 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Adaptive Type-2 Fuzzy Filter with Exclusively Two Fuzzy Membership Function for Filtering Salt and Pepper Noise
Aug 10, 2020
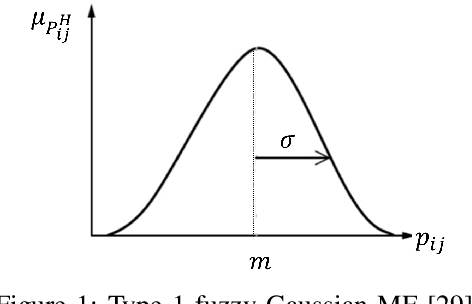
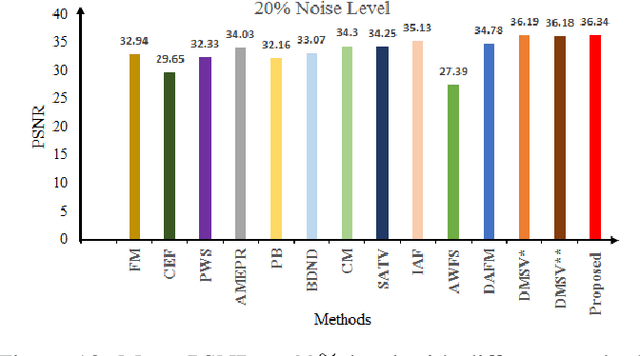
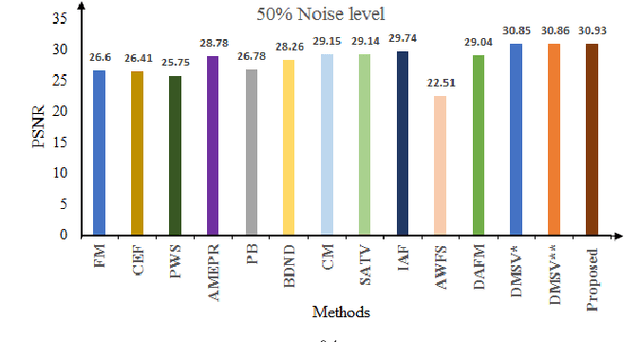
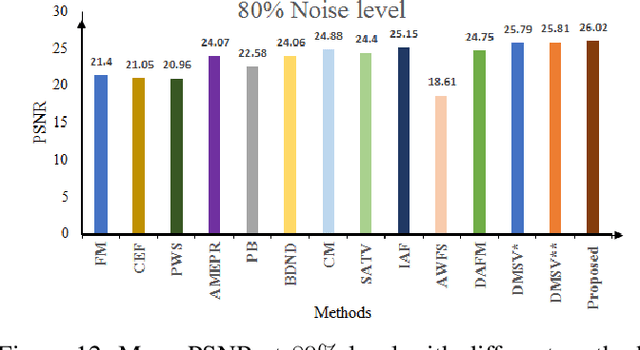
Image denoising is one of the preliminary steps in image processing methods in which the presence of noise can deteriorate the image quality. To overcome this limitation, in this paper a improved two-stage fuzzy filter is proposed for filtering salt and pepper noise from the images. In the first-stage, the pixels in the image are categorized as good or noisy based on adaptive thresholding using type-2 fuzzy logic with exclusively two different membership functions in the filter window. In the second-stage, the noisy pixels are denoised using modified ordinary fuzzy logic in the respective filter window. The proposed filter is validated on standard images with various noise levels. The proposed filter removes the noise and preserves useful image characteristics, i.e., edges and corners at higher noise level. The performance of the proposed filter is compared with the various state-of-the-art methods in terms of peak signal-to-noise ratio and computation time. To show the effectiveness of filter statistical tests, i.e., Friedman test and Bonferroni-Dunn (BD) test are also carried out which clearly ascertain that the proposed filter outperforms in comparison of various filtering approaches.
