 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving End-to-End Speech-to-Intent Classification with Reptile
Aug 05, 2020
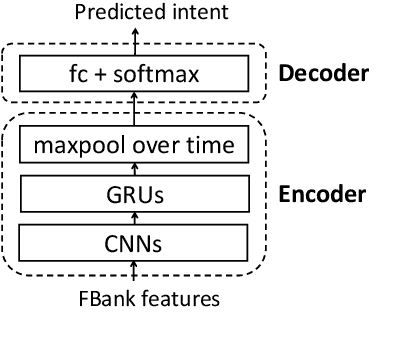
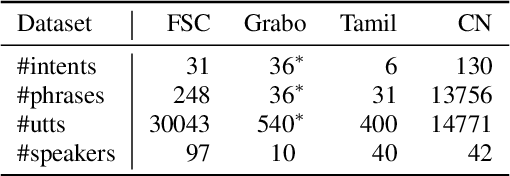
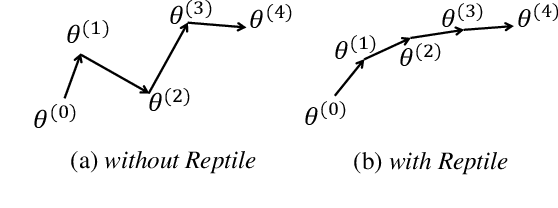
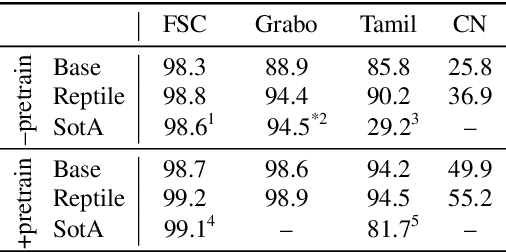
End-to-end spoken language understanding (SLU) systems have many advantages over conventional pipeline systems, but collecting in-domain speech data to train an end-to-end system is costly and time consuming. One question arises from this: how to train an end-to-end SLU with limited amounts of data? Many researchers have explored approaches that make use of other related data resources, typically by pre-training parts of the model on high-resource speech recognition. In this paper, we suggest improving the generalization performance of SLU models with a non-standard learning algorithm, Reptile. Though Reptile was originally proposed for model-agnostic meta learning, we argue that it can also be used to directly learn a target task and result in better generalization than conventional gradient descent. In this work, we employ Reptile to the task of end-to-end spoken intent classification. Experiments on four datasets of different languages and domains show improvement of intent prediction accuracy, both when Reptile is used alone and used in addition to pre-training.
Subclass Contrastive Loss for Injured Face Recognition
Aug 05, 2020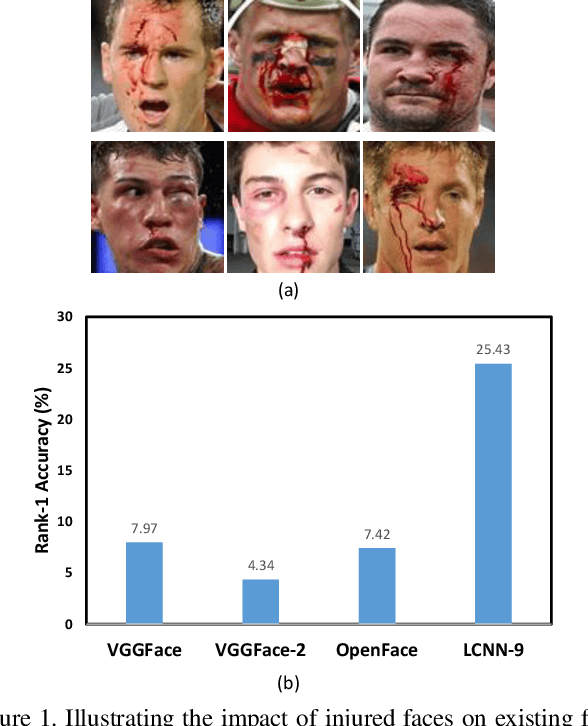
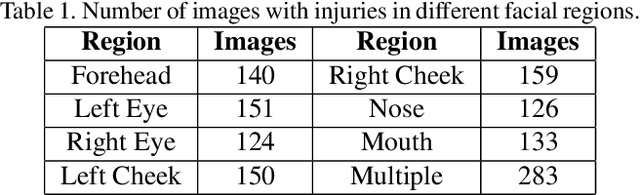
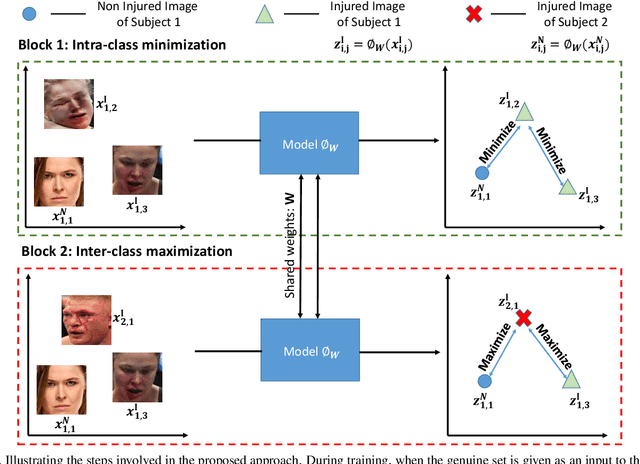
Deaths and injuries are common in road accidents, violence, and natural disaster. In such cases, one of the main tasks of responders is to retrieve the identity of the victims to reunite families and ensure proper identification of deceased/ injured individuals. Apart from this, identification of unidentified dead