 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Obtaining Adjustable Regularization for Free via Iterate Averaging
Aug 15, 2020
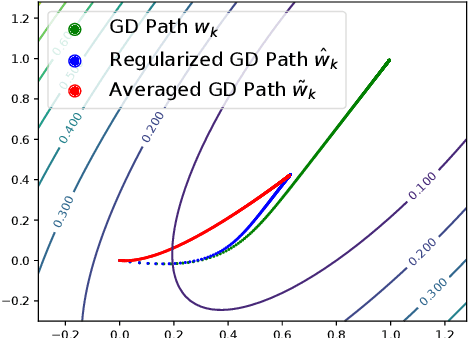
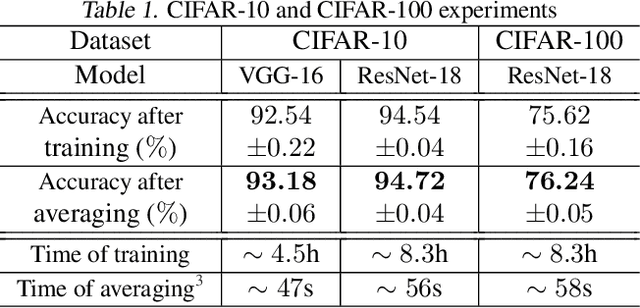

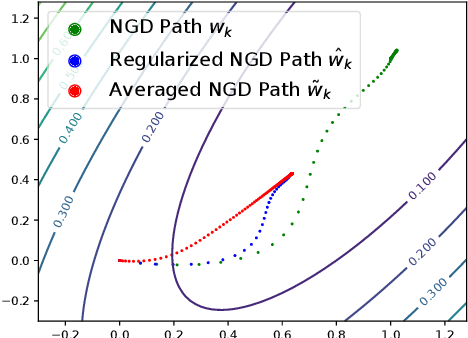
Regularization for optimization is a crucial technique to avoid overfitting in machine learning. In order to obtain the best performance, we usually train a model by tuning the regularization parameters. It becomes costly, however, when a single round of training takes significant amount of time. Very recently, Neu and Rosasco show that if we run stochastic gradient descent (SGD) on linear regression problems, then by averaging the SGD iterates properly, we obtain a regularized solution. It left open whether the same phenomenon can be achieved for other optimization problems and algorithms. In this paper, we establish an averaging scheme that provably converts the iterates of SGD on an arbitrary strongly convex and smooth objective function to its regularized counterpart with an adjustable regularization parameter. Our approaches can be used for accelerated and preconditioned optimization methods as well. We further show that the same methods work empirically on more general optimization objectives including neural networks. In sum, we obtain adjustable regularization for free for a large class of optimization problems and resolve an open question raised by Neu and Rosasco.
Wavelet Networks: Scale Equivariant Learning From Raw Waveforms
Jun 09, 2020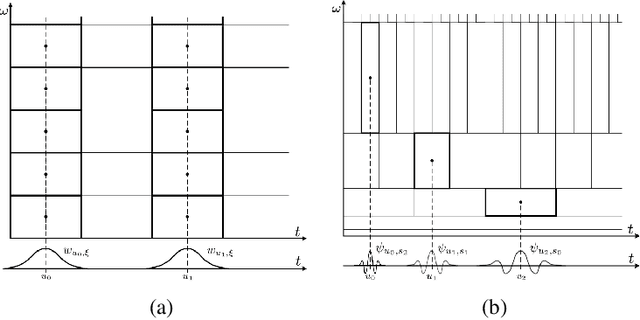
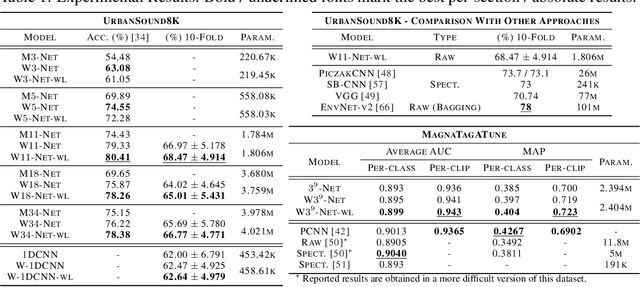
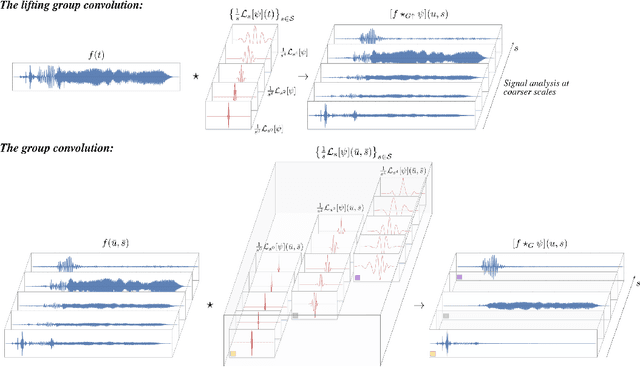
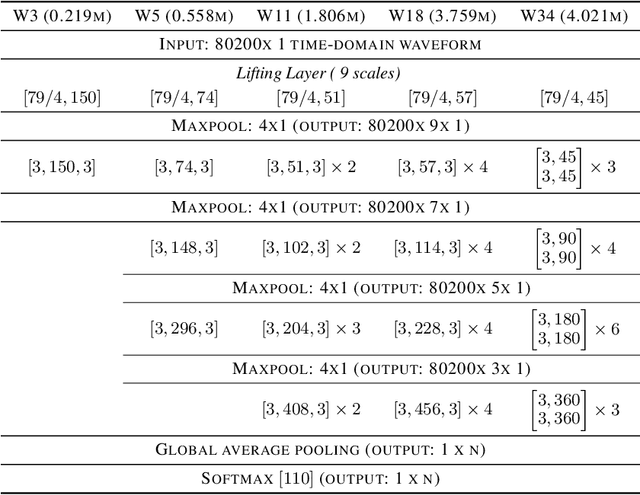
Inducing symmetry equivariance in deep neural architectures has resolved into improved data efficiency and generalization. In this work, we utilize the concept of scale and translation equivariance to tackle the problem of learning on time-series from raw waveforms. As a result, we obtain representations that largely resemble those of the wavelet transform at the first layer, but that evolve into much more descriptive ones as a function of depth. Our empirical results support the suitability of our Wavelet Networks which with a simple architecture design perform consistently better than CNNs on raw waveforms and on par with spectrogram-based methods.
Hard Negative Mixing for Contrastive Learning
Oct 02, 2020



Contrastive learning has become a key component of self-supervised learning approaches for computer vision. By learning to embed two augmented versions of the same image close to each other and to push the embeddings of different images apart, one can train highly transferable visual representations. As revealed by recent studies, heavy data augmentation and large sets of negatives are both crucial in learning such representations. At the same time, data mixing strategies either at the image or the feature level improve both supervised and semi-supervised learning by synthesizing novel examples, forcing networks to learn more robust features. In this paper, we argue that an important aspect of contrastive learning, i.e., the effect of hard negatives, has so far been neglected. To get more meaningful negative samples, current top contrastive self-supervised learning approaches either substantially increase the batch sizes, or keep very large memory banks; increasing the memory size, however, leads to diminishing returns in terms of performance. We therefore start by delving deeper into a top-performing framework and show evidence that harder negatives are needed to facilitate better and faster learning. Based on these observations, and motivated by the success of data mixing, we propose hard negative mixing strategies at the feature level, that can be computed on-the-fly with a minimal computational overhead. We exhaustively ablate our approach on linear classification, object detection and instance segmentation and show that employing our hard negative mixing procedure improves the quality of visual representations learned by a state-of-the-art self-supervised learning method.
