 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Measurement-driven Analysis of an Edge-Assisted Object Recognition System
Mar 07, 2020
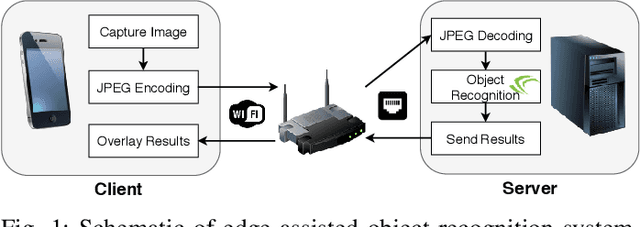
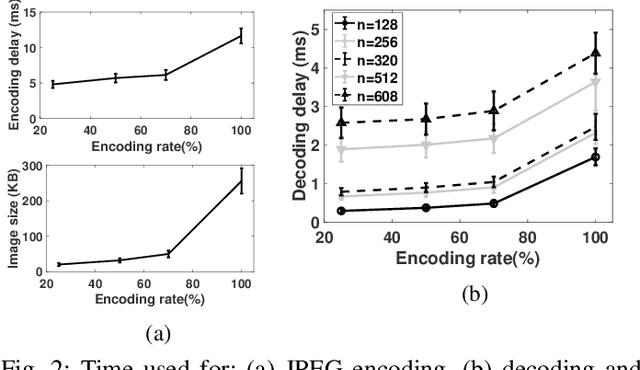
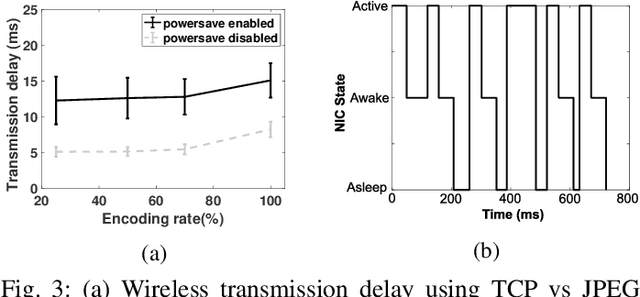
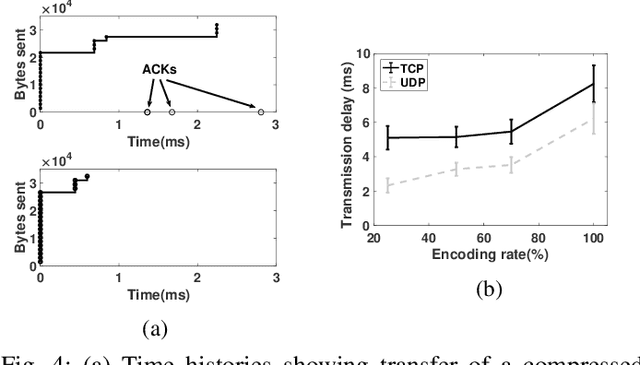
We develop an edge-assisted object recognition system with the aim of studying the system-level trade-offs between end-to-end latency and object recognition accuracy. We focus on developing techniques that optimize the transmission delay of the system and demonstrate the effect of image encoding rate and neural network size on these two performance metrics. We explore optimal trade-offs between these metrics by measuring the performance of our real time object recognition application. Our measurements reveal hitherto unknown parameter effects and sharp trade-offs, hence paving the road for optimizing this key service. Finally, we formulate two optimization problems using our measurement-based models and following a Pareto analysis we find that careful tuning of the system operation yields at least 33% better performance for real time conditions, over the standard transmission method.
