 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Trainable Self-Attentive Shallow Network for Text-Independent Speaker Verification
Aug 14, 2020
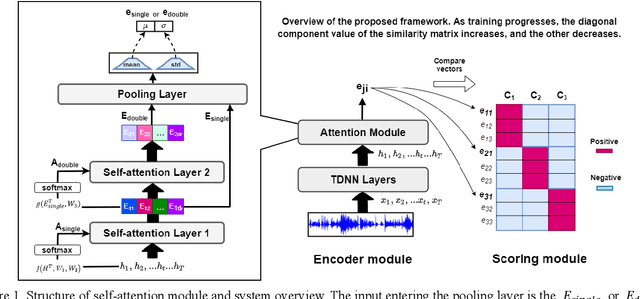

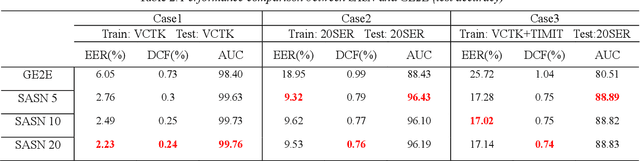
Generalized end-to-end (GE2E) model is widely used in speaker verification (SV) fields due to its expandability and generality regardless of specific languages. However, the long-short term memory (LSTM) based on GE2E has two limitations: First, the embedding of GE2E suffers from vanishing gradient, which leads to performance degradation for very long input sequences. Secondly, utterances are not represented as a properly fixed dimensional vector. In this paper, to overcome issues mentioned above, we propose a novel framework for SV, end-to-end trainable self-attentive shallow network (SASN), incorporating a time-delay neural network (TDNN) and a self-attentive pooling mechanism based on the self-attentive x-vector system during an utterance embedding phase. We demonstrate that the proposed model is highly efficient, and provides more accurate speaker verification than GE2E. For VCTK dataset, with just less than half the size of GE2E, the proposed model showed significant performance improvement over GE2E of about 63%, 67%, and 85% in EER (Equal error rate), DCF (Detection cost function), and AUC (Area under the curve), respectively. Notably, when the input length becomes longer, the DCF score improvement of the proposed model is about 17 times greater than that of GE2E.
Single Image Dehazing Algorithm Based on Sky Region Segmentation
Jul 10, 2020
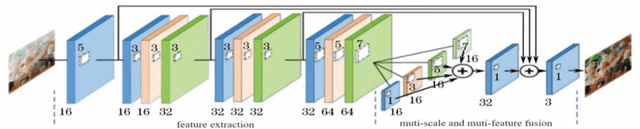
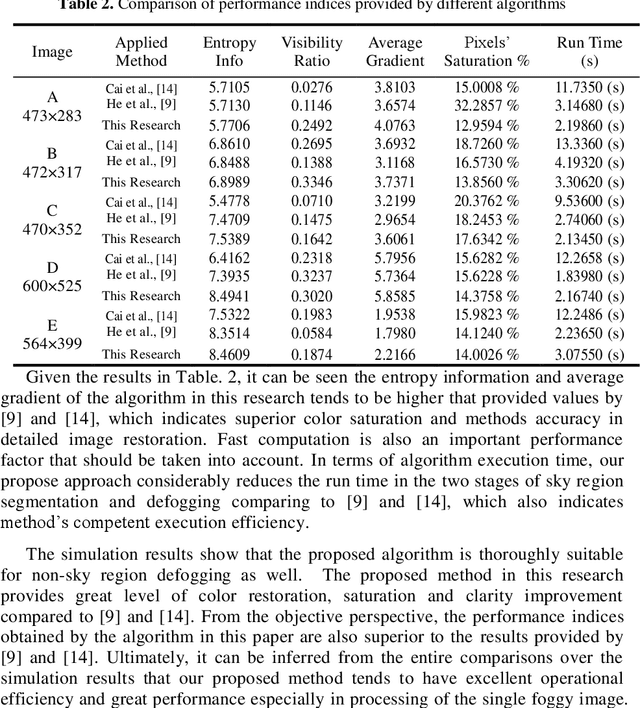
In this paper a hybrid image defogging approach based on region segmentation is proposed to address the dark channel priori algorithm's shortcomings in de-fogging the sky regions. The preliminary stage of the proposed approach focuses on the segmentation of sky and non-sky regions in a foggy image taking the advantageous of Meanshift and edge detection with embedded confidence. In the second stage, an improved dark channel priori algorithm is employed to defog the non-sky region. Ultimately, the sky area is processed by DehazeNet algorithm, which relies on deep learning Convolutional Neural Networks. The simulation results show that the proposed hybrid approach in this research addresses the problem of color distortion associated with sky regions in foggy images. The approach greatly improves the image quality indices including entropy information, visibility ratio of the edges, average gradient, and the saturation percentage with a very fast computation time, which is a good indication of the excellent performance of this model.
