 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Privacy Guarantees for De-identifying Text Transformations
Aug 07, 2020
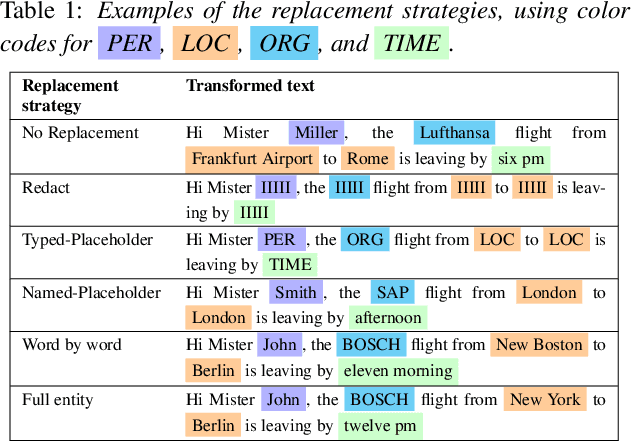
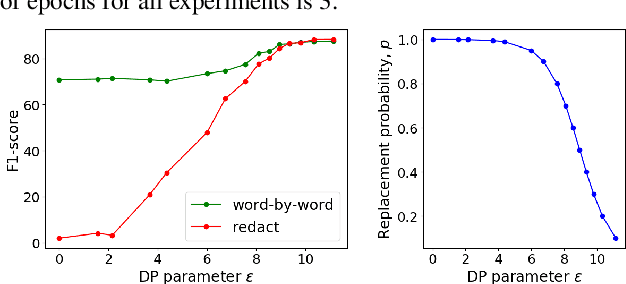

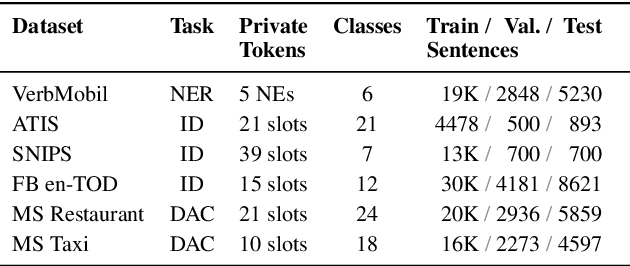
Machine Learning approaches to Natural Language Processing tasks benefit from a comprehensive collection of real-life user data. At the same time, there is a clear need for protecting the privacy of the users whose data is collected and processed. For text collections, such as, e.g., transcripts of voice interactions or patient records, replacing sensitive parts with benign alternatives can provide de-identification. However, how much privacy is actually guaranteed by such text transformations, and are the resulting texts still useful for machine learning? In this paper, we derive formal privacy guarantees for general text transformation-based de-identification methods on the basis of Differential Privacy. We also measure the effect that different ways of masking private information in dialog transcripts have on a subsequent machine learning task. To this end, we formulate different masking strategies and compare their privacy-utility trade-offs. In particular, we compare a simple redact approach with more sophisticated word-by-word replacement using deep learning models on multiple natural language understanding tasks like named entity recognition, intent detection, and dialog act classification. We find that only word-by-word replacement is robust against performance drops in various tasks.
