 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Jan 23, 2020
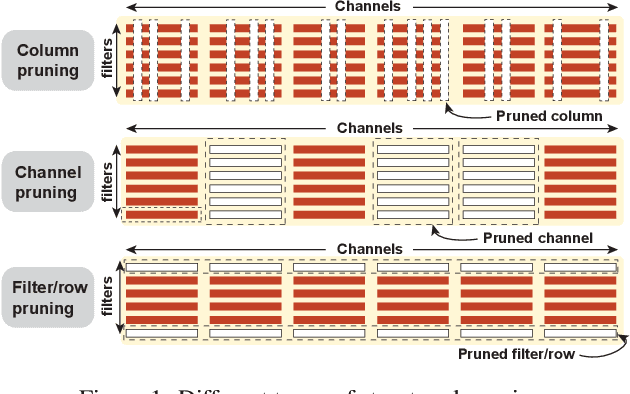
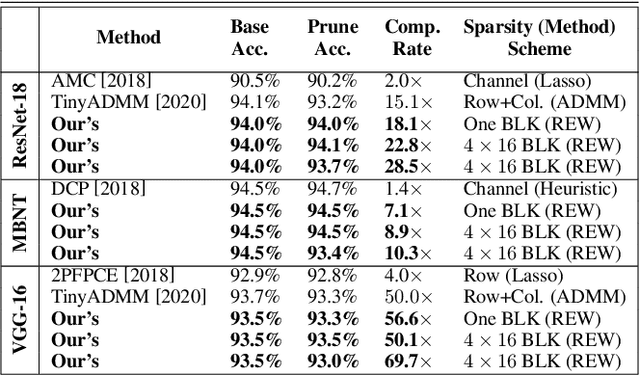
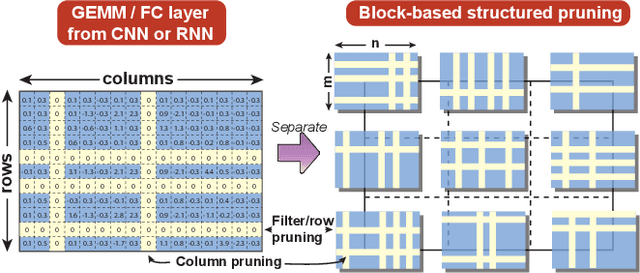
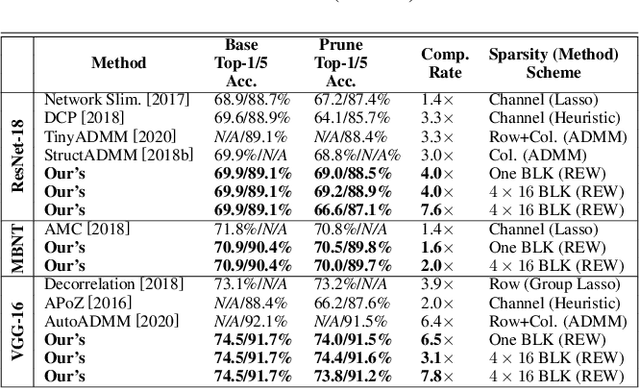
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
From Twitter to Traffic Predictor: Next-Day Morning Traffic Prediction Using Social Media Data
Sep 29, 2020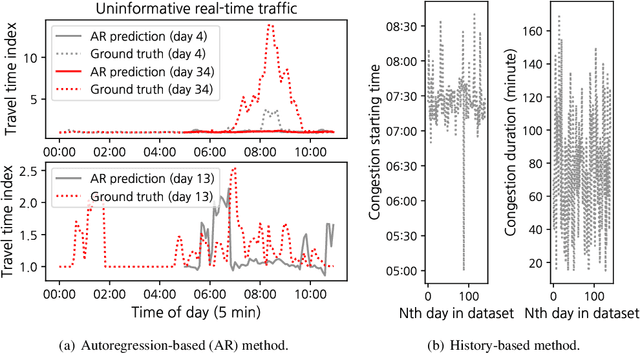



The effectiveness of traditional traffic prediction methods is often extremely limited when forecasting traffic dynamics in early morning. The reason is that traffic can break down drastically during the early morning commute, and the time and duration of this break-down vary substantially from day to day. Early morning traffic forecast is crucial to inform morning-commute traffic management, but they are generally challenging to predict in advance, particularly by midnight. In this paper, we propose to mine Twitter messages as a probing method to understand the impacts of people's work and rest patterns in the evening/midnight of the previous day to the next-day morning traffic. The model is tested on freeway networks in Pittsburgh as experiments. The resulting relationship is surprisingly simple and powerful. We find that, in general, the earlier people rest as indicated from Tweets, the more congested roads will be in the next morning. The occurrence of big events in the evening before, represented by higher or lower tweet sentiment than normal, often implies lower travel demand in the next morning than normal days. Besides, people's tweeting activities in the night before and early morning are statistically associated with congestion in morning peak hours. We make use of such relationships to build a predictive framework which forecasts morning commute congestion using people's tweeting profiles extracted by 5 am or as late as the midnight prior to the morning. The Pittsburgh study supports that our framework can precisely predict morning congestion, particularly for some road segments upstream of roadway bottlenecks with large day-to-day congestion variation. Our approach considerably outperforms those existing methods without Twitter message features, and it can learn meaningful representation of demand from tweeting profiles that offer managerial insights.