Real-time marker-less multi-person 3D pose estimation in RGB-Depth camera networks
Oct 17, 2017
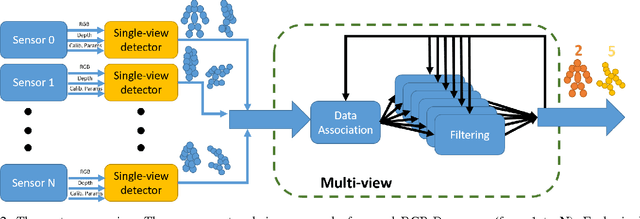
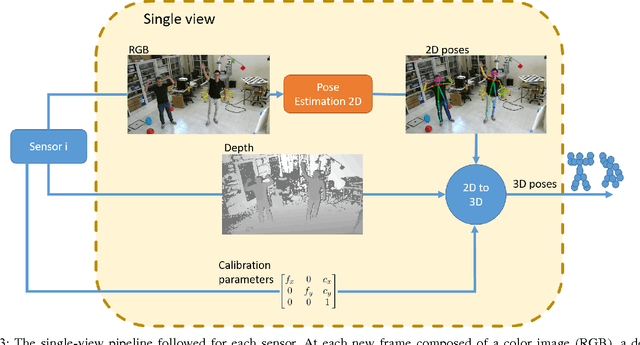
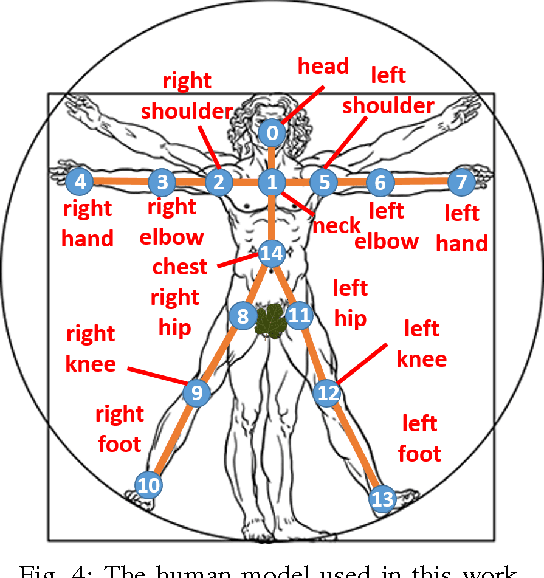
This paper proposes a novel system to estimate and track the 3D poses of multiple persons in calibrated RGB-Depth camera networks. The multi-view 3D pose of each person is computed by a central node which receives the single-view outcomes from each camera of the network. Each single-view outcome is computed by using a CNN for 2D pose estimation and extending the resulting skeletons to 3D by means of the sensor depth. The proposed system is marker-less, multi-person, independent of background and does not make any assumption on people appearance and initial pose. The system provides real-time outcomes, thus being perfectly suited for applications requiring user interaction. Experimental results show the effectiveness of this work with respect to a baseline multi-view approach in different scenarios. To foster research and applications based on this work, we released the source code in OpenPTrack, an open source project for RGB-D people tracking.
Graph Convolution Networks Using Message Passing and Multi-Source Similarity Features for Predicting circRNA-Disease Association
Sep 15, 2020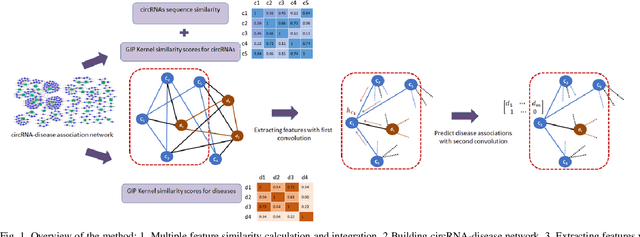
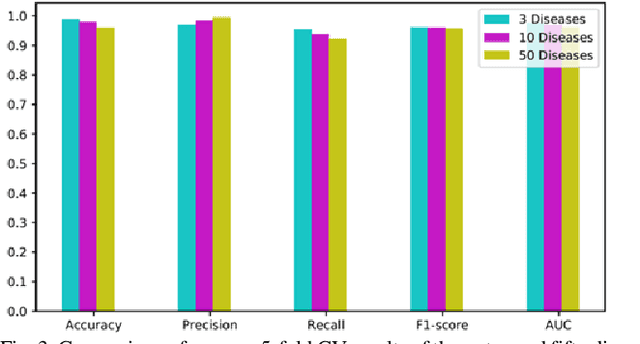
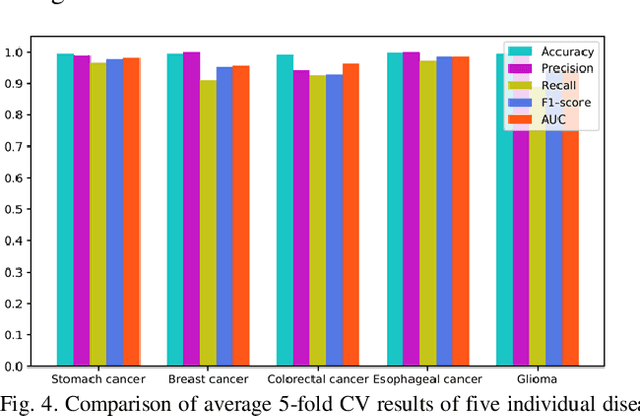
Graphs can be used to effectively represent complex data structures. Learning these irregular data in graphs is challenging and still suffers from shallow learning. Applying deep learning on graphs has recently showed good performance in many applications in social analysis, bioinformatics etc. A message passing graph convolution network is such a powerful method which has expressive power to learn graph structures. Meanwhile, circRNA is a type of non-coding RNA which plays a critical role in human diseases. Identifying the associations between circRNAs and diseases is important to diagnosis and treatment of complex diseases. However, there are limited number of known associations between them and conducting biological experiments to