 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Descent-to-Delete: Gradient-Based Methods for Machine Unlearning
Jul 06, 2020
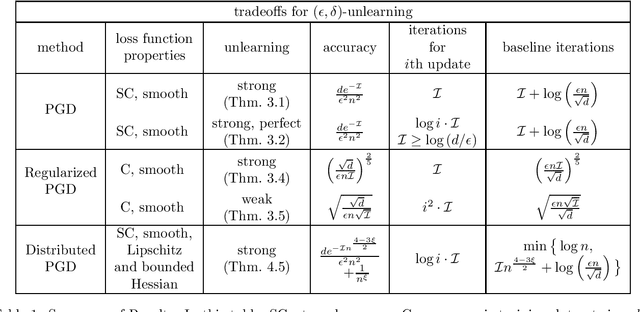
We study the data deletion problem for convex models. By leveraging techniques from convex optimization and reservoir sampling, we give the first data deletion algorithms that are able to handle an arbitrarily long sequence of adversarial updates while promising both per-deletion run-time and steady-state error that do not grow with the length of the update sequence. We also introduce several new conceptual distinctions: for example, we can ask that after a deletion, the entire state maintained by the optimization algorithm is statistically indistinguishable from the state that would have resulted had we retrained, or we can ask for the weaker condition that only the observable output is statistically indistinguishable from the observable output that would have resulted from retraining. We are able to give more efficient deletion algorithms under this weaker deletion criterion.
Localizing the Common Action Among a Few Videos
Aug 13, 2020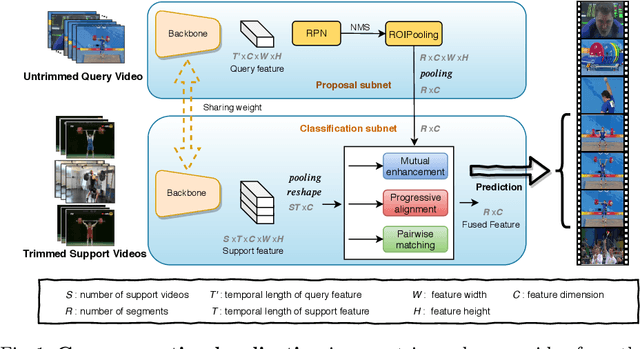
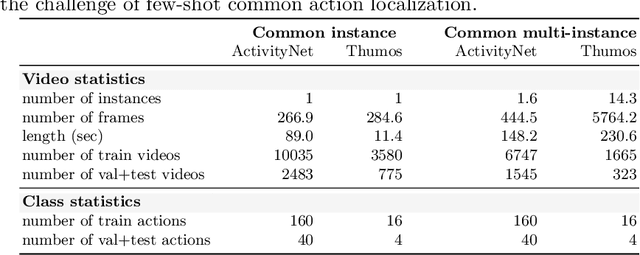
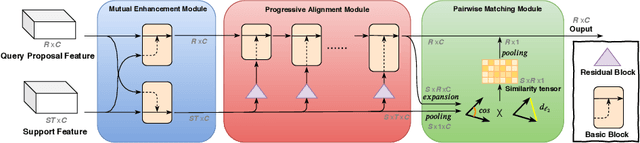
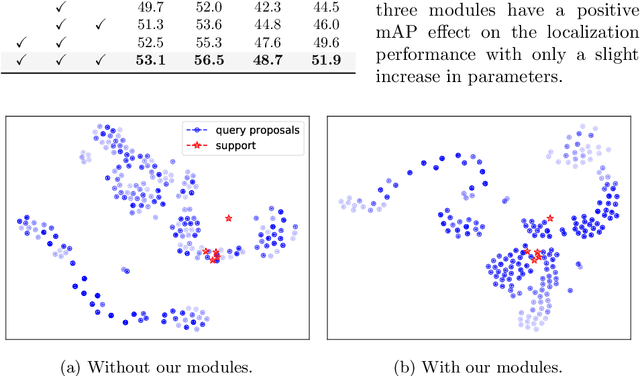
This paper strives to localize the temporal extent of an action in a long untrimmed video. Where existing work leverages many examples with their start, their ending, and/or the class of the action during training time, we propose few-shot common action localization. The start and end of an action in a long untrimmed video is determined based on just a hand-full of trimmed video examples containing the same action, without knowing their common class label. To address this task, we introduce a new 3D convolutional network architecture able to align representations from the support videos with the relevant query video segments. The network contains: (\textit{i}) a mutual enhancement module to simultaneously complement the representation of the few trimmed support videos and the untrimmed query video; (\textit{ii}) a progressive alignment module that iteratively fuses the support videos into the query branch; and (\textit{iii}) a pairwise matching module to weigh the importance of different support videos. Evaluation of few-shot common action localization in untrimmed videos containing a single or multiple action instances demonstrates the effectiveness and general applicability of our proposal.
