 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intelligent Residential Energy Management System using Deep Reinforcement Learning
May 28, 2020
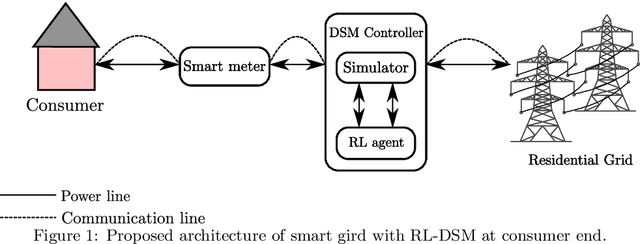
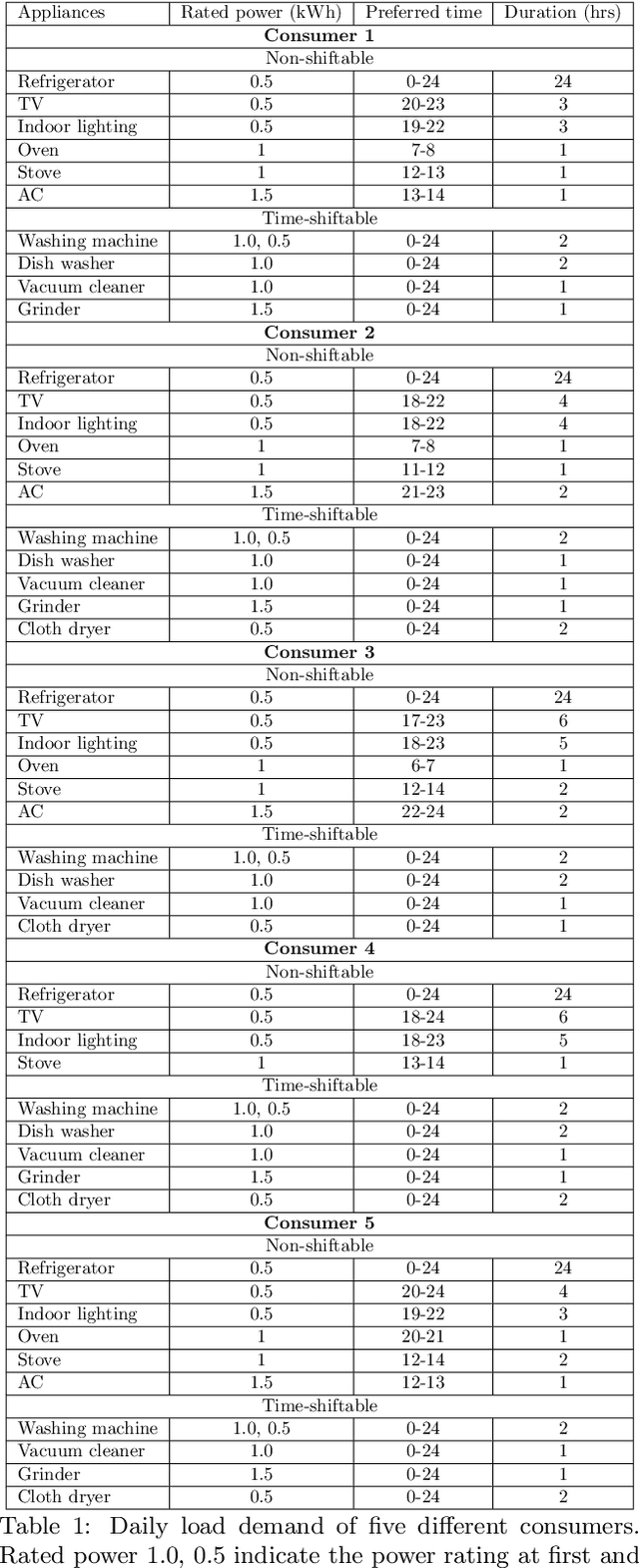
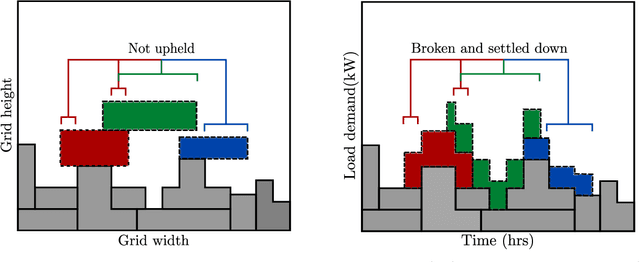
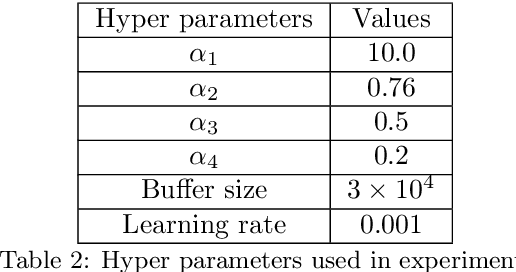
The rising demand for electricity and its essential nature in today's world calls for intelligent home energy management (HEM) systems that can reduce energy usage. This involves scheduling of loads from peak hours of the day when energy consumption is at its highest to leaner off-peak periods of the day when energy consumption is relatively lower thereby reducing the system's peak load demand, which would consequently result in lesser energy bills, and improved load demand profile. This work introduces a novel way to develop a learning system that can learn from experience to shift loads from one time instance to another and achieve the goal of minimizing the aggregate peak load. This paper proposes a Deep Reinforcement Learning (DRL) model for demand response where the virtual agent learns the task like humans do. The agent gets feedback for every action it takes in the environment; these feedbacks will drive the agent to learn about the environment and take much smarter steps later in its learning stages. Our method outperformed the state of the art mixed integer linear programming (MILP) for load peak reduction. The authors have also designed an agent to learn to minimize both consumers' electricity bills and utilities' system peak load demand simultaneously. The proposed model was analyzed with loads from five different residential consumers; the proposed method increases the monthly savings of each consumer by reducing their electricity bill drastically along with minimizing the peak load on the system when time shiftable loads are handled by the proposed method.
