 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S-RASTER: Contraction Clustering for Evolving Data Streams
Nov 21, 2019

Contraction Clustering (RASTER) is a very fast algorithm for density-based clustering, which requires only a single pass. It can process arbitrary amounts of data in linear time and in constant memory, quickly identifying approximate clusters. It also exhibits good scalability in the presence of multiple CPU cores. Yet, RASTER is limited to batch processing. In contrast, S-RASTER is an adaptation of RASTER to the stream processing paradigm that is able to identify clusters in evolving data streams. This algorithm retains the main benefits of its parent algorithm, i.e. single-pass linear time cost and constant memory requirements for each discrete time step in the sliding window. The sliding window is efficiently pruned, and clustering is still performed in linear time. Like RASTER, S-RASTER trades off an often negligible amount of precision for speed. It is therefore very well suited to real-world scenarios where clustering does not happen continually but only periodically. We describe the algorithm, including a discussion of implementation details.
An Efficient Machine-Learning Approach for PDF Tabulation in Turbulent Combustion Closure
May 18, 2020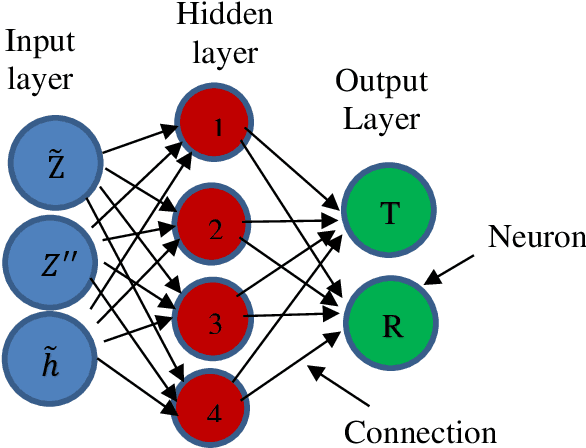
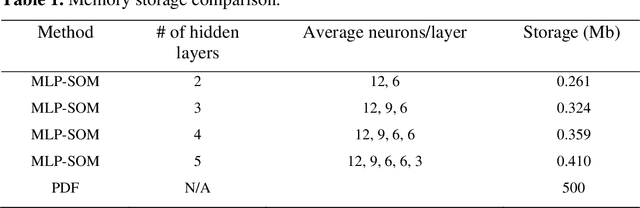
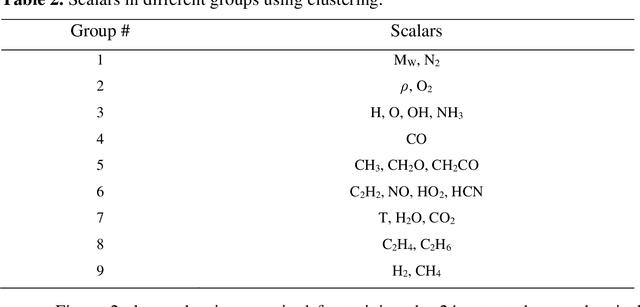
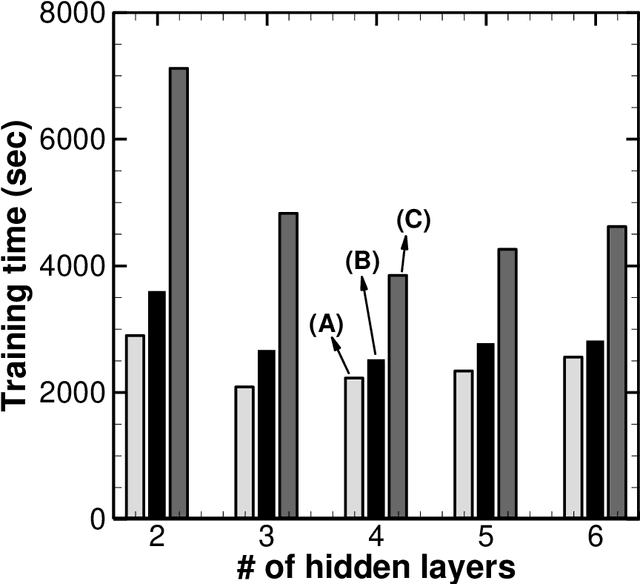
Probability density function (PDF) based turbulent combustion modelling is limited by the need to store multi-dimensional PDF tables that can take up large amounts of memory. A significant saving in storage can be achieved by using various machine-learning techniques that represent the thermo-chemical quantities of a PDF table using mathematical functions. These functions can be computationally more expensive than the existing interpolation methods used for thermo-chemical quantities. More importantly, the training time can amount to a considerable portion of the simulation time. In this work, we address these issues by introducing an adaptive training algorithm that relies on multi-layer perception (MLP) neural networks for regression and self-organizing maps (SOMs) for clustering data to tabulate using different networks. The algorithm is designed to address both the multi-dimensionality of the PDF table as well as the computational efficiency of the proposed algorithm. SOM clustering divides the PDF table into several parts based on similarities in data. Each cluster of data is trained using an MLP algorithm on simple network architectures to generate local functions for thermo-chemical quantities. The algorithm is validated for the so-called DLR-A turbulent jet diffusion flame using both RANS and LES simulations and the results of the PDF tabulation are compared to the standard linear interpolation method. The comparison yields a very good agreement between the two tabulation techniques and establishes the MLP-SOM approach as a viable method for PDF tabulation.
A Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition
Aug 15, 2020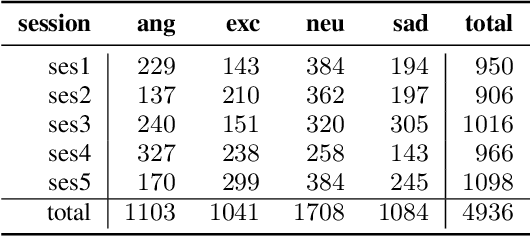
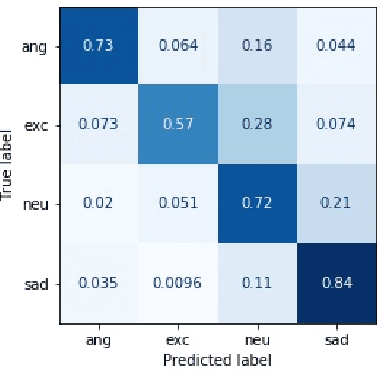

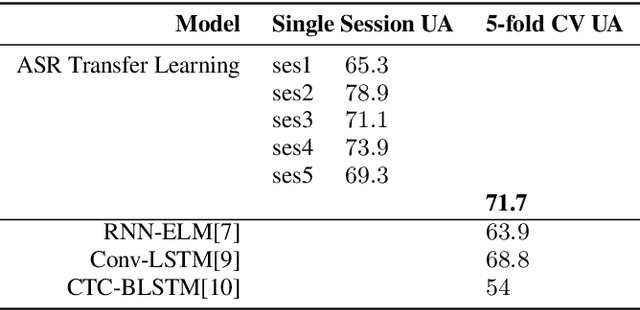
This paper presents a transfer learning method in speech emotion recognition based on a Time-Delay Neural Network (TDNN) architecture. A major challenge in the current speech-based emotion detection research is data scarcity. The proposed method resolves this problem by applying transfer learning techniques in order to leverage data from the automatic speech recognition (ASR) task for which ample data is available. Our experiments also show the advantage of speaker-class adaptation modeling techniques by adopting identity-vector (i-vector) based features in addition to standard Mel-Frequency Cepstral Coefficient (MFCC) features.[1] We show the transfer learning models significantly outperform the other methods without pretraining on ASR. The experiments performed on the publicly available IEMOCAP dataset which provides 12 hours of motional speech data. The transfer learning was initialized by using the Ted-Lium v.2 speech dataset providing 207 hours of audio with the corresponding transcripts. We achieve the highest significantly higher accuracy when compared to state-of-the-art, using five-fold cross validation. Using only speech, we obtain an accuracy 71.7% for anger, excitement, sadness, and neutrality emotion content.