A Review of Automatically Diagnosing COVID-19 based on Scanning Image
Jun 09, 2020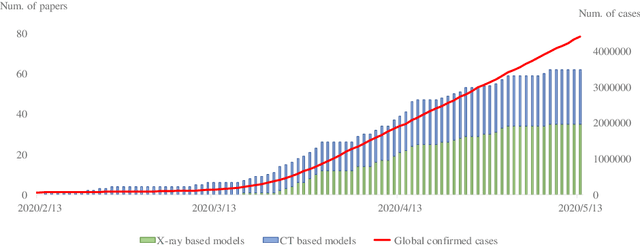
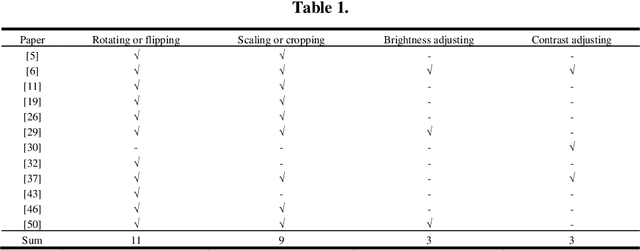
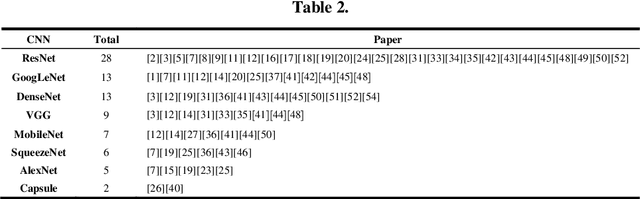
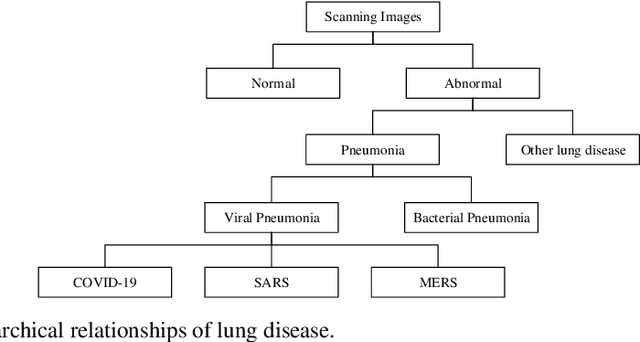
The pandemic of COVID-19 has caused millions of infectious. Due to the false-negative rate and the time cost of conventional RT-PCR tests, X-ray images and Computed Tomography (CT) images based diagnosing become widely adopted. Therefore, researchers of the computer vision area have developed many automatic diagnosing models to help the radiologists and pro-mote the diagnosing accuracy. In this paper, we present a review of these recently emerging automatic diagnosing models. 62 models from 14, February to 5, May, 2020 are involved. We analyzed the models from the perspective of preprocessing, feature extraction, classification, and evaluation. Then we pointed out that domain adaption in transfer learning and interpretability promotion are the possible future directions.
Deep Neural Networks for the Correction of Mie Scattering in Fourier-Transformed Infrared Spectra of Biological Samples
Feb 18, 2020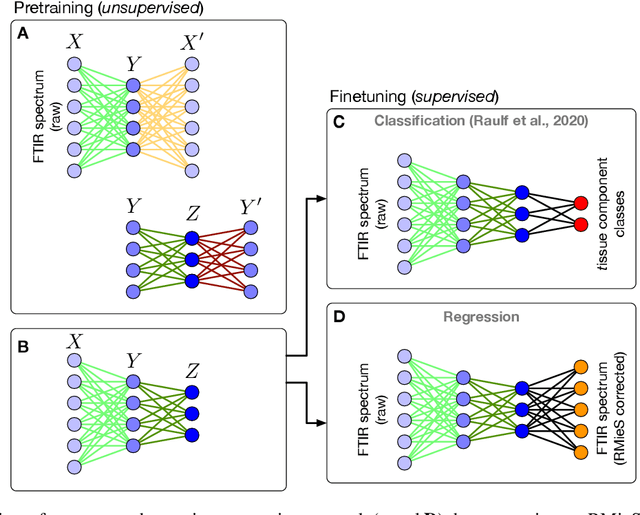


Infrared spectra obtained from cell or tissue specimen have commonly been observed to involve a significant degree of (resonant) Mie scattering, which often overshadows biochemically relevant spectral information by a non-linear, non-additive spectral component in Fourier transformed infrared (FTIR) spectroscopic measurements. Correspondingly, many successful machine learning approaches for FTIR spectra have relied on preprocessing procedures that computationally remove the scattering components from an infrared spectrum. We propose an approach to approximate this complex preprocessing function using deep neural networks. As we demonstrate, the resulting model is not just several orders of magnitudes faster, which is important for real-time clinical applications, but also generalizes strongly across different tissue types. Furthermore, our proposed method overcomes the trade-off between computation time and the corrected spectrum being biased towards an artificial reference spectrum.
