 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neurocoder: Learning General-Purpose Computation Using Stored Neural Programs
Sep 24, 2020
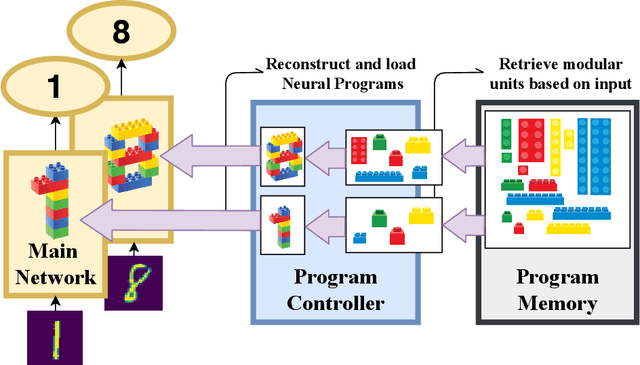
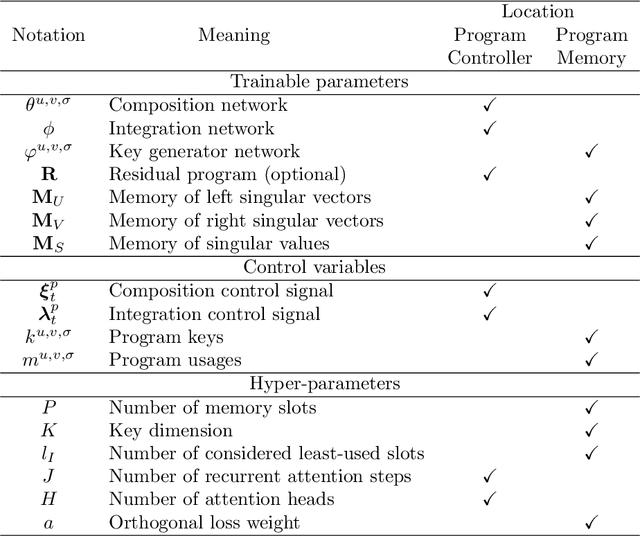
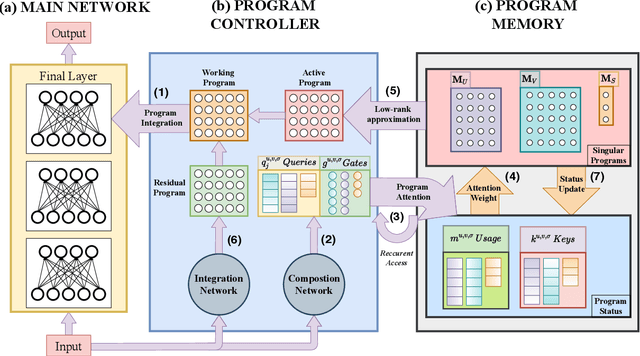
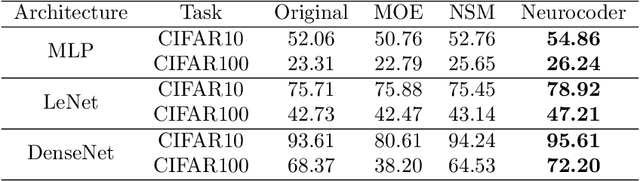
Artificial Neural Networks are uniquely adroit at machine learning by processing data through a network of artificial neurons. The inter-neuronal connection weights represent the learnt Neural Program that instructs the network on how to compute the data. However, without an external memory to store Neural Programs, they are restricted to only one, overwriting learnt programs when trained on new data. This is functionally equivalent to a special-purpose computer. Here we design Neurocoder, an entirely new class of general-purpose conditional computational machines in which the neural network "codes" itself in a data-responsive way by composing relevant programs from a set of shareable, modular programs. This can be considered analogous to building Lego structures from simple Lego bricks. Notably, our bricks change their shape through learning. External memory is used to create, store and retrieve modular programs. Like today's stored-program computers, Neurocoder can now access diverse programs to process different data. Unlike manually crafted computer programs, Neurocoder creates programs through training. Integrating Neurocoder into current neural architectures, we demonstrate new capacity to learn modular programs, handle severe pattern shifts and remember old programs as new ones are learnt, and show substantial performance improvement in solving object recognition, playing video games and continual learning tasks. Such integration with Neurocoder increases the computation capability of any current neural network and endows it with entirely new capacity to reuse simple programs to build complex ones. For the first time a Neural Program is treated as a datum in memory, paving the ways for modular, recursive and procedural neural programming.