Deep Markov Spatio-Temporal Factorization
Mar 22, 2020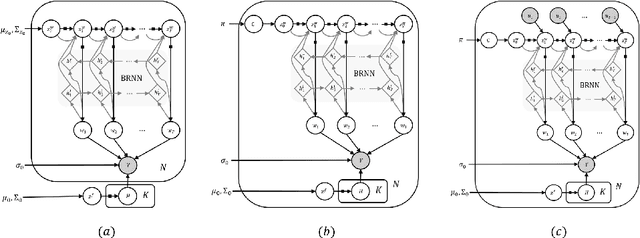

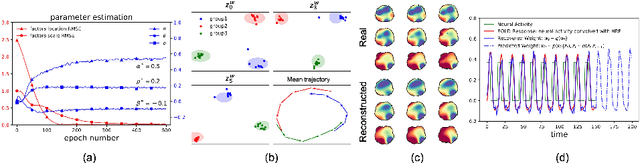

We introduce deep Markov spatio-temporal factorization (DMSTF), a deep generative model for spatio-temporal data. Like other factor analysis methods, DMSTF approximates high-dimensional data by a product between time-dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower-dimensional latent variables that we infer using stochastic variational inference. The innovation in DMSTF is that we parameterize weights in terms of a deep Markovian prior, which is able to characterize nonlinear temporal dynamics. We parameterize the corresponding variational distribution using a bidirectional recurrent network. This results in a flexible family of hierarchical deep generative factor analysis models that can be extended to perform time series clustering, or perform factor analysis in the presence of a control signal. Our experiments, which consider simulated data, fMRI data, and traffic data, demonstrate that DMSTF outperforms related methods in terms of reconstruction accuracy and can perform forecasting in a variety domains with nonlinear temporal transitions.
Traditional and accelerated gradient descent for neural architecture search
Jun 26, 2020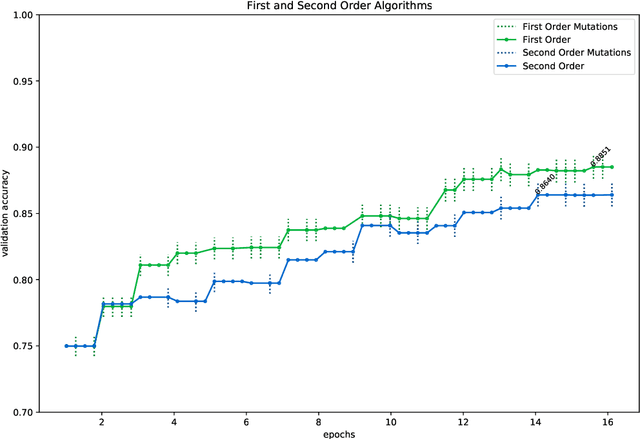
In this paper, we introduce two algorithms for neural architecture search (NASGD and NASAGD) following the theoretical work by two of the authors [3]. Such work aims to introduce the conceptual basis for new notions of traditional and accelerated gradient descent algorithms for the optimization of a function on a semi-discrete space using ideas from optimal transport theory. Our methods, which use the network morphism framework introduced in [2], can analyze