 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pandora: A Cyber Range Environment for the Safe Testing and Deployment of Autonomous Cyber Attack Tools
Sep 24, 2020
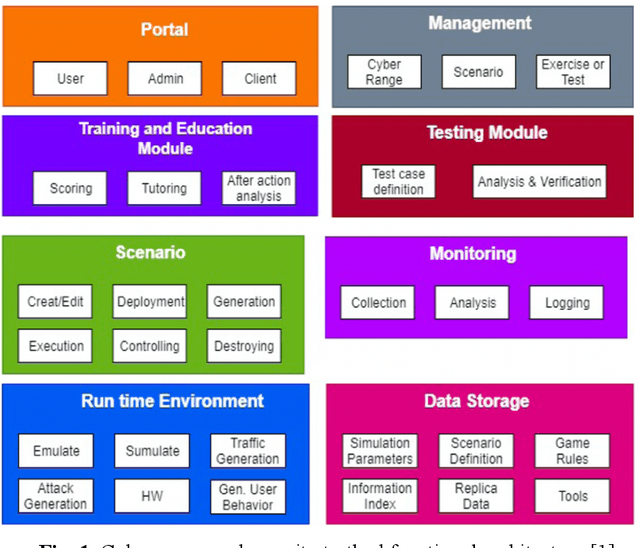
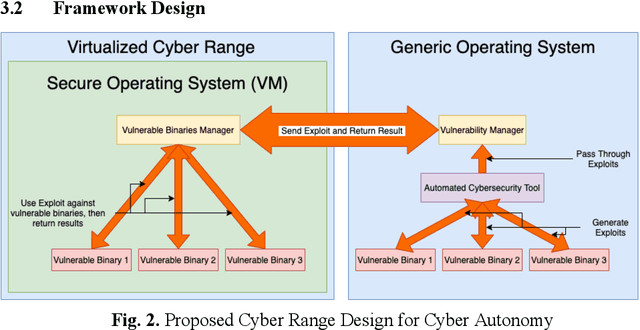
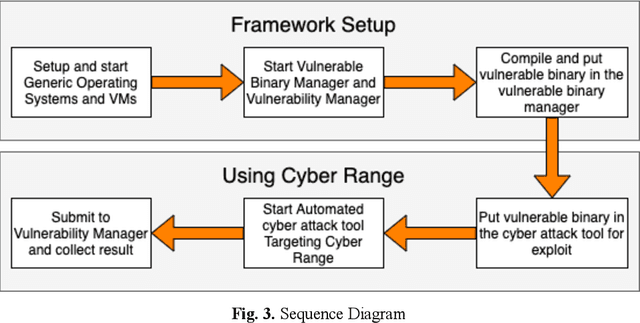

Cybersecurity tools are increasingly automated with artificial intelligent (AI) capabilities to match the exponential scale of attacks, compensate for the relatively slower rate of training new cybersecurity talents, and improve of the accuracy and performance of both tools and users. However, the safe and appropriate usage of autonomous cyber attack tools - especially at the development stages for these tools - is still largely an unaddressed gap. Our survey of current literature and tools showed that most of the existing cyber range designs are mostly using manual tools and have not considered augmenting automated tools or the potential security issues caused by the tools. In other words, there is still room for a novel cyber range design which allow security researchers to safely deploy autonomous tools and perform automated tool testing if needed. In this paper, we introduce Pandora, a safe testing environment which allows security researchers and cyber range users to perform experiments on automated cyber attack tools that may have strong potential of usage and at the same time, a strong potential for risks. Unlike existing testbeds and cyber ranges which have direct compatibility with enterprise computer systems and the potential for risk propagation across the enterprise network, our test system is intentionally designed to be incompatible with enterprise real-world computing systems to reduce the risk of attack propagation into actual infrastructure. Our design also provides a tool to convert in-development automated cyber attack tools into to executable test binaries for validation and usage realistic enterprise system environments if required. Our experiments tested automated attack tools on our proposed system to validate the usability of our proposed environment. Our experiments also proved the safety of our environment by compatibility testing using simple malicious code.
