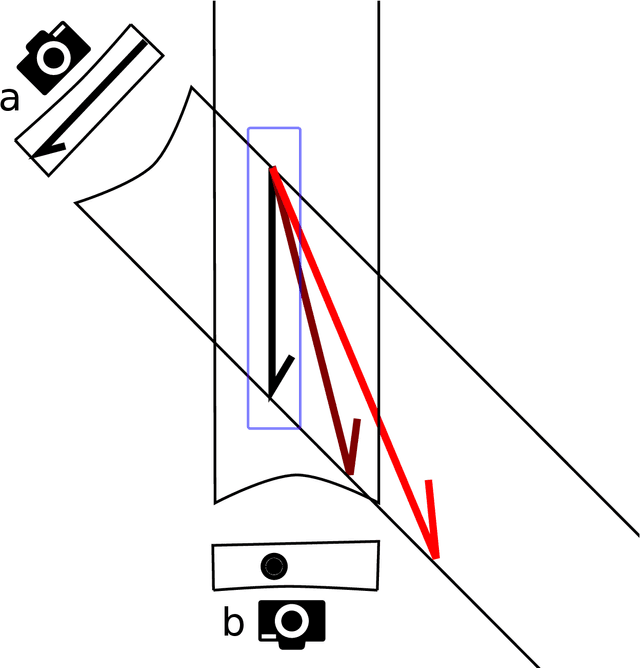
We develop a probabilistic method for tracking glacier surface motion based on time-lapse imagery, which works by sequentially resampling a stochastic state-space model according to a likelihood determined through correlation between reference and test images. The method is robust due to its natural handling of periodic occlusion and its capacity to follow multiple hypothesis displacements between images, and can improve estimates of velocity magnitude and direction through the inclusion of observations from an arbitrary number of cameras. We apply the method to an annual record of images from two cameras near the terminus of Columbia Glacier. While the method produces velocities at daily resolution, we verify our results by comparing eleven-day means to TerraSar-X. We find that Columbia Glacier transitions between a winter state characterized by moderate velocities and little temporal variability, to an early summer speed-up in which velocities are sensitive to increases in melt- and rainwater, to a fall slowdown, where velocities drop to below their winter mean and become insensitive to external forcing, a pattern consistent with the development and collapse of efficient and inefficient subglacial hydrologic networks throughout the year.
Learning Lines with Ordinal Constraints
May 25, 2020We study the problem of finding a mapping $f$ from a set of points into the real line, under ordinal triple constraints. An ordinal constraint for a triple of points $(u,v,w)$ asserts that $|f(u)-f(v)|<|f(u)-f(w)|$. We present an approximation algorithm for the dense case of this problem. Given an instance that admits a solution that satisfies $(1-\varepsilon)$-fraction of all constraints, our algorithm computes a solution that satisfies $(1-O(\varepsilon^{1/8}))$-fraction of all constraints, in time $O(n^7) + (1/\varepsilon)^{O(1/\varepsilon^{1/8})} n$.
Drift Theory in Continuous Search Spaces: Expected Hitting Time of the (1+1)-ES with 1/5 Success Rule
Apr 18, 2018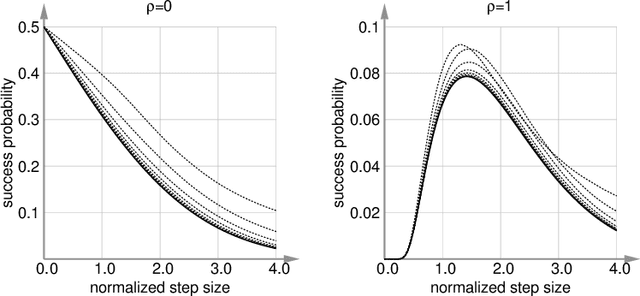
This paper explores the use of the standard approach for proving runtime bounds in discrete domains---often referred to as drift analysis---in the context of optimization on a continuous domain. Using this framework we analyze the (1+1) Evolution Strategy with one-fifth success rule on the sphere function. To deal with potential functions that are not lower-bounded, we formulate novel drift theorems. We then use the theorems to prove bounds on the expected hitting time to reach a certain target fitness in finite dimension $d$. The bounds are akin to linear convergence. We then study the dependency of the different terms on $d$ proving a convergence rate dependency of $\Theta(1/d)$. Our results constitute the first non-asymptotic analysis for the algorithm considered as well as the first explicit application of drift analysis to a randomized search heuristic with continuous domain.
