 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving the Speed and Quality of GAN by Adversarial Training
Aug 07, 2020

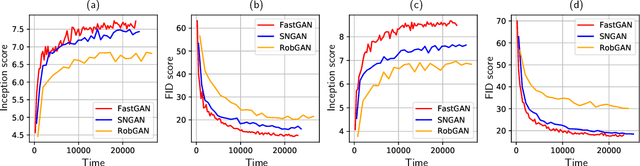
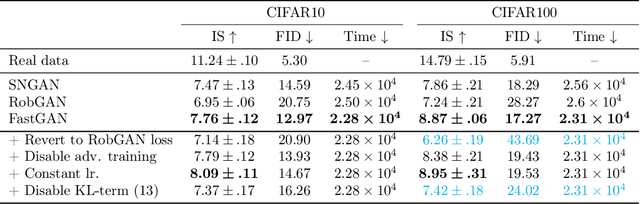

Generative adversarial networks (GAN) have shown remarkable results in image generation tasks. High fidelity class-conditional GAN methods often rely on stabilization techniques by constraining the global Lipschitz continuity. Such regularization leads to less expressive models and slower convergence speed; other techniques, such as the large batch training, require unconventional computing power and are not widely accessible. In this paper, we develop an efficient algorithm, namely FastGAN (Free AdverSarial Training), to improve the speed and quality of GAN training based on the adversarial training technique. We benchmark our method on CIFAR10, a subset of ImageNet, and the full ImageNet datasets. We choose strong baselines such as SNGAN and SAGAN; the results demonstrate that our training algorithm can achieve better generation quality (in terms of the Inception score and Frechet Inception distance) with less overall training time. Most notably, our training algorithm brings ImageNet training to the broader public by requiring 2-4 GPUs.
Efficient algorithms for autonomous electric vehicles' min-max routing problem
Aug 07, 2020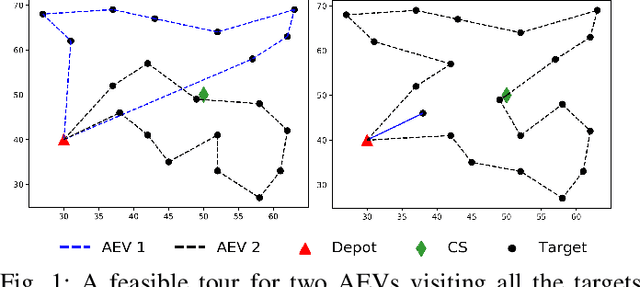
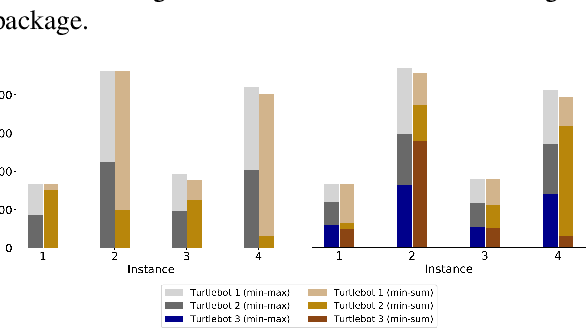
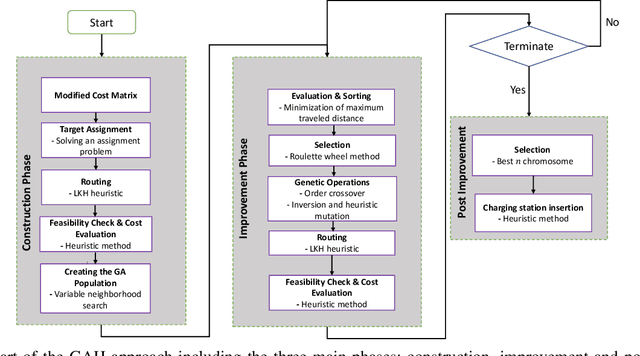
Increase in greenhouse gases emission from the transportation sector has led companies and government to elevate and support the production of electric vehicles. The natural synergy between increased support for electric and emergence of autonomous vehicles possibly can relieve the limitations regarding access to charging infrastructure, time management, and range anxiety. In this work, a fleet of Autonomous Electric Vehicles (AEV) is considered for transportation and logistic capabilities with limited battery capacity and scarce charging station availability are considered while planning to avoid inefficient routing strategies. We introduce a min-max autonomous electric vehicle routing problem (AEVRP) where the maximum distance traveled by any AEV is minimized while considering charging stations for recharging. We propose a genetic algorithm based meta-heuristic that can efficiently solve a variety of instances. Extensive computational results, sensitivity analysis, and data-driven simulation implemented with the robot operating system (ROS) middleware are performed to corroborate the efficiency of the proposed approach, both quantitatively and qualitatively.
RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework
Feb 19, 2020
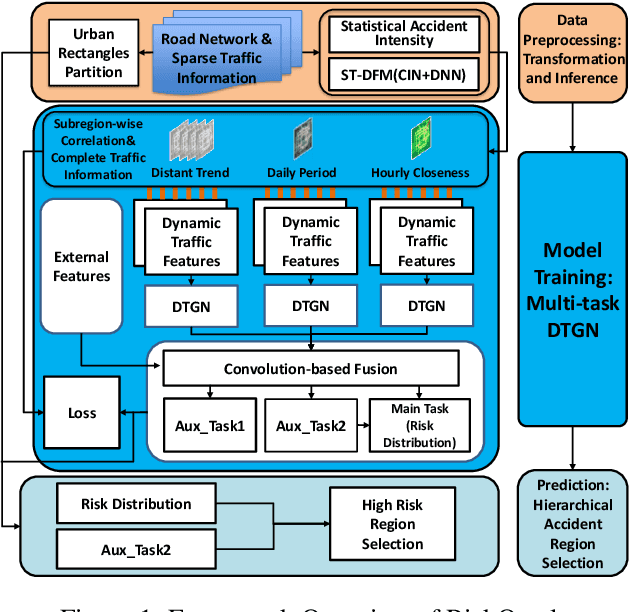
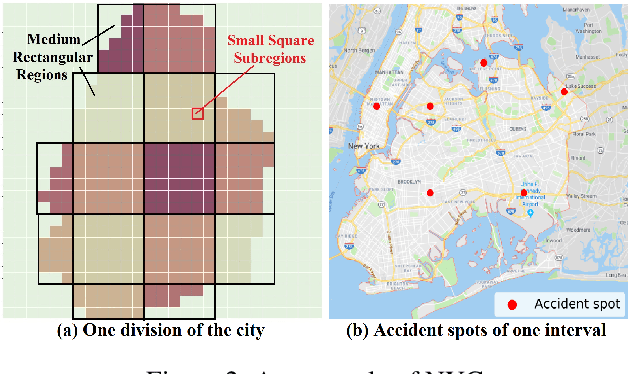
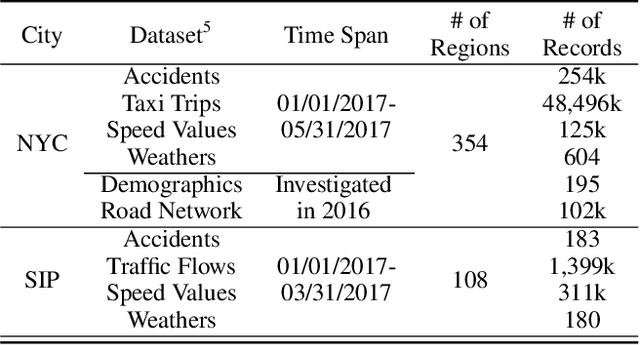
Real-time traffic accident forecasting is increasingly important for public safety and urban management (e.g., real-time safe route planning and emergency response deployment). Previous works on accident forecasting are often performed on hour levels, utilizing existed neural networks with static region-wise correlations taken into account. However, it is still challenging when the granularity of forecasting step improves as the highly dynamic nature of road network and inherent rareness of accident records in one training sample, which leads to biased results and zero-inflated issue. In this work, we propose a novel framework RiskOracle, to improve the prediction granularity to minute levels. Specifically, we first transform the zero-risk values in labels to fit the training network. Then, we propose the Differential Time-varying Graph neural network (DTGN) to capture the immediate changes of traffic status and dynamic inter-subregion correlations. Furthermore, we adopt multi-task and region selection schemes to highlight citywide most-likely accident subregions, bridging the gap between biased risk values and sporadic accident distribution. Extensive experiments on two real-world datasets demonstrate the effectiveness and scalability of our RiskOracle framework.
