 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multivariate Relations Aggregation Learning in Social Networks
Aug 09, 2020

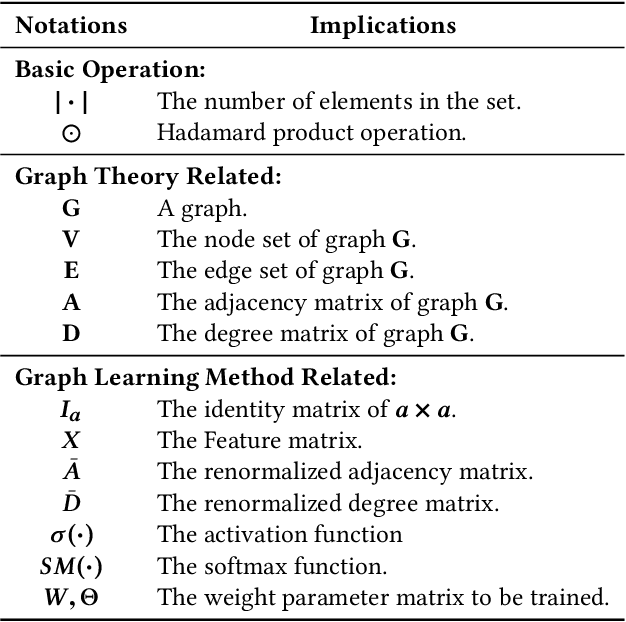
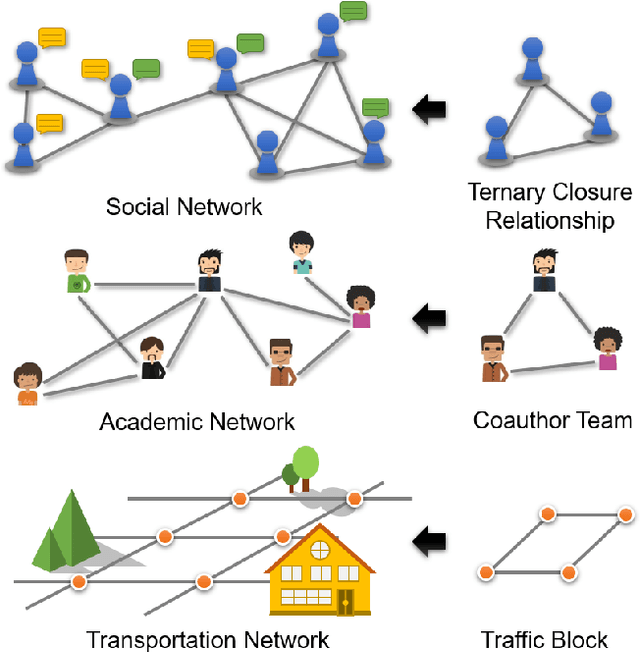
Multivariate relations are general in various types of networks, such as biological networks, social networks, transportation networks, and academic networks. Due to the principle of ternary closures and the trend of group formation, the multivariate relationships in social networks are complex and rich. Therefore, in graph learning tasks of social networks, the identification and utilization of multivariate relationship information are more important. Existing graph learning methods are based on the neighborhood information diffusion mechanism, which often leads to partial omission or even lack of multivariate relationship information, and ultimately affects the accuracy and execution efficiency of the task. To address these challenges, this paper proposes the multivariate relationship aggregation learning (MORE) method, which can effectively capture the multivariate relationship information in the network environment. By aggregating node attribute features and structural features, MORE achieves higher accuracy and faster convergence speed. We conducted experiments on one citation network and five social networks. The experimental results show that the MORE model has higher accuracy than the GCN (Graph Convolutional Network) model in node classification tasks, and can significantly reduce time cost.