Gibbs Sampling in Factorized Continuous-Time Markov Processes
Jun 13, 2012A central task in many applications is reasoning about processes that change over continuous time. Continuous-Time Bayesian Networks is a general compact representation language for multi-component continuous-time processes. However, exact inference in such processes is exponential in the number of components, and thus infeasible for most models of interest. Here we develop a novel Gibbs sampling procedure for multi-component processes. This procedure iteratively samples a trajectory for one of the components given the remaining ones. We show how to perform exact sampling that adapts to the natural time scale of the sampled process. Moreover, we show that this sampling procedure naturally exploits the structure of the network to reduce the computational cost of each step. This procedure is the first that can provide asymptotically unbiased approximation in such processes.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 14, 2020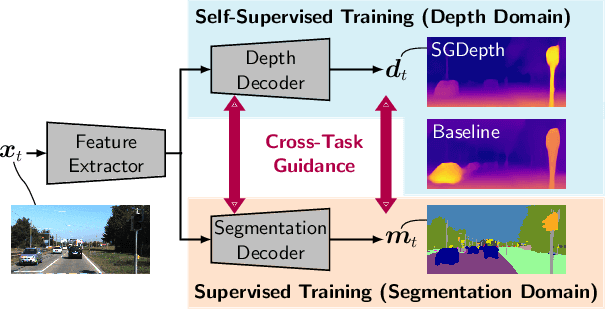
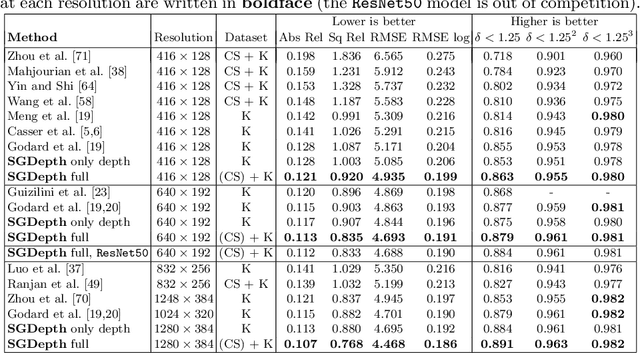
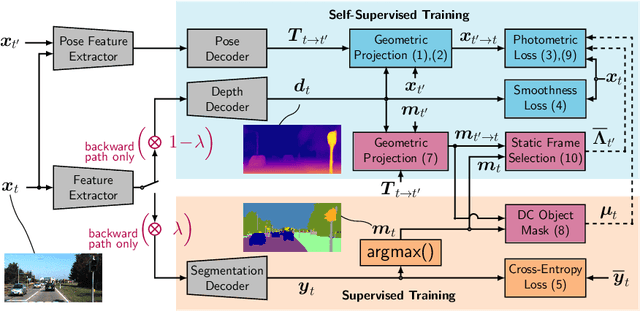
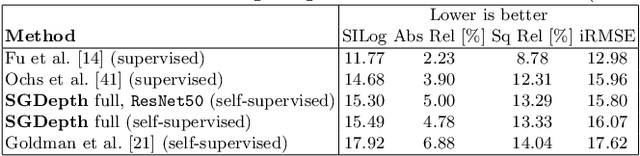
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement in all measures.
Multivariate Functional Singular Spectrum Analysis Over Different Dimensional Domains
Jun 06, 2020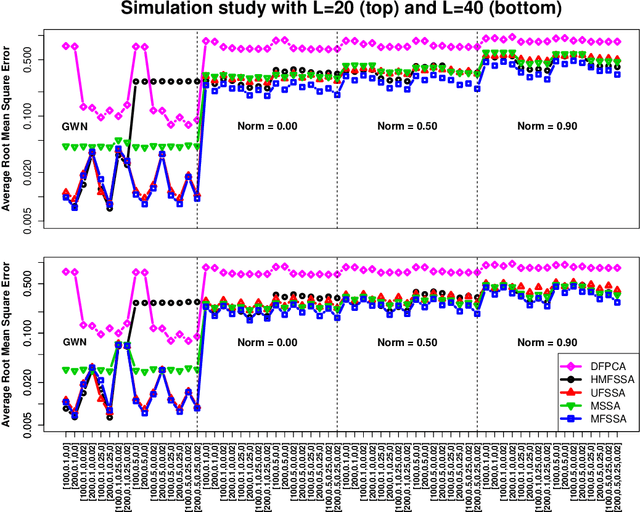
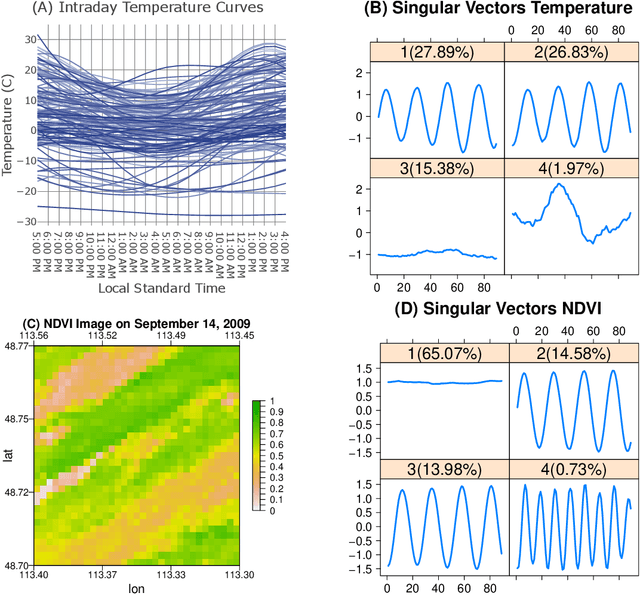
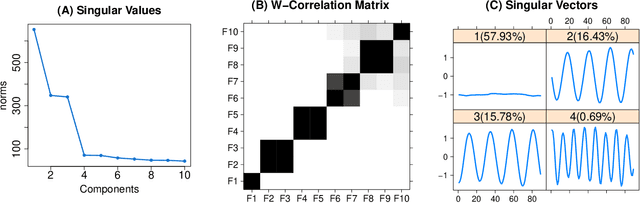
In this work, we develop multivariate functional singular spectrum analysis (MFSSA) over different dimensional domains which is the functional extension of multivariate singular spectrum analysis (MSSA). In the following, we provide all of the necessary theoretical details supporting the work