DeepSumm -- Deep Code Summaries using Neural Transformer Architecture
Mar 31, 2020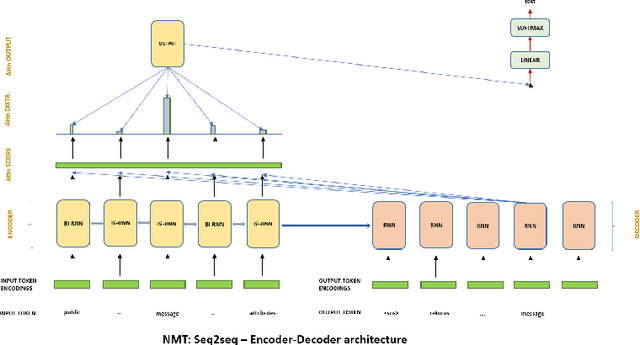
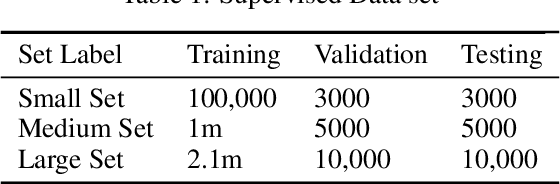
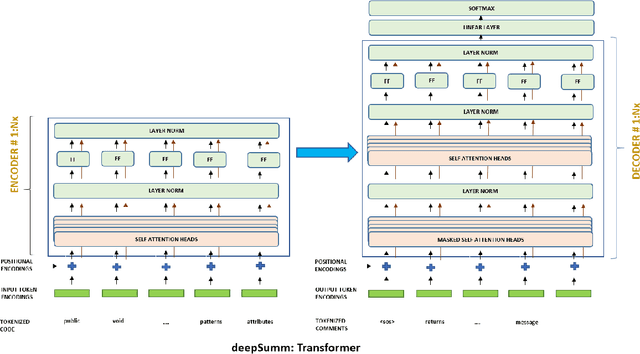
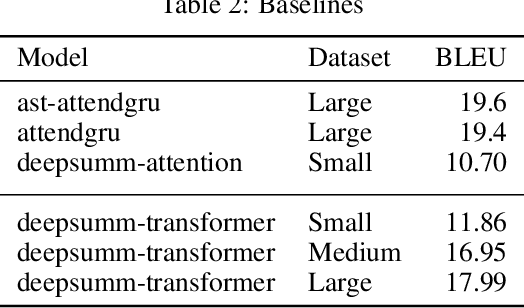
Source code summarizing is a task of writing short, natural language descriptions of source code behavior during run time. Such summaries are extremely useful for software development and maintenance but are expensive to manually author,hence it is done for small fraction of the code that is produced and is often ignored. Automatic code documentation can possibly solve this at a low cost. This is thus an emerging research field with further applications to program comprehension, and software maintenance. Traditional methods often relied on cognitive models that were built in the form of templates and by heuristics and had varying degree of adoption by the developer community. But with recent advancements, end to end data-driven approaches based on neural techniques have largely overtaken the traditional techniques. Much of the current landscape employs neural translation based architectures with recurrence and attention which is resource and time intensive training procedure. In this paper, we employ neural techniques to solve the task of source code summarizing and specifically compare NMT based techniques to more simplified and appealing Transformer architecture on a dataset of Java methods and comments. We bring forth an argument to dispense the need of recurrence in the training procedure. To the best of our knowledge, transformer based models have not been used for the task before. With supervised samples of more than 2.1m comments and code, we reduce the training time by more than 50% and achieve the BLEU score of 17.99 for the test set of examples.
