 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sampling possible reconstructions of undersampled acquisitions in MR imaging
Sep 30, 2020
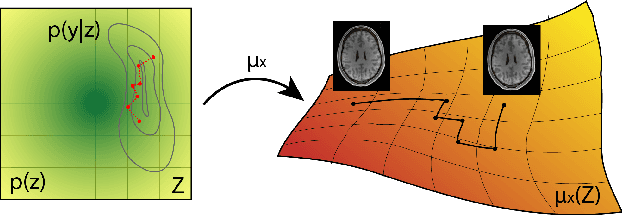
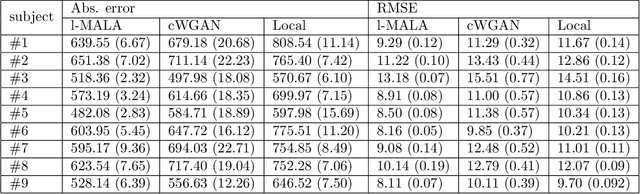
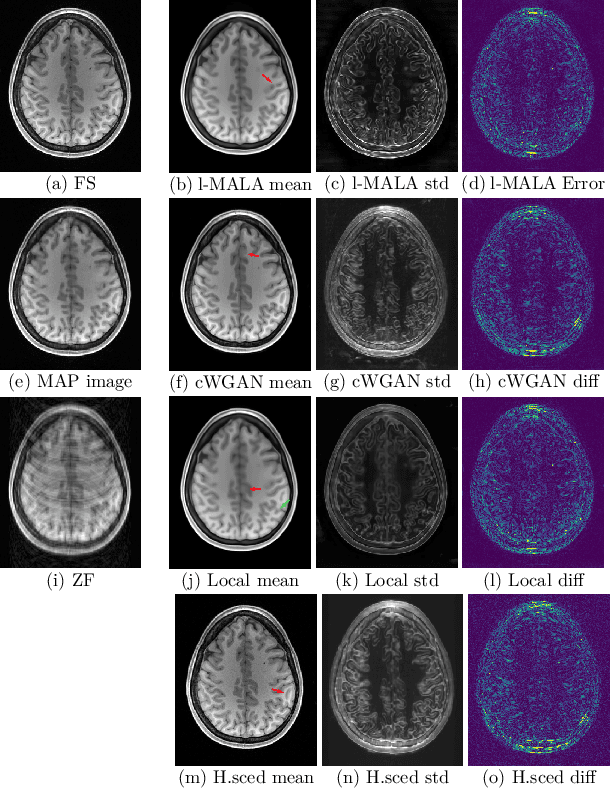
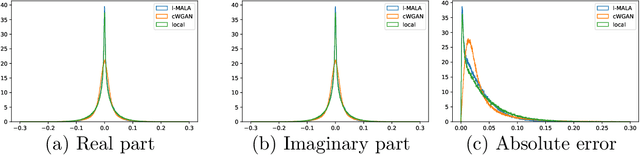
Undersampling the k-space during MR acquisitions saves time, however results in an ill-posed inversion problem, leading to an infinite set of images as possible solutions. Traditionally, this is tackled as a reconstruction problem by searching for a single "best" image out of this solution set according to some chosen regularization or prior. This approach, however, misses the possibility of other solutions and hence ignores the uncertainty in the inversion process. In this paper, we propose a method that instead returns multiple images which are possible under the acquisition model and the chosen prior. To this end, we introduce a low dimensional latent space and model the posterior distribution of the latent vectors given the acquisition data in k-space, from which we can sample in the latent space and obtain the corresponding images. We use a variational autoencoder for the latent model and the Metropolis adjusted Langevin algorithm for the sampling. This approach allows us to obtain multiple possible images and capture the uncertainty in the inversion process under the used prior. We evaluate our method on images from the Human Connectome Project dataset as well as in-house measured multi-coil images and compare to two different methods. The results indicate that the proposed method is capable of producing images that match the ground truth in regions where acquired k-space data is informative and construct different possible reconstructions, which show realistic structural variations, in regions where acquired k-space data is not informative. Keywords: Magnetic Resonance image reconstruction, uncertainty estimation, inverse problems, sampling, MCMC, deep learning, unsupervised learning.
