 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Stage Hybrid Federated Learning over Large-Scale Wireless Fog Networks
Aug 30, 2020
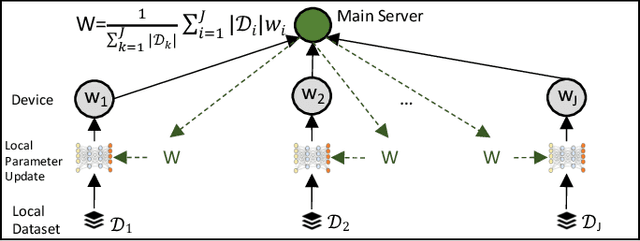
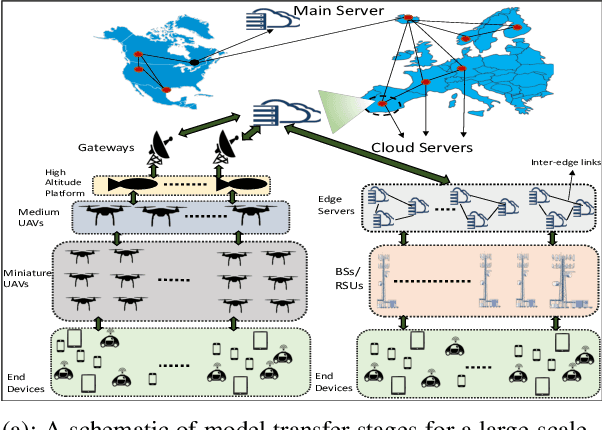
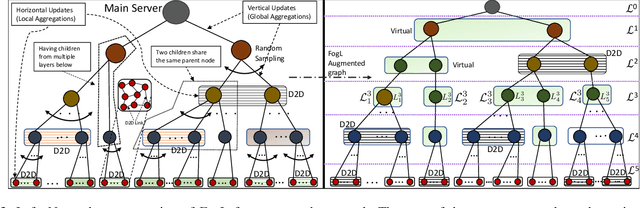
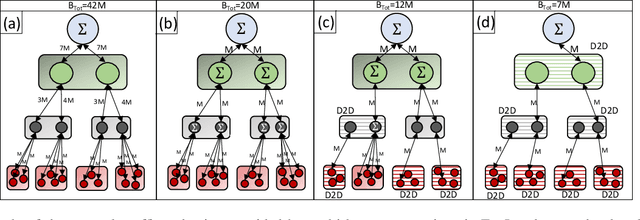
One of the popular methods for distributed machine learning (ML) is federated learning, in which devices train local models based on their datasets, which are in turn aggregated periodically by a server. In large-scale fog networks, the "star" learning topology of federated learning poses several challenges in terms of resource utilization. We develop multi-stage hybrid model training (MH-MT), a novel learning methodology for distributed ML in these scenarios. Leveraging the hierarchical structure of fog systems, MH-MT combines multi-stage parameter relaying with distributed consensus formation among devices in a hybrid learning paradigm across network layers. We theoretically derive the convergence bound of MH-MT with respect to the network topology, ML model, and algorithm parameters such as the rounds of consensus employed in different clusters of devices. We obtain a set of policies for the number of consensus rounds at different clusters to guarantee either a finite optimality gap or convergence to the global optimum. Subsequently, we develop an adaptive distributed control algorithm for MH-MT to tune the number of consensus rounds at each cluster of local devices over time to meet convergence criteria. Our numerical experiments validate the performance of MH-MT in terms of convergence speed and resource utilization.