* 11 pages, 6 figures
Named Entity Extraction with Finite State Transducers
Jun 20, 2020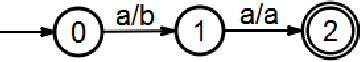
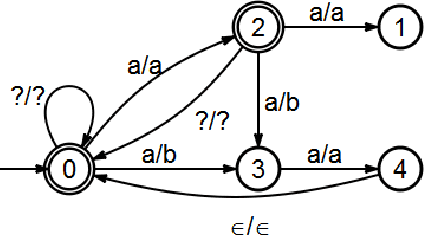
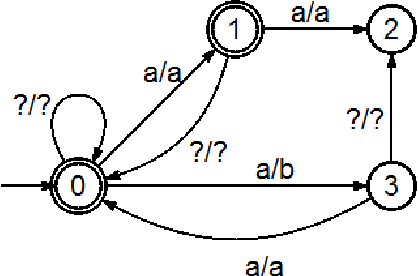
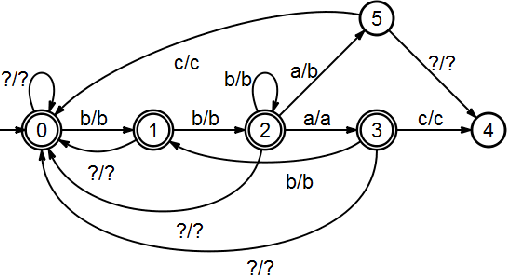
We describe a named entity tagging system that requires minimal linguistic knowledge and can be applied to more target languages without substantial changes. The system is based on the ideas of the Brill's tagger which makes it really simple. Using supervised machine learning, we construct a series of automatons (or transducers) in order to tag a given text. The final model is composed entirely of automatons and it requires a lineal time for tagging. It was tested with the Spanish data set provided in the CoNLL-$2002$ attaining an overall $F_{\beta = 1}$ measure of $60\%.$ Also, we present an algorithm for the construction of the final transducer used to encode all the learned contextual rules.
ISSAFE: Improving Semantic Segmentation in Accidents by Fusing Event-based Data
Aug 20, 2020
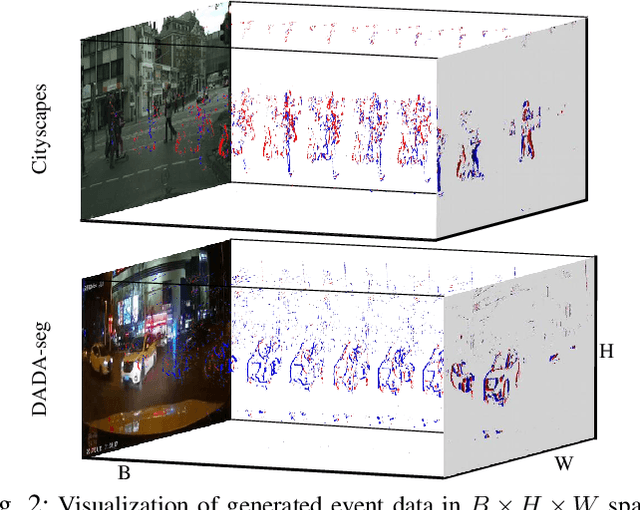
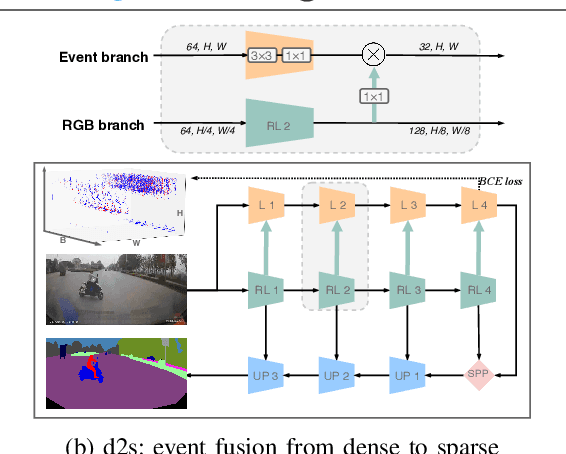
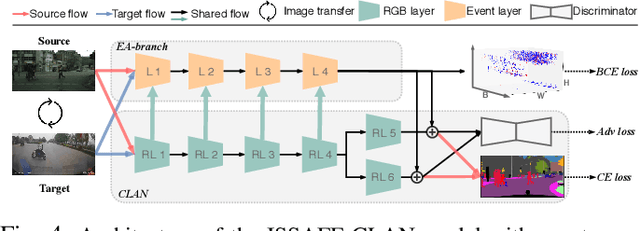
To bring autonomous vehicles closer to real-world applications, a major task is to ensure the safety of all traffic participants. In addition to the high accuracy under controlled conditions, the assistance system is still supposed to obtain robust perception against extreme situations, especially in accident scenarios, which involve object collisions, deformations, overturns, etc. However, models trained on common datasets may suffer from a large performance degradation when applied in these challenging scenes. To tackle this issue, we present a rarely addressed task regarding semantic segmentation in accident scenarios, along with an associated large-scale dataset DADA-seg. Our dataset contains 313 sequences with 40 frames each, of which the time windows are located before and during a traffic accident. For benchmarking the segmentation performance, every 11th frame is manually annotated with reference to Cityscapes. Furthermore, we propose a novel event-based multi-modal segmentation architecture ISSAFE. Our experiments indicate that event-based data can provide complementary information to stabilize semantic segmentation under adverse conditions by preserving fine-grain motion of fast-moving foreground (crash objects) in accidents. Compared with state-of-the-art models, our approach achieves 30.0% mIoU with 9.9% performance gain on the proposed evaluation set.