identify new associations is time consuming and expensive. As a result, there is a need of building efficient and feasible computation methods to predict potential circRNA-disease associations. In this paper, we propose a novel graph convolution network framework to learn features from a graph built with multi-source similarity information to predict circRNA-disease associations. First we use multi-source information of circRNA similarity, disease and circRNA Gaussian Interaction Profile (GIP) kernel similarity to extract the features using first graph convolution. Then we predict disease associations for each circRNA with second graph convolution. Proposed framework with five-fold cross validation on various experiments shows promising results in predicting circRNA-disease association and outperforms other existing methods.
Autonomous Braking and Throttle System: A Deep Reinforcement Learning Approach for Naturalistic Driving
Aug 15, 2020
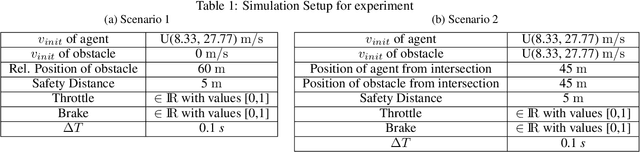
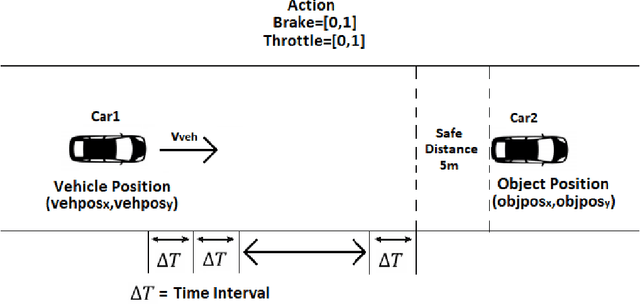
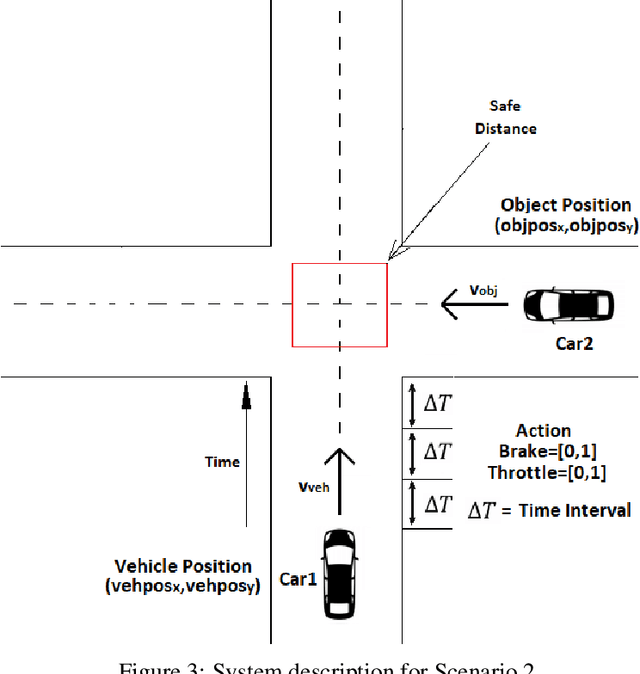
Autonomous Braking and Throttle control is key in developing safe driving systems for the future. There exists a need for autonomous vehicles to negotiate a multi-agent environment while ensuring safety and comfort. A Deep Reinforcement Learning based autonomous throttle and braking system is presented. For each time step, the proposed system makes a decision to apply the brake or throttle. The throttle and brake are modelled as continuous action space values. We demonstrate 2 scenarios where there is a need for a sophisticated braking and throttle system, i.e when there is a static obstacle in front of our agent like a car, stop sign. The second scenario consists of 2 vehicles approaching an intersection. The policies for brake and throttle control are learned through computer simulation using Deep deterministic policy gradients. The experiment shows that the system not only avoids a collision, but also it ensures that there is smooth change in the values of throttle/brake as it gets out of the emergency situation and abides by the speed regulations, i.e the system resembles human driving.
