 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Interpretable Deep Learning System for Automatically Scoring Request for Proposals
Aug 05, 2020
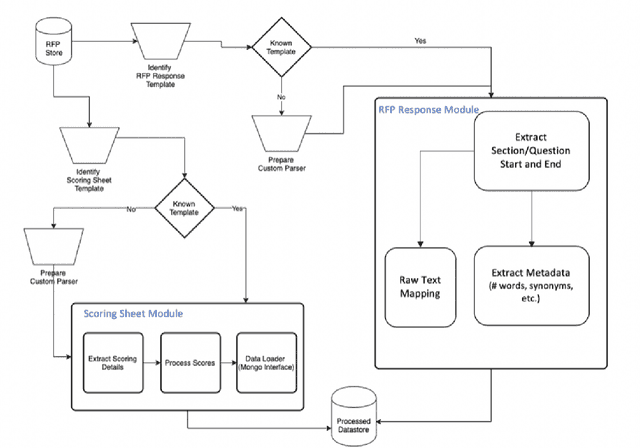



The Managed Care system within Medicaid (US Healthcare) uses Request For Proposals (RFP) to award contracts for various healthcare and related services. RFP responses are very detailed documents (hundreds of pages) submitted by competing organisations to win contracts. Subject matter expertise and domain knowledge play an important role in preparing RFP responses along with analysis of historical submissions. Automated analysis of these responses through Natural Language Processing (NLP) systems can reduce time and effort needed to explore historical responses, and assisting in writing better responses. Our work draws parallels between scoring RFPs and essay scoring models, while highlighting new challenges and the need for interpretability. Typical scoring models focus on word level impacts to grade essays and other short write-ups. We propose a novel Bi-LSTM based regression model, and provide deeper insight into phrases which latently impact scoring of responses. We contend the merits of our proposed methodology using extensive quantitative experiments. We also qualitatively asses the impact of important phrases using human evaluators. Finally, we introduce a novel problem statement that can be used to further improve the state of the art in NLP based automatic scoring systems.
Multi Agent Path Finding with Awareness for Spatially Extended Agents
Sep 20, 2020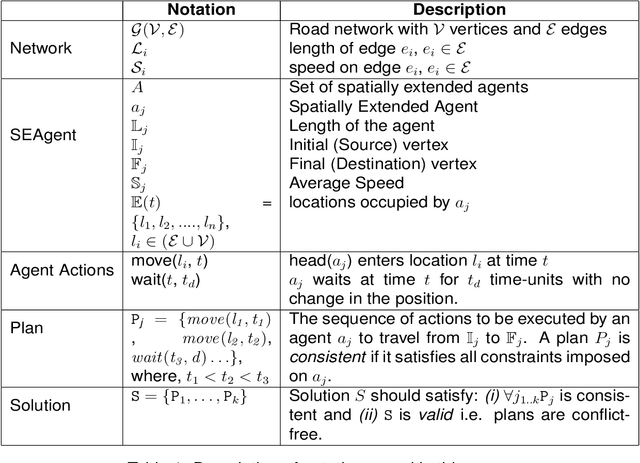
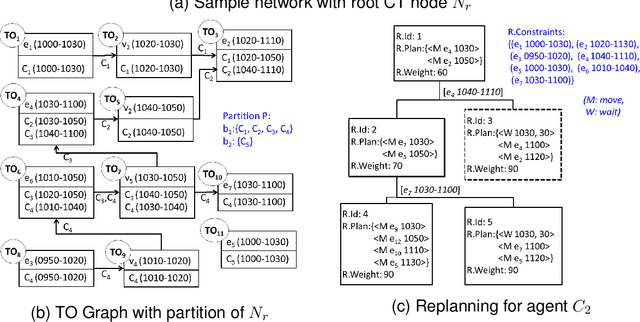
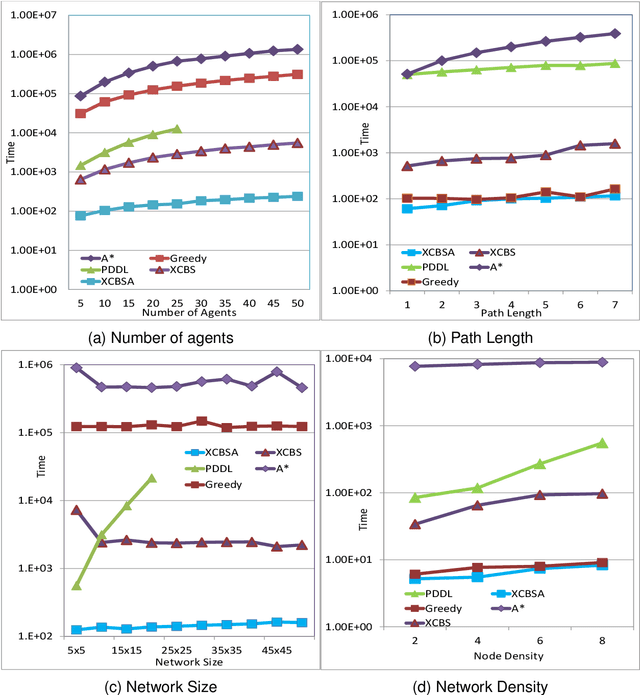
