 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communication Contention Aware Scheduling of Multiple Deep Learning Training Jobs
Feb 24, 2020
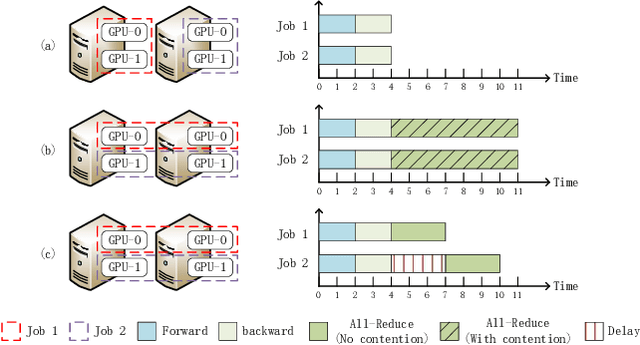
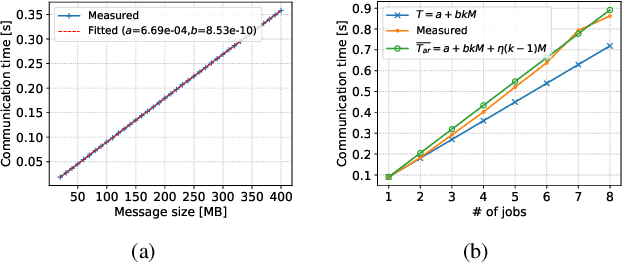
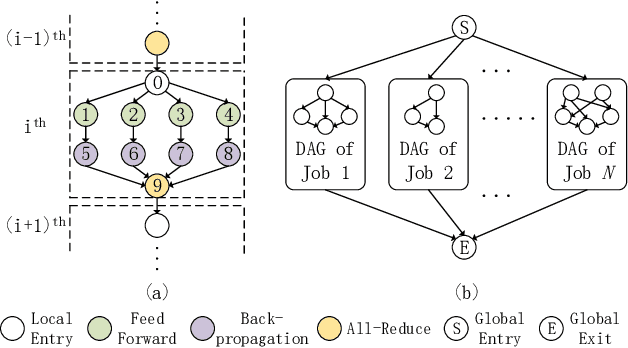
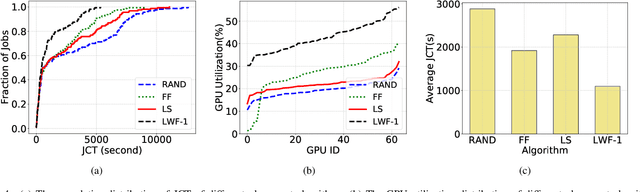
Distributed Deep Learning (DDL) has rapidly grown its popularity since it helps boost the training performance on high-performance GPU clusters. Efficient job scheduling is indispensable to maximize the overall performance of the cluster when training multiple jobs simultaneously. However, existing schedulers do not consider the communication contention of multiple communication tasks from different distributed training jobs, which could deteriorate the system performance and prolong the job completion time. In this paper, we first establish a new DDL job scheduling framework which organizes DDL jobs as Directed Acyclic Graphs (DAGs) and considers communication contention between nodes. We then propose an efficient algorithm, LWF-$\kappa$, to balance the GPU utilization and consolidate the allocated GPUs for each job. When scheduling those communication tasks, we observe that neither avoiding all the contention nor blindly accepting them is optimal to minimize the job completion time. We thus propose a provable algorithm, AdaDUAL, to efficiently schedule those communication tasks. Based on AdaDUAL, we finally propose Ada-SRSF for the DDL job scheduling problem. Simulations on a 64-GPU cluster connected with 10 Gbps Ethernet show that LWF-$\kappa$ achieves up to $1.59\times$ improvement over the classical first-fit algorithms. More importantly, Ada-SRSF reduces the average job completion time by $20.1\%$ and $36.7\%$, as compared to the SRSF(1) scheme (avoiding all the contention) and the SRSF(2) scheme (blindly accepting all of two-way communication contention) respectively.
