 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Bipartite Matching
Jun 02, 2020
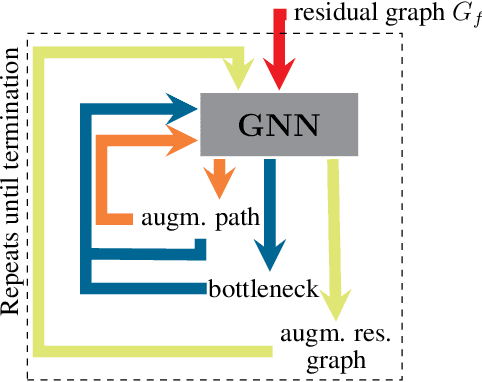

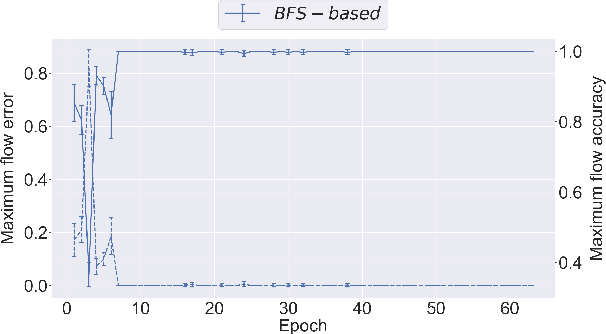
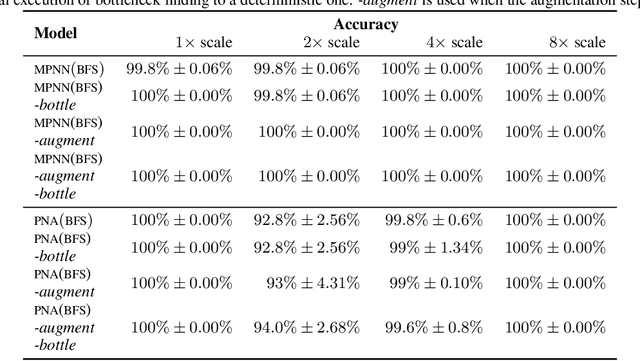
Graph neural networks (GNNs) have found application for learning in the space of algorithms. However, the algorithms chosen by existing research (sorting, Breadth-First search, shortest path finding, etc.) usually align perfectly with a standard GNN architecture. This report describes how neural execution is applied to a complex algorithm, such as finding maximum bipartite matching by reducing it to a flow problem and using Ford-Fulkerson to find the maximum flow. This is achieved via neural execution based only on features generated from a single GNN. The evaluation shows strongly generalising results with the network achieving optimal matching almost 100% of the time.
Controlling Computation versus Quality for Neural Sequence Models
Feb 17, 2020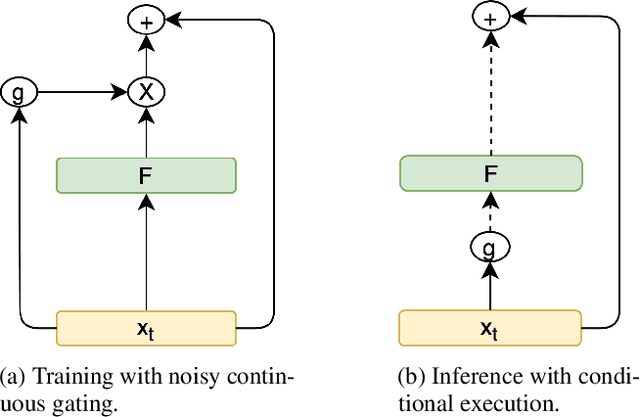
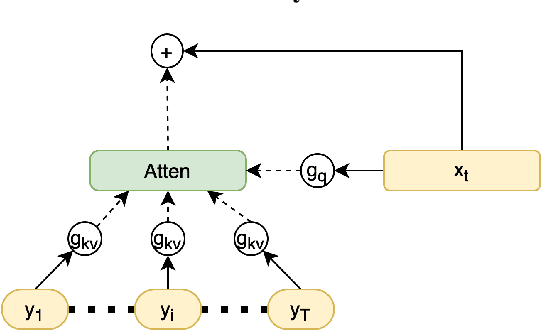
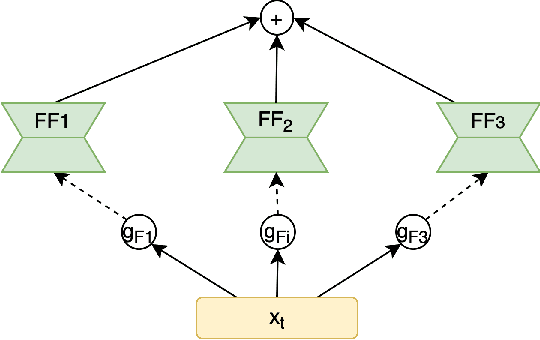
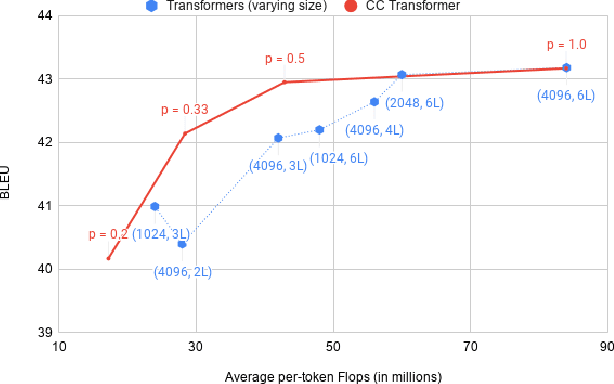
Most neural networks utilize the same amount of compute for every example independent of the inherent complexity of the input. Further, methods that adapt the amount of computation to the example focus on finding a fixed inference-time computational graph per example, ignoring any external computational budgets or varying inference time limitations. In this work, we utilize conditional computation to make neural sequence models (Transformer) more efficient and computation-aware during inference. We first modify the Transformer architecture, making each set of operations conditionally executable depending on the output of a learned control network. We then train this model in a multi-task setting, where each task corresponds