 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Learning for Identifying Events in Active Target Experiments
Aug 06, 2020
This article presents novel applications of unsupervised machine learning methods to the problem of event separation in an active target detector, the Active-Target Time Projection Chamber (AT-TPC). The overarching goal is to group similar events in the early stages of the data analysis, thereby improving efficiency by limiting the computationally expensive processing of unnecessary events. The application of unsupervised clustering algorithms to the analysis of two-dimensional projections of particle tracks from a resonant proton scattering experiment on $^{46}$Ar is introduced. We explore the performance of autoencoder neural networks and a pre-trained VGG16 convolutional neural network. We find that a $K$-means algorithm applied to the simulated data in the VGG16 latent space forms almost perfect clusters. Additionally, the VGG16+$K$-means approach finds high purity clusters of proton events for real experimental data. We also explore the application of clustering the latent space of autoencoder neural networks for event separation. While these networks show strong performance, they suffer from high variability in their results. %With autoencoder neural networks we find improved descriptions of data from experiments.
Fast Template Matching and Update for Video Object Tracking and Segmentation
Apr 16, 2020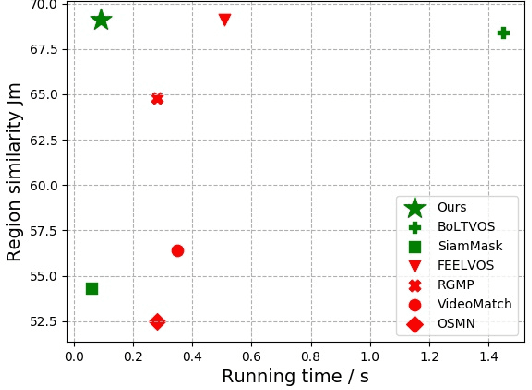
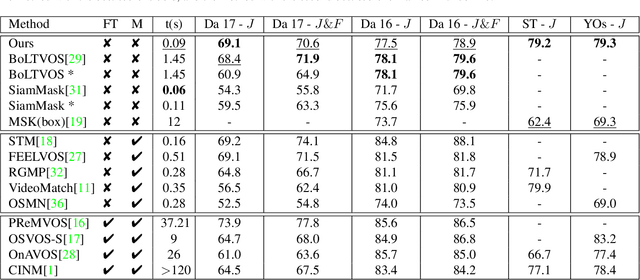
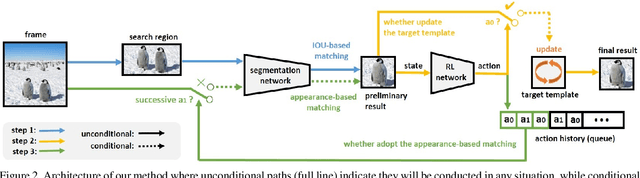
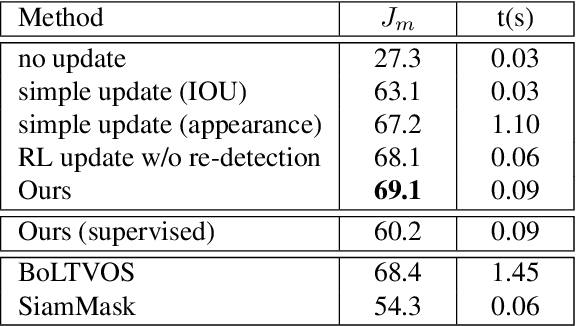
In this paper, the main task we aim to tackle is the multi-instance semi-supervised video object segmentation across a sequence of frames where only the first-frame box-level ground-truth is provided. Detection-based algorithms are widely adopted to handle this task, and the challenges lie in the selection of the matching method to predict the result as well as to decide whether to update the target template using the newly predicted result. The existing methods, however, make these selections in a rough and inflexible way, compromising their performance. To overcome this limitation, we propose a novel approach which utilizes reinforcement learning to make these two decisions at the same time. Specifically, the reinforcement learning agent learns to decide whether to update the target template according to the quality of the predicted result. The choice of the matching method will be determined at the same time, based on the action history of the reinforcement learning agent. Experiments show that our method is almost 10 times faster than the previous state-of-the-art method with even higher accuracy (region similarity of 69.1% on DAVIS 2017 dataset).