Scalar Coupling Constant Prediction Using Graph Embedding Local Attention Encoder
Sep 07, 2020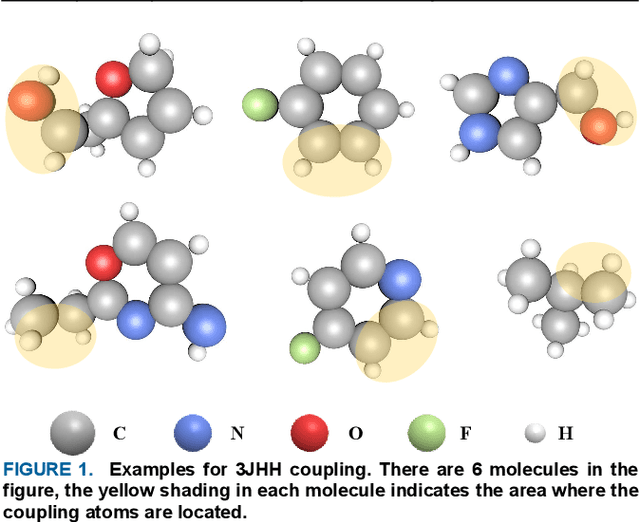
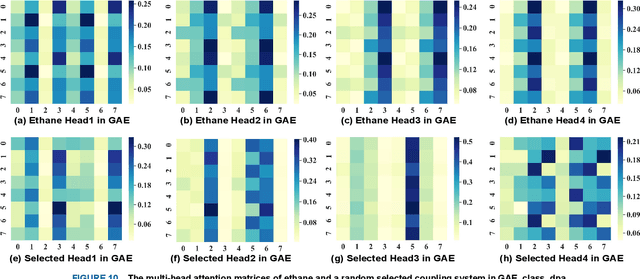
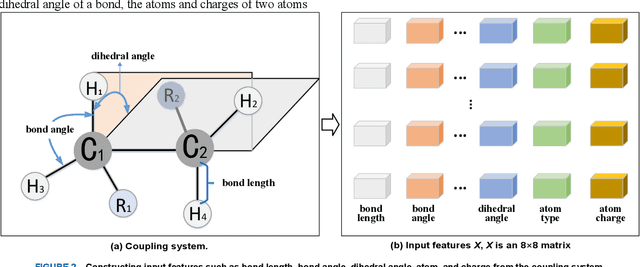
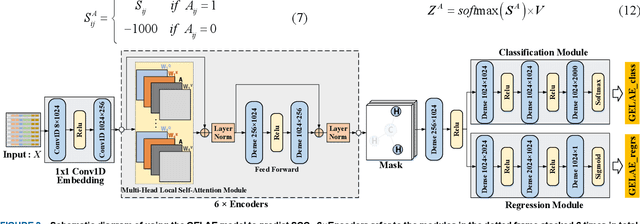
Scalar coupling constant (SCC) plays a key role in the analysis of three-dimensional structure of organic matter, however, the traditional SCC prediction using quantum mechanical calculations is very time-consuming. To calculate SCC efficiently and accurately, we proposed a graph embedding local self-attention encoder (GELAE) model, in which, a novel invariant structure representation of the coupling system in terms of bond length, bond angle and dihedral angle was presented firstly, and then a local self-attention module embedded with the adjacent matrix of a graph was designed to extract effectively the features of coupling systems, finally, with a modified classification loss function, the SCC was predicted. To validate the superiority of the proposed method, we conducted a series of comparison experiments using different structure representations, different attention modules, and different losses. The experimental results demonstrate that, compared to the traditional chemical bond structure representations, the rotation and translation invariant structure representations proposed in this work can improve the SCC prediction accuracy; with the graph embedded local self-attention, the mean absolute error (MAE) of the prediction model in the validation set decreases from 0.1603 Hz to 0.1067 Hz; using the classification based loss function instead of the scaled regression loss, the MAE of the predicted SCC can be decreased to 0.0963 HZ, which is close to the quantum chemistry standard on CHAMPS dataset.