Differentiable model-based adaptive optics with transmitted and reflected light
Jul 27, 2020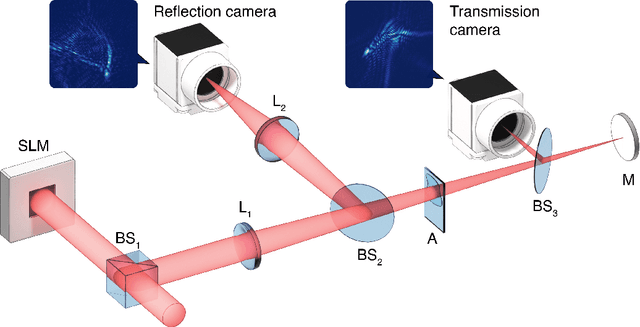
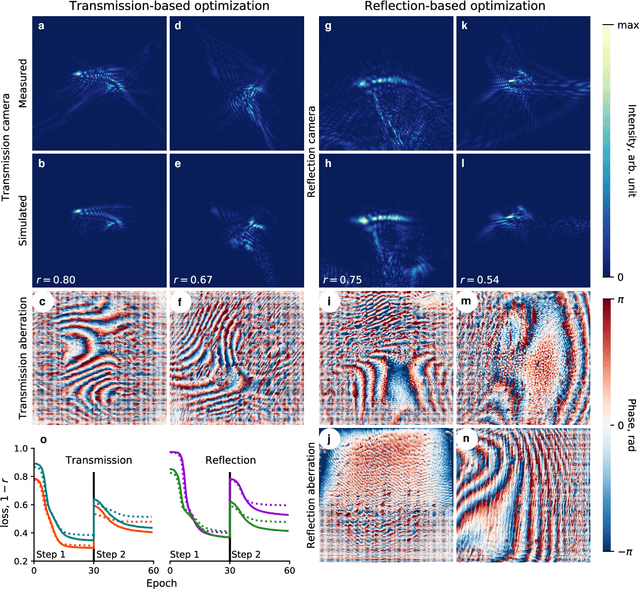
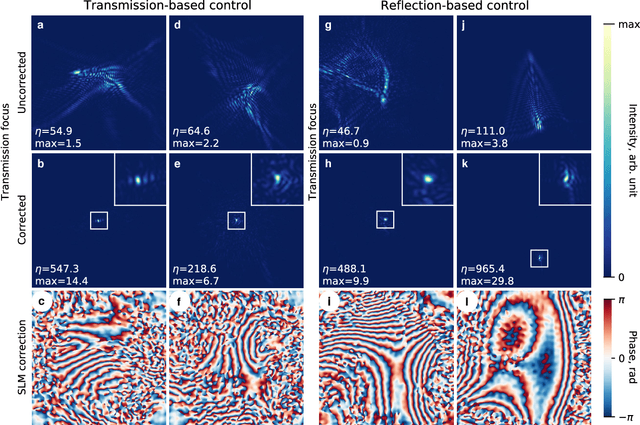
Aberrations limit optical systems in many situations, for example when imaging in biological tissue. Machine learning offers novel ways to improve imaging under such conditions by learning inverse models of aberrations. Learning requires datasets that cover a wide range of possible aberrations, which however becomes limiting for more strongly scattering samples, and does not take advantage of prior information about the imaging process. Here, we show that combining model-based adaptive optics with the optimization techniques of machine learning frameworks can find aberration corrections with a small number of measurements. Corrections are determined in a transmission configuration through a single aberrating layer and in a reflection configuration through two different layers at the same time. Additionally, corrections are not limited by a predetermined model of aberrations (such as combinations of Zernike modes). Focusing in transmission can be achieved based only on reflected light, compatible with an epidetection imaging configuration.
