 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SIR: Similar Image Retrieval for Product Search in E-Commerce
Sep 29, 2020
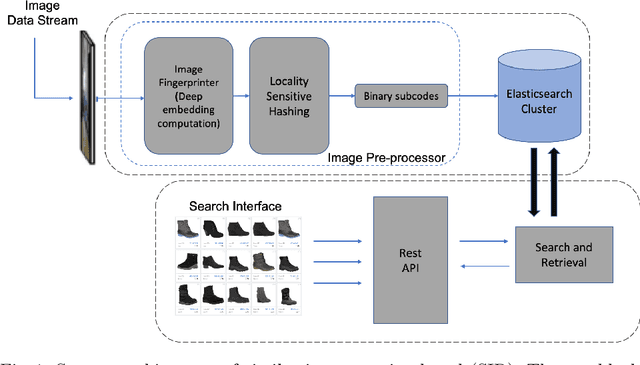
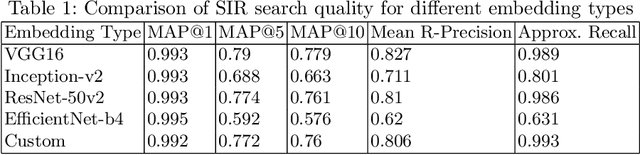
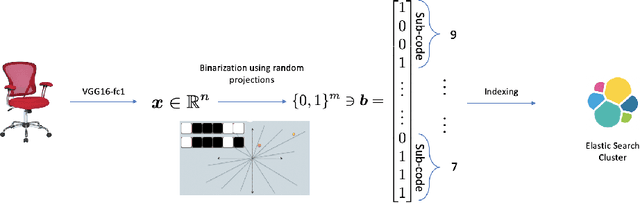

We present a similar image retrieval (SIR) platform that is used to quickly discover visually similar products in a catalog of millions. Given the size, diversity, and dynamism of our catalog, product search poses many challenges. It can be addressed by building supervised models to tagging product images with labels representing themes and later retrieving them by labels. This approach suffices for common and perennial themes like "white shirt" or "lifestyle image of TV". It does not work for new themes such as "e-cigarettes", hard-to-define ones such as "image with a promotional badge", or the ones with short relevance span such as "Halloween costumes". SIR is ideal for such cases because it allows us to search by an example, not a pre-defined theme. We describe the steps - embedding computation, encoding, and indexing - that power the approximate nearest neighbor search back-end. We also highlight two applications of SIR. The first one is related to the detection of products with various types of potentially objectionable themes. This application is run with a sense of urgency, hence the typical time frame to train and bootstrap a model is not permitted. Also, these themes are often short-lived based on current trends, hence spending resources to build a lasting model is not justified. The second application is a variant item detection system where SIR helps discover visual variants that are hard to find through text search. We analyze the performance of SIR in the context of these applications.