Link Prediction for Temporally Consistent Networks
Jun 06, 2020

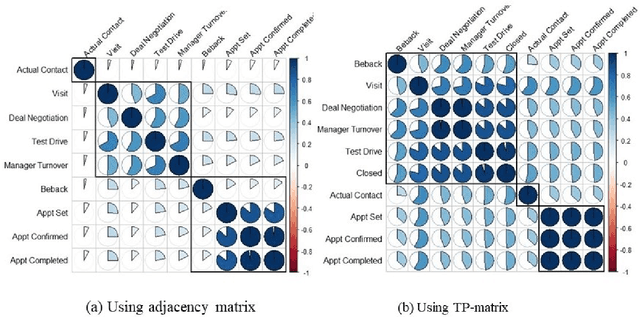
Dynamic networks have intrinsic structural, computational, and multidisciplinary advantages. Link prediction estimates the next relationship in dynamic networks. However, in the current link prediction approaches, only bipartite or non-bipartite but homogeneous networks are considered. The use of adjacency matrix to represent dynamically evolving networks limits the ability to analytically learn from heterogeneous, sparse, or forming networks. In the case of a heterogeneous network, modeling all network states using a binary-valued matrix can be difficult. On the other hand, sparse or currently forming networks have many missing edges, which are represented as zeros, thus introducing class imbalance or noise. We propose a time-parameterized matrix (TP-matrix) and empirically demonstrate its effectiveness in non-bipartite, heterogeneous networks. In addition, we propose a predictive influence index as a measure of a node's boosting or diminishing predictive influence using backward and forward-looking maximization over the temporal space of the n-degree neighborhood. We further propose a new method of canonically representing heterogeneous time-evolving activities as a temporally parameterized network model (TPNM). The new method robustly enables activities to be represented as a form of a network, thus potentially inspiring new link prediction applications, including intelligent business process management systems and context-aware workflow engines. We evaluated our model on four datasets of different network systems. We present results that show the proposed model is more effective in capturing and retaining temporal relationships in dynamically evolving networks. We also show that our model performed better than state-of-the-art link prediction benchmark results for networks that are sensitive to temporal evolution.
A Hybrid Residual Dilated LSTM end Exponential Smoothing Model for Mid-Term Electric Load Forecasting
Mar 29, 2020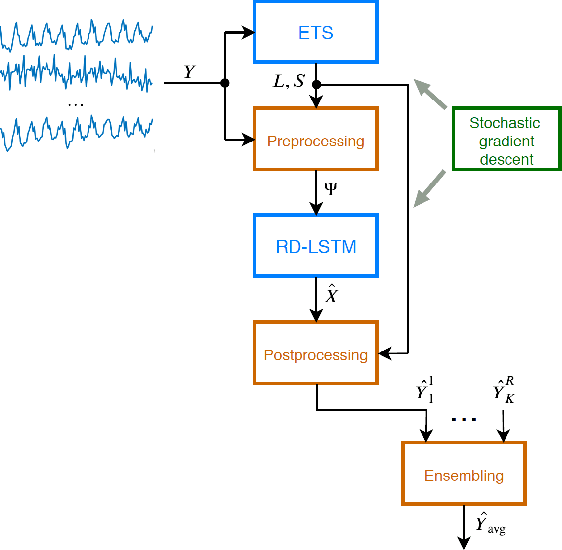
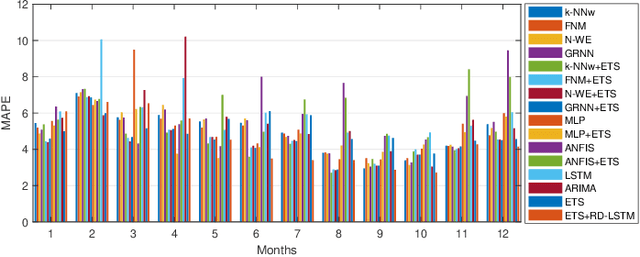
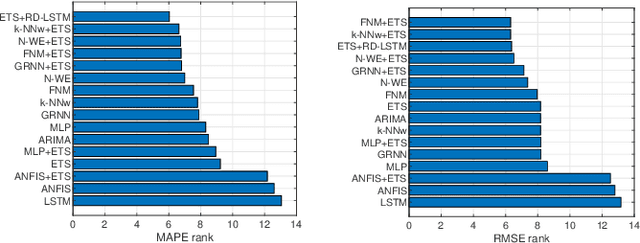
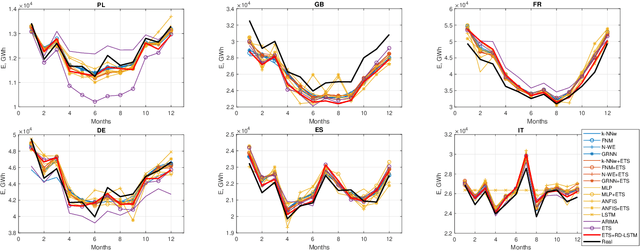
This work presents a hybrid and hierarchical deep learning model for mid-term load forecasting. The model combines exponential smoothing (ETS), advanced Long Short-Term Memory (LSTM) and ensembling. ETS extracts dynamically the main components of each individual time series and enables the model to learn their representation. Multi-layer LSTM is equipped with dilated recurrent skip connections and a spatial shortcut path from lower layers to allow the model to better capture long-term seasonal relationships and ensure more efficient training. A common learning procedure for LSTM and ETS, with a penalized pinball loss, leads to simultaneous optimization of data representation and forecasting performance. In addition, ensembling at three levels ensures a powerful regularization. A simulation study performed on the monthly electricity demand time series for 35 European countries confirmed the high performance of the proposed model and its competitiveness with classical models such as ARIMA and ETS as well as state-of-the-art models based on machine learning.