Small Towers Make Big Differences
Aug 13, 2020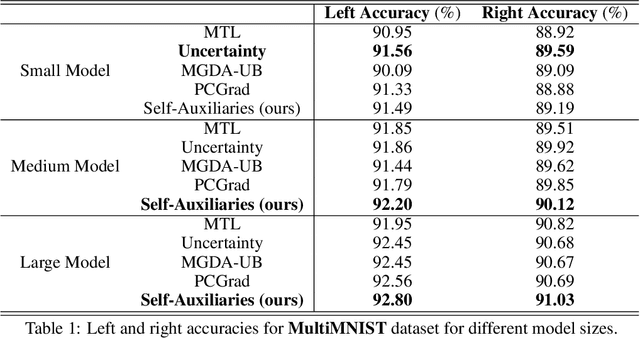
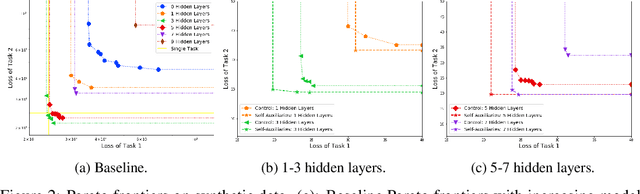
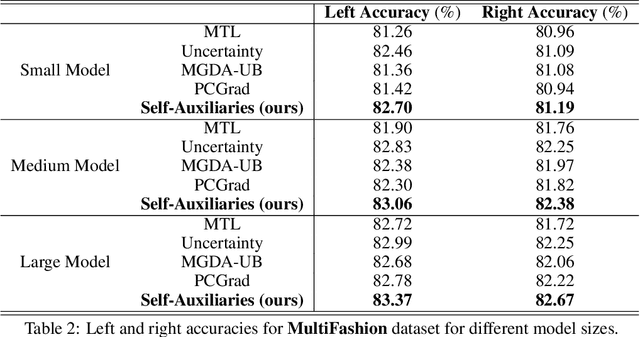
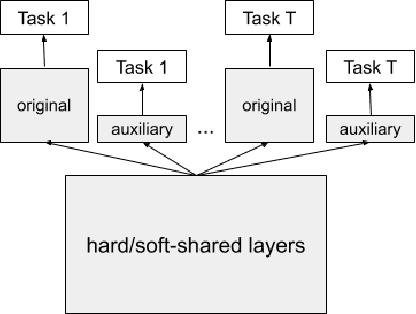
Multi-task learning aims at solving multiple machine learning tasks at the same time. A good solution to a multi-task learning problem should be generalizable in addition to being Pareto optimal. In this paper, we provide some insights on understanding the trade-off between Pareto efficiency and generalization as a result of parameterization in multi-task deep learning models. As a multi-objective optimization problem, enough parameterization is needed for handling task conflicts in a constrained solution space; however, from a multi-task generalization perspective, over-parameterization undermines the benefit of learning a shared representation which helps harder tasks or tasks with limited training examples. A delicate balance between multi-task generalization and multi-objective optimization is therefore needed for finding a better trade-off between efficiency and generalization. To this end, we propose a method of under-parameterized self-auxiliaries for multi-task models to achieve the best of both worlds. It is task-agnostic and works with other multi-task learning algorithms. Empirical results show that small towers of under-parameterized self-auxiliaries can make big differences in improving Pareto efficiency in various multi-task applications.