Data-driven geophysics: from dictionary learning to deep learning
Jul 13, 2020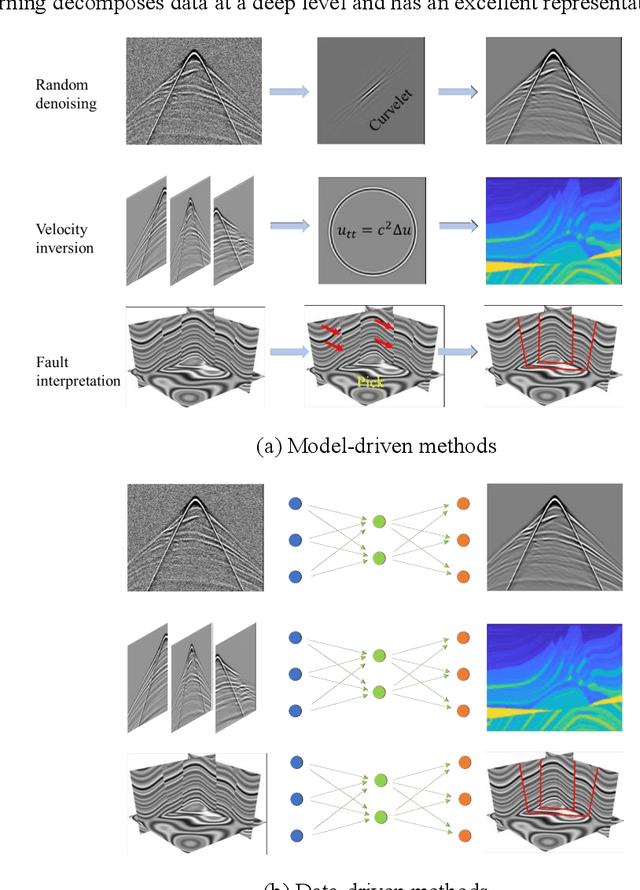

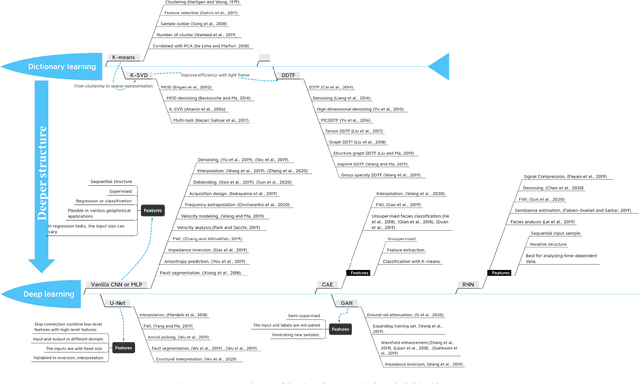
Understanding the principles of geophysical phenomena is an essential and challenging task. Model-driven approaches have supported the development of geophysics for a long time; however, such methods suffer from the curse of dimensionality and may inaccurately model the subsurface. Data-driven techniques may overcome these issues with increasingly available geophysical data. In this article, we review the basic concepts of and recent advances in data-driven approaches from dictionary learning to deep learning in a variety of geophysical scenarios, including seismic and earthquake data processing, inversion, and interpretation. We present a coding tutorial and a summary of tips for beginners and interested geophysical readers to rapidly explore deep learning. Some promising directions are provided for future research involving deep learning in geophysics, such as unsupervised learning, transfer learning, multimodal deep learning, federated learning, uncertainty estimation, and activate learning.
Dynamic backup workers for parallel machine learning
Apr 30, 2020
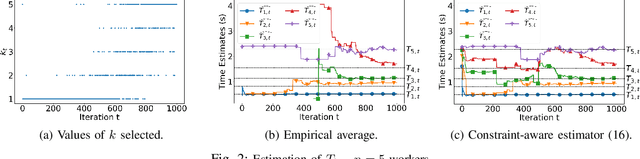
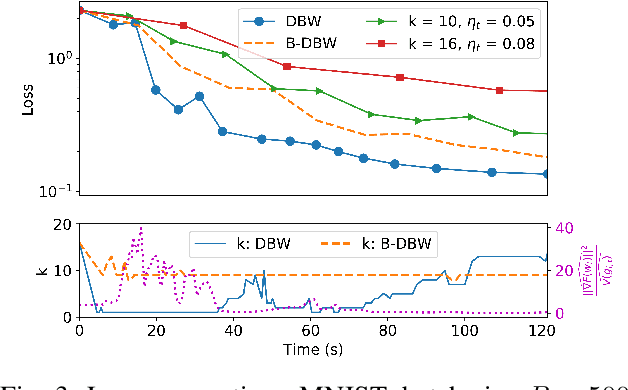
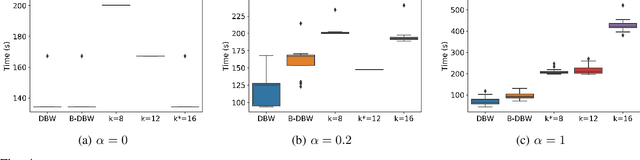
The most popular framework for distributed training of machine learning models is the (synchronous) parameter server (PS). This paradigm consists of $n$ workers, which iteratively compute updates of the model parameters, and a stateful PS, which waits and aggregates all updates to generate a new estimate of model parameters and sends it back to the workers for a new iteration. Transient computation slowdowns or transmission delays can intolerably lengthen the time of each iteration. An efficient way to mitigate this problem is to let the PS wait only for the fastest $n-b$ updates, before generating the new parameters. The slowest $b$ workers are called backup workers. The optimal number $b$ of backup workers depends on the cluster configuration and workload, but also (as we show in this paper) on the hyper-parameters of the learning algorithm and the current stage of the training. We propose DBW, an algorithm that dynamically decides the number of backup workers during the training process to maximize the convergence speed at each iteration. Our experiments show that DBW 1) removes the necessity to tune $b$ by preliminary time-consuming experiments, and 2) makes the training up to a factor $3$ faster than the optimal static configuration.
