 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Beneficial Perturbation Network for designing general adaptive artificial intelligence systems
Sep 27, 2020
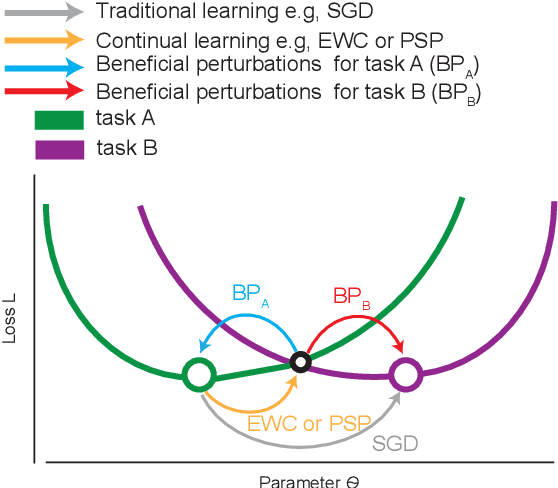
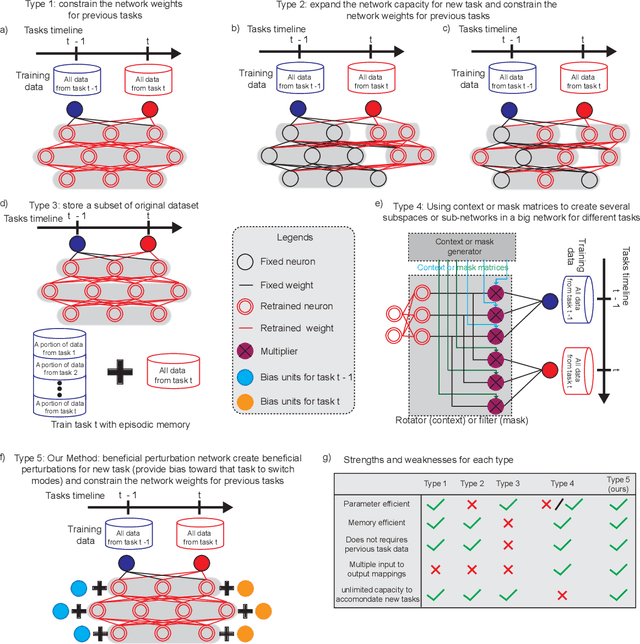
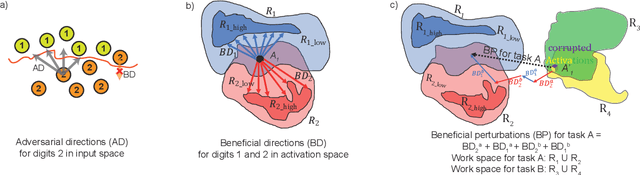
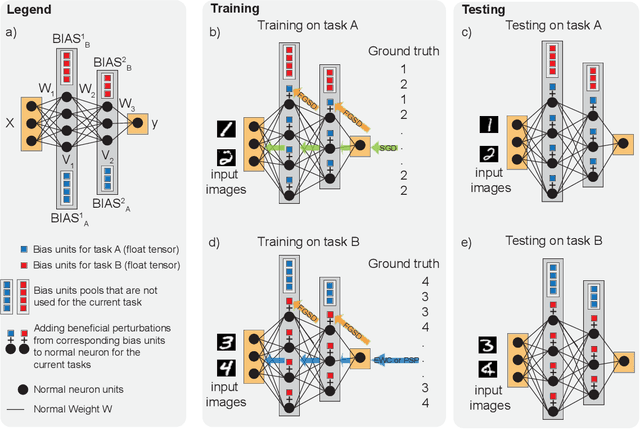
The human brain is the gold standard of adaptive learning. It not only can learn and benefit from experience, but also can adapt to new situations. In contrast, deep neural networks only learn one sophisticated but fixed mapping from inputs to outputs. This limits their applicability to more dynamic situations, where input to output mapping may change with different contexts. A salient example is continual learning - learning new independent tasks sequentially without forgetting previous tasks. Continual learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby a previously learned mapping of an old task is erased when learning new mappings for new tasks. Here, we propose a new biologically plausible type of deep neural network with extra, out-of-network, task-dependent biasing units to accommodate these dynamic situations. This allows, for the first time, a single network to learn potentially unlimited parallel input to output mappings, and to switch on the fly between them at runtime. Biasing units are programmed by leveraging beneficial perturbations (opposite to well-known adversarial perturbations) for each task. Beneficial perturbations for a given task bias the network toward that task, essentially switching the network into a different mode to process that task. This largely eliminates catastrophic interference between tasks. Our approach is memory-efficient and parameter-efficient, can accommodate many tasks, and achieves state-of-the-art performance across different tasks and domains.