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 11, 2020
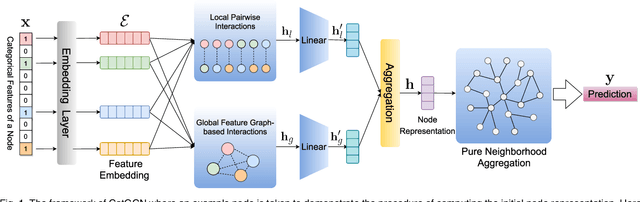
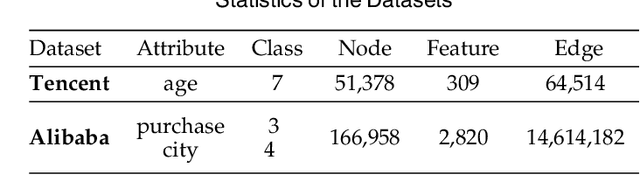
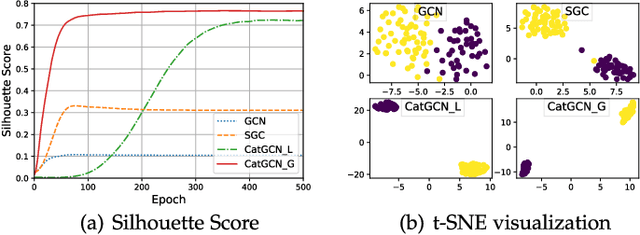
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
STAN: Synthetic Network Traffic Generation using Autoregressive Neural Models
Sep 27, 2020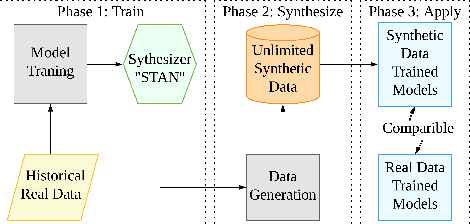
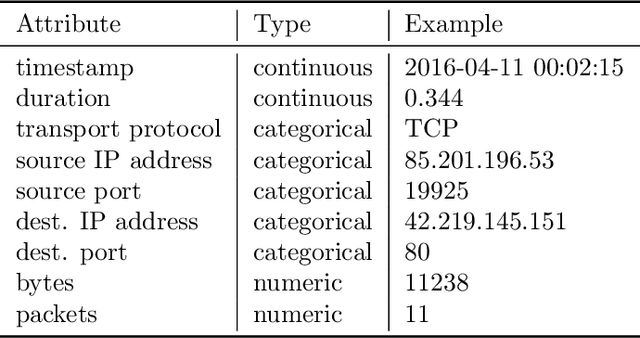

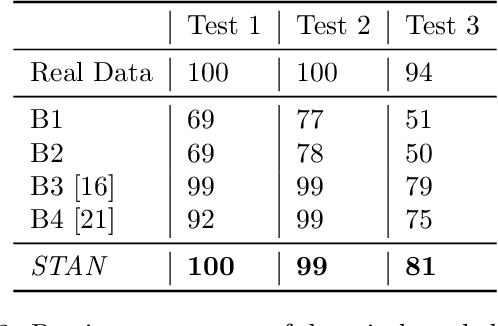
Deep learning models have achieved great success in recent years. However, large amounts of data are typically required to train such models. While some types of data, such as images, videos, and text, are easier to find, data in certain domains is difficult to obtain. For instance, cybersecurity applications routinely use network traffic data which organizations are reluctant to share, even internally, due to privacy reasons. An alternative is to use synthetically generated data; however, most existing data generating methods lack the ability to capture complex dependency structures that are usually prevalent in real data by assuming independence either temporally or between attributes. This paper presents our approach called STAN, Synthetic Network Traffic Generation using Autoregressive Neural models, to generate realistic synthetic network traffic data. Our novel autoregressive neural architecture captures both temporal dependence and dependence between attributes at any given time. It integrates convolutional neural layers (CNN) with mixture density layers (MDN) and softmax layers to model both continuous and discrete variables. We evaluate performance of STAN by training it on both a simulated dataset and a real network traffic data set. Multiple metrics are used to compare the generated data with real data and with data generated via several baseline methods. Finally, to answer the question -- can real network traffic data be substituted with synthetic data to train models of comparable accuracy -- we consider two commonly used models for anomaly detection in such data, and compare F1/MSE measures of models trained on real data and those on increasing proportions of generated data. The results show only a small decline in accuracy of models trained solely on synthetic data.
