 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Event-scheduling algorithms with Kalikow decomposition for simulating potentially infinite neuronal networks
Oct 23, 2019
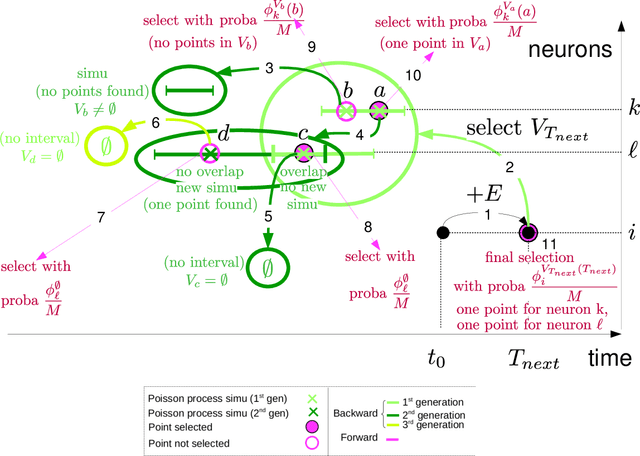
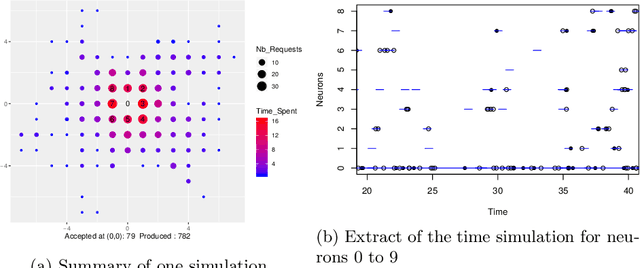
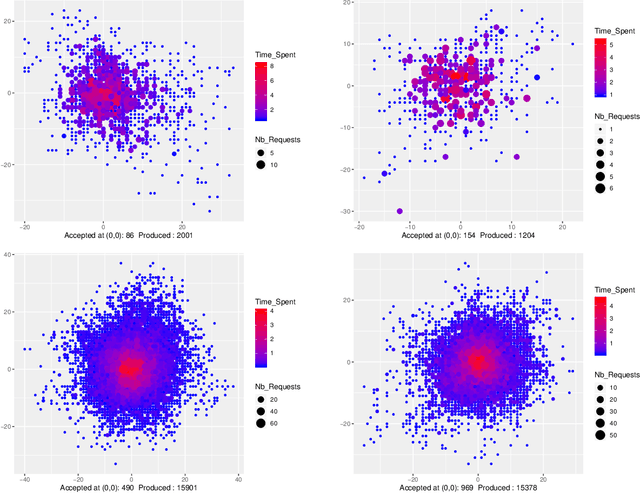
Event-scheduling algorithms can compute in continuous time the next occurrence of points (as events) of a counting process based on their current conditional intensity. In particular event-scheduling algorithms can be adapted to perform the simulation of finite neuronal networks activity. These algorithms are based on Ogata's thinning strategy \cite{Oga81}, which always needs to simulate the whole network to access the behaviour of one particular neuron of the network. On the other hand, for discrete time models, theoretical algorithms based on Kalikow decomposition can pick at random influencing neurons and perform a perfect simulation (meaning without approximations) of the behaviour of one given neuron embedded in an infinite network, at every time step. These algorithms are currently not computationally tractable in continuous time. To solve this problem, an event-scheduling algorithm with Kalikow decomposition is proposed here for the sequential simulation of point processes neuronal models satisfying this decomposition. This new algorithm is applied to infinite neuronal networks whose finite time simulation is a prerequisite to realistic brain modeling.