End-to-End Rate-Distortion Optimization for Bi-Directional Learned Video Compression
Aug 11, 2020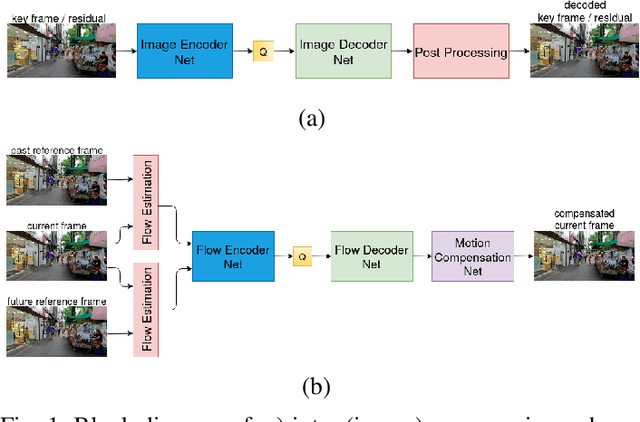
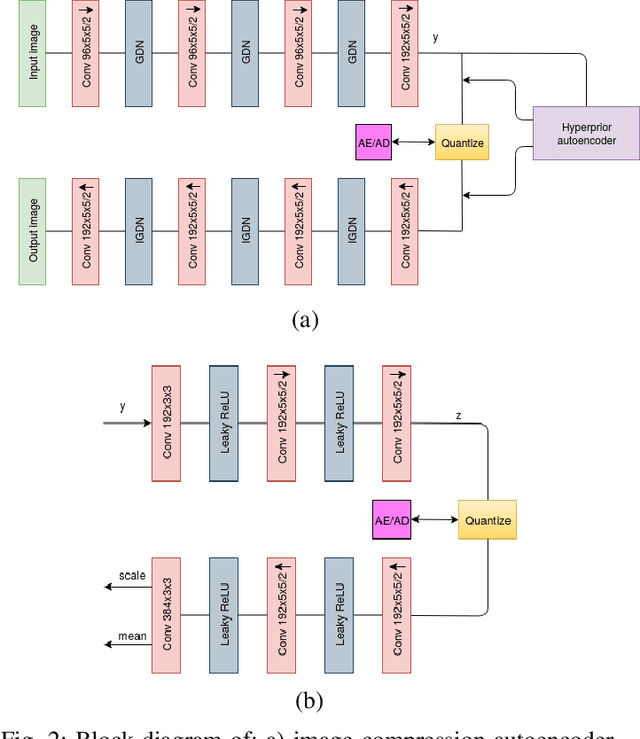
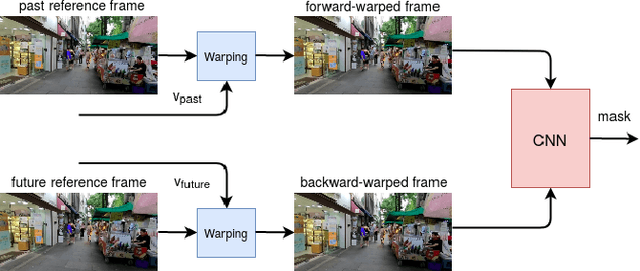
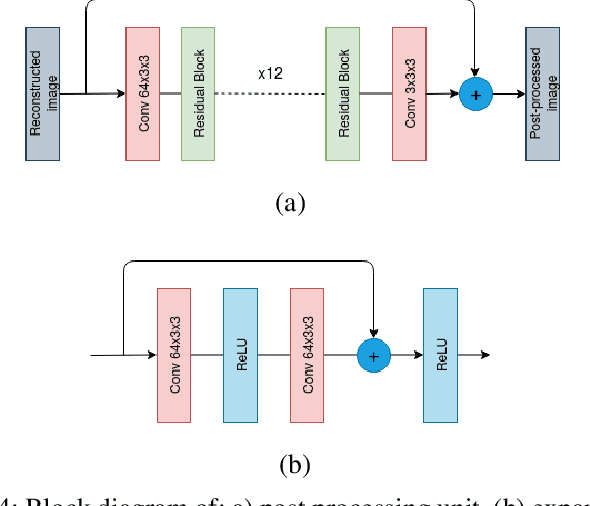
Conventional video compression methods employ a linear transform and block motion model, and the steps of motion estimation, mode and quantization parameter selection, and entropy coding are optimized individually due to combinatorial nature of the end-to-end optimization problem. Learned video compression allows end-to-end rate-distortion optimized training of all nonlinear modules, quantization parameter and entropy model simultaneously. While previous work on learned video compression considered training a sequential video codec based on end-to-end optimization of cost averaged over pairs of successive frames, it is well-known in conventional video compression that hierarchical, bi-directional coding outperforms sequential compression. In this paper, we propose for the first time end-to-end optimization of a hierarchical, bi-directional motion compensated learned codec by accumulating cost function over fixed-size groups of pictures (GOP). Experimental results show that the rate-distortion performance of our proposed learned bi-directional {\it GOP coder} outperforms the state-of-the-art end-to-end optimized learned sequential compression as expected.