forty times as many architectures as the fastest methods in the literature [2,10] while using the same computational resources and time and achieving comparable levels of accuracy. For example, with NASGD, on CIFAR-10, our method designs and trains networks with an error rate of 4.06 in only 12 hours on a single GPU.
Optimizing Information Loss Towards Robust Neural Networks
Aug 07, 2020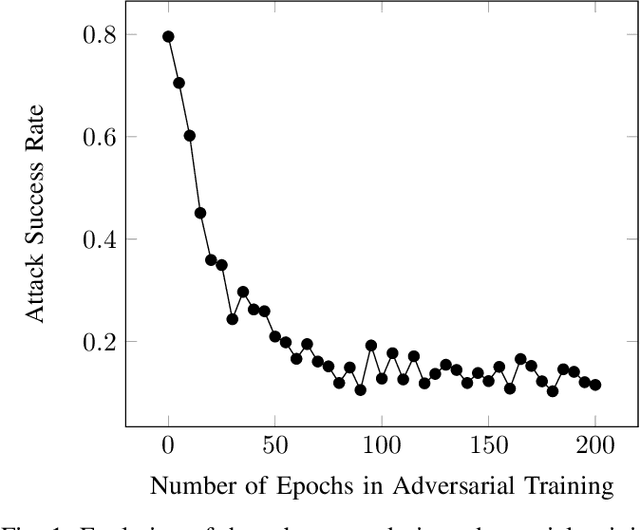
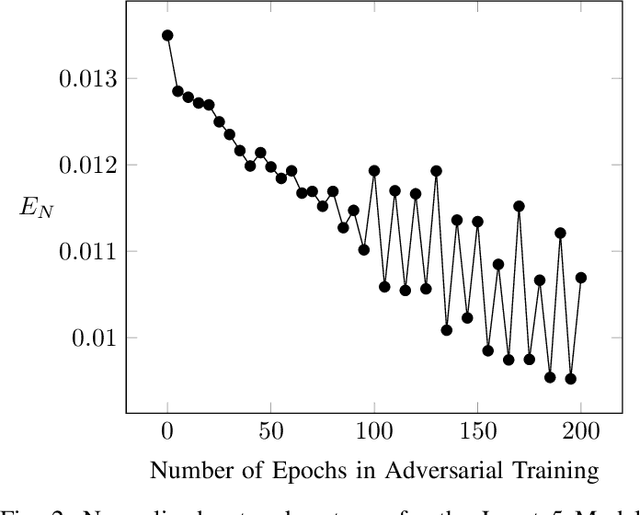
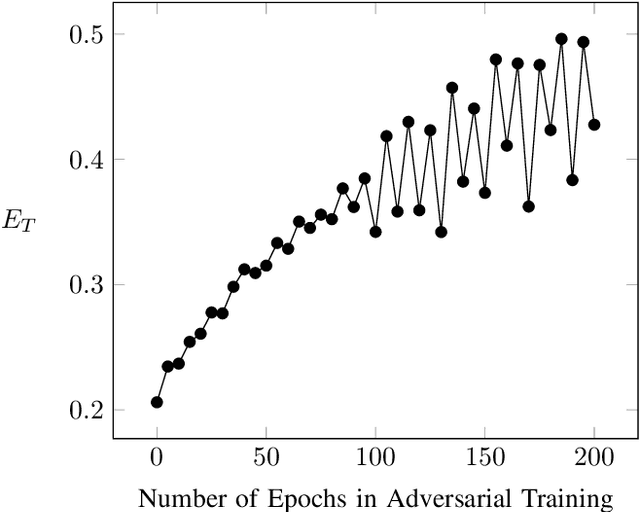
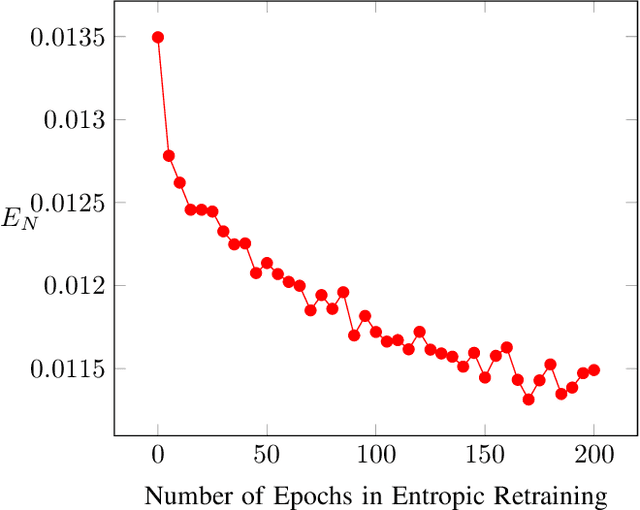
Neural Networks (NNs) are vulnerable to adversarial examples. Such inputs differ only slightly from their benign counterparts yet provoke misclassifications of the attacked NNs. The required perturbations to craft the examples are often negligible and even human imperceptible. To protect deep learning based system from such attacks, several countermeasures have been proposed with adversarial training still being considered the most effective. Here, NNs are iteratively retrained using adversarial examples forming a computational expensive and time consuming process often leading to a performance decrease. To overcome the downsides of adversarial training while still providing a high level of security, we present a new training approach we call entropic retraining. Based on an information-theoretic analysis, entropic retraining mimics the effects of adversarial training without the need of the laborious generation of adversarial examples. We empirically show that entropic retraining leads to a significant increase in NNs' security and robustness while only relying on the given original data. With our prototype implementation we validate and show the effectiveness of our approach for various NN architectures and data sets.
