 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey of Evaluation Metrics Used for NLG Systems
Oct 05, 2020
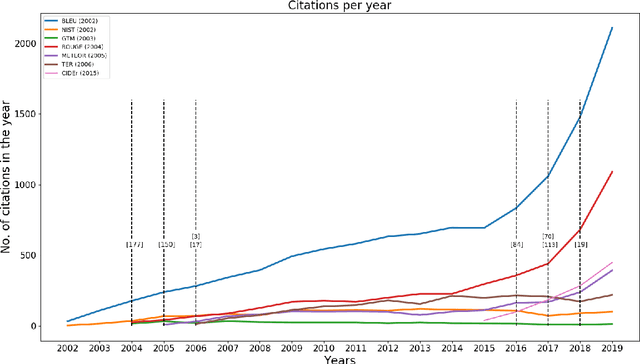
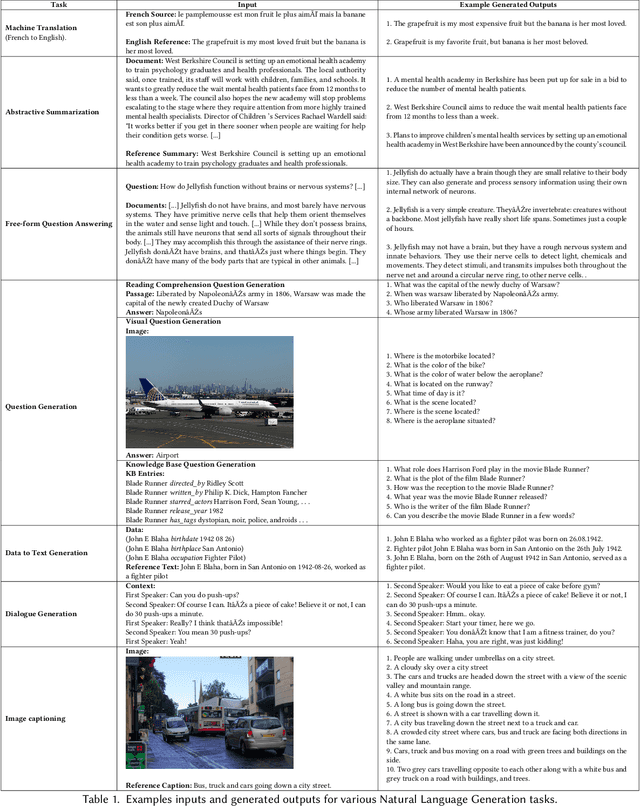


The success of Deep Learning has created a surge in interest in a wide a range of Natural Language Generation (NLG) tasks. Deep Learning has not only pushed the state of the art in several existing NLG tasks but has also facilitated researchers to explore various newer NLG tasks such as image captioning. Such rapid progress in NLG has necessitated the development of accurate automatic evaluation metrics that would allow us to track the progress in the field of NLG. However, unlike classification tasks, automatically evaluating NLG systems in itself is a huge challenge. Several works have shown that early heuristic-based metrics such as BLEU, ROUGE are inadequate for capturing the nuances in the different NLG tasks. The expanding number of NLG models and the shortcomings of the current metrics has led to a rapid surge in the number of evaluation metrics proposed since 2014. Moreover, various evaluation metrics have shifted from using pre-determined heuristic-based formulae to trained transformer models. This rapid change in a relatively short time has led to the need for a survey of the existing NLG metrics to help existing and new researchers to quickly come up to speed with the developments that have happened in NLG evaluation in the last few years. Through this survey, we first wish to highlight the challenges and difficulties in automatically evaluating NLG systems. Then, we provide a coherent taxonomy of the evaluation metrics to organize the existing metrics and to better understand the developments in the field. We also describe the different metrics in detail and highlight their key contributions. Later, we discuss the main shortcomings identified in the existing metrics and describe the methodology used to evaluate evaluation metrics. Finally, we discuss our suggestions and recommendations on the next steps forward to improve the automatic evaluation metrics.