Regulating Accuracy-Efficiency Trade-Offs in Distributed Machine Learning Systems
Jul 09, 2020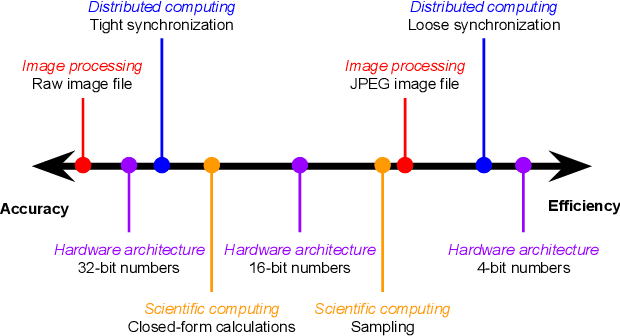
In this paper we discuss the trade-off between accuracy and efficiency in distributed machine learning (ML) systems and analyze its resulting policy considerations. This trade-off is in fact quite common in multiple disciplines, including law and medicine, and it applies to a wide variety of subfields within computer science. Accuracy and efficiency trade-offs have unique implications in ML algorithms because, being probabilistic in nature, such algorithms generally exhibit error tolerance. After describing how the trade-off takes shape in real-world distributed computing systems, we show the interplay between such systems and ML algorithms, explaining in detail how accuracy and efficiency interact particularly in distributed ML systems. We close by making specific calls to action for approaching regulatory policy for the emerging technology of real-time distributed ML systems.
Rapid AI Development Cycle for the Coronavirus (COVID-19) Pandemic: Initial Results for Automated Detection & Patient Monitoring using Deep Learning CT Image Analysis
Mar 12, 2020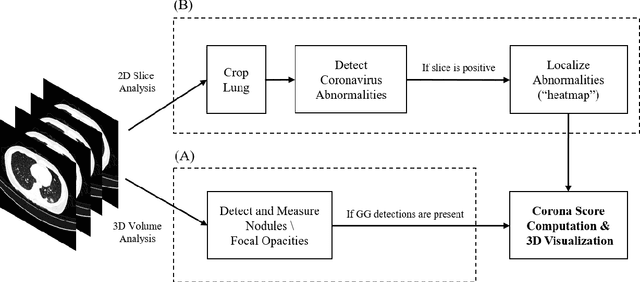
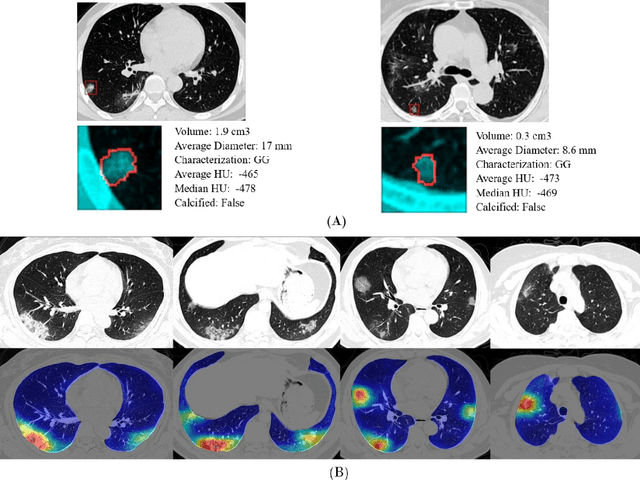
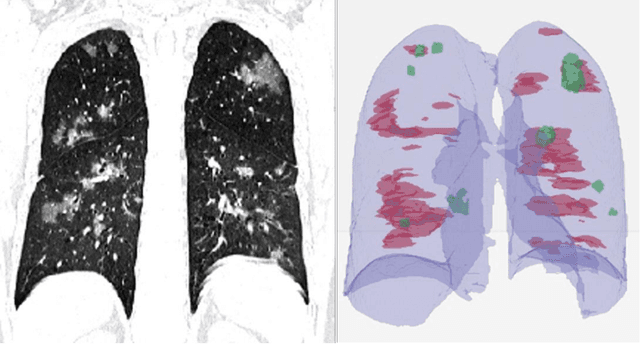
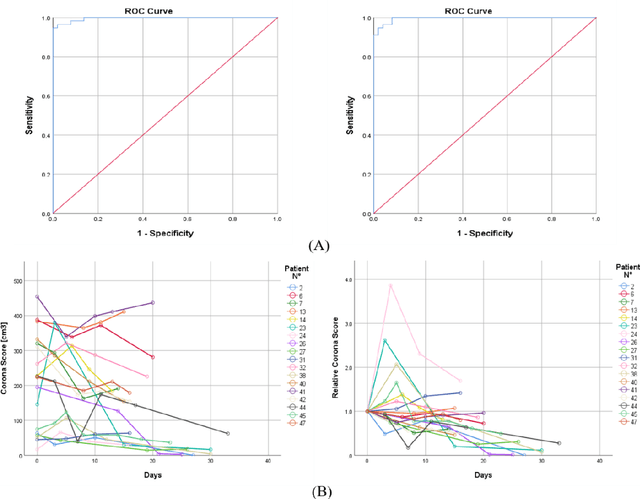
Purpose: Develop AI-based automated CT image analysis tools for detection, quantification, and tracking of Coronavirus; demonstrate they can differentiate coronavirus patients from non-patients. Materials and Methods: Multiple international datasets, including from Chinese disease-infected areas were included. We present a system that utilizes robust 2D and 3D deep learning models, modifying and adapting existing AI models and combining them with clinical understanding. We conducted multiple retrospective experiments to analyze the performance of the system in the detection of suspected COVID-19 thoracic CT features and to evaluate evolution of the disease in each