 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Fourier State Space Model for Bayesian ODE Filters
Jul 22, 2020
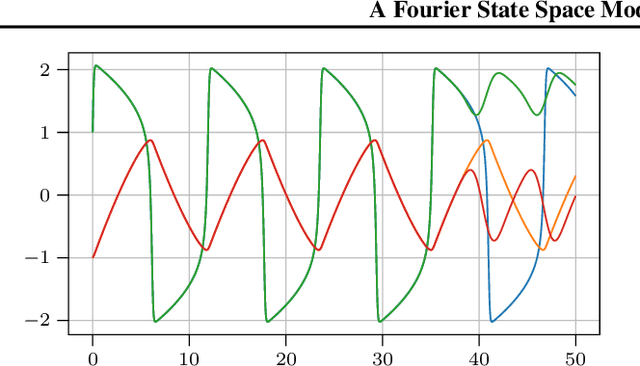
Gaussian ODE filtering is a probabilistic numerical method to solve ordinary differential equations (ODEs). It computes a Bayesian posterior over the solution from evaluations of the vector field defining the ODE. Its most popular version, which employs an integrated Brownian motion prior, uses Taylor expansions of the mean to extrapolate forward and has the same convergence rates as classical numerical methods. As the solution of many important ODEs are periodic functions (oscillators), we raise the question whether Fourier expansions can also be brought to bear within the framework of Gaussian ODE filtering. To this end, we construct a Fourier state space model for ODEs and a `hybrid' model that combines a Taylor (Brownian motion) and Fourier state space model. We show by experiments how the hybrid model might become useful in cheaply predicting until the end of the time domain.
Deep Variational Generative Models for Audio-visual Speech Separation
Aug 17, 2020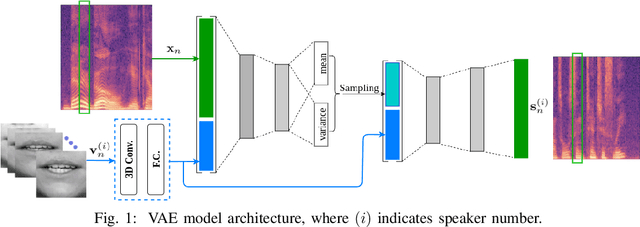
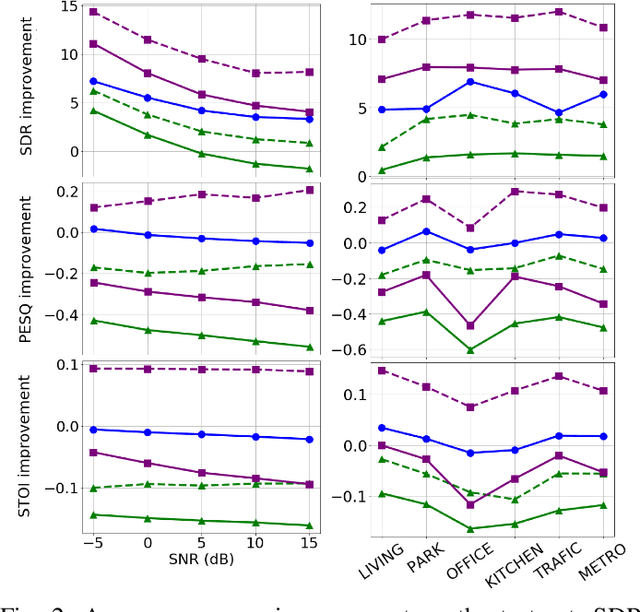
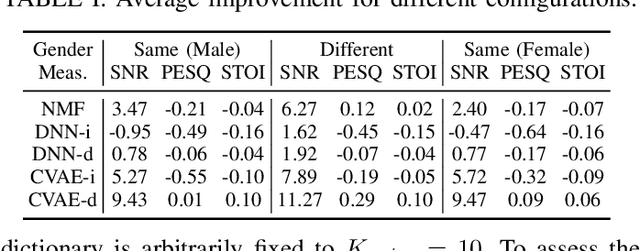
In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background noise. All the latent variables and noise parameters are then estimated by a Monte Carlo expectation-maximization algorithm. Our experiments show that the proposed unsupervised VAE-based method yields better separation performance than NMF-based approaches as well as a supervised deep learning-based technique.
