 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Learning for Unpaired Image-to-Image Translation
Aug 18, 2020
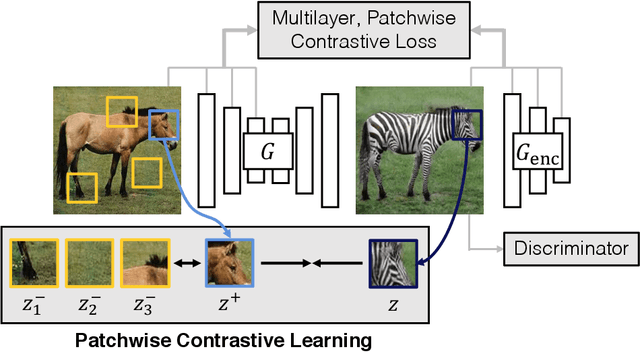
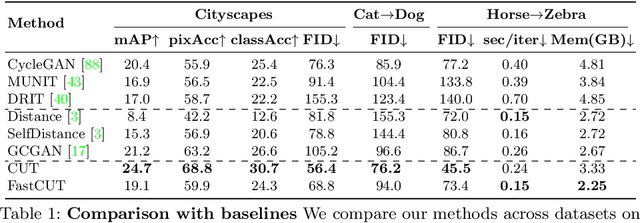
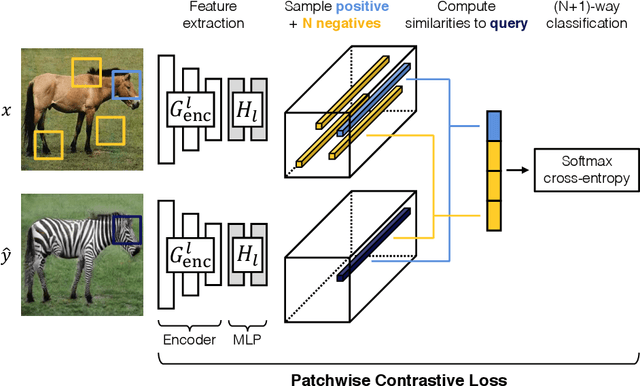
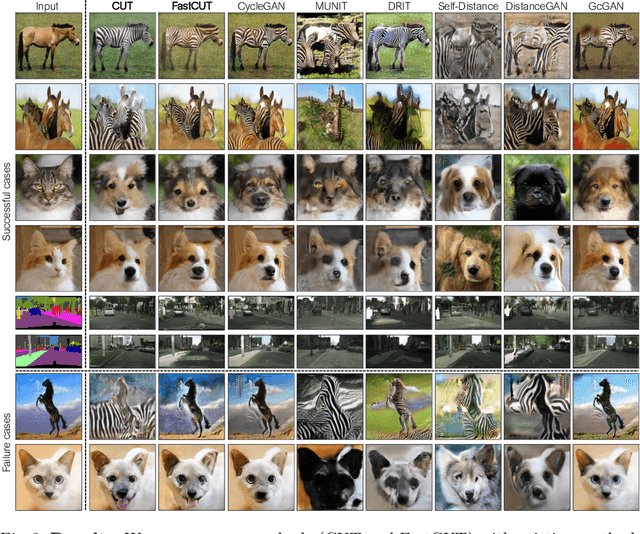
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
Neuro-Endo-Trainer-Online Assessment System (NET-OAS) for Neuro-Endoscopic Skills Training
Jul 16, 2020
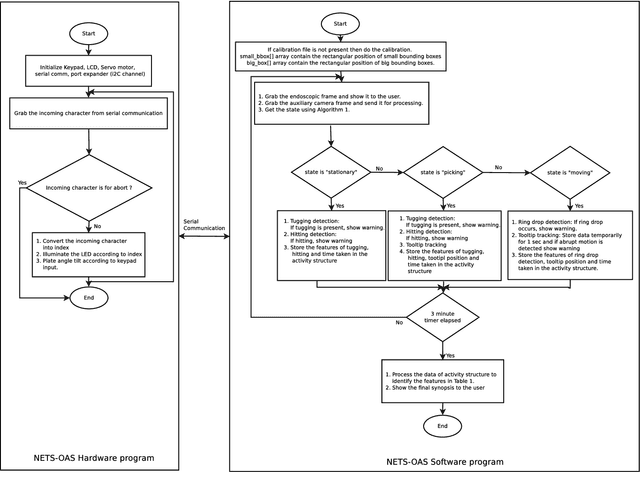
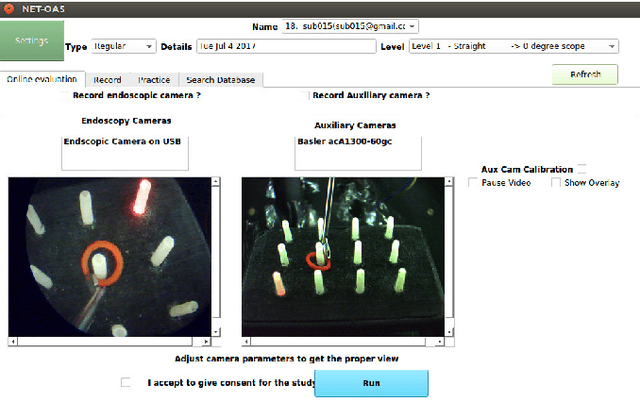
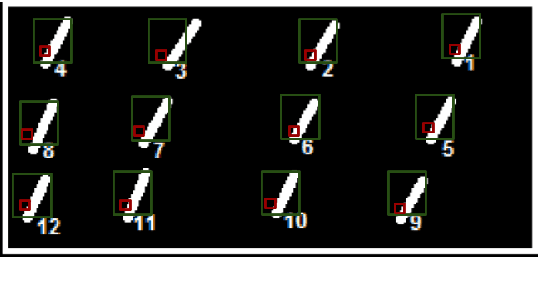
Neuro-endoscopy is a challenging minimally invasive neurosurgery that requires surgical skills to be acquired using training methods different from the existing apprenticeship model. There are various training systems developed for imparting fundamental technical skills in laparoscopy where as limited systems for neuro-endoscopy. Neuro-Endo-Trainer was a box-trainer developed for endo-nasal transsphenoidal surgical skills training with video based offline evaluation system. The objective of the current study was to develop a modified version (Neuro-Endo-Trainer-Online Assessment System (NET-OAS)) by providing a stand-alone system with online evaluation and real-time feedback. The validation study on a group of 15 novice participants shows the improvement in the technical skills for handling the neuro-endoscope and the tool while performing pick and place activity.