Unpaired Deep Learning for Accelerated MRI using Optimal Transport Driven CycleGAN
Aug 29, 2020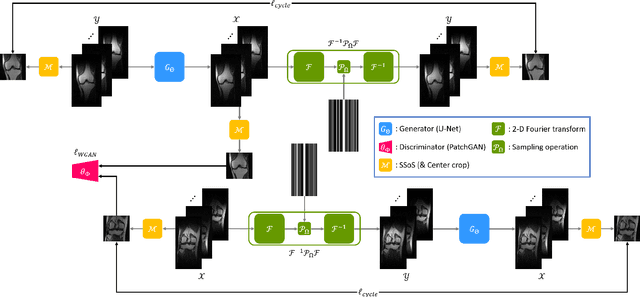

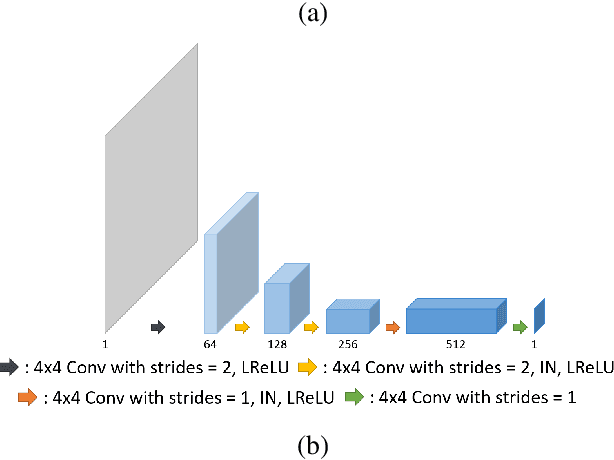

Recently, deep learning approaches for accelerated MRI have been extensively studied thanks to their high performance reconstruction in spite of significantly reduced runtime complexity. These neural networks are usually trained in a supervised manner, so matched pairs of subsampled and fully sampled k-space data are required. Unfortunately, it is often difficult to acquire matched fully sampled k-space data, since the acquisition of fully sampled k-space data requires long scan time and often leads to the change of the acquisition protocol. Therefore, unpaired deep learning without matched label data has become a very important research topic. In this paper, we propose an unpaired deep learning approach using a optimal transport driven cycle-consistent generative adversarial network (OT-cycleGAN) that employs a single pair of generator and discriminator. The proposed OT-cycleGAN architecture is rigorously derived from a dual formulation of the optimal transport formulation using a specially designed penalized least squares cost. The experimental results show that our method can reconstruct high resolution MR images from accelerated k- space data from both single and multiple coil acquisition, without requiring matched reference data.
