 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating action plans for smart poultry houses
Aug 17, 2020
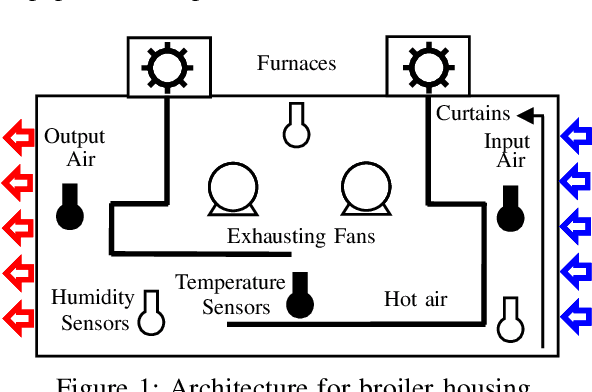
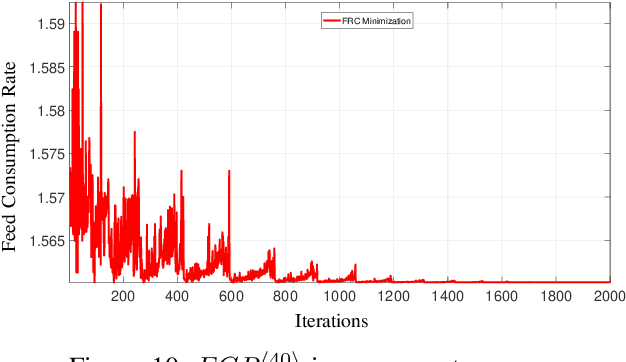
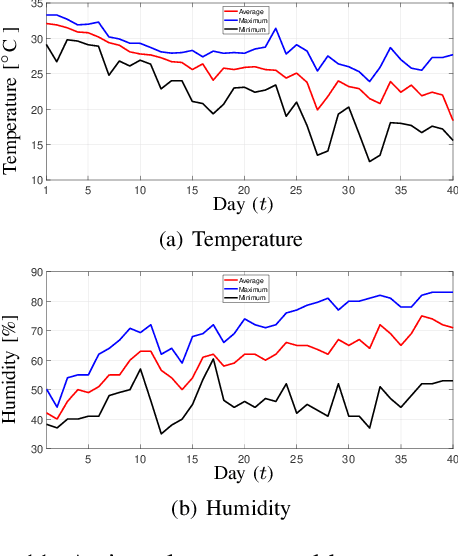
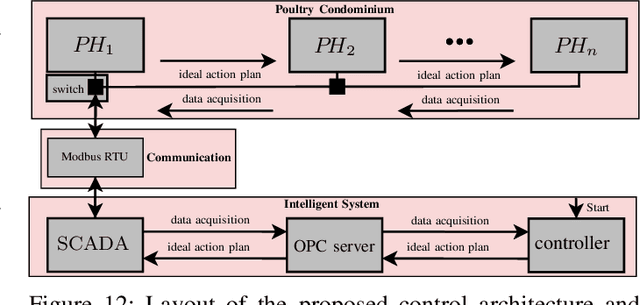
In poultry farming, the systematic choice, update, and implementation of periodic (t) action plans define the feed conversion rate (FCR[t]), which is an acceptable measure for successful production. Appropriate action plans provide tailored resources for broilers, allowing them to grow within the so-called thermal comfort zone, without wast or lack of resources. Although the implementation of an action plan is automatic, its configuration depends on the knowledge of the specialist, tending to be inefficient and error-prone, besides to result in different FCR[t] for each poultry house. In this article, we claim that the specialist's perception can be reproduced, to some extent, by computational intelligence. By combining deep learning and genetic algorithm techniques, we show how action plans can adapt their performance over the time, based on previous well succeeded plans. We also implement a distributed network infrastructure that allows to replicate our method over distributed poultry houses, for their smart, interconnected, and adaptive control. A supervision system is provided as interface to users. Experiments conducted over real data show that our method improves 5% on the performance of the most productive specialist, staying very close to the optimal FCR[t].