patient over time using a 3D volume review, generating a Corona score. The study includes a testing set of 157 international patients (China and U.S). Results: Classification results for Coronavirus vs Non-coronavirus cases per thoracic CT studies were 0.996 AUC (95%CI: 0.989-1.00) ; on datasets of Chinese control and infected patients. Possible working point: 98.2% sensitivity, 92.2% specificity. For time analysis of Coronavirus patients, the system output enables quantitative measurements for smaller opacities (volume, diameter) and visualization of the larger opacities in a slice-based heat map or a 3D volume display. Our suggested Corona score measures the progression of disease over time. Conclusion: This initial study, which is currently being expanded to a larger population, demonstrated that rapidly developed AI-based image analysis can achieve high accuracy in detection of Coronavirus as well as quantification and tracking of disease burden.
D2D: Learning to find good correspondences for image matching and manipulation
Jul 16, 2020
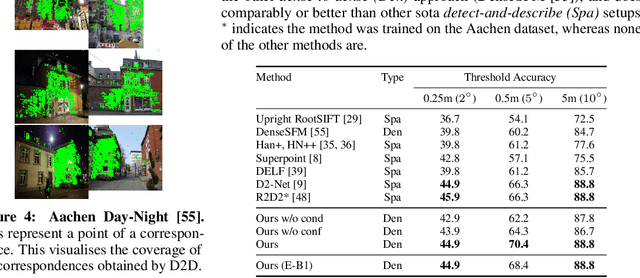
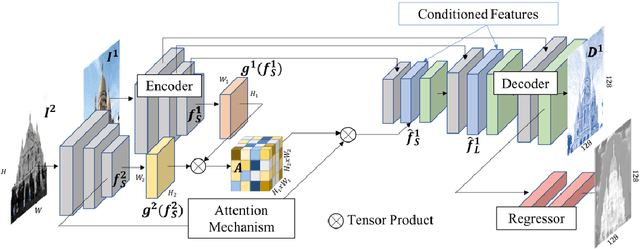
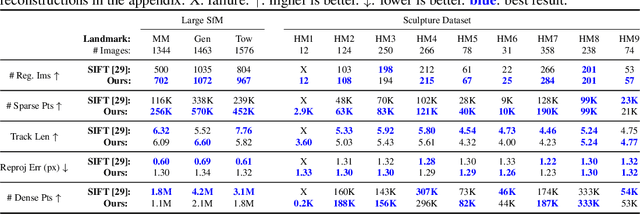
We propose a new approach to determining correspondences between image pairs under large changes in illumination, viewpoint, context, and material. While most approaches seek to extract a set of reliably detectable regions in each image which are then compared (sparse-to-sparse) using increasingly complicated or specialized pipelines, we propose a simple approach for matching all points between the images (dense-to-dense) and subsequently selecting the best matches. The two key parts of our approach are: (i) to condition the learned features on both images, and (ii) to learn a distinctiveness score which is used to choose the best matches at test time. We demonstrate that our model can be used to achieve state of the art or competitive results on a wide range of tasks: local matching, camera localization, 3D reconstruction, and image stylization.