A Robot that Counts Like a Child -- a Developmental Model of Counting and Pointing
Aug 05, 2020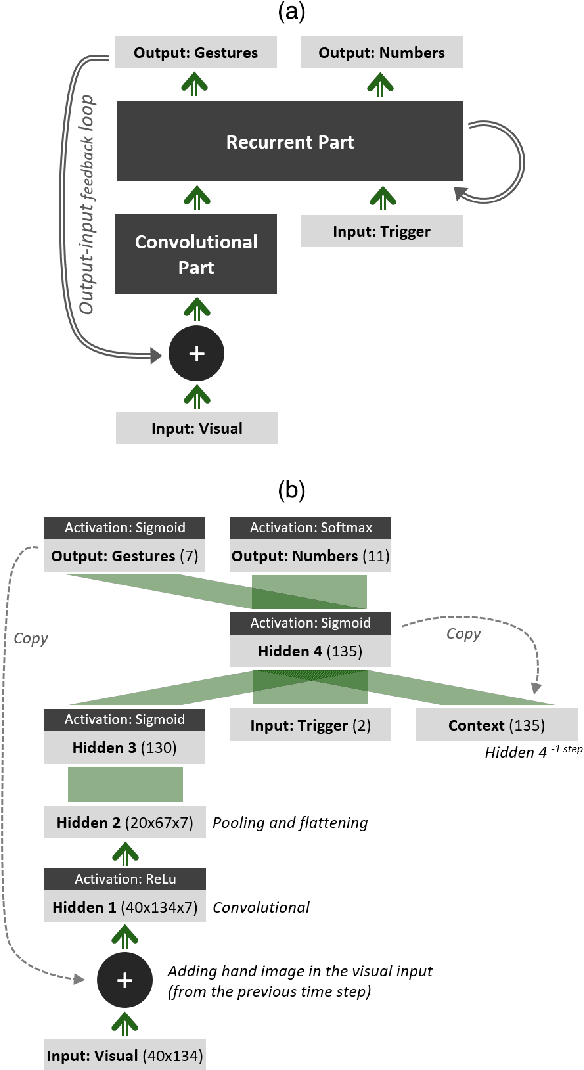
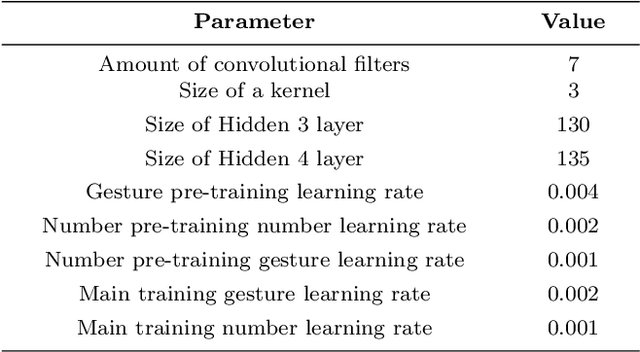

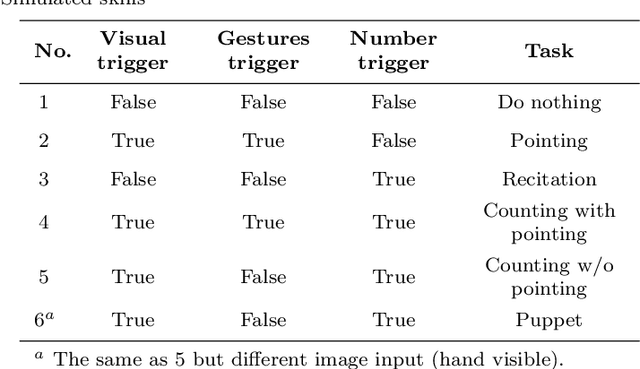
In this paper, a novel neuro-robotics model capable of counting real items is introduced. The model allows us to investigate the interaction between embodiment and numerical cognition. This is composed of a deep neural network capable of image processing and sequential tasks performance, and a robotic platform providing the embodiment - the iCub humanoid robot. The network is trained using images from the robot's cameras and proprioceptive signals from its joints. The trained model is able to count a set of items and at the same time points to them. We investigate the influence of pointing on the counting process and compare our results with those from studies with children. Several training approaches are presented in this paper all of them uses pre-training routine allowing the network to gain the ability of pointing and number recitation (from 1 to 10) prior to counting training. The impact of the counted set size and distance to the objects are investigated. The obtained results on counting performance show similarities with those from human studies.
RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning
Sep 15, 2020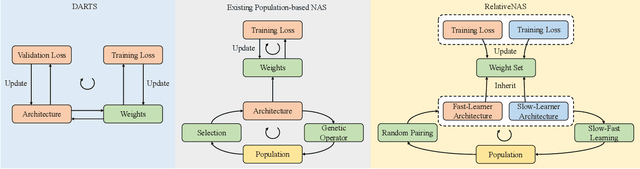
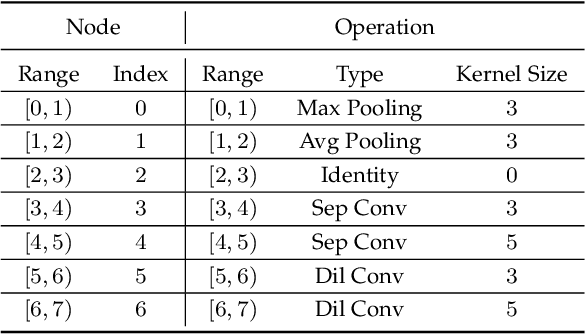
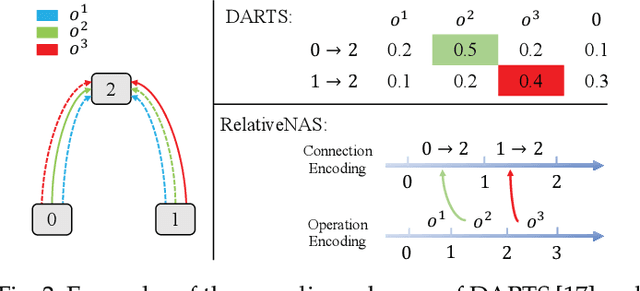
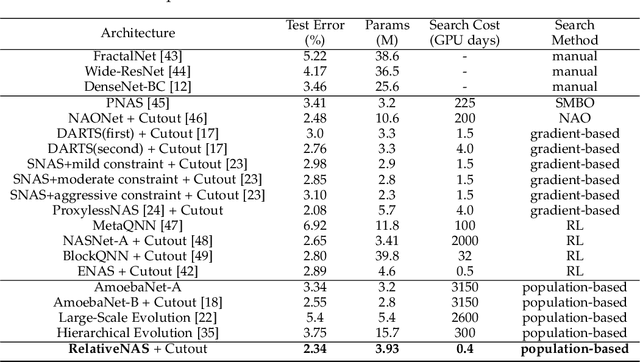
Despite the remarkable successes of Convolutional Neural Networks (CNNs) in computer vision, it is time-consuming and error-prone to manually design a CNN. Among various Neural Architecture Search (NAS) methods that are motivated to automate designs of high-performance CNNs, the differentiable NAS and population-based NAS are attracting increasing interests due to their unique characters. To benefit from the merits while overcoming the deficiencies of both, this work proposes a novel NAS method, RelativeNAS. As the key to efficient search, RelativeNAS performs joint learning between fast-learners (i.e. networks with relatively higher accuracy) and slow-learners in a pairwise manner. Moreover, since RelativeNAS only requires low-fidelity performance estimation to distinguish each pair of fast-learner and slow-learner, it saves certain computation costs for training the candidate architectures. The proposed RelativeNAS brings several unique advantages: (1) it achieves state-of-the-art performance on ImageNet with top-1 error rate of 24.88%, i.e. outperforming DARTS and AmoebaNet-B by 1.82% and 1.12% respectively; (2) it spends only nine hours with a single 1080Ti GPU to obtain the discovered cells, i.e. 3.75x and 7875x faster than DARTS and AmoebaNet respectively; (3) it provides that the discovered cells obtained on