* Published at Federated Conference on Computer Science and Information Systems - FedCSIS 2017
Category Level Object Pose Estimation via Neural Analysis-by-Synthesis
Aug 18, 2020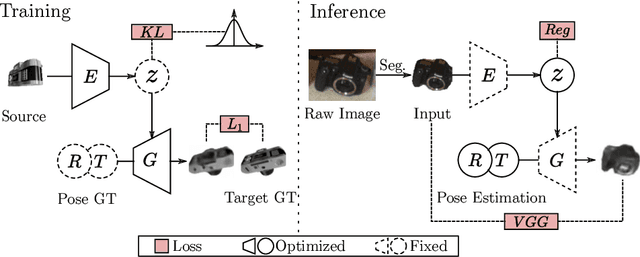

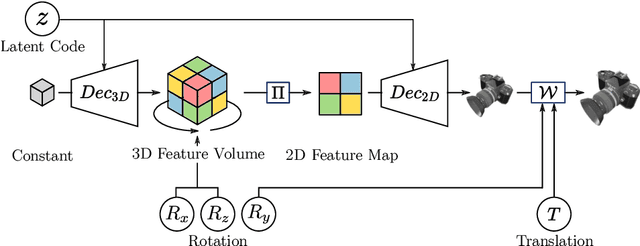
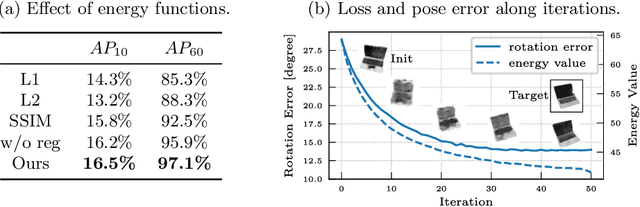
Many object pose estimation algorithms rely on the analysis-by-synthesis framework which requires explicit representations of individual object instances. In this paper we combine a gradient-based fitting procedure with a parametric neural image synthesis module that is capable of implicitly representing the appearance, shape and pose of entire object categories, thus rendering the need for explicit CAD models per object instance unnecessary. The image synthesis network is designed to efficiently span the pose configuration space so that model capacity can be used to capture the shape and local appearance (i.e., texture) variations jointly. At inference time the synthesized images are compared to the target via an appearance based loss and the error signal is backpropagated through the network to the input parameters. Keeping the network parameters fixed, this allows for iterative optimization of the object pose, shape and appearance in a joint manner and we experimentally show that the method can recover orientation of objects with high accuracy from 2D images alone. When provided with depth measurements, to overcome scale ambiguities, the method can accurately recover the full 6DOF pose successfully.