Automatic Deep Learning System for COVID-19 Infection Quantification in chest CT
Oct 01, 2020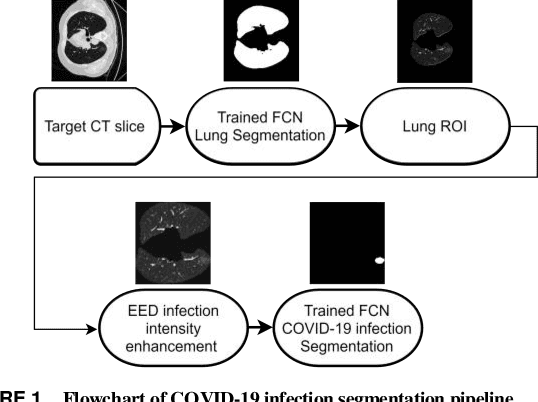
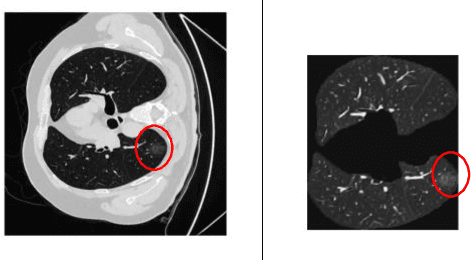
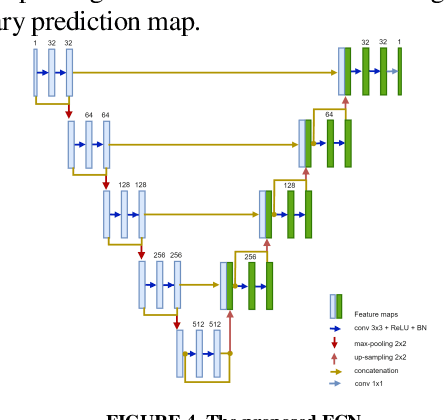
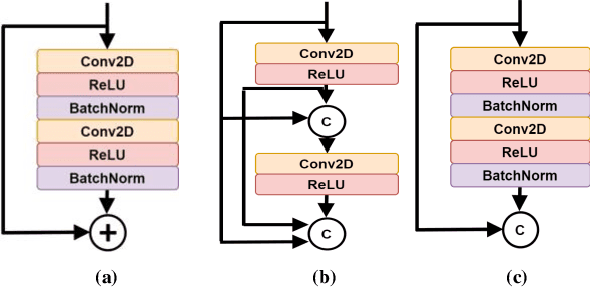
Coronavirus Disease spread globally and infected millions of people quickly, causing high pressure on the health-system facilities. PCR screening is the adopted diagnostic testing method for COVID-19 detection. However, PCR is criticized due its low sensitivity ratios, also, it is time-consuming and manual complicated process. CT imaging proved its ability to detect the disease even for asymptotic patients, which make it a trustworthy alternative for PCR. In addition, the appearance of COVID-19 infections in CT slices, offers high potential to support in disease evolution monitoring using automated infection segmentation methods. However, COVID-19 infection areas include high variations in term of size, shape, contrast and intensity homogeneity, which impose a big challenge on segmentation process. To address these challenges, this paper proposed an automatic deep learning system for COVID-19 infection areas segmentation. The system include different steps to enhance and improve infection areas appearance in the CT slices so they can be learned efficiently using the deep network. The system start prepare the region of interest by segmenting the lung organ, which then undergo edge enhancing diffusion filtering (EED) to improve the infection areas contrast and intensity homogeneity. The proposed FCN is implemented using U-net architecture with modified residual block with concatenation skip connection. The block improves the learning of gradient values by forwarding the infection area features through the network. To demonstrate the generalization and effectiveness of the proposed system, it is trained and tested using many 2D CT slices extracted from diverse datasets from different sources. The proposed system is evaluated using different measures and achieved dice overlapping score of 0.961 and 0.780 for lung and infection areas segmentation, respectively.