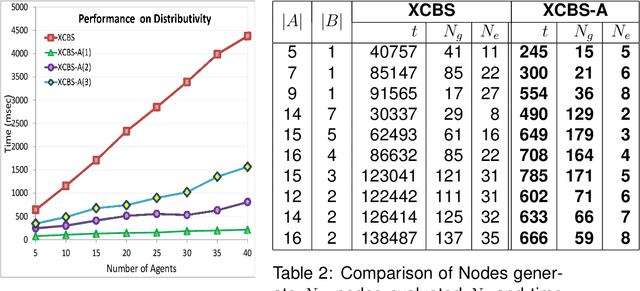
Path finding problems involve identification of a plan for conflict free movement of agents over a common road network. Most approaches to this problem handle the agents as point objects, wherein the size of the agent is significantly smaller than the road on which it travels. In this paper, we consider spatially extended agents which have a size comparable to the length of the road on which they travel. An optimal multi agent path finding approach for spatially-extended agents was proposed in the eXtended Conflict Based Search (XCBS) algorithm. As XCBS resolves only a pair of conflicts at a time, it results in deeper search trees in case of cascading or multiple (more than two agent) conflicts at a given location. This issue is addressed in eXtended Conflict Based Search with Awareness (XCBS-A) in which an agent uses awareness of other agents' plans to make its own plan. In this paper, we explore XCBS-A in greater detail, we theoretically prove its completeness and empirically demonstrate its performance with other algorithms in terms of variances in road characteristics, agent characteristics and plan characteristics. We demonstrate the distributive nature of the algorithm by evaluating its performance when distributed over multiple machines. XCBS-A generates a huge search space impacting its efficiency in terms of memory; to address this we propose an approach for memory-efficiency and empirically demonstrate the performance of the algorithm. The nature of XCBS-A is such that it may lead to suboptimal solutions, hence the final contribution of this paper is an enhanced approach, XCBS-Local Awareness (XCBS-LA) which we prove will be optimal and complete.