Best Arm Identification for Cascading Bandits in the Fixed Confidence Setting
Jan 24, 2020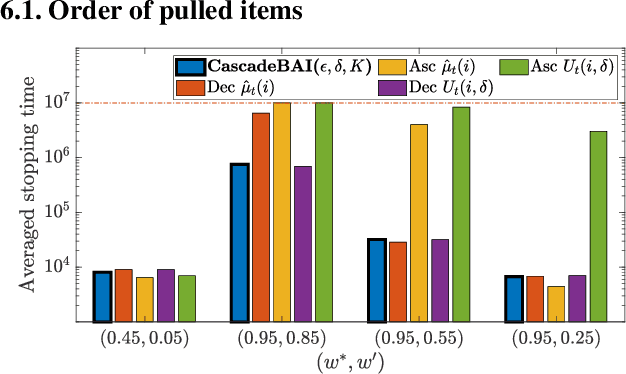

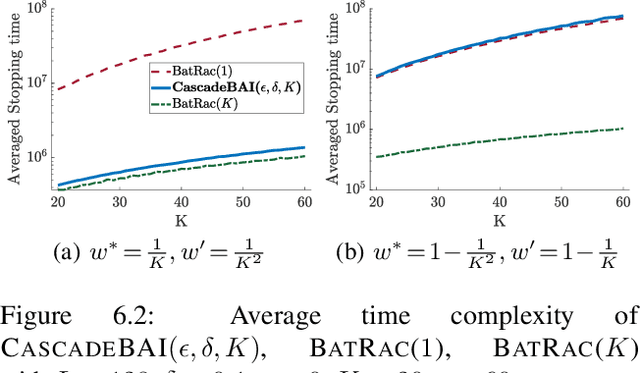
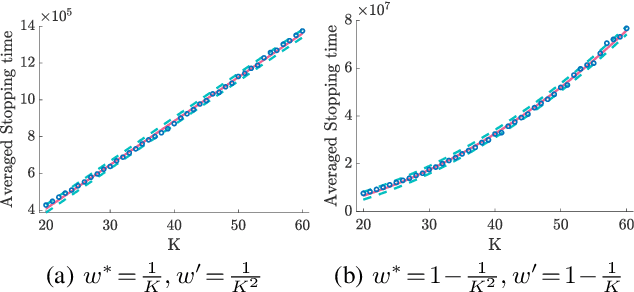
We design and analyze CascadeBAI, an algorithm for finding the best set of $K$ items, also called an arm, within the framework of cascading bandits. An upper bound on the time complexity of CascadeBAI is derived by overcoming a crucial analytical challenge, namely, that of probabilistically estimating the amount of available feedback at each step. To do so, we define a new class of random variables (r.v.'s) which we term as left-sided sub-Gaussian r.v.'s; these are r.v.'s whose cumulant generating functions (CGFs) can be bounded by a quadratic only for non-positive arguments of the CGFs. This enables the application of a sufficiently tight Bernstein-type concentration inequality. We show, through the derivation of a lower bound on the time complexity, that the performance of CascadeBAI is optimal in some practical regimes. Finally, extensive numerical simulations corroborate the efficacy of CascadeBAI as well as the tightness of our upper bound on its time complexity.