Building Robust Industrial Applicable Object Detection Models Using Transfer Learning and Single Pass Deep Learning Architectures
Jul 09, 2020

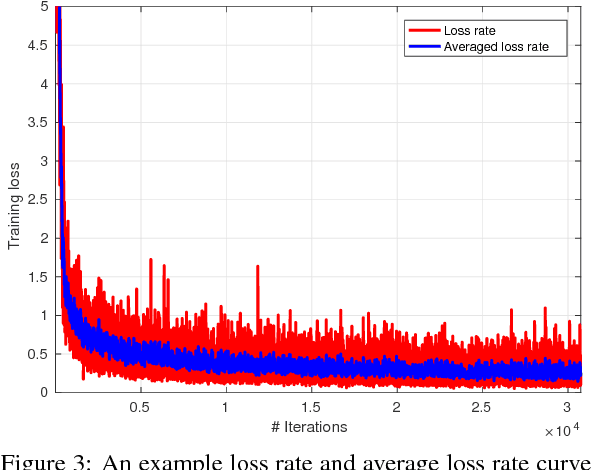
The uprising trend of deep learning in computer vision and artificial intelligence can simply not be ignored. On the most diverse tasks, from recognition and detection to segmentation, deep learning is able to obtain state-of-the-art results, reaching top notch performance. In this paper we explore how deep convolutional neural networks dedicated to the task of object detection can improve our industrial-oriented object detection pipelines, using state-of-the-art open source deep learning frameworks, like Darknet. By using a deep learning architecture that integrates region proposals, classification and probability estimation in a single run, we aim at obtaining real-time performance. We focus on reducing the needed amount of training data drastically by exploring transfer learning, while still maintaining a high average precision. Furthermore we apply these algorithms to two industrially relevant applications, one being the detection of promotion boards in eye tracking data and the other detecting and recognizing packages of warehouse products for augmented advertisements.
Weakness Analysis of Cyberspace Configuration Based on Reinforcement Learning
Jul 09, 2020

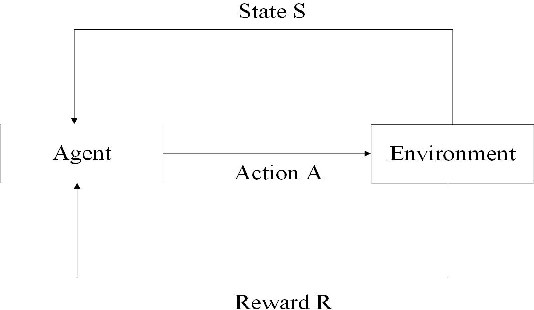
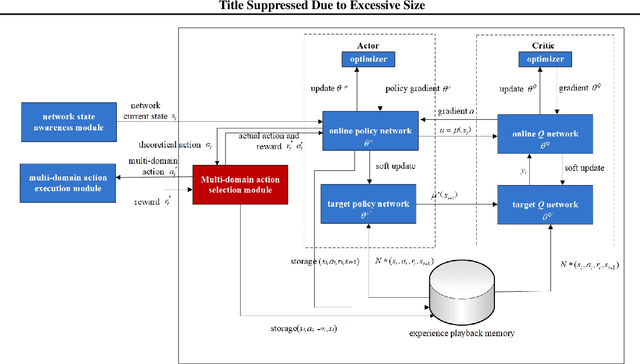
In this work, we present a learning-based approach to analysis cyberspace configuration. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of agents as attackers, our method becomes better at rapidly finding attack paths for previously hidden paths, especially in multiple domain cyberspace. To achieve these results, we pose finding attack paths as a Reinforcement Learning (RL) problem and train an agent to find multiple domain attack paths. To enable our RL policy to find more hidden attack paths, we ground representation introduction an multiple domain action select module in RL. By designing a simulated cyberspace experimental environment to verify our method. Our objective is to find more hidden attack paths, to analysis the weakness of cyberspace configuration. The experimental results show that our method can find more hidden multiple domain attack paths than existing baselines methods.