Gaussian process modelling of multiple short time series
Oct 09, 2012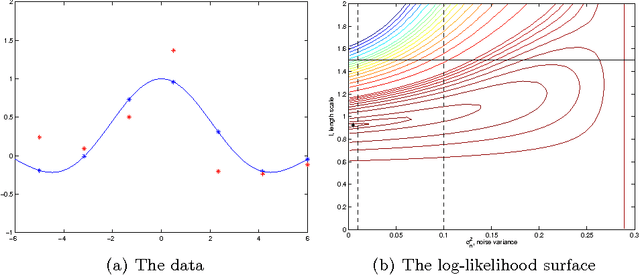

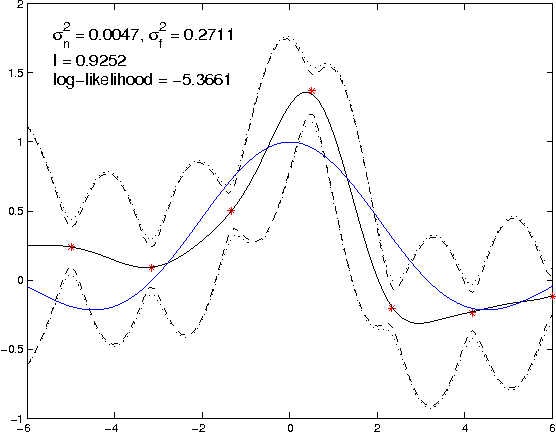

We present techniques for effective Gaussian process (GP) modelling of multiple short time series. These problems are common when applying GP models independently to each gene in a gene expression time series data set. Such sets typically contain very few time points. Naive application of common GP modelling techniques can lead to severe over-fitting or under-fitting in a significant fraction of the fitted models, depending on the details of the data set. We propose avoiding over-fitting by constraining the GP length-scale to values that focus most of the energy spectrum to frequencies below the Nyquist frequency corresponding to the sampling frequency in the data set. Under-fitting can be avoided by more informative priors on observation noise. Combining these methods allows applying GP methods reliably automatically to large numbers of independent instances of short time series. This is illustrated with experiments with both synthetic data and real gene expression data.
Survey of explainable machine learning with visual and granular methods beyond quasi-explanations
Sep 21, 2020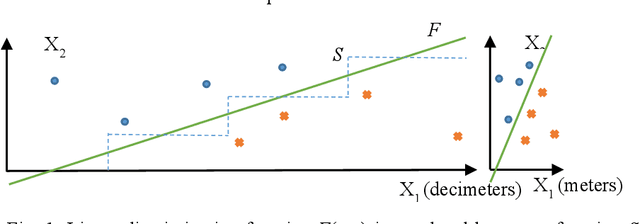
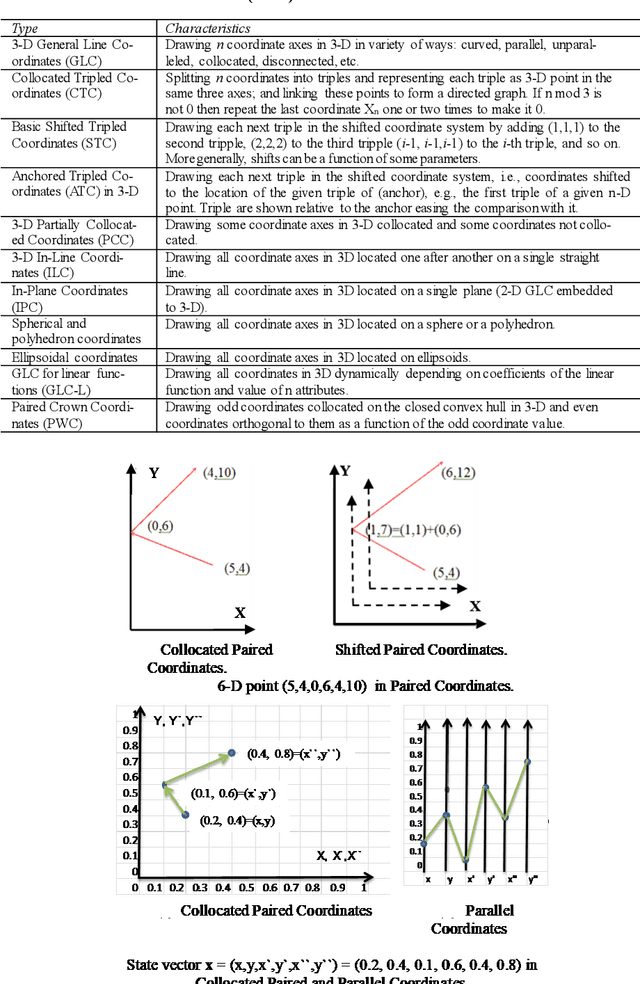
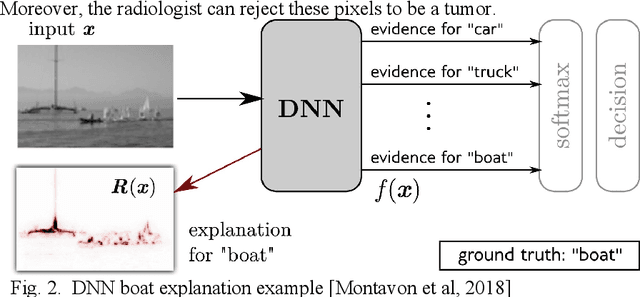
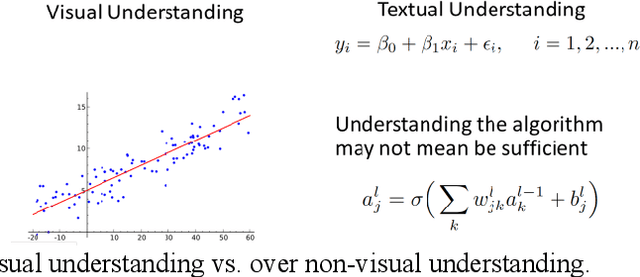