Bio-inspired Optimization: metaheuristic algorithms for optimization
Feb 24, 2020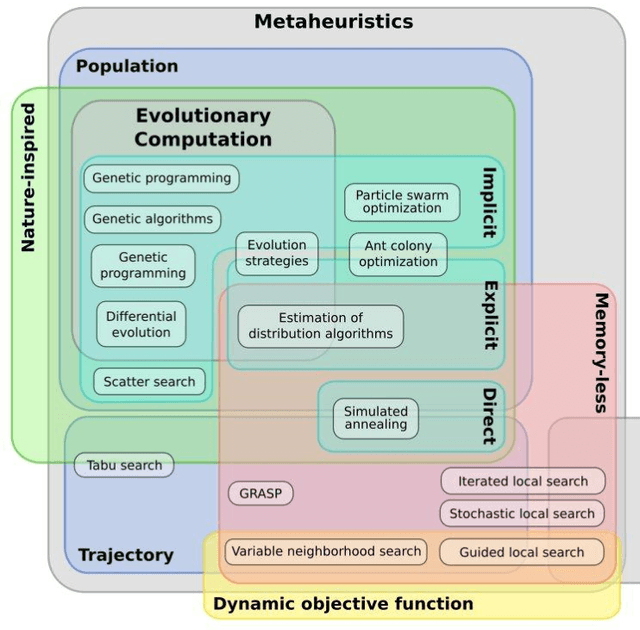
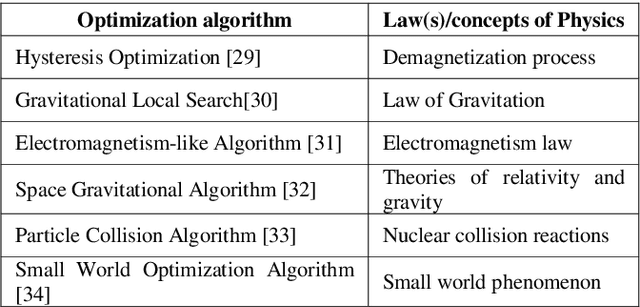
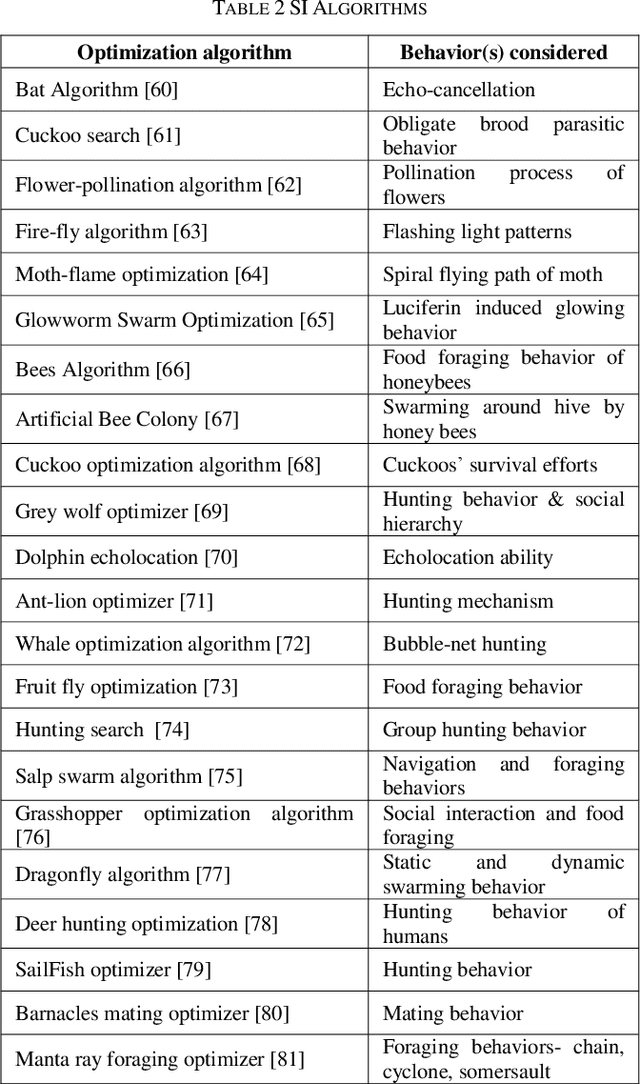
In today's day and time solving real-world complex problems has become fundamentally vital and critical task. Many of these are combinatorial problems, where optimal solutions are sought rather than exact solutions. Traditional optimization methods are found to be effective for small scale problems. However, for real-world large scale problems, traditional methods either do not scale up or fail to obtain optimal solutions or they end-up giving solutions after a long running time. Even earlier artificial intelligence based techniques used to solve these problems could not give acceptable results. However, last two decades have seen many new methods in AI based on the characteristics and behaviors of the living organisms in the nature which are categorized as bio-inspired or nature inspired optimization algorithms. These methods, are also termed meta-heuristic optimization methods, have been proved theoretically and implemented using simulation as well used to create many useful applications. They have been used extensively to solve many industrial and engineering complex problems due to being easy to understand, flexible, simple to adapt to the problem at hand and most importantly their ability to come out of local optima traps. This local optima avoidance property helps in finding global optimal solutions. This paper is aimed at understanding how nature has inspired many optimization algorithms, basic categorization of them, major bio-inspired optimization algorithms invented in recent time with their applications.