Convergence of Online Adaptive and Recurrent Optimization Algorithms
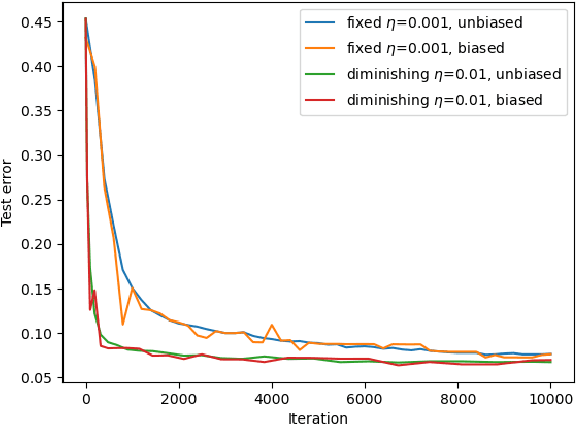
May 12, 2020We prove local convergence of several notable gradient descentalgorithms used inmachine learning, for which standard stochastic gradient descent theorydoes not apply. This includes, first, online algorithms for recurrent models and dynamicalsystems, such as \emph{Real-time recurrent learning} (RTRL) and its computationally lighter approximations NoBackTrack and UORO; second,several adaptive algorithms such as RMSProp, online natural gradient, and Adam with $\beta^2\to 1$.Despite local convergence being a relatively weak requirement for a newoptimization algorithm, no local analysis was available for these algorithms, as far aswe knew. Analysis of these algorithms does not immediately followfrom standard stochastic gradient (SGD) theory. In fact, Adam has been provedto lack local convergence in some simple situations. For recurrent models, online algorithms modify the parameterwhile the model is running, which further complicates the analysis withrespect to simple SGD.Local convergence for these various algorithms results from a single,more general set of assumptions, in the setup of learning dynamicalsystems online. Thus, these results can cover other variants ofthe algorithms considered.We adopt an ``ergodic'' rather than probabilistic viewpoint, working withempirical time averages instead of probability distributions. This ismore data-agnostic andcreates differences with respect to standard SGD theory,especially for the range of possible learning rates. For instance, withcycling or per-epoch reshuffling over a finite dataset instead of purei.i.d. sampling with replacement, empiricalaverages of gradients converge at rate $1/T$ insteadof $1/\sqrt{T}$ (cycling acts as a variance reduction method),theoretically allowingfor larger learning rates than in SGD.