SMPLpix: Neural Avatars from 3D Human Models
Aug 16, 2020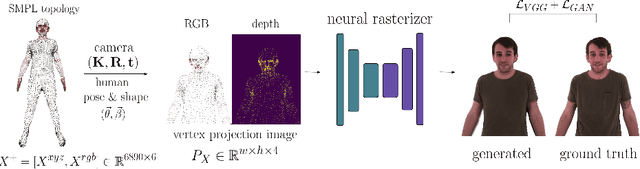
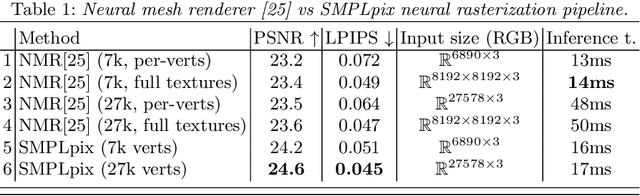


Recent advances in deep generative models have led to an unprecedented level of realism for synthetically generated images of humans. However, one of the remaining fundamental limitations of these models is the ability to flexibly control the generative process, e.g. change the camera and human pose while retaining the subject identity. At the same time, deformable human body models like SMPL and its successors provide full control over pose and shape, but rely on classic computer graphics pipelines for rendering. Such rendering pipelines require explicit mesh rasterization that (a) does not have the potential to fix artifacts or lack of realism in the original 3D geometry and (b) until recently, were not fully incorporated into deep learning frameworks. In this work, we propose to bridge the gap between classic geometry-based rendering and the latest generative networks operating in pixel space by introducing a neural rasterizer, a trainable neural network module that directly "renders" a sparse set of 3D mesh vertices as photorealistic images, avoiding any hardwired logic in pixel colouring and occlusion reasoning. We train our model on a large corpus of human 3D models and corresponding real photos, and show the advantage over conventional differentiable renderers both in terms of the level of photorealism and rendering efficiency.
Uncertainty Quantification for Inferring Hawkes Networks
Jun 12, 2020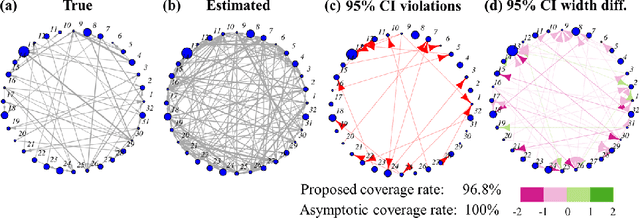
Multivariate Hawkes processes are commonly used to model streaming networked event data in a wide variety of applications. However, it remains a challenge to extract reliable inference from complex datasets with uncertainty quantification. Aiming towards this, we develop a statistical inference framework to learn causal relationships between nodes from networked data, where the underlying directed graph implies Granger causality. We provide uncertainty quantification for the maximum likelihood estimate of the network multivariate Hawkes process by providing a non-asymptotic confidence set. The main technique is based on the concentration inequalities of continuous-time martingales. We compare our method to the previously-derived asymptotic Hawkes process confidence interval, and demonstrate the strengths of our method in an application to neuronal connectivity reconstruction.
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-ray Segmentation
Sep 27, 2020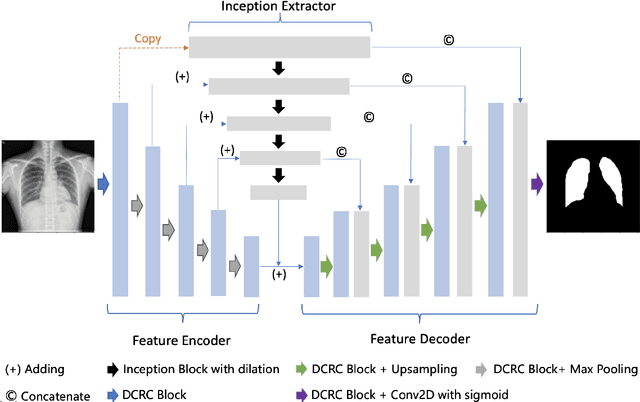
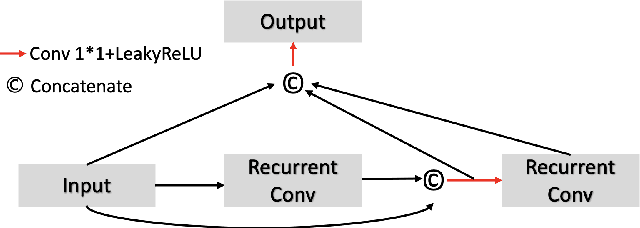
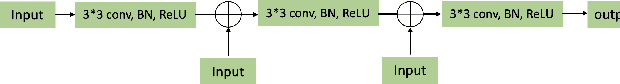