Protein Conformational States: A First Principles Bayesian Method
Aug 05, 2020
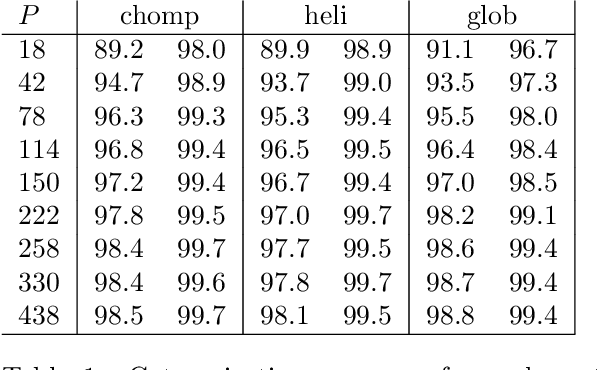
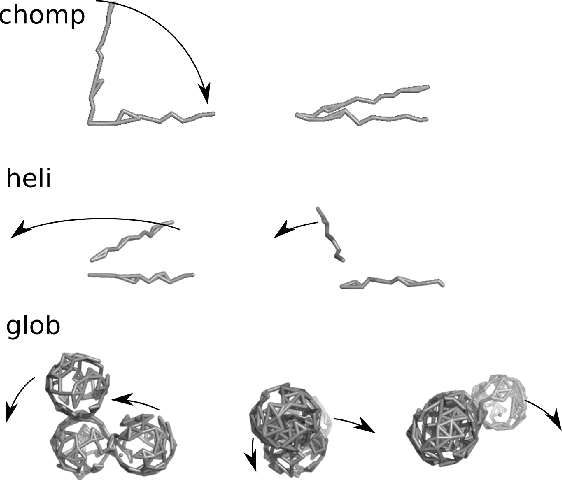
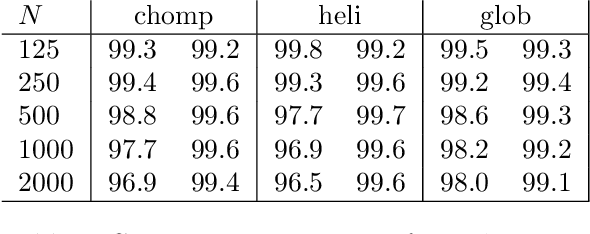
Automated identification of protein conformational states from simulation of an ensemble of structures is a hard problem because it requires teaching a computer to recognize shapes. We adapt the naive Bayes classifier from the machine learning community for use on atom-to-atom pairwise contacts. The result is an unsupervised learning algorithm that samples a `distribution' over potential classification schemes. We apply the classifier to a series of test structures and one real protein, showing that it identifies the conformational transition with > 95% accuracy in most cases. A nontrivial feature of our adaptation is a new connection to information entropy that allows us to vary the level of structural detail without spoiling the categorization. This is confirmed by comparing results as the number of atoms and time-samples are varied over 1.5 orders of magnitude. Further, the method's derivation from Bayesian analysis on the set of inter-atomic contacts makes it easy to understand and extend to more complex cases.
Comparing Time and Frequency Domain for Audio Event Recognition Using Deep Learning
Mar 18, 2016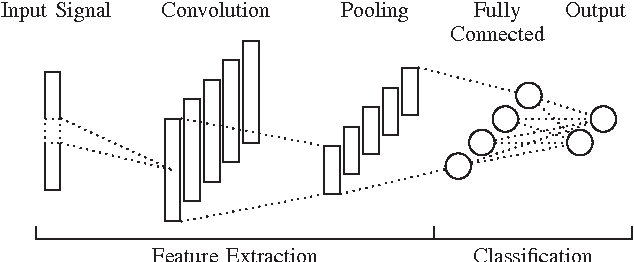
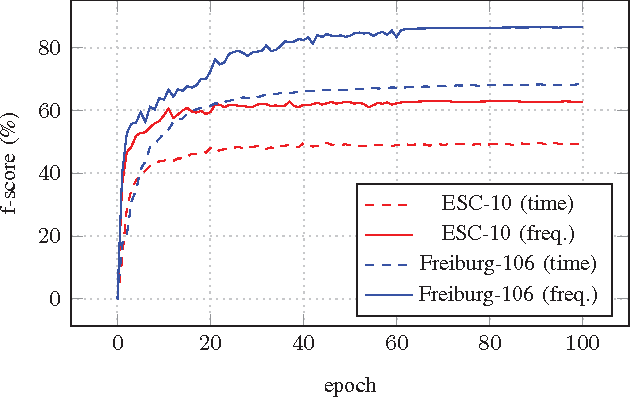
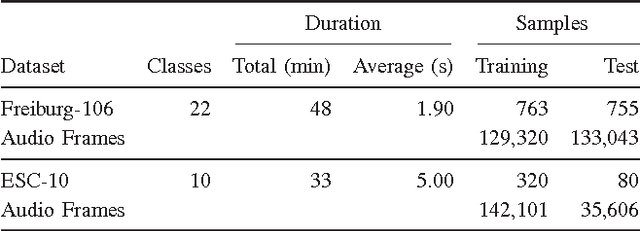
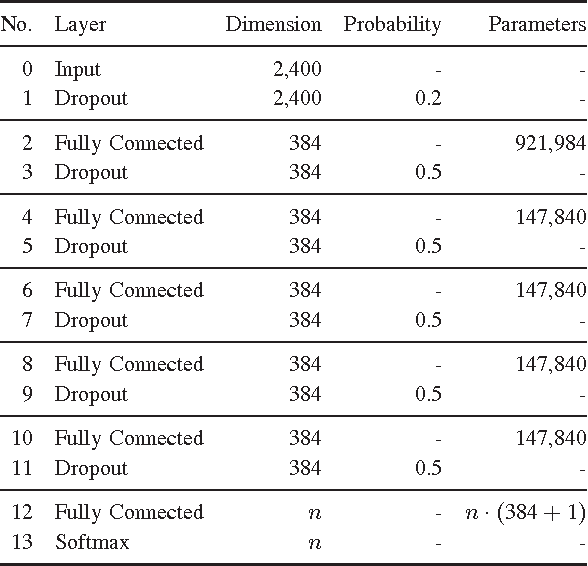