Out-of-Core GPU Gradient Boosting
May 19, 2020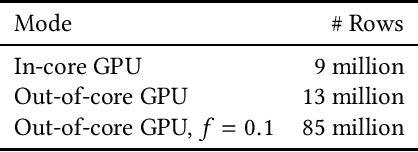
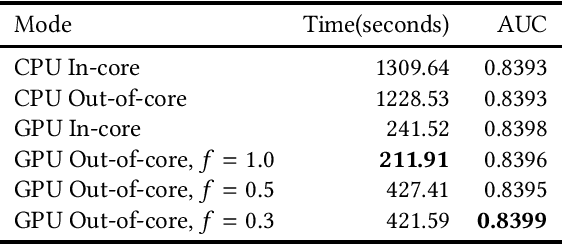
GPU-based algorithms have greatly accelerated many machine learning methods; however, GPU memory is typically smaller than main memory, limiting the size of training data. In this paper, we describe an out-of-core GPU gradient boosting algorithm implemented in the XGBoost library. We show that much larger datasets can fit on a given GPU, without degrading model accuracy or training time. To the best of our knowledge, this is the first out-of-core GPU implementation of gradient boosting. Similar approaches can be applied to other machine learning algorithms
Bach or Mock? A Grading Function for Chorales in the Style of J.S. Bach
Jun 23, 2020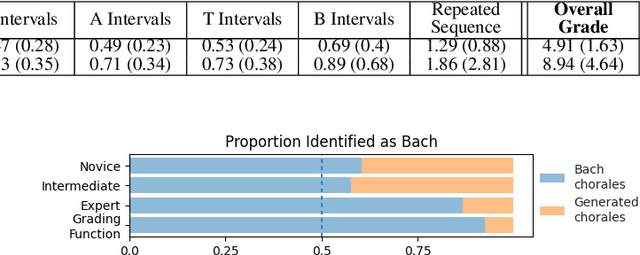

Deep generative systems that learn probabilistic models from a corpus of existing music do not explicitly encode knowledge of a musical style, compared to traditional rule-based systems. Thus, it can be difficult to determine whether deep models generate stylistically correct output without expert evaluation, but this is expensive and time-consuming. Therefore, there is a need for automatic, interpretable, and musically-motivated evaluation measures of generated music. In this paper, we introduce a grading function that evaluates four-part chorales in the style of J.S. Bach along important musical features. We use the grading function to evaluate the output of a Transformer model, and show that the function is both interpretable and outperforms human experts at discriminating Bach chorales from model-generated ones.
A Novel Indoor Positioning System for unprepared firefighting scenarios
Aug 04, 2020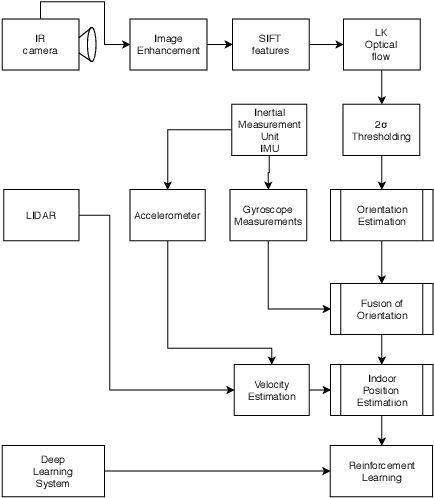
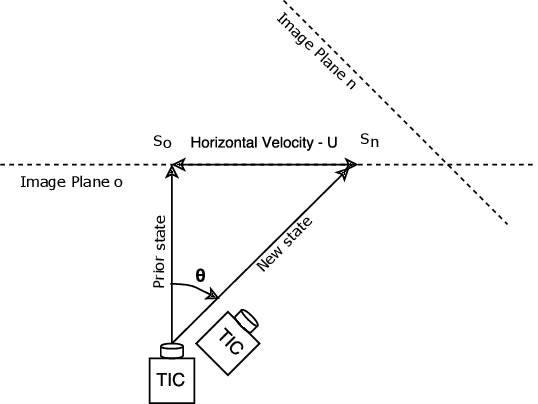

Situational awareness and Indoor location tracking for firefighters is one of the tasks with paramount importance in search and rescue operations. For Indoor Positioning systems (IPS), GPS is not the best possible solution. There are few other techniques like dead reckoning, Wifi and bluetooth based triangulation, Structure from Motion (SFM) based scene reconstruction for Indoor positioning system. However due to high temperatures, the rapidly changing environment of fires, and low parallax in the thermal images, these techniques are not suitable for relaying the necessary information in a fire fighting environment needed to increase situational awareness in real time. In fire fighting environments, thermal imaging cameras are used due to smoke and low visibility hence obtaining relative orientation from the vanishing point estimation is very difficult. The following technique that is the content of this research implements a novel optical flow based video compass for orientation estimation and fused IMU data based activity recognition for IPS. This technique helps first responders to go into unprepared, unknown environments and still maintain situational awareness like the orientation and, position of the victim fire fighters.