BiteNet: Bidirectional Temporal Encoder Network to Predict Medical Outcomes
Sep 24, 2020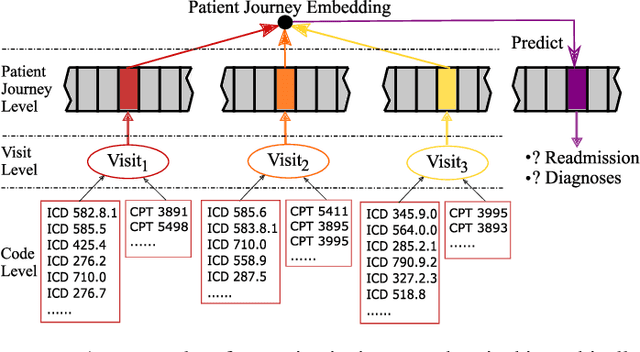
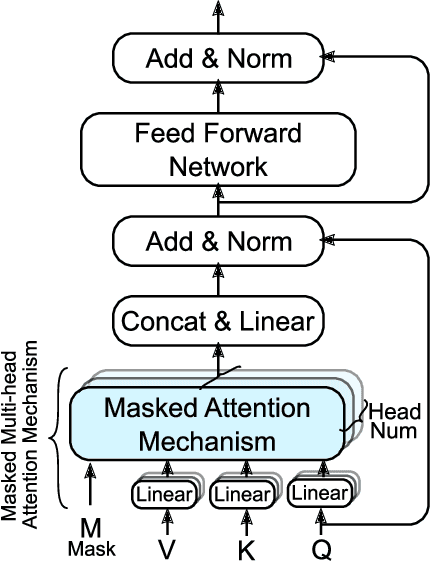
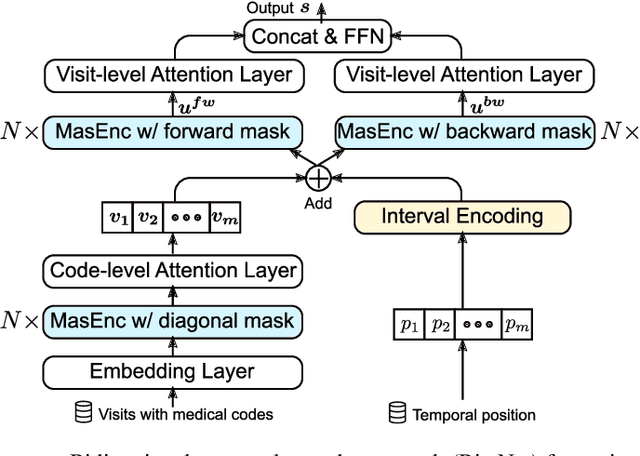
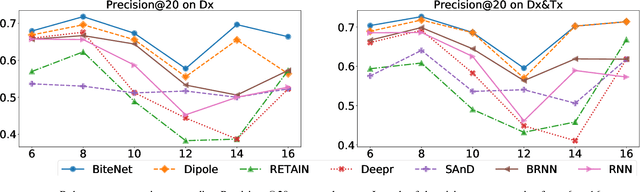
Electronic health records (EHRs) are longitudinal records of a patient's interactions with healthcare systems. A patient's EHR data is organized as a three-level hierarchy from top to bottom: patient journey - all the experiences of diagnoses and treatments over a period of time; individual visit - a set of medical codes in a particular visit; and medical code - a specific record in the form of medical codes. As EHRs begin to amass in millions, the potential benefits, which these data might hold for medical research and medical outcome prediction, are staggering - including, for example, predicting future admissions to hospitals, diagnosing illnesses or determining the efficacy of medical treatments. Each of these analytics tasks requires a domain knowledge extraction method to transform the hierarchical patient journey into a vector representation for further prediction procedure. The representations should embed a sequence of visits and a set of medical codes with a specific timestamp, which are crucial to any downstream prediction tasks. Hence, expressively powerful representations are appealing to boost learning performance. To this end, we propose a novel self-attention mechanism that captures the contextual dependency and temporal relationships within a patient's healthcare journey. An end-to-end bidirectional temporal encoder network (BiteNet) then learns representations of the patient's journeys, based solely on the proposed attention mechanism. We have evaluated the effectiveness of our methods on two supervised prediction and two unsupervised clustering tasks with a real-world EHR dataset. The empirical results demonstrate the proposed BiteNet model produces higher-quality representations than state-of-the-art baseline methods.