Micro-Facial Expression Recognition in Video Based on Optimal Convolutional Neural Network (MFEOCNN) Algorithm
Sep 29, 2020
Facial expression is a standout amongst the most imperative features of human emotion recognition. For demonstrating the emotional states facial expressions are utilized by the people. In any case, recognition of facial expressions has persisted a testing and intriguing issue with regards to PC vision. Recognizing the Micro-Facial expression in video sequence is the main objective of the proposed approach. For efficient recognition, the proposed method utilizes the optimal convolution neural network. Here the proposed method considering the input dataset is the CK+ dataset. At first, by means of Adaptive median filtering preprocessing is performed in the input image. From the preprocessed output, the extracted features are Geometric features, Histogram of Oriented Gradients features and Local binary pattern features. The novelty of the proposed method is, with the help of Modified Lion Optimization (MLO) algorithm, the optimal features are selected from the extracted features. In a shorter computational time, it has the benefits of rapidly focalizing and effectively acknowledging with the aim of getting an overall arrangement or idea. Finally, the recognition is done by Convolution Neural network (CNN). Then the performance of the proposed MFEOCNN method is analysed in terms of false measures and recognition accuracy. This kind of emotion recognition is mainly used in medicine, marketing, E-learning, entertainment, law and monitoring. From the simulation, we know that the proposed approach achieves maximum recognition accuracy of 99.2% with minimum Mean Absolute Error (MAE) value. These results are compared with the existing for MicroFacial Expression Based Deep-Rooted Learning (MFEDRL), Convolutional Neural Network with Lion Optimization (CNN+LO) and Convolutional Neural Network (CNN) without optimization. The simulation of the proposed method is done in the working platform of MATLAB.