Interpretable Control by Reinforcement Learning
Jul 20, 2020

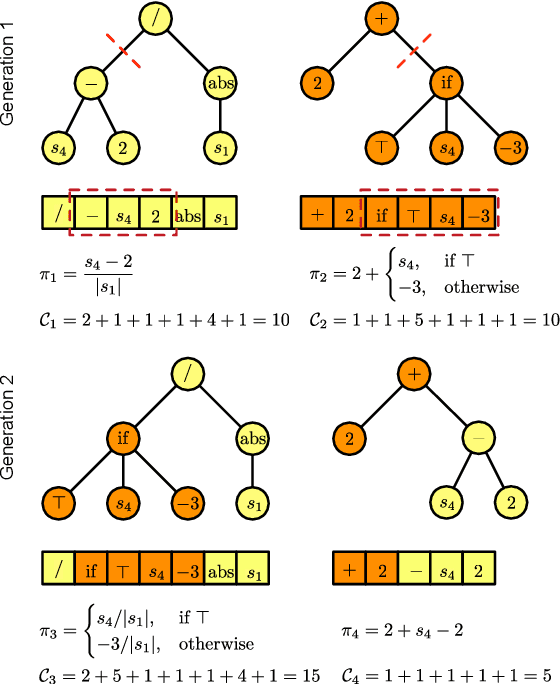
In this paper, three recently introduced reinforcement learning (RL) methods are used to generate human-interpretable policies for the cart-pole balancing benchmark. The novel RL methods learn human-interpretable policies in the form of compact fuzzy controllers and simple algebraic equations. The representations as well as the achieved control performances are compared with two classical controller design methods and three non-interpretable RL methods. All eight methods utilize the same previously generated data batch and produce their controller offline - without interaction with the real benchmark dynamics. The experiments show that the novel RL methods are able to automatically generate well-performing policies which are at the same time human-interpretable. Furthermore, one of the methods is applied to automatically learn an equation-based policy for a hardware cart-pole demonstrator by using only human-player-generated batch data. The solution generated in the first attempt already represents a successful balancing policy, which demonstrates the methods applicability to real-world problems.
End-to-end Learning for OFDM: From Neural Receivers to Pilotless Communication
Sep 11, 2020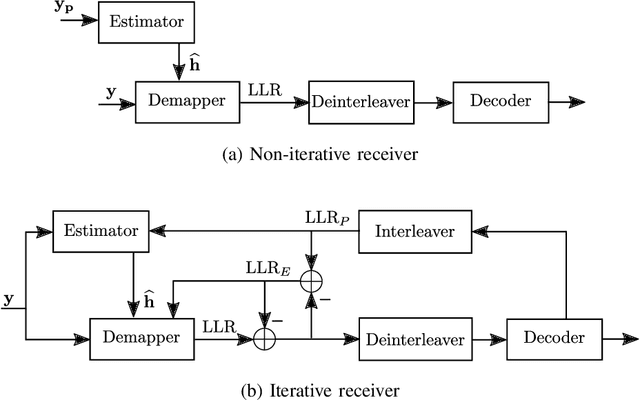
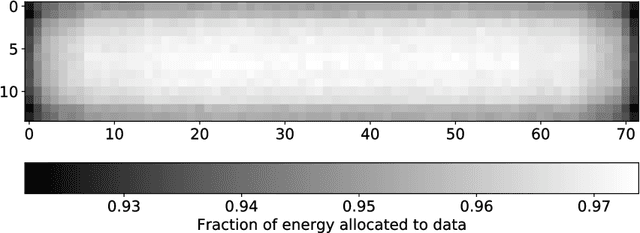
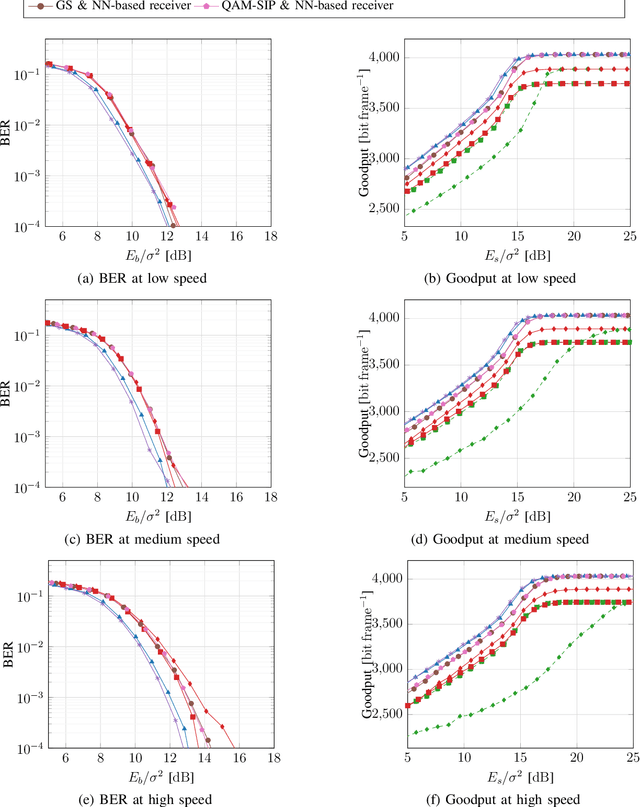
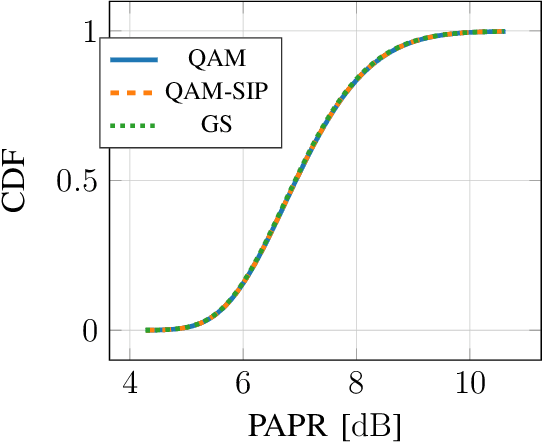