Holistic Features For Real-Time Crowd Behaviour Anomaly Detection
Jun 16, 2016
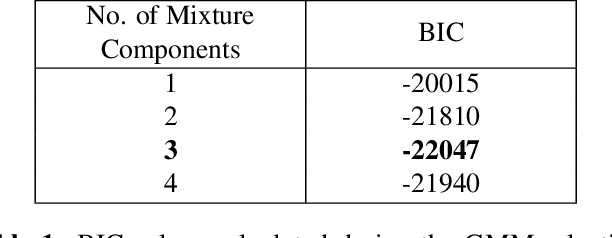
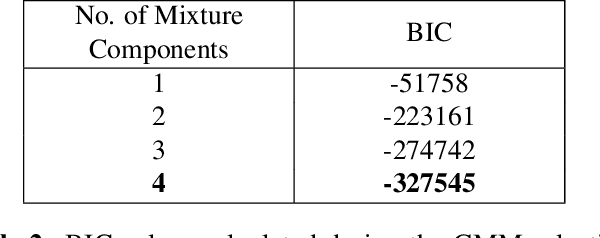
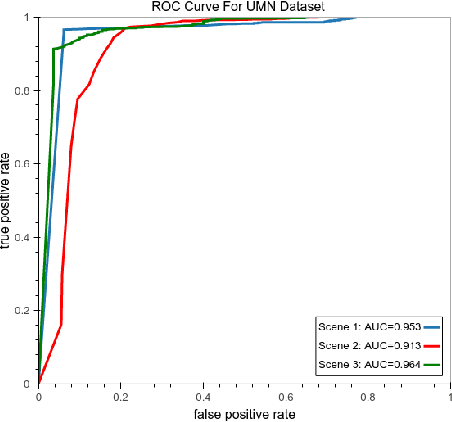
This paper presents a new approach to crowd behaviour anomaly detection that uses a set of efficiently computed, easily interpretable, scene-level holistic features. This low-dimensional descriptor combines two features from the literature: crowd collectiveness [1] and crowd conflict [2], with two newly developed crowd features: mean motion speed and a new formulation of crowd density. Two different anomaly detection approaches are investigated using these features. When only normal training data is available we use a Gaussian Mixture Model (GMM) for outlier detection. When both normal and abnormal training data is available we use a Support Vector Machine (SVM) for binary classification. We evaluate on two crowd behaviour anomaly detection datasets, achieving both state-of-the-art classification performance on the violent-flows dataset [3] as well as better than real-time processing performance (40 frames per second).