A Genetic Algorithm for Obtaining Memory Constrained Near-Perfect Hashing
Jul 16, 2020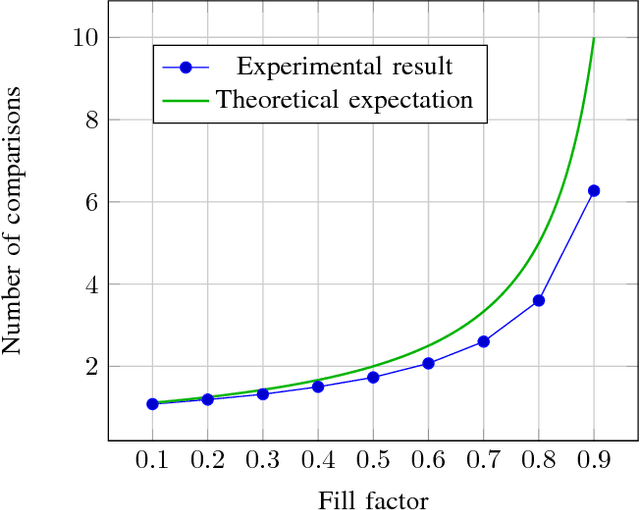
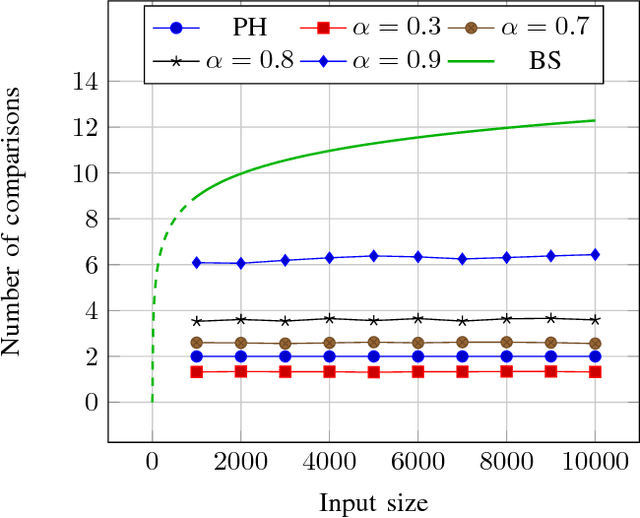
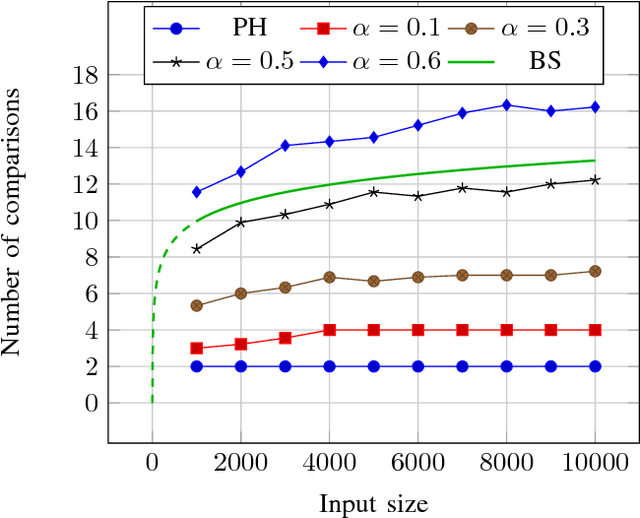
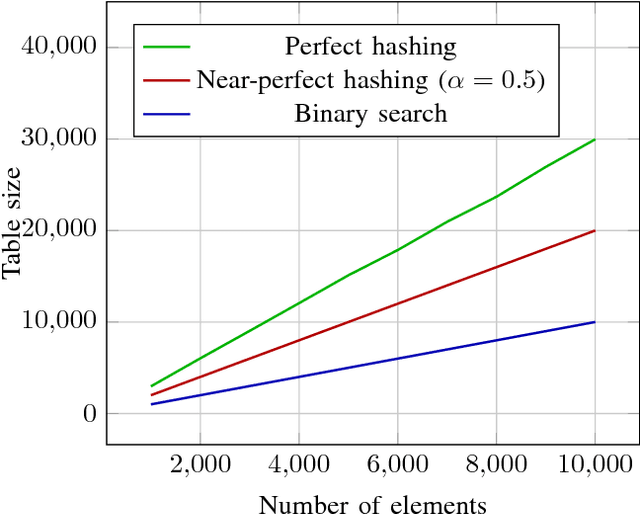
The problem of fast items retrieval from a fixed collection is often encountered in most computer science areas, from operating system components to databases and user interfaces. We present an approach based on hash tables that focuses on both minimizing the number of comparisons performed during the search and minimizing the total collection size. The standard open-addressing double-hashing approach is improved with a non-linear transformation that can be parametrized in order to ensure a uniform distribution of the data in the hash table. The optimal parameter is determined using a genetic algorithm. The paper results show that near-perfect hashing is faster than binary search, yet uses less memory than perfect hashing, being a good choice for memory-constrained applications where search time is also critical.