Interpretable Control by Reinforcement Learning
Jul 20, 2020

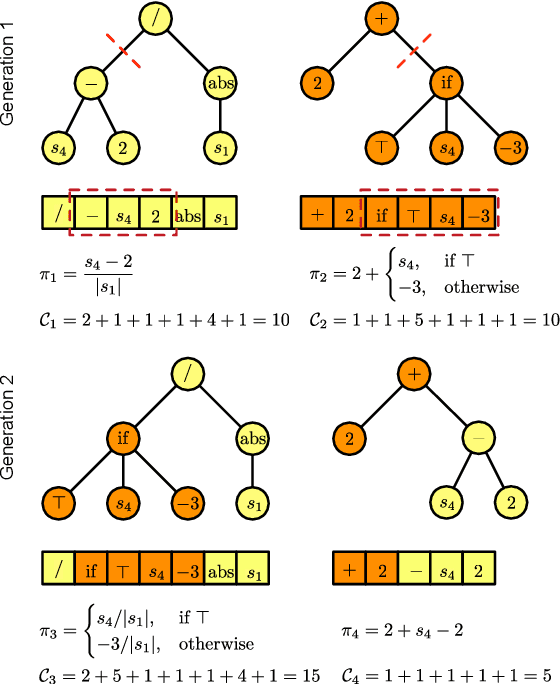
In this paper, three recently introduced reinforcement learning (RL) methods are used to generate human-interpretable policies for the cart-pole balancing benchmark. The novel RL methods learn human-interpretable policies in the form of compact fuzzy controllers and simple algebraic equations. The representations as well as the achieved control performances are compared with two classical controller design methods and three non-interpretable RL methods. All eight methods utilize the same previously generated data batch and produce their controller offline - without interaction with the real benchmark dynamics. The experiments show that the novel RL methods are able to automatically generate well-performing policies which are at the same time human-interpretable. Furthermore, one of the methods is applied to automatically learn an equation-based policy for a hardware cart-pole demonstrator by using only human-player-generated batch data. The solution generated in the first attempt already represents a successful balancing policy, which demonstrates the methods applicability to real-world problems.
Localizing the Common Action Among a Few Videos
Aug 13, 2020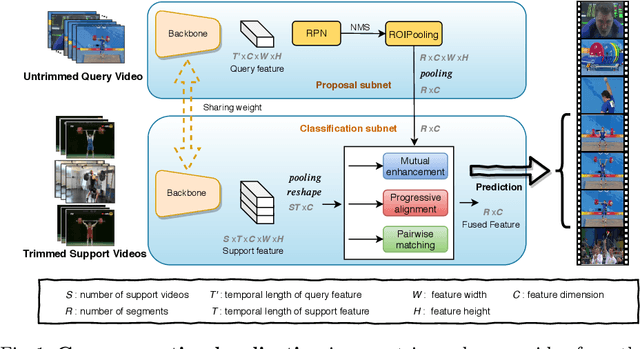
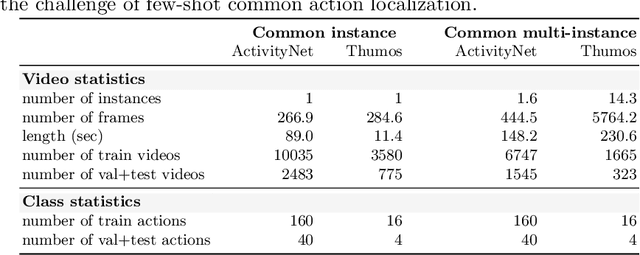
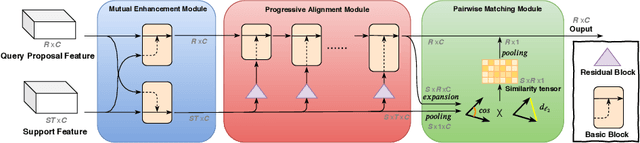
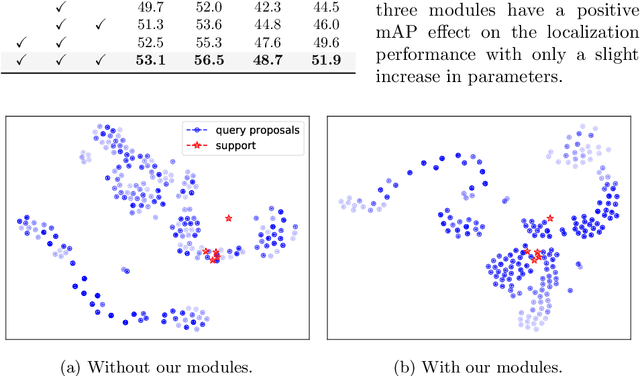