Asynchronous Federated Learning with Reduced Number of Rounds and with Differential Privacy from Less Aggregated Gaussian Noise
Jul 17, 2020


The feasibility of federated learning is highly constrained by the server-clients infrastructure in terms of network communication. Most newly launched smartphones and IoT devices are equipped with GPUs or sufficient computing hardware to run powerful AI models. However, in case of the original synchronous federated learning, client devices suffer waiting times and regular communication between clients and server is required. This implies more sensitivity to local model training times and irregular or missed updates, hence, less or limited scalability to large numbers of clients and convergence rates measured in real time will suffer. We propose a new algorithm for asynchronous federated learning which eliminates waiting times and reduces overall network communication - we provide rigorous theoretical analysis for strongly convex objective functions and provide simulation results. By adding Gaussian noise we show how our algorithm can be made differentially private -- new theorems show how the aggregated added Gaussian noise is significantly reduced.
Velocity variations at Columbia Glacier captured by particle filtering of oblique time-lapse images
Nov 15, 2017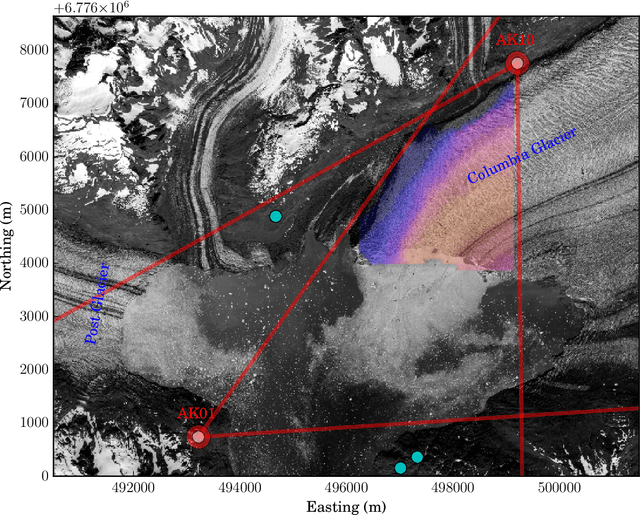
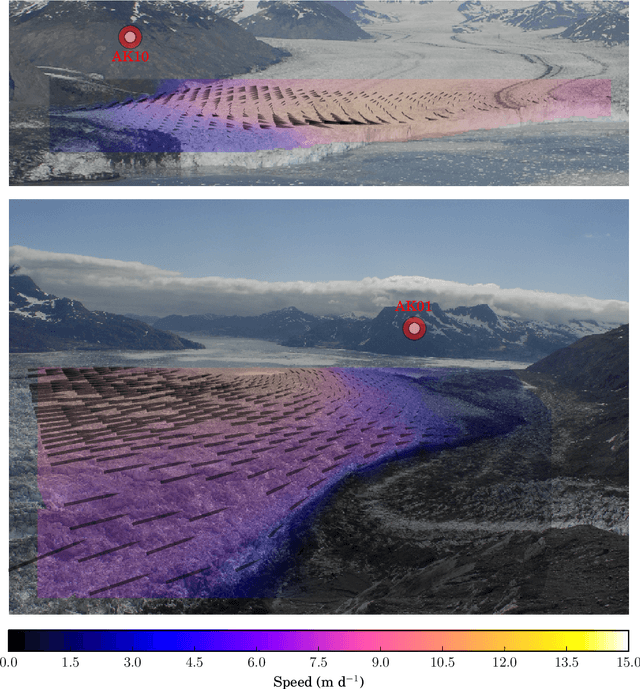
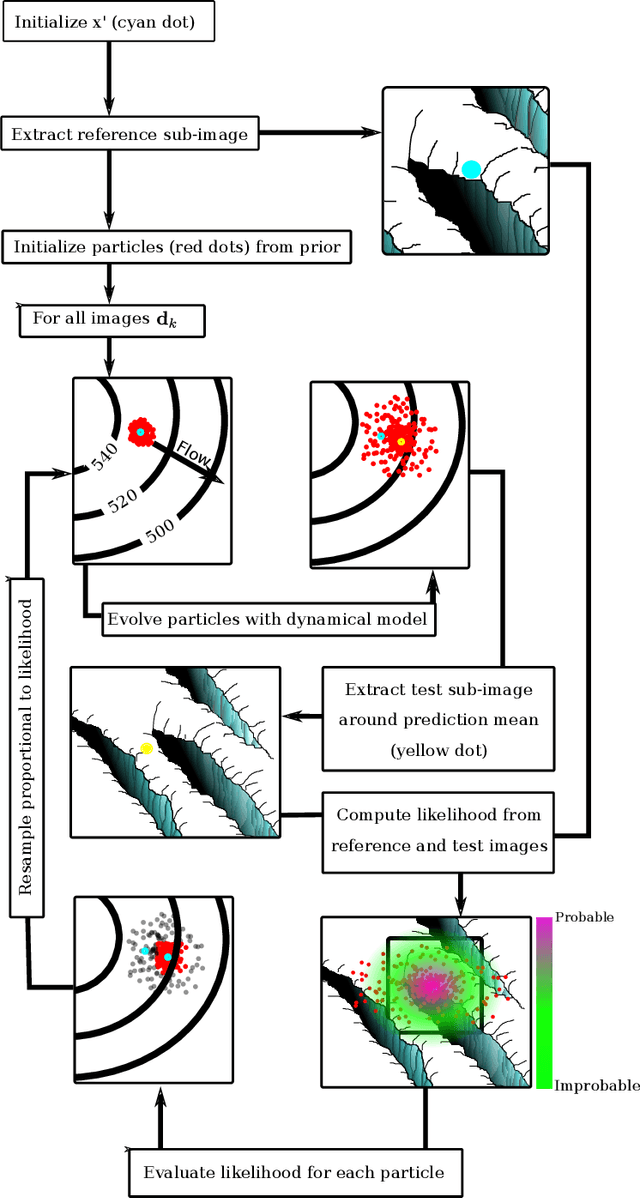
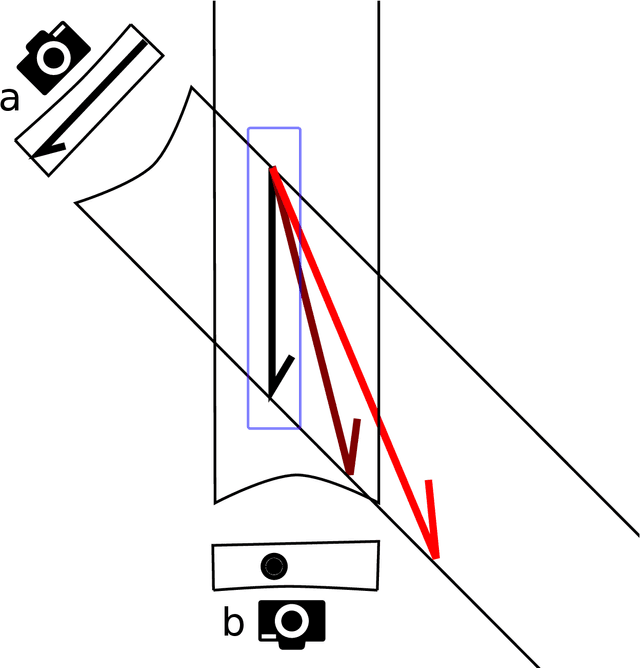