The Importance of Being Correlated: Implications of Dependence in Joint Spectral Inference across Multiple Networks
Aug 01, 2020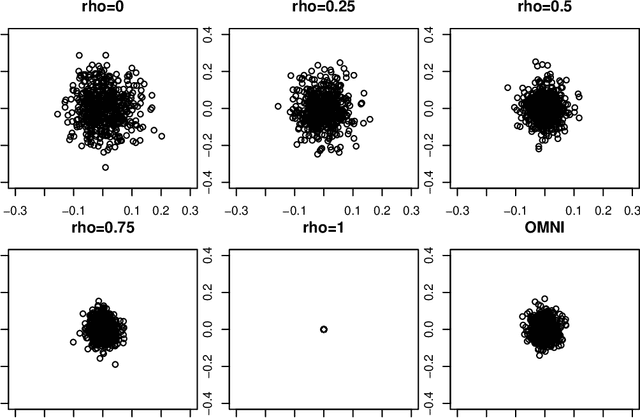

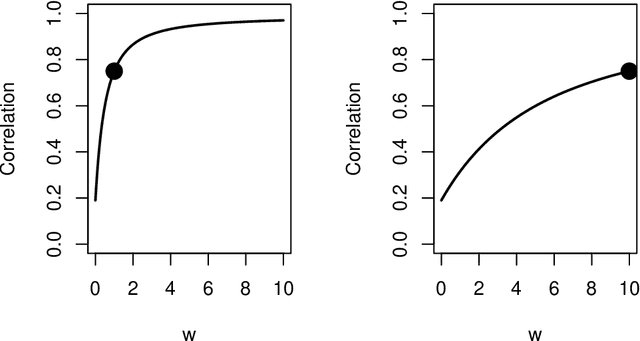
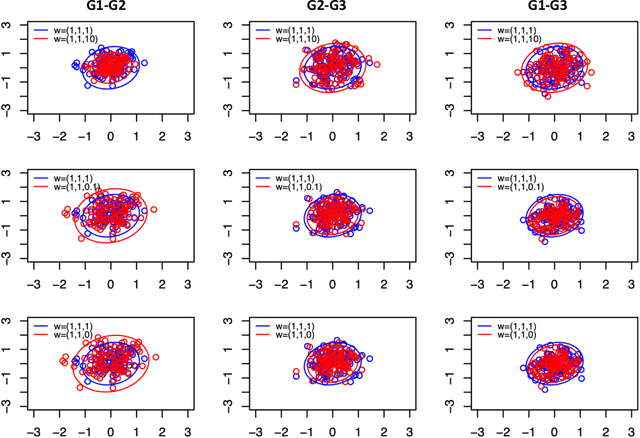
Spectral inference on multiple networks is a rapidly-developing subfield of graph statistics. Recent work has demonstrated that joint, or simultaneous, spectral embedding of multiple independent network realizations can deliver more accurate estimation than individual spectral decompositions of those same networks. Little attention has been paid, however, to the network correlation that such joint embedding procedures necessarily induce. In this paper, we present a detailed analysis of induced correlation in a {\em generalized omnibus} embedding for multiple networks. We show that our embedding procedure is flexible and robust, and, moreover, we prove a central limit theorem for this embedding and explicitly compute the limiting covariance. We examine how this covariance can impact inference in a network time series, and we construct an appropriately calibrated omnibus embedding that can detect changes in real biological networks that previous embedding procedures could not discern. Our analysis confirms that the effect of induced correlation can be both subtle and transformative, with import in theory and practice.