Recognizing acoustic events is an intricate problem for a machine and an emerging field of research. Deep neural networks achieve convincing results and are currently the state-of-the-art approach for many tasks. One advantage is their implicit feature learning, opposite to an explicit feature extraction of the input signal. In this work, we analyzed whether more discriminative features can be learned from either the time-domain or the frequency-domain representation of the audio signal. For this purpose, we trained multiple deep networks with different architectures on the Freiburg-106 and ESC-10 datasets. Our results show that feature learning from the frequency domain is superior to the time domain. Moreover, additionally using convolution and pooling layers, to explore local structures of the audio signal, significantly improves the recognition performance and achieves state-of-the-art results.
MAT: Motion-Aware Multi-Object Tracking
Sep 18, 2020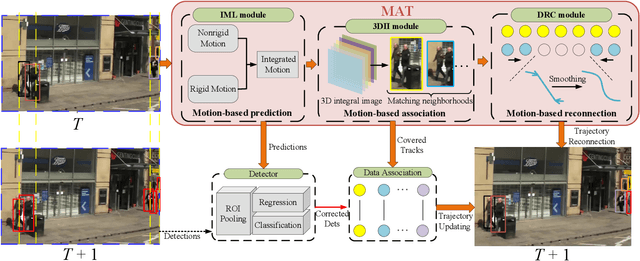
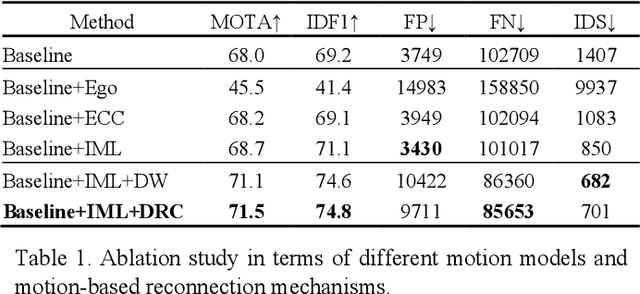
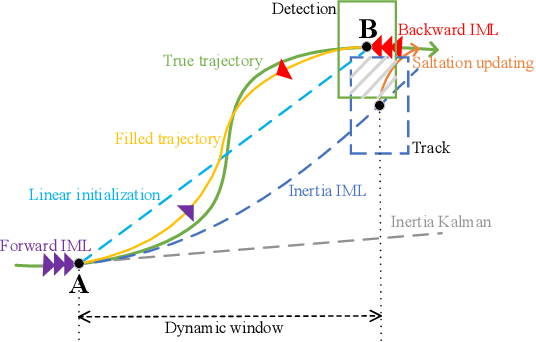
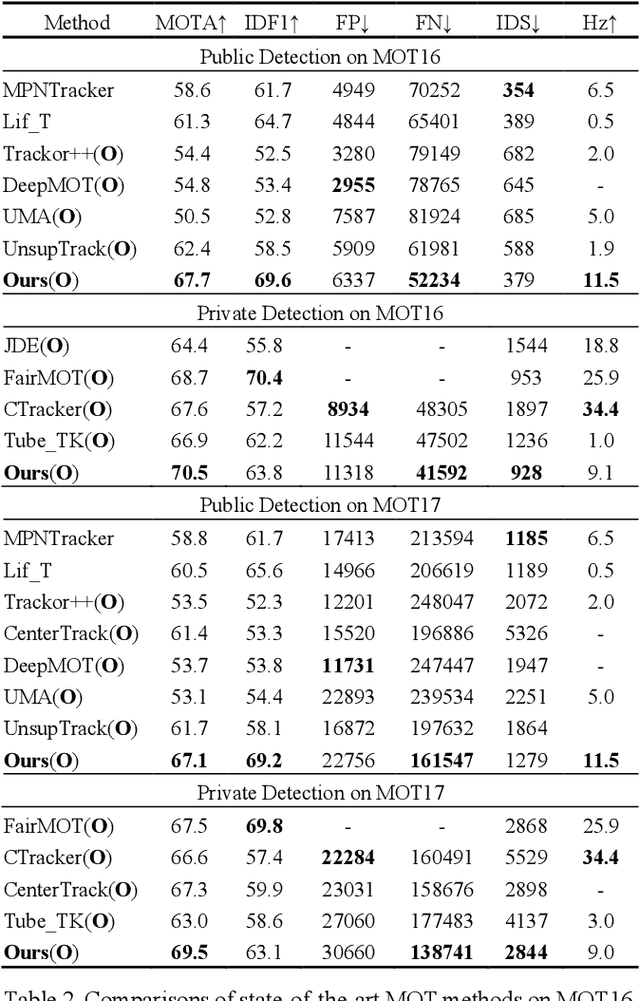
Modern multi-object tracking (MOT) systems usually model the trajectories by associating per-frame detections. However, when camera motion, fast motion, and occlusion challenges occur, it is difficult to ensure long-range tracking or even the tracklet purity, especially for small objects. Although re-identification is often employed, due to noisy partial-detections, similar appearance, and lack of temporal-spatial constraints, it is not only unreliable and time-consuming, but still cannot address the false negatives for occluded and blurred objects. In this paper, we propose an enhanced MOT paradigm, namely Motion-Aware Tracker (MAT), focusing more on various motion patterns of different objects. The rigid camera motion and nonrigid pedestrian motion are