Adversarial Attacks on Deep Learning Systems for User Identification based on Motion Sensors
Sep 02, 2020
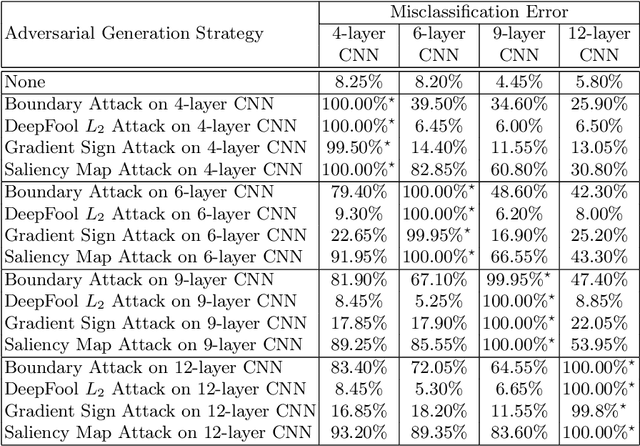
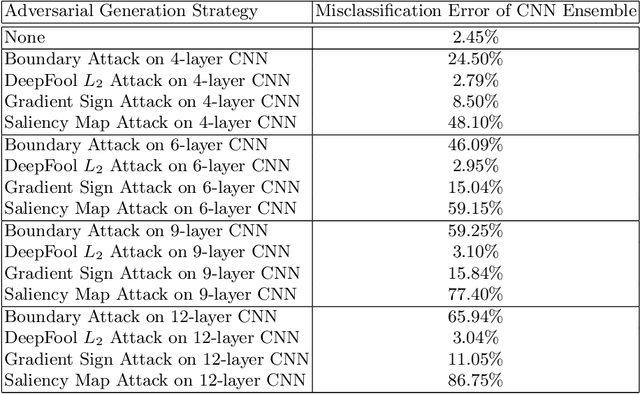
For the time being, mobile devices employ implicit authentication mechanisms, namely, unlock patterns, PINs or biometric-based systems such as fingerprint or face recognition. While these systems are prone to well-known attacks, the introduction of an explicit and unobtrusive authentication layer can greatly enhance security. In this study, we focus on deep learning methods for explicit authentication based on motion sensor signals. In this scenario, attackers could craft adversarial examples with the aim of gaining unauthorized access and even restraining a legitimate user to access his mobile device. To our knowledge, this is the first study that aims at quantifying the impact of adversarial attacks on machine learning models used for user identification based on motion sensors. To accomplish our goal, we study multiple methods for generating adversarial examples. We propose three research questions regarding the impact and the universality of adversarial examples, conducting relevant experiments in order to answer our research questions. Our empirical results demonstrate that certain adversarial example generation methods are specific to the attacked classification model, while others tend to be generic. We thus conclude that deep neural networks trained for user identification tasks based on motion sensors are subject to a high percentage of misclassification when given adversarial input.