Analysis and Prediction of Pedestrian Crosswalk Behavior during Automated Vehicle Interactions
Mar 22, 2020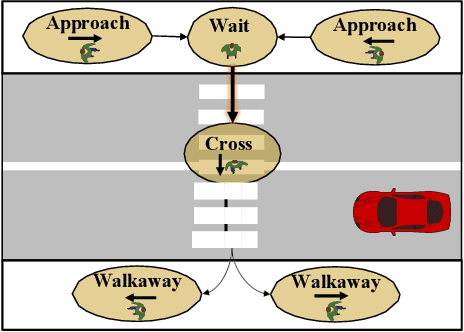

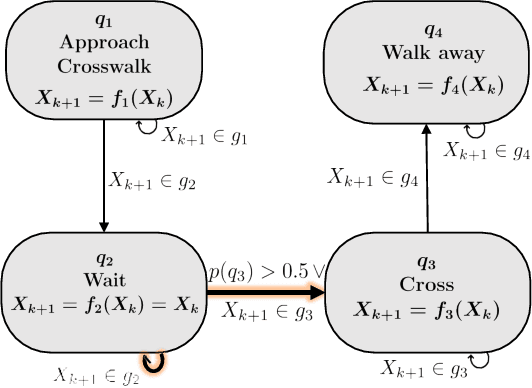
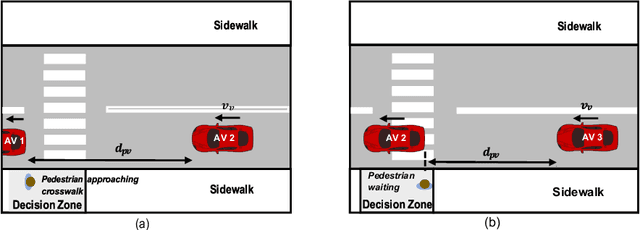
For safe navigation around pedestrians, automated vehicles (AVs) need to plan their motion by accurately predicting pedestrians trajectories over long time horizons. Current approaches to AV motion planning around crosswalks predict only for short time horizons (1-2 s) and are based on data from pedestrian interactions with human-driven vehicles (HDVs). In this paper, we develop a hybrid systems model that uses pedestrians gap acceptance behavior and constant velocity dynamics for long-term pedestrian trajectory prediction when interacting with AVs. Results demonstrate the applicability of the model for long-term (> 5 s) pedestrian trajectory prediction at crosswalks. Further we compared measures of pedestrian crossing behaviors in the immersive virtual environment (when interacting with AVs) to that in the real world (results of published studies of pedestrians interacting with HDVs), and found similarities between the two. These similarities demonstrate the applicability of the hybrid model of AV interactions developed from an immersive virtual environment (IVE) for real-world scenarios for both AVs and HDVs.
Supervised Learning for Optimal Power Flow as a Real-Time Proxy
Dec 20, 2016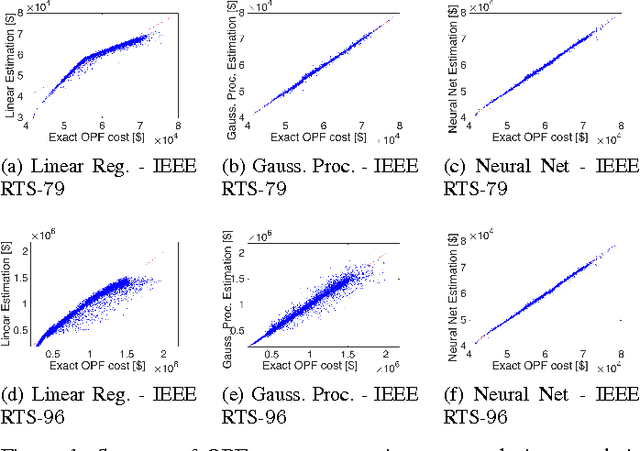
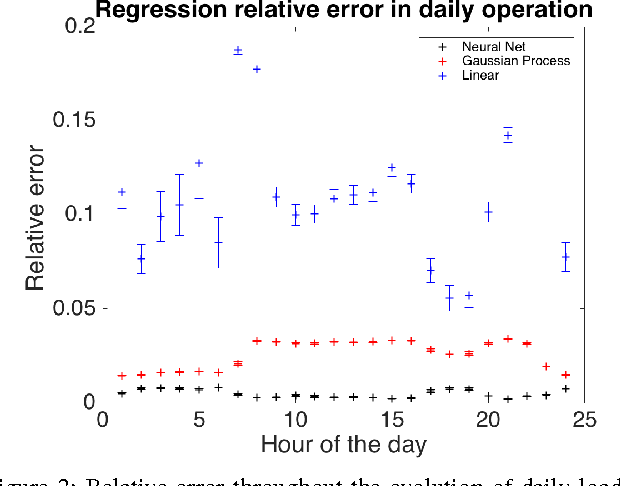
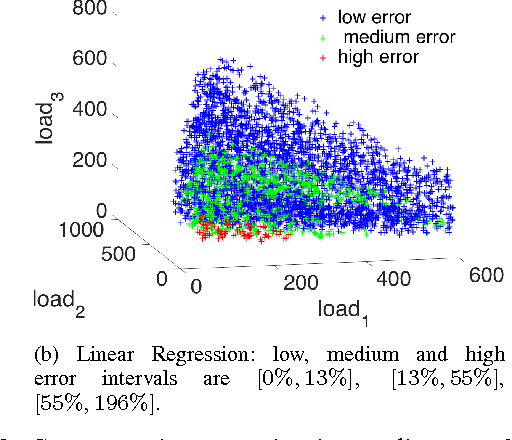
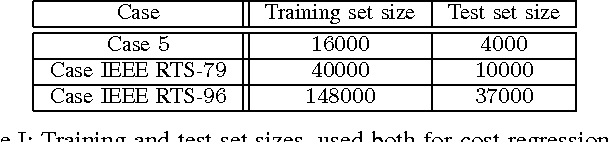