Deep Learning Techniques for Geospatial Data Analysis
Aug 30, 2020
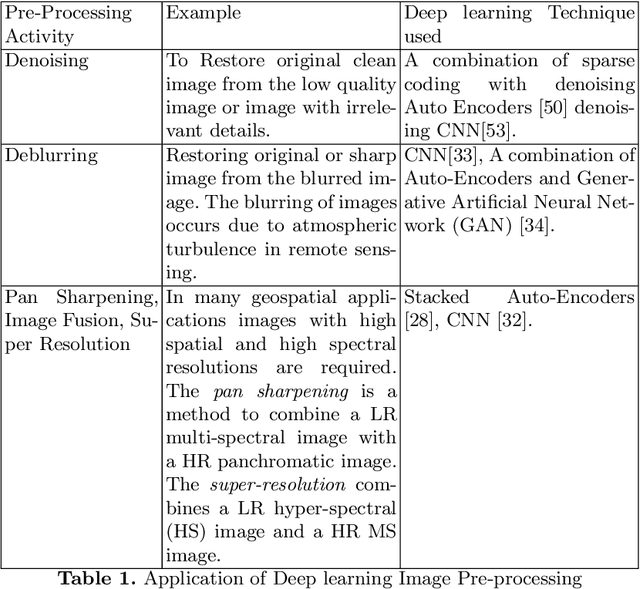

Consumer electronic devices such as mobile handsets, goods tagged with RFID labels, location and position sensors are continuously generating a vast amount of location enriched data called geospatial data. Conventionally such geospatial data is used for military applications. In recent times, many useful civilian applications have been designed and deployed around such geospatial data. For example, a recommendation system to suggest restaurants or places of attraction to a tourist visiting a particular locality. At the same time, civic bodies are harnessing geospatial data generated through remote sensing devices to provide better services to citizens such as traffic monitoring, pothole identification, and weather reporting. Typically such applications are leveraged upon non-hierarchical machine learning techniques such as Naive-Bayes Classifiers, Support Vector Machines, and decision trees. Recent advances in the field of deep-learning showed that Neural Network-based techniques outperform conventional techniques and provide effective solutions for many geospatial data analysis tasks such as object recognition, image classification, and scene understanding. The chapter presents a survey on the current state of the applications of deep learning techniques for analyzing geospatial data. The chapter is organized as below: (i) A brief overview of deep learning algorithms. (ii)Geospatial Analysis: a Data Science Perspective (iii) Deep-learning techniques for Remote Sensing data analytics tasks (iv) Deep-learning techniques for GPS data analytics(iv) Deep-learning techniques for RFID data analytics.
* This is a pre-print of the following chapter: Arvind W. Kiwelekar, Geetanjali S. Mahamunkar, Laxman D. Netak, Valmik B Nikam, {\em Deep Learning Techniques for Geospatial Data Analysis}, published in {\bf Machine Learning Paradigms}, edited by George A. TsihrintzisLakhmi C. Jain, 2020, publisher Springer, Cham reproduced with permission of publisher Springer, Cham
Bilaterally Mirrored Movements Improve the Accuracy and Precision of Training Data for Supervised Learning of Neural or Myoelectric Prosthetic Control