Bio-inspired Optimization: metaheuristic algorithms for optimization
Feb 24, 2020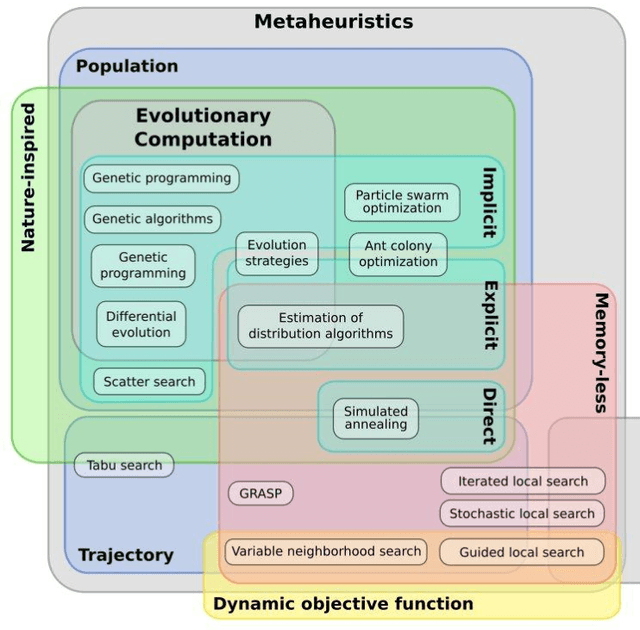
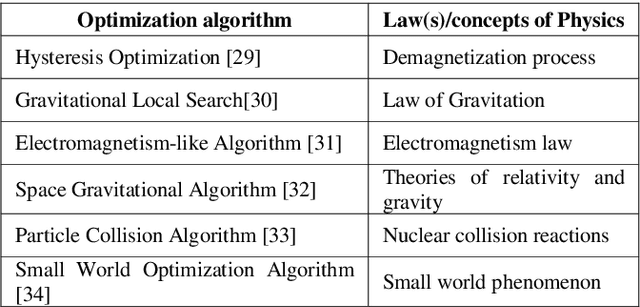
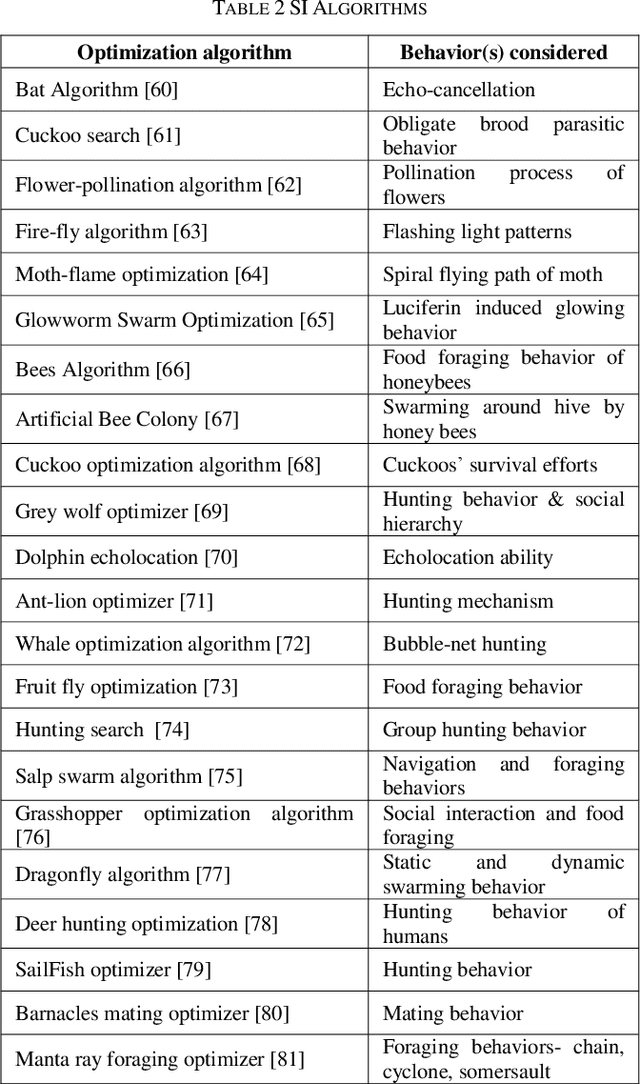
In today's day and time solving real-world complex problems has become fundamentally vital and critical task. Many of these are combinatorial problems, where optimal solutions are sought rather than exact solutions. Traditional optimization methods are found to be effective for small scale problems. However, for real-world large scale problems, traditional methods either do not scale up or fail to obtain optimal solutions or they end-up giving solutions after a long running time. Even earlier artificial intelligence based techniques used to solve these problems could not give acceptable results. However, last two decades have seen many new methods in AI based on the characteristics and behaviors of the living organisms in the nature which are categorized as bio-inspired or nature inspired optimization algorithms. These methods, are also termed meta-heuristic optimization methods, have been proved theoretically and implemented using simulation as well used to create many useful applications. They have been used extensively to solve many industrial and engineering complex problems due to being easy to understand, flexible, simple to adapt to the