Deep image prior for 3D magnetic particle imaging: A quantitative comparison of regularization techniques on Open MPI dataset
Jul 03, 2020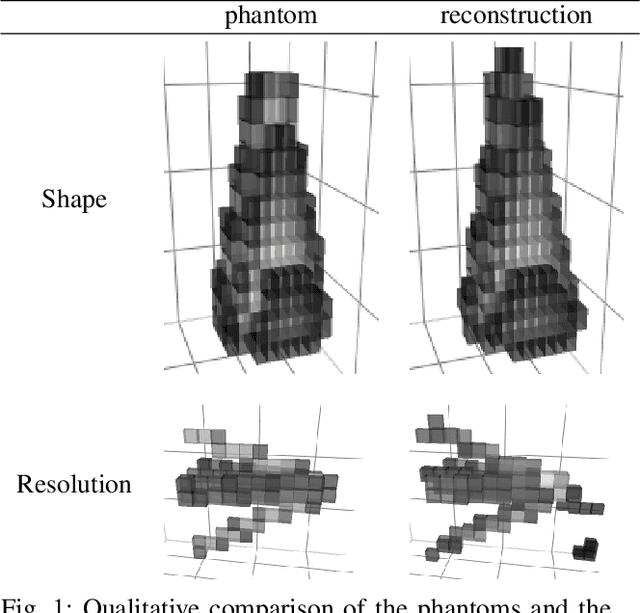
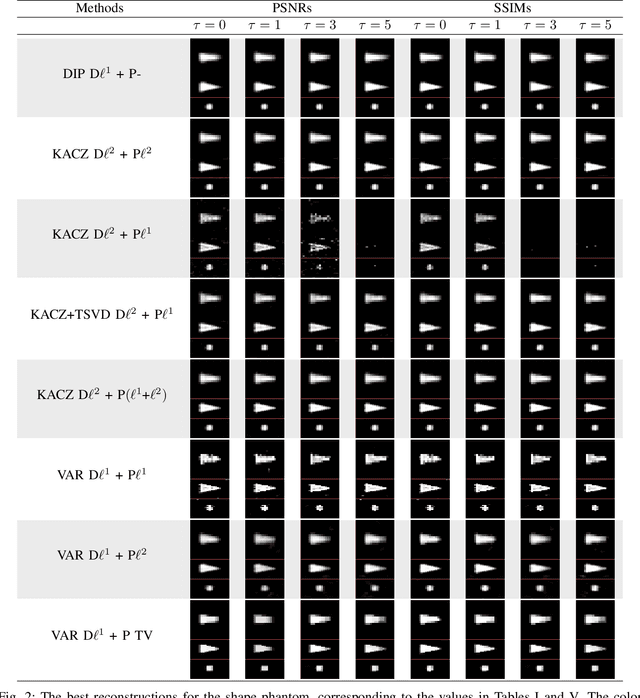
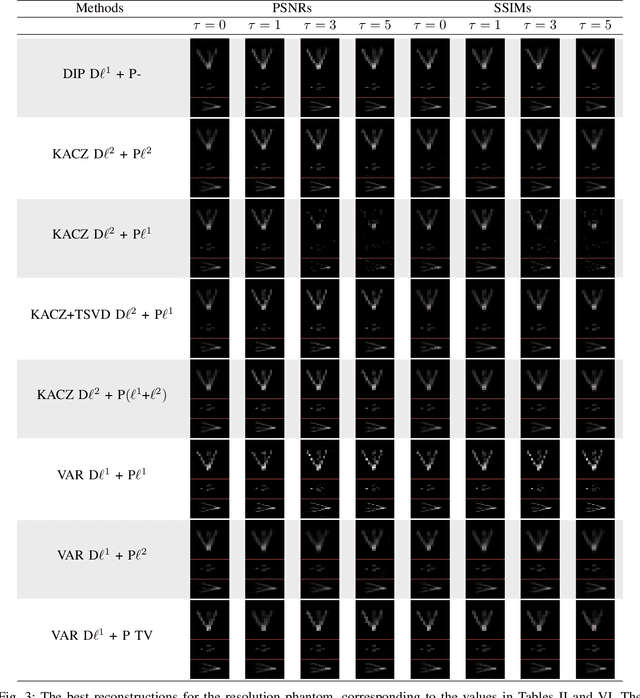
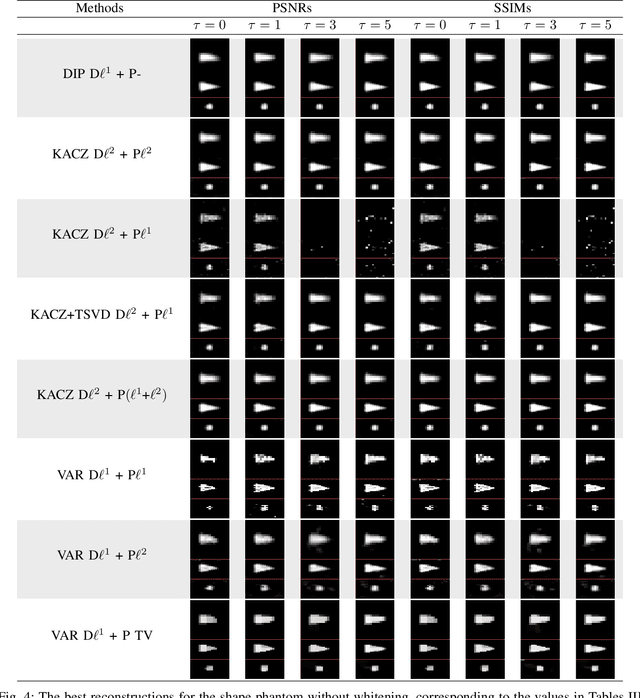
Magnetic particle imaging (MPI) is an imaging modality exploiting the nonlinear magnetization behavior of (super-)paramagnetic nanoparticles to obtain a space- and often also time-dependent concentration of a tracer consisting of these nanoparticles. MPI has a continuously increasing number of potential medical applications. One prerequisite for successful performance in these applications is a proper solution to the image reconstruction problem. More classical methods from inverse problems theory, as well as novel approaches from the field of machine learning, have the potential to deliver high-quality reconstructions in MPI. We investigate a novel reconstruction approach based on a deep image prior, which builds on representing the solution by a deep neural network. Novel approaches, as well as variational and iterative regularization techniques, are compared quantitatively in terms of peak signal-to-noise ratios and structural similarity indices on the publicly available Open MPI dataset.
Revisiting One-vs-All Classifiers for Predictive Uncertainty and Out-of-Distribution Detection in Neural Networks