Commonsense Knowledge in Wikidata
Aug 18, 2020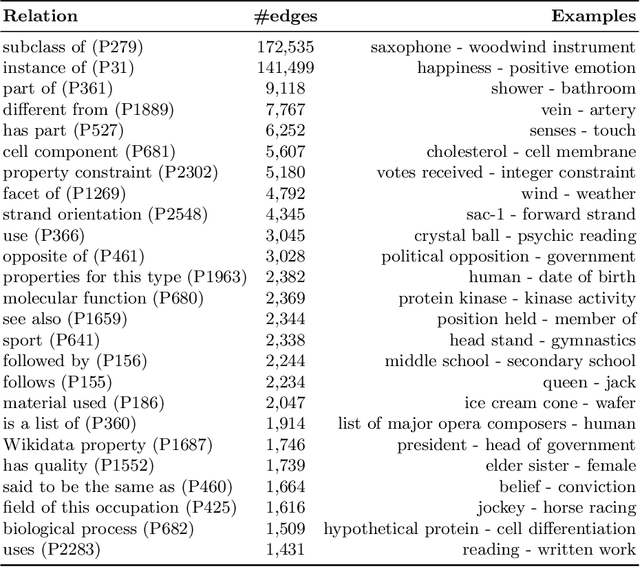
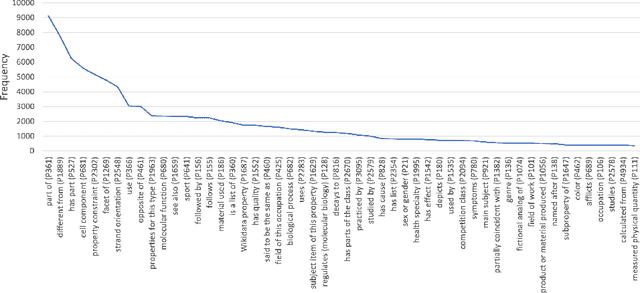
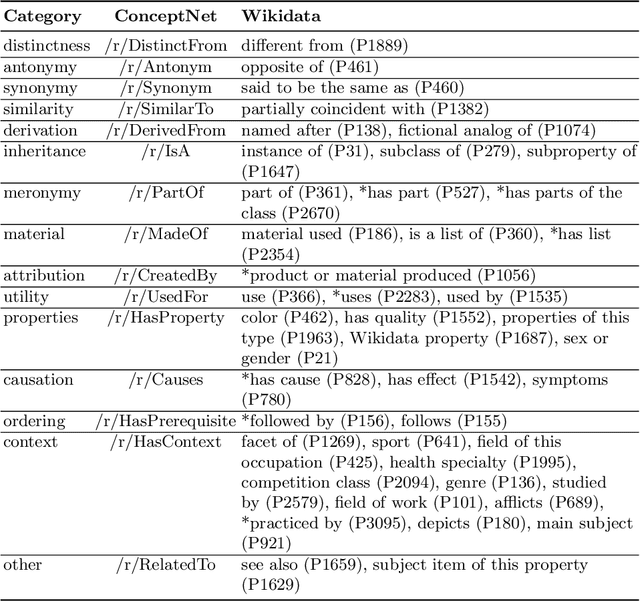

Wikidata and Wikipedia have been proven useful for reason-ing in natural language applications, like question answering or entitylinking. Yet, no existing work has studied the potential of Wikidata for commonsense reasoning. This paper investigates whether Wikidata con-tains commonsense knowledge which is complementary to existing commonsense sources. Starting from a definition of common sense, we devise three guiding principles, and apply them to generate a commonsense subgraph of Wikidata (Wikidata-CS). Within our approach, we map the relations of Wikidata to ConceptNet, which we also leverage to integrate Wikidata-CS into an existing consolidated commonsense graph. Our experiments reveal that: 1) albeit Wikidata-CS represents a small portion of Wikidata, it is an indicator that Wikidata contains relevant commonsense knowledge, which can be mapped to 15 ConceptNet relations; 2) the overlap between Wikidata-CS and other commonsense sources is low, motivating the value of knowledge integration; 3) Wikidata-CS has been evolving over time at a slightly slower rate compared to the overall Wikidata, indicating a possible lack of focus on commonsense knowledge. Based on these findings, we propose three recommended actions to improve the coverage and quality of Wikidata-CS further.