problem at hand and most importantly their ability to come out of local optima traps. This local optima avoidance property helps in finding global optimal solutions. This paper is aimed at understanding how nature has inspired many optimization algorithms, basic categorization of them, major bio-inspired optimization algorithms invented in recent time with their applications.
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Jul 24, 2020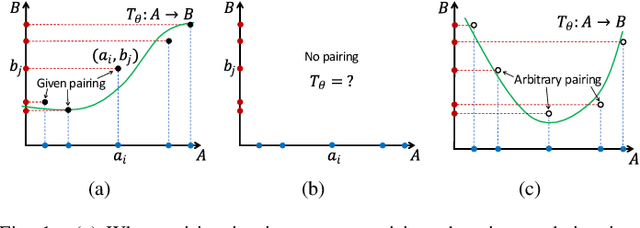



Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but we show that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. In this paper we introduce linear encoder-decoder architectures for unsupervised image to image translation. We show that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, we show a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.
ReLeaSER: A Reinforcement Learning Strategy for Optimizing Utilization Of Ephemeral Cloud Resources
Sep 23, 2020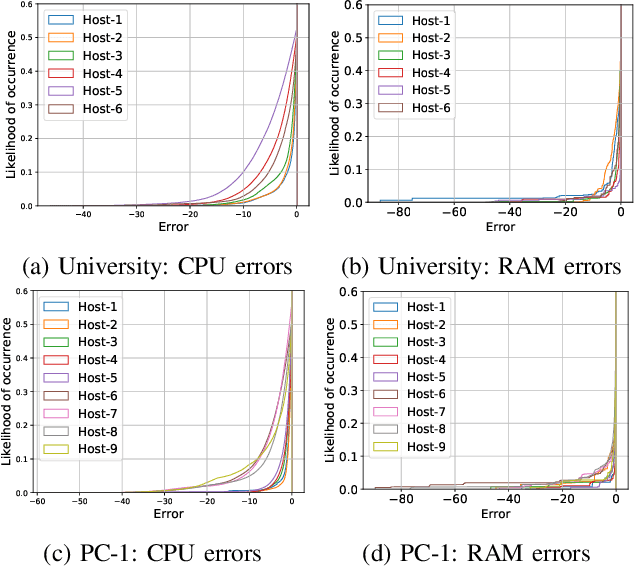
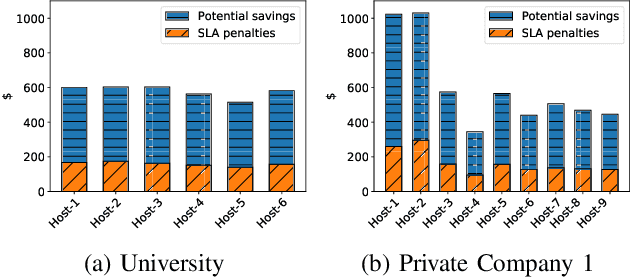
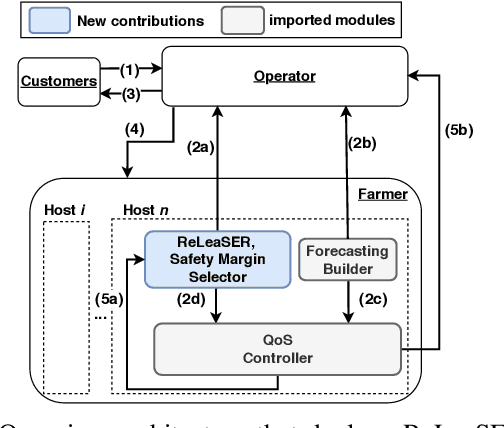
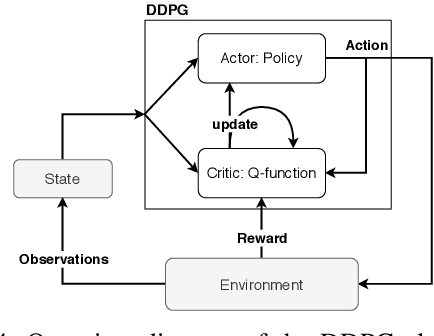
Cloud data center capacities are over-provisioned to handle demand peaks and hardware failures which leads to low resources' utilization. One way to improve resource utilization and thus reduce the total cost of ownership is to offer the unused resources at a lower price. However, reselling resources needs to meet the expectations of its customers in terms of Quality of Service. The goal is so to maximize the amount of reclaimed resources while avoiding SLA penalties. To achieve that, cloud providers have to estimate their future utilization to provide availability guarantees. The prediction should consider a safety margin of resources to react to unpredictable workloads. The challenge is to find the safety margin that provides the best trade-off between the amount of resources to reclaim and the risk of SLA violations. Most state-of-the-art solutions consider a fixed safety margin for all types of metrics (e.g., CPU, RAM). However, a unique fixed margin does not consider various workloads variations over time which may lead to SLA violations or/and poor utilization. In order to tackle these challenges, we propose ReLeaSER, a Reinforcement Learning strategy for optimizing the ephemeral resources' utilization in the cloud. ReLeaSER dynamically tunes the safety margin at the host-level for each resource metric. The strategy learns from past prediction errors (that caused SLA violations). Our solution reduces significantly the SLA violation penalties on average by 2.7x and up to 3.4x. It also improves considerably the CPs' potential savings by 27.6% on average and up to 43.6%.