In this work we design and compare different supervised learning algorithms to compute the cost of Alternating Current Optimal Power Flow (ACOPF). The motivation for quick calculation of OPF cost outcomes stems from the growing need of algorithmic-based long-term and medium-term planning methodologies in power networks. Integrated in a multiple time-horizon coordination framework, we refer to this approximation module as a proxy for predicting short-term decision outcomes without the need of actual simulation and optimization of them. Our method enables fast approximate calculation of OPF cost with less than 1% error on average, achieved in run-times that are several orders of magnitude lower than of exact computation. Several test-cases such as IEEE-RTS96 are used to demonstrate the efficiency of our approach.
Lazy Greedy Hypervolume Subset Selection from Large Candidate Solution Sets
Jul 04, 2020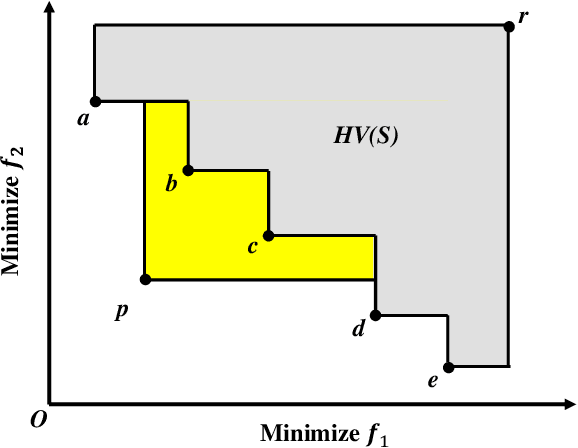
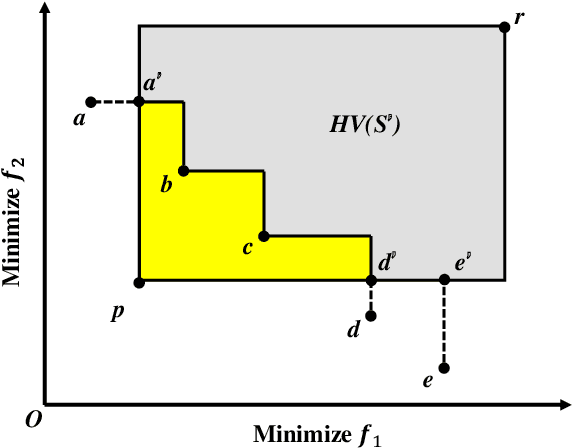
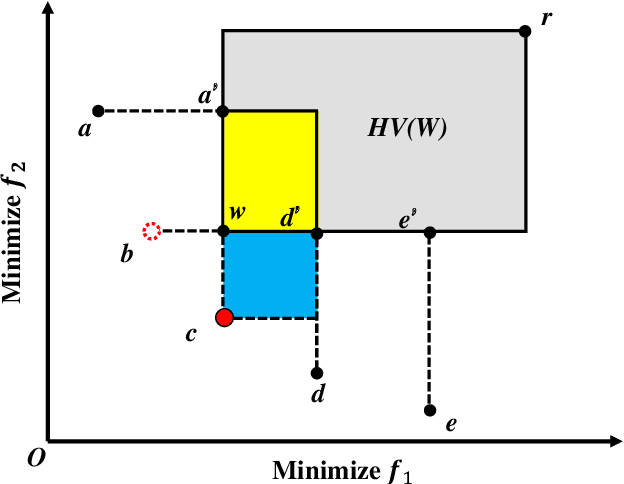

Subset selection is a popular topic in recent years and a number of subset selection methods have been proposed. Among those methods, hypervolume subset selection is widely used. Greedy hypervolume subset selection algorithms can achieve good approximations to the optimal subset. However, when the candidate set is large (e.g., an unbounded external archive with a large number of solutions), the algorithm is very time-consuming. In this paper, we propose a new lazy greedy algorithm exploiting the submodular property of the hypervolume indicator. The core idea is to avoid unnecessary hypervolume contribution calculation when finding the solution with the largest contribution. Experimental results show that the proposed algorithm is hundreds of times faster than the original greedy inclusion algorithm and several times faster than the fastest known greedy inclusion algorithm on many test problems.