ReLeaSER: A Reinforcement Learning Strategy for Optimizing Utilization Of Ephemeral Cloud Resources
Oct 05, 2020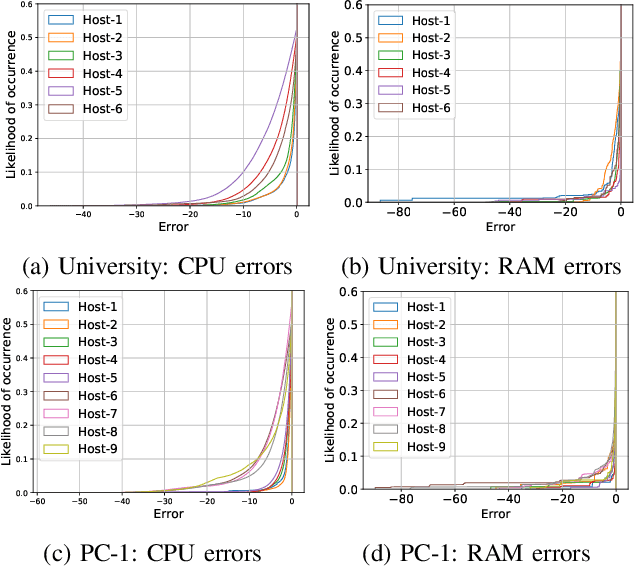
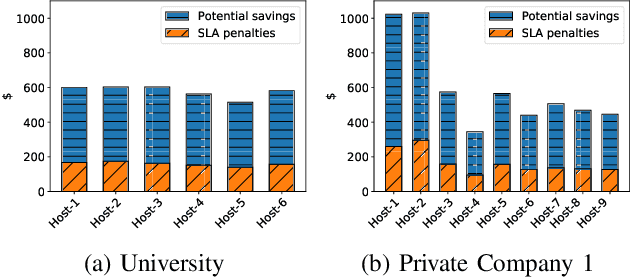
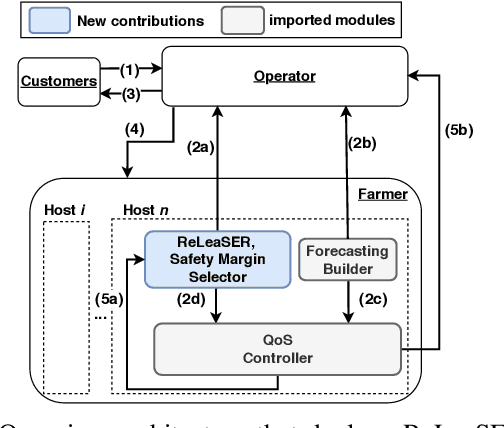
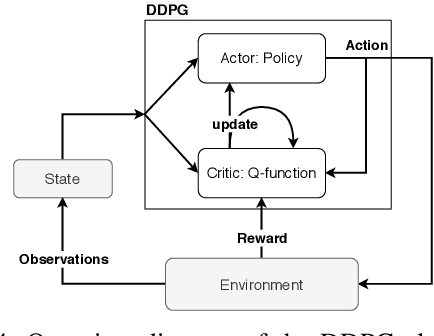
Cloud data center capacities are over-provisioned to handle demand peaks and hardware failures which leads to low resources' utilization. One way to improve resource utilization and thus reduce the total cost of ownership is to offer the unused resources at a lower price. However, reselling resources needs to meet the expectations of its customers in terms of Quality of Service. The goal is so to maximize the amount of reclaimed resources while avoiding SLA penalties. To achieve that, cloud providers have to estimate their future utilization to provide availability guarantees. The prediction should consider a safety margin of resources to react to unpredictable workloads. The challenge is to find the safety margin that provides the best trade-off between the amount of resources to reclaim and the risk of SLA violations. Most state-of-the-art solutions consider a fixed safety margin for all types of metrics (e.g., CPU, RAM). However, a unique fixed margin does not consider various workloads variations over time which may lead to SLA violations or/and poor utilization. In order to tackle these challenges, we propose ReLeaSER, a Reinforcement Learning strategy for optimizing the ephemeral resources' utilization in the cloud. ReLeaSER dynamically tunes the safety margin at the host-level for each resource metric. The strategy learns from past prediction errors (that caused SLA violations). Our solution reduces significantly the SLA violation penalties on average by 2.7x and up to 3.4x. It also improves considerably the CPs' potential savings by 27.6% on average and up to 43.6%.
AB3DMOT: A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics
Aug 18, 2020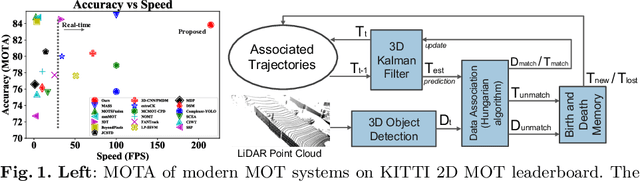
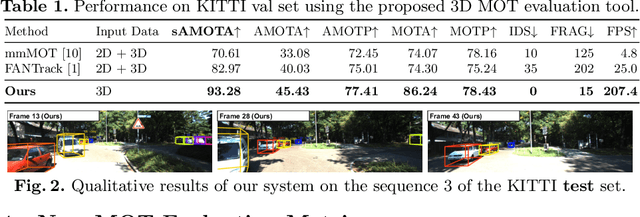
3D multi-object tracking (MOT) is essential to applications such as autonomous driving. Recent work focuses on developing accurate systems giving less attention to computational cost and system complexity. In contrast, this work proposes a simple real-time 3D MOT system with strong performance. Our system first obtains 3D detections from a LiDAR point cloud. Then, a straightforward combination of a 3D Kalman filter and the Hungarian algorithm is used for state estimation and data association. Additionally, 3D MOT datasets such as KITTI evaluate MOT methods in 2D space and standardized 3D MOT evaluation tools are missing for a fair comparison of 3D MOT methods. We propose a new 3D MOT evaluation tool along with three new metrics to comprehensively evaluate 3D MOT methods. We show that, our proposed method achieves strong 3D MOT performance on KITTI and runs at a rate of $207.4$ FPS on the KITTI dataset, achieving the fastest speed among modern 3D MOT systems. Our code is publicly available at http://www.xinshuoweng.com/projects/AB3DMOT.