Classifying Image Sequences of Astronomical Transients with Deep Neural Networks
Apr 28, 2020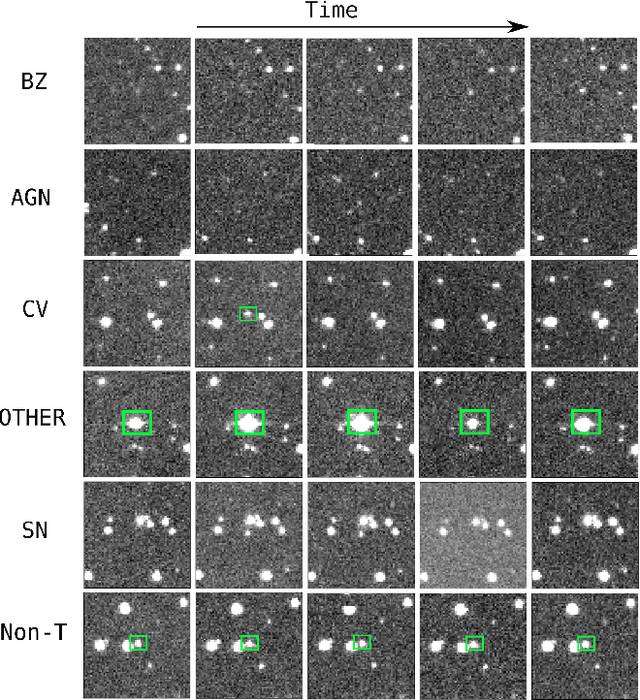


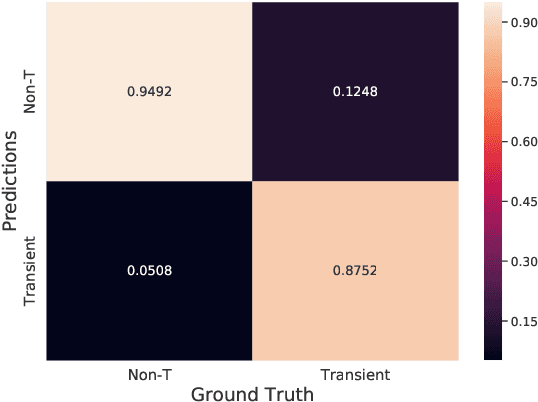
Supervised classification of temporal sequences of astronomical images into meaningful transient astrophysical phenomena has been considered a hard problem because it requires the intervention of human experts. The classifier uses the expert's knowledge to find heuristic features to process the images, for instance, by performing image subtraction or by extracting sparse information such as flux time series in the form of light curves. We present a successful deep learning approach that learns directly from imaging data. Our method models explicitly the spatio-temporal patterns with Deep Convolutional Neural Networks and Gated Recurrent Units. We train these deep neural networks using 1.3 million real astronomical images from the Catalina Real-Time Transient Survey to classify the sequences into five different types of astronomical transient classes. The TAO-Net (for Transient Astronomical Objects Network) architecture achieves on the five-type classification task an average F1-score of 54.58$\pm$13.32, almost nine points higher than the F1-score of 45.49 $\pm$ 13.75 from the random forest classification on light curves. The achievement TAO-Net opens the possibility to develop new deep-learning architectures for early transient detection. We make available the training dataset and trained models of TAO-Net to allow for future extensions of this work.