Dynamic Task Allocation for Robotic Network Cloud Systems
Jul 22, 2020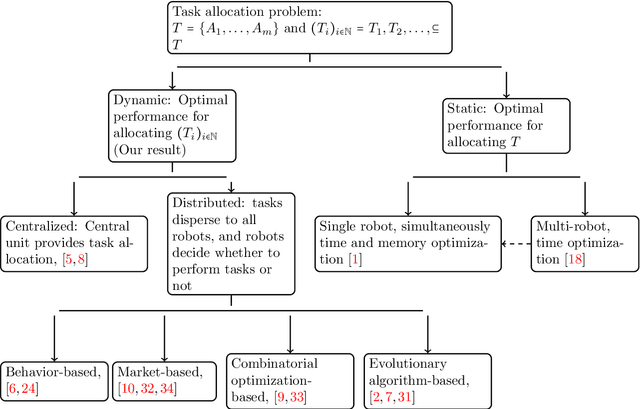

Every robotic network cloud system can be seen as a graph with nodes as hardware with independent computational processing powers and edges as data transmissions between nodes. When assigning a task to a node we may change several values corresponding to the node such as distance to other nodes, the time to complete all of its tasks, the energy level of the node, energy consumed while performing all of its tasks, geometrical position, communication with other nodes, and so on. These values can be seen as fingerprints for the current state of the node which can be evaluated as a subspace of a hyperspace. We proposed a theoretical model describing how assigning tasks to a node will change the subspace of the hyperspace, and from that, we show how to obtain the optimal task allocation. We described the communication instability between nodes and the capability of nodes as subspaces of a hyperspace. We translate task scheduling to nodes as finding the maximum volume of the hyperspace.
An Improved Historical Embedding without Alignment
Oct 19, 2019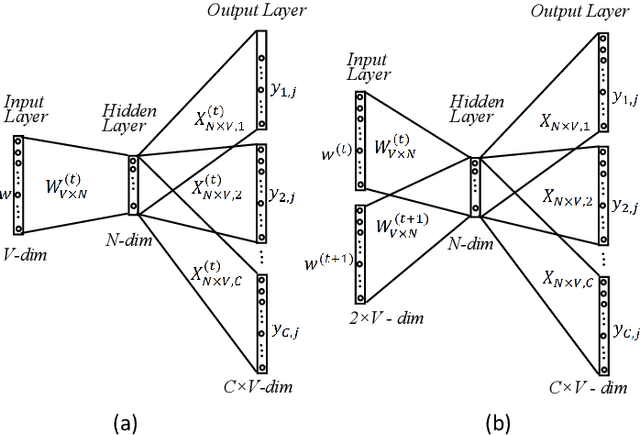
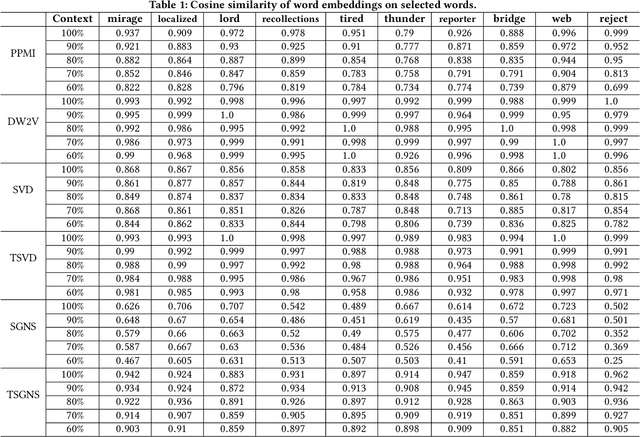
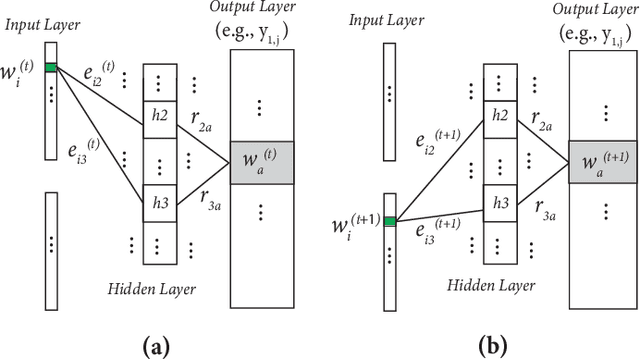
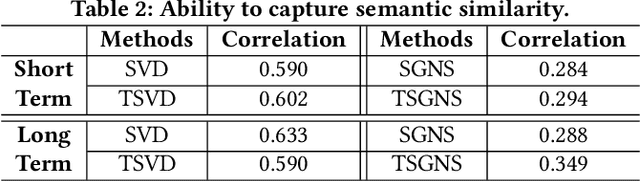
Many words have evolved in meaning as a result of cultural and social change. Understanding such changes is crucial for modelling language and cultural evolution. Low-dimensional embedding methods have shown promise in detecting words' meaning change by encoding them into dense vectors. However, when exploring semantic change of words over time, these methods require the alignment of word embeddings across different time periods. This process is computationally