The Computational Capacity of Memristor Reservoirs
Aug 31, 2020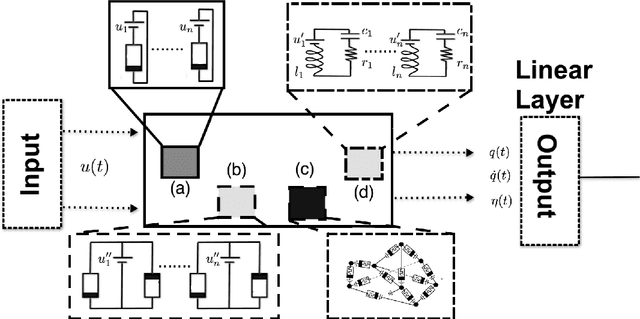
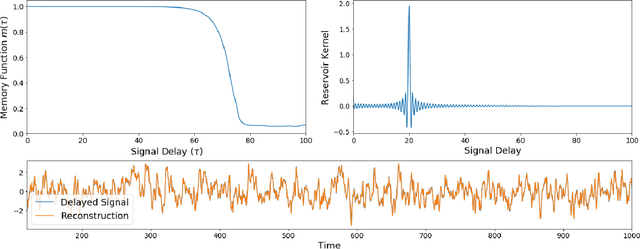
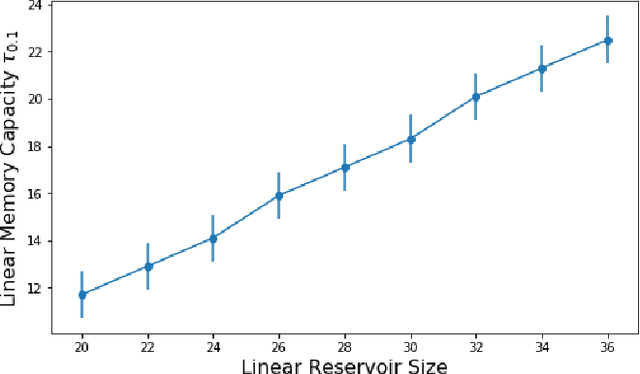
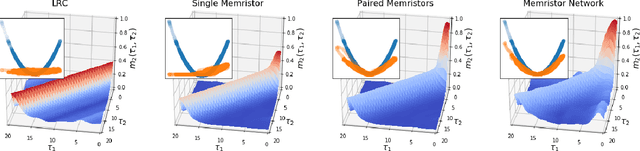
Reservoir computing is a machine learning paradigm in which a high-dimensional dynamical system, or \emph{reservoir}, is used to approximate and perform predictions on time series data. Its simple training procedure allows for very large reservoirs that can provide powerful computational capabilities. The scale, speed and power-usage characteristics of reservoir computing could be enhanced by constructing reservoirs out of electronic circuits, but this requires a precise understanding of how such circuits process and store information. We analyze the feasibility and optimal design of such reservoirs by considering the equations of motion of circuits that include both linear elements (resistors, inductors, and capacitors) and nonlinear memory elements (called memristors). This complements previous studies, which have examined such systems through simulation and experiment. We provide analytic results regarding the fundamental feasibility of such reservoirs, and give a systematic characterization of their computational properties, examining the types of input-output relationships that may be approximated. This allows us to design reservoirs with optimal properties in terms of their ability to reconstruct a certain signal (or functions thereof). In particular, by introducing measures of the total linear and nonlinear computational capacities of the reservoir, we are able to design electronic circuits whose total computation capacity scales linearly with the system size. Comparison with conventional echo state reservoirs show that these electronic reservoirs can match or exceed their performance in a form that may be directly implemented in hardware.