PANDA: Predicting the change in proteins binding affinity upon mutations using sequence information
Sep 16, 2020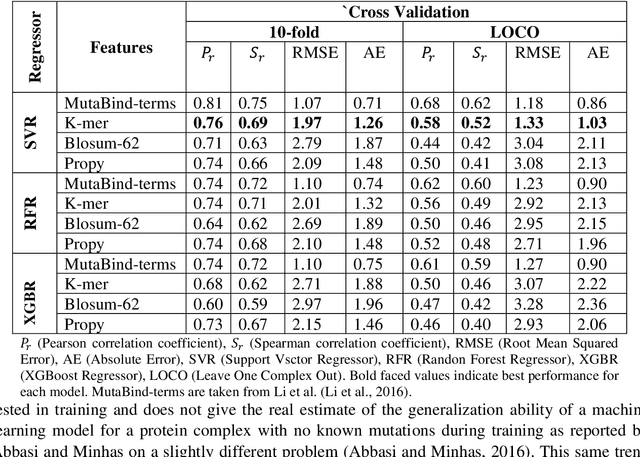
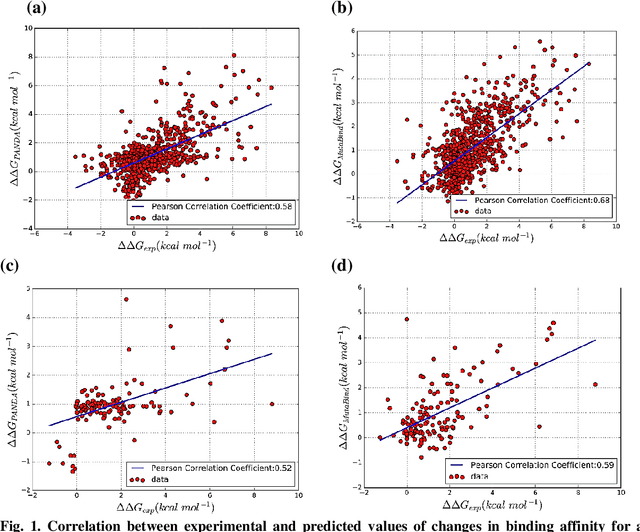
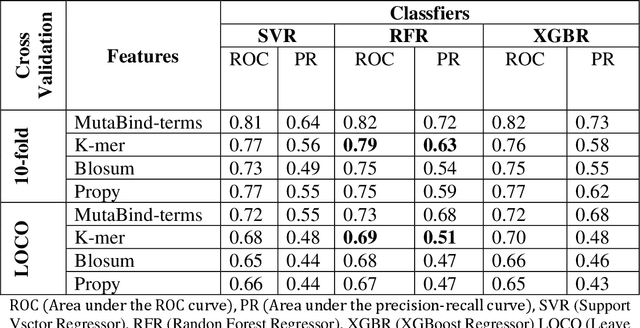
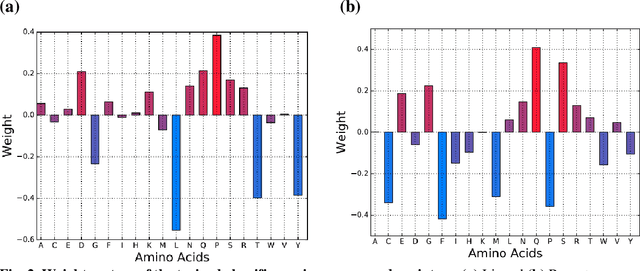
Accurately determining a change in protein binding affinity upon mutations is important for the discovery and design of novel therapeutics and to assist mutagenesis studies. Determination of change in binding affinity upon mutations requires sophisticated, expensive, and time-consuming wet-lab experiments that can be aided with computational methods. Most of the computational prediction techniques require protein structures that limit their applicability to protein complexes with known structures. In this work, we explore the sequence-based prediction of change in protein binding affinity upon mutation. We have used protein sequence information instead of protein structures along with machine learning techniques to accurately predict the change in protein binding affinity upon mutation. Our proposed sequence-based novel change in protein binding affinity predictor called PANDA gives better accuracy than existing methods over the same validation set as well as on an external independent test dataset. On an external test dataset, our proposed method gives a maximum Pearson correlation coefficient of 0.52 in comparison to the state-of-the-art existing protein structure-based method called MutaBind which gives a maximum Pearson correlation coefficient of 0.59. Our proposed protein sequence-based method, to predict a change in binding affinity upon mutations, has wide applicability and comparable performance in comparison to existing protein structure-based methods. A cloud-based webserver implementation of PANDA and its python code is available at https://sites.google.com/view/wajidarshad/software and https://github.com/wajidarshad/panda.