Suphx: Mastering Mahjong with Deep Reinforcement Learning
Mar 30, 2020
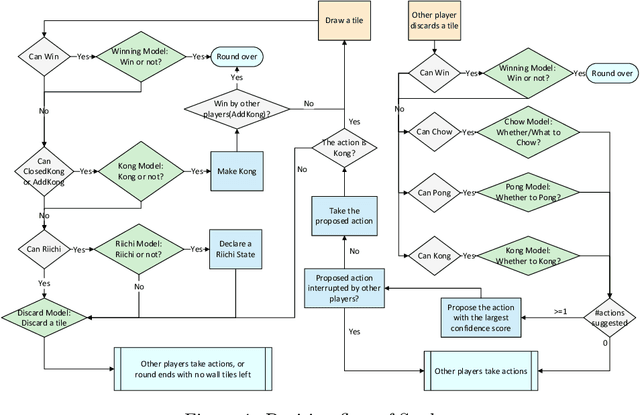
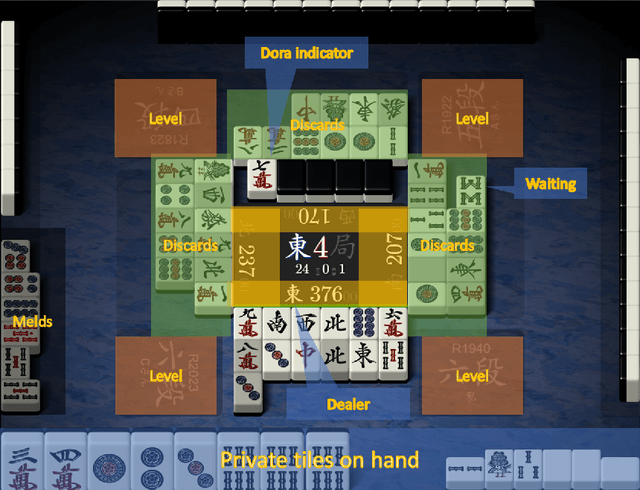

Artificial Intelligence (AI) has achieved great success in many domains, and game AI is widely regarded as its beachhead since the dawn of AI. In recent years, studies on game AI have gradually evolved from relatively simple environments (e.g., perfect-information games such as Go, chess, shogi or two-player imperfect-information games such as heads-up Texas hold'em) to more complex ones (e.g., multi-player imperfect-information games such as multi-player Texas hold'em and StartCraft II). Mahjong is a popular multi-player imperfect-information game worldwide but very challenging for AI research due to its complex playing/scoring rules and rich hidden information. We design an AI for Mahjong, named Suphx, based on deep reinforcement learning with some newly introduced techniques including global reward prediction, oracle guiding, and run-time policy adaptation. Suphx has demonstrated stronger performance than most top human players in terms of stable rank and is rated above 99.99% of all the officially ranked human players in the Tenhou platform. This is the first time that a computer program outperforms most top human players in Mahjong.
Using Machine Learning to Emulate Agent-Based Simulations
May 05, 2020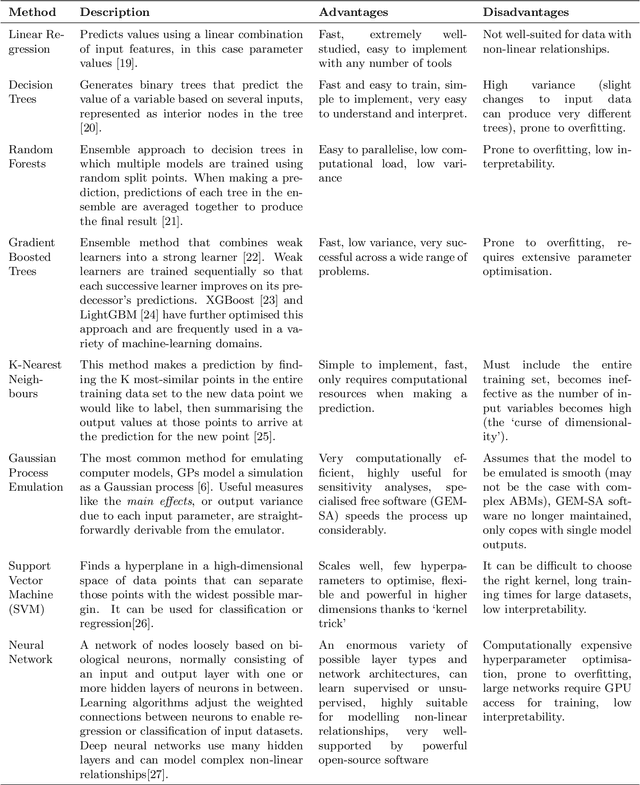
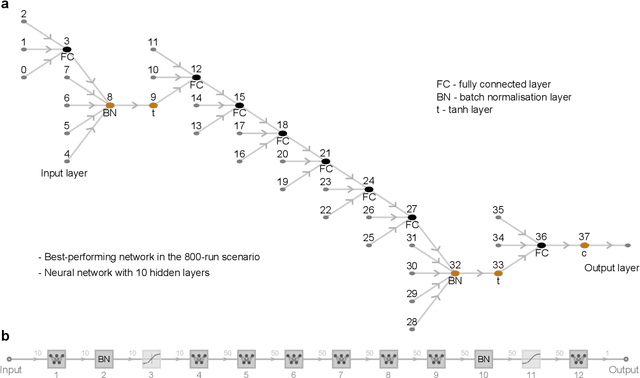

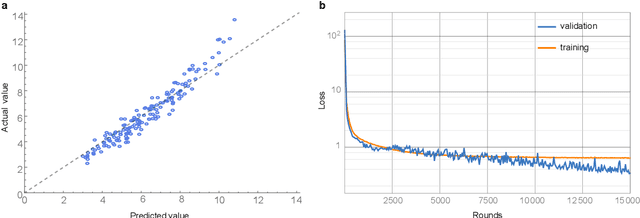
In this paper, we evaluate the performance of multiple machine-learning methods in the emulation of agent-based models (ABMs). ABMs are a popular methodology for modelling complex systems composed of multiple interacting processes. The analysis of ABM outputs is often not straightforward, as the relationships between input parameters can be non-linear or even chaotic, and each individual model run can require significant CPU time. Statistical emulation, in which a statistical model of the ABM is constructed to allow for more in-depth model analysis, has proven valuable for some applications. Here we compare multiple machine-learning methods for ABM emulation in order to determine the approaches best-suited to replicating the complex