Scalar Coupling Constant Prediction Using Graph Embedding Local Attention Encoder
Sep 07, 2020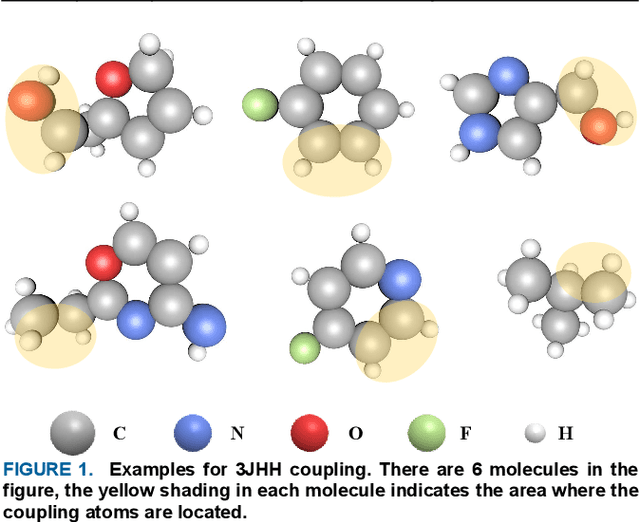
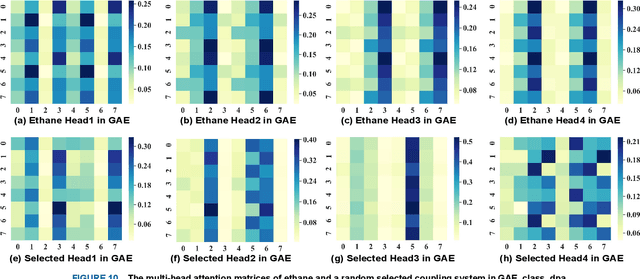
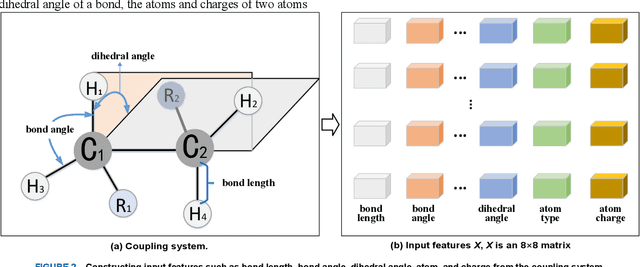
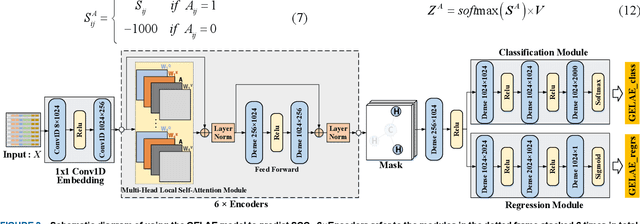
Scalar coupling constant (SCC) plays a key role in the analysis of three-dimensional structure of organic matter, however, the traditional SCC prediction using quantum mechanical calculations is very time-consuming. To calculate SCC efficiently and accurately, we proposed a graph embedding local self-attention encoder (GELAE) model, in which, a novel invariant structure representation of the coupling system in terms of bond length, bond angle and dihedral angle was presented firstly, and then a local self-attention module embedded with the adjacent matrix of a graph was designed to extract effectively the features of coupling systems, finally, with a modified classification loss function, the SCC was predicted. To validate the superiority of the proposed method, we conducted a series of comparison experiments using different structure representations, different attention modules, and different losses. The experimental results demonstrate that, compared to the traditional chemical bond structure representations, the rotation and translation invariant structure representations proposed in this work can improve the SCC prediction accuracy; with the graph embedded local self-attention, the mean absolute error (MAE) of the prediction model in the validation set decreases from 0.1603 Hz to 0.1067 Hz; using the classification based loss function instead of the scaled regression loss, the MAE of the predicted SCC can be decreased to 0.0963 HZ, which is close to the quantum chemistry standard on CHAMPS dataset.