Lightweight Mask R-CNN for Long-Range Wireless Power Transfer Systems
Apr 19, 2020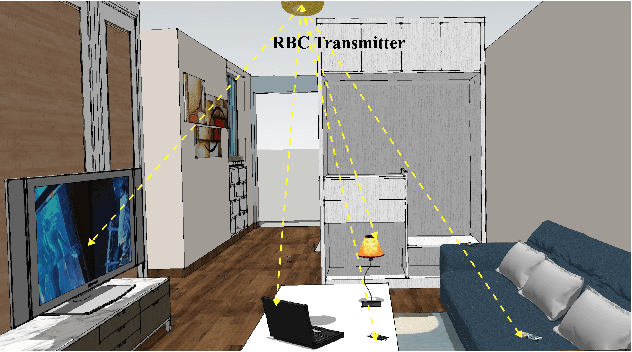
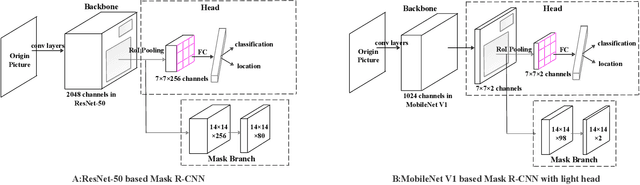


Resonant Beam Charging (RBC) is a wireless charging technology which supports multi-watt power transfer over meter-level distance. The features of safety, mobility and simultaneous charging capability enable RBC to charge multiple mobile devices safely at the same time. To detect the devices that need to be charged, a Mask R-CNN based dection model is proposed in previous work. However, considering the constraints of the RBC system, it's not easy to apply Mask R-CNN in lightweight hardware-embedded devices because of its heavy model and huge computation. Thus, we propose a machine learning detection approach which provides a lighter and faster model based on traditional Mask R-CNN. The proposed approach makes the object detection much easier to be transplanted on mobile devices and reduce the burden of hardware computation. By adjusting the structure of the backbone and the head part of Mask R-CNN, we reduce the average detection time from $1.02\mbox{s}$ per image to $0.6132\mbox{s}$, and reduce the model size from $245\mbox{MB}$ to $47.1\mbox{MB}$. The improved model is much more suitable for the application in the RBC system.