Delay-aware Resource Allocation in Fog-assisted IoT Networks Through Reinforcement Learning
Apr 30, 2020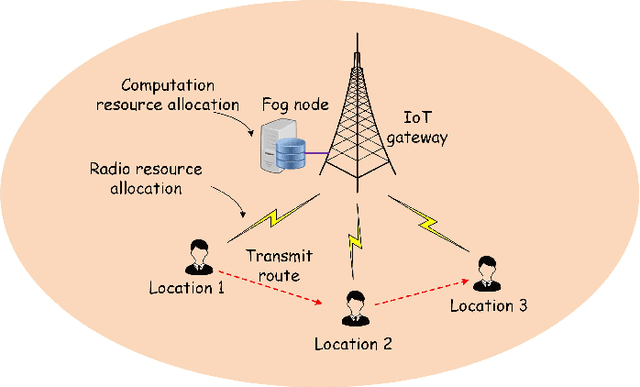
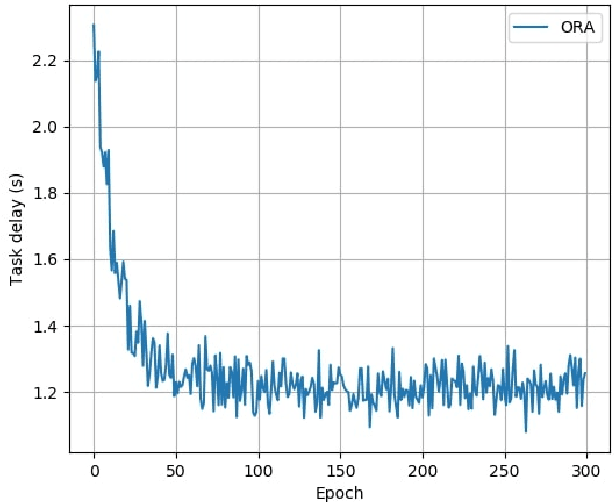
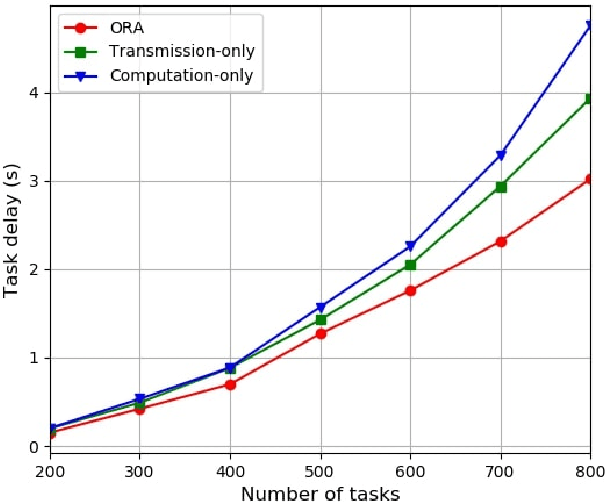
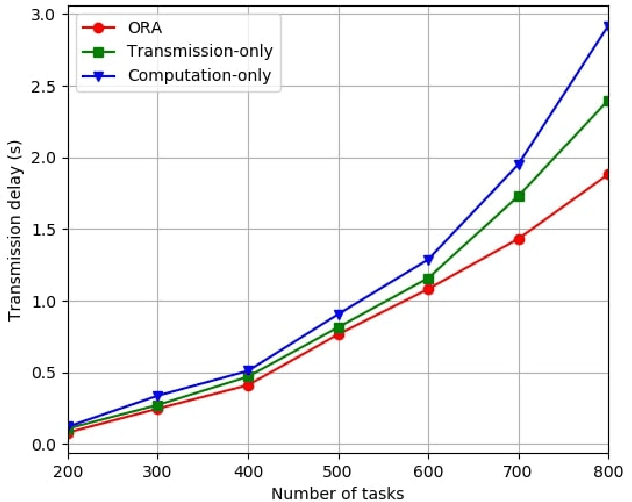
Fog nodes in the vicinity of IoT devices are promising to provision low latency services by offloading tasks from IoT devices to them. Mobile IoT is composed by mobile IoT devices such as vehicles, wearable devices and smartphones. Owing to the time-varying channel conditions, traffic loads and computing loads, it is challenging to improve the quality of service (QoS) of mobile IoT devices. As task delay consists of both the transmission delay and computing delay, we investigate the resource allocation (i.e., including both radio resource and computation resource) in both the wireless channel and fog node to minimize the delay of all tasks while their QoS constraints are satisfied. We formulate the resource allocation problem into an integer non-linear problem, where both the radio resource and computation resource are taken into account. As IoT tasks are dynamic, the resource allocation for different tasks are coupled with each other and the future information is impractical to be obtained. Therefore, we design an on-line reinforcement learning algorithm to make the sub-optimal decision in real time based on the historical data. The performance of the designed algorithm has been demonstrated by extensive simulation results.