blended compatibly to form the integrated motion localization module. Meanwhile, we introduce the dynamic reconnection context module, which aims to balance the robustness of long-range motion-based reconnection, and includes the cyclic pseudo-observation updating strategy to smoothly fill in the tracking fragments caused by occlusion or blur. Additionally, the 3D integral image module is presented to efficiently cut useless track-detection association connections with temporal-spatial constraints. Extensive experiments on MOT16 and MOT17 challenging benchmarks demonstrate that our MAT approach can achieve the superior performance by a large margin with high efficiency, in contrast to other state-of-the-art trackers.
Complexity of Planning
Mar 27, 2020
This is a chapter in the Encyclopedia of Robotics. It is devoted to the study of complexity of complete (or exact) algorithms for robot motion planning. The term ``complete'' indicates that an approach is guaranteed to find the correct solution (a motion path or trajectory in our setting), or to report that none exists otherwise (in case that for instance, no feasible path exists). Complexity theory is a fundamental tool in computer science for analyzing the performance of algorithms, in terms of the amount of resources they require. (While complexity can express different quantities such as space and communication effort, our focus in this chapter is on time complexity.) Moreover, complexity theory helps to identify ``hard'' problems which require excessive amount of computation time to solve. In the context of motion planning, complexity theory can come in handy in various ways, some of which are illustrated here.