Hierarchial Reinforcement Learning in StarCraft II with Human Expertise in Subgoals Selection
Aug 08, 2020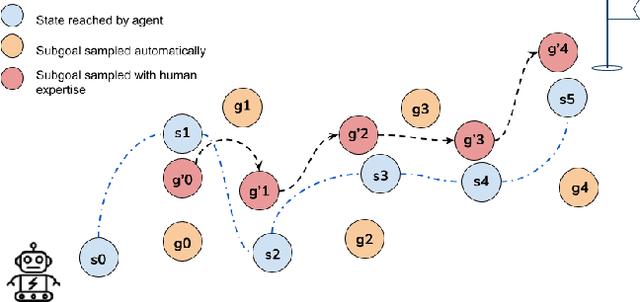
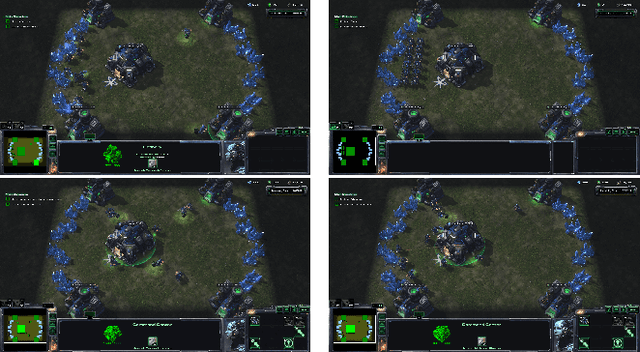
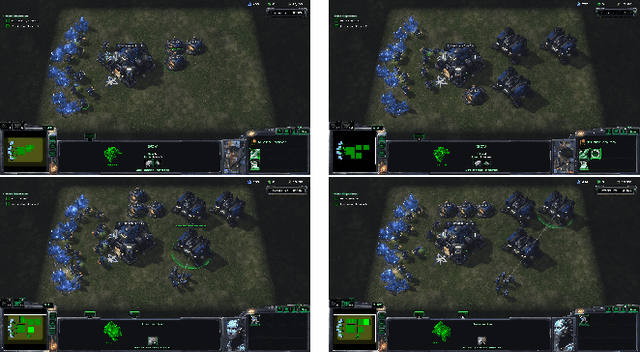
This work is inspired by recent advances in hierarchical reinforcement learning (HRL) (Barto and Mahadevan 2003;Hengst 2010), and improvements in learning efficiency with heuristic-based subgoal selection and hindsight experience replay (HER)(Andrychowicz et al. 2017; Levy et al. 2019). We propose a new method to integrate HRL, HER and effective subgoal selection based on human expertise to support sample-efficient learning and enhance interpretability of the agent's behavior. Human expertise remains indispensable in many areas such as medicine (Buch, Ahmed, and Maruthappu 2018) and law (Cath 2018), where interpretability, explainability and transparency are crucial in the decision making process, for ethical and legal reasons. Our method simplifies the complex task sets for achieving the overall objectives by decomposing into subgoals at different levels of abstraction. Incorporating relevant subjective knowledge also significantly reduces the computational resources spent in exploration for RL, especially in high speed, changing, and complex environments where the transition dynamics cannot be effectively learned and modelled in a short time. Experimental results in two StarCraft II (SC2) minigames demonstrate that our method can achieve better sample efficiency than flat and end-to-end RL methods, and provide an effective method for explaining the agent's performance.
Designing high-fidelity multi-qubit gates for semiconductor quantum dots through deep reinforcement learning
Jun 15, 2020



In this paper, we present a machine learning framework to design high-fidelity multi-qubit gates for quantum processors based on quantum dots in silicon, with qubits encoded in the spin of single electrons. In this hardware architecture, the control landscape is vast and complex, so we use the deep reinforcement learning method to design optimal control pulses to achieve high fidelity multi-qubit gates. In our learning model, a simulator models the physical system of quantum dots and performs the time evolution of the system, and a deep neural network serves as the function approximator to learn the control policy. We evolve the Hamiltonian in the full state-space of the system, and enforce realistic constraints to ensure experimental feasibility.