Estimating Time-varying Brain Connectivity Networks from Functional MRI Time Series
Apr 13, 2014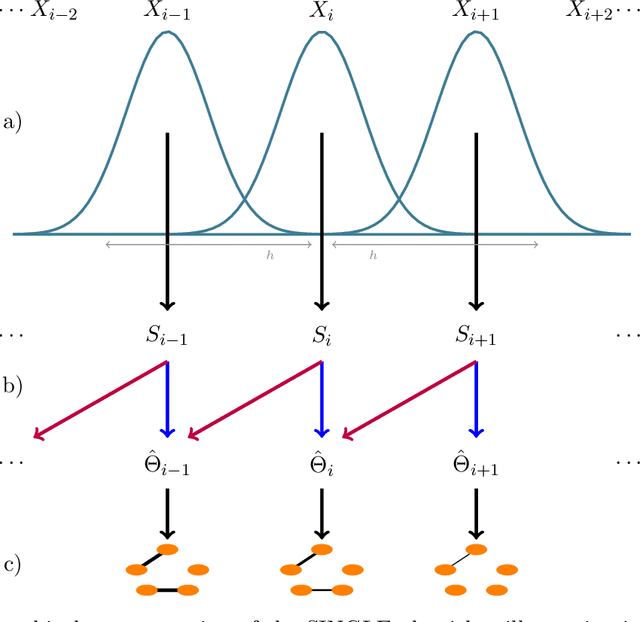
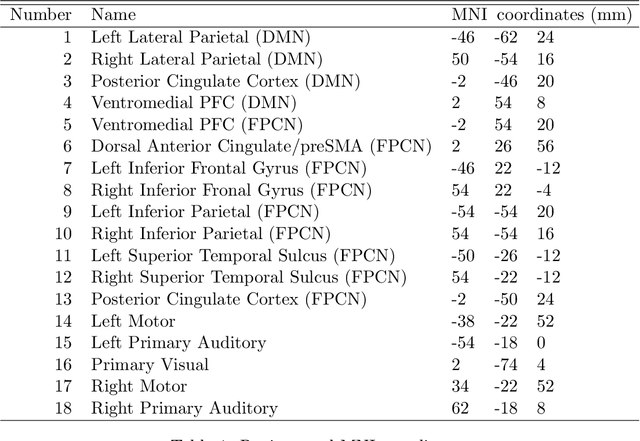
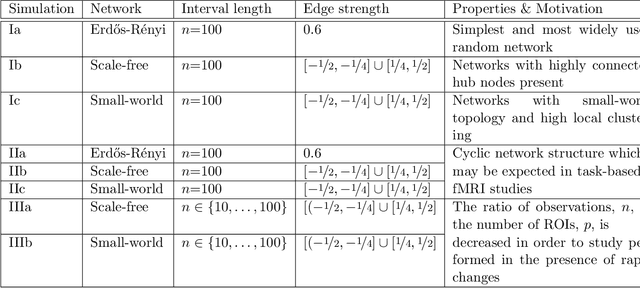
Understanding the functional architecture of the brain in terms of networks is becoming increasingly common. In most fMRI applications functional networks are assumed to be stationary, resulting in a single network estimated for the entire time course. However recent results suggest that the connectivity between brain regions is highly non-stationary even at rest. As a result, there is a need for new brain imaging methodologies that comprehensively account for the dynamic (i.e., non-stationary) nature of the fMRI data. In this work we propose the Smooth Incremental Graphical Lasso Estimation (SINGLE) algorithm which estimates dynamic brain networks from fMRI data. We apply the SINGLE algorithm to functional MRI data from 24 healthy patients performing a choice-response task to demonstrate the dynamic changes in network structure that accompany a simple but attentionally demanding cognitive task. Using graph theoretic measures we show that the Right Inferior Frontal Gyrus, frequently reported as playing an important role in cognitive control, dynamically changes with the task. Our results suggest that the Right Inferior Frontal Gyrus plays a fundamental role in the attention and executive function during cognitively demanding tasks and may play a key role in regulating the balance between other brain regions.