Jul 10, 2020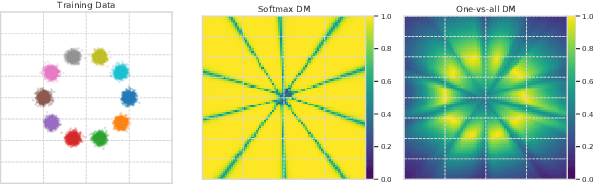
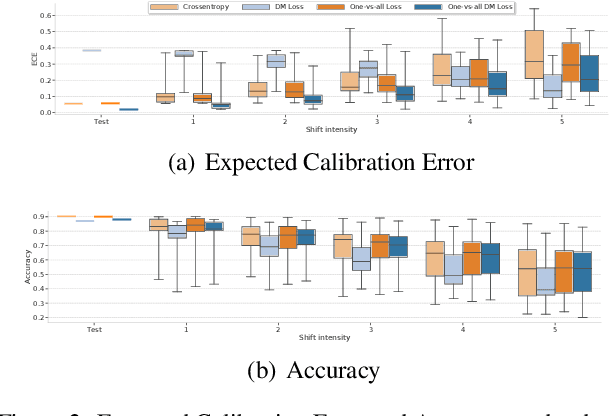
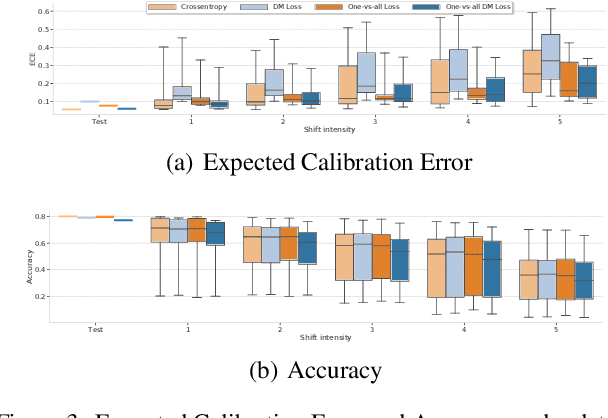
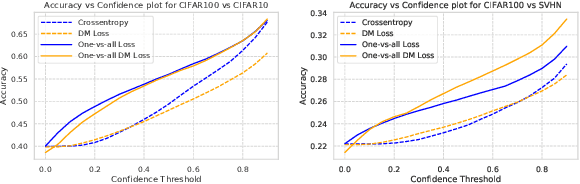
Accurate estimation of predictive uncertainty in modern neural networks is critical to achieve well calibrated predictions and detect out-of-distribution (OOD) inputs. The most promising approaches have been predominantly focused on improving model uncertainty (e.g. deep ensembles and Bayesian neural networks) and post-processing techniques for OOD detection (e.g. ODIN and Mahalanobis distance). However, there has been relatively little investigation into how the parametrization of the probabilities in discriminative classifiers affects the uncertainty estimates, and the dominant method, softmax cross-entropy, results in misleadingly high confidences on OOD data and under covariate shift. We investigate alternative ways of formulating probabilities using (1) a one-vs-all formulation to capture the notion of "none of the above", and (2) a distance-based logit representation to encode uncertainty as a function of distance to the training manifold. We show that one-vs-all formulations can improve calibration on image classification tasks, while matching the predictive performance of softmax without incurring any additional training or test-time complexity.