bodies due to violence and accidents is crucial for the police investigation. In the absence of identification cards, current practices for this task include DNA profiling and dental profiling. Face is one of the most commonly used and widely accepted biometric modalities for recognition. However, face recognition is challenging in the presence of facial injuries such as swelling, bruises, blood clots, laceration, and avulsion which affect the features used in recognition. In this paper, for the first time, we address the problem of injured face recognition and propose a novel Subclass Contrastive Loss (SCL) for this task. A novel database, termed as Injured Face (IF) database, is also created to instigate research in this direction. Experimental analysis shows that the proposed loss function surpasses existing algorithm for injured face recognition.
Solving Mixed Model Workplace Time-dependent Assembly Line Balancing Problem with FSS Algorithm
Jul 19, 2017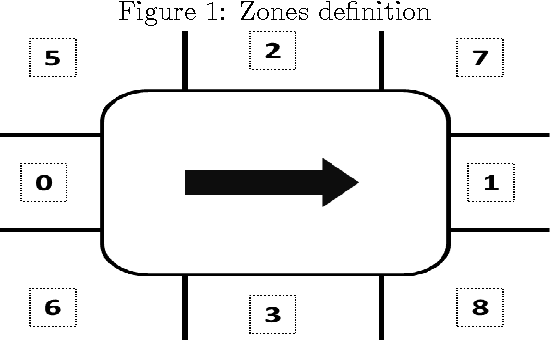
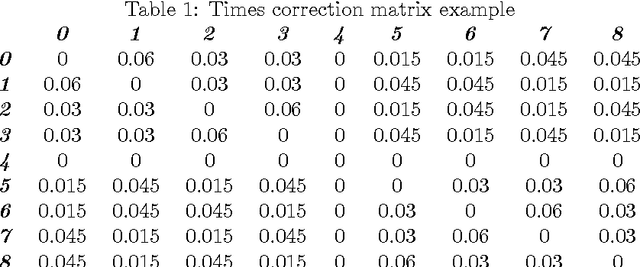
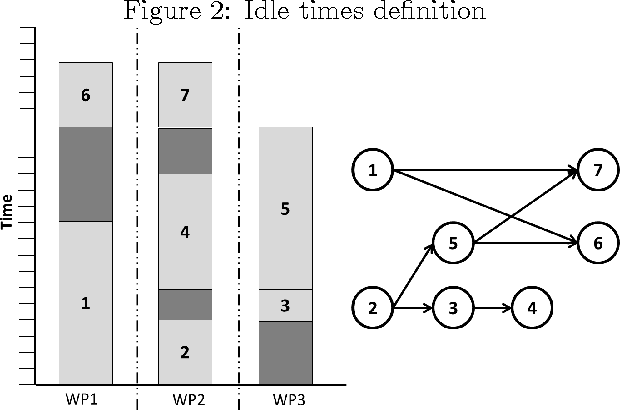

Balancing assembly lines, a family of optimization problems commonly known as Assembly Line Balancing Problem, is notoriously NP-Hard. They comprise a set of problems of enormous practical interest to manufacturing industry due to the relevant frequency of this type of production paradigm. For this reason, many researchers on Computational Intelligence and Industrial Engineering have been conceiving algorithms for tackling different versions of assembly line balancing problems utilizing different methodologies. In this article, it was proposed a problem version referred as Mixed Model Workplace Time-dependent Assembly Line Balancing Problem with the intention of including pressing issues of real assembly lines in the optimization problem, to which four versions were