We develop a probabilistic method for tracking glacier surface motion based on time-lapse imagery, which works by sequentially resampling a stochastic state-space model according to a likelihood determined through correlation between reference and test images. The method is robust due to its natural handling of periodic occlusion and its capacity to follow multiple hypothesis displacements between images, and can improve estimates of velocity magnitude and direction through the inclusion of observations from an arbitrary number of cameras. We apply the method to an annual record of images from two cameras near the terminus of Columbia Glacier. While the method produces velocities at daily resolution, we verify our results by comparing eleven-day means to TerraSar-X. We find that Columbia Glacier transitions between a winter state characterized by moderate velocities and little temporal variability, to an early summer speed-up in which velocities are sensitive to increases in melt- and rainwater, to a fall slowdown, where velocities drop to below their winter mean and become insensitive to external forcing, a pattern consistent with the development and collapse of efficient and inefficient subglacial hydrologic networks throughout the year.
Fast Automatic Visibility Optimization for Thermal Synthetic Aperture Visualization
May 08, 2020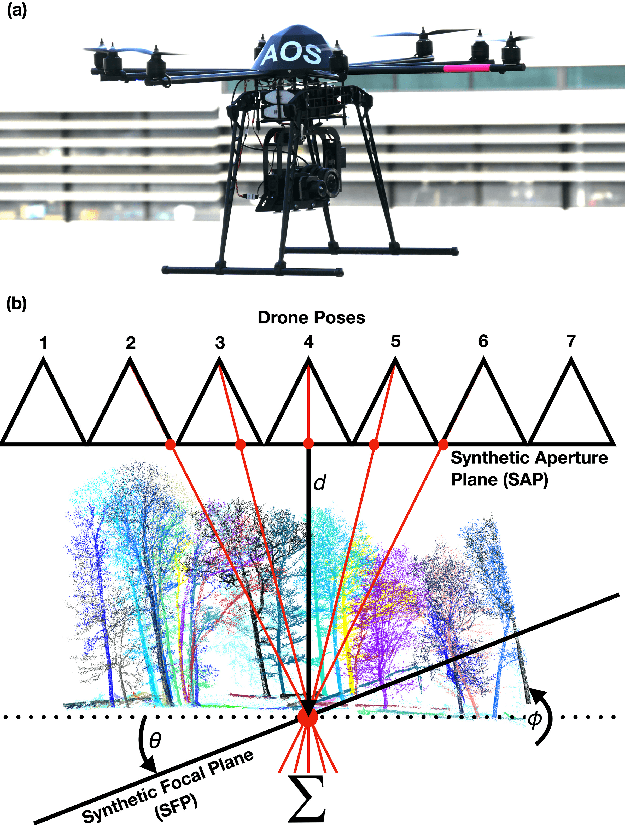

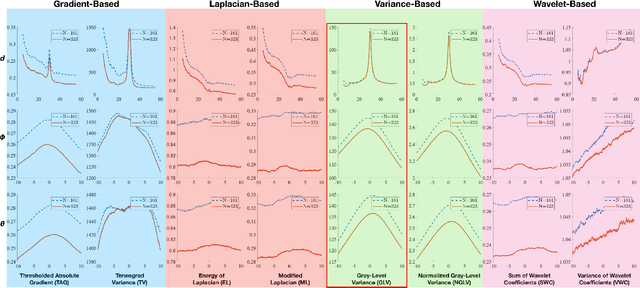
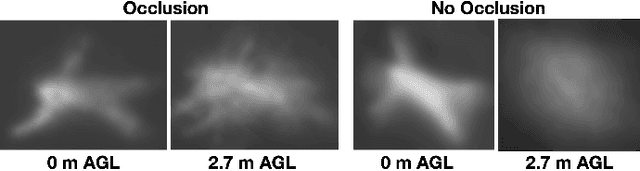
In this article, we describe and validate the first fully automatic parameter optimization for thermal synthetic aperture visualization. It replaces previous manual exploration of the parameter space, which is time consuming and error prone. We prove that the visibility of targets in thermal integral images is proportional to the variance of the targets' image. Since this is invariant to occlusion it represents a suitable objective function for optimization. Our findings have the potential to enable fully autonomous search and recuse operations with camera drones.