A Novel Twitter Sentiment Analysis Model with Baseline Correlation for Financial Market Prediction with Improved Efficiency
Mar 18, 2020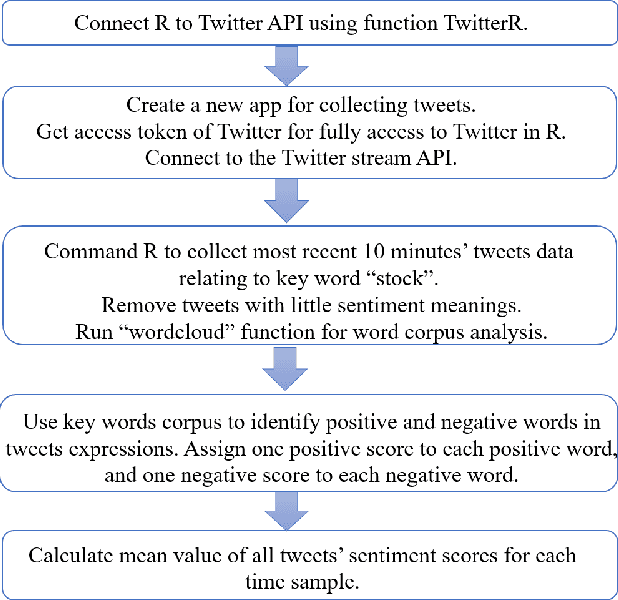
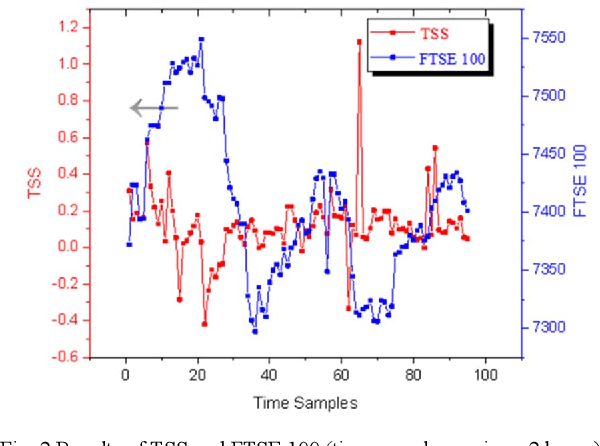
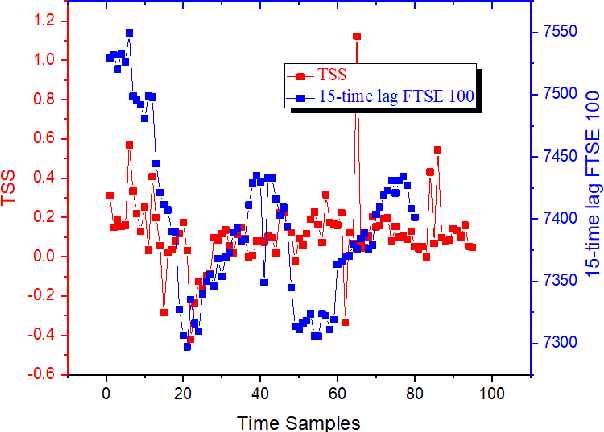
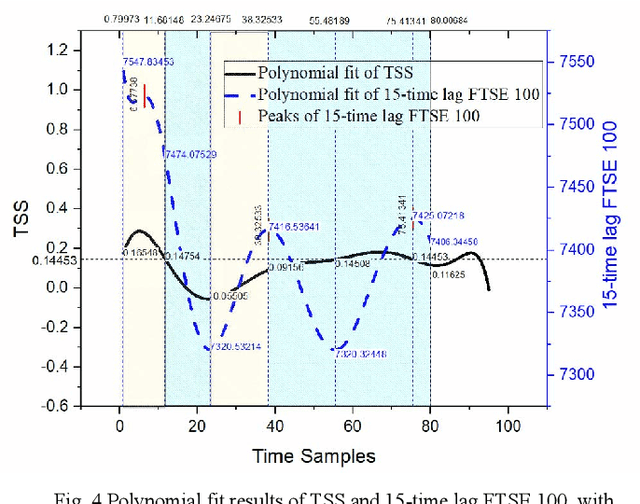
A novel social networks sentiment analysis model is proposed based on Twitter sentiment score (TSS) for real-time prediction of the future stock market price FTSE 100, as compared with conventional econometric models of investor sentiment based on closed-end fund discount (CEFD). The proposed TSS model features a new baseline correlation approach, which not only exhibits a decent prediction accuracy, but also reduces the computation burden and enables a fast decision making without the knowledge of historical data. Polynomial regression, classification modelling and lexicon-based sentiment analysis are performed using R. The obtained TSS predicts the future stock market trend in advance by 15 time samples (30 working hours) with an accuracy of 67.22% using the proposed baseline criterion without referring to historical TSS or market data. Specifically, TSS's prediction performance of an upward market is found far better than that of a downward market. Under the logistic regression and linear discriminant analysis, the accuracy of TSS in predicting the upward trend of the future market achieves 97.87%.
* 2019 Sixth IEEE International Conference on Social Networks Analysis, Management and Security (SNAMS)