Experimental Review of Neural-based approaches for Network Intrusion Management
Sep 18, 2020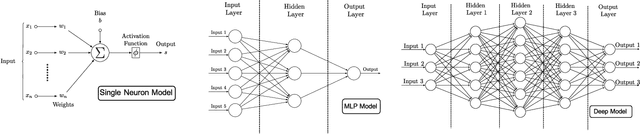
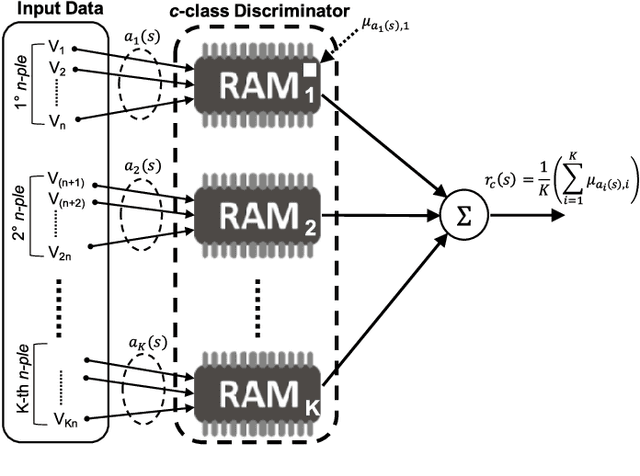
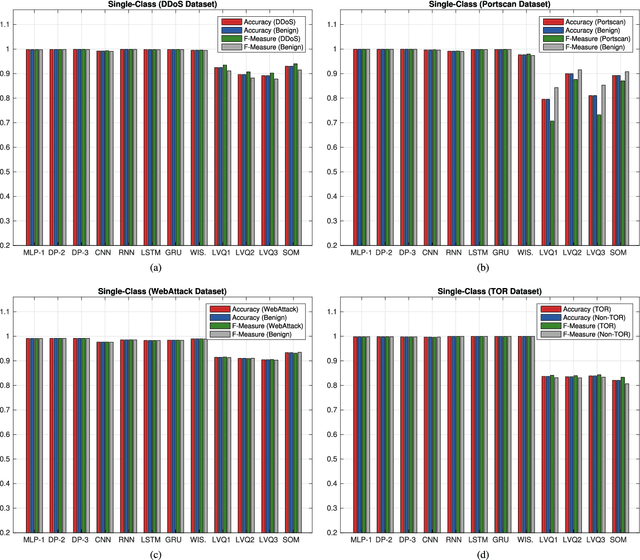
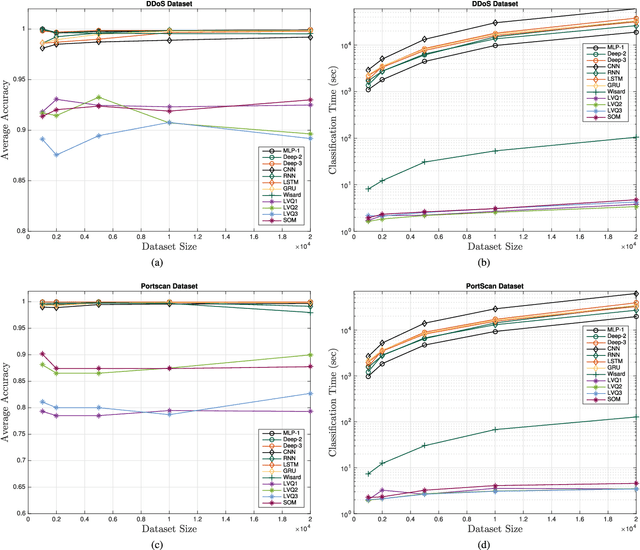
The use of Machine Learning (ML) techniques in Intrusion Detection Systems (IDS) has taken a prominent role in the network security management field, due to the substantial number of sophisticated attacks that often pass undetected through classic IDSs. These are typically aimed at recognising attacks based on a specific signature, or at detecting anomalous events. However, deterministic, rule-based methods often fail to differentiate particular (rarer) network conditions (as in peak traffic during specific network situations) from actual cyber attacks. In this paper we provide an experimental-based review of neural-based methods applied to intrusion detection issues. Specifically, we i) offer a complete view of the most prominent neural-based techniques relevant to intrusion detection, including deep-based approaches or weightless neural networks, which feature surprising outcomes; ii) evaluate novel datasets (updated w.r.t. the obsolete KDD99 set) through a designed-from-scratch Python-based routine; iii) perform experimental analyses including time complexity and performance (accuracy and F-measure), considering both single-class and multi-class problems, and identifying trade-offs between resource consumption and performance. Our evaluation quantifies the value of neural networks, particularly when state-of-the-art datasets are used to train the models. This leads to interesting guidelines for security managers and computer network practitioners who are looking at the incorporation of neural-based ML into IDS.