LETI: Latency Estimation Tool and Investigation of Neural Networks inference on Mobile GPU
Oct 06, 2020
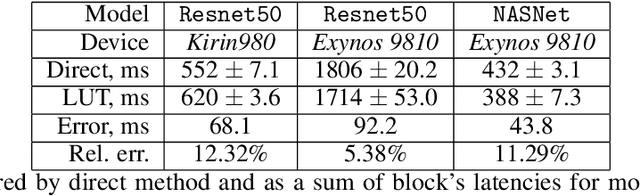
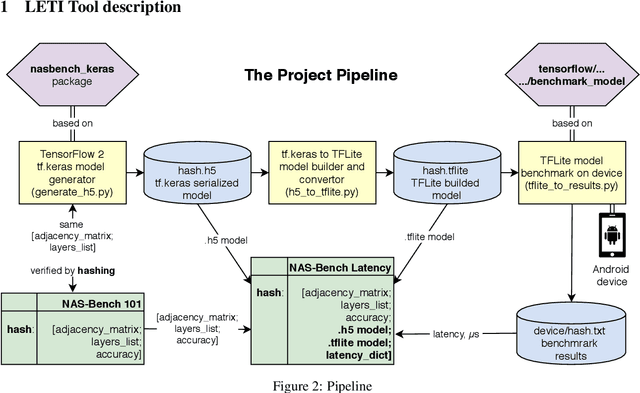
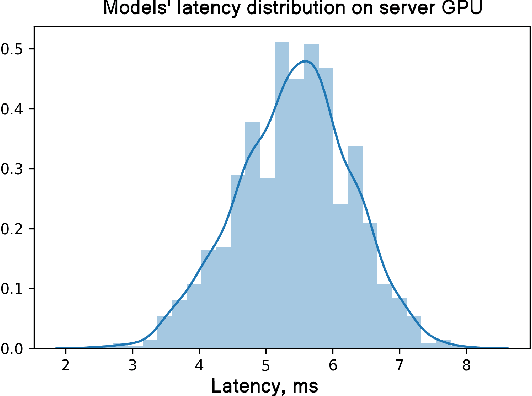
A lot of deep learning applications are desired to be run on mobile devices. Both accuracy and inference time are meaningful for a lot of them. While the number of FLOPs is usually used as a proxy for neural network latency, it may be not the best choice. In order to obtain a better approximation of latency, research community uses look-up tables of all possible layers for latency calculation for the final prediction of the inference on mobile CPU. It requires only a small number of experiments. Unfortunately, on mobile GPU this method is not applicable in a straight-forward way and shows low precision. In this work, we consider latency approximation on mobile GPU as a data and hardware-specific problem. Our main goal is to construct a convenient latency estimation tool for investigation(LETI) of neural network inference and building robust and accurate latency prediction models for each specific task. To achieve this goal, we build open-source tools which provide a convenient way to conduct massive experiments on different target devices focusing on mobile GPU. After evaluation of the dataset, we learn the regression model on experimental data and use it for future latency prediction and analysis. We experimentally demonstrate the applicability of such an approach on a subset of popular NAS-Benchmark 101 dataset and also evaluate the most popular neural network architectures for two mobile GPUs. As a result, we construct latency prediction model with good precision on the target evaluation subset. We consider LETI as a useful tool for neural architecture search or massive latency evaluation. The project is available at https://github.com/leti-ai