Binarized Graph Neural Network
Apr 19, 2020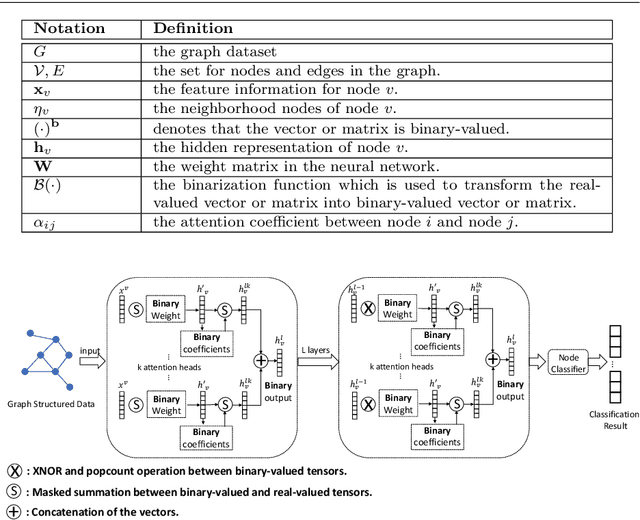
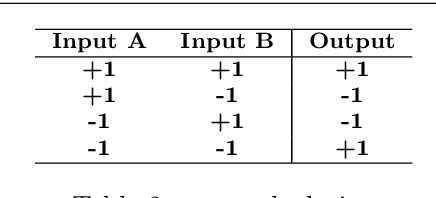
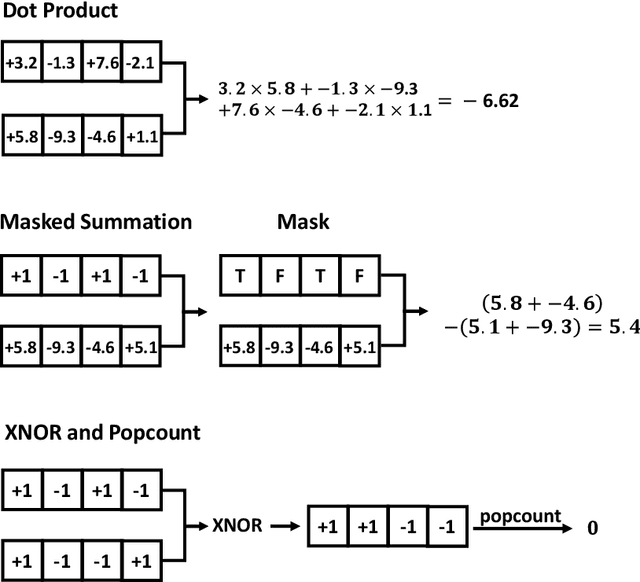
Recently, there have been some breakthroughs in graph analysis by applying the graph neural networks (GNNs) following a neighborhood aggregation scheme, which demonstrate outstanding performance in many tasks. However, we observe that the parameters of the network and the embedding of nodes are represented in real-valued matrices in existing GNN-based graph embedding approaches which may limit the efficiency and scalability of these models. It is well-known that binary vector is usually much more space and time efficient than the real-valued vector. This motivates us to develop a binarized graph neural network to learn the binary representations of the nodes with binary network parameters following the GNN-based paradigm. Our proposed method can be seamlessly integrated into the existing GNN-based embedding approaches to binarize the model parameters and learn the compact embedding. Extensive experiments indicate that the proposed binarized graph neural network, namely BGN, is orders of magnitude more efficient in terms of both time and space while matching the state-of-the-art performance.
Learning effective physical laws for generating cosmological hydrodynamics with Lagrangian Deep Learning
Oct 06, 2020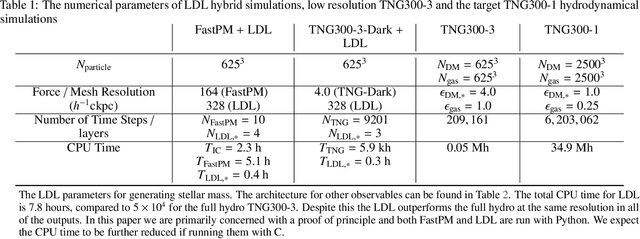
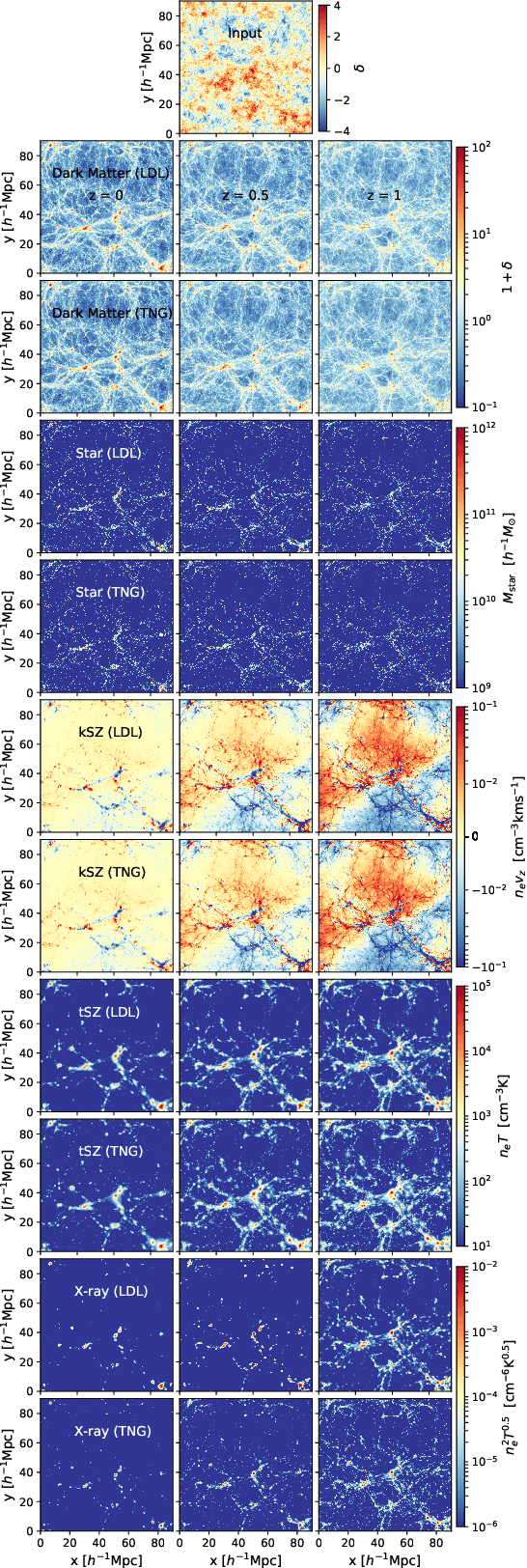
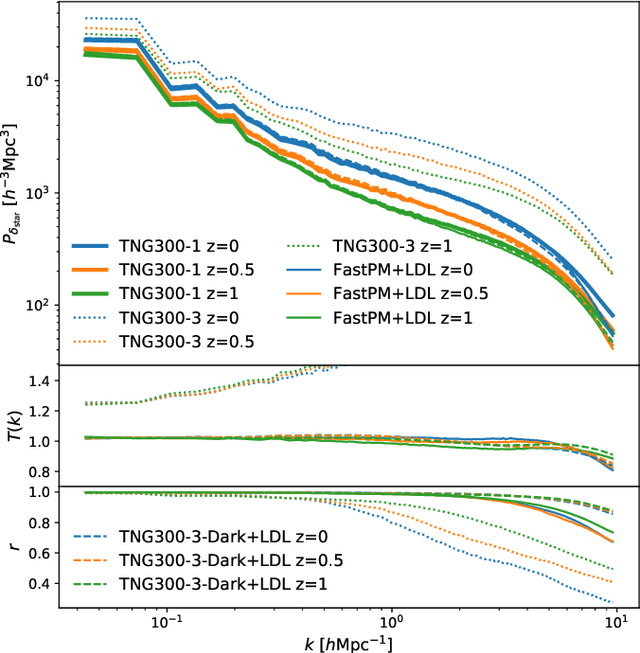
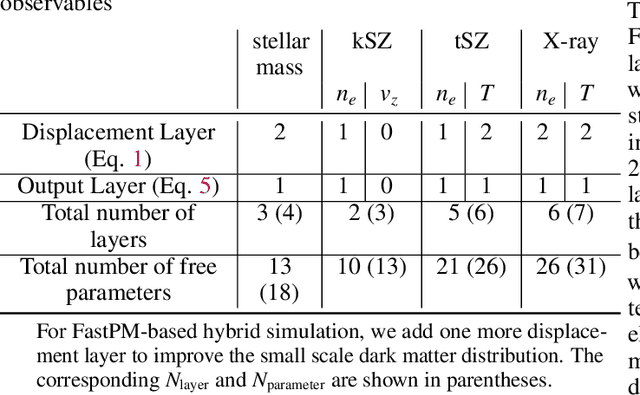
The goal of generative models is to learn the intricate relations between the data to create new simulated data, but current approaches fail in very high dimensions. When the true data generating process is based on physical processes these impose symmetries and constraints, and the generative model can be created by learning an effective description of the underlying physics, which enables scaling of the generative model to very high dimensions. In this work we propose Lagrangian Deep Learning (LDL) for this purpose, applying it to learn outputs of cosmological hydrodynamical simulations. The model uses layers of Lagrangian displacements of particles describing the observables to learn the effective physical laws. The displacements are modeled as the gradient of an effective potential, which explicitly satisfies the translational and rotational invariance. The total number of learned parameters is only of order 10, and they can be viewed as effective theory parameters. We combine N-body solver FastPM with LDL and apply them to a wide range of cosmological outputs, from the dark matter to the stellar maps, gas density and temperature. The computational cost of LDL is nearly four orders of magnitude lower than the full hydrodynamical simulations, yet it outperforms it at the same resolution. We achieve this with only of order 10 layers from the initial conditions to the final output, in contrast to typical cosmological simulations with thousands of time steps. This opens up the possibility of analyzing cosmological observations entirely within this framework, without the need for large dark-matter simulations.