Cross-Utterance Language Models with Acoustic Error Sampling
Aug 19, 2020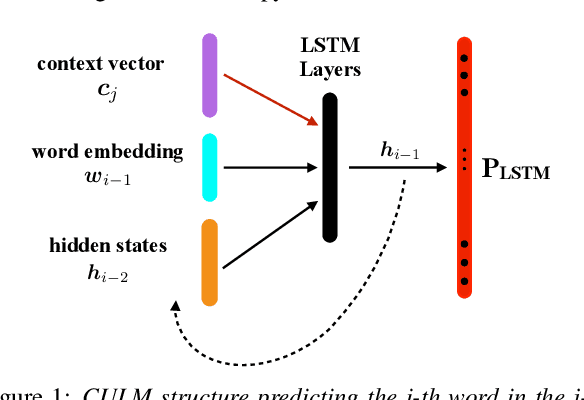
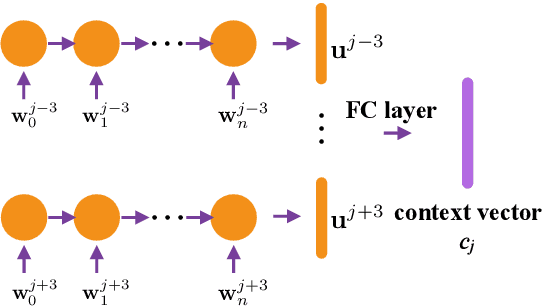
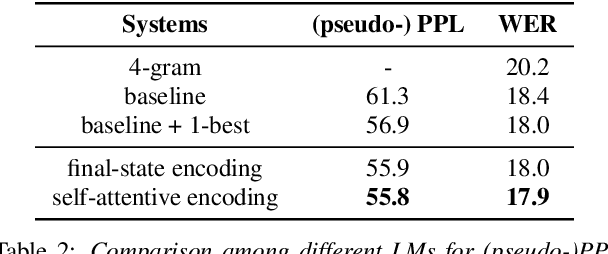
The effective exploitation of richer contextual information in language models (LMs) is a long-standing research problem for automatic speech recognition (ASR). A cross-utterance LM (CULM) is proposed in this paper, which augments the input to a standard long short-term memory (LSTM) LM with a context vector derived from past and future utterances using an extraction network. The extraction network uses another LSTM to encode surrounding utterances into vectors which are integrated into a context vector using either a projection of LSTM final hidden states, or a multi-head self-attentive layer. In addition, an acoustic error sampling technique is proposed to reduce the mismatch between training and test-time. This is achieved by considering possible ASR errors into the model training procedure, and can therefore improve the word error rate (WER). Experiments performed on both AMI and Switchboard datasets show that CULMs outperform the LSTM LM baseline WER. In particular, the CULM with a self-attentive layer-based extraction network and acoustic error sampling achieves 0.6% absolute WER reduction on AMI, 0.3% WER reduction on the Switchboard part and 0.9% WER reduction on the Callhome part of Eval2000 test set over the respective baselines.
Efficient Generation of Structured Objects with Constrained Adversarial Networks
Jul 26, 2020


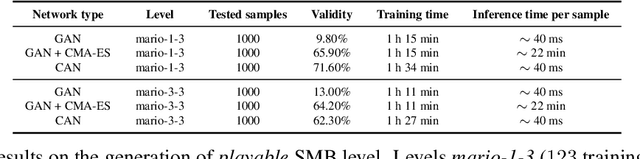
Generative Adversarial Networks (GANs) struggle to generate structured objects like molecules and game maps. The issue is that structured objects must satisfy hard requirements (e.g., molecules must be chemically valid) that are difficult to acquire from examples alone. As a remedy, we propose Constrained Adversarial Networks (CANs), an extension of GANs in which the constraints are embedded into the model during training. This is achieved by penalizing the generator proportionally to the mass it allocates to invalid structures. In contrast to other generative models, CANs support efficient inference of valid structures (with high probability) and allows to turn on and off the learned constraints at inference time. CANs handle arbitrary logical constraints and leverage knowledge compilation techniques to efficiently evaluate the disagreement between the model and the constraints. Our setup is further extended to hybrid logical-neural constraints for capturing very complex constraints, like graph reachability. An extensive empirical analysis shows that CANs efficiently generate valid structures that are both high-quality and novel.