and non-linear behaviour of ABMs. Our results suggest that, in most scenarios, artificial neural networks (ANNs) and support vector machines outperform Gaussian process emulators, currently the most commonly used method for the emulation of complex computational models. ANNs produced the most accurate model replications in scenarios with high numbers of model runs, although training times for these emulators were considerably longer than for any other method. We propose that users of complex ABMs would benefit from using machine-learning methods for emulation, as this can facilitate more robust sensitivity analyses for their models as well as reducing CPU time consumption when calibrating and analysing the simulation.
Dynamic Future Net: Diversified Human Motion Generation
Aug 25, 2020
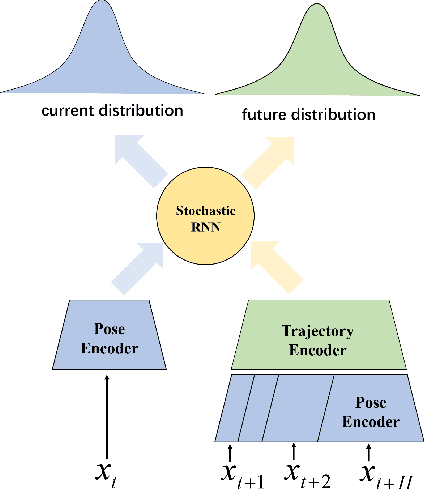
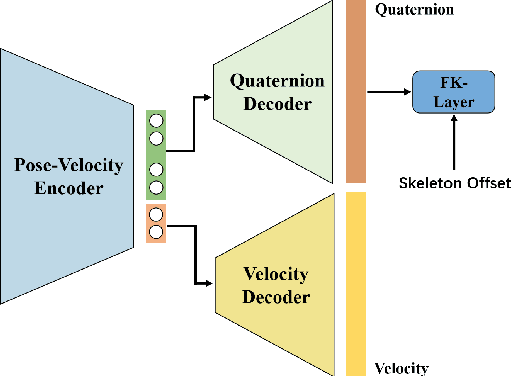
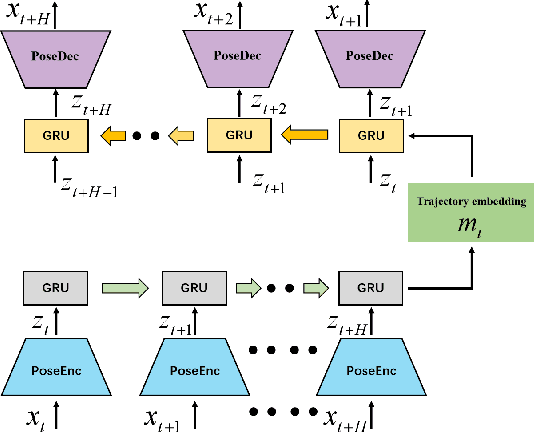
Human motion modelling is crucial in many areas such as computer graphics, vision and virtual reality. Acquiring high-quality skeletal motions is difficult due to the need for specialized equipment and laborious manual post-posting, which necessitates maximizing the use of existing data to synthesize new data. However, it is a challenge due to the intrinsic motion stochasticity of human motion dynamics, manifested in the short and long terms. In the short term, there is strong randomness within a couple frames, e.g. one frame followed by multiple possible frames leading to different motion styles; while in the long term, there are non-deterministic action transitions. In this paper, we present Dynamic Future Net, a new deep learning model where we explicitly focuses on the aforementioned motion stochasticity by constructing a generative model with non-trivial modelling capacity in temporal stochasticity. Given limited amounts of data, our model can generate a large number of high-quality motions with arbitrary duration, and visually-convincing variations in both space and time. We evaluate our model on a wide range of motions and compare it with the state-of-the-art methods. Both qualitative and quantitative results show the superiority of our method, for its robustness, versatility and high-quality.