CIFAR-10 can be directly transferred to object detection, semantic segmentation, and keypoint detection, yielding competitive results of 73.1% mAP on PASCAL VOC, 78.7% mIoU on Cityscapes, and 68.5% AP on MSCOCO, respectively. The implementation of RelativeNAS is available at https://github.com/EMI-Group/RelativeNAS
Adiabatic Quantum Linear Regression
Aug 05, 2020
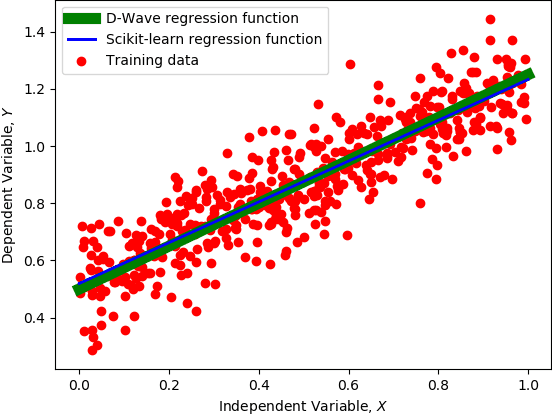
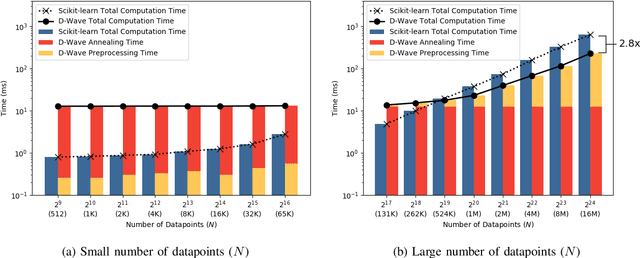
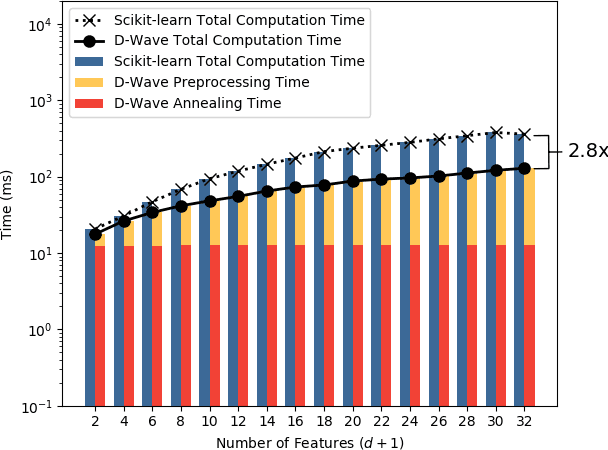
A major challenge in machine learning is the computational expense of training these models. Model training can be viewed as a form of optimization used to fit a machine learning model to a set of data, which can take up significant amount of time on classical computers. Adiabatic quantum computers have been shown to excel at solving optimization problems, and therefore, we believe, present a promising alternative to improve machine learning training times. In this paper, we present an adiabatic quantum computing approach for training a linear regression model. In order to do this, we formulate the regression problem as a quadratic unconstrained binary optimization (QUBO) problem. We analyze our quantum approach theoretically, test it on the D-Wave 2000Q adiabatic quantum computer and compare its performance to a classical approach that uses the Scikit-learn library in Python. Our analysis shows that the quantum approach attains up to 2.8x speedup over the classical approach on larger datasets, and performs at par with the classical approach on the regression error metric.