A number of methods based on the deep learning have been applied to medical image segmentation and have achieved state-of-the-art performance. Due to the importance of chest x-ray data in studying COVID-19, there is a demand for state-of-the-art models capable of precisely segmenting soft tissue on the chest x-rays before obtaining mask annotations about this sort of dataset. The dataset for exploring best pre-trained model is from Montgomery and Shenzhen hospital which had opened in 2014. The most famous technique is U-Net which has been used to many medical datasets including the Chest X-ray. However, most variant U-Nets mainly focus on extraction of contextual information and skip connection. There is still a large space for improving extraction of spatial features. In this paper, we propose a dual encoder fusion U-Net framework for Chest X-rays based on Inception Convolutional Neural Network with dilation, Densely Connected Recurrent Convolutional Neural Network, which is named DEFU-Net. The densely connected recurrent path extends the network deeper for facilitating context feature extraction. In order to increase the width of network and enrich representation of features, the inception blocks with dilation have been used. The inception blocks can capture globally and locally spatial information by various receptive fields. At the same time, the two paths are fused by summing features, thus preserving context and the spatial information for decoding part. This multi-learning-scale model is benefiting in Chest X-ray dataset from two different manufacturers (Montgomery and Shenzhen hospital). The DEFU-Net achieves the better performance than basic U-Net, residual U-Net, BCDU-Net, modified R2U-Net and modified attention R2U-Net. This model has proved the feasibility for mixed dataset. The open source code for this proposed framework will be public soon.
A Time and Space Efficient Junction Tree Architecture
Dec 23, 2014The junction tree algorithm is a way of computing marginals of boolean multivariate probability distributions that factorise over sets of random variables. The junction tree algorithm first constructs a tree called a junction tree who's vertices are sets of random variables. The algorithm then performs a generalised version of belief propagation on the junction tree. The Shafer-Shenoy and Hugin architectures are two ways to perform this belief propagation that tradeoff time and space complexities in different ways: Hugin propagation is at least as fast as Shafer-Shenoy propagation and in the cases that we have large vertices of high degree is significantly faster. However, this speed increase comes at the cost of an increased space complexity. This paper first introduces a simple novel architecture, ARCH-1, which has the best of both worlds: the speed of Hugin propagation and the low space requirements of Shafer-Shenoy propagation. A more complicated novel architecture, ARCH-2, is then introduced which has, up to a factor only linear in the maximum cardinality of any vertex, time and space complexities at least as good as ARCH-1 and in the cases that we have large vertices of high degree is significantly faster than ARCH-1.