This paper surveys visual methods of explainability of Machine Learning (ML) with focus on moving from quasi-explanations that dominate in ML to domain-specific explanation supported by granular visuals. ML interpretation is fundamentally a human activity and visual methods are more readily interpretable. While efficient visual representations of high-dimensional data exist, the loss of interpretable information, occlusion, and clutter continue to be a challenge, which lead to quasi-explanations. We start with the motivation and the different definitions of explainability. The paper focuses on a clear distinction between quasi-explanations and domain specific explanations, and between explainable and an actually explained ML model that are critically important for the explainability domain. We discuss foundations of interpretability, overview visual interpretability and present several types of methods to visualize the ML models. Next, we present methods of visual discovery of ML models, with the focus on interpretable models, based on the recently introduced concept of General Line Coordinates (GLC). These methods take the critical step of creating visual explanations that are not merely quasi-explanations but are also domain specific visual explanations while these methods themselves are domain-agnostic. The paper includes results on theoretical limits to preserve n-D distances in lower dimensions, based on the Johnson-Lindenstrauss lemma, point-to-point and point-to-graph GLC approaches, and real-world case studies. The paper also covers traditional visual methods for understanding ML models, which include deep learning and time series models. We show that many of these methods are quasi-explanations and need further enhancement to become domain specific explanations. We conclude with outlining open problems and current research frontiers.