Tera-SLASH: A Distributed Energy-Efficient MPI based LSH System for Tera-Scale Similarity Search
Aug 05, 2020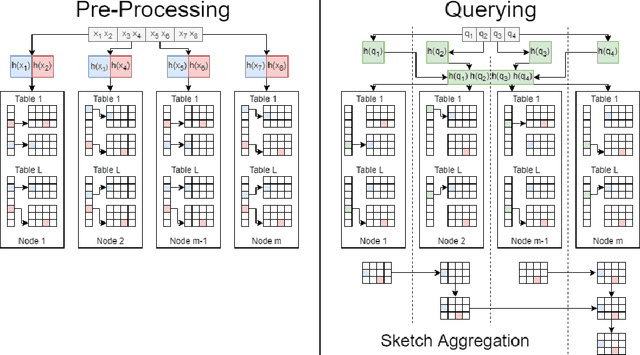

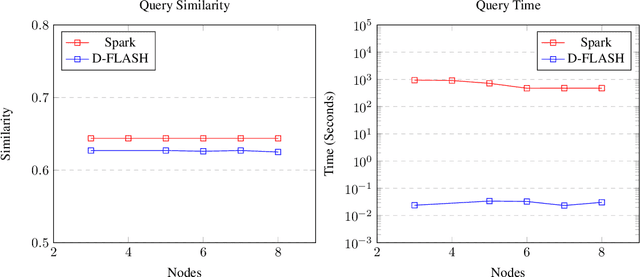
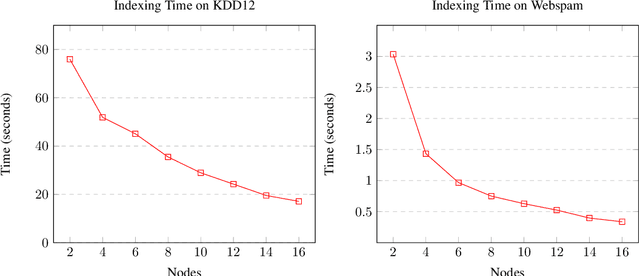
We present Tera-SLASH, an MPI (Message Passing Interface) based distributed system for approximate similarity search over tera-scale datasets. SLASH provides a multi-node implementation of the popular LSH (locality sensitive hashing) algorithm, which is generally implemented on a single machine. We offer a novel design and sketching solution to reduce the inter-machine communication overheads exponentially. In a direct comparison on comparable hardware, SLASH is more than 10000x faster than the popular LSH package in PySpark. PySpark is a widely-adopted distributed implementation of the LSH algorithm for large datasets and is deployed in commercial platforms. In the end, we show how our system scale to Tera-scale Criteo dataset with more than 4 billion samples. SLASH can index this 2.3 terabyte data over 20 nodes (on a shared cluster at Rice) in under an hour, with a query time in a fraction of milliseconds. To the best of our knowledge, there is no open-source system that can index and perform a similarity search on Criteo with a commodity cluster.
Contextualized Translation of Automatically Segmented Speech
Aug 05, 2020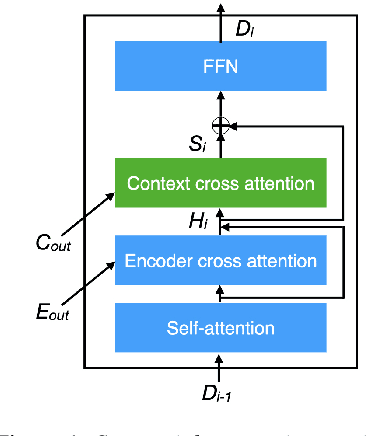
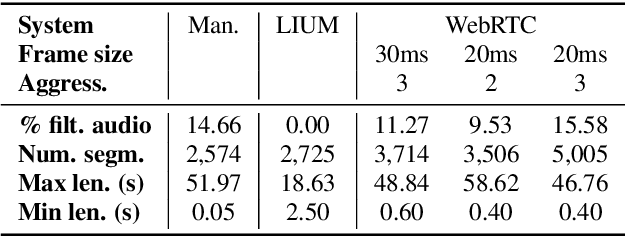
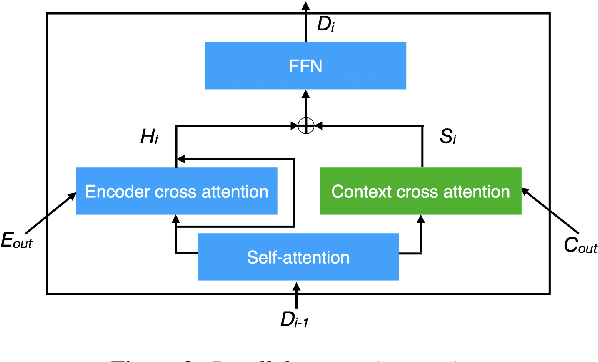
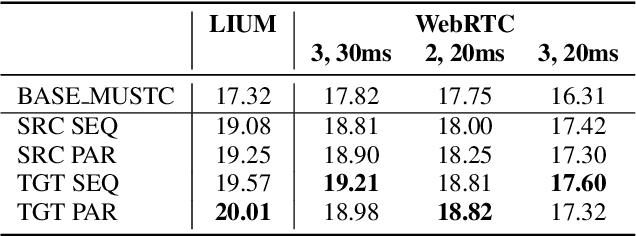
Direct speech-to-text translation (ST) models are usually trained on corpora segmented at sentence level, but at inference time they are commonly fed with audio split by a voice activity detector (VAD). Since VAD segmentation is not syntax-informed, the resulting segments do not necessarily correspond to well-formed sentences uttered by the speaker but, most likely, to fragments of one or more sentences. This segmentation mismatch degrades considerably the quality of ST models' output. So far, researchers have focused on improving audio segmentation towards producing sentence-like splits. In this paper, instead, we address the issue in the model, making it more robust to a different, potentially sub-optimal segmentation. To this aim, we train our models on randomly segmented data and compare two approaches: fine-tuning and adding the previous segment as context. We show that our context-aware solution is more robust to VAD-segmented input, outperforming a strong base model and the fine-tuning on different VAD segmentations of an English-German test set by up to 4.25 BLEU points.