SELD-TCN: Sound Event Localization & Detection via Temporal Convolutional Networks
Mar 03, 2020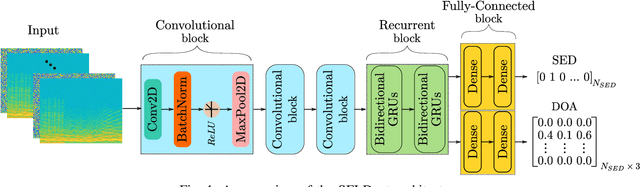
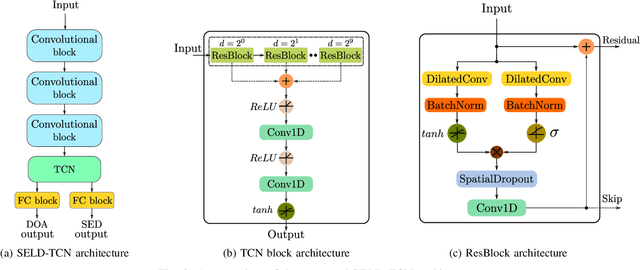
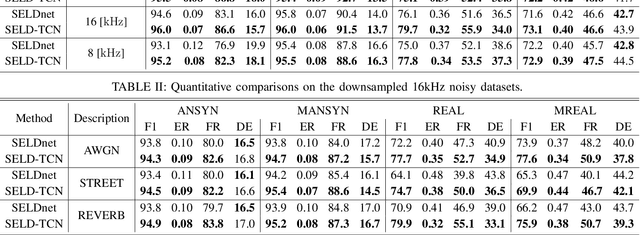
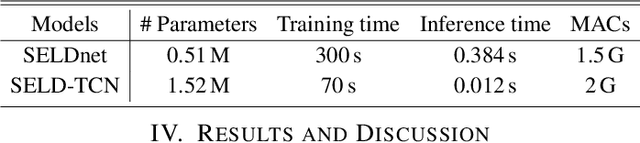
The understanding of the surrounding environment plays a critical role in autonomous robotic systems, such as self-driving cars. Extensive research has been carried out concerning visual perception. Yet, to obtain a more complete perception of the environment, autonomous systems of the future should also take acoustic information into account. Recent sound event localization and detection (SELD) frameworks utilize convolutional recurrent neural networks (CRNNs). However, considering the recurrent nature of CRNNs, it becomes challenging to implement them efficiently on embedded hardware. Not only are their computations strenuous to parallelize, but they also require high memory bandwidth and large memory buffers. In this work, we develop a more robust and hardware-friendly novel architecture based on a temporal convolutional network(TCN). The proposed framework (SELD-TCN) outperforms the state-of-the-art SELDnet performance on four different datasets. Moreover, SELD-TCN achieves 4x faster training time per epoch and 40x faster inference time on an ordinary graphics processing unit (GPU).
Learning Memory-guided Normality for Anomaly Detection
Mar 30, 2020
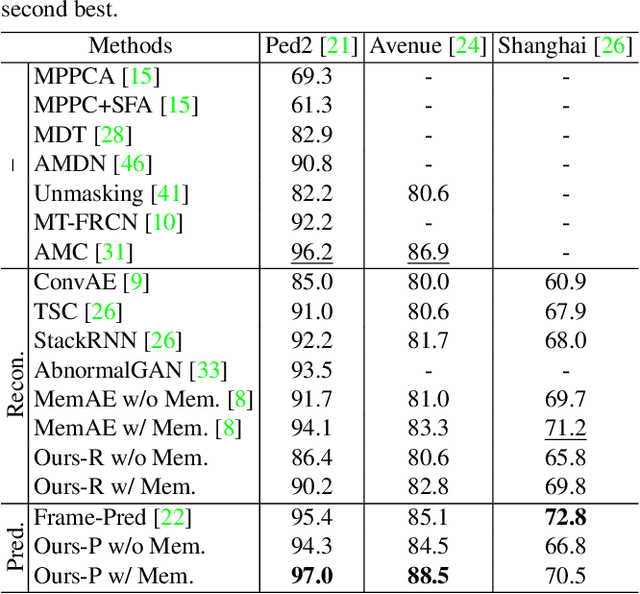
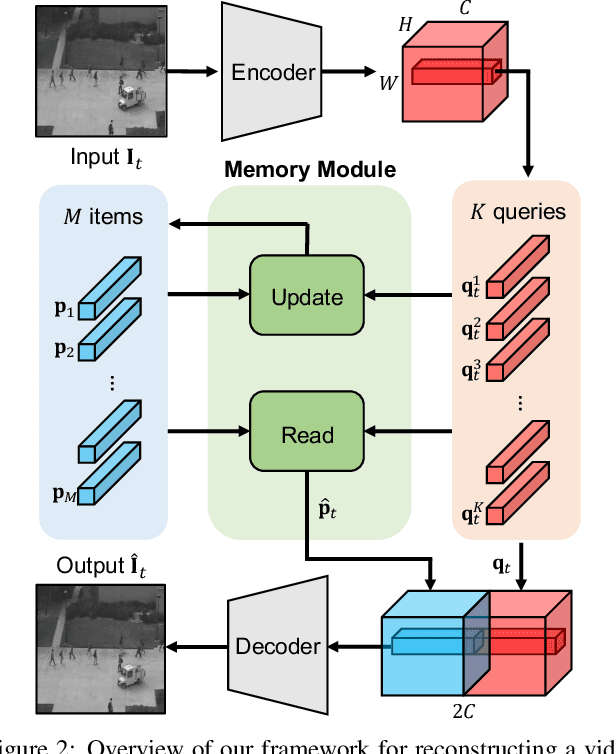
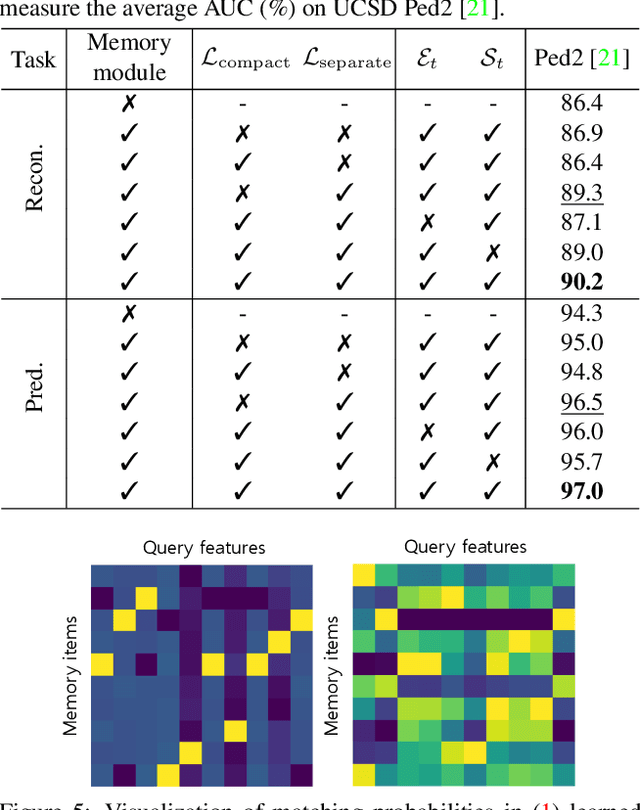