Jan 23, 2020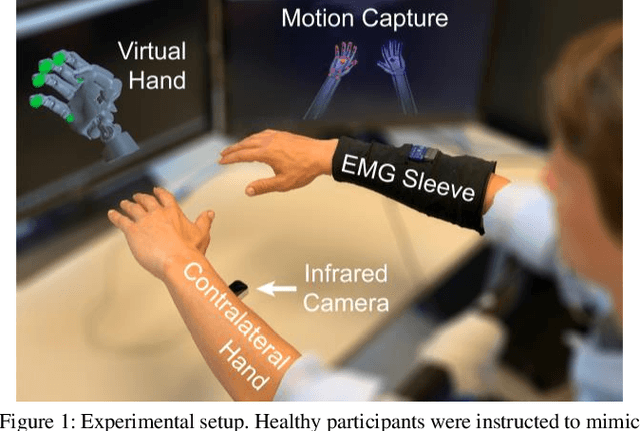
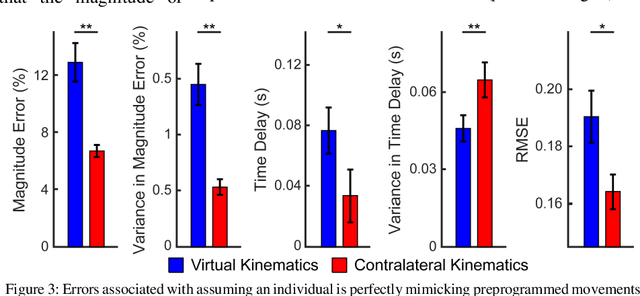
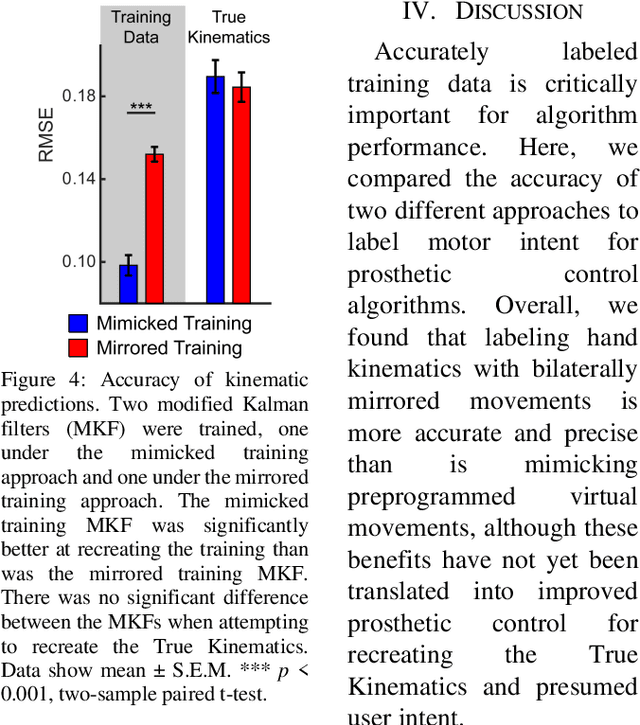
Intuitive control of prostheses relies on training algorithms to correlate biological recordings to motor intent. The quality of the training dataset is critical to run-time performance, but it is difficult to label hand kinematics accurately after the hand has been amputated. We quantified the accuracy and precision of labeling hand kinematics for two different approaches: 1) assuming a participant is perfectly mimicking predetermined motions of a prosthesis (mimicked training), and 2) assuming a participant is perfectly mirroring their contralateral hand during identical bilateral movements (mirrored training). We compared these approaches in non-amputee individuals, using an infrared camera to track eight different joint angles of the hands in real-time. Aggregate data revealed that mimicked training does not account for biomechanical coupling or temporal changes in hand posture. Mirrored training was significantly more accurate and precise at labeling hand kinematics. However, when training a modified Kalman filter to estimate motor intent, the mimicked and mirrored training approaches were not significantly different. The results suggest that the mirrored training approach creates a more faithful but more complex dataset. Advanced algorithms, more capable of learning the complex mirrored training dataset, may yield better run-time prosthetic control.
Exploring Bayesian Surprise to Prevent Overfitting and to Predict Model Performance in Non-Intrusive Load Monitoring
Sep 16, 2020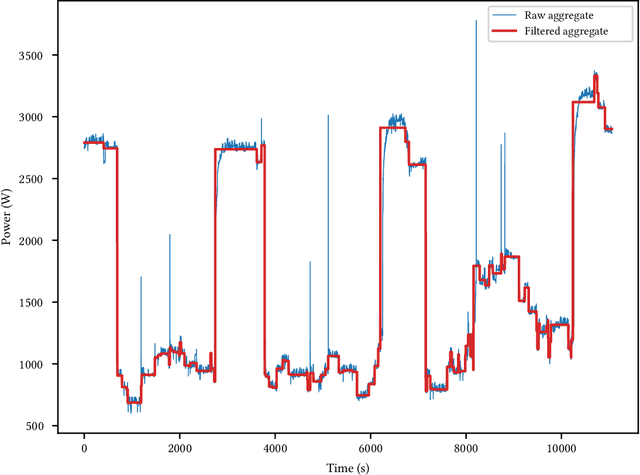
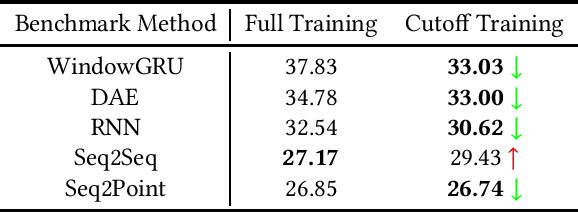
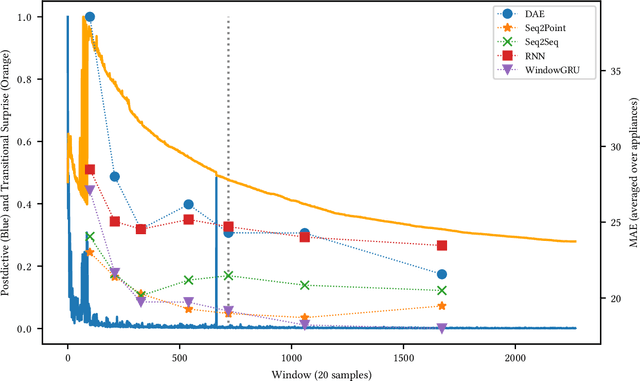
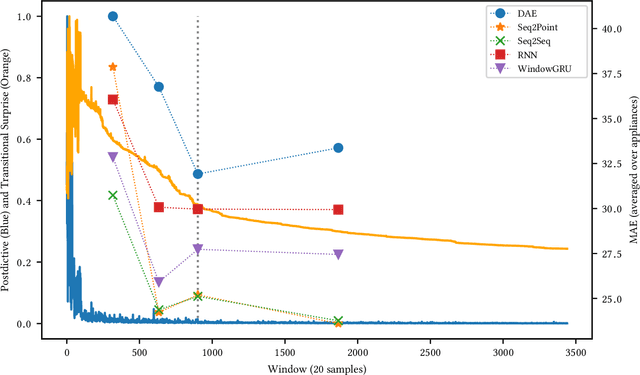