Learnable Graph Inception Network for Emotion Recognition
Aug 06, 2020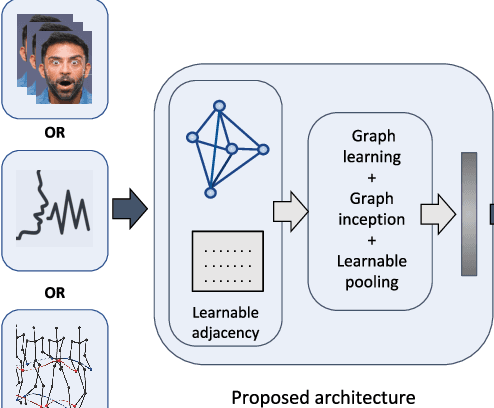
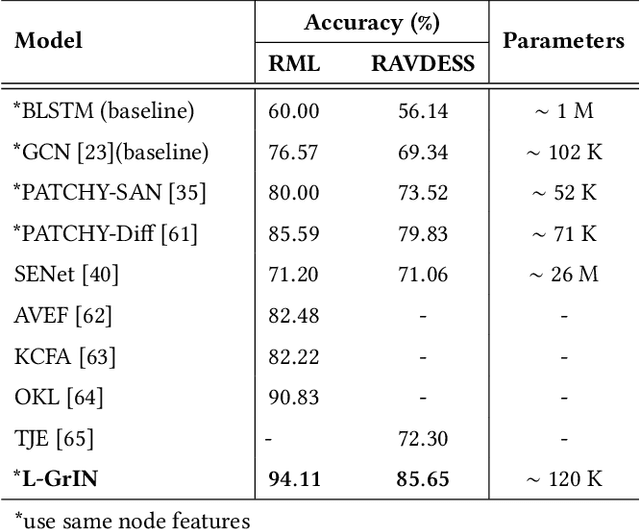
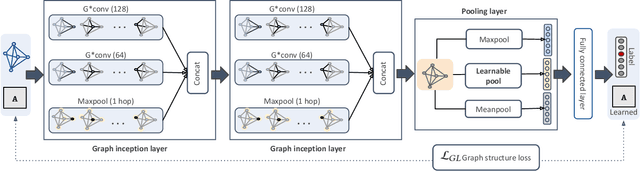
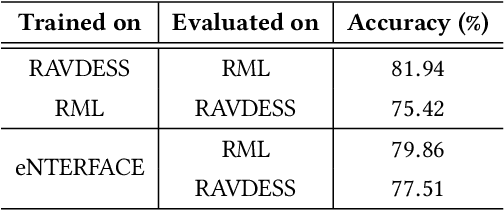
Analyzing emotion from verbal and non-verbal behavioral cues is critical for many intelligent human-centric systems. The emotional cues can be captured using audio, video, motion-capture (mocap) or other modalities. We propose a generalized graph approach to emotion recognition that can take any time-varying (dynamic) data modality as input. To alleviate the problem of optimal graph construction, we cast this as a joint graph learning and classification task. To this end, we present the \emph{Learnable Graph Inception Network} (L-GrIN) that jointly learns to recognize emotion and to identify the underlying graph structure in data. Our architecture comprises multiple novel components: a new graph convolution operation, a graph inception layer, learnable adjacency, and a learnable pooling function that yields a graph-level embedding. We evaluate the proposed architecture on four benchmark emotion recognition databases spanning three different modalities (video, audio, mocap), where each database captures one of the following emotional cues: facial expressions, speech and body gestures. We achieve state-of-the-art performance on all databases outperforming several competitive baselines and relevant existing methods.