PC-PG: Policy Cover Directed Exploration for Provable Policy Gradient Learning
Aug 13, 2020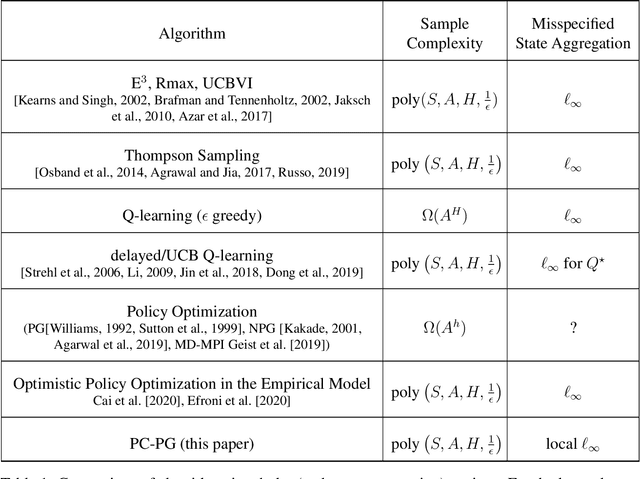
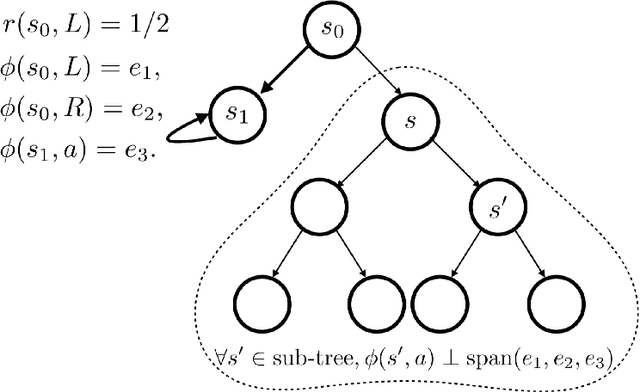
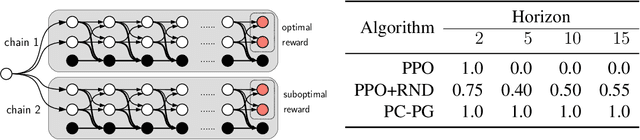
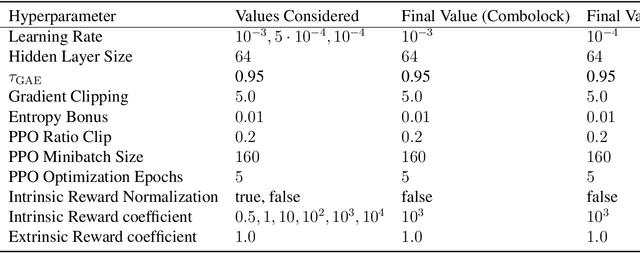
Direct policy gradient methods for reinforcement learning are a successful approach for a variety of reasons: they are model free, they directly optimize the performance metric of interest, and they allow for richly parameterized policies. Their primary drawback is that, by being local in nature, they fail to adequately explore the environment. In contrast, while model-based approaches and Q-learning directly handle exploration through the use of optimism, their ability to handle model misspecification and function approximation is far less evident. This work introduces the the Policy Cover-Policy Gradient (PC-PG) algorithm, which provably balances the exploration vs. exploitation tradeoff using an ensemble of learned policies (the policy cover). PC-PG enjoys polynomial sample complexity and run time for both tabular MDPs and, more generally, linear MDPs in an infinite dimensional RKHS. Furthermore, PC-PG also has strong guarantees under model misspecification that go beyond the standard worst case $\ell_{\infty}$ assumptions; this includes approximation guarantees for state aggregation under an average case error assumption, along with guarantees under a more general assumption where the approximation error under distribution shift is controlled. We complement the theory with empirical evaluation across a variety of domains in both reward-free and reward-driven settings.