Previous studies have demonstrated that end-to-end learning enables significant shaping gains over additive white Gaussian noise (AWGN) channels. However, its benefits have not yet been quantified over realistic wireless channel models. This work aims to fill this gap by exploring the gains of end-to-end learning over a frequency- and time-selective fading channel using orthogonal frequency division multiplexing (OFDM). With imperfect channel knowledge at the receiver, the shaping gains observed on AWGN channels vanish. Nonetheless, we identify two other sources of performance improvements. The first comes from a neural network (NN)-based receiver operating over a large number of subcarriers and OFDM symbols which allows to significantly reduce the number of orthogonal pilots without loss of bit error rate (BER). The second comes from entirely eliminating orthognal pilots by jointly learning a neural receiver together with either superimposed pilots (SIPs), linearly combined with conventional quadrature amplitude modulation (QAM), or an optimized constellation geometry. The learned geometry works for a wide range of signal-to-noise ratios (SNRs), Doppler and delay spreads, has zero mean and does hence not contain any form of superimposed pilots. Both schemes achieve the same BER as the pilot-based baseline with around 7% higher throughput. Thus, we believe that a jointly learned transmitter and receiver are a very interesting component for beyond-5G communication systems which could remove the need and associated control overhead for demodulation reference signals (DMRSs).