expensive, prohibitively time consuming and suffering from contextual variability. In this paper, we propose a new and scalable method for encoding words from different time periods into one dense vector space. This can greatly improve performance when it comes to identifying words that have changed in meaning over time. We evaluated our method on dataset from Google Books N-gram. Our method outperformed three other popular methods in terms of the number of words correctly identified to have changed in meaning. Additionally, we provide an intuitive visualization of the semantic evolution of some words extracted by our method
Endo-Sim2Real: Consistency learning-based domain adaptation for instrument segmentation
Jul 22, 2020

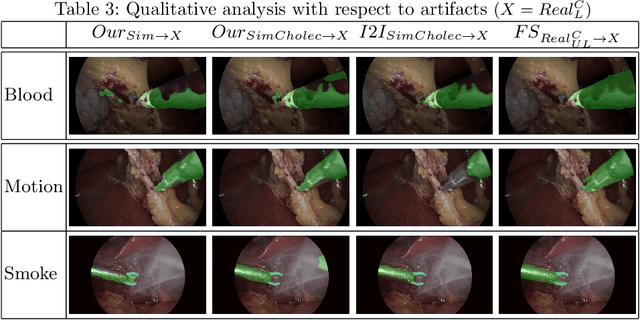

Surgical tool segmentation in endoscopic videos is an important component of computer assisted interventions systems. Recent success of image-based solutions using fully-supervised deep learning approaches can be attributed to the collection of big labeled datasets. However, the annotation of a big dataset of real videos can be prohibitively expensive and time consuming. Computer simulations could alleviate the manual labeling problem, however, models trained on simulated data do not generalize to real data. This work proposes a consistency-based framework for joint learning of simulated and real (unlabeled) endoscopic data to bridge this performance generalization issue. Empirical results on two data sets (15 videos of the Cholec80 and EndoVis'15 dataset) highlight the effectiveness of the proposed \emph{Endo-Sim2Real} method for instrument segmentation. We compare the segmentation of the proposed approach with state-of-the-art solutions and show that our method improves segmentation both in terms of quality and quantity.