Improved Adaptive Type-2 Fuzzy Filter with Exclusively Two Fuzzy Membership Function for Filtering Salt and Pepper Noise
Aug 10, 2020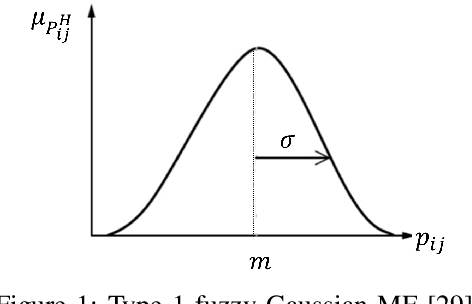
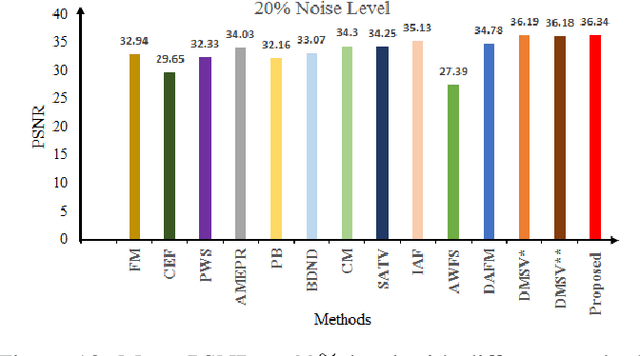
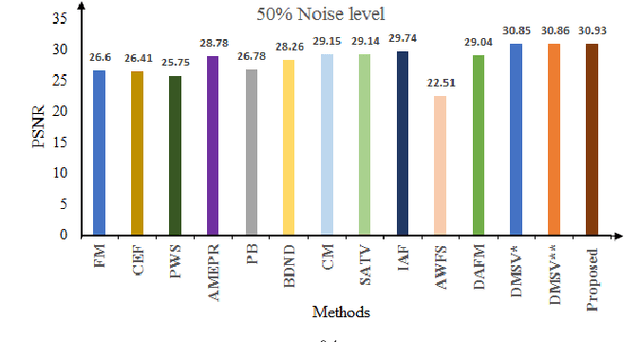
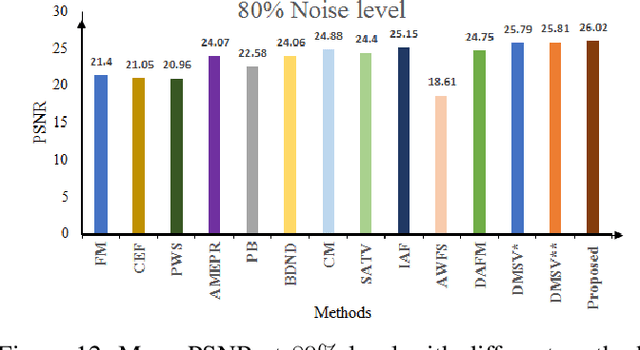
Image denoising is one of the preliminary steps in image processing methods in which the presence of noise can deteriorate the image quality. To overcome this limitation, in this paper a improved two-stage fuzzy filter is proposed for filtering salt and pepper noise from the images. In the first-stage, the pixels in the image are categorized as good or noisy based on adaptive thresholding using type-2 fuzzy logic with exclusively two different membership functions in the filter window. In the second-stage, the noisy pixels are denoised using modified ordinary fuzzy logic in the respective filter window. The proposed filter is validated on standard images with various noise levels. The proposed filter removes the noise and preserves useful image characteristics, i.e., edges and corners at higher noise level. The performance of the proposed filter is compared with the various state-of-the-art methods in terms of peak signal-to-noise ratio and computation time. To show the effectiveness of filter statistical tests, i.e., Friedman test and Bonferroni-Dunn (BD) test are also carried out which clearly ascertain that the proposed filter outperforms in comparison of various filtering approaches.