Non-Intrusive Load Monitoring (NILM) is a field of research focused on segregating constituent electrical loads in a system based only on their aggregated signal. Significant computational resources and research time are spent training models, often using as much data as possible, perhaps driven by the preconception that more data equates to more accurate models and better performing algorithms. When has enough prior training been done? When has a NILM algorithm encountered new, unseen data? This work applies the notion of Bayesian surprise to answer these questions which are important for both supervised and unsupervised algorithms. We quantify the degree of surprise between the predictive distribution (termed postdictive surprise), as well as the transitional probabilities (termed transitional surprise), before and after a window of observations. We compare the performance of several benchmark NILM algorithms supported by NILMTK, in order to establish a useful threshold on the two combined measures of surprise. We validate the use of transitional surprise by exploring the performance of a popular Hidden Markov Model as a function of surprise threshold. Finally, we explore the use of a surprise threshold as a regularization technique to avoid overfitting in cross-dataset performance. Although the generality of the specific surprise threshold discussed herein may be suspect without further testing, this work provides clear evidence that a point of diminishing returns of model performance with respect to dataset size exists. This has implications for future model development, dataset acquisition, as well as aiding in model flexibility during deployment.
Transfer Deep Reinforcement Learning-enabled Energy Management Strategy for Hybrid Tracked Vehicle
Jul 16, 2020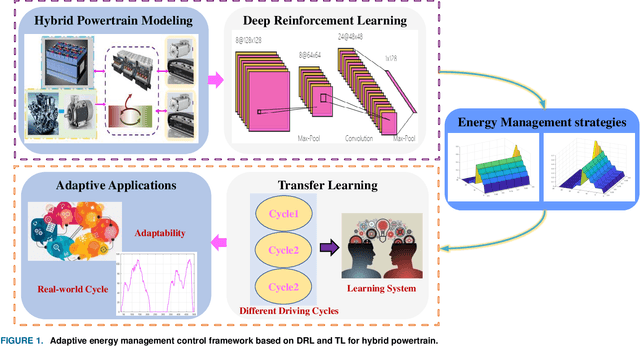
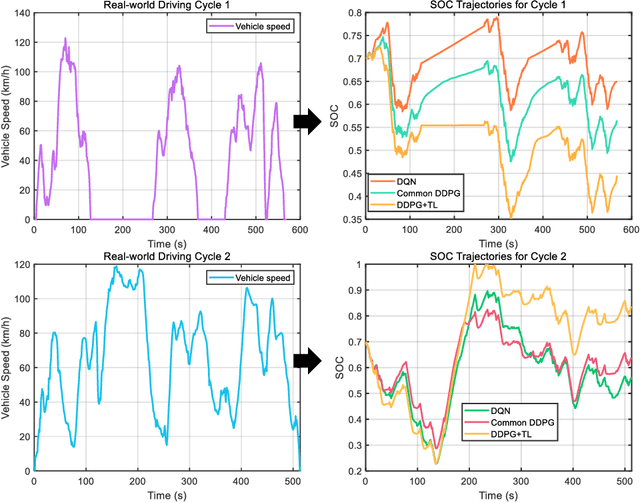
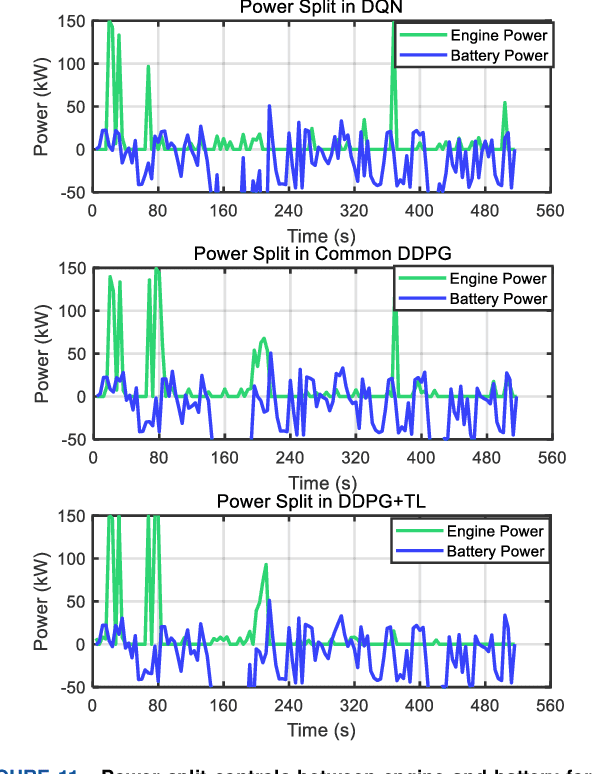
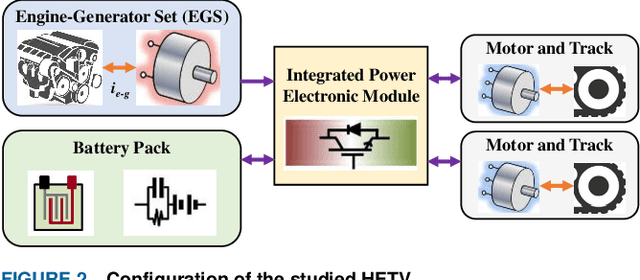
This paper proposes an adaptive energy management strategy for hybrid electric vehicles by combining deep reinforcement learning (DRL) and transfer learning (TL). This work aims to address the defect of DRL in tedious training time. First, an optimization control modeling of a hybrid tracked vehicle is built, wherein the elaborate powertrain components are introduced. Then, a bi-level control framework is constructed to derive the energy management strategies (EMSs). The upper-level is applying the particular deep