Unlucky Explorer: A Complete non-Overlapping Map Exploration
May 28, 2020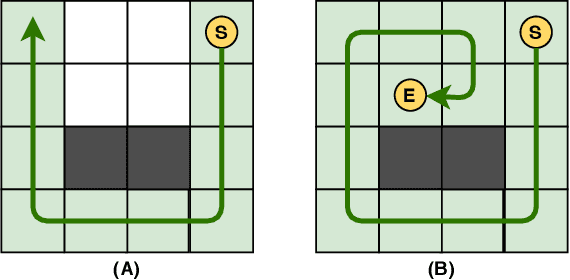
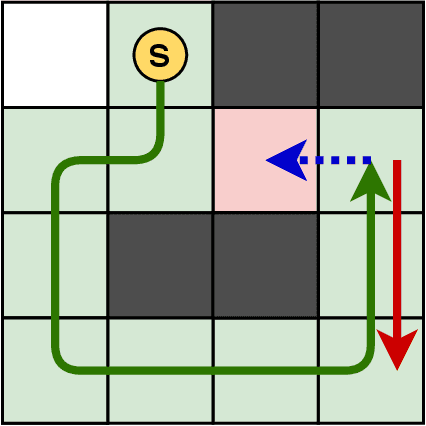
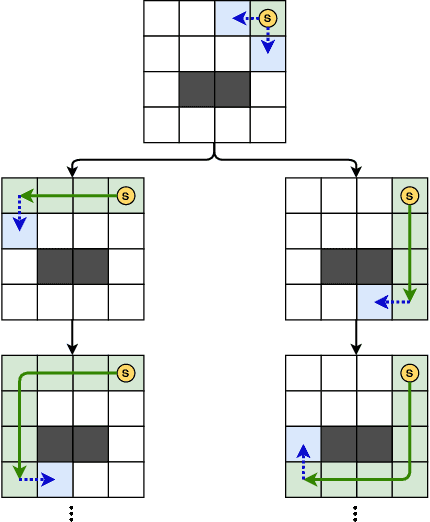
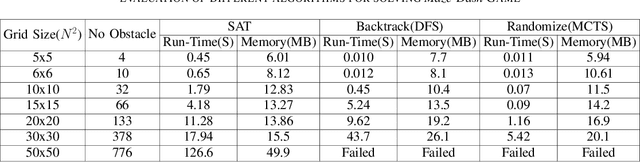
Nowadays, the field of Artificial Intelligence in Computer Games (AI in Games) is going to be more alluring since computer games challenge many aspects of AI with a wide range of problems, particularly general problems. One of these kinds of problems is Exploration, which states that an unknown environment must be explored by one or several agents. In this work, we have first introduced the Maze Dash puzzle as an exploration problem where the agent must find a Hamiltonian Path visiting all the cells. Then, we have investigated to find suitable methods by a focus on Monte-Carlo Tree Search (MCTS) and SAT to solve this puzzle quickly and accurately. An optimization has been applied to the proposed MCTS algorithm to obtain a promising result. Also, since the prefabricated test cases of this puzzle are not large enough to assay the proposed method, we have proposed and employed a technique to generate solvable test cases to evaluate the approaches. Eventually, the MCTS-based method has been assessed by the auto-generated test cases and compared with our implemented SAT approach that is considered a good rival. Our comparison indicates that the MCTS-based approach is an up-and-coming method that could cope with the test cases with small and medium sizes with faster run-time compared to SAT. However, for certain discussed reasons, including the features of the problem, tree search organization, and also the approach of MCTS in the Simulation step, MCTS takes more time to execute in Large size scenarios. Consequently, we have found the bottleneck for the MCTS-based method in significant test cases that could be improved in two real-world problems.