Active Preference-Based Gaussian Process Regression for Reward Learning
May 06, 2020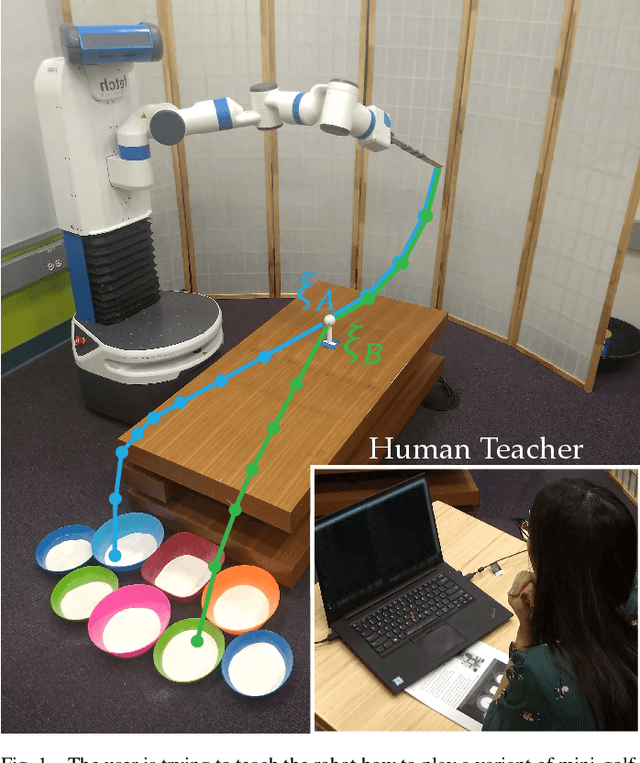
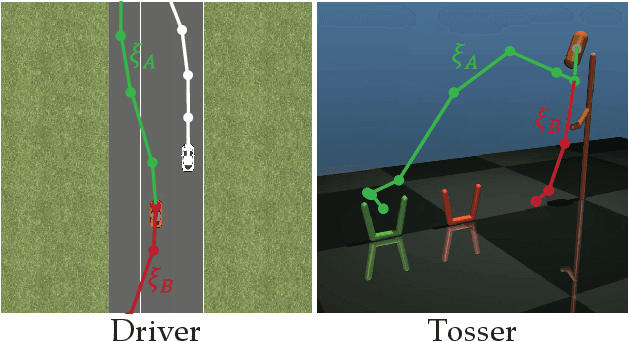
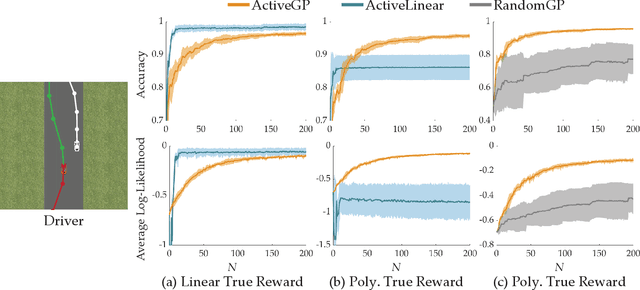
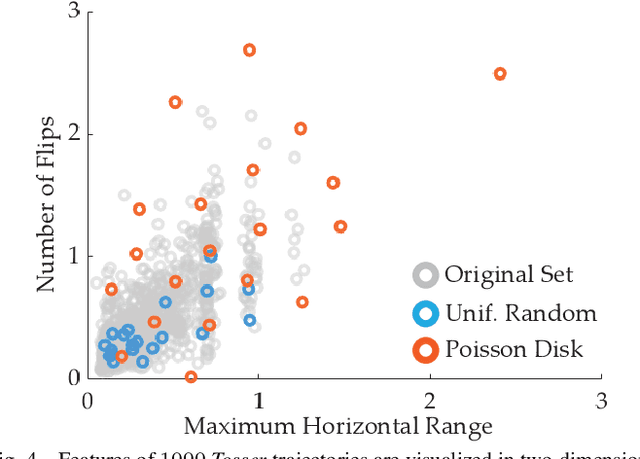
Designing reward functions is a challenging problem in AI and robotics. Humans usually have a difficult time directly specifying all the desirable behaviors that a robot needs to optimize. One common approach is to learn reward functions from collected expert demonstrations. However, learning reward functions from demonstrations introduces many challenges ranging from methods that require highly structured models, e.g. reward functions that are linear in some predefined set of features to less structured reward functions that on the other hand require tremendous amount of data. In addition, humans tend to have a difficult time providing demonstrations on robots with high degrees of freedom, or even quantifying reward values for given demonstrations. To address these challenges, we present a preference-based learning approach, where as an alternative, the human feedback is only of the form of comparisons between trajectories. Furthermore, we do not assume highly constrained structures on the reward function. Instead, we model the reward function using a Gaussian Process (GP) and propose a mathematical formulation to actively find a GP using only human preferences. Our approach enables us to tackle both inflexibility and data-inefficiency problems within a preference-based learning framework. Our results in simulations and a user study suggest that our approach can efficiently learn expressive reward functions for robotics tasks.