Unsupervised Learning for Identifying Events in Active Target Experiments
Aug 06, 2020This article presents novel applications of unsupervised machine learning methods to the problem of event separation in an active target detector, the Active-Target Time Projection Chamber (AT-TPC). The overarching goal is to group similar events in the early stages of the data analysis, thereby improving efficiency by limiting the computationally expensive processing of unnecessary events. The application of unsupervised clustering algorithms to the analysis of two-dimensional projections of particle tracks from a resonant proton scattering experiment on $^{46}$Ar is introduced. We explore the performance of autoencoder neural networks and a pre-trained VGG16 convolutional neural network. We find that a $K$-means algorithm applied to the simulated data in the VGG16 latent space forms almost perfect clusters. Additionally, the VGG16+$K$-means approach finds high purity clusters of proton events for real experimental data. We also explore the application of clustering the latent space of autoencoder neural networks for event separation. While these networks show strong performance, they suffer from high variability in their results. %With autoencoder neural networks we find improved descriptions of data from experiments.
Iterative Refinement in the Continuous Space for Non-Autoregressive Neural Machine Translation
Sep 15, 2020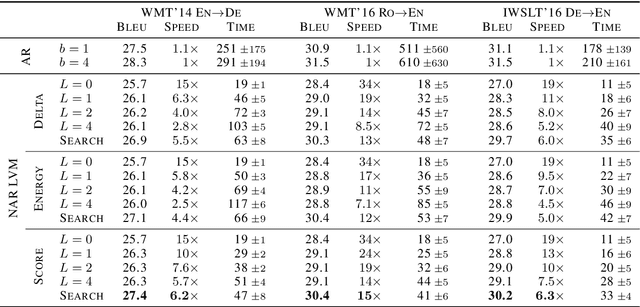
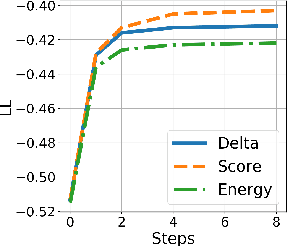
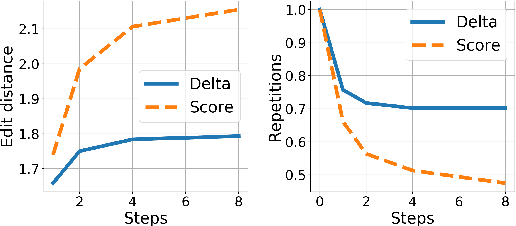

We propose an efficient inference procedure for non-autoregressive machine translation that iteratively refines translation purely in the continuous space. Given a continuous latent variable model for machine translation (Shu et al., 2020), we train an inference network to approximate the gradient of the marginal log probability of the target sentence, using only the latent variable as input. This allows us to use gradient-based optimization to find the target sentence at inference time that approximately maximizes its marginal probability. As each refinement step only involves computation in the latent space of low dimensionality (we use 8 in our experiments), we avoid computational overhead incurred by existing non-autoregressive inference procedures that often refine in token space. We compare our approach to a recently proposed EM-like inference procedure (Shu et al., 2020) that optimizes in a hybrid space, consisting of both discrete and continuous variables. We evaluate our approach on WMT'14 En-De, WMT'16 Ro-En and IWSLT'16 De-En, and observe two advantages over the EM-like inference: (1) it is computationally efficient, i.e. each refinement step is twice as fast, and (2) it is more effective, resulting in higher marginal probabilities and BLEU scores with the same number of refinement steps. On WMT'14 En-De, for instance, our approach is able to decode 6.2 times faster than the autoregressive model with minimal degradation to translation quality (0.9 BLEU).