deterministic policy gradient (DDPG) algorithms for EMS training at different speed intervals. The lower-level is employing the TL method to transform the pre-trained neural networks for a novel driving cycle. Finally, a series of experiments are executed to prove the effectiveness of the presented control framework. The optimality and adaptability of the formulated EMS are illuminated. The founded DRL and TL-enabled control policy is capable of enhancing energy efficiency and improving system performance.
Region Comparison Network for Interpretable Few-shot Image Classification
Sep 08, 2020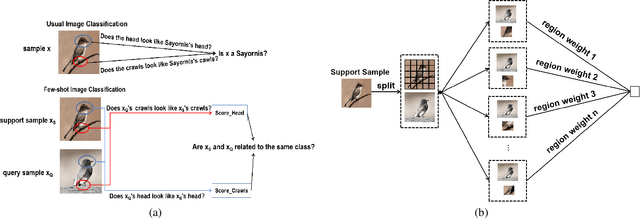
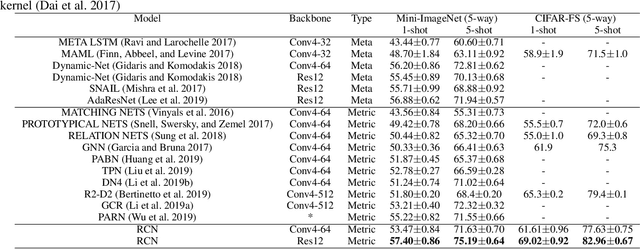
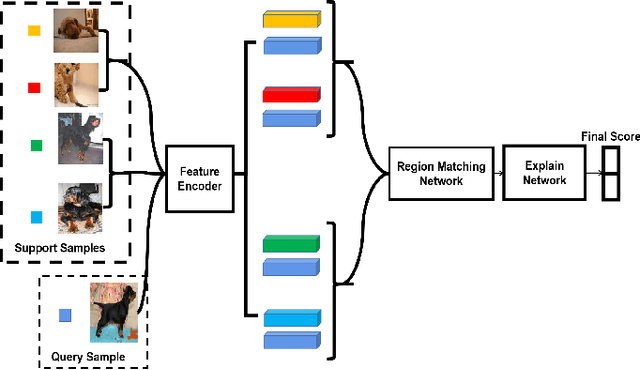
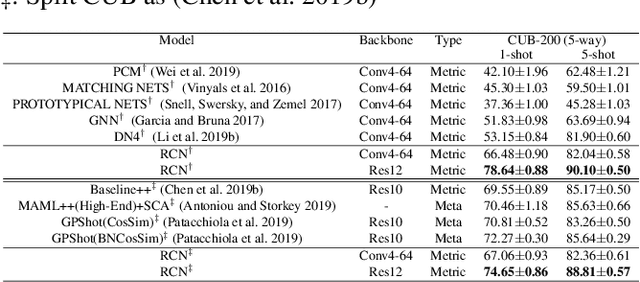
While deep learning has been successfully applied to many real-world computer vision tasks, training robust classifiers usually requires a large amount of well-labeled data. However, the annotation is often expensive and time-consuming. Few-shot image classification has thus been proposed to effectively use only a limited number of labeled examples to train models for new classes. Recent works based on transferable metric learning methods have achieved promising classification performance through learning the similarity between the features of samples from the query and support sets. However, rare of them explicitly considers the model interpretability, which can actually be revealed during the training phase. For that, in this work, we propose a metric learning based method named Region Comparison Network (RCN), which is able to reveal how few-shot learning works as in a neural network as well as to find out specific regions that are related to each other in images coming from the query and support sets. Moreover, we also present a visualization strategy named Region Activation Mapping (RAM) to intuitively explain what our method has learned by visualizing intermediate variables in our network. We also present a new way to generalize the interpretability from the level of tasks to categories, which can also be viewed as a method to find the prototypical parts for supporting the final decision of our RCN. Extensive experiments on four benchmark datasets clearly show the effectiveness of our method over existing baselines.