Lazy Greedy Hypervolume Subset Selection from Large Candidate Solution Sets
Jul 04, 2020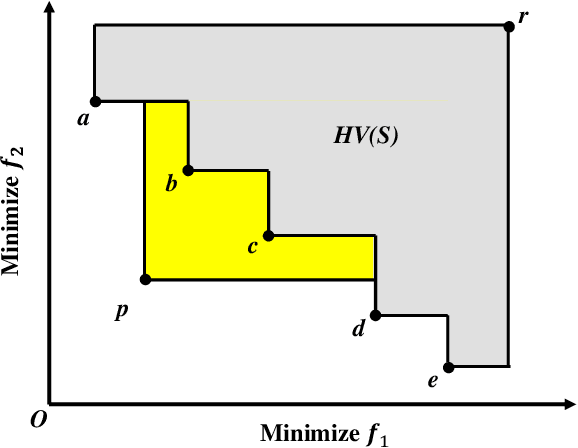
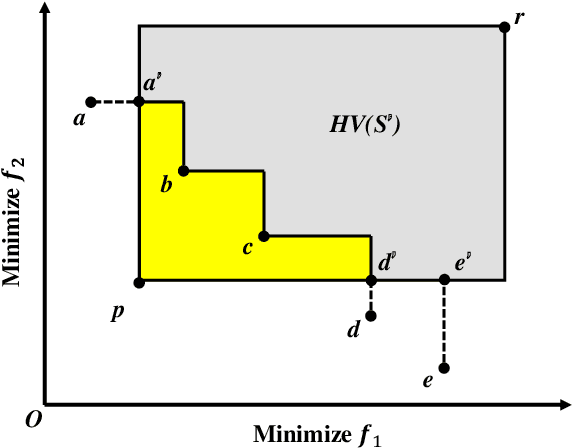
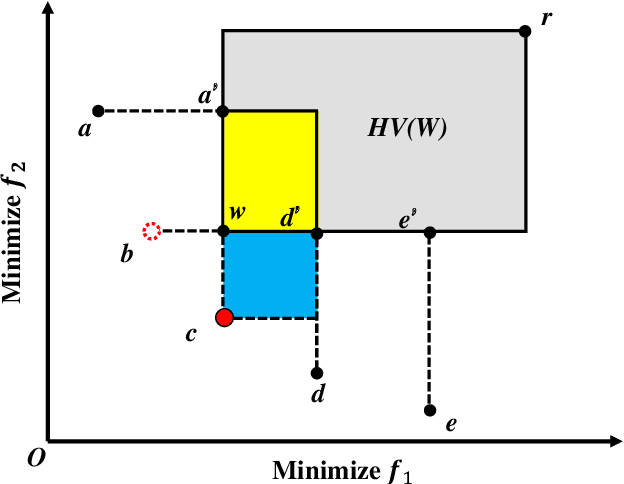

Subset selection is a popular topic in recent years and a number of subset selection methods have been proposed. Among those methods, hypervolume subset selection is widely used. Greedy hypervolume subset selection algorithms can achieve good approximations to the optimal subset. However, when the candidate set is large (e.g., an unbounded external archive with a large number of solutions), the algorithm is very time-consuming. In this paper, we propose a new lazy greedy algorithm exploiting the submodular property of the hypervolume indicator. The core idea is to avoid unnecessary hypervolume contribution calculation when finding the solution with the largest contribution. Experimental results show that the proposed algorithm is hundreds of times faster than the original greedy inclusion algorithm and several times faster than the fastest known greedy inclusion algorithm on many test problems.