Using LDA and LSTM Models to Study Public Opinions and Critical Groups Towards Congestion Pricing in New York City through 2007 to 2019
Aug 01, 2020
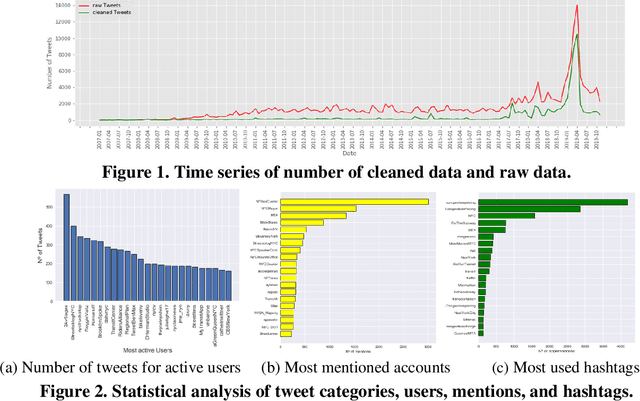

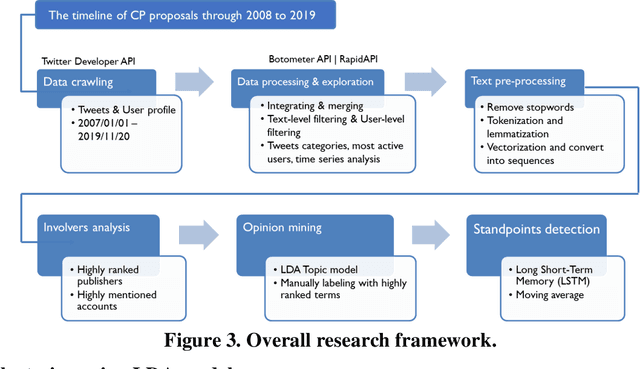
This study explores how people view and respond to the proposals of NYC congestion pricing evolve in time. To understand these responses, Twitter data is collected and analyzed. Critical groups in the recurrent process are detected by statistically analyzing the active users and the most mentioned accounts, and the trends of people's attitudes and concerns over the years are identified with text mining and hybrid Nature Language Processing techniques, including LDA topic modeling and LSTM sentiment classification. The result shows that multiple interest groups were involved and played crucial roles during the proposal, especially Mayor and Governor, MTA, and outer-borough representatives. The public shifted the concern of focus from the plan details to a wider city's sustainability and fairness. Furthermore, the plan's approval relies on several elements, the joint agreement reached in the political process, strong motivation in the real-world, the scheme based on balancing multiple interests, and groups' awareness of tolling's benefits and necessity.
GraphXCOVID: Explainable Deep Graph Diffusion Pseudo-Labelling for Identifying COVID-19 on Chest X-rays
Sep 30, 2020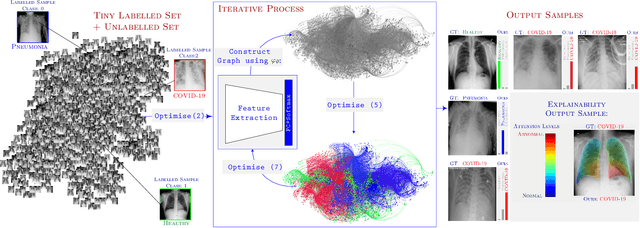
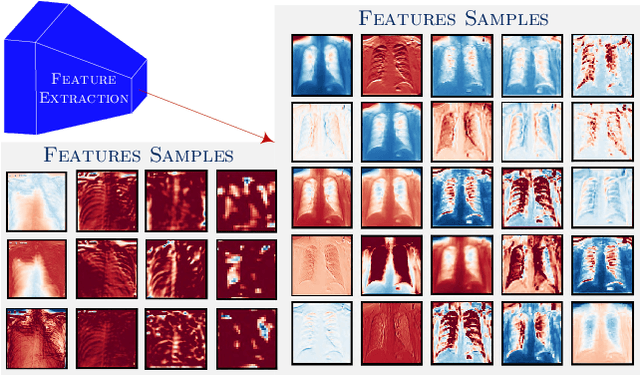
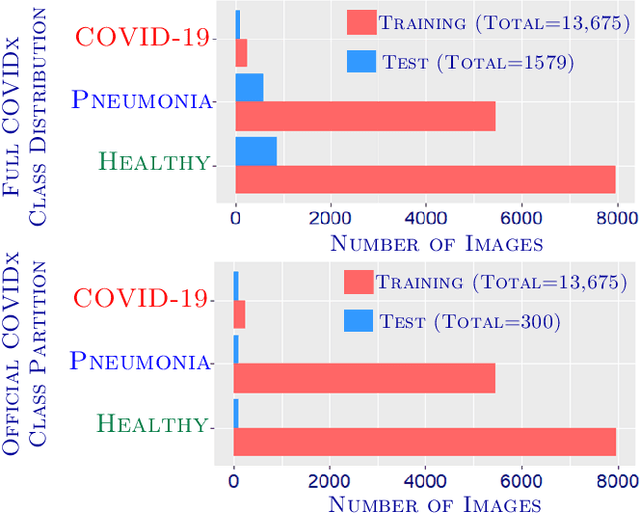
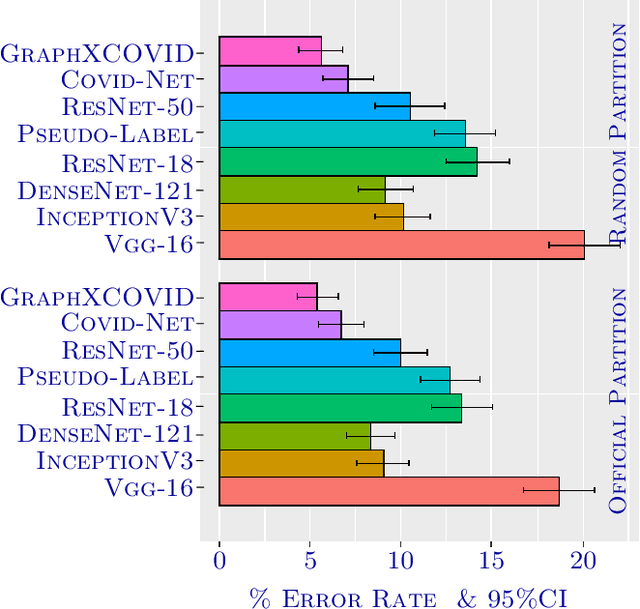