Learning to Prune in Training via Dynamic Channel Propagation
Jul 03, 2020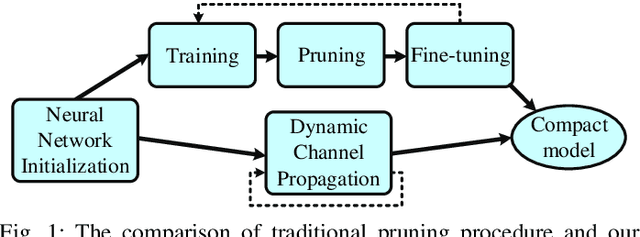
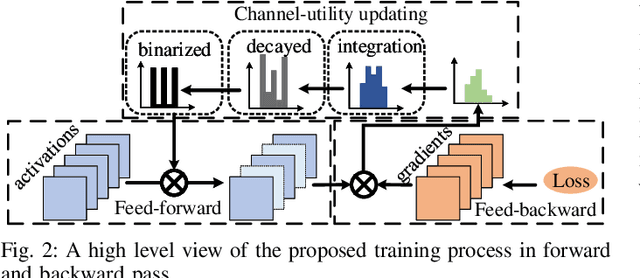
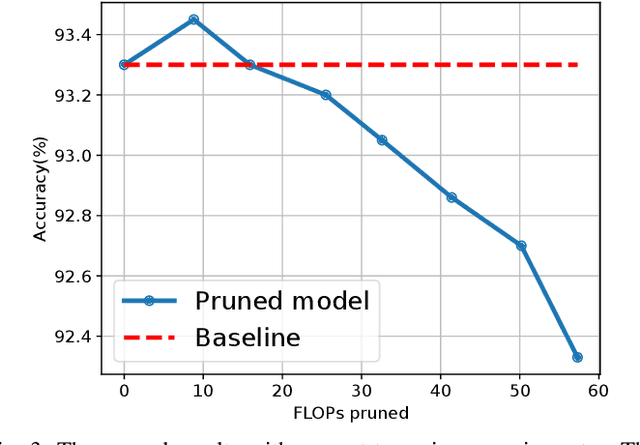
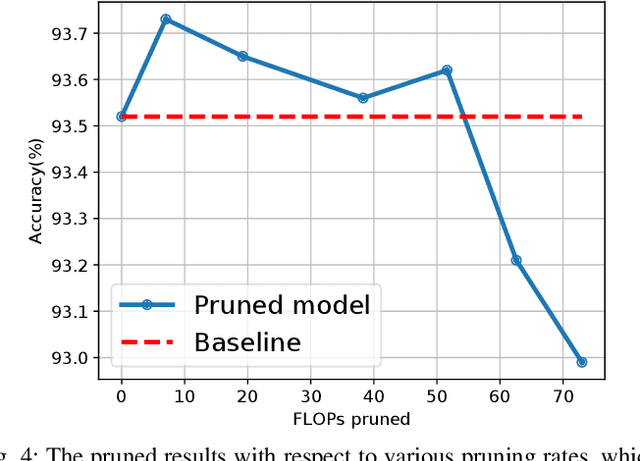
In this paper, we propose a novel network training mechanism called "dynamic channel propagation" to prune the neural networks during the training period. In particular, we pick up a specific group of channels in each convolutional layer to participate in the forward propagation in training time according to the significance level of channel, which is defined as channel utility. The utility values with respect to all selected channels are updated simultaneously with the error back-propagation process and will adaptively change. Furthermore, when the training ends, channels with high utility values are retained whereas those with low utility values are discarded. Hence, our proposed scheme trains and prunes neural networks simultaneously. We empirically evaluate our novel training scheme on various representative benchmark datasets and advanced convolutional neural network (CNN) architectures, including VGGNet and ResNet. The experiment results verify the superior performance and robust effectiveness of our approach.