Comparing Time and Frequency Domain for Audio Event Recognition Using Deep Learning
Mar 18, 2016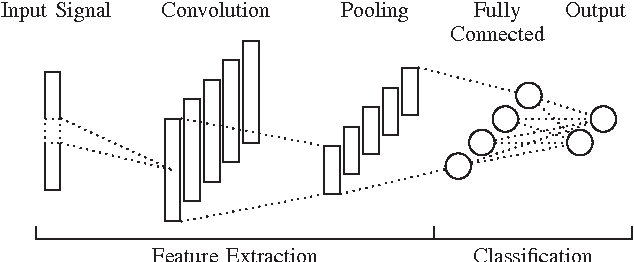
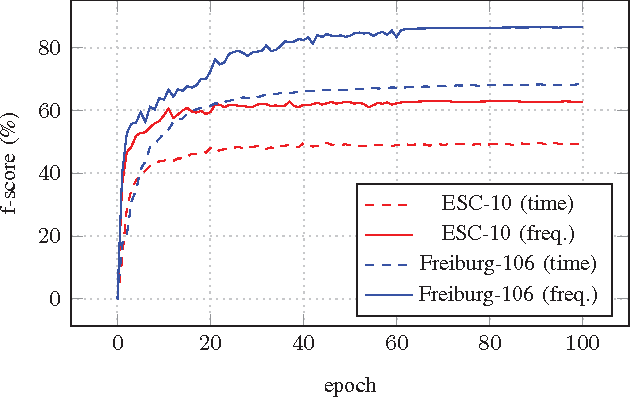
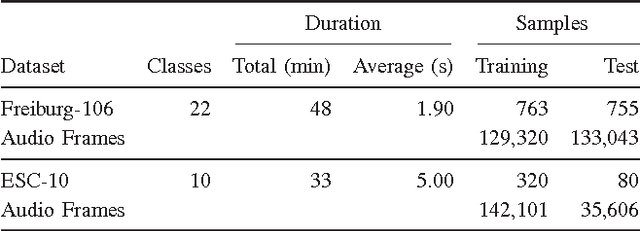
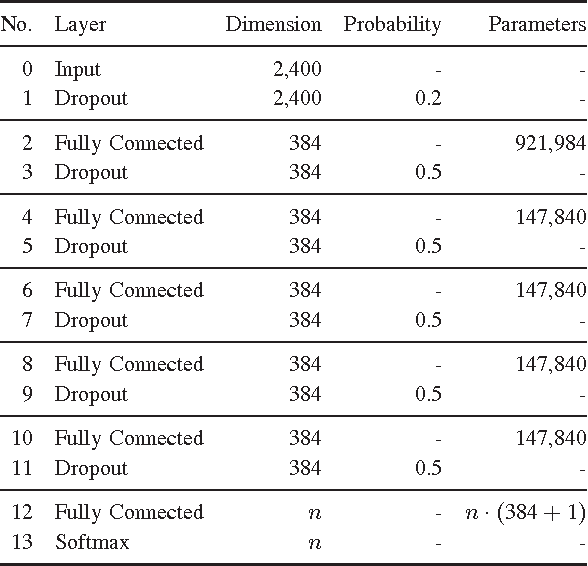
Recognizing acoustic events is an intricate problem for a machine and an emerging field of research. Deep neural networks achieve convincing results and are currently the state-of-the-art approach for many tasks. One advantage is their implicit feature learning, opposite to an explicit feature extraction of the input signal. In this work, we analyzed whether more discriminative features can be learned from either the time-domain or the frequency-domain representation of the audio signal. For this purpose, we trained multiple deep networks with different architectures on the Freiburg-106 and ESC-10 datasets. Our results show that feature learning from the frequency domain is superior to the time domain. Moreover, additionally using convolution and pooling layers, to explore local structures of the audio signal, significantly improves the recognition performance and achieves state-of-the-art results.