Adaptive model selection in photonic reservoir computing by reinforcement learning
Apr 27, 2020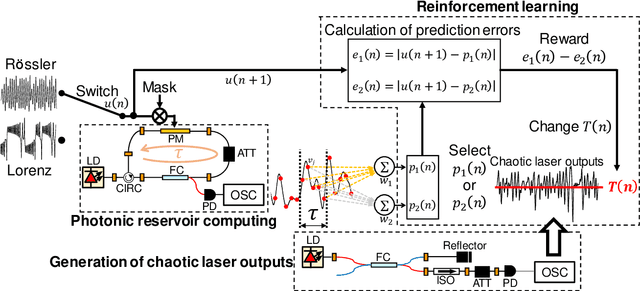
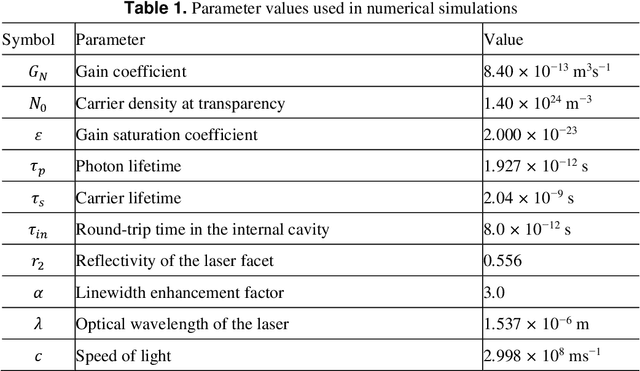
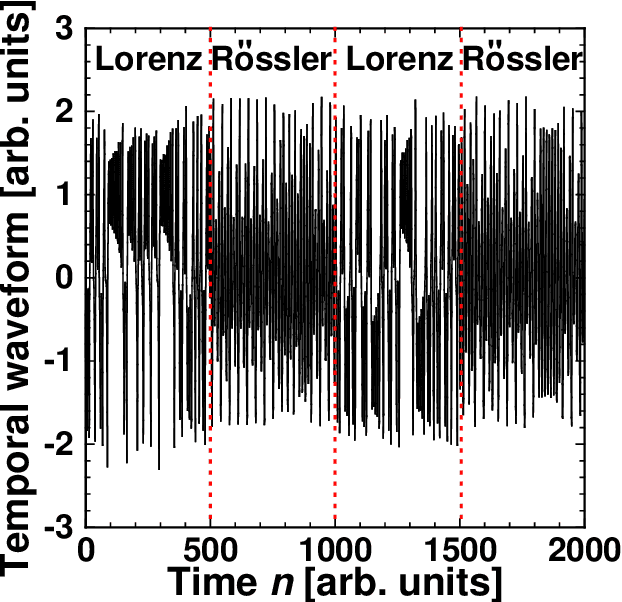
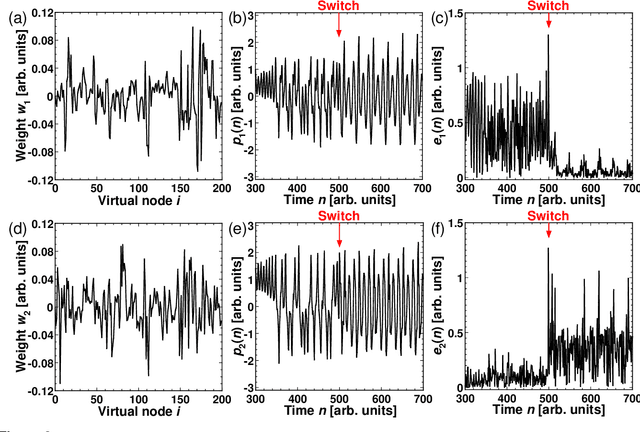
Photonic reservoir computing is an emergent technology toward beyond-Neumann computing. Although photonic reservoir computing provides superior performance in environments whose characteristics are coincident with the training datasets for the reservoir, the performance is significantly degraded if these characteristics deviate from the original knowledge used in the training phase. Here, we propose a scheme of adaptive model selection in photonic reservoir computing using reinforcement learning. In this scheme, a temporal waveform is generated by different dynamic source models that change over time. The system autonomously identifies the best source model for the task of time series prediction using photonic reservoir computing and reinforcement learning. We prepare two types of output weights for the source models, and the system adaptively selected the correct model using reinforcement learning, where the prediction errors are associated with rewards. We succeed in adaptive model selection when the source signal is temporally mixed, having originally been generated by two different dynamic system models, as well as when the signal is a mixture from the same model but with different parameter values. This study paves the way for autonomous behavior in photonic artificial intelligence and could lead to new applications in load forecasting and multi-objective control, where frequent environment changes are expected.