conceived. Heuristic search procedures were used, namely two Swarm Intelligence algorithms from the Fish School Search family: the original version, named "vanilla", and a special variation including a stagnation avoidance routine. Either approaches solved the newly posed problem achieving good results when compared to Particle Swarm Optimization algorithm.
A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19
Sep 05, 2020
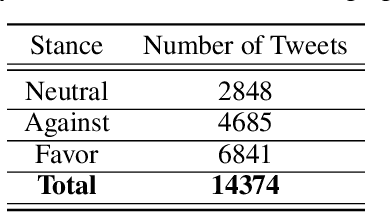

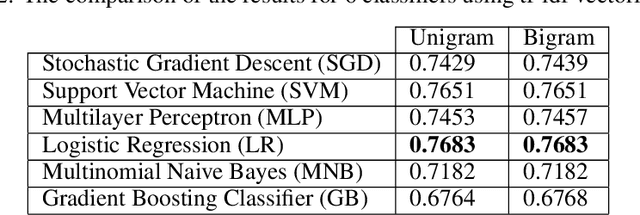
At the time of this study, the SARS-CoV-2 virus that caused the COVID-19 pandemic has spread significantly across the world. Considering the uncertainty about policies, health risks, financial difficulties, etc. the online media, specially the Twitter platform, is experiencing a high volume of activity related to this pandemic. Among the hot topics, the polarized debates about unconfirmed medicines for the treatment and prevention of the disease have attracted significant attention from online media users. In this work, we present a stance data set, COVID-CQ, of user-generated content on Twitter in the context of COVID-19. We investigated more than 14 thousand tweets and manually annotated the opinions of the tweet initiators regarding the use of "chloroquine" and "hydroxychloroquine" for the treatment or prevention of COVID-19. To the best of our knowledge, COVID-CQ is the first data set of Twitter users' stances in the context of the COVID-19 pandemic, and the largest Twitter data set on users' stances towards a claim, in any domain. We have made this data set available to the research community via GitHub. We expect this data set to be useful for many research purposes, including stance detection, evolution and dynamics of opinions regarding this outbreak, and changes in opinions in response to the exogenous shocks such as policy decisions and events.