A Machine Learning Approach to Assess Student Group Collaboration Using Individual Level Behavioral Cues
Aug 05, 2020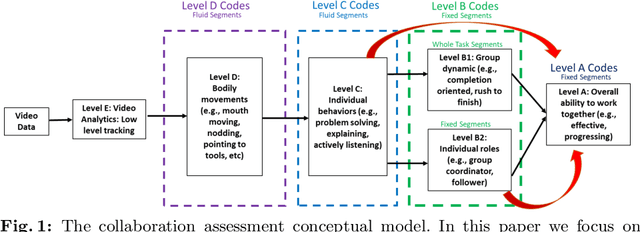

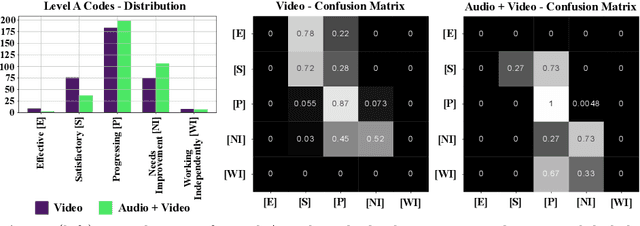
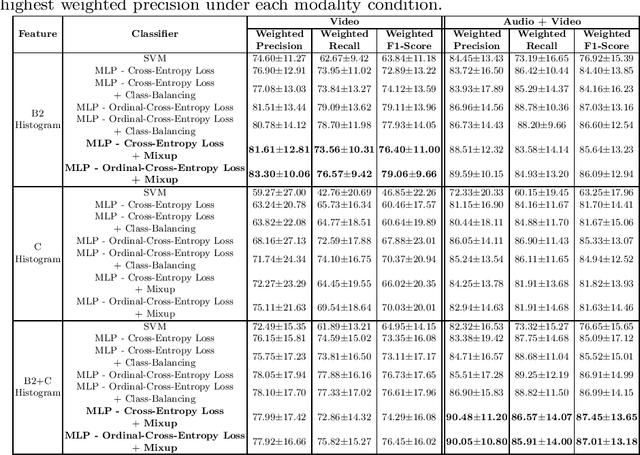
K-12 classrooms consistently integrate collaboration as part of their learning experiences. However, owing to large classroom sizes, teachers do not have the time to properly assess each student and give them feedback. In this paper we propose using simple deep-learning-based machine learning models to automatically determine the overall collaboration quality of a group based on annotations of individual roles and individual level behavior of all the students in the group. We come across the following challenges when building these models: 1) Limited training data, 2) Severe class label imbalance. We address these challenges by using a controlled variant of Mixup data augmentation, a method for generating additional data samples by linearly combining different pairs of data samples and their corresponding class labels. Additionally, the label space for our problem exhibits an ordered structure. We take advantage of this fact and also explore using an ordinal-cross-entropy loss function and study its effects with and without Mixup.
CONDA-PM -- A Systematic Review and Framework for Concept Drift Analysis in Process Mining
Sep 08, 2020
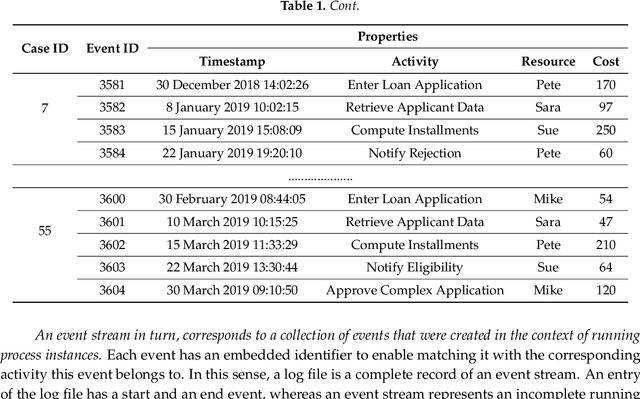
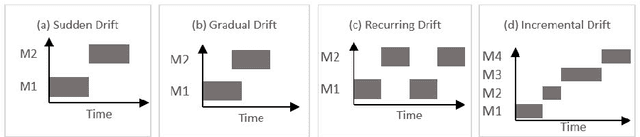
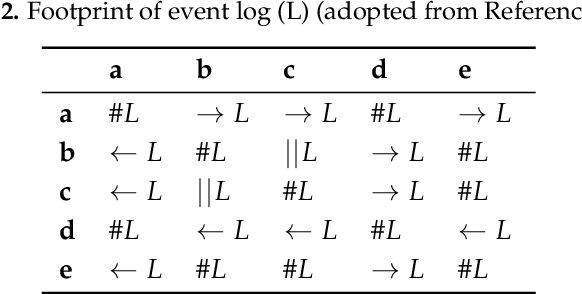
Business processes evolve over time to adapt to changing business environments. This requires continuous monitoring of business processes to gain insights into whether they conform to the intended design or deviate from it. The situation when a business process changes while being analysed is denoted as Concept Drift. Its analysis is concerned with studying how a business process changes, in terms of detecting and localising changes and studying the effects of the latter. Concept drift analysis is crucial to enable early detection and management of changes, that is, whether to promote a change to become part of an improved process, or to reject the change and make decisions to mitigate its effects. Despite its importance, there exists no comprehensive framework for analysing concept drift types, affected process perspectives, and granularity levels of a business process. This article proposes the CONcept Drift Analysis in Process Mining (CONDA-PM) framework describing phases and requirements of a concept drift analysis approach. CONDA-PM was derived from a Systematic Literature Review (SLR) of current approaches analysing concept drift. We apply the CONDA-PM framework on current approaches to concept drift analysis and evaluate their maturity. Applying CONDA-PM framework highlights areas where research is needed to complement existing efforts.