Understanding Fairness of Gender Classification Algorithms Across Gender-Race Groups
Sep 24, 2020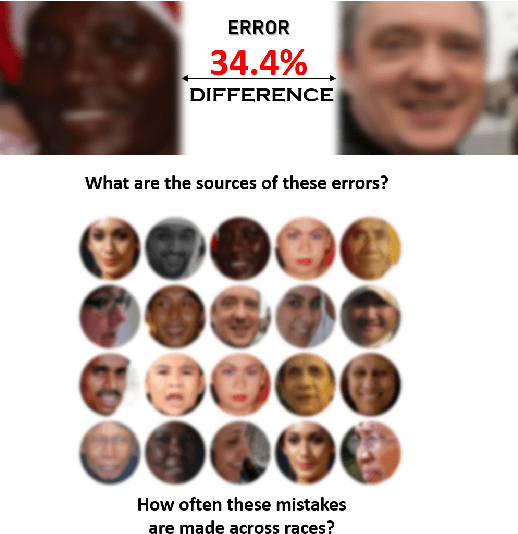


Automated gender classification has important applications in many domains, such as demographic research, law enforcement, online advertising, as well as human-computer interaction. Recent research has questioned the fairness of this technology across gender and race. Specifically, the majority of the studies raised the concern of higher error rates of the face-based gender classification system for darker-skinned people like African-American and for women. However, to date, the majority of existing studies were limited to African-American and Caucasian only. The aim of this paper is to investigate the differential performance of the gender classification algorithms across gender-race groups. To this aim, we investigate the impact of (a) architectural differences in the deep learning algorithms and (b) training set imbalance, as a potential source of bias causing differential performance across gender and race. Experimental investigations are conducted on two latest large-scale publicly available facial attribute datasets, namely, UTKFace and FairFace. The experimental results suggested that the algorithms with architectural differences varied in performance with consistency towards specific gender-race groups. For instance, for all the algorithms used, Black females (Black race in general) always obtained the least accuracy rates. Middle Eastern males and Latino females obtained higher accuracy rates most of the time. Training set imbalance further widens the gap in the unequal accuracy rates across all gender-race groups. Further investigations using facial landmarks suggested that facial morphological differences due to the bone structure influenced by genetic and environmental factors could be the cause of the least performance of Black females and Black race, in general.
Differentiable Algorithm for Marginalising Changepoints
Nov 22, 2019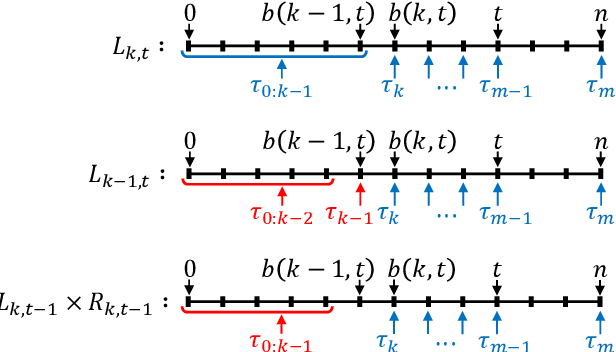

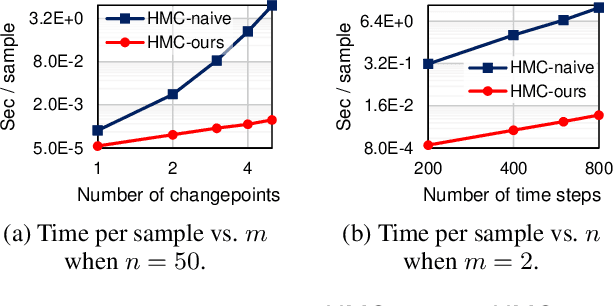
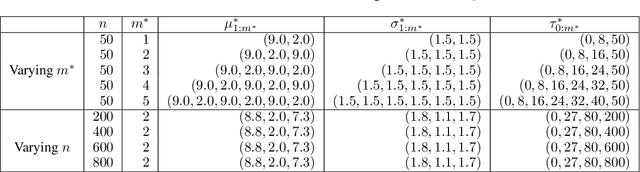
We present an algorithm for marginalising changepoints in time-series models that assume a fixed number of unknown changepoints. Our algorithm is differentiable with respect to its inputs, which are the values of latent random variables other than changepoints. Also, it runs in time O(mn) where n is the number of time steps and m the number of changepoints, an improvement over a naive marginalisation method with O(n^m) time complexity. We derive the algorithm by identifying quantities related to this marginalisation problem, showing that these quantities satisfy recursive relationships, and transforming the relationships to an algorithm via dynamic programming. Since our algorithm is differentiable, it can be applied to convert a model non-differentiable due to changepoints to a differentiable one, so that the resulting models can be analysed using gradient-based inference or learning techniques. We empirically show the effectiveness of our algorithm in this application by tackling the posterior inference problem on synthetic and real-world data.