Survey of explainable machine learning with visual and granular methods beyond quasi-explanations
Sep 21, 2020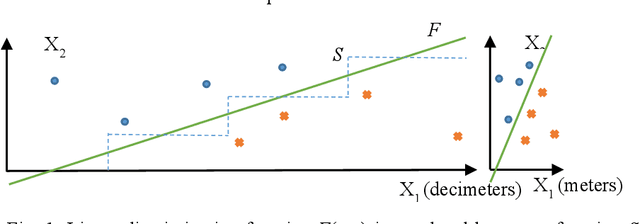
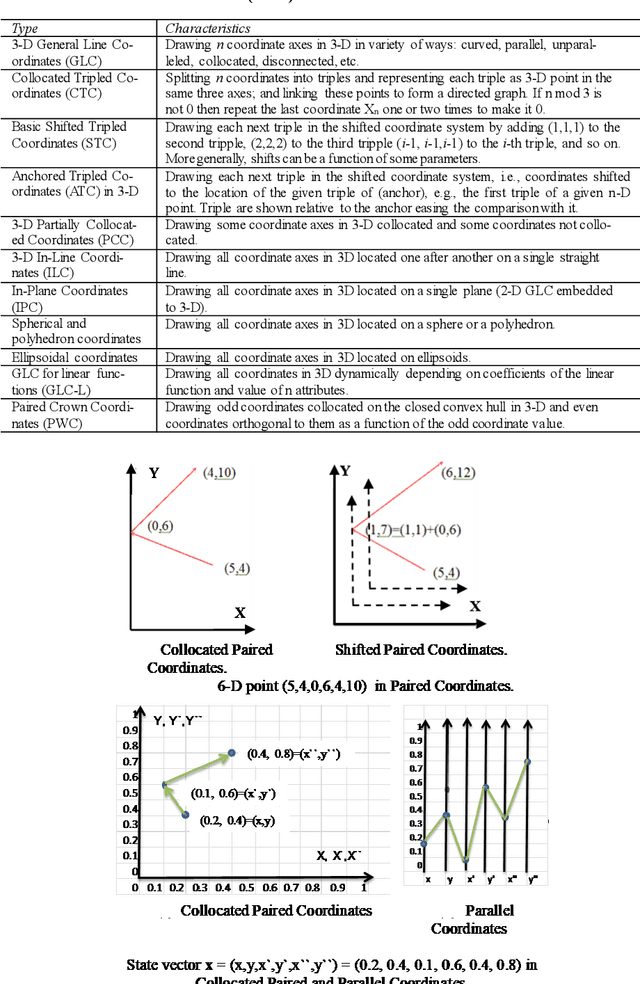
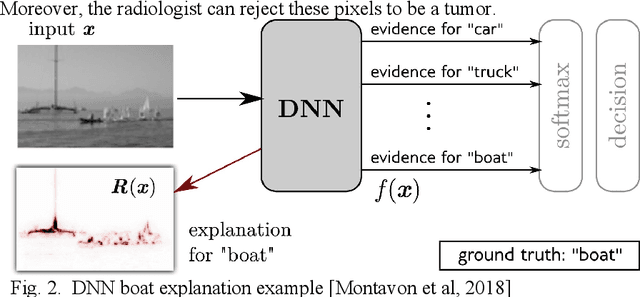
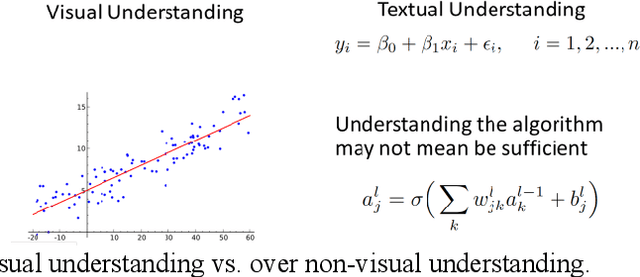
This paper surveys visual methods of explainability of Machine Learning (ML) with focus on moving from quasi-explanations that dominate in ML to domain-specific explanation supported by granular visuals. ML interpretation is fundamentally a human activity and visual methods are more readily interpretable. While efficient visual representations of high-dimensional data exist, the loss of interpretable information, occlusion, and clutter continue to be a challenge, which lead to quasi-explanations. We start with the motivation and the different definitions of explainability. The paper focuses on a clear distinction between quasi-explanations and domain specific explanations, and between explainable and an actually explained ML model that are critically important for the explainability domain. We discuss foundations of interpretability, overview visual interpretability and present several types of methods to visualize the ML models. Next, we present methods of visual discovery of ML models, with the focus on interpretable models, based on the recently introduced concept of General Line Coordinates (GLC). These methods take the critical step of creating visual explanations that are not merely quasi-explanations but are also domain specific visual explanations while these methods themselves are domain-agnostic. The paper includes results on theoretical limits to preserve n-D distances in lower dimensions, based on the Johnson-Lindenstrauss lemma, point-to-point and point-to-graph GLC approaches, and real-world case studies. The paper also covers traditional visual methods for understanding ML models, which include deep learning and time series models. We show that many of these methods are quasi-explanations and need further enhancement to become domain specific explanations. We conclude with outlining open problems and current research frontiers.