to a particular computation budget. This allows us to train a single model that can be controlled to operate on different points of the computation-quality trade-off curve, depending on the available computation budget at inference time. We evaluate our approach on two tasks: (i) WMT English-French Translation and (ii) Unsupervised representation learning (BERT). Our experiments demonstrate that the proposed Conditional Computation Transformer (CCT) is competitive with vanilla Transformers when allowed to utilize its full computational budget, while improving significantly over computationally equivalent baselines when operating on smaller computational budgets.
ECG Beats Fast Classification Base on Sparse Dictionaries
Sep 08, 2020
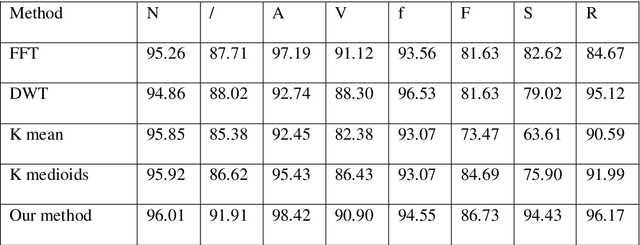

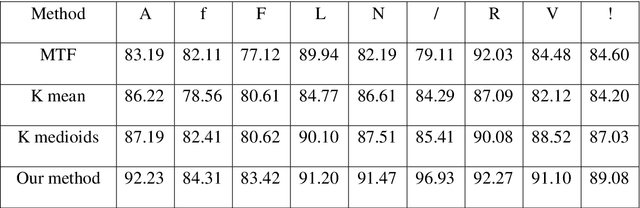
Feature extraction plays an important role in Electrocardiogram (ECG) Beats classification system. Compared to other popular methods, VQ method performs well in feature extraction from ECG with advantages of dimensionality reduction. In VQ method, a set of dictionaries corresponding to segments of ECG beats is trained, and VQ codes are used to represent each heartbeat. However, in practice, VQ codes optimized by k-means or k-means++ exist large quantization errors, which results in VQ codes for two heartbeats of the same type being very different. So the essential differences between different types of heartbeats cannot be representative well. On the other hand, VQ uses too much data during codebook construction, which limits the speed of dictionary learning. In this paper, we propose a new method to improve the speed and accuracy of VQ method. To reduce the computation of codebook construction, a set of sparse dictionaries corresponding to wave segments of ECG beats is constructed. After initialized, sparse dictionaries are