as well as the implementation strategy that contains the recipes needed for the algorithm. We provide a simulation study showcasing the better performance in reconstruction accuracy of a multivariate functional time series (MFTS) signal found using MFSSA as compared to other approaches and we give a real data study showing how MFSSA enriches analysis using intraday temperature curves and remote sensing images of vegetation. MFSSA is available for use through the Rfssa R package.
QTIP: Quick simulation-based adaptation of Traffic model per Incident Parameters
Mar 09, 2020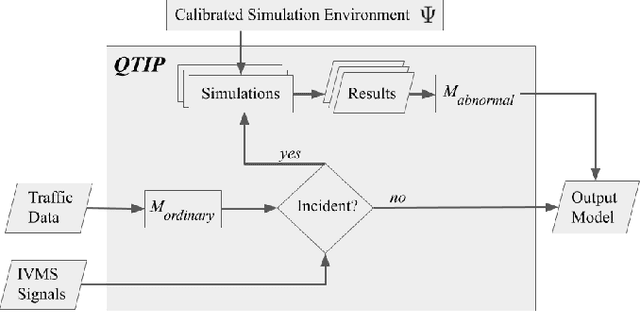
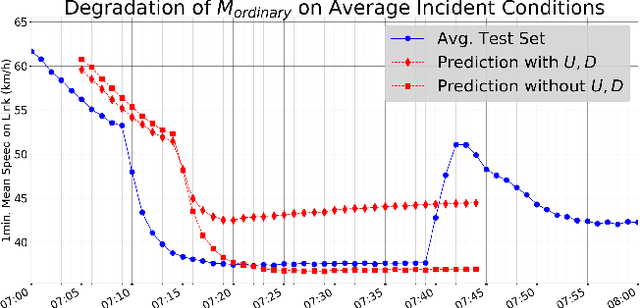
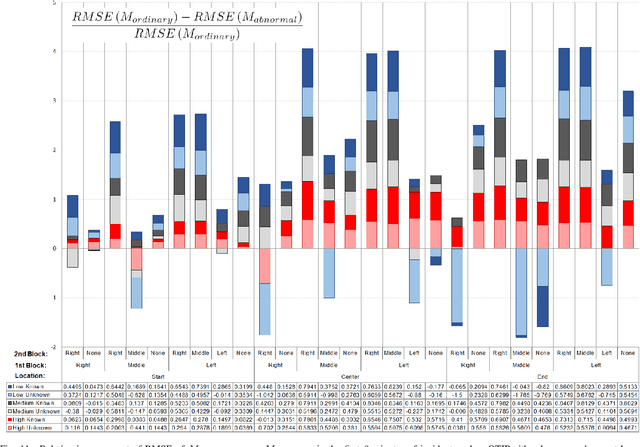
Current data-driven traffic prediction models are usually trained with large datasets, e.g. several months of speeds and flows. Such models provide very good fit for ordinary road conditions, but often fail just when they are most needed: when traffic suffers a sudden and significant disruption, such as a road incident. In this work, we describe QTIP: a simulation-based framework for quasi-instantaneous adaptation of prediction models upon traffic disruption. In a nutshell, QTIP performs real-time simulations of the affected road for multiple scenarios, analyzes the results, and suggests a change to an ordinary prediction model accordingly. QTIP constructs the simulated scenarios per properties of the incident, as conveyed by immediate distress signals from affected vehicles. Such real-time signals are provided by In-Vehicle Monitor Systems, which are becoming increasingly prevalent world-wide. We experiment QTIP in a case study of a Danish motorway, and the results show that QTIP can improve traffic prediction in the first critical minutes of road incidents.