Self-Supervised Contrastive Learning for Unsupervised Phoneme Segmentation
Jul 27, 2020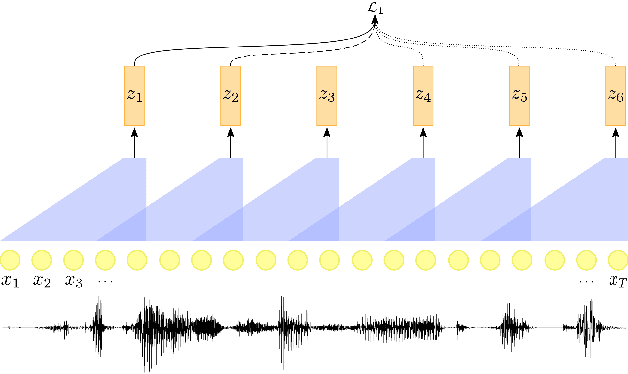
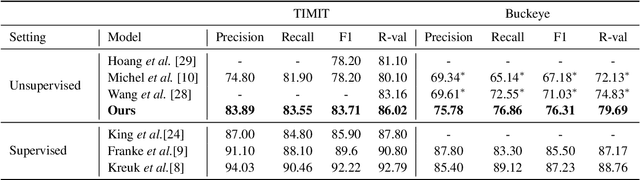
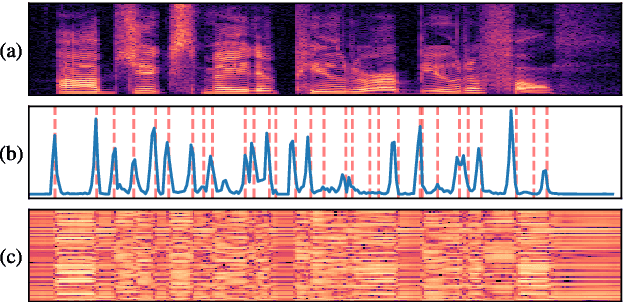
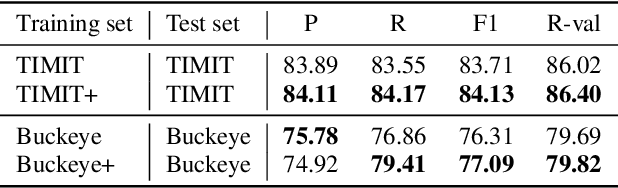
We propose a self-supervised representation learning model for the task of unsupervised phoneme boundary detection. The model is a convolutional neural network that operates directly on the raw waveform. It is optimized to identify spectral changes in the signal using the Noise-Contrastive Estimation principle. At test time, a peak detection algorithm is applied over the model outputs to produce the final boundaries. As such, the proposed model is trained in a fully unsupervised manner with no manual annotations in the form of target boundaries nor phonetic transcriptions. We compare the proposed approach to several unsupervised baselines using both TIMIT and Buckeye corpora. Results suggest that our approach surpasses the baseline models and reaches state-of-the-art performance on both data sets. Furthermore, we experimented with expanding the training set with additional examples from the Librispeech corpus. We evaluated the resulting model on distributions and languages that were not seen during the training phase (English, Hebrew and German) and showed that utilizing additional untranscribed data is beneficial for model performance.
Classifying sleep-wake stages through recurrent neural networks using pulse oximetry signals
Aug 07, 2020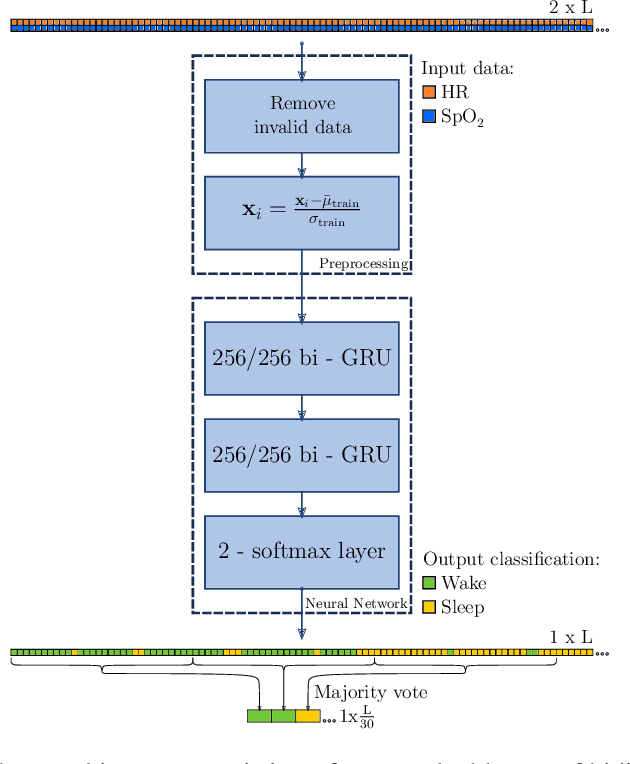
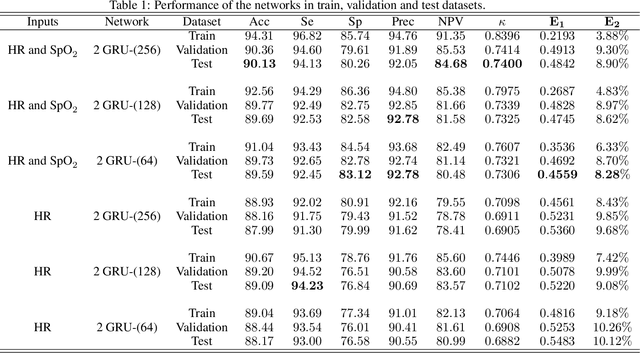
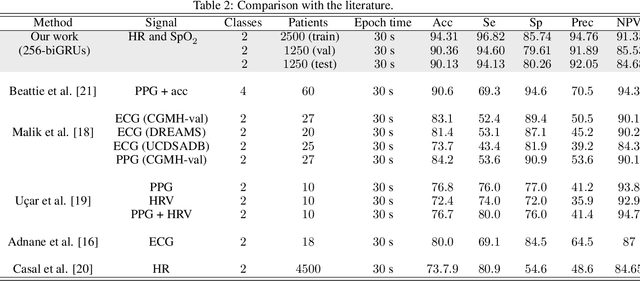
The regulation of the autonomic nervous system changes with the sleep stages causing variations in the physiological variables. We exploit these changes with the aim of classifying the sleep stages in awake or asleep using pulse oximeter signals. We applied a recurrent neural network to heart rate and