CSVideoNet: A Real-time End-to-end Learning Framework for High-frame-rate Video Compressive Sensing
Jan 28, 2018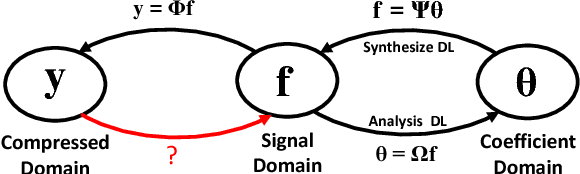
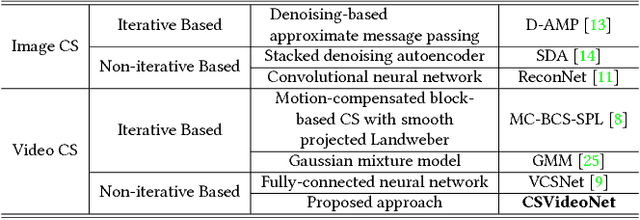
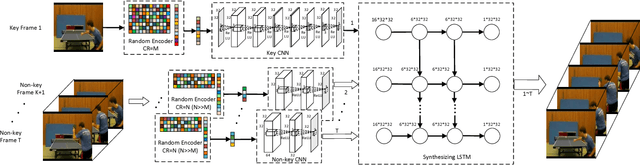
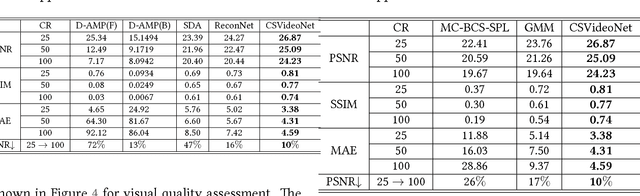
This paper addresses the real-time encoding-decoding problem for high-frame-rate video compressive sensing (CS). Unlike prior works that perform reconstruction using iterative optimization-based approaches, we propose a non-iterative model, named "CSVideoNet". CSVideoNet directly learns the inverse mapping of CS and reconstructs the original input in a single forward propagation. To overcome the limitations of existing CS cameras, we propose a multi-rate CNN and a synthesizing RNN to improve the trade-off between compression ratio (CR) and spatial-temporal resolution of the reconstructed videos. The experiment results demonstrate that CSVideoNet significantly outperforms the state-of-the-art approaches. With no pre/post-processing, we achieve 25dB PSNR recovery quality at 100x CR, with a frame rate of 125 fps on a Titan X GPU. Due to the feedforward and high-data-concurrency natures of CSVideoNet, it can take advantage of GPU acceleration to achieve three orders of magnitude speed-up over conventional iterative-based approaches. We share the source code at https://github.com/PSCLab-ASU/CSVideoNet.
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
Feb 18, 2016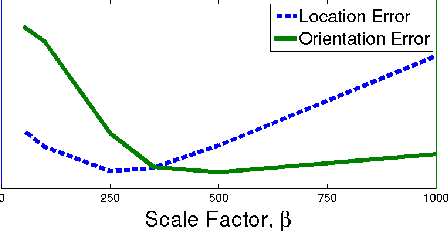
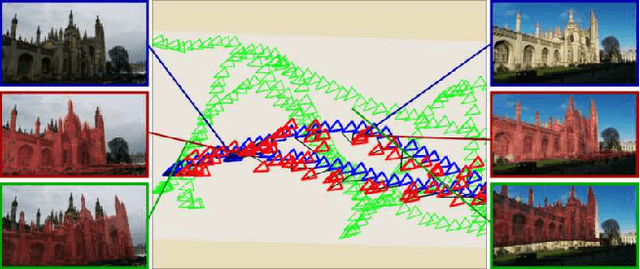
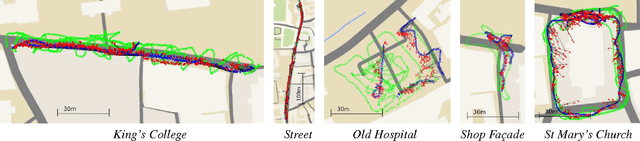
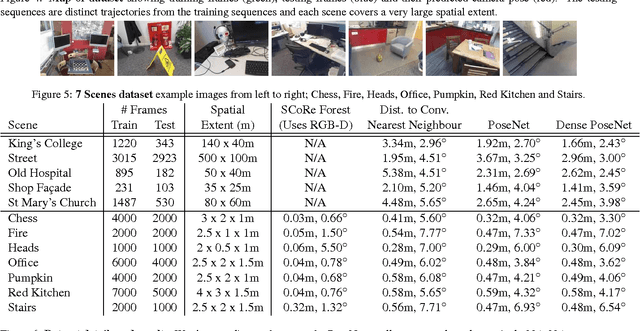
We present a robust and real-time monocular six degree of freedom relocalization system. Our system trains a convolutional neural network to regress the 6-DOF camera pose from a single RGB image in an end-to-end manner with no need of additional engineering or graph optimisation. The algorithm can operate indoors and outdoors in real time, taking 5ms per frame to compute. It obtains approximately 2m and 6 degree accuracy for large scale outdoor scenes and 0.5m and 10 degree accuracy indoors. This is achieved using an efficient 23 layer deep convnet, demonstrating that convnets can be used to solve complicated out of image plane regression problems. This was made possible by