ePointDA: An End-to-End Simulation-to-Real Domain Adaptation Framework for LiDAR Point Cloud Segmentation
Sep 07, 2020
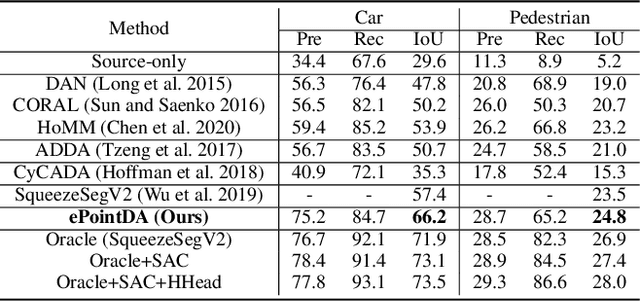
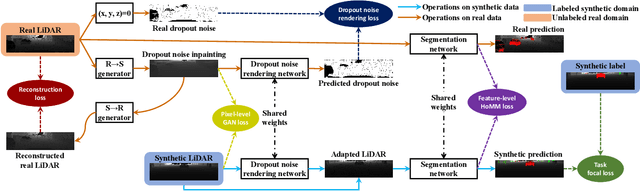
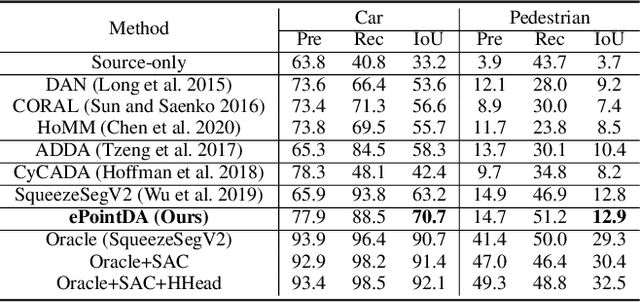
Due to its robust and precise distance measurements, LiDAR plays an important role in scene understanding for autonomous driving. Training deep neural networks (DNNs) on LiDAR data requires large-scale point-wise annotations, which are time-consuming and expensive to obtain. Instead, simulation-to-real domain adaptation (SRDA) trains a DNN using unlimited synthetic data with automatically generated labels and transfers the learned model to real scenarios. Existing SRDA methods for LiDAR point cloud segmentation mainly employ a multi-stage pipeline and focus on feature-level alignment. They require prior knowledge of real-world statistics and ignore the pixel-level dropout noise gap and the spatial feature gap between different domains. In this paper, we propose a novel end-to-end framework, named ePointDA, to address the above issues. Specifically, ePointDA consists of three components: self-supervised dropout noise rendering, statistics-invariant and spatially-adaptive feature alignment, and transferable segmentation learning. The joint optimization enables ePointDA to bridge the domain shift at the pixel-level by explicitly rendering dropout noise for synthetic LiDAR and at the feature-level by spatially aligning the features between different domains, without requiring the real-world statistics. Extensive experiments adapting from synthetic GTA-LiDAR to real KITTI and SemanticKITTI demonstrate the superiority of ePointDA for LiDAR point cloud segmentation.
Local-Global Video-Text Interactions for Temporal Grounding
Apr 16, 2020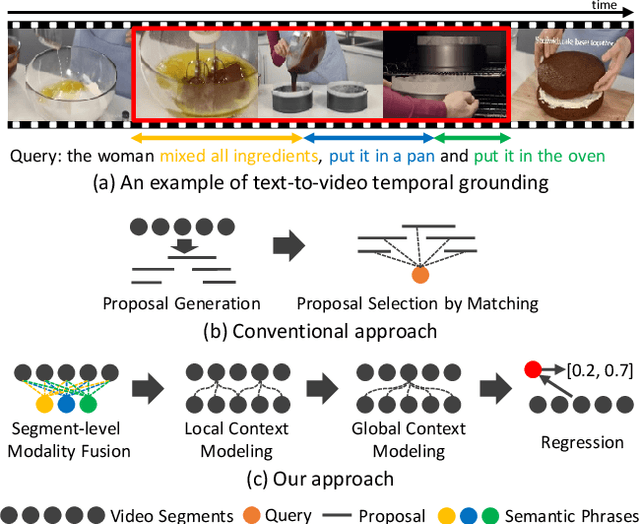
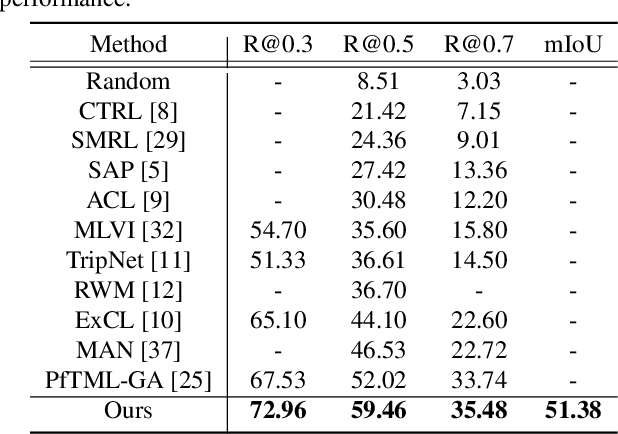
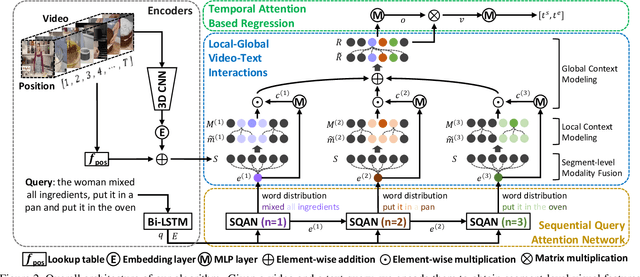
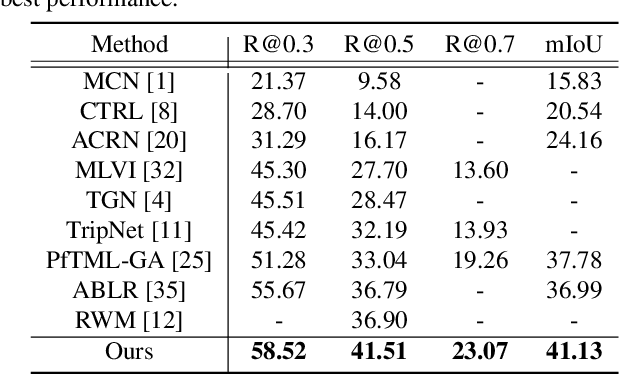
This paper addresses the problem of text-to-video temporal grounding, which aims to identify the time interval in a video semantically relevant to a text query. We tackle this problem using a novel regression-based model that learns to extract a collection of mid-level features for semantic phrases in a text query, which corresponds to important semantic entities described in the query (e.g., actors, objects, and actions), and reflect bi-modal interactions between the linguistic features of the query and the visual features of the video in multiple levels. The proposed