Ensemble Forecasting of the Zika Space-TimeSpread with Topological Data Analysis
Sep 24, 2020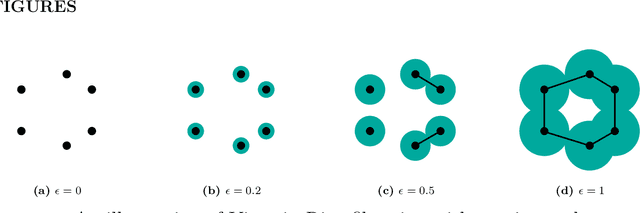

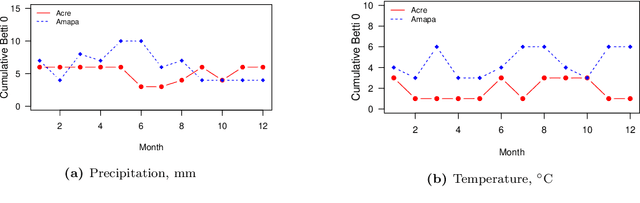
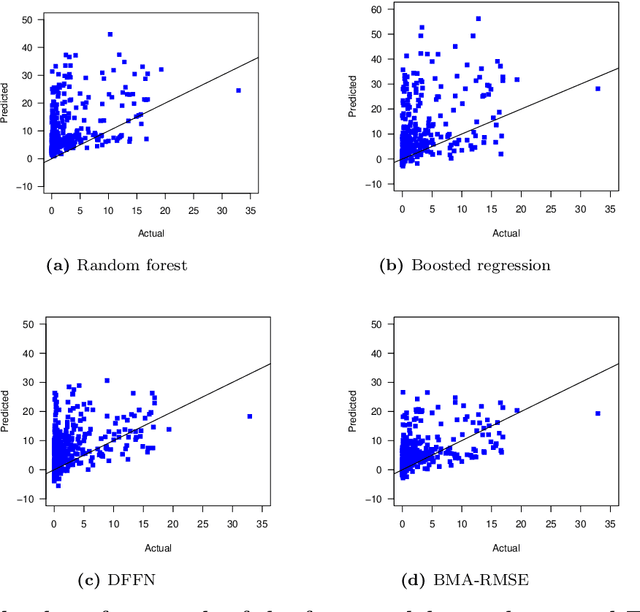
As per the records of theWorld Health Organization, the first formally reported incidence of Zika virus occurred in Brazil in May 2015. The disease then rapidly spread to other countries in Americas and East Asia, affecting more than 1,000,000 people. Zika virus is primarily transmitted through bites of infected mosquitoes of the species Aedes (Aedes aegypti and Aedes albopictus). The abundance of mosquitoes and, as a result, the prevalence of Zika virus infections are common in areas which have high precipitation, high temperature, and high population density.Nonlinear spatio-temporal dependency of such data and lack of historical public health records make prediction of the virus spread particularly challenging. In this article, we enhance Zika forecasting by introducing the concepts of topological data analysis and, specifically, persistent homology of atmospheric variables, into the virus spread modeling. The topological summaries allow for capturing higher order dependencies among atmospheric variables that otherwise might be unassessable via conventional spatio-temporal modeling approaches based on geographical proximity assessed via Euclidean distance. We introduce a new concept of cumulative Betti numbers and then integrate the cumulative Betti numbers as topological descriptors into three predictive machine learning models: random forest, generalized boosted regression, and deep neural network. Furthermore, to better quantify for various sources of uncertainties, we combine the resulting individual model forecasts into an ensemble of the Zika spread predictions using Bayesian model averaging. The proposed methodology is illustrated in application to forecasting of the Zika space-time spread in Brazil in the year 2018.
* 29 page, 5 figures
Unsupervised Learning for Identifying Events in Active Target Experiments
Aug 07, 2020This article presents novel applications of unsupervised machine learning methods to the problem of event separation in an active target detector, the Active-Target Time Projection Chamber (AT-TPC). The overarching goal is to group similar events in the early stages of the data analysis, thereby improving efficiency by limiting the computationally expensive processing of unnecessary events. The application of unsupervised clustering algorithms to the analysis of two-dimensional projections of particle tracks from a resonant proton scattering experiment on $^{46}$Ar is introduced. We explore the performance of autoencoder neural networks and a pre-trained VGG16 convolutional neural network. We find that a $K$-means algorithm applied to the simulated data in the VGG16 latent space forms almost perfect clusters. Additionally, the VGG16+$K$-means approach finds high purity clusters of proton events for real experimental data. We also explore the application of clustering the latent space of autoencoder neural networks for event separation. While these networks show strong performance, they suffer from high variability in their results.