Dynamics Generalization via Information Bottleneck in Deep Reinforcement Learning
Aug 03, 2020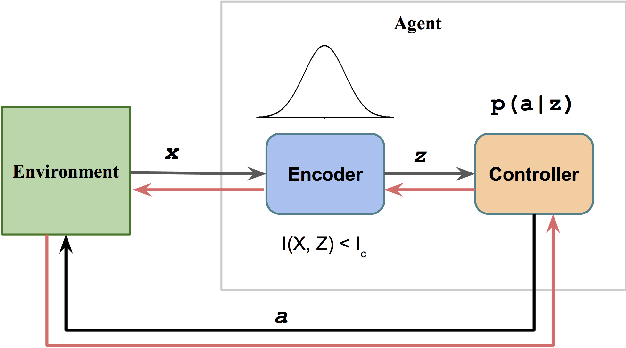
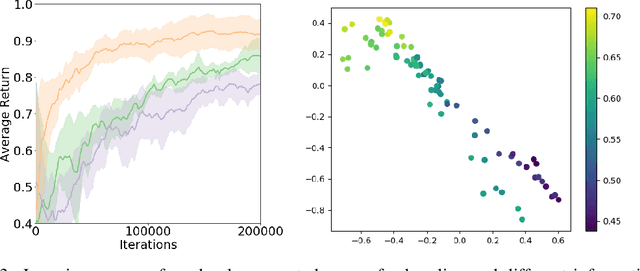
Despite the significant progress of deep reinforcement learning (RL) in solving sequential decision making problems, RL agents often overfit to training environments and struggle to adapt to new, unseen environments. This prevents robust applications of RL in real world situations, where system dynamics may deviate wildly from the training settings. In this work, our primary contribution is to propose an information theoretic regularization objective and an annealing-based optimization method to achieve better generalization ability in RL agents. We demonstrate the extreme generalization benefits of our approach in different domains ranging from maze navigation to robotic tasks; for the first time, we show that agents can generalize to test parameters more than 10 standard deviations away from the training parameter distribution. This work provides a principled way to improve generalization in RL by gradually removing information that is redundant for task-solving; it opens doors for the systematic study of generalization from training to extremely different testing settings, focusing on the established connections between information theory and machine learning.