The Trade-Offs of Private Prediction
Jul 09, 2020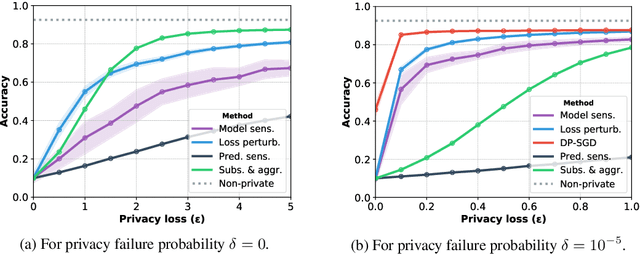
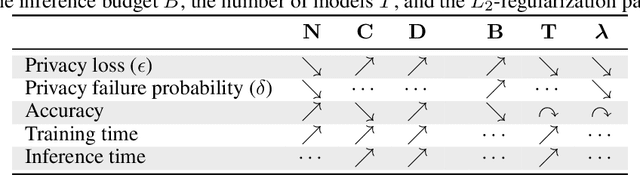
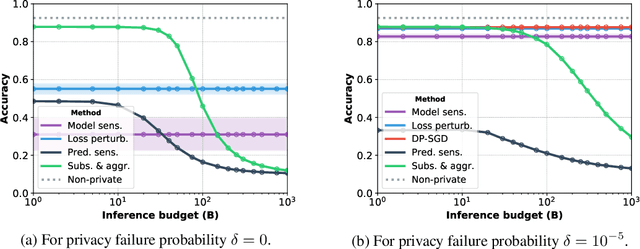
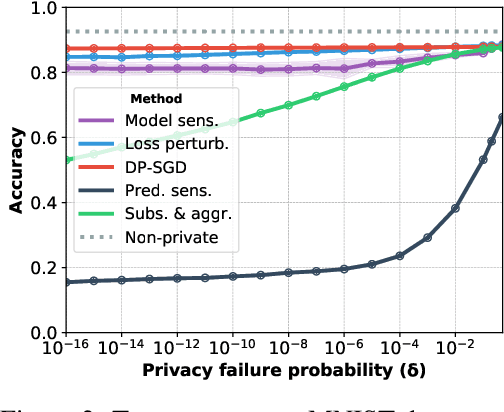
Machine learning models leak information about their training data every time they reveal a prediction. This is problematic when the training data needs to remain private. Private prediction methods limit how much information about the training data is leaked by each prediction. Private prediction can also be achieved using models that are trained by private training methods. In private prediction, both private training and private prediction methods exhibit trade-offs between privacy, privacy failure probability, amount of training data, and inference budget. Although these trade-offs are theoretically well-understood, they have hardly been studied empirically. This paper presents the first empirical study into the trade-offs of private prediction. Our study sheds light on which methods are best suited for which learning setting. Perhaps surprisingly, we find private training methods outperform private prediction methods in a wide range of private prediction settings.
Automatic Speech Summarisation: A Scoping Review
Aug 27, 2020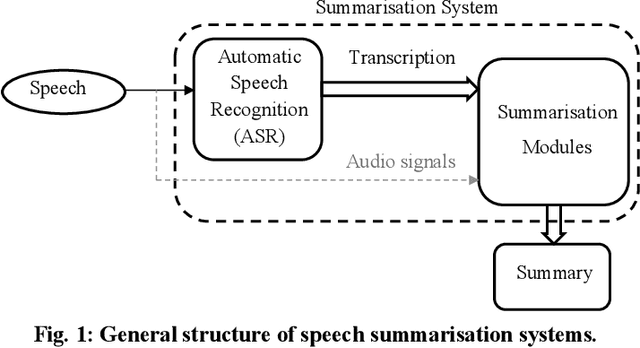
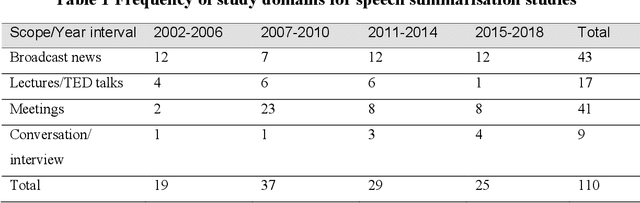
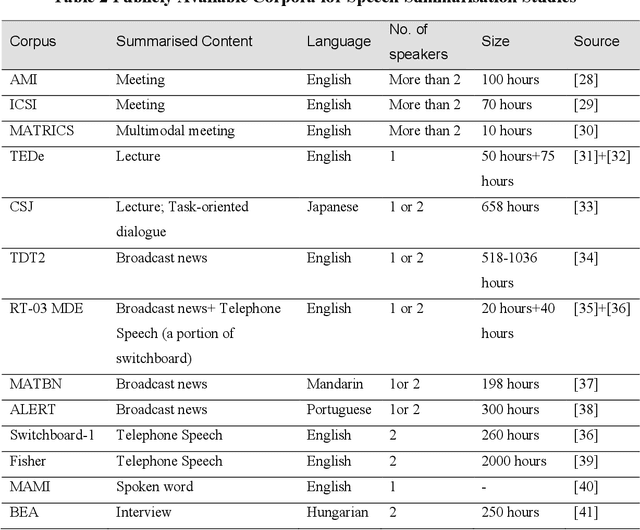
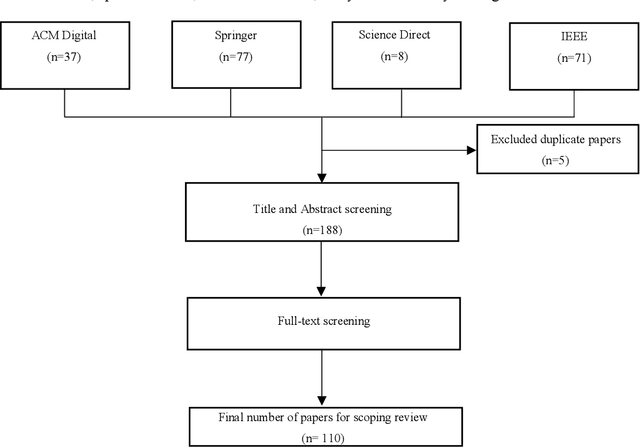
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