Stochastic Linear Bandits Robust to Adversarial Attacks
Jul 07, 2020

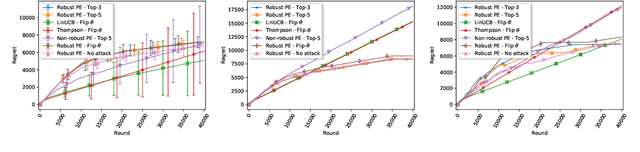
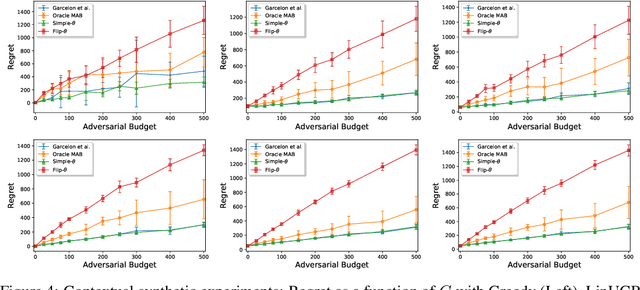
We consider a stochastic linear bandit problem in which the rewards are not only subject to random noise, but also adversarial attacks subject to a suitable budget $C$ (i.e., an upper bound on the sum of corruption magnitudes across the time horizon). We provide two variants of a Robust Phased Elimination algorithm, one that knows $C$ and one that does not. Both variants are shown to attain near-optimal regret in the non-corrupted case $C = 0$, while incurring additional additive terms respectively having a linear and quadratic dependency on $C$ in general. We present algorithm independent lower bounds showing that these additive terms are near-optimal. In addition, in a contextual setting, we revisit a setup of diverse contexts, and show that a simple greedy algorithm is provably robust with a near-optimal additive regret term, despite performing no explicit exploration and not knowing $C$.