method effectively predicts the target time interval by exploiting contextual information from local to global during bi-modal interactions. Through in-depth ablation studies, we find out that incorporating both local and global context in video and text interactions is crucial to the accurate grounding. Our experiment shows that the proposed method outperforms the state of the arts on Charades-STA and ActivityNet Captions datasets by large margins, 7.44\% and 4.61\% points at Recall@tIoU=0.5 metric, respectively. Code is available in https://github.com/JonghwanMun/LGI4temporalgrounding.
Simulating Tariff Impact in Electrical Energy Consumption Profiles with Conditional Variational Autoencoders
Jun 10, 2020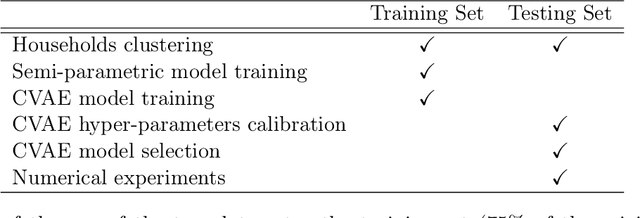


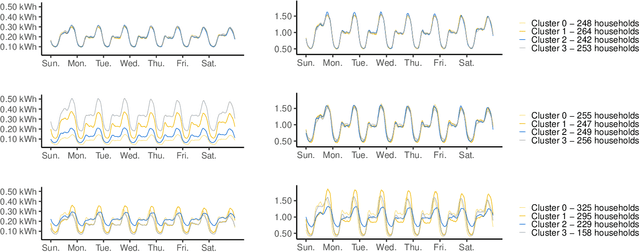
The implementation of efficient demand response (DR) programs for household electricity consumption would benefit from data-driven methods capable of simulating the impact of different tariffs schemes. This paper proposes a novel method based on conditional variational autoencoders (CVAE) to generate, from an electricity tariff profile combined with exogenous weather and calendar variables, daily consumption profiles of consumers segmented in different clusters. First, a large set of consumers is gathered into clusters according to their consumption behavior and price-responsiveness. The clustering method is based on a causality model that measures the effect of a specific tariff on the consumption level. Then, daily electrical energy consumption profiles are generated for each cluster with CVAE. This non-parametric approach is compared to a semi-parametric data generator based on generalized additive models and that uses prior knowledge of energy consumption. Experiments in a publicly available data set show that, the proposed method presents comparable performance to the semi-parametric one when it comes to generating the average value of the original data. The main contribution from this new method is the capacity to reproduce rebound and side effects in the generated consumption profiles. Indeed, the application of a special electricity tariff over a time window may also affect consumption outside this time window. Another contribution is that the clustering approach segments consumers according to their daily consumption profile and elasticity to tariff changes. These two results combined are very relevant for an ex-ante testing of future DR policies by system operators, retailers and energy regulators.