Continuous Authentication of Wearable Device Users from Heart Rate, Gait, and Breathing Data
Aug 25, 2020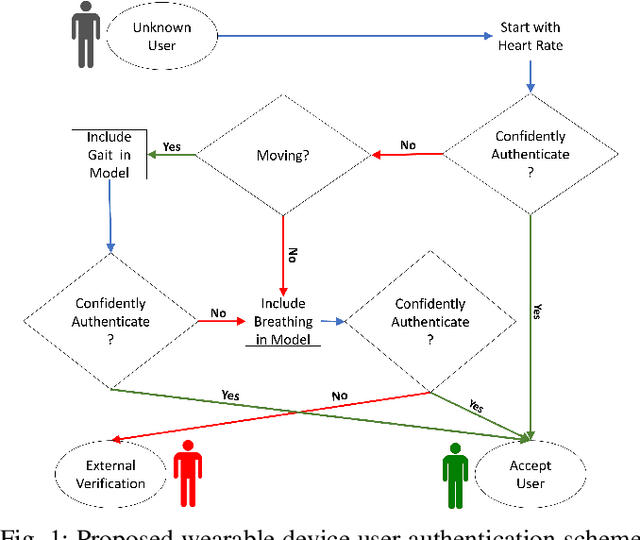
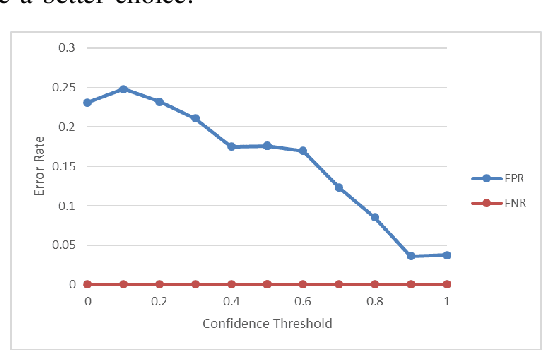
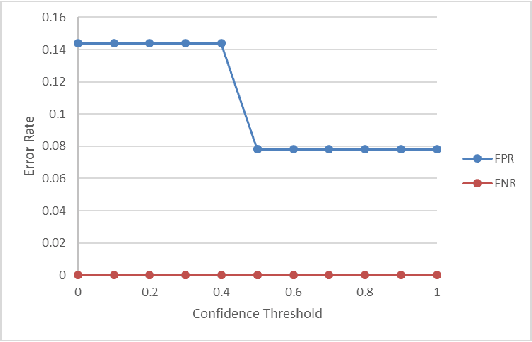
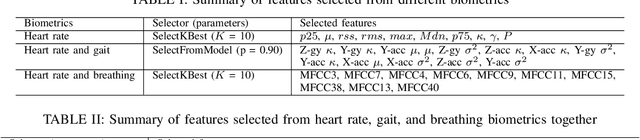
The security of private information is becoming the bedrock of an increasingly digitized society. While the users are flooded with passwords and PINs, these gold-standard explicit authentications are becoming less popular and valuable. Recent biometric-based authentication methods, such as facial or finger recognition, are getting popular due to their higher accuracy. However, these hard-biometric-based systems require dedicated devices with powerful sensors and authentication models, which are often limited to most of the market wearables. Still, market wearables are collecting various private information of a user and are becoming an integral part of life: accessing cars, bank accounts, etc. Therefore, time demands a burden-free implicit authentication mechanism for wearables using the less-informative soft-biometric data that are easily obtainable from modern market wearables. In this work, we present a context-dependent soft-biometric-based authentication system for wearables devices using heart rate, gait, and breathing audio signals. From our detailed analysis using the "leave-one-out" validation, we find that a lighter $k$-Nearest Neighbor ($k$-NN) model with $k = 2$ can obtain an average accuracy of $0.93 \pm 0.06$, $F_1$ score $0.93 \pm 0.03$, and {\em false positive rate} (FPR) below $0.08$ at 50\% level of confidence, which shows the promise of this work.
A radiomics approach to analyze cardiac alterations in hypertension