leveraging transfer learning from large scale classification data. We show the convnet localizes from high level features and is robust to difficult lighting, motion blur and different camera intrinsics where point based SIFT registration fails. Furthermore we show how the pose feature that is produced generalizes to other scenes allowing us to regress pose with only a few dozen training examples. PoseNet code, dataset and an online demonstration is available on our project webpage, at http://mi.eng.cam.ac.uk/projects/relocalisation/
Exploring Bayesian Surprise to Prevent Overfitting and to Predict Model Performance in Non-Intrusive Load Monitoring
Sep 16, 2020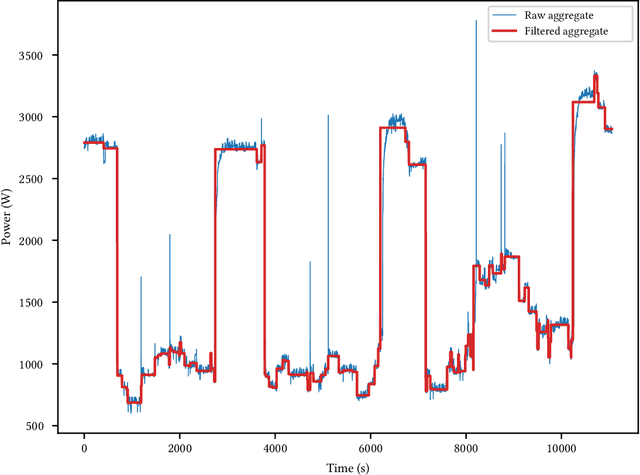
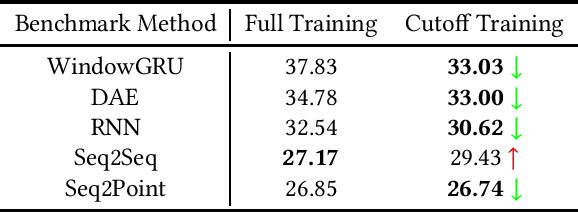
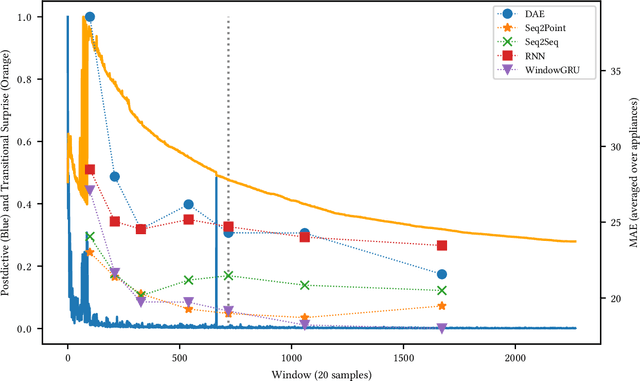
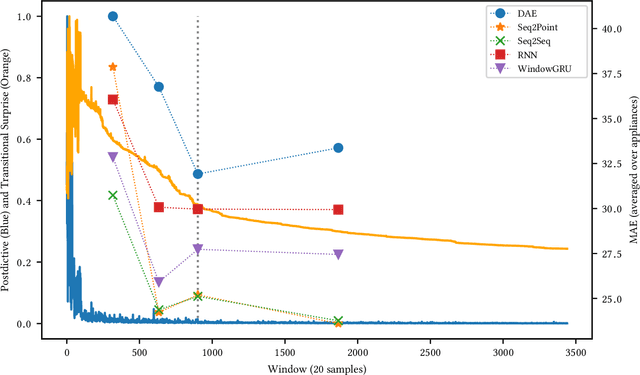
Non-Intrusive Load Monitoring (NILM) is a field of research focused on segregating constituent electrical loads in a system based only on their aggregated signal. Significant computational resources and research time are spent training models, often using as much data as possible, perhaps driven by the preconception that more data equates to more accurate models and better performing algorithms. When has enough prior training been done? When has a NILM algorithm encountered new, unseen data? This work applies the notion of Bayesian surprise to answer these questions which are important for both supervised and unsupervised algorithms. We quantify the degree of surprise between the predictive distribution (termed postdictive surprise), as well as the transitional probabilities (termed transitional surprise), before and after a window of observations. We compare the performance of several benchmark NILM algorithms supported by NILMTK, in order to establish a useful threshold on the two combined measures of surprise. We validate the use of transitional surprise by exploring the performance of a popular Hidden Markov Model as a function of surprise threshold. Finally, we explore the use of a surprise threshold as a regularization technique to avoid overfitting in cross-dataset performance. Although the generality of the specific surprise threshold discussed herein may be suspect without further testing, this work provides clear evidence that a point of diminishing returns of model performance with respect to dataset size exists. This has implications for future model development, dataset acquisition, as well as aiding in model flexibility during deployment.