This paper strives to localize the temporal extent of an action in a long untrimmed video. Where existing work leverages many examples with their start, their ending, and/or the class of the action during training time, we propose few-shot common action localization. The start and end of an action in a long untrimmed video is determined based on just a hand-full of trimmed video examples containing the same action, without knowing their common class label. To address this task, we introduce a new 3D convolutional network architecture able to align representations from the support videos with the relevant query video segments. The network contains: (\textit{i}) a mutual enhancement module to simultaneously complement the representation of the few trimmed support videos and the untrimmed query video; (\textit{ii}) a progressive alignment module that iteratively fuses the support videos into the query branch; and (\textit{iii}) a pairwise matching module to weigh the importance of different support videos. Evaluation of few-shot common action localization in untrimmed videos containing a single or multiple action instances demonstrates the effectiveness and general applicability of our proposal.
Real-time Pedestrian Surveillance with Top View Cumulative Grids
Feb 06, 2014
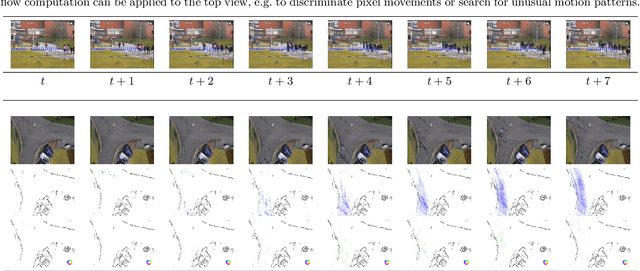

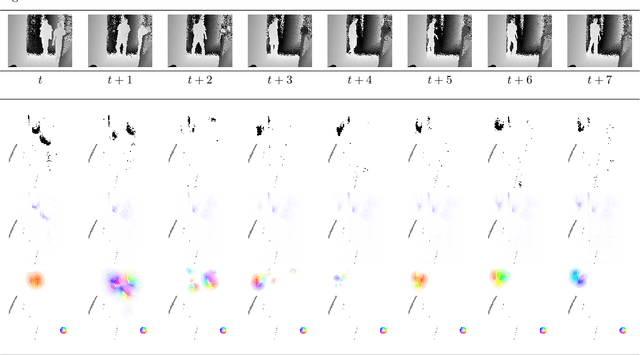
This manuscript presents an efficient approach to map pedestrian surveillance footage to an aerial view for global assessment of features. The analysis of the footages relies on low level computer vision and enable real-time surveillance. While we neglect object tracking, we introduce cumulative grids on top view scene flow visualization to highlight situations of interest in the footage. Our approach is tested on multiview footage both from RGB cameras and, for the first time in the field, on RGB-D-sensors.