Hand-drawn Symbol Recognition of Surgical Flowsheet Graphs with Deep Image Segmentation
Jun 30, 2020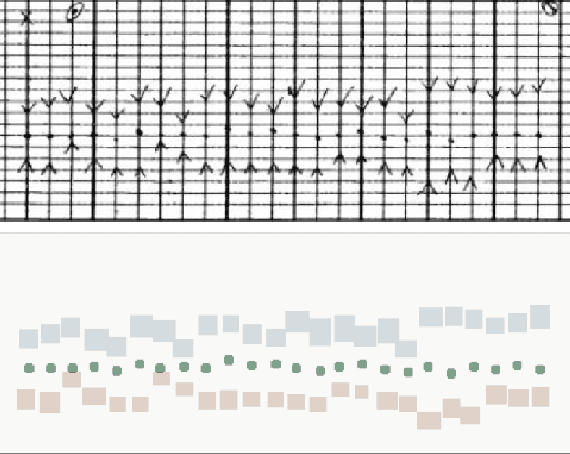
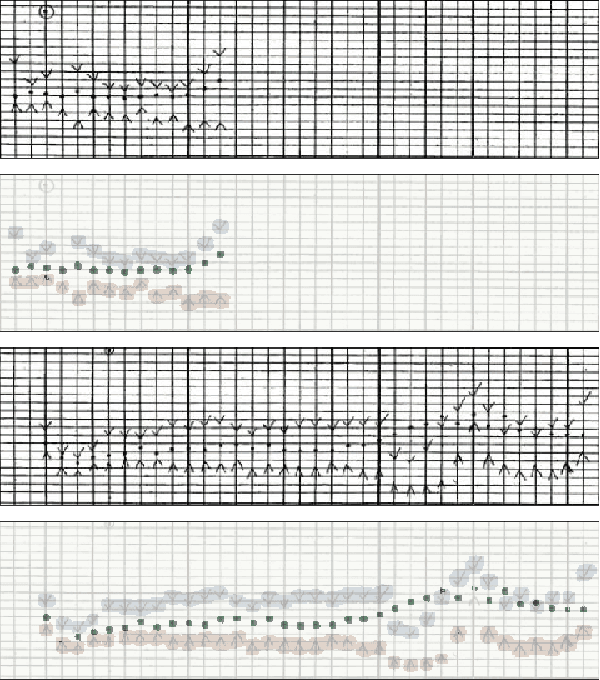

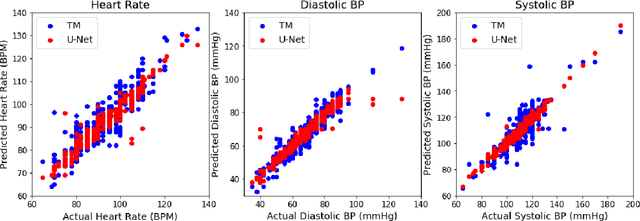
Perioperative data are essential to investigating the causes of adverse surgical outcomes. In some low to middle income countries, these data are computationally inaccessible due to a lack of digitization of surgical flowsheets. In this paper, we present a deep image segmentation approach using a U-Net architecture that can detect hand-drawn symbols on a flowsheet graph. The segmentation mask outputs are post-processed with techniques unique to each symbol to convert into numeric values. The U-Net method can detect, at the appropriate time intervals, the symbols for heart rate and blood pressure with over 99 percent accuracy. Over 95 percent of the predictions fall within an absolute error of five when compared to the actual value. The deep learning model outperformed template matching even with a small size of annotated images available for the training set.
Real-time 3D Human Tracking for Mobile Robots with Multisensors
Mar 15, 2017
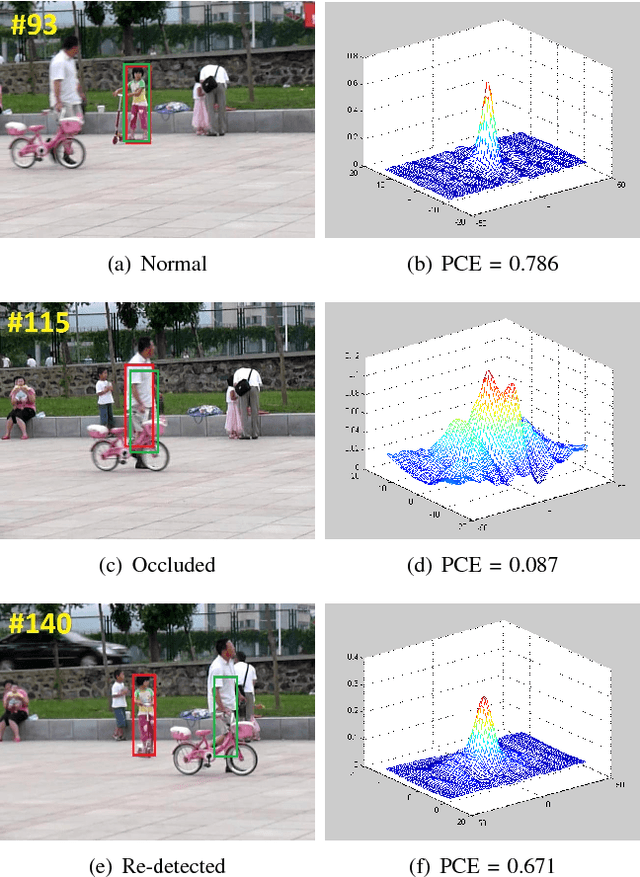

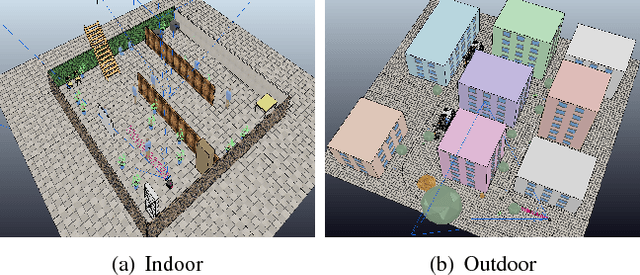
Acquiring the accurate 3-D position of a target person around a robot provides fundamental and valuable information that is applicable to a wide range of robotic tasks, including home service, navigation and entertainment. This paper presents a real-time robotic 3-D human tracking system which combines a monocular camera with an ultrasonic sensor by the extended Kalman filter (EKF). The proposed system consists of three sub-modules: monocular camera sensor tracking model, ultrasonic sensor tracking model and multi-sensor fusion. An improved visual tracking algorithm is presented to provide partial location estimation (2-D). The algorithm is designed to overcome severe occlusions, scale variation, target missing and achieve robust re-detection. The scale accuracy is further enhanced