A Review on Cyber Crimes on the Internet of Things
Sep 12, 2020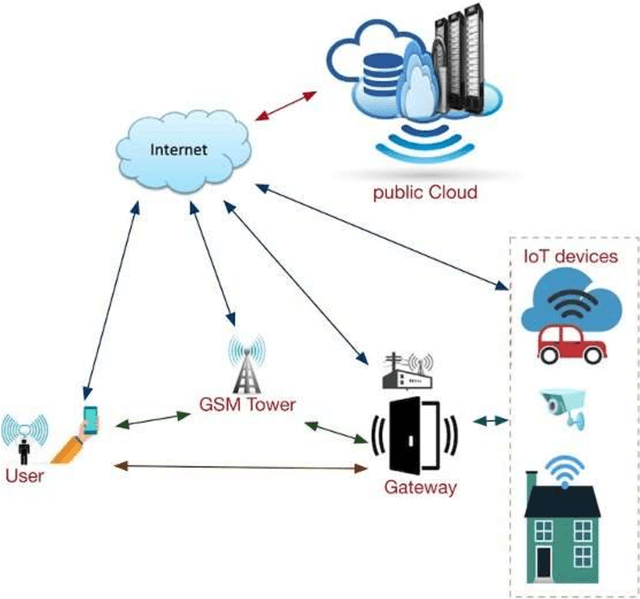
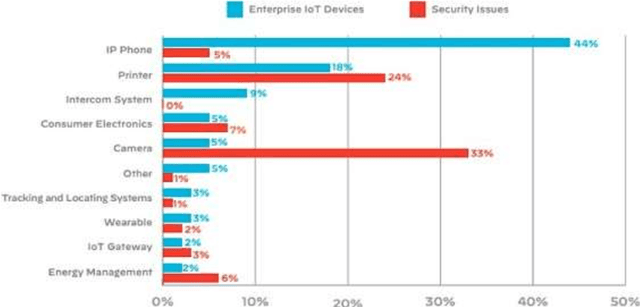
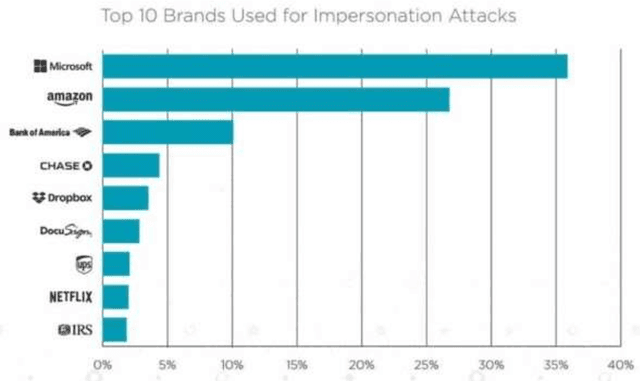
Internet of Things (IoT) devices are rapidly becoming universal. The success of IoT cannot be ignored in the scenario today, along with its attacks and threats on IoT devices and facilities are also increasing day by day. Cyber attacks become a part of IoT and affecting the life and society of users, so steps must be taken to defend cyber seriously. Cybercrimes threaten the infrastructure of governments and businesses globally and can damage the users in innumerable ways. With the global cybercrime damages predicted to cost up to 6 trillion dollars annually on the global economy by cyber crime. Estimated of 328 Million Dollar annual losses with the cyber attacks in Australia itself. Various steps are taken to slow down these attacks but unfortunately not able to achieve success properly. Therefor secure IoT is the need of this time and understanding of attacks and threats in IoT structure should be studied. The reasons for cyber-attacks can be Countries having week cyber securities, Cybercriminals use new technologies to attack, Cybercrime is possible with services and other business schemes. MSP (Managed Service Providers) face different difficulties in fighting with Cyber-crime. They have to ensure that security of the customer as well as their security in terms of their servers, devices, and systems. Hence, they must use effective, fast, and easily usable antivirus and antimalware tools.