Can one learn to diagnose COVID-19 under extreme minimal supervision? Since the outbreak of the novel COVID-19 there has been a rush for developing Artificial Intelligence techniques for expert-level disease identification on Chest X-ray data. In particular, the use of deep supervised learning has become the go-to paradigm. However, the performance of such models is heavily dependent on the availability of a large and representative labelled dataset. The creation of which is a heavily expensive and time consuming task, and especially imposes a great challenge for a novel disease. Semi-supervised learning has shown the ability to match the incredible performance of supervised models whilst requiring a small fraction of the labelled examples. This makes the semi-supervised paradigm an attractive option for identifying COVID-19. In this work, we introduce a graph based deep semi-supervised framework for classifying COVID-19 from chest X-rays. Our framework introduces an optimisation model for graph diffusion that reinforces the natural relation among the tiny labelled set and the vast unlabelled data. We then connect the diffusion prediction output as pseudo-labels that are used in an iterative scheme in a deep net. We demonstrate, through our experiments, that our model is able to outperform the current leading supervised model with a tiny fraction of the labelled examples. Finally, we provide attention maps to accommodate the radiologist's mental model, better fitting their perceptual and cognitive abilities. These visualisation aims to assist the radiologist in judging whether the diagnostic is correct or not, and in consequence to accelerate the decision.