* 45 pages, 11 tables, 13 figures
MicroAnalyzer: A Python Tool for Automated Bacterial Analysis with Fluorescence Microscopy
Sep 26, 2020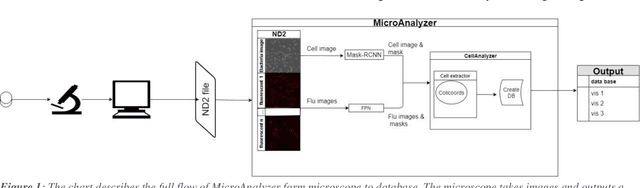
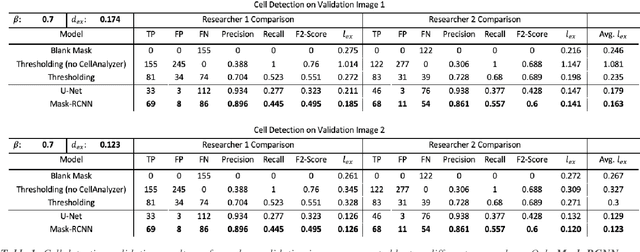
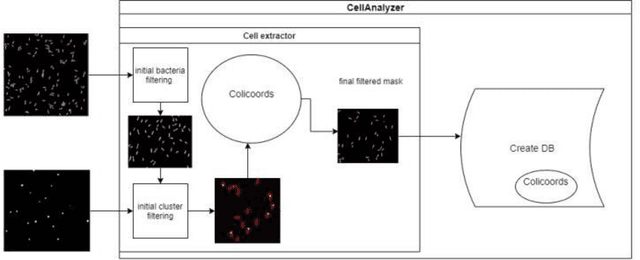
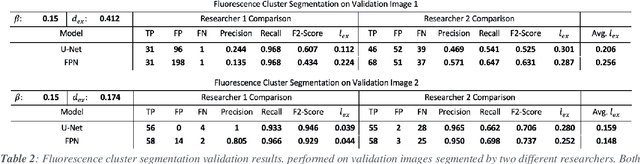
Fluorescence microscopy is a widely used method among cell biologists for studying the localization and co-localization of fluorescent protein. For microbial cell biologists, these studies often include tedious and time-consuming manual segmentation of bacteria and of the fluorescence clusters or working with multiple programs. Here, we present MicroAnalyzer - a tool that automates these tasks by providing an end-to-end platform for microscope image analysis. While such tools do exist, they are costly, black-boxed programs. Microanalyzer offers an open-source alternative to these tools, allowing flexibility and expandability by advanced users. MicroAnalyzer provides accurate cell and fluorescence cluster segmentation based on state-of-the-art deep-learning segmentation models, combined with ad-hoc post-processing and Colicoords - an open-source cell image analysis tool for calculating general cell and fluorescence measurements. Using these methods, it performs better than generic approaches since the dynamic nature of neural networks allows for a quick adaptation to experiment restrictions and assumptions. Other existing tools do not consider experiment assumptions, nor do they provide fluorescence cluster detection without the need for any specialized equipment. The key goal of MicroAnalyzer is to automate the entire process of cell and fluorescence image analysis "from microscope to database", meaning it does not require any further input from the researcher except for the initial deep-learning model training. In this fashion, it allows the researchers to concentrate on the bigger picture instead of granular, eye-straining labor