We address the problem of anomaly detection, that is, detecting anomalous events in a video sequence. Anomaly detection methods based on convolutional neural networks (CNNs) typically leverage proxy tasks, such as reconstructing input video frames, to learn models describing normality without seeing anomalous samples at training time, and quantify the extent of abnormalities using the reconstruction error at test time. The main drawbacks of these approaches are that they do not consider the diversity of normal patterns explicitly, and the powerful representation capacity of CNNs allows to reconstruct abnormal video frames. To address this problem, we present an unsupervised learning approach to anomaly detection that considers the diversity of normal patterns explicitly, while lessening the representation capacity of CNNs. To this end, we propose to use a memory module with a new update scheme where items in the memory record prototypical patterns of normal data. We also present novel feature compactness and separateness losses to train the memory, boosting the discriminative power of both memory items and deeply learned features from normal data. Experimental results on standard benchmarks demonstrate the effectiveness and efficiency of our approach, which outperforms the state of the art.
Auxiliary Tasks Speed Up Learning PointGoal Navigation
Jul 09, 2020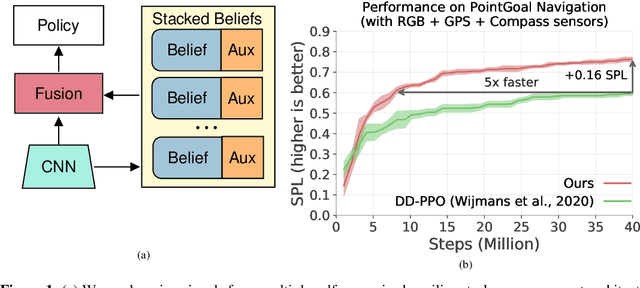

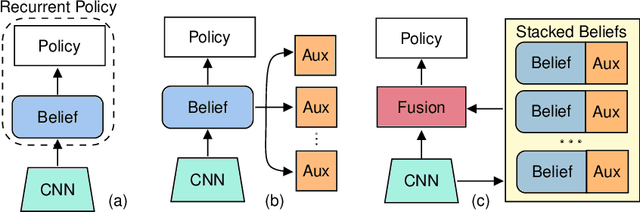
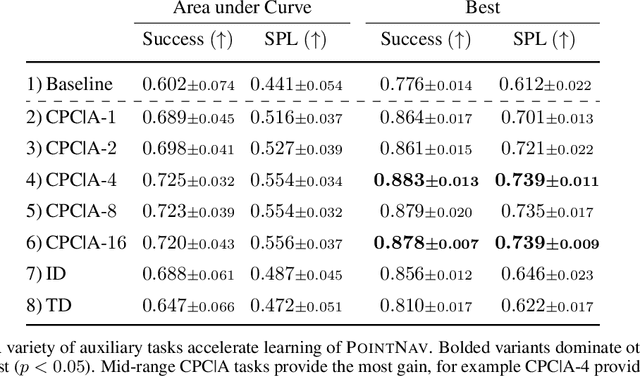
PointGoal Navigation is an embodied task that requires agents to navigate to a specified point in an unseen environment. Wijmans et al. showed that this task is solvable but their method is computationally prohibitive, requiring 2.5 billion frames and 180 GPU-days. In this work, we develop a method to significantly increase sample and time efficiency in learning PointNav using self-supervised auxiliary tasks (e.g. predicting the action taken between two egocentric observations, predicting the distance between two observations from a trajectory,etc.).We find that naively combining