A Partial Regularization Method for Network Compression
Sep 04, 2020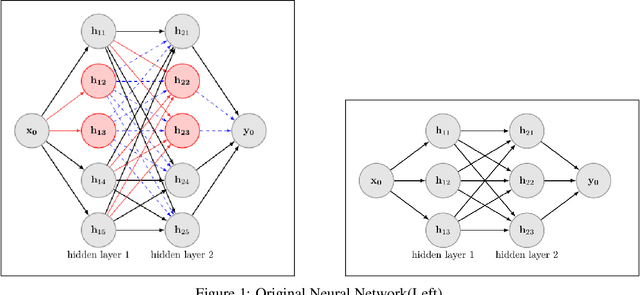
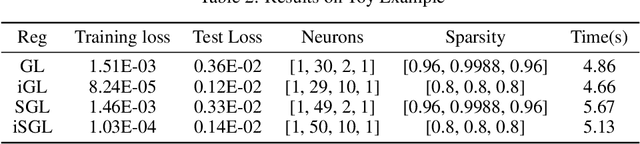
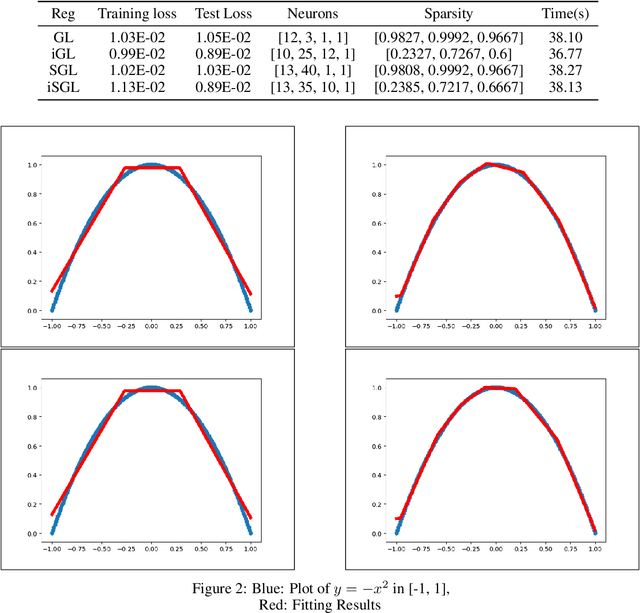
Deep Neural Networks have achieved remarkable success relying on the developing availability of GPUs and large-scale datasets with increasing network depth and width. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in order to make them practical for constrained platforms. In this paper, we propose an approach of partial regularization rather than the original form of penalizing all parameters, which is said to be full regularization, to conduct model compression at a higher speed. It is reasonable and feasible according to the existence of the permutation invariant property of neural networks. Experimental results show that as we expected, the computational complexity is reduced by observing less running time in almost all situations. It should be owing to the fact that partial regularization method invovles a lower number of elements for calculation. Surprisingly, it helps to improve some important metrics such as regression fitting results and classification accuracy in both training and test phases on multiple datasets, telling us that the pruned models have better performance and generalization ability. What's more, we analyze the results and draw a conclusion that an optimal network structure must exist and depend on the input data.
Synthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild
Sep 22, 2020
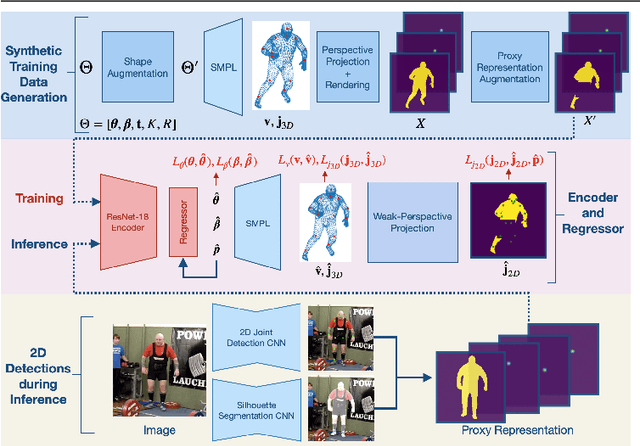
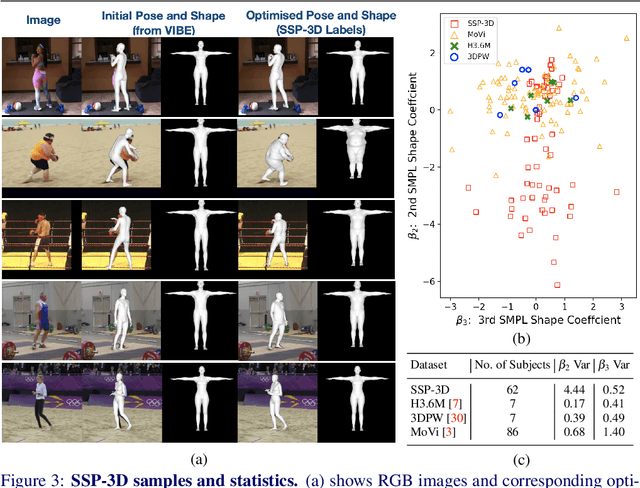

This paper addresses the problem of monocular 3D human shape and pose estimation from an RGB image. Despite great progress in this field in terms of pose prediction accuracy, state-of-the-art methods often predict inaccurate body shapes. We suggest that this is primarily due to the scarcity of in-the-wild training data with diverse and accurate body shape labels. Thus, we propose STRAPS (Synthetic Training for Real Accurate Pose and Shape), a system that utilises proxy representations, such as silhouettes and 2D joints, as inputs to a shape and pose regression neural network, which is trained with synthetic training data (generated on-the-fly during training using the SMPL statistical body model) to overcome data scarcity. We bridge the gap between synthetic training inputs and noisy real inputs, which are predicted by keypoint detection and segmentation CNNs at test-time, by using data augmentation and corruption during training. In order to evaluate our approach, we curate and provide a challenging evaluation dataset for monocular human shape estimation, Sports Shape and Pose 3D (SSP-3D). It consists of RGB images of tightly-clothed sports-persons with a variety of body shapes and corresponding pseudo-ground-truth SMPL shape and pose parameters, obtained via multi-frame optimisation. We show that STRAPS outperforms other state-of-the-art methods on SSP-3D in terms of shape prediction accuracy, while remaining competitive with the state-of-the-art on pose-centric datasets and metrics.