Scaling Up Deep Neural Network Optimization for Edge Inference
Sep 17, 2020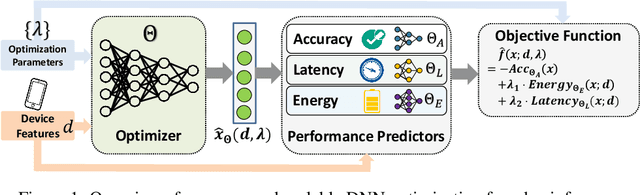
Deep neural networks (DNNs) have been increasingly deployed on and integrated with edge devices, such as mobile phones, drones, robots and wearables. To run DNN inference directly on edge devices (a.k.a. edge inference) with a satisfactory performance, optimizing the DNN design (e.g., network architecture and quantization policy) is crucial. While state-of-the-art DNN designs have leveraged performance predictors to speed up the optimization process, they are device-specific (i.e., each predictor for only one target device) and hence cannot scale well in the presence of extremely diverse edge devices. Moreover, even with performance predictors, the optimizer (e.g., search-based optimization) can still be time-consuming when optimizing DNNs for many different devices. In this work, we propose two approaches to scaling up DNN optimization. In the first approach, we reuse the performance predictors built on a proxy device, and leverage the performance monotonicity to scale up the DNN optimization without re-building performance predictors for each different device. In the second approach, we build scalable performance predictors that can estimate the resulting performance (e.g., inference accuracy/latency/energy) given a DNN-device pair, and use a neural network-based automated optimizer that takes both device features and optimization parameters as input and then directly outputs the optimal DNN design without going through a lengthy optimization process for each individual device.
Revisiting Bounded-Suboptimal Safe Interval Path Planning
Jun 01, 2020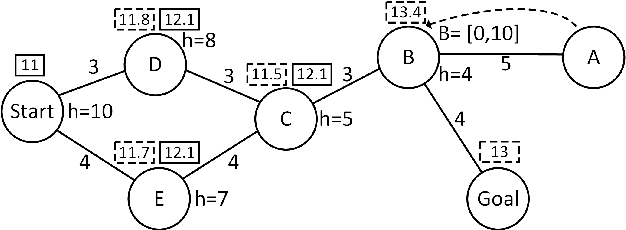
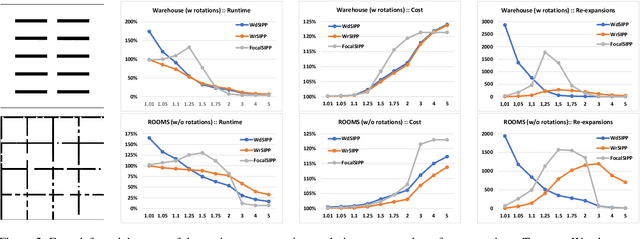
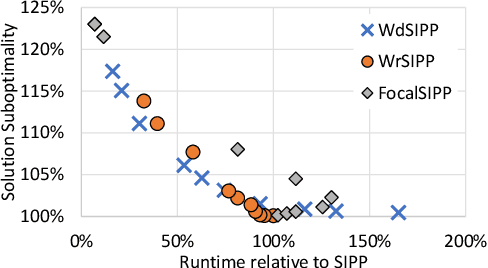
Safe-interval path planning (SIPP) is a powerful algorithm for finding a path in the presence of dynamic obstacles. SIPP returns provably optimal solutions. However, in many practical applications of SIPP such as path planning for robots, one would like to trade-off optimality for shorter planning time. In this paper we explore different ways to build a bounded-suboptimal SIPP and discuss their pros and cons. We compare the different bounded-suboptimal versions of SIPP experimentally. While there is no universal winner, the results provide insights into when each method should be used.