Better Fine-Tuning by Reducing Representational Collapse
Aug 06, 2020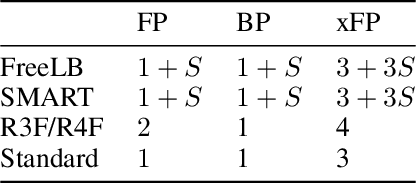
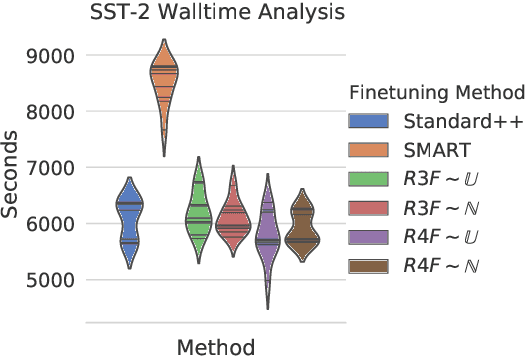
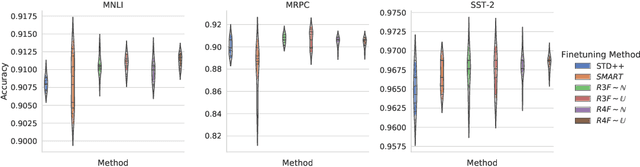
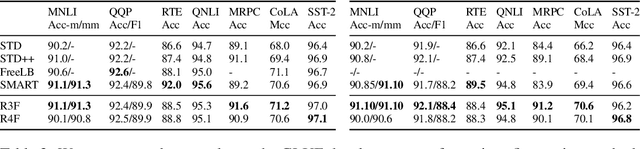
Although widely adopted, existing approaches for fine-tuning pre-trained language models have been shown to be unstable across hyper-parameter settings, motivating recent work on trust region methods. In this paper, we present a simplified and efficient method rooted in trust region theory that replaces previously used adversarial objectives with parametric noise (sampling from either a normal or uniform distribution), thereby discouraging representation change during fine-tuning when possible without hurting performance. We also introduce a new analysis to motivate the use of trust region methods more generally, by studying representational collapse; the degradation of generalizable representations from pre-trained models as they are fine-tuned for a specific end task. Extensive experiments show that our fine-tuning method matches or exceeds the performance of previous trust region methods on a range of understanding and generation tasks (including DailyMail/CNN, Gigaword, Reddit TIFU, and the GLUE benchmark), while also being much faster. We also show that it is less prone to representation collapse; the pre-trained models maintain more generalizable representations every time they are fine-tuned.
InfecTracer: Approximate Nearest Neighbors Retrieval of GPS Location Traces to Retrieve Susceptible Cases
Apr 19, 2020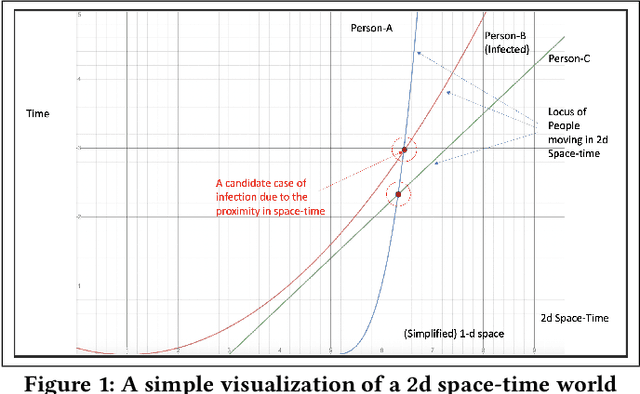
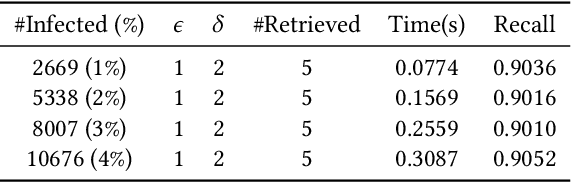
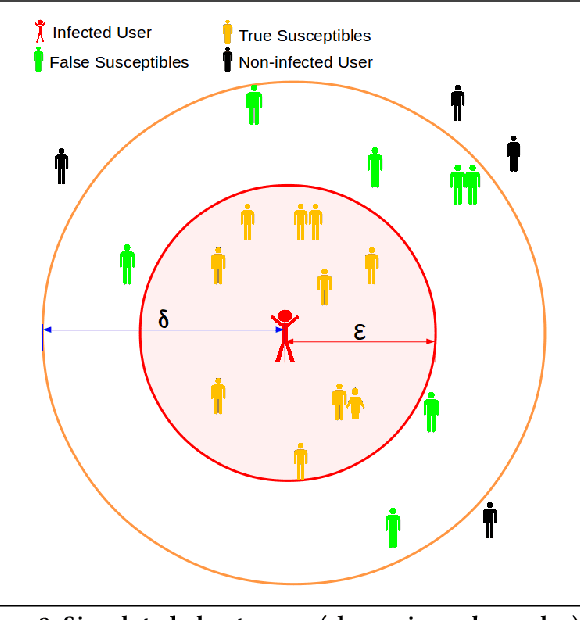
Epidemics, such as the present Covid-19 pandemic, usually spread at a rapid rate. Standard models, e.g., the SIR model, have stressed on the importance of finding the susceptible cases to flatten the growth rate of the spread of infection as early as possible. In the present scientific world, location traces in the form of GPS coordinates are logged by mobile device manufacturing and their operating