Improving Dependability of Neuromorphic Computing With Non-Volatile Memory
Jun 10, 2020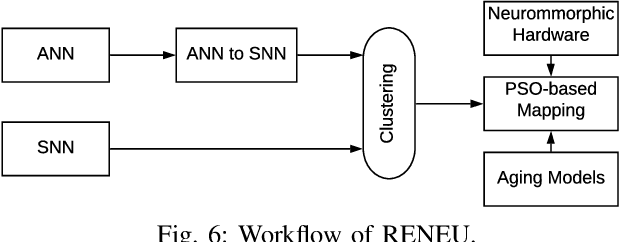
As process technology continues to scale aggressively, circuit aging in a neuromorphic hardware due to negative bias temperature instability (NBTI) and time-dependent dielectric breakdown (TDDB) is becoming a critical reliability issue and is expected to proliferate when using non-volatile memory (NVM) for synaptic storage. This is because an NVM requires high voltage and current to access its synaptic weight, which further accelerates the circuit aging in a neuromorphic hardware. Current methods for qualifying reliability are overly conservative, since they estimate circuit aging considering worst-case operating conditions and unnecessarily constrain performance. This paper proposes RENEU, a reliability-oriented approach to map machine learning applications to neuromorphic hardware, with the aim of improving system-wide reliability without compromising key performance metrics such as execution time of these applications on the hardware. Fundamental to RENEU is a novel formulation of the aging of CMOS-based circuits in a neuromorphic hardware considering different failure mechanisms. Using this formulation, RENEU develops a system-wide reliability model which can be used inside a design-space exploration framework involving the mapping of neurons and synapses to the hardware. To this end, RENEU uses an instance of Particle Swarm Optimization (PSO) to generate mappings that are Pareto-optimal in terms of performance and reliability. We evaluate RENEU using different machine learning applications on a state-of-the-art neuromorphic hardware with NVM synapses. Our results demonstrate an average 38\% reduction in circuit aging, leading to an average 18% improvement in the lifetime of the hardware compared to current practices. RENEU only introduces a marginal performance overhead of 5% compared to a performance-oriented state-of-the-art.
Distributed Consistent Multi-Robot Semantic Localization and Mapping
Jul 06, 2020


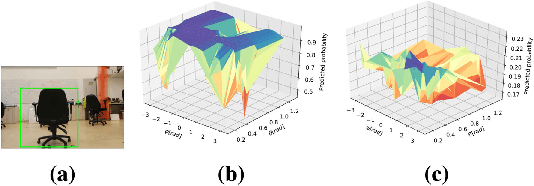