DCANet: Learning Connected Attentions for Convolutional Neural Networks
Jul 09, 2020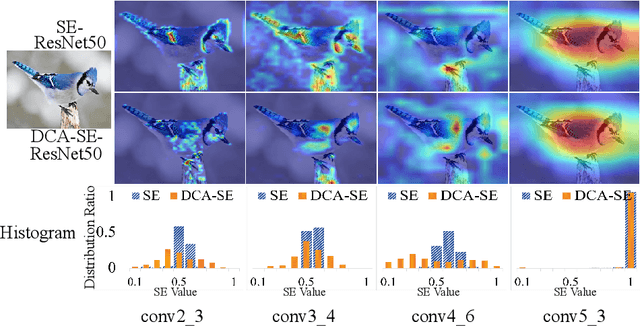
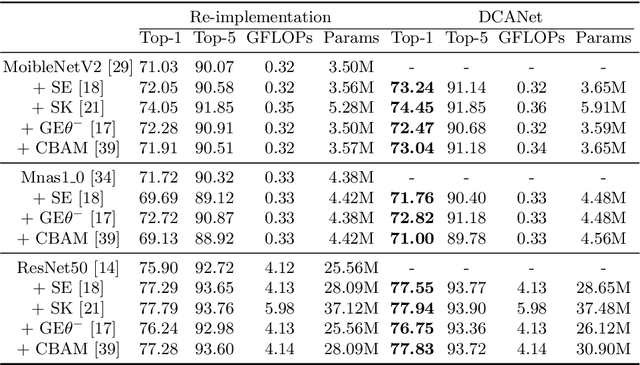
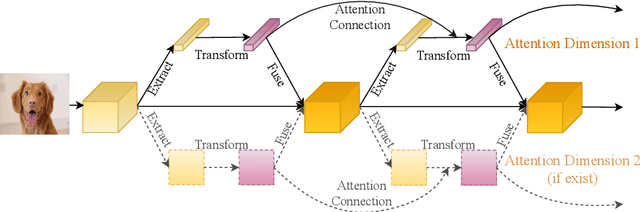
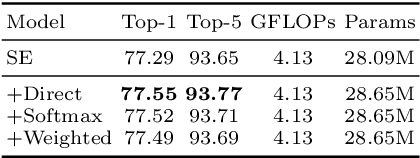
While self-attention mechanism has shown promising results for many vision tasks, it only considers the current features at a time. We show that such a manner cannot take full advantage of the attention mechanism. In this paper, we present Deep Connected Attention Network (DCANet), a novel design that boosts attention modules in a CNN model without any modification of the internal structure. To achieve this, we interconnect adjacent attention blocks, making information flow among attention blocks possible. With DCANet, all attention blocks in a CNN model are trained jointly, which improves the ability of attention learning. Our DCANet is generic. It is not limited to a specific attention module or base network architecture. Experimental results on ImageNet and MS COCO benchmarks show that DCANet consistently outperforms the state-of-the-art attention modules with a minimal additional computational overhead in all test cases. All code and models are made publicly available.