Efficient Multi-Robot Exploration with Energy Constraint based on Optimal Transport Theory
Sep 02, 2020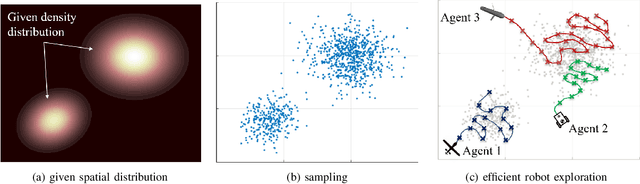
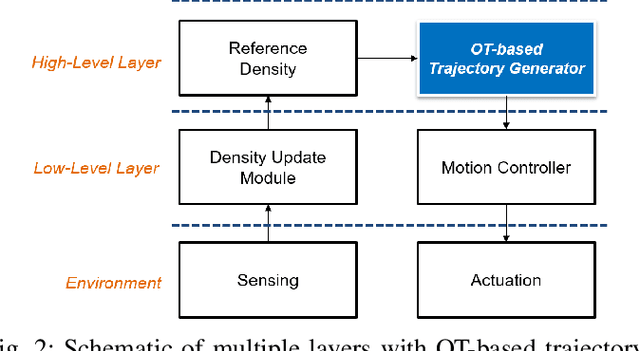
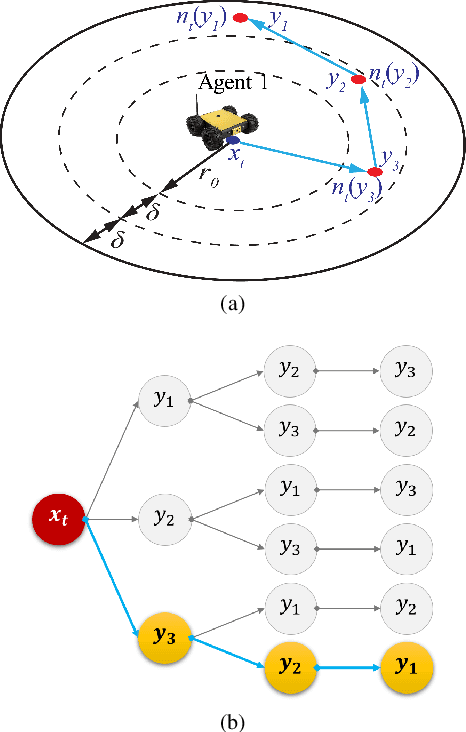
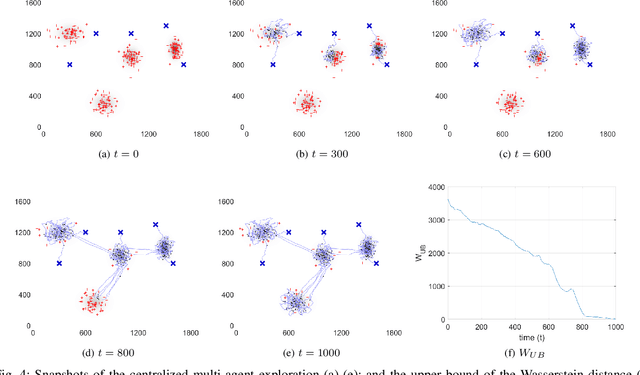
This paper addresses an Optimal Transport (OT)-based efficient multi-robot exploration problem, considering the energy constraints of a multi-robot system. The efficiency in this problem implies how a team of robots (agents) covers a given domain, reflecting a priority of areas of interest represented by a density distribution, rather than simply following a preset of uniform patterns. To achieve an efficient multi-robot exploration, the optimal transport theory that quantifies a distance between two density distributions is employed as a tool, which also serves as a means of performance measure. The energy constraints for the multi-robot system is then incorporated into the OT-based multi-robot exploration scheme. The proposed scheme is decoupled from robot dynamics, broadening the applicability of the multi-robot exploration plan to heterogeneous robot platforms. Not only the centralized but also decentralized algorithms are provided to cope with more realistic scenarios such as communication range limits between agents. To measure the exploration efficiency, the upper bound of the performance is developed for both the centralized and decentralized cases based on the optimal transport theory, which is computationally tractable as well as efficient. The proposed multi-robot exploration scheme is also applicable to a time-varying distribution, where the spatio-temporal evolution of the given reference distribution is desired. To validate the proposed method, multiple simulation results are provided.