Jul 21, 2020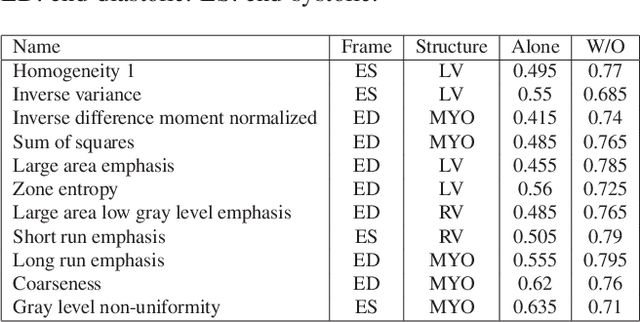
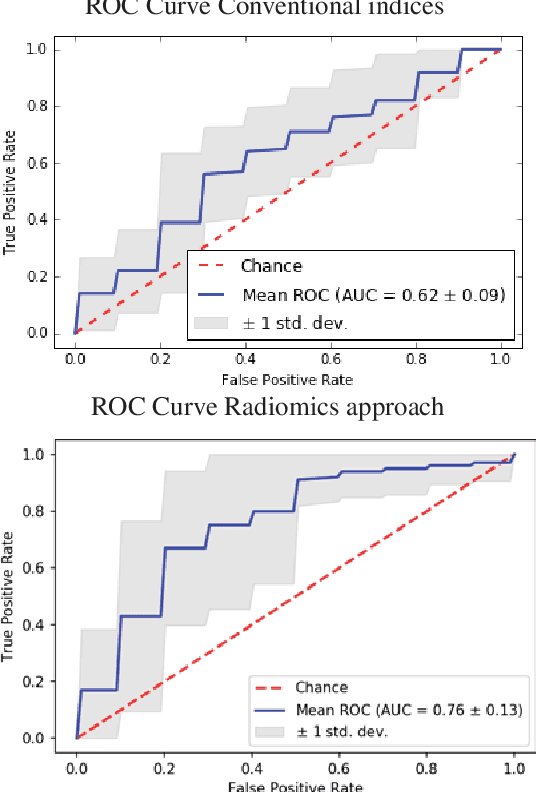
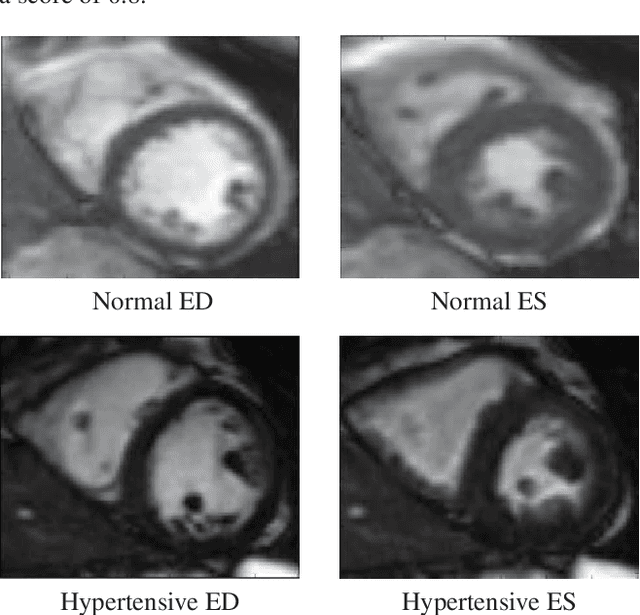
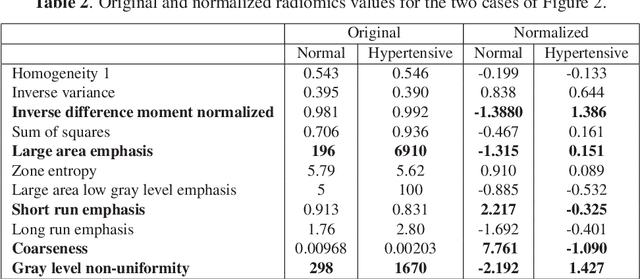
Hypertension is a medical condition that is well-established as a risk factor for many major diseases. For example, it can cause alterations in the cardiac structure and function over time that can lead to heart related morbidity and mortality. However, at the subclinical stage, these changes are subtle and cannot be easily captured using conventional cardiovascular indices calculated from clinical cardiac imaging. In this paper, we describe a radiomics approach for identifying intermediate imaging phenotypes associated with hypertension. The method combines feature selection and machine learning techniques to identify the most subtle as well as complex structural and tissue changes in hypertensive subgroups as compared to healthy individuals. Validation based on a sample of asymptomatic hearts that include both hypertensive and non-hypertensive cases demonstrate that the proposed radiomics model is capable of detecting intensity and textural changes well beyond the capabilities of conventional imaging phenotypes, indicating its potential for improved understanding of the longitudinal effects of hypertension on cardiovascular health and disease.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 21, 2020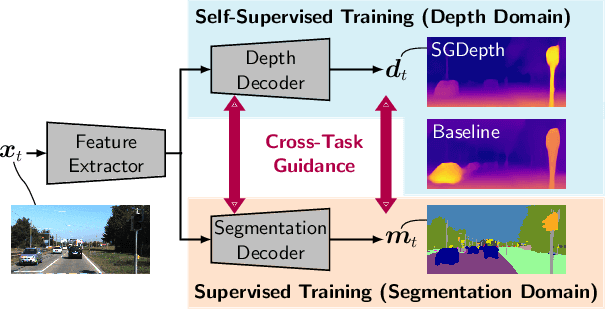
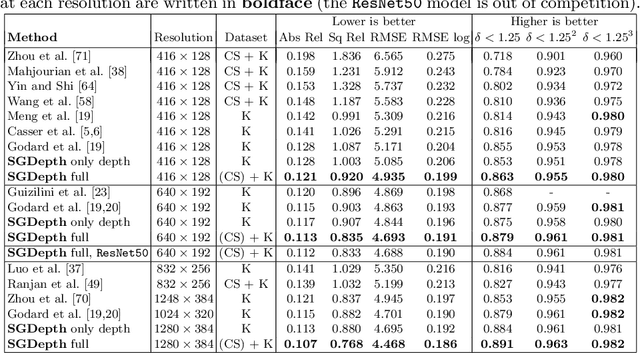
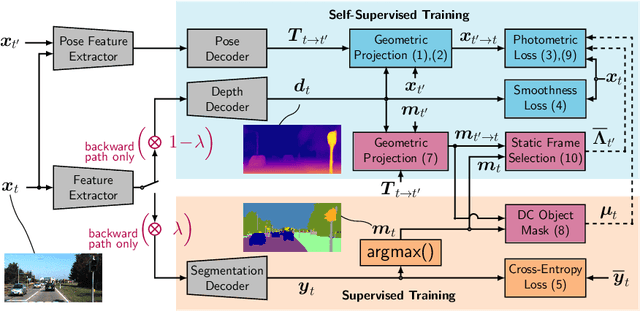
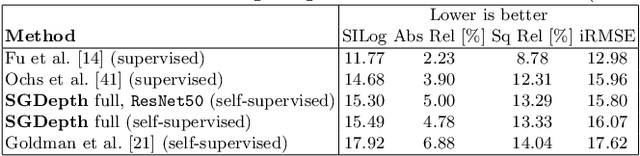
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement.
P2ExNet: Patch-based Prototype Explanation Network