COALESCE: Component Assembly by Learning to Synthesize Connections
Aug 05, 2020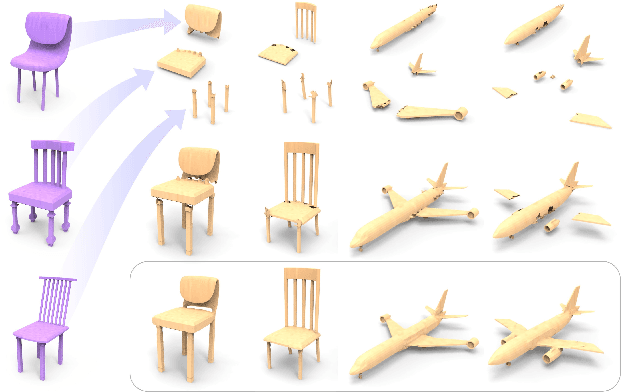
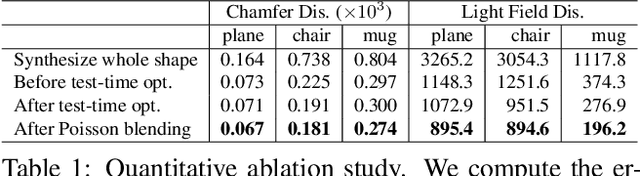
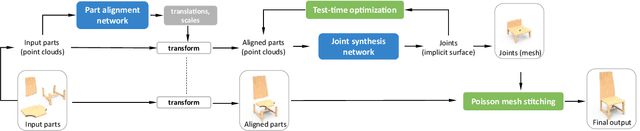
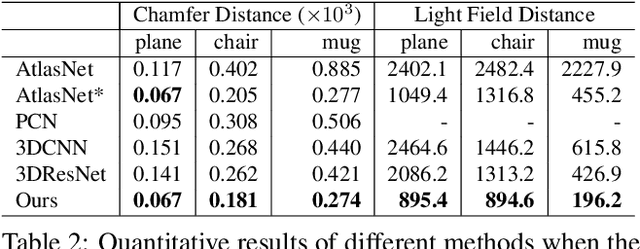
We introduce COALESCE, the first data-driven framework for component-based shape assembly which employs deep learning to synthesize part connections. To handle geometric and topological mismatches between parts, we remove the mismatched portions via erosion, and rely on a joint synthesis step, which is learned from data, to fill the gap and arrive at a natural and plausible part joint. Given a set of input parts extracted from different objects, COALESCE automatically aligns them and synthesizes plausible joints to connect the parts into a coherent 3D object represented by a mesh. The joint synthesis network, designed to focus on joint regions, reconstructs the surface between the parts by predicting an implicit shape representation that agrees with existing parts, while generating a smooth and topologically meaningful connection. We employ test-time optimization to further ensure that the synthesized joint region closely aligns with the input parts to create realistic component assemblies from diverse input parts. We demonstrate that our method significantly outperforms prior approaches including baseline deep models for 3D shape synthesis, as well as state-of-the-art methods for shape completion.