systems developing companies, such as Apple, Samsung, Google etc. However, due to the sensitive nature of this data, it is usually not shared with other organisations, mainly to protect individual privacy. However, in disaster situations, such as epidemics, data in the form of location traces of a community of people can potentially be helpful to proactively locate susceptible people from the community and enforce quarantine on them as early as possible. Since procuring such data for the purpose of restricted use is difficult (time-consuming) due to the sensitive nature of the data, a strong case needs to be made that how could such data be useful in disaster situations. The aim of this article is to to demonstrate a proof-of-the-concept that with the availability of massive amounts of real check-in data, it is feasible to develop a scalable system that is both effective (in terms of identifying the susceptible people) and efficient (in terms of the time taken to do so). We believe that this proof-of-the-concept will encourage sharing (with restricted use) of such sensitive data in order to help mitigate disaster situations. In this article, we describe a software resource to efficiently (consuming a small run-time) locate a set of susceptible persons given a global database of user check-ins and a set of infected people. Specifically, we describe a system, named InfecTracer, that seeks to find out cases of close proximity of a person with another infected person.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020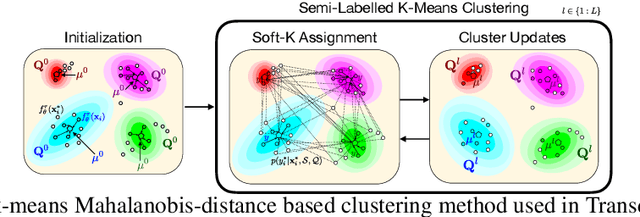
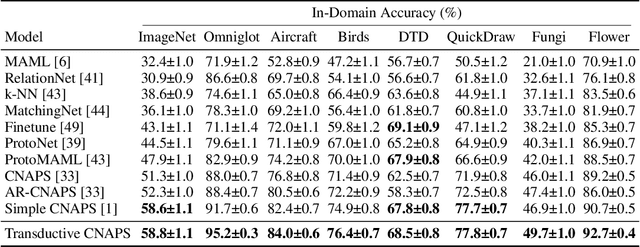
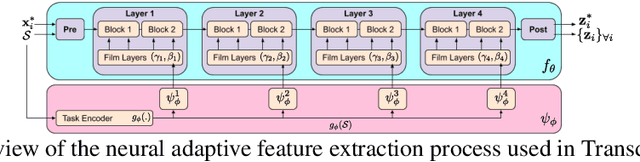
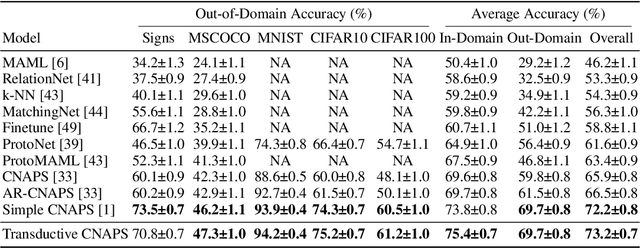
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning
Sep 15, 2020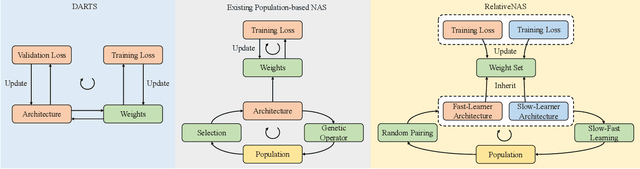
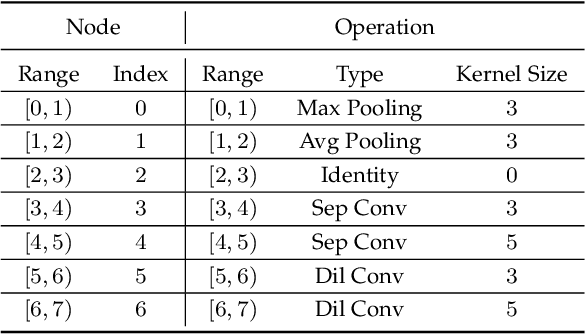
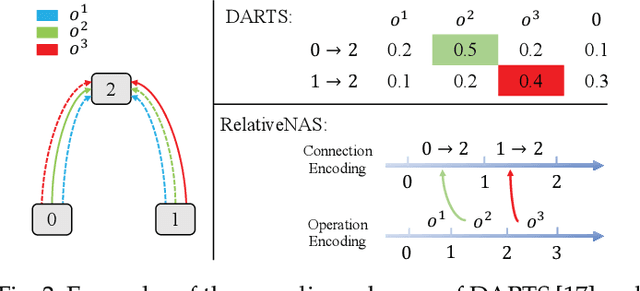
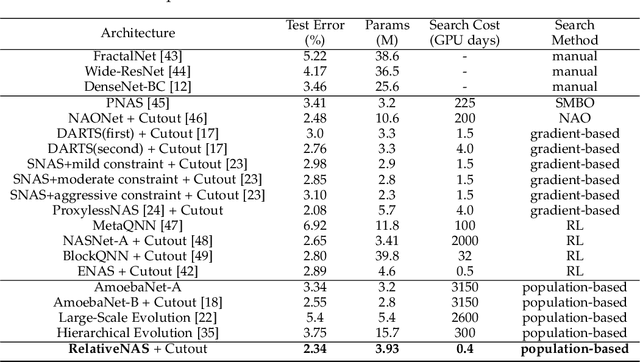