MPE: A Mobility Pattern Embedding Model for Predicting Next Locations
Mar 16, 2020
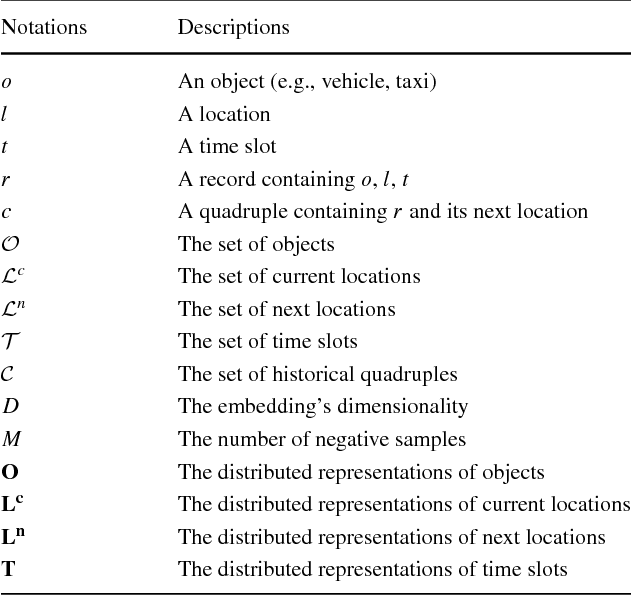
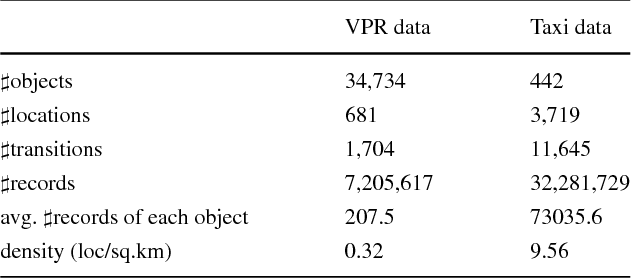
The wide spread use of positioning and photographing devices gives rise to a deluge of traffic trajectory data (e.g., vehicle passage records and taxi trajectory data), with each record having at least three attributes: object ID, location ID, and time-stamp. In this paper, we propose a novel mobility pattern embedding model called MPE to shed the light on people's mobility patterns in traffic trajectory data from multiple aspects, including sequential, personal, and temporal factors. MPE has two salient features: (1) it is capable of casting various types of information (object, location and time) to an integrated low-dimensional latent space; (2) it considers the effect of ``phantom transitions'' arising from road networks in traffic trajectory data. This embedding model opens the door to a wide range of applications such as next location prediction and visualization. Experimental results on two real-world datasets show that MPE is effective and outperforms the state-of-the-art methods significantly in a variety of tasks.
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Aug 13, 2020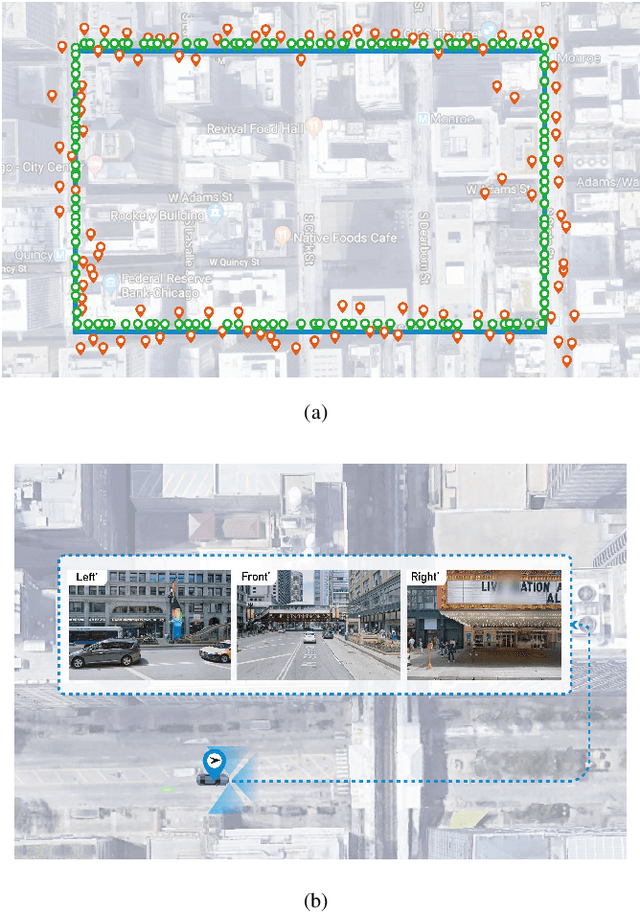
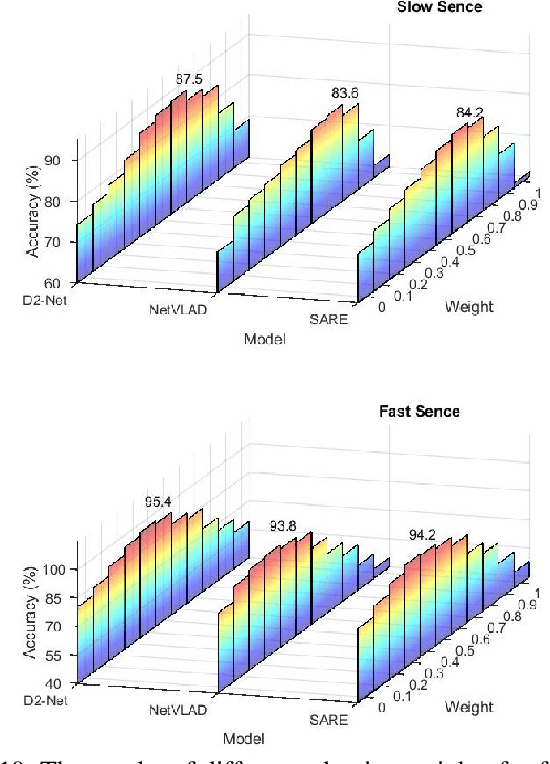