by the estimated 3-D information. An ultrasonic sensor array is employed to provide the range information from the target person to the robot and Gaussian Process Regression is used for partial location estimation (2-D). EKF is adopted to sequentially process multiple, heterogeneous measurements arriving in an asynchronous order from the vision sensor and the ultrasonic sensor separately. In the experiments, the proposed tracking system is tested in both simulation platform and actual mobile robot for various indoor and outdoor scenes. The experimental results show the superior performance of the 3-D tracking system in terms of both the accuracy and robustness.
Using Machine Teaching to Investigate Human Assumptions when Teaching Reinforcement Learners
Sep 05, 2020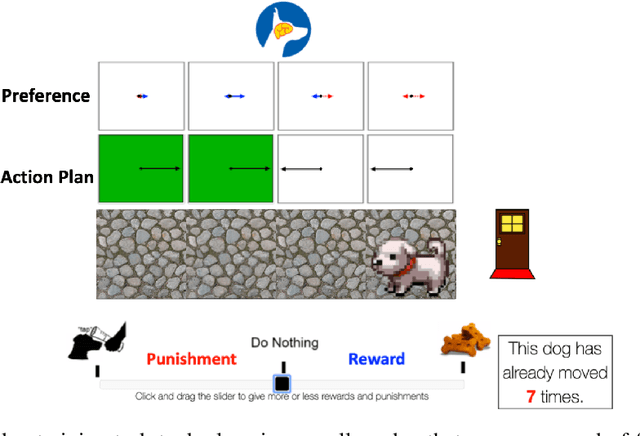
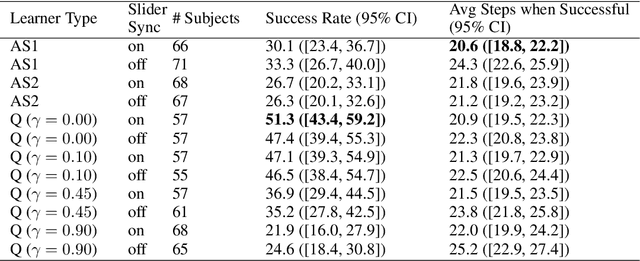
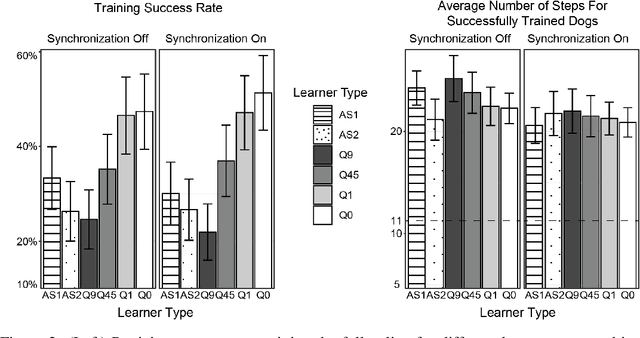
Successful teaching requires an assumption of how the learner learns - how the learner uses experiences from the world to update their internal states. We investigate what expectations people have about a learner when they teach them in an online manner using rewards and punishment. We focus on a common reinforcement learning method, Q-learning, and examine what assumptions people have using a behavioral experiment. To do so, we first establish a normative standard, by formulating the problem as a machine teaching optimization problem. To solve the machine teaching optimization problem, we use a deep learning approximation method which simulates learners in the environment and learns to predict how feedback affects the learner's internal states. What do people assume about a learner's learning and discount rates when they teach them an idealized exploration-exploitation task? In a behavioral experiment, we find that people can teach the task to Q-learners in a relatively efficient and effective manner when the learner uses a small value for its discounting rate and a large value for its learning rate. However, they still are