Signs in time: Encoding human motion as a temporal image
Aug 06, 2016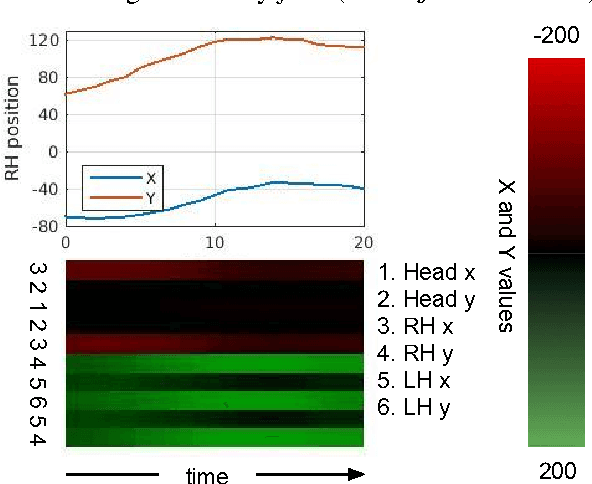

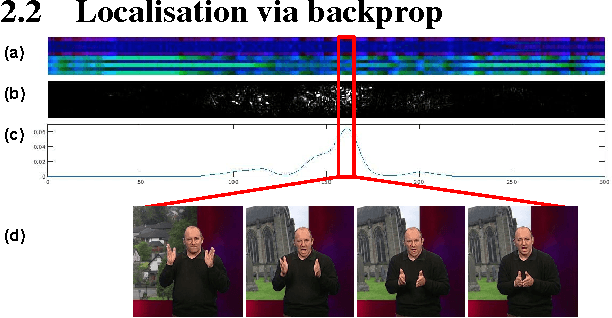
The goal of this work is to recognise and localise short temporal signals in image time series, where strong supervision is not available for training. To this end we propose an image encoding that concisely represents human motion in a video sequence in a form that is suitable for learning with a ConvNet. The encoding reduces the pose information from an image to a single column, dramatically diminishing the input requirements for the network, but retaining the essential information for recognition. The encoding is applied to the task of recognizing and localizing signed gestures in British Sign Language (BSL) videos. We demonstrate that using the proposed encoding, signs as short as 10 frames duration can be learnt from clips lasting hundreds of frames using only weak (clip level) supervision and with considerable label noise.
Particle detection and tracking in fluorescence time-lapse imaging: a contrario approach
Dec 22, 2016
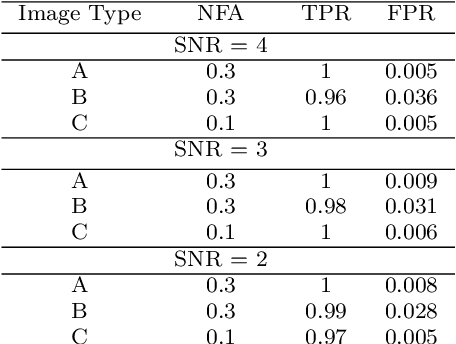
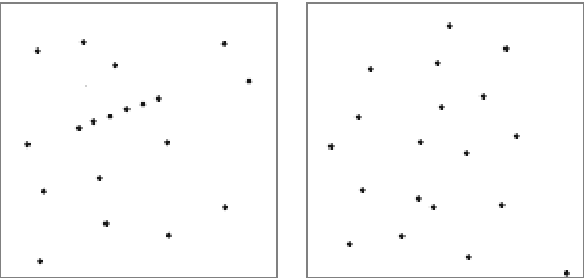

This paper proposes a probabilistic approach for the detection and the tracking of particles in fluorescent time-lapse imaging. In the presence of a very noised and poor-quality data, particles and trajectories can be characterized by an a contrario model, that estimates the probability of observing the structures of interest in random data. This approach, first introduced in the modeling of human visual perception and then successfully applied in many image processing tasks, leads to algorithms that neither require a previous learning stage, nor a tedious parameter tuning and are very robust to noise. Comparative evaluations against a well-established baseline show that the proposed approach outperforms the state of the art.