CycleMorph: Cycle Consistent Unsupervised Deformable Image Registration
Aug 13, 2020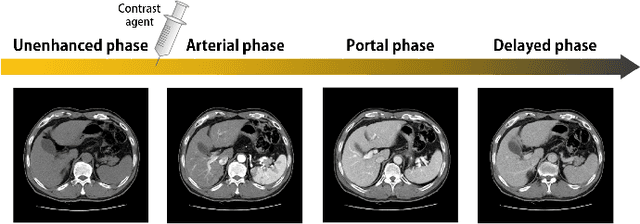
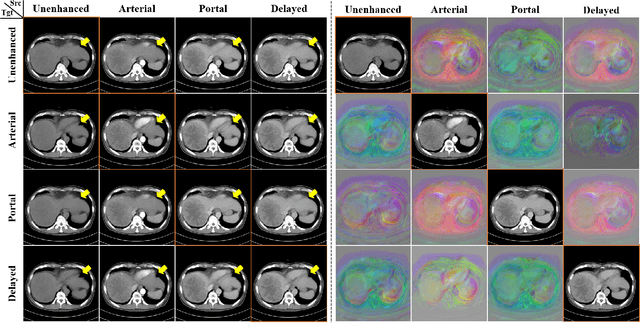
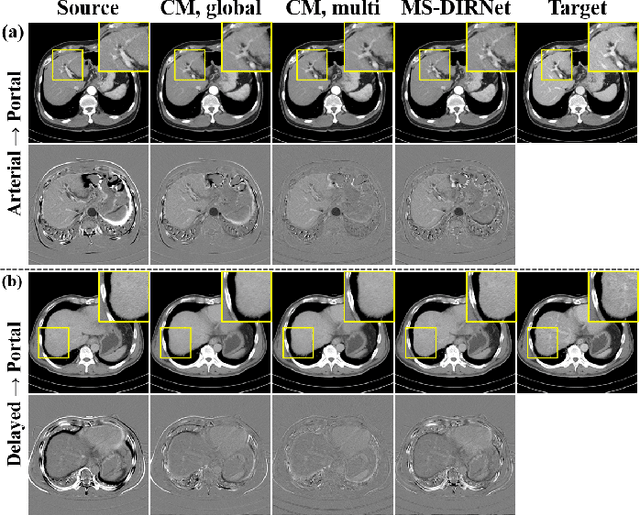
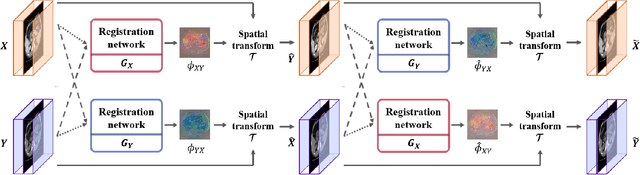
Image registration is a fundamental task in medical image analysis. Recently, deep learning based image registration methods have been extensively investigated due to their excellent performance despite the ultra-fast computational time. However, the existing deep learning methods still have limitation in the preservation of original topology during the deformation with registration vector fields. To address this issues, here we present a cycle-consistent deformable image registration. The cycle consistency enhances image registration performance by providing an implicit regularization to preserve topology during the deformation. The proposed method is so flexible that can be applied for both 2D and 3D registration problems for various applications, and can be easily extended to multi-scale implementation to deal with the memory issues in large volume registration. Experimental results on various datasets from medical and non-medical applications demonstrate that the proposed method provides effective and accurate registration on diverse image pairs within a few seconds. Qualitative and quantitative evaluations on deformation fields also verify the effectiveness of the cycle consistency of the proposed method.