ECG Beats Fast Classification Base on Sparse Dictionaries
Sep 08, 2020
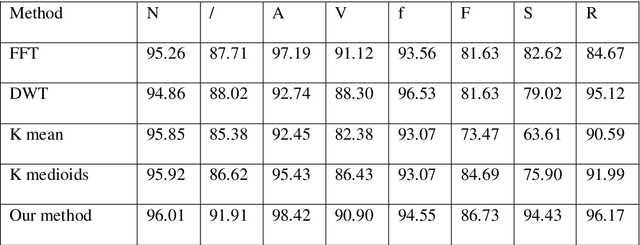

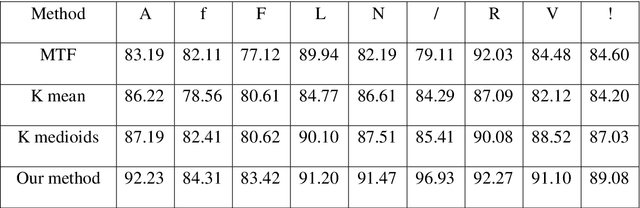
Feature extraction plays an important role in Electrocardiogram (ECG) Beats classification system. Compared to other popular methods, VQ method performs well in feature extraction from ECG with advantages of dimensionality reduction. In VQ method, a set of dictionaries corresponding to segments of ECG beats is trained, and VQ codes are used to represent each heartbeat. However, in practice, VQ codes optimized by k-means or k-means++ exist large quantization errors, which results in VQ codes for two heartbeats of the same type being very different. So the essential differences between different types of heartbeats cannot be representative well. On the other hand, VQ uses too much data during codebook construction, which limits the speed of dictionary learning. In this paper, we propose a new method to improve the speed and accuracy of VQ method. To reduce the computation of codebook construction, a set of sparse dictionaries corresponding to wave segments of ECG beats is constructed. After initialized, sparse dictionaries are updated efficiently by Feature-sign and Lagrange dual algorithm. Based on those dictionaries, a set of codes can be computed to represent original ECG beats.Experimental results show that features extracted from ECG by our method are more efficient and separable. The accuracy of our method is higher than other methods with less time consumption of feature extraction
Human Body Model Fitting by Learned Gradient Descent
Aug 19, 2020
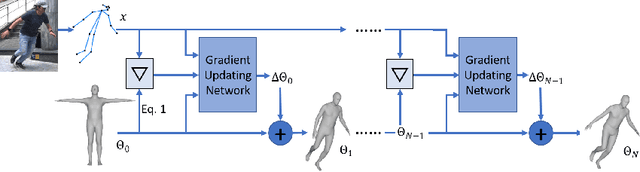
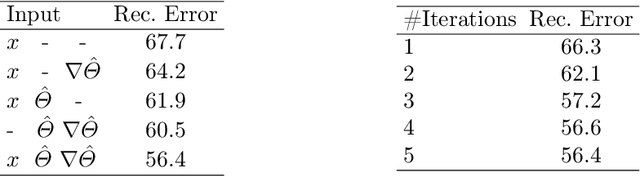
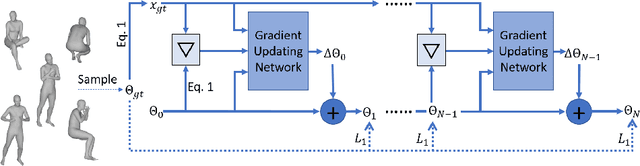
We propose a novel algorithm for the fitting of 3D human shape to images. Combining the accuracy and refinement capabilities of iterative gradient-based optimization techniques with the robustness of deep neural networks, we propose a gradient descent algorithm that leverages a neural network to predict the parameter update rule for each iteration. This per-parameter and state-aware update guides the optimizer towards a good solution in very few steps, converging in typically few steps. During training our approach only requires MoCap data of human poses, parametrized via SMPL. From this data the network learns a subspace of valid poses and shapes in which optimization is performed much more efficiently. The approach does not require any hard to acquire image-to-3D correspondences. At test time we only optimize the 2D joint re-projection error without the need for any further priors or regularization terms. We show empirically that this algorithm is fast (avg. 120ms convergence), robust to initialization and dataset, and achieves state-of-the-art results on public evaluation datasets including the challenging 3DPW in-the-wild benchmark (improvement over SMPLify 45%) and also approaches using image-to-3D correspondences
Enhancing the Interpretability of Deep Models in Heathcare Through Attention: Application to Glucose Forecasting for Diabetic People
Sep 08, 2020