Resource-Efficient Speech Mask Estimation for Multi-Channel Speech Enhancement
Jul 22, 2020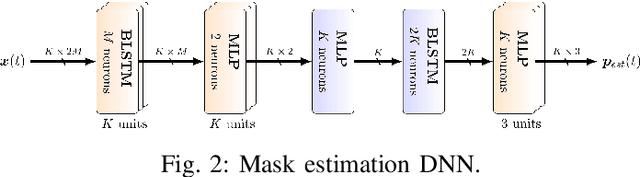
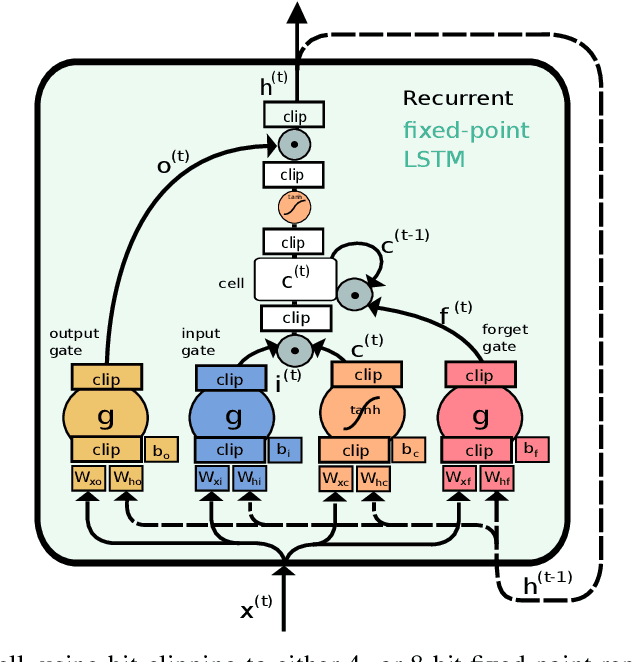
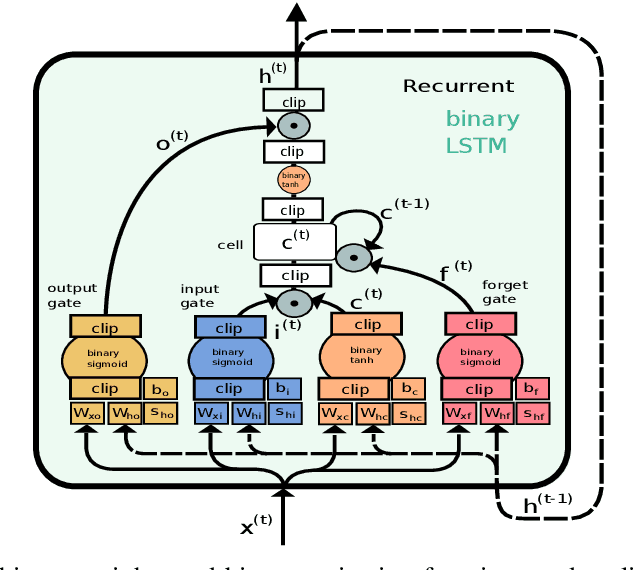
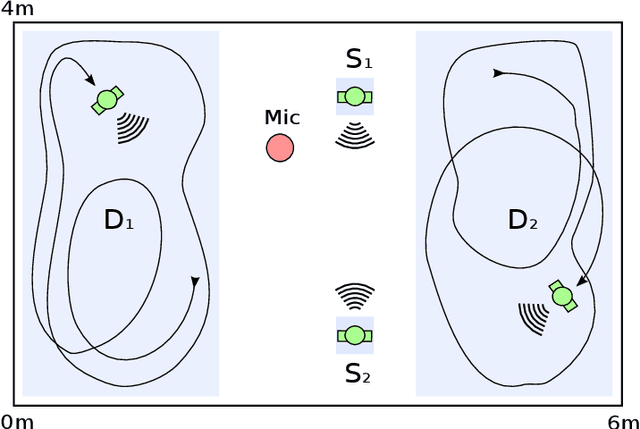
While machine learning techniques are traditionally resource intensive, we are currently witnessing an increased interest in hardware and energy efficient approaches. This need for resource-efficient machine learning is primarily driven by the demand for embedded systems and their usage in ubiquitous computing and IoT applications. In this article, we provide a resource-efficient approach for multi-channel speech enhancement based on Deep Neural Networks (DNNs). In particular, we use reduced-precision DNNs for estimating a speech mask from noisy, multi-channel microphone observations. This speech mask is used to obtain either the Minimum Variance Distortionless Response (MVDR) or Generalized Eigenvalue (GEV) beamformer. In the extreme case of binary weights and reduced precision activations, a significant reduction of execution time and memory footprint is possible while still obtaining an audio quality almost on par to single-precision DNNs and a slightly larger Word Error Rate (WER) for single speaker scenarios using the WSJ0 speech corpus.