Multiple Node Immunisation for Preventing Epidemics on Networks by Exact Multiobjective Optimisation of Cost and Shield-Value
Oct 13, 2020



The general problem in this paper is vertex (node) subset selection with the goal to contain an infection that spreads in a network. Instead of selecting the single most important node, this paper deals with the problem of selecting multiple nodes for removal. As compared to previous work on multiple-node selection, the trade-off between cost and benefit is considered. The benefit is measured in terms of increasing the epidemic threshold which is a measure of how difficult it is for an infection to spread in a network. The cost is measured in terms of the number and size of nodes to be removed or controlled. Already in its single-objective instance with a fixed number of $k$ nodes to be removed, the multiple vertex immunisation problems have been proven to be NP-hard. Several heuristics have been developed to approximate the problem. In this work, we compare meta-heuristic techniques with exact methods on the Shield-value, which is a sub-modular proxy for the maximal eigenvalue and used in the current state-of-the-art greedy node-removal strategies. We generalise it to the multi-objective case and replace the greedy algorithm by a quadratic program (QP), which then can be solved with exact QP solvers. The main contribution of this paper is the insight that, if time permits, exact and problem-specific methods approximation should be used, which are often far better than Pareto front approximations obtained by general meta-heuristics. Based on these, it will be more effective to develop strategies for controlling real-world networks when the goal is to prevent or contain epidemic outbreaks. This paper is supported by ready to use Python implementation of the optimization methods and datasets.
Recurrent Neural Network Control of a Hybrid Dynamic Transfemoral Prosthesis with EdgeDRNN Accelerator
Feb 08, 2020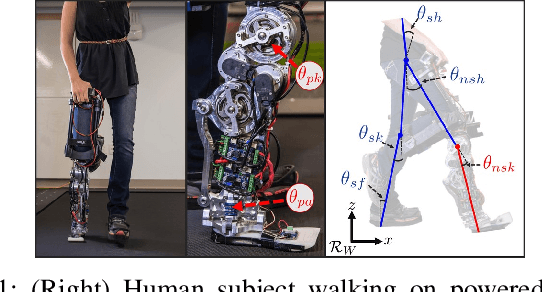
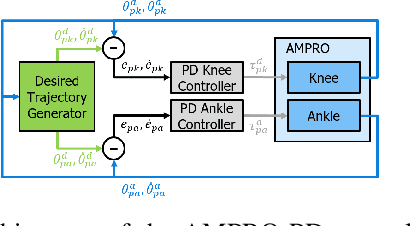
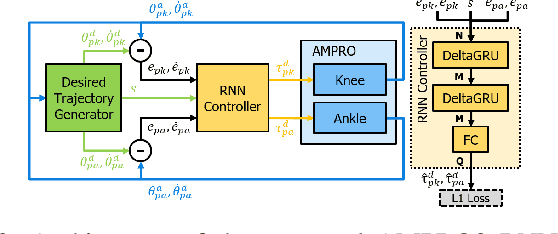
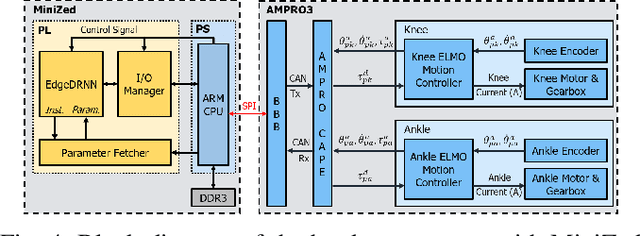
Lower leg prostheses could improve the lives of amputees by increasing comfort and reducing energy to locomote, but currently the control methods make it difficult to modulate behaviors based upon the human's experience. This paper describes the first steps toward learning complex controllers for dynamic robotic assistive devices. We provide the first example of behavioral cloning to control a powered transfemoral knee and ankle prostheses using a Gated Recurrent Unit (GRU) based recurrent neural network (RNN) running on a custom hardware accelerator that exploits temporal sparsity. The RNN is trained on data collected from the original prosthesis controller. The RNN inference is realized by a novel EdgeDRNN accelerator in real-time. Experimental results show that the RNN can model the dynamic system with impacts and replace the nominal PD controller to realize end-to-end control of the AMPRO3 prosthetic leg walking on flat ground and unforeseen slopes with comparable tracking accuracy. EdgeRNN computes the RNN about 240 times faster than real time, opening the possibility of more complex future optimizations. Implementing an RNN on this real-time dynamic system with impacts sets the ground work to incorporate other learned elements of the human-prosthesis system into prosthesis control.