peripheral oxygen saturation signals to classify the sleep stage every 30 seconds. The network architecture consists of two stacked layers of bidirectional gated recurrent units (GRUs) and a softmax layer to classify the output. In this paper, we used 5000 patients from the Sleep Heart Health Study dataset. 2500 patients were used to train the network, and two subsets of 1250 were used to validate and test the trained models. In the test stage, the best result obtained was 90.13% accuracy, 94.13% sensitivity, 80.26% specificity, 92.05% precision, and 84.68% negative predictive value. Further, the Cohen's Kappa coefficient was 0.74 and the average absolute error percentage to the actual sleep time was 8.9%. The performance of the proposed network is comparable with the state-of-the-art algorithms when they use much more informative signals (except those with EEG).
Semi-supervised Sequential Generative Models
Jun 30, 2020


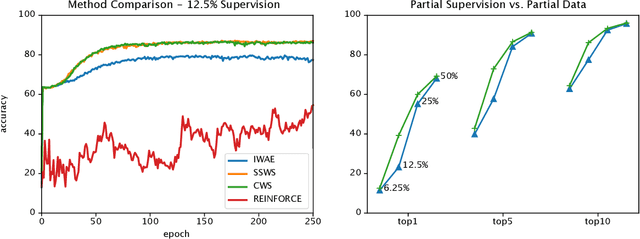
We introduce a novel objective for training deep generative time-series models with discrete latent variables for which supervision is only sparsely available. This instance of semi-supervised learning is challenging for existing methods, because the exponential number of possible discrete latent configurations results in high variance gradient estimators. We first overcome this problem by extending the standard semi-supervised generative modeling objective with reweighted wake-sleep. However, we find that this approach still suffers when the frequency of available labels varies between training sequences. Finally, we introduce a unified objective inspired by teacher-forcing and show that this approach is robust to variable length supervision. We call the resulting method caffeinated wake-sleep (CWS) to emphasize its additional dependence on real data. We demonstrate its effectiveness with experiments on MNIST, handwriting, and fruit fly trajectory data.