Jointly Sparse Signal Recovery and Support Recovery via Deep Learning with Applications in MIMO-based Grant-Free Random Access
Sep 08, 2020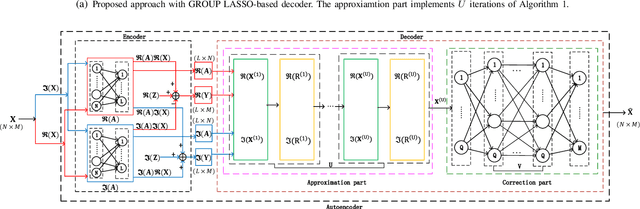
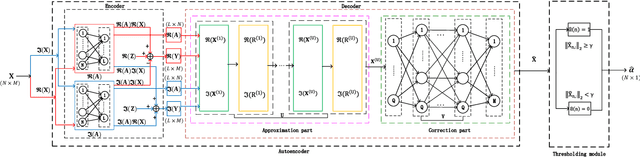
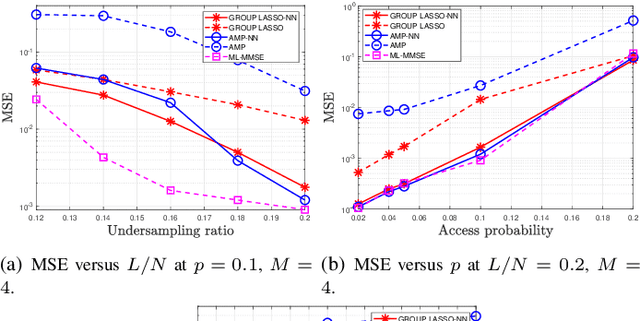
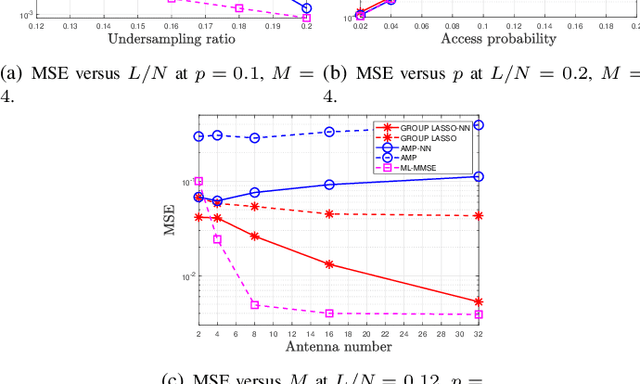
In this paper, we investigate jointly sparse signal recovery and jointly sparse support recovery in Multiple Measurement Vector (MMV) models for complex signals, which arise in many applications in communications and signal processing. Recent key applications include channel estimation and device activity detection in MIMO-based grant-free random access which is proposed to support massive machine-type communications (mMTC) for Internet of Things (IoT). Utilizing techniques in compressive sensing, optimization and deep learning, we propose two model-driven approaches, based on the standard auto-encoder structure for real numbers. One is to jointly design the common measurement matrix and jointly sparse signal recovery method, and the other aims to jointly design the common measurement matrix and jointly sparse support recovery method. The proposed model-driven approaches can effectively utilize features of sparsity patterns in designing common measurement matrices and adjusting model-driven decoders, and can greatly benefit from the underlying state-of-the-art recovery methods with theoretical guarantee. Hence, the obtained common measurement matrices and recovery methods can significantly outperform the underlying advanced recovery methods. We conduct extensive numerical results on channel estimation and device activity detection in MIMO-based grant-free random access. The numerical results show that the proposed approaches provide pilot sequences and channel estimation or device activity detection methods which can achieve higher estimation or detection accuracy with shorter computation time than existing ones. Furthermore, the numerical results explain how such gains are achieved via the proposed approaches.