Towards Accurate Predictions and Causal 'What-if' Analyses for Planning and Policy-making: A Case Study in Emergency Medical Services Demand
Apr 25, 2020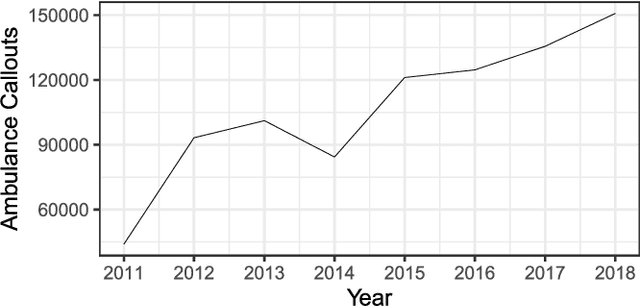
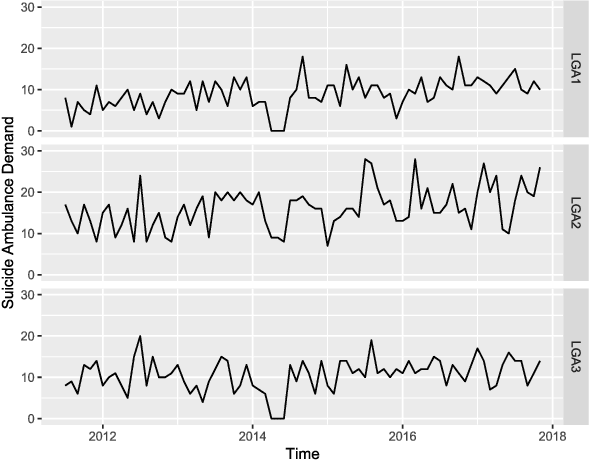

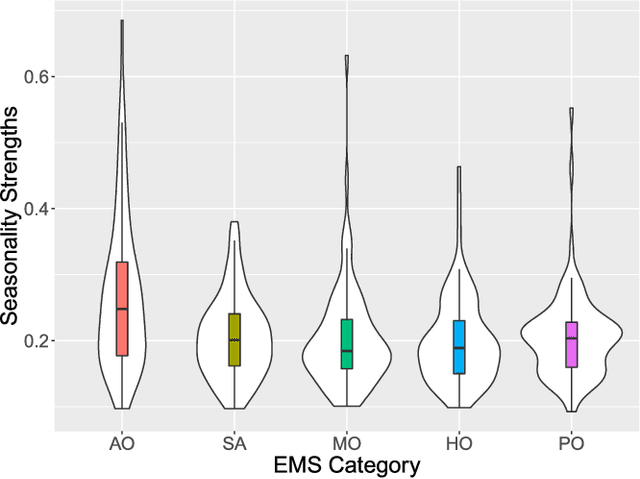
Emergency Medical Services (EMS) demand load has become a considerable burden for many government authorities, and EMS demand is often an early indicator for stress in communities, a warning sign of emerging problems. In this paper, we introduce Deep Planning and Policy Making Net (DeepPPMNet), a Long Short-Term Memory network based, global forecasting and inference framework to forecast the EMS demand, analyse causal relationships, and perform `what-if' analyses for policy-making across multiple local government areas. Unless traditional univariate forecasting techniques, the proposed method follows the global forecasting methodology, where a model is trained across all the available EMS demand time series to exploit the potential cross-series information available. DeepPPMNet also uses seasonal decomposition techniques, incorporated in two different training paradigms into the framework, to suit various characteristics of the EMS related time series data. We then explore causal relationships using the notion of Granger Causality, where the global forecasting framework enables us to perform `what-if' analyses that could be used for the national policy-making process. We empirically evaluate our method, using a set of EMS datasets related to alcohol, drug use and self-harm in Australia. The proposed framework is able to outperform many state-of-the-art techniques and achieve competitive results in terms of forecasting accuracy. We finally illustrate its use for policy-making in an example regarding alcohol outlet licenses.
Improved Estimation in Time Varying Models
Jun 27, 2012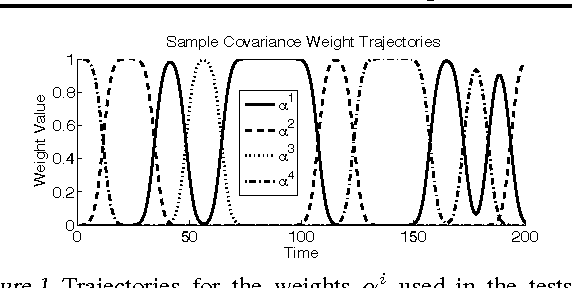
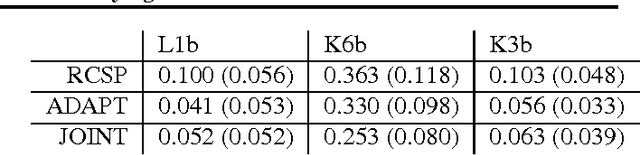

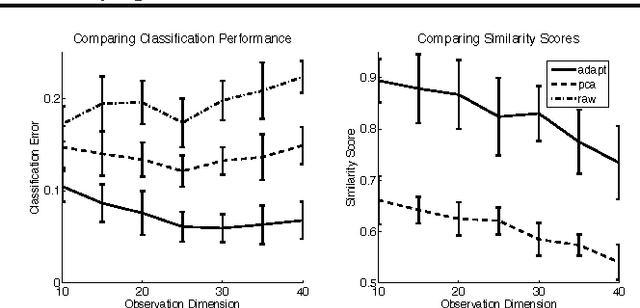
Locally adapted parameterizations of a model (such as locally weighted regression) are expressive but often suffer from high variance. We describe an approach for reducing the variance, based on the idea of estimating simultaneously a transformed space for the model, as well as locally adapted parameterizations in this new space. We present a new problem formulation that captures this idea and illustrate it in the important context of time varying models. We develop an algorithm for learning a set of bases for approximating a time varying sparse network; each learned basis constitutes an archetypal sparse network structure. We also provide an extension for learning task-driven bases. We present empirical results on synthetic data sets, as well as on a BCI EEG classification task.