Self-Supervised Contrastive Learning for Unsupervised Phoneme Segmentation
Jul 27, 2020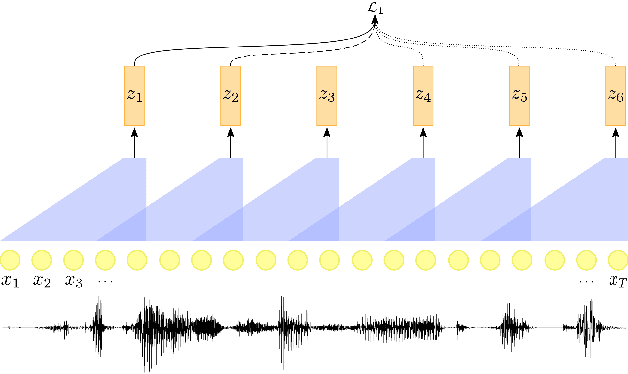
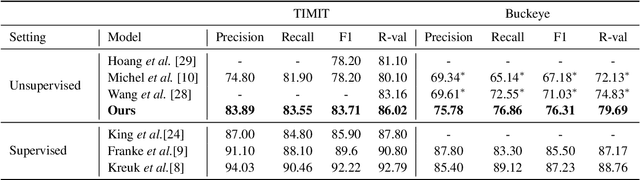
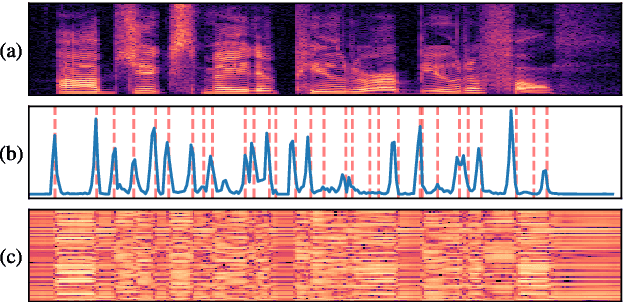
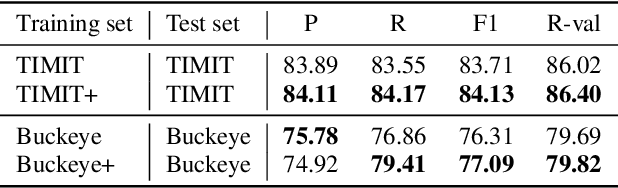
We propose a self-supervised representation learning model for the task of unsupervised phoneme boundary detection. The model is a convolutional neural network that operates directly on the raw waveform. It is optimized to identify spectral changes in the signal using the Noise-Contrastive Estimation principle. At test time, a peak detection algorithm is applied over the model outputs to produce the final boundaries. As such, the proposed model is trained in a fully unsupervised manner with no manual annotations in the form of target boundaries nor phonetic transcriptions. We compare the proposed approach to several unsupervised baselines using both TIMIT and Buckeye corpora. Results suggest that our approach surpasses the baseline models and reaches state-of-the-art performance on both data sets. Furthermore, we experimented with expanding the training set with additional examples from the Librispeech corpus. We evaluated the resulting model on distributions and languages that were not seen during the training phase (English, Hebrew and German) and showed that utilizing additional untranscribed data is beneficial for model performance.