Deep Learning Techniques for Geospatial Data Analysis
Aug 30, 2020
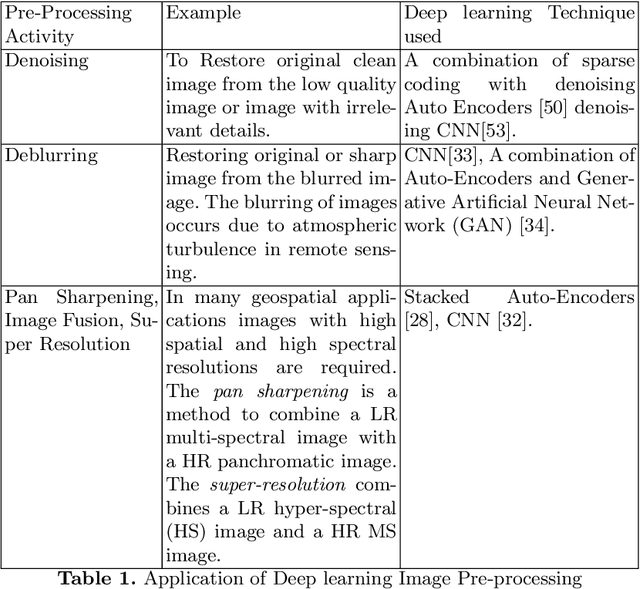

Consumer electronic devices such as mobile handsets, goods tagged with RFID labels, location and position sensors are continuously generating a vast amount of location enriched data called geospatial data. Conventionally such geospatial data is used for military applications. In recent times, many useful civilian applications have been designed and deployed around such geospatial data. For example, a recommendation system to suggest restaurants or places of attraction to a tourist visiting a particular locality. At the same time, civic bodies are harnessing geospatial data generated through remote sensing devices to provide better services to citizens such as traffic monitoring, pothole identification, and weather reporting. Typically such applications are leveraged upon non-hierarchical machine learning techniques such as Naive-Bayes Classifiers, Support Vector Machines, and decision trees. Recent advances in the field of deep-learning showed that Neural Network-based techniques outperform conventional techniques and provide effective solutions for many geospatial data analysis tasks such as object recognition, image classification, and scene understanding. The chapter presents a survey on the current state of the applications of deep learning techniques for analyzing geospatial data. The chapter is organized as below: (i) A brief overview of deep learning algorithms. (ii)Geospatial Analysis: a Data Science Perspective (iii) Deep-learning techniques for Remote Sensing data analytics tasks (iv) Deep-learning techniques for GPS data analytics(iv) Deep-learning techniques for RFID data analytics.
* This is a pre-print of the following chapter: Arvind W. Kiwelekar, Geetanjali S. Mahamunkar, Laxman D. Netak, Valmik B Nikam, {\em Deep Learning Techniques for Geospatial Data Analysis}, published in {\bf Machine Learning Paradigms}, edited by George A. TsihrintzisLakhmi C. Jain, 2020, publisher Springer, Cham reproduced with permission of publisher Springer, Cham