Eye Gaze Controlled Robotic Arm for Persons with SSMI
May 25, 2020
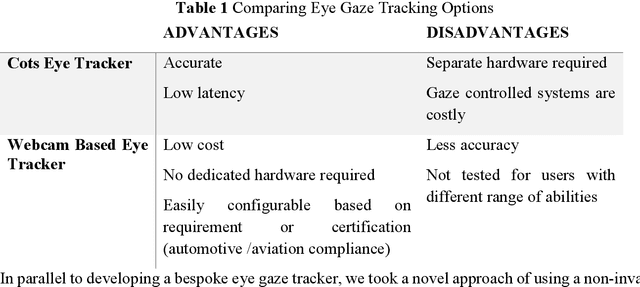
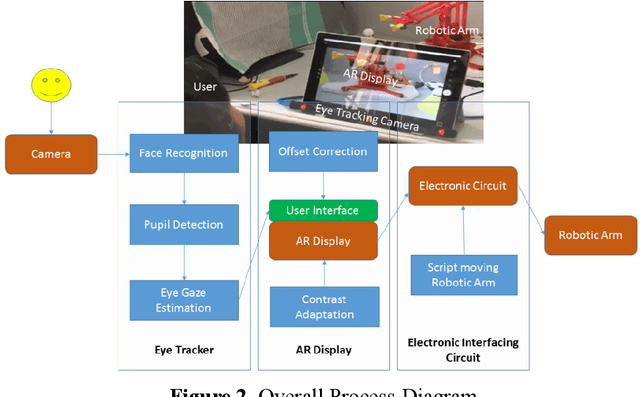
Background: People with severe speech and motor impairment (SSMI) often uses a technique called eye pointing to communicate with outside world. One of their parents, caretakers or teachers hold a printed board in front of them and by analyzing their eye gaze manually, their intentions are interpreted. This technique is often error prone and time consuming and depends on a single caretaker. Objective: We aimed to automate the eye tracking process electronically by using commercially available tablet, computer or laptop and without requiring any dedicated hardware for eye gaze tracking. The eye gaze tracker is used to develop a video see through based AR (augmented reality) display that controls a robotic device with eye gaze and deployed for a fabric printing task. Methodology: We undertook a user centred design process and separately evaluated the web cam based gaze tracker and the video see through based human robot interaction involving users with SSMI. We also reported a user study on manipulating a robotic arm with webcam based eye gaze tracker. Results: Using our bespoke eye gaze controlled interface, able bodied users can select one of nine regions of screen at a median of less than 2 secs and users with SSMI can do so at a median of 4 secs. Using the eye gaze controlled human-robot AR display, users with SSMI could undertake representative pick and drop task at an average duration less than 15 secs and reach a randomly designated target within 60 secs using a COTS eye tracker and at an average time of 2 mins using the webcam based eye gaze tracker.
Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops
Aug 05, 2020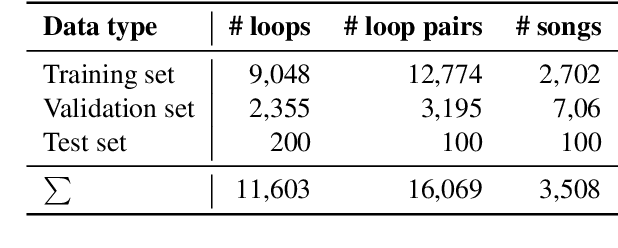
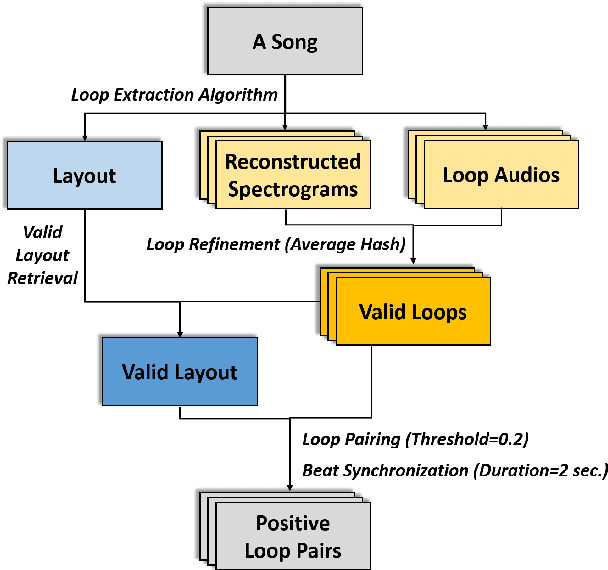
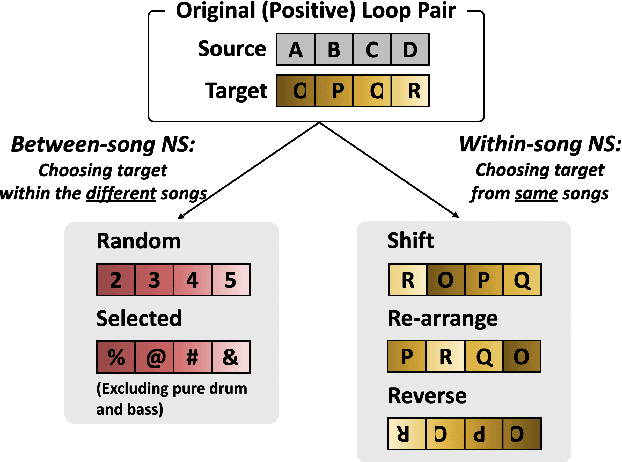
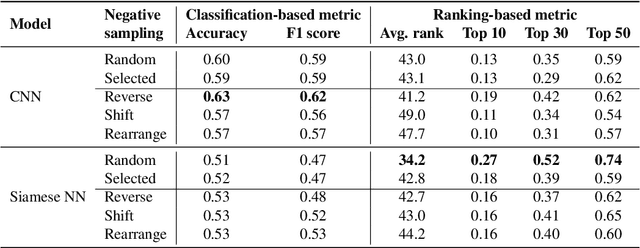
Music producers who use loops may have access to thousands in loop libraries, but finding ones that are compatible is a time-consuming process; we hope to reduce this burden with automation. State-of-the-art systems for estimating compatibility, such as AutoMashUpper, are mostly rule-based and could be improved on with machine learning. To train a model, we need a large set of loops with ground truth compatibility values. No such dataset exists, so we extract loops from existing music to obtain positive examples of compatible loops, and propose and compare various strategies for choosing negative examples. For reproducibility, we curate data from the Free Music Archive. Using this data, we investigate two types of model architectures for estimating the compatibility of loops: one based on a Siamese network, and the other a pure convolutional neural network (CNN). We conducted a user study in which participants rated the quality of the combinations suggested by each model, and found the CNN to outperform the Siamese network. Both model-based approaches outperformed the rule-based one. We have opened source the code for building the models and the dataset.