May 05, 2020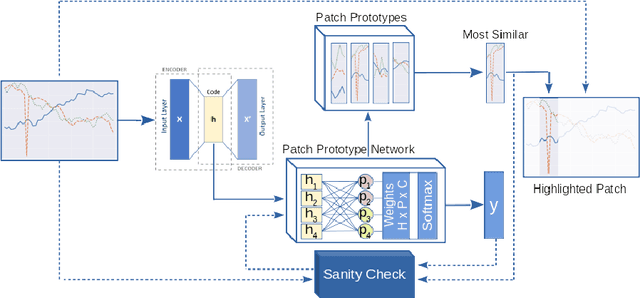
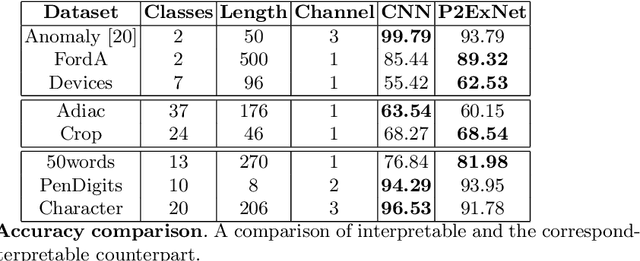

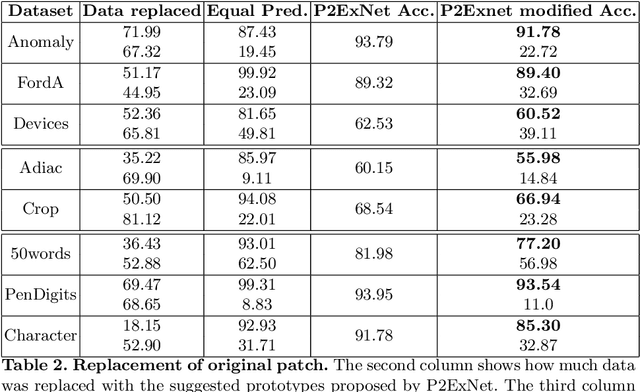
Deep learning methods have shown great success in several domains as they process a large amount of data efficiently, capable of solving complex classification, forecast, segmentation, and other tasks. However, they come with the inherent drawback of inexplicability limiting their applicability and trustworthiness. Although there exists work addressing this perspective, most of the existing approaches are limited to the image modality due to the intuitive and prominent concepts. Conversely, the concepts in the time-series domain are more complex and non-comprehensive but these and an explanation for the network decision are pivotal in critical domains like medical, financial, or industry. Addressing the need for an explainable approach, we propose a novel interpretable network scheme, designed to inherently use an explainable reasoning process inspired by the human cognition without the need of additional post-hoc explainability methods. Therefore, class-specific patches are used as they cover local concepts relevant to the classification to reveal similarities with samples of the same class. In addition, we introduce a novel loss concerning interpretability and accuracy that constraints P2ExNet to provide viable explanations of the data including relevant patches, their position, class similarities, and comparison methods without compromising accuracy. Analysis of the results on eight publicly available time-series datasets reveals that P2ExNet reaches comparable performance when compared to its counterparts while inherently providing understandable and traceable decisions.