Algorithm Based on One Monocular Video Delivers Highly Valid and Reliable Gait Parameters
Sep 08, 2020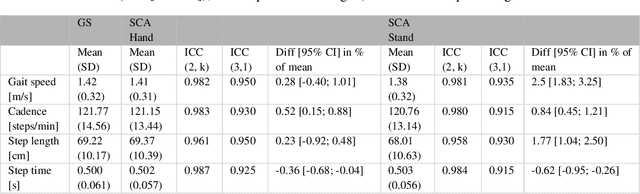
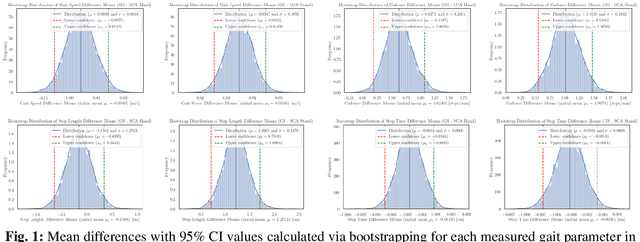
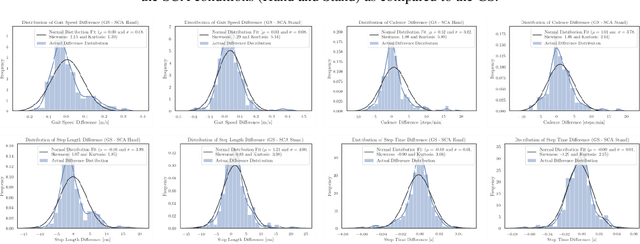
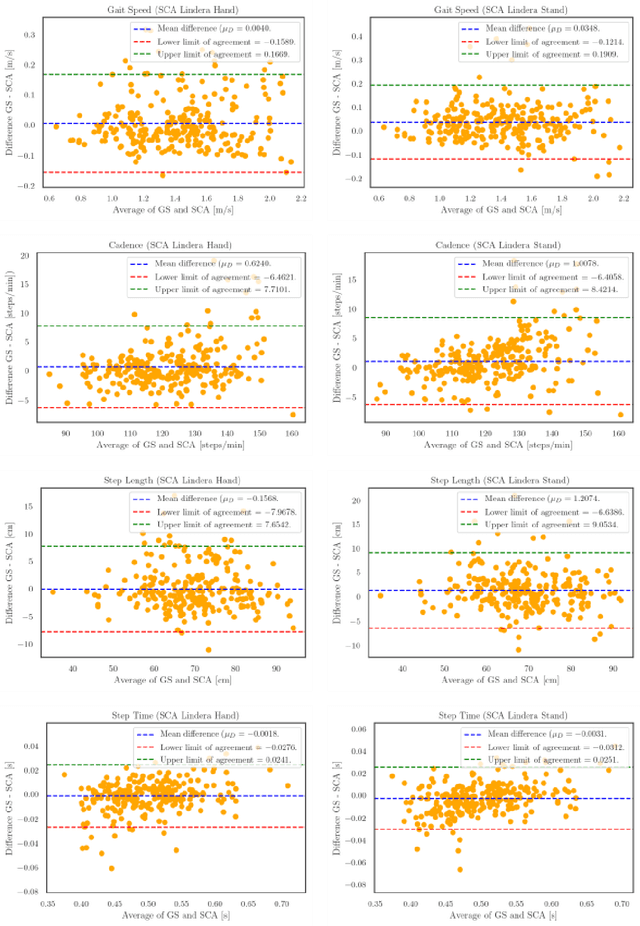
Despite its paramount importance for manifold use cases (e.g., in the health care industry, sports, rehabilitation and fitness assessment), sufficiently valid and reliable gait parameter measurement is still limited to high-tech gait laboratories in large clinics. Here, we demonstrate the excellent validity and test-retest repeatability of a novel gait assessment system which is built upon modern convolutional neuronal networks to extract three-dimensional skeleton joints from monocular frontal-view videos of walking humans. The validity study is based on a comparison to the GAITRite pressure-sensitive walkway system. All measured gait parameters (gait speed, cadence, step length and step time) showed excellent concurrent validity for multiple walk trials at normal and fast gait speeds. The test-retest-repeatability is on the same level as the GAITRite system. In conclusion, we are convinced that our results can pave the way for cost, space and operationally effective gait analysis in broad mainstream applications. Most sensor-based systems are costly, must be operated by extensively trained personnel (e.g., motion capture systems) or - even if not quite as costly - still possess considerable complexity (e.g. wearable sensors). In contrast, a video sufficient for the assessment method presented here can be obtained by anyone, without much training, via a smartphone camera.