Few-Shot Unsupervised Continual Learning through Meta-Examples
Sep 17, 2020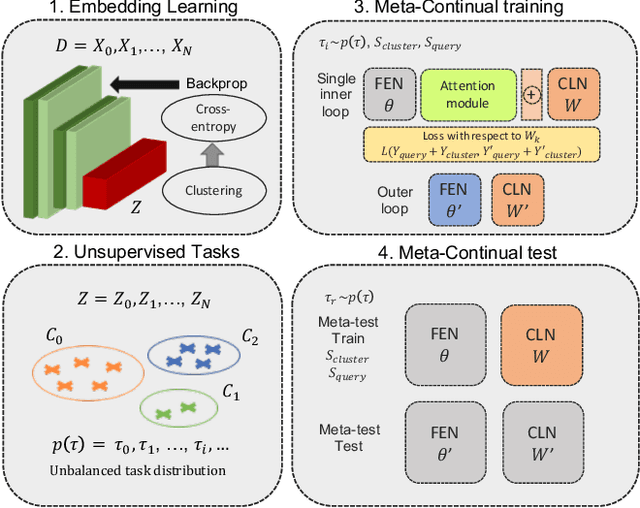
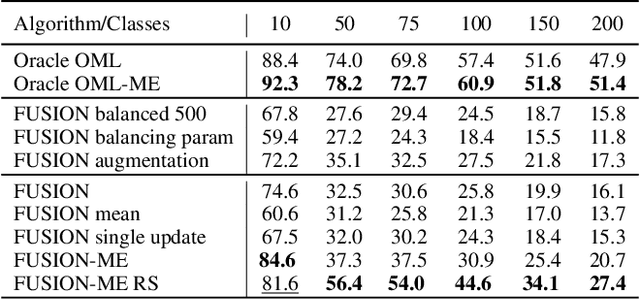
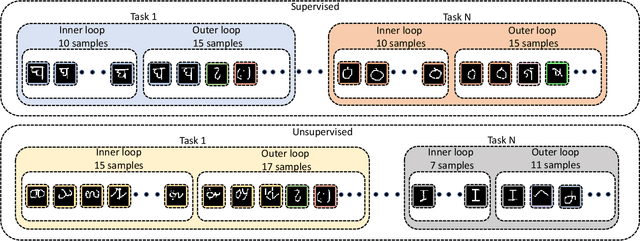
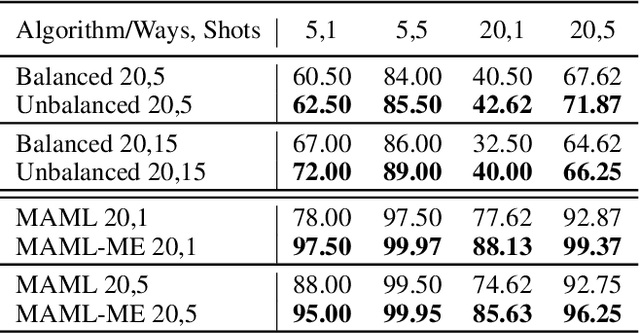
In real-world applications, data do not reflect the ones commonly used for neural networks training, since they are usually few, unbalanced, unlabeled and can be available as a stream. Hence many existing deep learning solutions suffer from a limited range of applications, in particular in the case of online streaming data that evolve over time. To narrow this gap, in this work we introduce a novel and complex setting involving unsupervised meta-continual learning with unbalanced tasks. These tasks are built through a clustering procedure applied to a fitted embedding space. We exploit a meta-learning scheme that simultaneously alleviates catastrophic forgetting and favors the generalization to new tasks, even Out-of-Distribution ones. Moreover, to encourage feature reuse during the meta-optimization, we exploit a single inner loop taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. Experimental results on few-shot learning benchmarks show competitive performance even compared to the supervised case. Additionally, we empirically observe that in an unsupervised scenario, the small tasks and the variability in the clusters pooling play a crucial role in the generalization capability of the network. Further, on complex datasets, the exploitation of more clusters than the true number of classes leads to higher results, even compared to the ones obtained with full supervision, suggesting that a predefined partitioning into classes can miss relevant structural information.
TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
Apr 16, 2020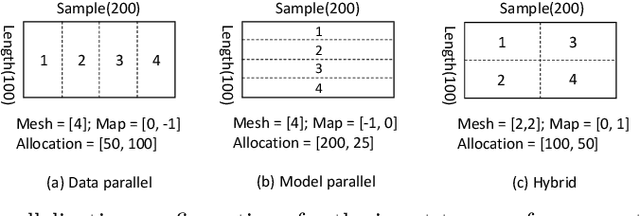
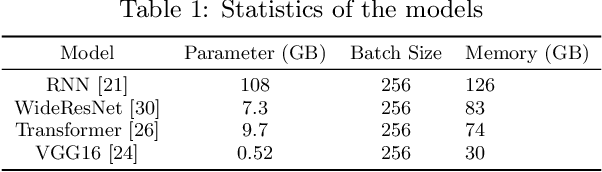
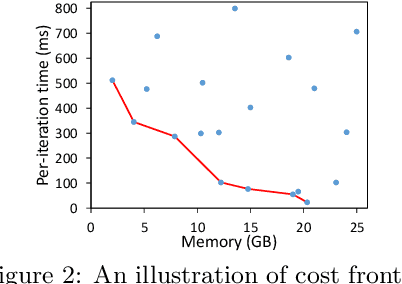

A good parallelization strategy can significantly improve the efficiency or reduce the cost for the distributed training of deep neural networks (DNNs). Recently, several methods have been proposed to find efficient parallelization strategies but they all optimize a single objective (e.g., execution time, memory consumption) and produce only one strategy. We propose FT, an efficient algorithm that searches for an optimal set of parallelization strategies to allow the trade-off among different objectives. FT can adapt to different scenarios by minimizing the memory consumption when the number of devices is limited and fully utilize additional resources to reduce the execution time. For popular DNN models (e.g., vision, language), an in-depth analysis is conducted to understand the trade-offs among different objectives and their influence on the parallelization strategies. We also develop a user-friendly system, called TensorOpt, which allows users to run their distributed DNN training jobs without caring the details of parallelization strategies. Experimental results show that FT runs efficiently and provides accurate estimation of runtime costs, and TensorOpt is more flexible in adapting to resource availability compared with existing frameworks.
Camera-Based Piano Sheet Music Identification
Jul 29, 2020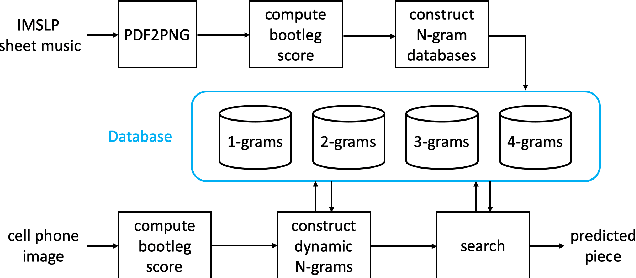
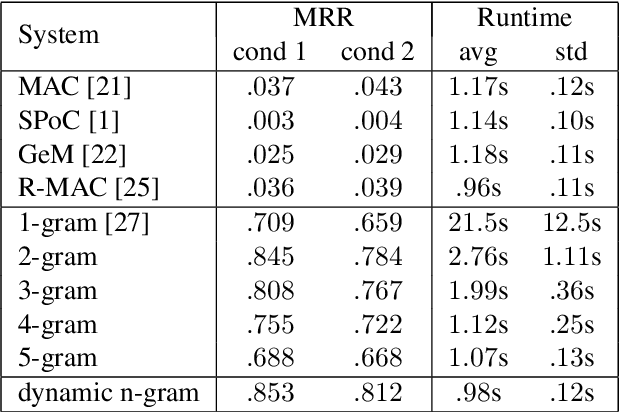

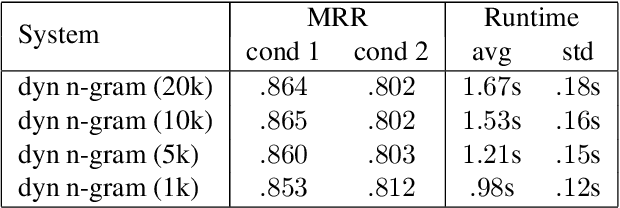
This paper presents a method for large-scale retrieval of piano sheet music images. Our work differs from previous studies on sheet music retrieval in two ways. First, we investigate the problem at a much larger scale than previous studies, using all solo piano sheet music images in the entire IMSLP dataset as a searchable database. Second, we use cell phone images of sheet music as our input queries, which lends itself to a practical, user-facing application. We show that a previously proposed fingerprinting method for sheet music retrieval is far too slow for a real-time application, and we diagnose its shortcomings. We propose a novel hashing scheme called dynamic n-gram fingerprinting that significantly reduces runtime while simultaneously boosting retrieval accuracy. In experiments on IMSLP data, our proposed method achieves a mean reciprocal rank of 0.85 and an average runtime of 0.98 seconds per query.