multiple auxiliary tasks improves sample efficiency,but only provides marginal gains beyond a point. To overcome this, we use attention to combine representations learnt from individual auxiliary tasks. Our best agent is 5x faster to reach the performance of the previous state-of-the-art, DD-PPO, at 40M frames, and improves on DD-PPO's performance at40M frames by 0.16 SPL. Our code is publicly available at https://github.com/joel99/habitat-pointnav-aux.
One Click Lesion RECIST Measurement and Segmentation on CT Scans
Jul 21, 2020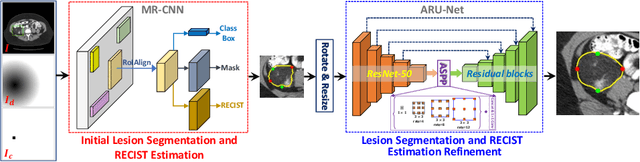
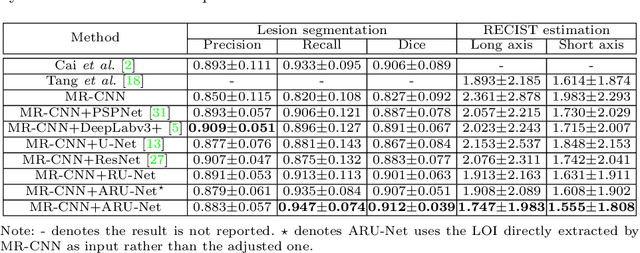
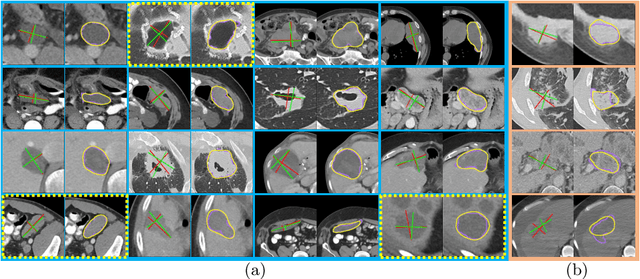
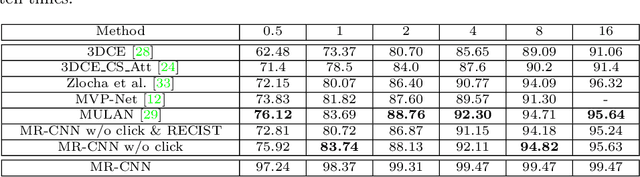
In clinical trials, one of the radiologists' routine work is to measure tumor sizes on medical images using the RECIST criteria (Response Evaluation Criteria In Solid Tumors). However, manual measurement is tedious and subject to inter-observer variability. We propose a unified framework named SEENet for semi-automatic lesion \textit{SE}gmentation and RECIST \textit{E}stimation on a variety of lesions over the entire human body. The user is only required to provide simple guidance by clicking once near the lesion. SEENet consists of two main parts. The first one extracts the lesion of interest with the one-click guidance, roughly segments the lesion, and estimates its RECIST measurement. Based on the results of the first network, the second one refines the lesion segmentation and RECIST estimation. SEENet achieves state-of-the-art performance in lesion segmentation and RECIST estimation on the large-scale public DeepLesion dataset. It offers a practical tool for radiologists to generate reliable lesion measurements (i.e. segmentation mask and RECIST) with minimal human effort and greatly reduced time.