suboptimal. We also find that providing people with real-time updates of how possible feedback would affect the Q-learner's internal states weakly helps them teach. Our results reveal how people teach using evaluative feedback and provide guidance for how engineers should design machine agents in a manner that is intuitive for people.
Toward the Fundamental Limits of Imitation Learning
Sep 13, 2020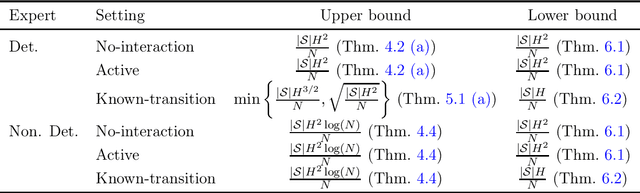
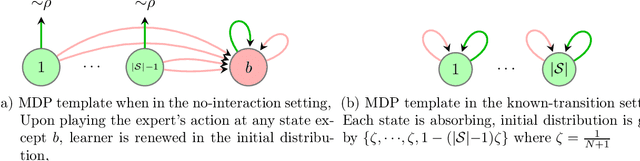
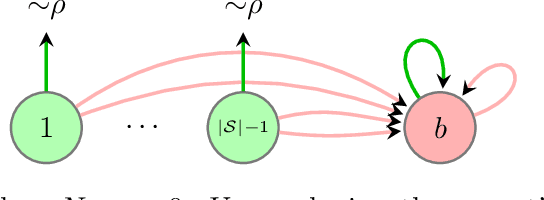
Imitation learning (IL) aims to mimic the behavior of an expert policy in a sequential decision-making problem given only demonstrations. In this paper, we focus on understanding the minimax statistical limits of IL in episodic Markov Decision Processes (MDPs). We first consider the setting where the learner is provided a dataset of $N$ expert trajectories ahead of time, and cannot interact with the MDP. Here, we show that the policy which mimics the expert whenever possible is in expectation $\lesssim \frac{|\mathcal{S}| H^2 \log (N)}{N}$ suboptimal compared to the value of the expert, even when the expert follows an arbitrary stochastic policy. Here $\mathcal{S}$ is the state space, and $H$ is the length of the episode. Furthermore, we establish a suboptimality lower bound of $\gtrsim |\mathcal{S}| H^2 / N$ which applies even if the expert is constrained to be deterministic, or if the learner is allowed to actively query the expert at visited states while interacting with the MDP for $N$ episodes. To our knowledge, this is the first algorithm with suboptimality having no dependence on the number of actions, under no additional assumptions. We then propose a novel algorithm based on minimum-distance functionals in the setting where the transition model is given and the expert is deterministic. The algorithm is suboptimal by $\lesssim \min \{ H \sqrt{|\mathcal{S}| / N} ,\ |\mathcal{S}| H^{3/2} / N \}$, showing that knowledge of transition improves the minimax rate by at least a $\sqrt{H}$ factor.