We present an approach for multi-robot consistent distributed localization and semantic mapping in an unknown environment, considering scenarios with classification ambiguity, where objects' visual appearance generally varies with viewpoint. Our approach addresses such a setting by maintaining a distributed posterior hybrid belief over continuous localization and discrete classification variables. In particular, we utilize a viewpoint-dependent classifier model to leverage the coupling between semantics and geometry. Moreover, our approach yields a consistent estimation of both continuous and discrete variables, with the latter being addressed for the first time, to the best of our knowledge. We evaluate the performance of our approach in a multi-robot semantic SLAM simulation and in a real-world experiment, demonstrating an increase in both classification and localization accuracy compared to maintaining a hybrid belief using local information only.
* 28 pages, 73 figures, for an associated video, see https://youtu.be/jATog1snfwc
Autonomous Social Distancing in Urban Environments using a Quadruped Robot
Aug 20, 2020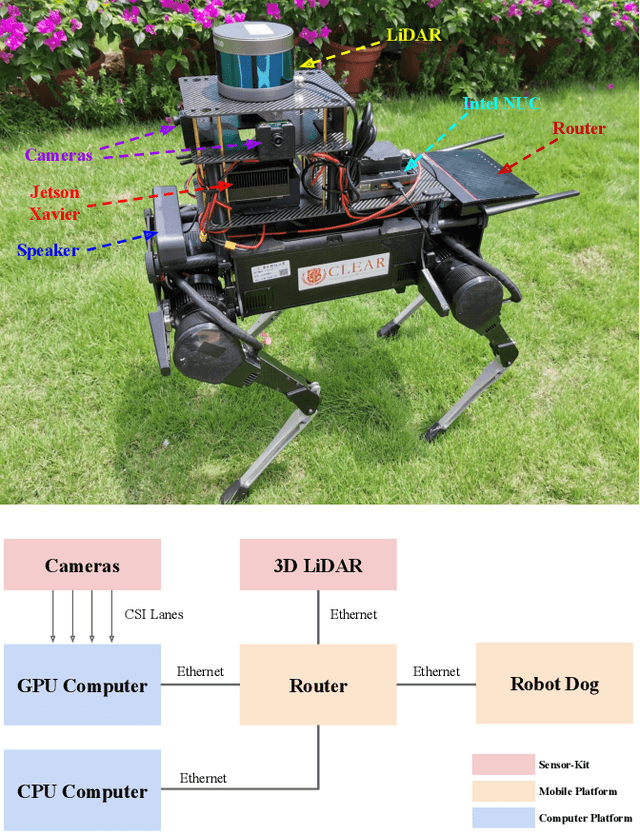
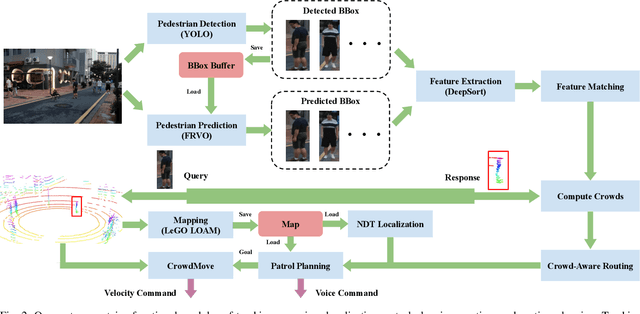
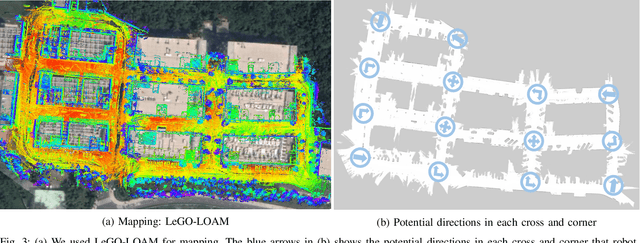
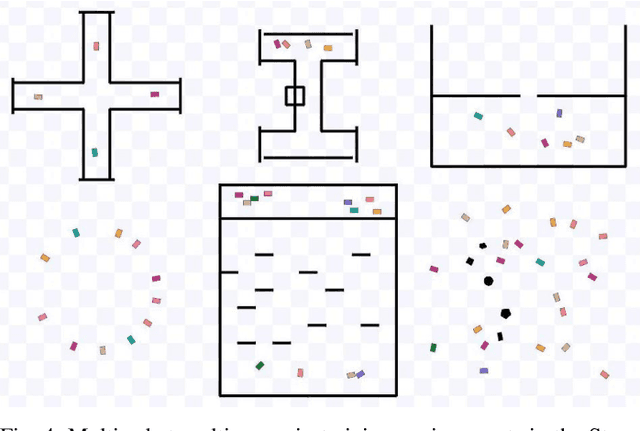
COVID-19 pandemic has become a global challenge faced by people all over the world. Social distancing has been proved to be an effective practice to reduce the spread of COVID-19. Against this backdrop, we propose that the surveillance robots can not only monitor but also promote social distancing. Robots can be flexibly deployed and they can take precautionary actions to remind people of practicing social distancing. In this paper, we introduce a fully autonomous surveillance robot based on a quadruped platform that can promote social distancing in complex urban environments. Specifically, to achieve autonomy, we mount multiple cameras and a 3D LiDAR on the legged robot. The robot then uses an onboard real-time social distancing detection system to track nearby pedestrian groups. Next, the robot uses a crowd-aware navigation algorithm to move freely in highly dynamic scenarios. The robot finally uses a crowd-aware routing algorithm to effectively promote social distancing by using human-friendly verbal cues to send suggestions to over-crowded pedestrians. We demonstrate and validate that our robot can be operated autonomously by conducting several experiments in various urban scenarios.