Predicting SLA Violations in Real Time using Online Machine Learning
Sep 04, 2015



Detecting faults and SLA violations in a timely manner is critical for telecom providers, in order to avoid loss in business, revenue and reputation. At the same time predicting SLA violations for user services in telecom environments is difficult, due to time-varying user demands and infrastructure load conditions. In this paper, we propose a service-agnostic online learning approach, whereby the behavior of the system is learned on the fly, in order to predict client-side SLA violations. The approach uses device-level metrics, which are collected in a streaming fashion on the server side. Our results show that the approach can produce highly accurate predictions (>90% classification accuracy and < 10% false alarm rate) in scenarios where SLA violations are predicted for a video-on-demand service under changing load patterns. The paper also highlight the limitations of traditional offline learning methods, which perform significantly worse in many of the considered scenarios.
A Robust Laser-Inertial Odometry and Mapping Method for Large-Scale Highway Environments
Sep 06, 2020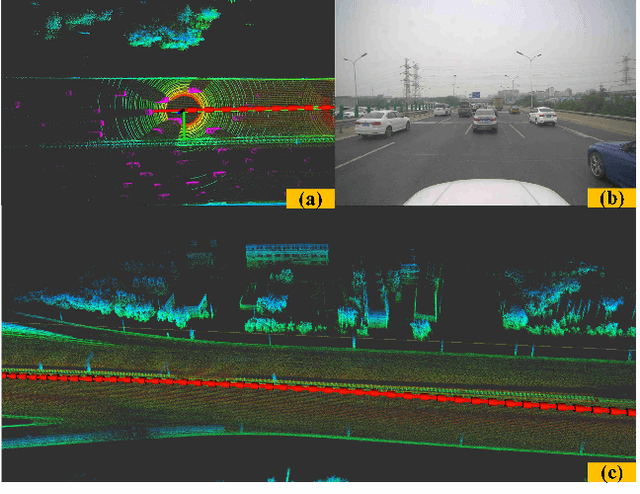
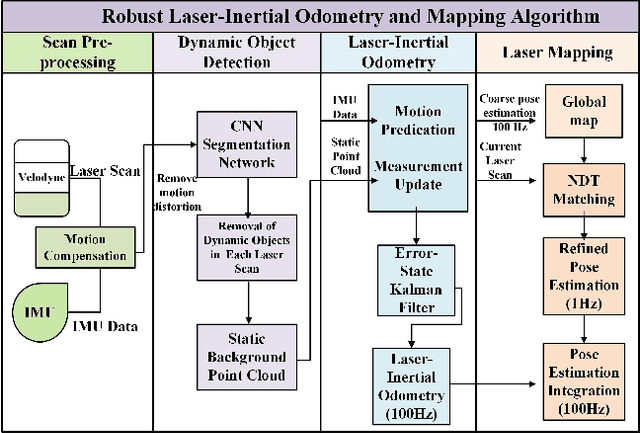
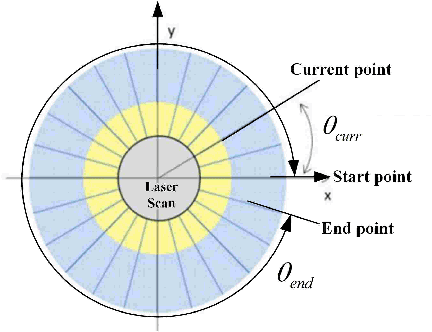

In this paper, we propose a novel laser-inertial odometry and mapping method to achieve real-time, low-drift and robust pose estimation in large-scale highway environments. The proposed method is mainly composed of four sequential modules, namely scan pre-processing module, dynamic object detection module, laser-inertial odometry module and laser mapping module. Scan pre-processing module uses inertial measurements to compensate the motion distortion of each laser scan. Then, the dynamic object detection module is used to detect and remove dynamic objects from each laser scan by applying CNN segmentation network. After obtaining the undistorted point cloud without moving objects, the laser inertial odometry module uses an Error State Kalman Filter to fuse the data of laser and IMU and output the coarse pose estimation at high frequency. Finally, the laser mapping module performs a fine processing step and the "Frame-to-Model" scan matching strategy is used to create a static global map. We compare the performance of our method with two state-ofthe-art methods, LOAM and SuMa, using KITTI dataset and real highway scene dataset. Experiment results show that our method performs better than the state-of-the-art methods in real highway environments and achieves competitive accuracy on the KITTI dataset.