updated efficiently by Feature-sign and Lagrange dual algorithm. Based on those dictionaries, a set of codes can be computed to represent original ECG beats.Experimental results show that features extracted from ECG by our method are more efficient and separable. The accuracy of our method is higher than other methods with less time consumption of feature extraction
Cross-Utterance Language Models with Acoustic Error Sampling
Aug 19, 2020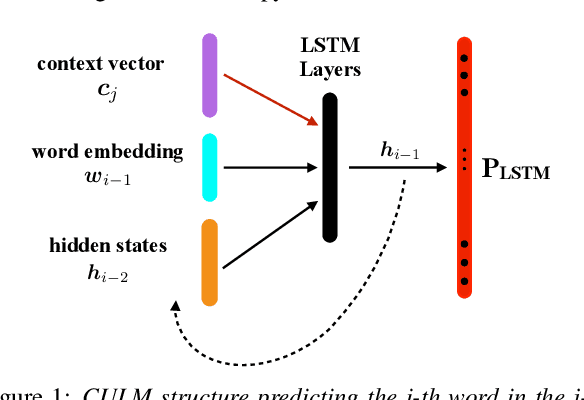
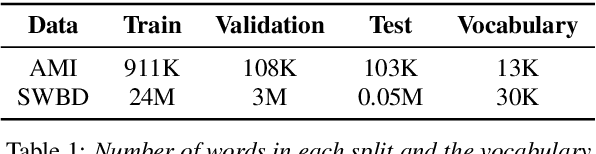
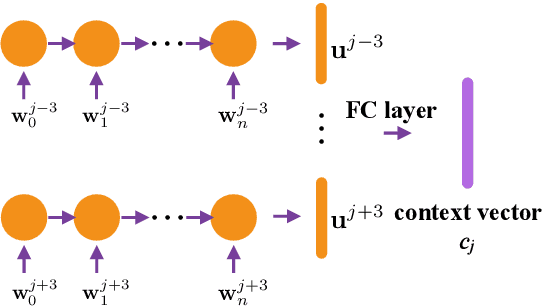
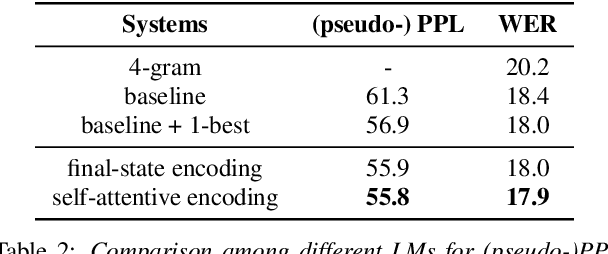
The effective exploitation of richer contextual information in language models (LMs) is a long-standing research problem for automatic speech recognition (ASR). A cross-utterance LM (CULM) is proposed in this paper, which augments the input to a standard long short-term memory (LSTM) LM with a context vector derived from past and future utterances using an extraction network. The extraction network uses another LSTM to encode surrounding utterances into vectors which are integrated into a context vector using either a projection of LSTM final hidden states, or a multi-head self-attentive layer. In addition, an acoustic error sampling technique is proposed to reduce the mismatch between training and test-time. This is achieved by considering possible ASR errors into the model training procedure, and can therefore improve the word error rate (WER). Experiments performed on both AMI and Switchboard datasets show that CULMs outperform the LSTM LM baseline WER. In particular, the CULM with a self-attentive layer-based extraction network and acoustic error sampling achieves 0.6% absolute WER reduction on AMI, 0.3% WER reduction on the Switchboard part and 0.9% WER reduction on the Callhome part of Eval2000 test set over the respective baselines.