No-regret Algorithms for Multi-task Bayesian Optimization
Aug 20, 2020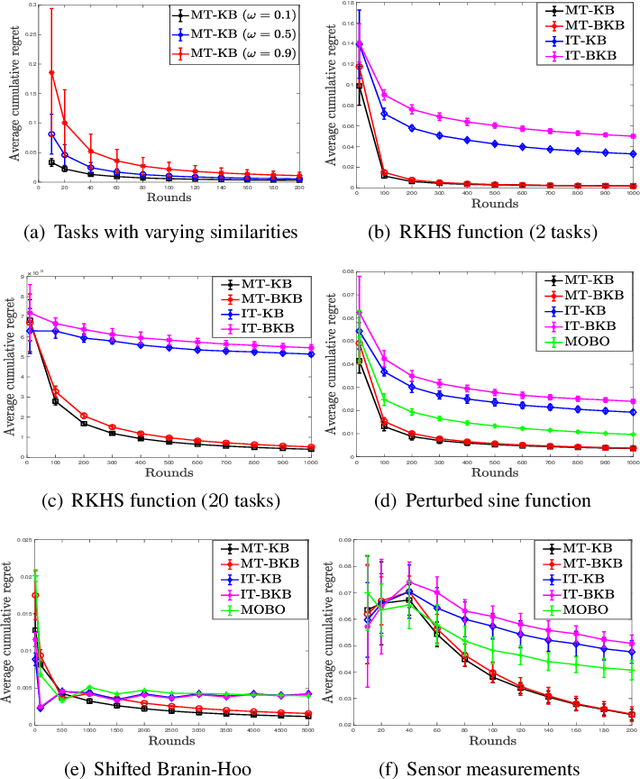
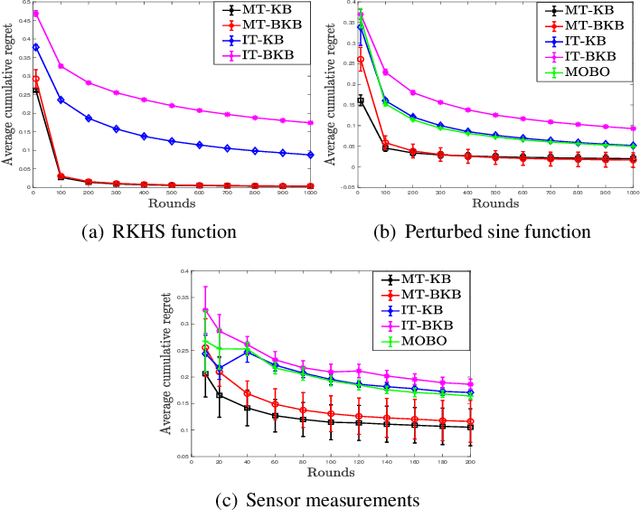
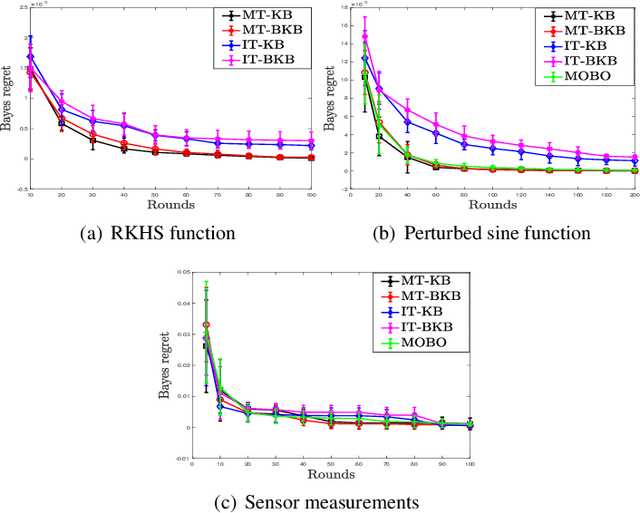
We consider multi-objective optimization (MOO) of an unknown vector-valued function in the non-parametric Bayesian optimization (BO) setting, with the aim being to learn points on the Pareto front of the objectives. Most existing BO algorithms do not model the fact that the multiple objectives, or equivalently, tasks can share similarities, and even the few that do lack rigorous, finite-time regret guarantees that capture explicitly inter-task structure. In this work, we address this problem by modelling inter-task dependencies using a multi-task kernel and develop two novel BO algorithms based on random scalarizations of the objectives. Our algorithms employ vector-valued kernel regression as a stepping stone and belong to the upper confidence bound class of algorithms. Under a smoothness assumption that the unknown vector-valued function is an element of the reproducing kernel Hilbert space associated with the multi-task kernel, we derive worst-case regret bounds for our algorithms that explicitly capture the similarities between tasks. We numerically benchmark our algorithms on both synthetic and real-life MOO problems, and show the advantages offered by learning with multi-task kernels.