Despite the remarkable successes of Convolutional Neural Networks (CNNs) in computer vision, it is time-consuming and error-prone to manually design a CNN. Among various Neural Architecture Search (NAS) methods that are motivated to automate designs of high-performance CNNs, the differentiable NAS and population-based NAS are attracting increasing interests due to their unique characters. To benefit from the merits while overcoming the deficiencies of both, this work proposes a novel NAS method, RelativeNAS. As the key to efficient search, RelativeNAS performs joint learning between fast-learners (i.e. networks with relatively higher accuracy) and slow-learners in a pairwise manner. Moreover, since RelativeNAS only requires low-fidelity performance estimation to distinguish each pair of fast-learner and slow-learner, it saves certain computation costs for training the candidate architectures. The proposed RelativeNAS brings several unique advantages: (1) it achieves state-of-the-art performance on ImageNet with top-1 error rate of 24.88%, i.e. outperforming DARTS and AmoebaNet-B by 1.82% and 1.12% respectively; (2) it spends only nine hours with a single 1080Ti GPU to obtain the discovered cells, i.e. 3.75x and 7875x faster than DARTS and AmoebaNet respectively; (3) it provides that the discovered cells obtained on CIFAR-10 can be directly transferred to object detection, semantic segmentation, and keypoint detection, yielding competitive results of 73.1% mAP on PASCAL VOC, 78.7% mIoU on Cityscapes, and 68.5% AP on MSCOCO, respectively. The implementation of RelativeNAS is available at https://github.com/EMI-Group/RelativeNAS
Ownership at Large -- Open Problems and Challenges in Ownership Management
Apr 15, 2020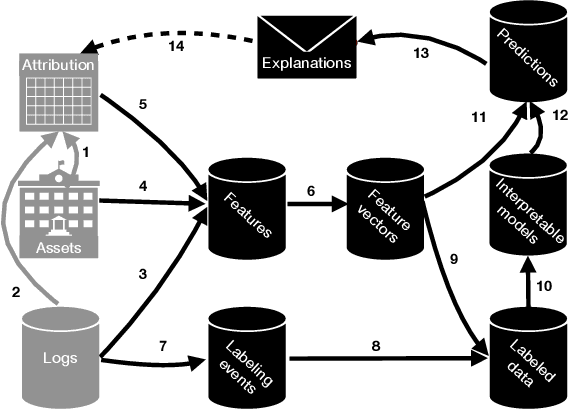
Software-intensive organizations rely on large numbers of software assets of different types, e.g., source-code files, tables in the data warehouse, and software configurations. Who is the most suitable owner of a given asset changes over time, e.g., due to reorganization and individual function changes. New forms of automation can help suggest more suitable owners for any given asset at a given point in time. By such efforts on ownership health, accountability