Joint Mind Modeling for Explanation Generation in Complex Human-Robot Collaborative Tasks
Jul 24, 2020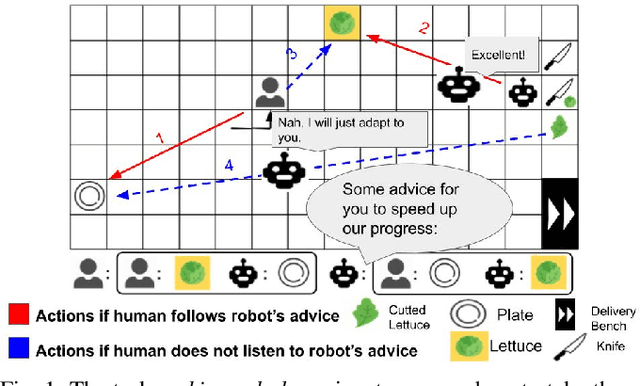
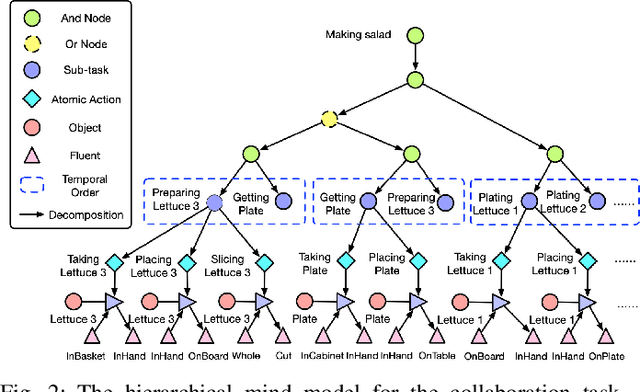
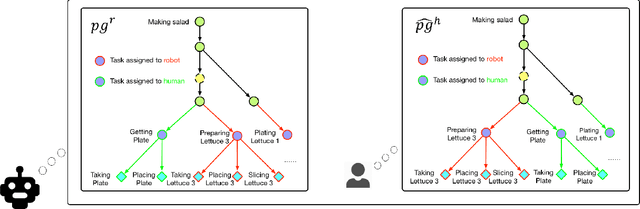
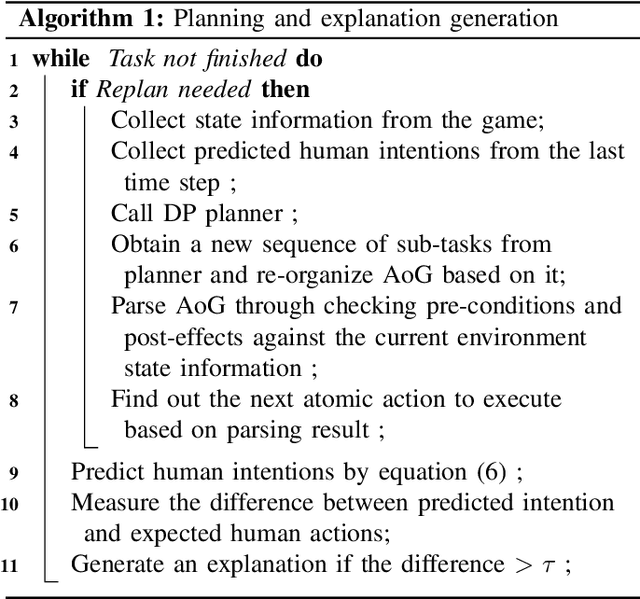
Human collaborators can effectively communicate with their partners to finish a common task by inferring each other's mental states (e.g., goals, beliefs, and desires). Such mind-aware communication minimizes the discrepancy among collaborators' mental states, and is crucial to the success in human ad-hoc teaming. We believe that robots collaborating with human users should demonstrate similar pedagogic behavior. Thus, in this paper, we propose a novel explainable AI (XAI) framework for achieving human-like communication in human-robot collaborations, where the robot builds a hierarchical mind model of the human user and generates explanations of its own mind as a form of communications based on its online Bayesian inference of the user's mental state. To evaluate our framework, we conduct a user study on a real-time human-robot cooking task. Experimental results show that the generated explanations of our approach significantly improves the collaboration performance and user perception of the robot. Code and video demos are available on our project website: https://xfgao.github.io/xCookingWeb/.