Using context to make gas classifiers robust to sensor drift
Mar 16, 2020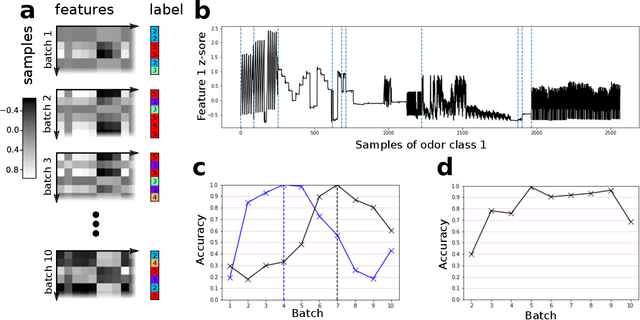
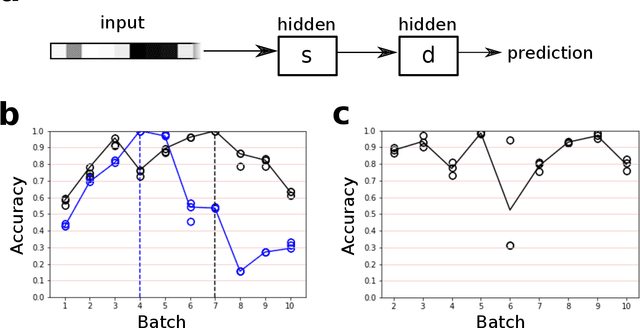
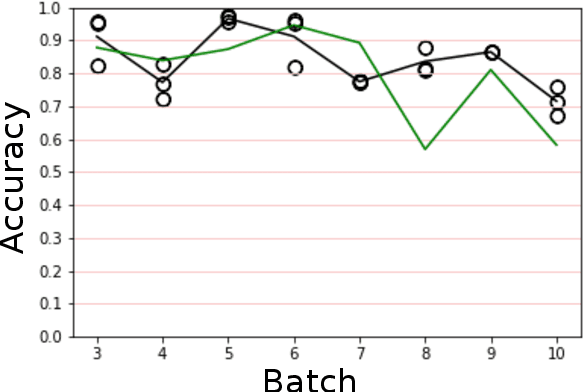
The interaction of a gas particle with a metal-oxide based gas sensor changes the sensor irreversibly. The compounded changes, referred to as sensor drift, are unstable, but adaptive algorithms can sustain the accuracy of odor sensor systems. Here we focus on extending the lifetime of sensor systems without additional data acquisition by transfering knowledge from one time window to a subsequent one after drift has occurred. To support generalization across sensor states, we introduce a context-based neural network model which forms a latent representation of sensor state. We tested our models to classify samples taken from unseen subsequent time windows and discovered favorable accuracy compared to drift-naive and ensemble methods on a gas sensor array drift dataset. By reducing the effect that sensor drift has on classification accuracy, context-based models may extend the effective lifetime of gas identification systems in practical settings.
An evolutionary perspective on the design of neuromorphic shape filters
Aug 30, 2020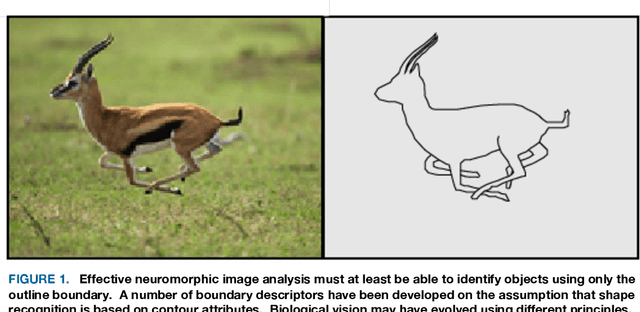
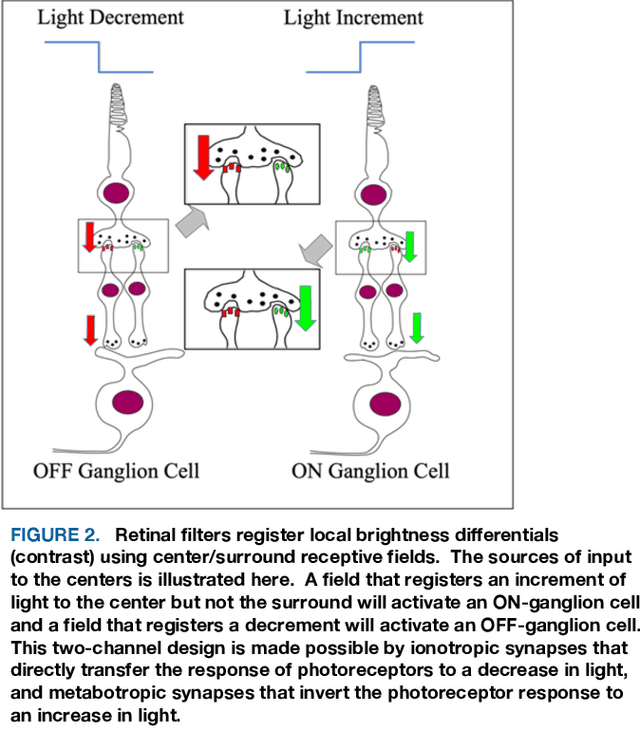
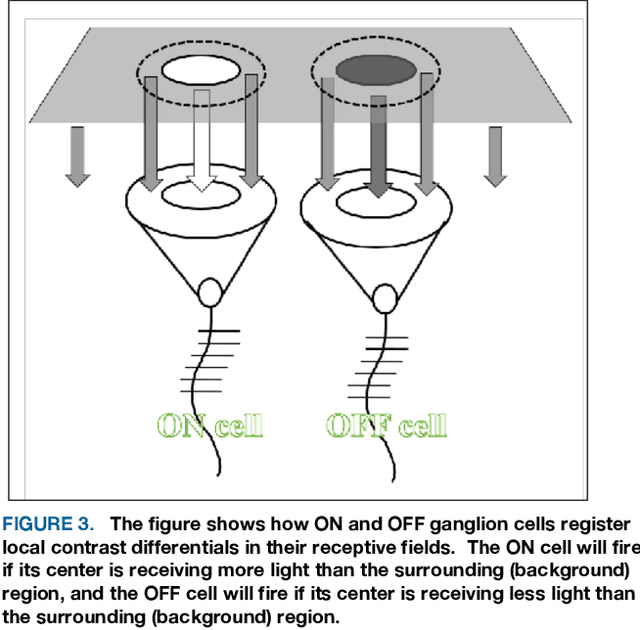
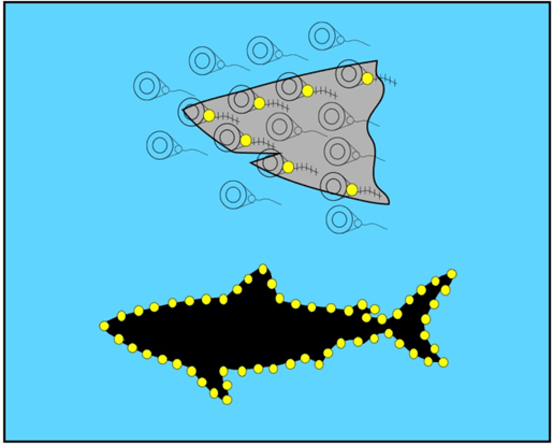
A substantial amount of time and energy has been invested to develop machine vision using connectionist (neural network) principles. Most of that work has been inspired by theories advanced by neuroscientists and behaviorists for how cortical systems store stimulus information. Those theories call for information flow through connections among several neuron populations, with the initial connections being random (or at least non-functional). Then the strength or location of connections are modified through training trials to achieve an effective output, such as the ability to identify an object. Those theories ignored the fact that animals that have no cortex, e.g., fish, can demonstrate visual skills that outpace the best neural network models. Neural circuits that allow for immediate effective vision and quick learning have been preprogrammed by hundreds of millions of years of evolution and the visual skills are available shortly after hatching. Cortical systems may be providing advanced image processing, but most likely are using design principles that had been proven effective in simpler systems. The present article provides a brief overview of retinal and cortical mechanisms for registering shape information, with the hope that it might contribute to the design of shape-encoding circuits that more closely match the mechanisms of biological vision.