Machine Learning for Health: Personalized Models for Forecasting of Alzheimer Disease Progression
Aug 05, 2020

In this thesis the aim is to work on optimizing the modern machine learning models for personalized forecasting of Alzheimer Disease (AD) Progression from clinical trial data. The data comes from the TADPOLE challenge, which is one of the largest publicly available datasets for AD research (ADNI dataset). The goal of the project is to develop machine learning models that can be used to perform personalized forecasts of the participants cognitive changes (e.g., ADAS-Cog13 scores) over the time period of 6,12, 18 and 24 months in the future and the change in Clinical Status (CS) i.e., whether a person will convert to AD within 2 years or not. This is important for informing current clinical trials and better design of future clinical trials for AD. We will work with personalized Gaussian processes as machine learning models to predict ADAS-Cog13 score and Cox model along with a classifier to predict the conversion in a patient within 2 years.This project is done with the collaboration with researchers from the MIT MediaLab.
SpinAPS: A High-Performance Spintronic Accelerator for Probabilistic Spiking Neural Networks
Aug 05, 2020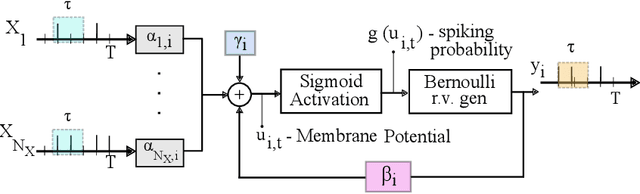

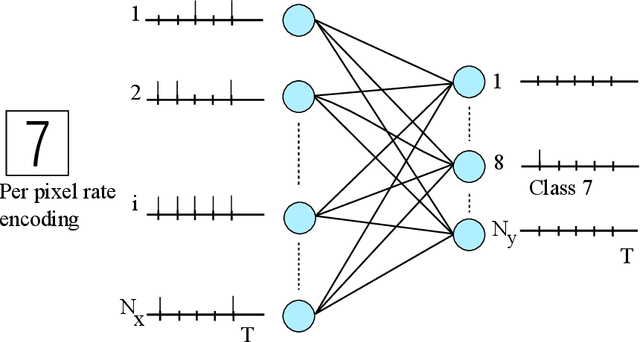
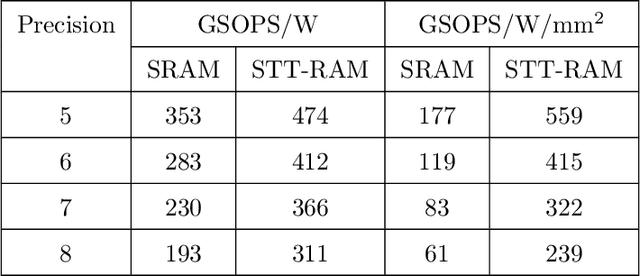
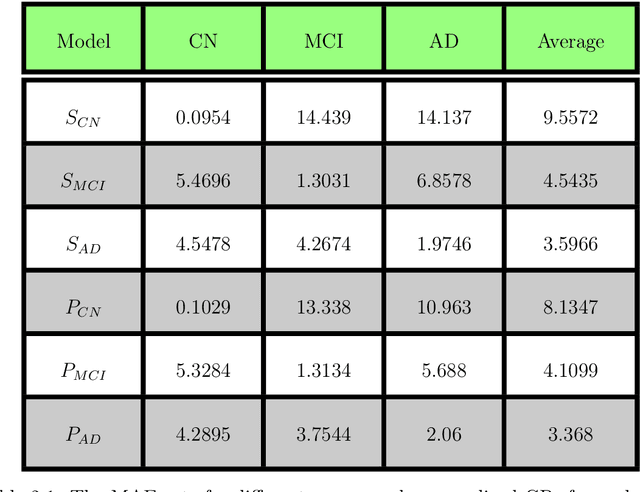
We discuss a high-performance and high-throughput hardware accelerator for probabilistic Spiking Neural Networks (SNNs) based on Generalized Linear Model (GLM) neurons, that uses binary STT-RAM devices as synapses and digital CMOS logic for neurons. The inference accelerator, termed "SpinAPS" for Spintronic Accelerator for Probabilistic SNNs, implements a principled direct learning rule for first-to-spike decoding without the need for conversion from pre-trained ANNs. The proposed solution is shown to achieve comparable performance with an equivalent ANN on handwritten digit and human activity recognition benchmarks. The inference engine, SpinAPS, is shown through software emulation tools to achieve 4x performance improvement in terms of GSOPS/W/mm2 when compared to an equivalent SRAM-based design. The architecture leverages probabilistic spiking neural networks that employ first-to-spike decoding rule to make inference decisions at low latencies, achieving 75% of the test performance in as few as 4 algorithmic time steps on the handwritten digit benchmark. The accelerator also exhibits competitive performance with other memristor-based DNN/SNN accelerators and state-of-the-art GPUs.