A Novel Ramp Metering Approach Based on Machine Learning and Historical Data
May 26, 2020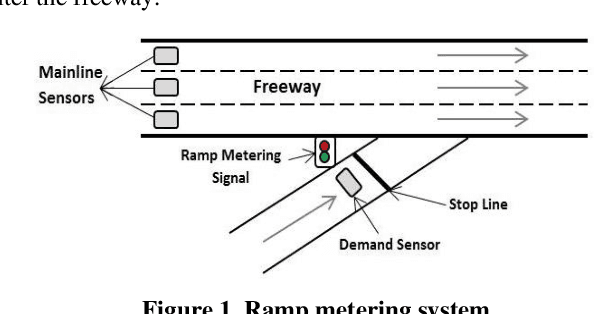

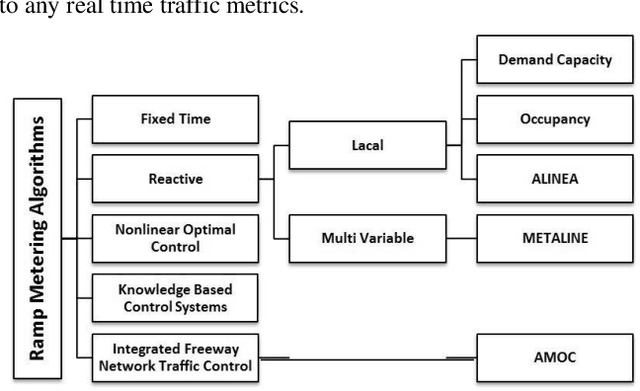
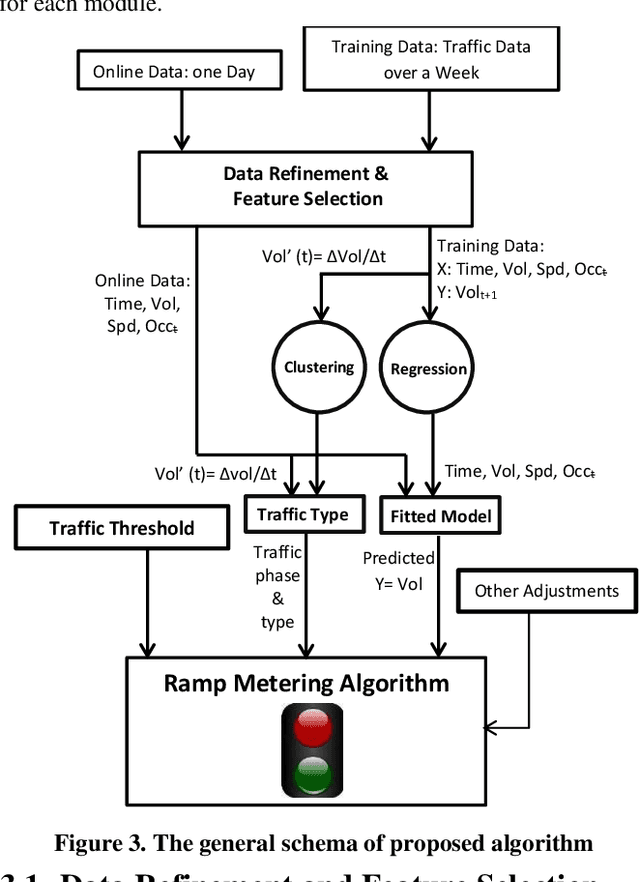
The random nature of traffic conditions on freeways can cause excessive congestions and irregularities in the traffic flow. Ramp metering is a proven effective method to maintain freeway efficiency under various traffic conditions. Creating a reliable and practical ramp metering algorithm that considers both critical traffic measures and historical data is still a challenging problem. In this study we use machine learning approaches to develop a novel real-time prediction model for ramp metering. We evaluate the potentials of our approach in providing promising results by comparing it with a baseline traffic-responsive ramp metering algorithm.