Human-centered collaborative robots with deep reinforcement learning
Jul 02, 2020

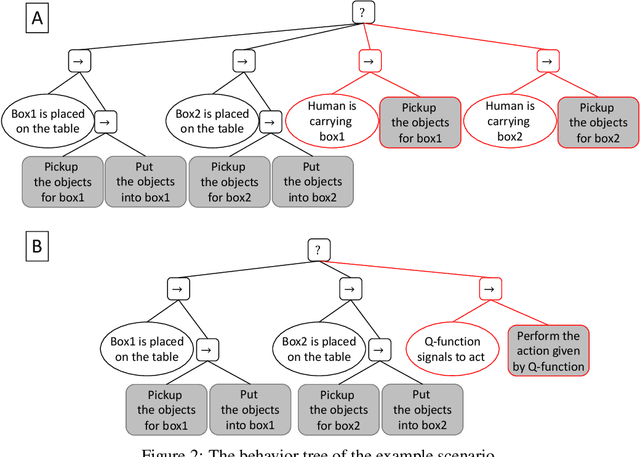
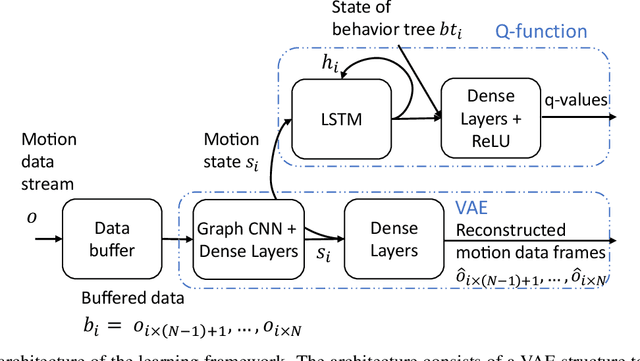
We present a reinforcement learning based framework for human-centered collaborative systems. The framework is proactive and balances the benefits of timely actions with the risk of taking improper actions by minimizing the total time spent to complete the task. The framework is learned end-to-end in an unsupervised fashion addressing the perception uncertainties and decision making in an integrated manner. The framework is shown to provide more fluent coordination between human and robot partners on an example task of packaging compared to alternatives for which perception and decision-making systems are learned independently, using supervised learning. The foremost benefit of the proposed approach is that it allows for fast adaptation to new human partners and tasks since tedious annotation of motion data is avoided and the learning is performed on-line.