Working Memory for Online Memory Binding Tasks: A Hybrid Model
Aug 05, 2020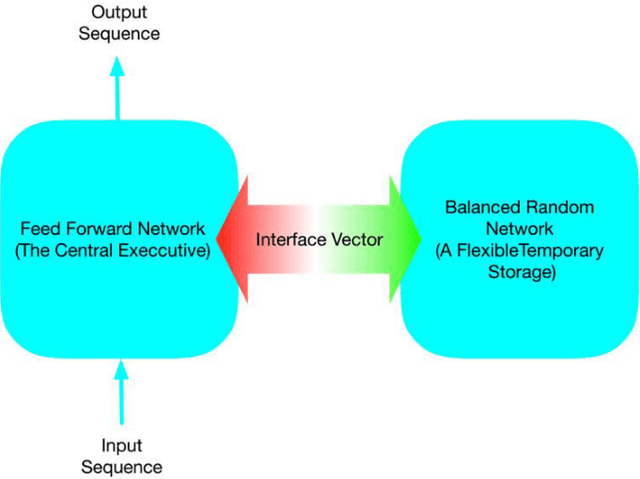
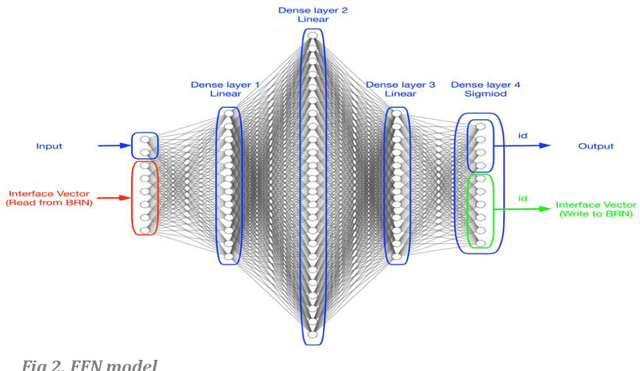
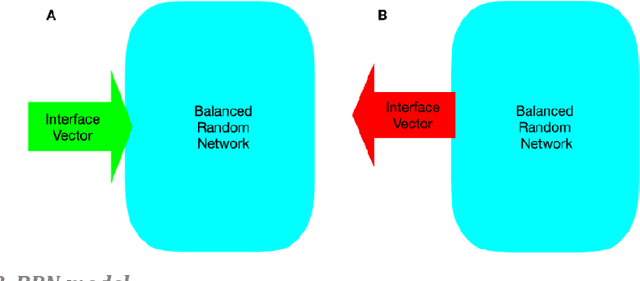
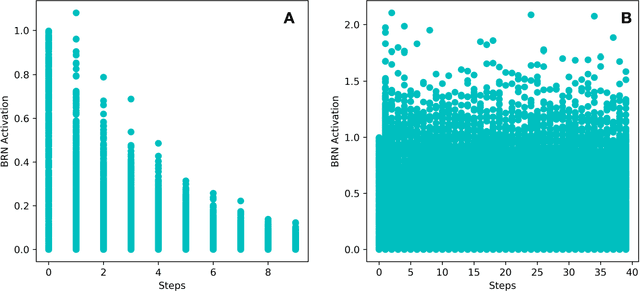
Working Memory is the brain module that holds and manipulates information online. In this work, we design a hybrid model in which a simple feed-forward network is coupled to a balanced random network via a read-write vector called the interface vector. First, we consider some simple memory binding tasks in which the output is set to be a copy of the given input and a selective sequence of previous inputs online. Next, we design a more complex binding task based on a cue that encodes binding relations. The important result is that our dual-component model of working memory shows good performance with learning restricted to the feed-forward component only. Here we take advantage of the random network property without learning. To our knowledge, this is the first time that random networks as a flexible memory is shown to play an important role in online binding tasks. We may interpret our results as a candidate model of working memory in which the feed-forward network learns to interact with the temporary storage random network as an attentional-controlling executive system.