Real-time Claim Detection from News Articles and Retrieval of Semantically-Similar Factchecks
Jul 03, 2019
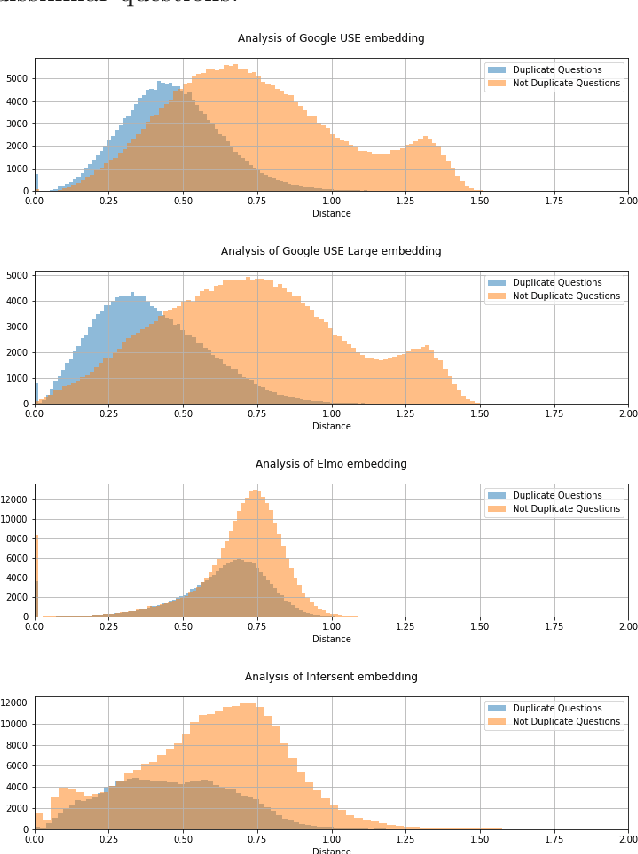
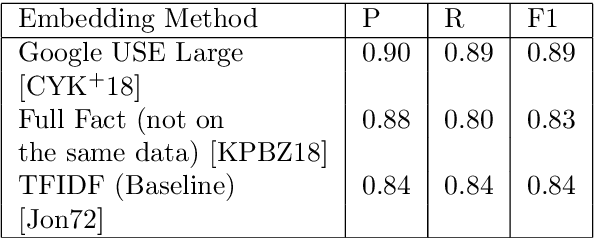
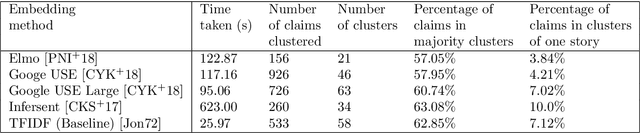
Factchecking has always been a part of the journalistic process. However with newsroom budgets shrinking it is coming under increasing pressure just as the amount of false information circulating is on the rise. We therefore propose a method to increase the efficiency of the factchecking process, using the latest developments in Natural Language Processing (NLP). This method allows us to compare incoming claims to an existing corpus and return similar, factchecked, claims in a live system-allowing factcheckers to work simultaneously without duplicating their work.
Enhancing the Interpretability of Deep Models in Heathcare Through Attention: Application to Glucose Forecasting for Diabetic People
Sep 08, 2020



The adoption of deep learning in healthcare is hindered by their "black box" nature. In this paper, we explore the RETAIN architecture for the task of glusose forecasting for diabetic people. By using a two-level attention mechanism, the recurrent-neural-network-based RETAIN model is interpretable. We evaluate the RETAIN model on the type-2 IDIAB and the type-1 OhioT1DM datasets by comparing its statistical and clinical performances against two deep models and three models based on decision trees. We show that the RETAIN model offers a very good compromise between accuracy and interpretability, being almost as accurate as the LSTM and FCN models while remaining interpretable. We show the usefulness of its interpretable nature by analyzing the contribution of each variable to the final prediction. It revealed that signal values older than one hour are not used by the RETAIN model for the 30-minutes ahead of time prediction of glucose. Also, we show how the RETAIN model changes its behavior upon the arrival of an event such as carbohydrate intakes or insulin infusions. In particular, it showed that the patient's state before the event is particularily important for the prediction. Overall the RETAIN model, thanks to its interpretability, seems to be a very promissing model for regression or classification tasks in healthcare.