The Right Tool for the Job: Matching Model and Instance Complexities
Apr 16, 2020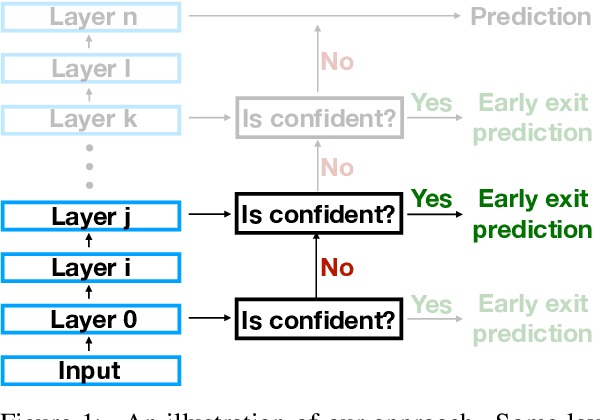
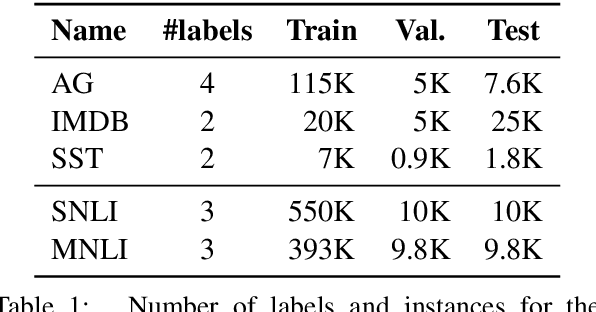
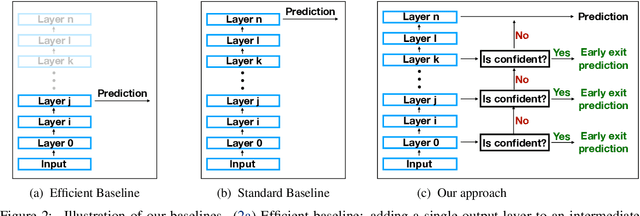
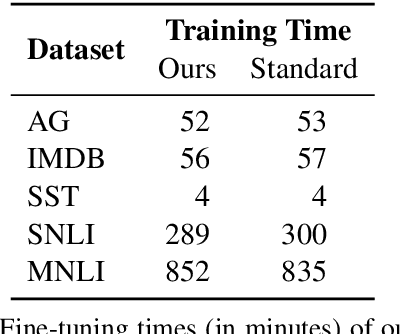
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and environmental costs. To better respect a given inference budget, we propose a modification to contextual representation fine-tuning which, during inference, allows for an early (and fast) "exit" from neural network calculations for simple instances, and late (and accurate) exit for hard instances. To achieve this, we add classifiers to different layers of BERT and use their calibrated confidence scores to make early exit decisions. We test our proposed modification on five different datasets in two tasks: three text classification datasets and two natural language inference benchmarks. Our method presents a favorable speed/accuracy tradeoff in almost all cases, producing models which are up to five times faster than the state of the art, while preserving their accuracy. Our method also requires almost no additional training resources (in either time or parameters) compared to the baseline BERT model. Finally, our method alleviates the need for costly retraining of multiple models at different levels of efficiency; we allow users to control the inference speed/accuracy tradeoff using a single trained model, by setting a single variable at inference time. We publicly release our code.