Regularized Forward-Backward Decoder for Attention Models
Jun 15, 2020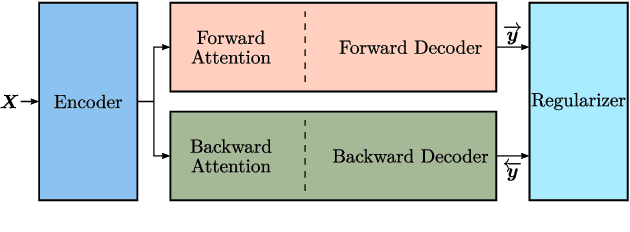
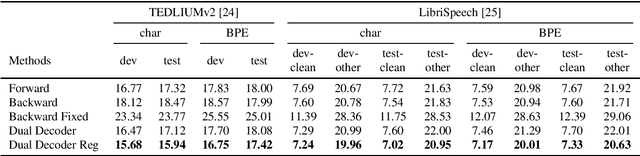
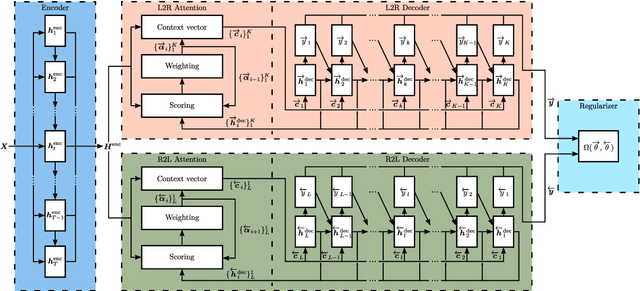
Nowadays, attention models are one of the popular candidates for speech recognition. So far, many studies mainly focus on the encoder structure or the attention module to enhance the performance of these models. However, mostly ignore the decoder. In this paper, we propose a novel regularization technique incorporating a second decoder during the training phase. This decoder is optimized on time-reversed target labels beforehand and supports the standard decoder during training by adding knowledge from future context. Since it is only added during training, we are not changing the basic structure of the network or adding complexity during decoding. We evaluate our approach on the smaller TEDLIUMv2 and the larger LibriSpeech dataset, achieving consistent improvements on both of them.
Learning from Multimodal and Multitemporal Earth Observation Data for Building Damage Mapping
Sep 14, 2020Earth observation technologies, such as optical imaging and synthetic aperture radar (SAR), provide excellent means to monitor ever-growing urban environments continuously. Notably, in the case of large-scale disasters (e.g., tsunamis and earthquakes), in which a response is highly time-critical, images from both data modalities can complement each other to accurately convey the full damage condition in the disaster's aftermath. However, due to several factors, such as weather and satellite coverage, it is often uncertain which data modality will be the first available for rapid disaster response efforts. Hence, novel methodologies that can utilize all accessible EO datasets are essential for disaster management. In this study, we have developed a global multisensor and multitemporal dataset for building damage mapping. We included building damage characteristics from three disaster types, namely, earthquakes, tsunamis, and typhoons, and considered three building damage categories. The global dataset contains high-resolution optical imagery and high-to-moderate-resolution multiband SAR data acquired before and after each disaster. Using this comprehensive dataset, we analyzed five data modality scenarios for damage mapping: single-mode (optical and SAR datasets), cross-modal (pre-disaster optical and post-disaster SAR datasets), and mode fusion scenarios. We defined a damage mapping framework for the semantic segmentation of damaged buildings based on a deep convolutional neural network algorithm. We compare our approach to another state-of-the-art baseline model for damage mapping. The results indicated that our dataset, together with a deep learning network, enabled acceptable predictions for all the data modality scenarios.
Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)
Sep 28, 2020Software Engineering, as a discipline, has matured over the past 5+ decades. The modern world heavily depends on it, so the increased maturity of Software Engineering was an eventuality. Practices like testing and reliable technologies help make Software Engineering reliable enough to build industries upon. Meanwhile, Machine Learning (ML) has also grown over the past 2+ decades. ML is used more and more for research, experimentation and production workloads. ML now commonly powers widely-used products integral to our lives. But ML Engineering, as a discipline, has not widely matured as much as its Software Engineering ancestor. Can we take what we have learned and help the nascent field of applied ML evolve into ML Engineering the way Programming evolved into Software Engineering [1]? In this article we will give a whirlwind tour of Sibyl [2] and TensorFlow Extended (TFX) [3], two successive end-to-end (E2E) ML platforms at Alphabet. We will share the lessons learned from over a decade of applied ML built on these platforms, explain both their similarities and their differences, and expand on the shifts (both mental and technical) that helped us on our journey. In addition, we will highlight some of the capabilities of TFX that help realize several aspects of ML Engineering. We argue that in order to unlock the gains ML can bring, organizations should advance the maturity of their ML teams by investing in robust ML infrastructure and promoting ML Engineering education. We also recommend that before focusing on cutting-edge ML modeling techniques, product leaders should invest more time in adopting interoperable ML platforms for their organizations. In closing, we will also share a glimpse into the future of TFX.
Multi-Level Temporal Pyramid Network for Action Detection
Aug 07, 2020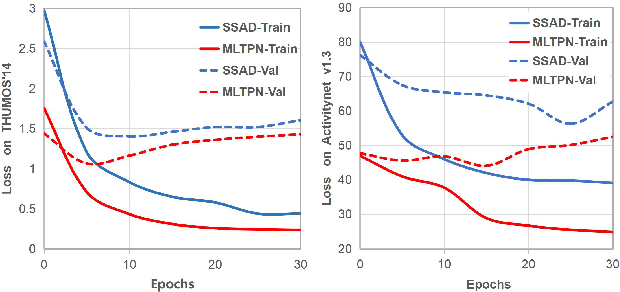
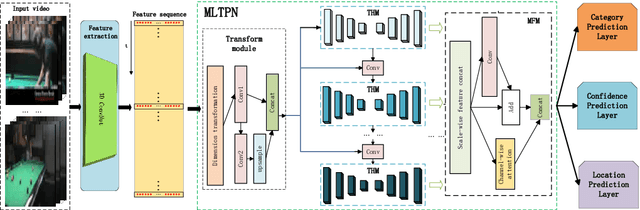
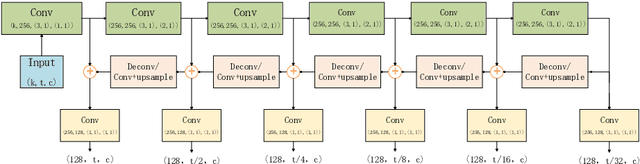
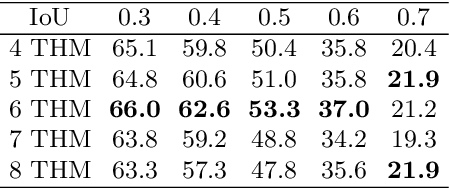
Currently, one-stage frameworks have been widely applied for temporal action detection, but they still suffer from the challenge that the action instances span a wide range of time. The reason is that these one-stage detectors, e.g., Single Shot Multi-Box Detector (SSD), extract temporal features only applying a single-level layer for each head, which is not discriminative enough to perform classification and regression. In this paper, we propose a Multi-Level Temporal Pyramid Network (MLTPN) to improve the discrimination of the features. Specially, we first fuse the features from multiple layers with different temporal resolutions, to encode multi-layer temporal information. We then apply a multi-level feature pyramid architecture on the features to enhance their discriminative abilities. Finally, we design a simple yet effective feature fusion module to fuse the multi-level multi-scale features. By this means, the proposed MLTPN can learn rich and discriminative features for different action instances with different durations. We evaluate MLTPN on two challenging datasets: THUMOS'14 and Activitynet v1.3, and the experimental results show that MLTPN obtains competitive performance on Activitynet v1.3 and outperforms the state-of-the-art approaches on THUMOS'14 significantly.