The adoption of deep learning in healthcare is hindered by their "black box" nature. In this paper, we explore the RETAIN architecture for the task of glusose forecasting for diabetic people. By using a two-level attention mechanism, the recurrent-neural-network-based RETAIN model is interpretable. We evaluate the RETAIN model on the type-2 IDIAB and the type-1 OhioT1DM datasets by comparing its statistical and clinical performances against two deep models and three models based on decision trees. We show that the RETAIN model offers a very good compromise between accuracy and interpretability, being almost as accurate as the LSTM and FCN models while remaining interpretable. We show the usefulness of its interpretable nature by analyzing the contribution of each variable to the final prediction. It revealed that signal values older than one hour are not used by the RETAIN model for the 30-minutes ahead of time prediction of glucose. Also, we show how the RETAIN model changes its behavior upon the arrival of an event such as carbohydrate intakes or insulin infusions. In particular, it showed that the patient's state before the event is particularily important for the prediction. Overall the RETAIN model, thanks to its interpretability, seems to be a very promissing model for regression or classification tasks in healthcare.
Hardware Architecture Proposal for TEDA algorithm to Data Streaming Anomaly Detection
Mar 08, 2020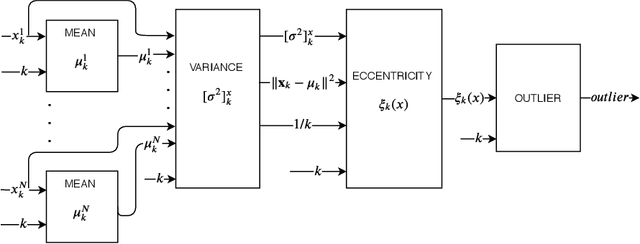

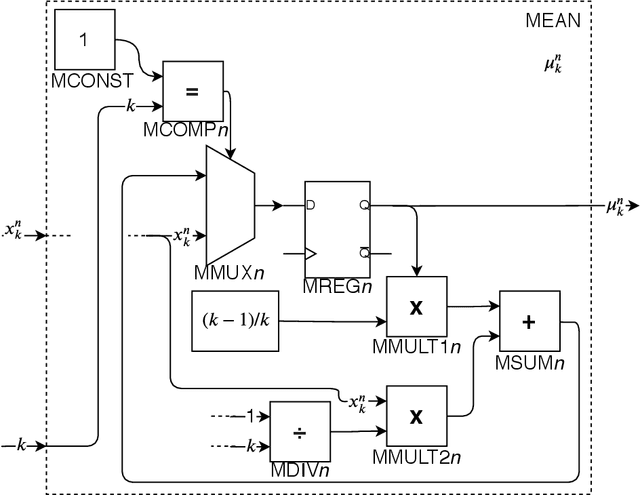
The amount of data in real-time, such as time series and streaming data, available today continues to grow. Being able to analyze this data the moment it arrives can bring an immense added value. However, it also requires a lot of computational effort and new acceleration techniques. As a possible solution to this problem, this paper proposes a hardware architecture for Typicality and Eccentricity Data Analytic (TEDA) algorithm implemented on Field Programmable Gate Arrays (FPGA) for use in data streaming anomaly detection. TEDA is based on a new approach to outlier detection in the data stream context. In order to validate the proposals, results of the occupation and throughput of the proposed hardware are presented. Besides, the bit accurate simulation results are also presented. The project aims to Xilinx Virtex-6 xc6vlx240t-1ff1156 as the target FPGA.
Concave Aspects of Submodular Functions
Jun 27, 2020Submodular Functions are a special class of set functions, which generalize several information-theoretic quantities such as entropy and mutual information [1]. Submodular functions have subgradients and subdifferentials [2] and admit polynomial-time algorithms for minimization, both of which are fundamental characteristics of convex functions. Submodular functions also show signs similar to concavity. Submodular function maximization, though NP-hard, admits constant-factor approximation guarantees, and concave functions composed with modular functions are submodular. In this paper, we try to provide a more complete picture of the relationship between submodularity with concavity. We characterize the super-differentials and polyhedra associated with upper bounds and provide optimality conditions for submodular maximization using the-super differentials. This paper is a concise and shorter version of our longer preprint [3].