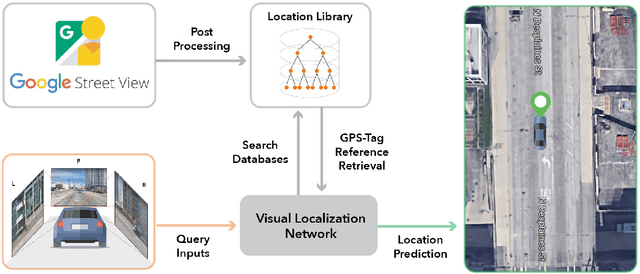
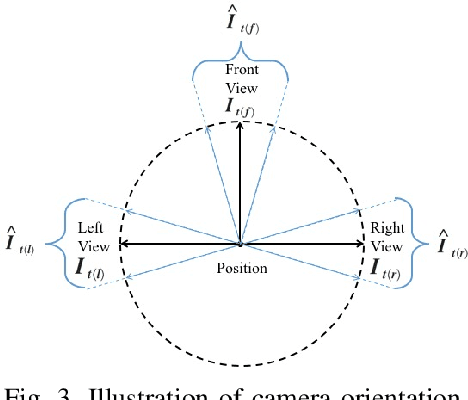
Accurate localization is a foundational capacity, required for autonomous vehicles to accomplish other tasks such as navigation or path planning. It is a common practice for vehicles to use GPS to acquire location information. However, the application of GPS can result in severe challenges when vehicles run within the inner city where different kinds of structures may shadow the GPS signal and lead to inaccurate location results. To address the localization challenges of urban settings, we propose a novel feature voting technique for visual localization. Different from the conventional front-view-based method, our approach employs views from three directions (front, left, and right) and thus significantly improves the robustness of location prediction. In our work, we craft the proposed feature voting method into three state-of-the-art visual localization networks and modify their architectures properly so that they can be applied for vehicular operation. Extensive field test results indicate that our approach can predict location robustly even in challenging inner-city settings. Our research sheds light on using the visual localization approach to help autonomous vehicles to find accurate location information in a city maze, within a desirable time constraint.