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 17, 2020
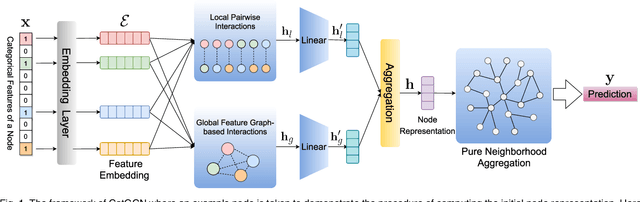
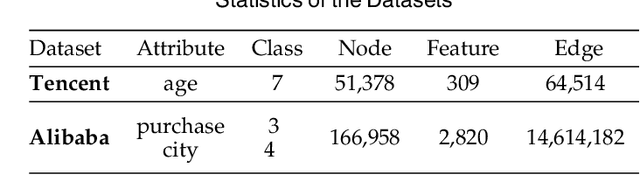
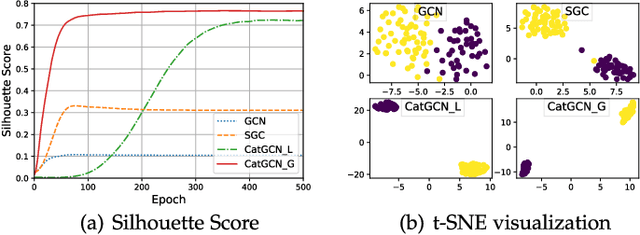
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
Computational Design of Cold Bent Glass Façades
Sep 08, 2020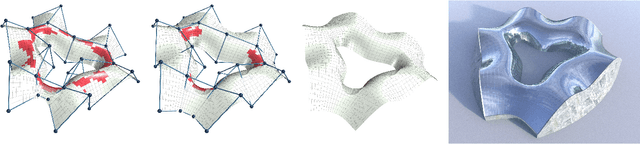


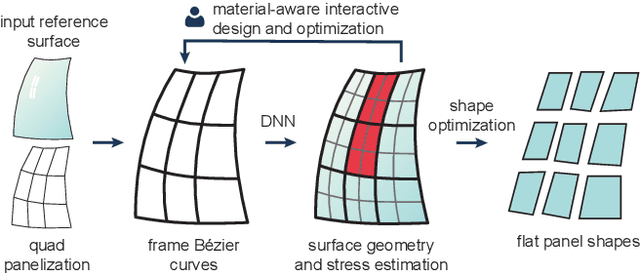
Cold bent glass is a promising and cost-efficient method for realizing doubly curved glass fa\c{c}ades. They are produced by attaching planar glass sheets to curved frames and require keeping the occurring stress within safe limits. However, it is very challenging to navigate the design space of cold bent glass panels due to the fragility of the material, which impedes the form-finding for practically feasible and aesthetically pleasing cold bent glass fa\c{c}ades. We propose an interactive, data-driven approach for designing cold bent glass fa\c{c}ades that can be seamlessly integrated into a typical architectural design pipeline. Our method allows non-expert users to interactively edit a parametric surface while providing real-time feedback on the deformed shape and maximum stress of cold bent glass panels. Designs are automatically refined to minimize several fairness criteria while maximal stresses are kept within glass limits. We achieve interactive frame rates by using a differentiable Mixture Density Network trained from more than a million simulations. Given a curved boundary, our regression model is capable of handling multistable configurations and accurately predicting the equilibrium shape of the panel and its corresponding maximal stress. We show predictions are highly accurate and validate our results with a physical realization of a cold bent glass surface.