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020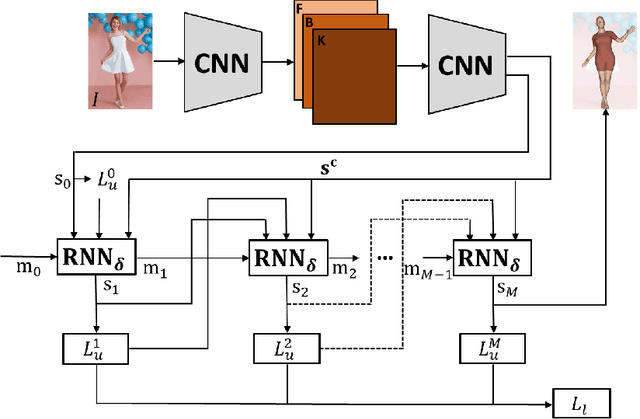
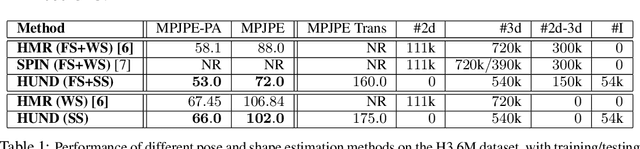

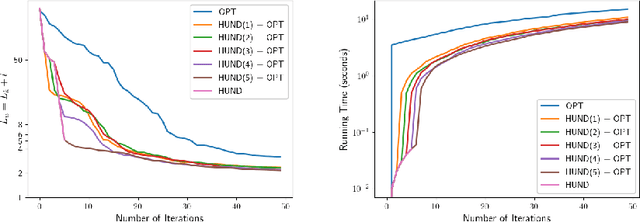
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
An Overview on the Landscape of R Packages for Credit Scoring
Jul 02, 2020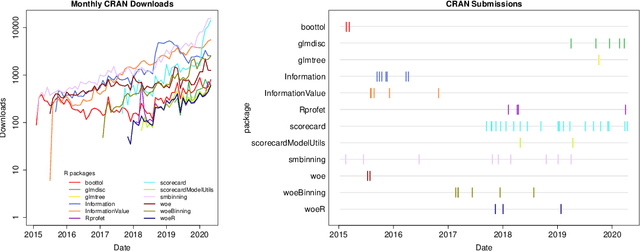
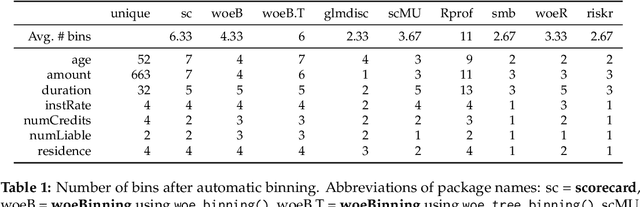
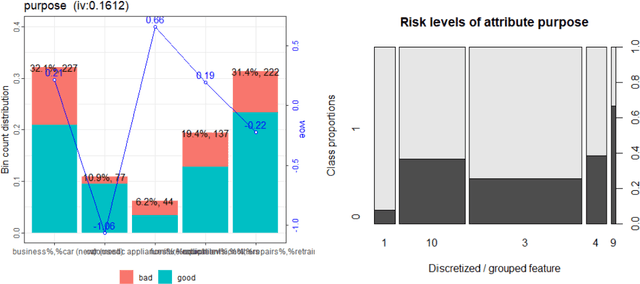
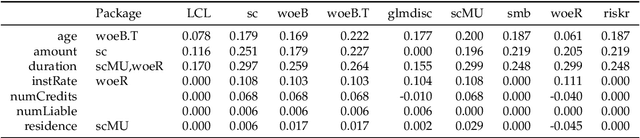
The credit scoring industry has a long tradition of using statistical tools for loan default probability prediction and domain specific standards have been established long before the hype of machine learning. Although several commercial software companies offer specific solutions for credit scorecard modelling in R explicit packages for this purpose have been missing long time. In the recent years this has changed and several packages have been developed which are dedicated to credit scoring. The aim of this paper is to give a structured overview on these packages. This may guide users to select the appropriate functions for a desired purpose and further hopefully will contribute to directing future development activities. The paper is guided by the chain of subsequent modelling steps as they are forming the typical scorecard development process.