Optical Flow Distillation: Towards Efficient and Stable Video Style Transfer
Jul 10, 2020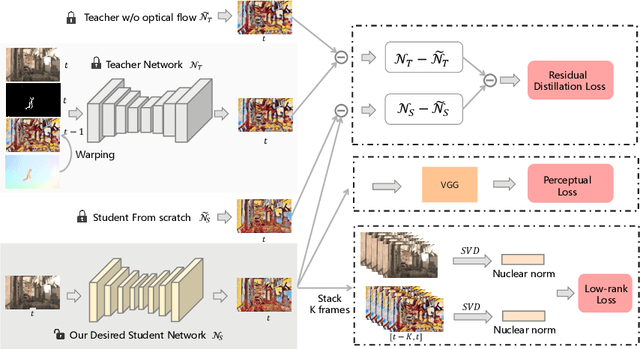
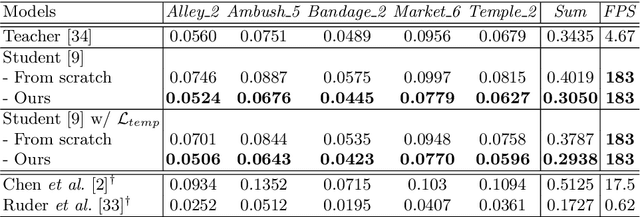
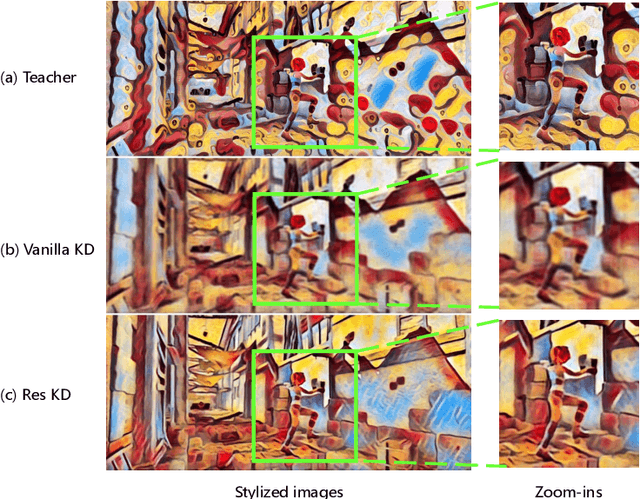
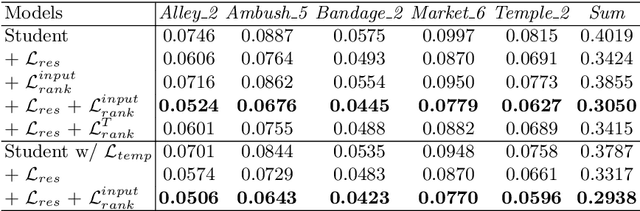
Video style transfer techniques inspire many exciting applications on mobile devices. However, their efficiency and stability are still far from satisfactory. To boost the transfer stability across frames, optical flow is widely adopted, despite its high computational complexity, e.g. occupying over 97% inference time. This paper proposes to learn a lightweight video style transfer network via knowledge distillation paradigm. We adopt two teacher networks, one of which takes optical flow during inference while the other does not. The output difference between these two teacher networks highlights the improvements made by optical flow, which is then adopted to distill the target student network. Furthermore, a low-rank distillation loss is employed to stabilize the output of student network by mimicking the rank of input videos. Extensive experiments demonstrate that our student network without an optical flow module is still able to generate stable video and runs much faster than the teacher network.