Activation Density driven Energy-Efficient Pruning in Training
Feb 07, 2020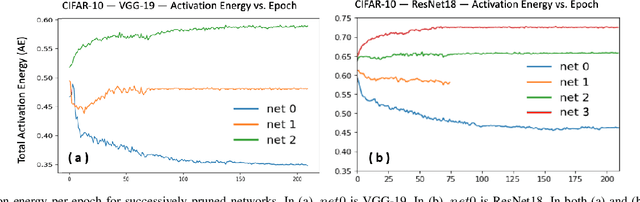
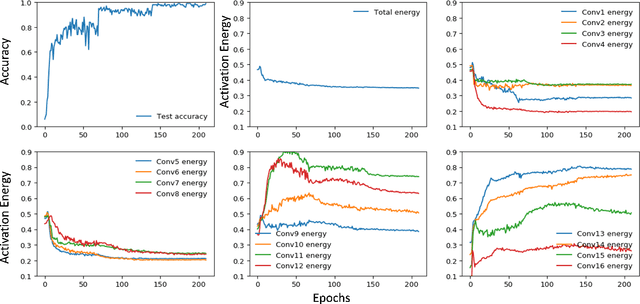
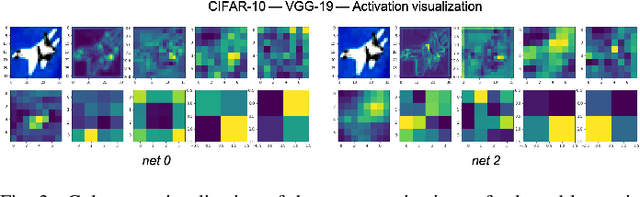
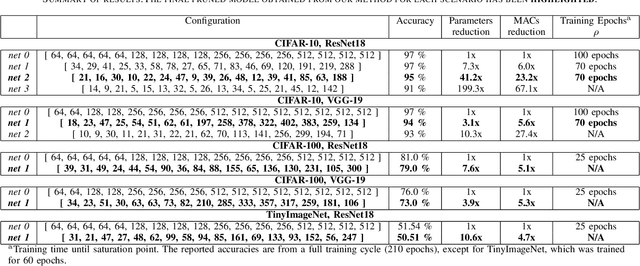
The process of neural network pruning with suitable fine-tuning and retraining can yield networks with considerably fewer parameters than the original with comparable degrees of accuracy. Typically, pruning methods require large, pre-trained networks as a starting point from which they perform a time-intensive iterative pruning and retraining algorithm. We propose a novel pruning in-training method that prunes a network real-time during training, reducing the overall training time to achieve an optimal compressed network. To do so, we introduce an activation density based analysis that identifies the optimal relative sizing or compression for each layer of the network. Our method removes the need for pre-training and is architecture agnostic, allowing it to be employed on a wide variety of systems. For VGG-19 and ResNet18 on CIFAR-10, CIFAR-100, and TinyImageNet, we obtain exceedingly sparse networks (up to 200x reduction in parameters and >60x reduction in inference compute operations in the best case) with comparable accuracies (up to 2%-3% loss with respect to the baseline network). By reducing the network size periodically during training, we achieve total training times that are shorter than those of previously proposed pruning methods. Furthermore, training compressed networks at different epochs with our proposed method yields considerable reduction in training compute complexity (1.6x -3.2x lower) at near iso-accuracy as compared to a baseline network trained entirely from scratch.
Task-agnostic Temporally Consistent Facial Video Editing
Jul 03, 2020
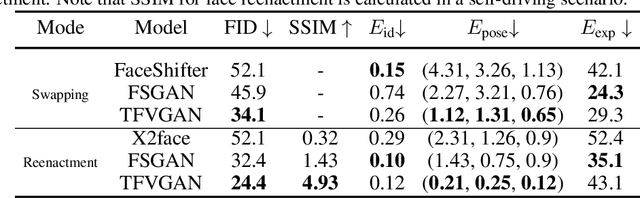
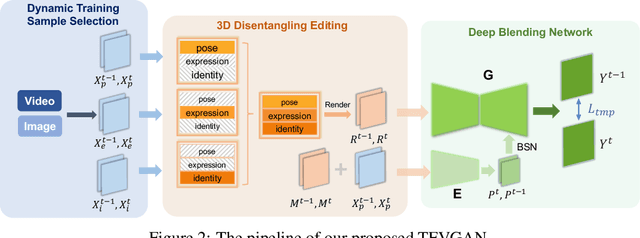
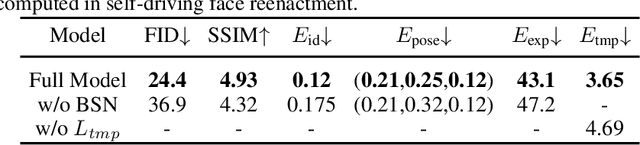
Recent research has witnessed the advances in facial image editing tasks. For video editing, however, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In addition, these methods are confined to dealing with one specific task at a time without any extensibility. In this paper, we propose a task-agnostic temporally consistent facial video editing framework. Based on a 3D reconstruction model, our framework is designed to handle several editing tasks in a more unified and disentangled manner. The core design includes a dynamic training sample selection mechanism and a novel 3D temporal loss constraint that fully exploits both image and video datasets and enforces temporal consistency. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.