Human Body Model Fitting by Learned Gradient Descent
Aug 19, 2020
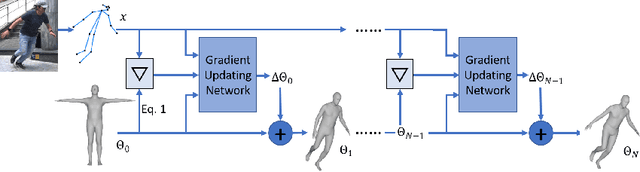
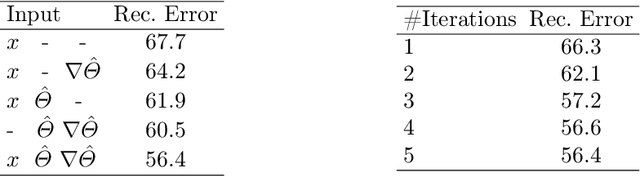
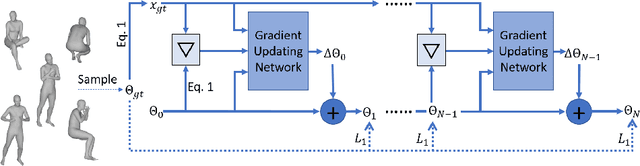
We propose a novel algorithm for the fitting of 3D human shape to images. Combining the accuracy and refinement capabilities of iterative gradient-based optimization techniques with the robustness of deep neural networks, we propose a gradient descent algorithm that leverages a neural network to predict the parameter update rule for each iteration. This per-parameter and state-aware update guides the optimizer towards a good solution in very few steps, converging in typically few steps. During training our approach only requires MoCap data of human poses, parametrized via SMPL. From this data the network learns a subspace of valid poses and shapes in which optimization is performed much more efficiently. The approach does not require any hard to acquire image-to-3D correspondences. At test time we only optimize the 2D joint re-projection error without the need for any further priors or regularization terms. We show empirically that this algorithm is fast (avg. 120ms convergence), robust to initialization and dataset, and achieves state-of-the-art results on public evaluation datasets including the challenging 3DPW in-the-wild benchmark (improvement over SMPLify 45%) and also approaches using image-to-3D correspondences
SenWave: Monitoring the Global Sentiments under the COVID-19 Pandemic
Jun 18, 2020
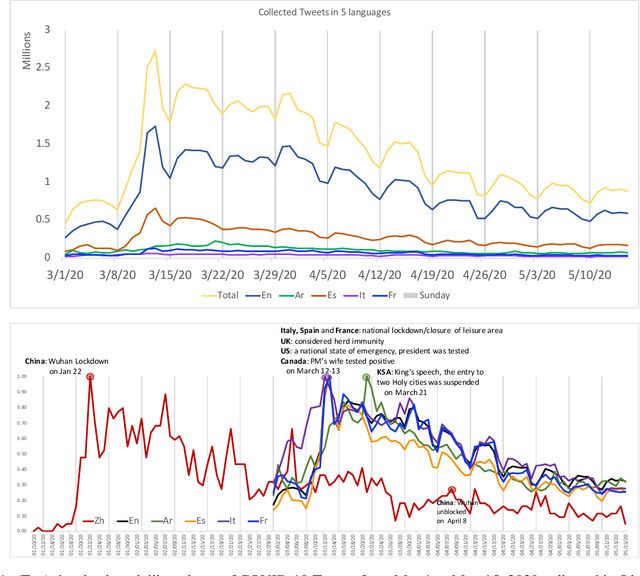
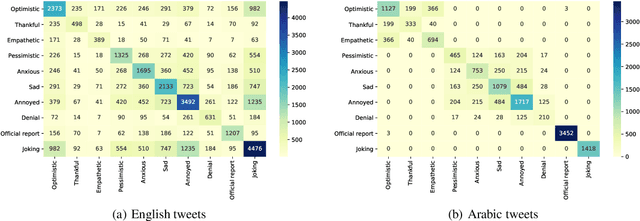

Since the first alert launched by the World Health Organization (5 January, 2020), COVID-19 has been spreading out to over 180 countries and territories. As of June 18, 2020, in total, there are now over 8,400,000 cases and over 450,000 related deaths. This causes massive losses in the economy and jobs globally and confining about 58% of the global population. In this paper, we introduce SenWave, a novel sentimental analysis work using 105+ million collected tweets and Weibo messages to evaluate the global rise and falls of sentiments during the COVID-19 pandemic. To make a fine-grained analysis on the feeling when we face this global health crisis, we annotate 10K tweets in English and 10K tweets in Arabic in 10 categories, including optimistic, thankful, empathetic, pessimistic, anxious, sad, annoyed, denial, official report, and joking. We then utilize an integrated transformer framework, called simpletransformer, to conduct multi-label sentimental classification by fine-tuning the pre-trained language model on the labeled data. Meanwhile, in order for a more complete analysis, we also translate the annotated English tweets into different languages (Spanish, Italian, and French) to generated training data for building sentiment analysis models for these languages. SenWave thus reveals the sentiment of global conversation in six different languages on COVID-19 (covering English, Spanish, French, Italian, Arabic and Chinese), followed the spread of the epidemic. The conversation showed a remarkably similar pattern of rapid rise and slow decline over time across all nations, as well as on special topics like the herd immunity strategies, to which the global conversation reacts strongly negatively. Overall, SenWave shows that optimistic and positive sentiments increased over time, foretelling a desire to seek, together, a reset for an improved COVID-19 world.