of ownership is increased. The problem of finding the most suitable owners for an asset is essentially a program comprehension problem: how do we automatically determine who would be best placed to understand, maintain, evolve (and thereby assume ownership of) a given asset. This paper introduces the Facebook Ownesty system, which uses a combination of ultra large scale data mining and machine learning and has been deployed at Facebook as part of the company's ownership management approach. Ownesty processes many millions of software assets (e.g., source-code files) and it takes into account workflow and organizational aspects. The paper sets out open problems and challenges on ownership for the research community with advances expected from the fields of software engineering, programming languages, and machine learning.
Differentiable Algorithm for Marginalising Changepoints
Nov 22, 2019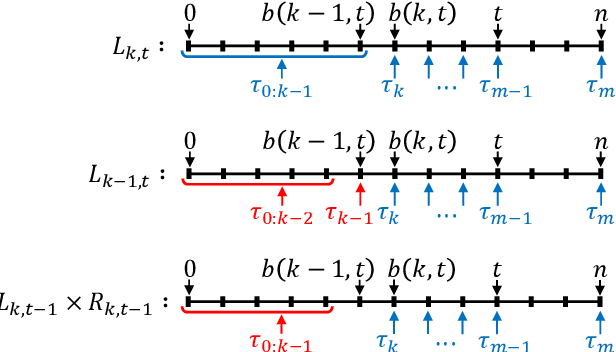

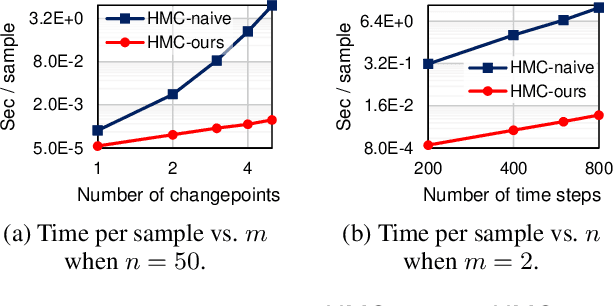
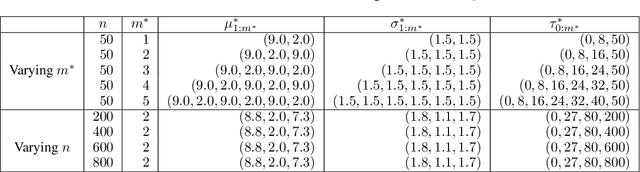
We present an algorithm for marginalising changepoints in time-series models that assume a fixed number of unknown changepoints. Our algorithm is differentiable with respect to its inputs, which are the values of latent random variables other than changepoints. Also, it runs in time O(mn) where n is the number of time steps and m the number of changepoints, an improvement over a naive marginalisation method with O(n^m) time complexity. We derive the algorithm by identifying quantities related to this marginalisation problem, showing that these quantities satisfy recursive relationships, and transforming the relationships to an algorithm via dynamic programming. Since our algorithm is differentiable, it can be applied to convert a model non-differentiable due to changepoints to a differentiable one, so that the resulting models can be analysed using gradient-based inference or learning techniques. We empirically show the effectiveness of our algorithm in this application by tackling the posterior inference problem on synthetic and real-world data.