Wandering Within a World: Online Contextualized Few-Shot Learning
Jul 09, 2020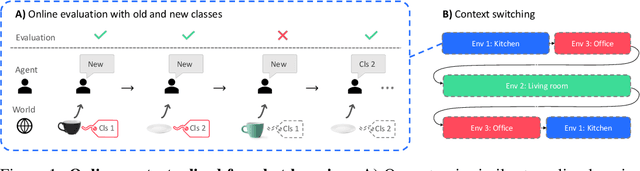


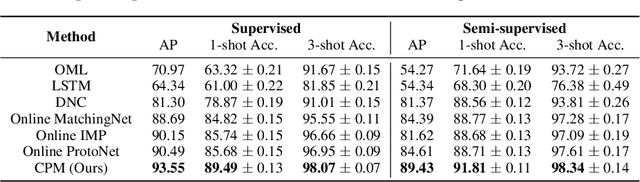
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new model named contextual prototypical memory that can make use of spatiotemporal contextual information from the recent past.
Versatile Multilinked Aerial Robot with Tilting Propellers: Design, Modeling, Control and State Estimation for Autonomous Flight and Manipulation
Aug 12, 2020
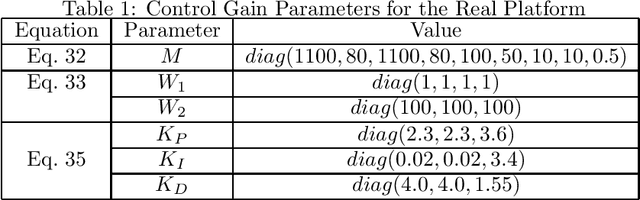
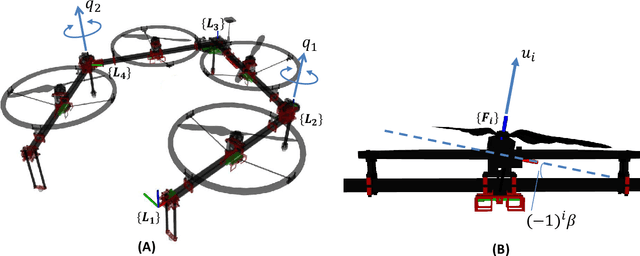
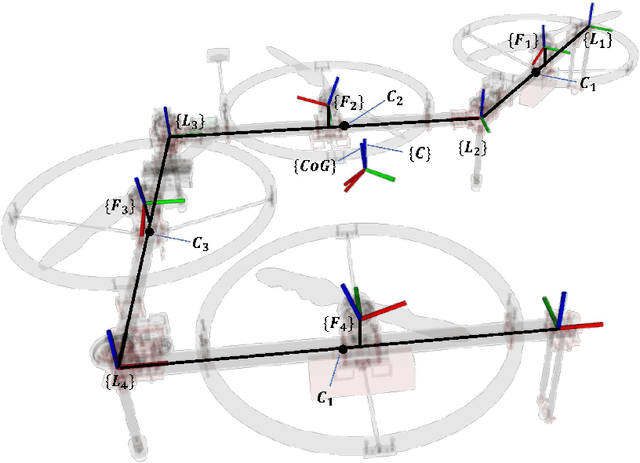
Multilinked aerial robot is one of the state-of-the-art works in aerial robotics, which demonstrates the deformability benefiting both maneuvering and manipulation. However, the performance in outdoor physical world has not yet been evaluated because of the weakness in the controllability and the lack of the state estimation for autonomous flight. Thus we adopt tilting propellers to enhance the controllability. The related design, modeling and control method are developed in this work to enable the stable hovering and deformation. Furthermore, the state estimation which involves the time synchronization between sensors and the multilinked kinematics is also presented in this work to enable the fully autonomous flight in the outdoor environment. Various autonomous outdoor experiments, including the fast maneuvering for interception with target, object grasping for delivery, and blanket manipulation for firefighting are performed to evaluate the feasibility and versatility of the proposed robot platform. To the best of our knowledge, this is the first study for the multilinked aerial robot to achieve the fully autonomous flight and the manipulation task in outdoor environment. We also applied our platform in all challenges of the 2020 Mohammed Bin Zayed International Robotics Competition, and ranked third place in Challenge 1 and sixth place in Challenge 3 internationally, demonstrating the reliable flight performance in the fields.