How to tune the RBF SVM hyperparameters?: An empirical evaluation of 18 search algorithms
Aug 26, 2020

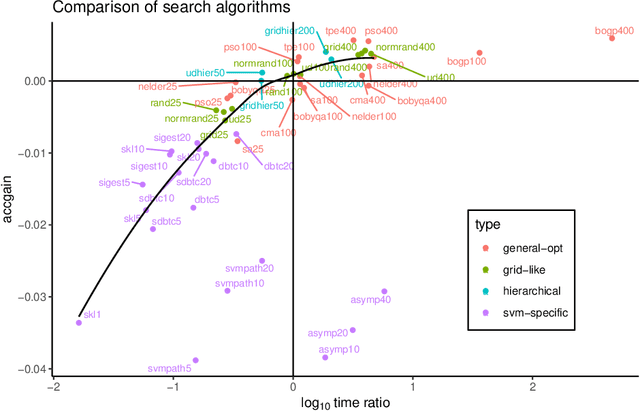
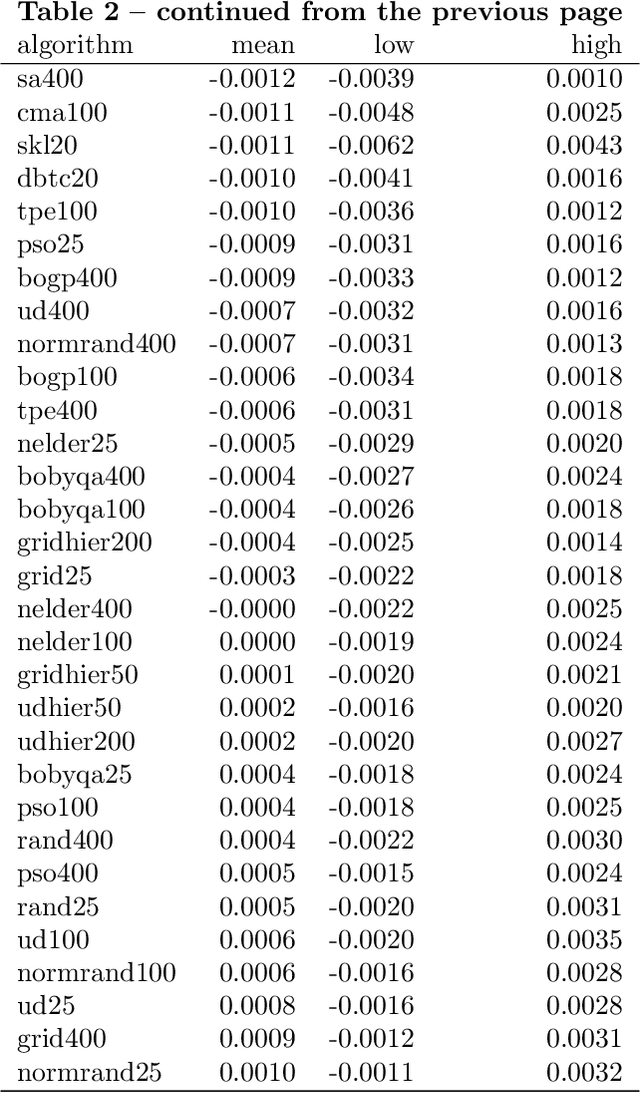
SVM with an RBF kernel is usually one of the best classification algorithms for most data sets, but it is important to tune the two hyperparameters $C$ and $\gamma$ to the data itself. In general, the selection of the hyperparameters is a non-convex optimization problem and thus many algorithms have been proposed to solve it, among them: grid search, random search, Bayesian optimization, simulated annealing, particle swarm optimization, Nelder Mead, and others. There have also been proposals to decouple the selection of $\gamma$ and $C$. We empirically compare 18 of these proposed search algorithms (with different parameterizations for a total of 47 combinations) on 115 real-life binary data sets. We find (among other things) that trees of Parzen estimators and particle swarm optimization select better hyperparameters with only a slight increase in computation time with respect to a grid search with the same number of evaluations. We also find that spending too much computational effort searching the hyperparameters will not likely result in better performance for future data and that there are no significant differences among the different procedures to select the best set of hyperparameters when more than one is found by the search algorithms.