POINTER: Constrained Text Generation via Insertion-based Generative Pre-training
May 01, 2020

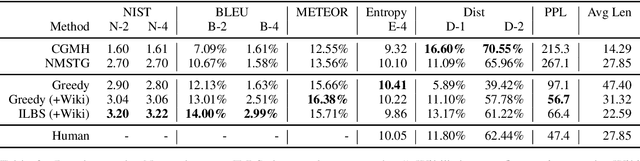
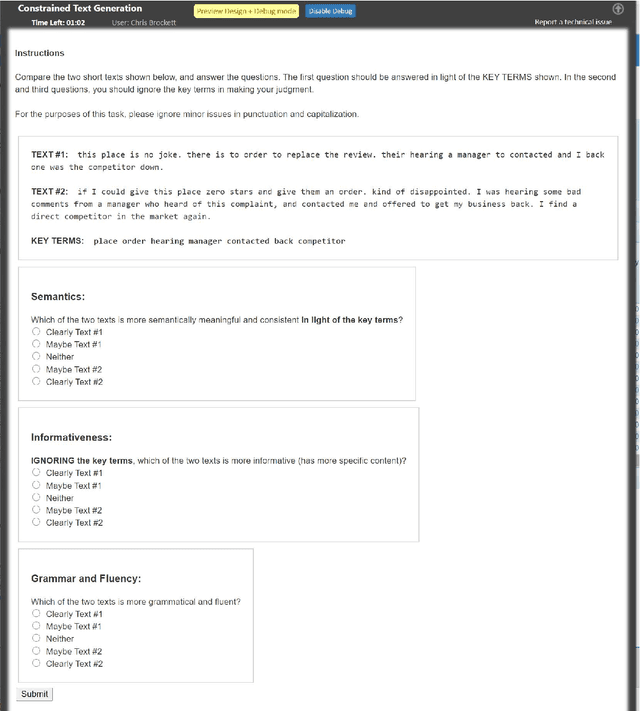
Large-scale pre-trained language models, such as BERT and GPT-2, have achieved excellent performance in language representation learning and free-form text generation. However, these models cannot be directly employed to generate text under specified lexical constraints. To address this challenge, we present POINTER, a simple yet novel insertion-based approach for hard-constrained text generation. The proposed method operates by progressively inserting new tokens between existing tokens in a parallel manner. This procedure is recursively applied until a sequence is completed. The resulting coarse-to-fine hierarchy makes the generation process intuitive and interpretable. Since our training objective resembles the objective of masked language modeling, BERT can be naturally utilized for initialization. We pre-train our model with the proposed progressive insertion-based objective on a 12GB Wikipedia dataset, and fine-tune it on downstream hard-constrained generation tasks. Non-autoregressive decoding yields a logarithmic time complexity during inference time. Experimental results on both News and Yelp datasets demonstrate that POINTER achieves state-of-the-art performance on constrained text generation. We intend to release the pre-trained model to facilitate future research.
Hyper-spectral NIR and MIR data and optimal wavebands for detecting of apple trees diseases
Apr 05, 2020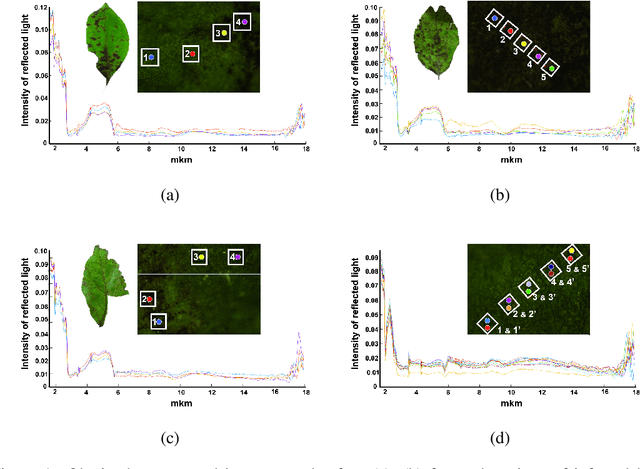

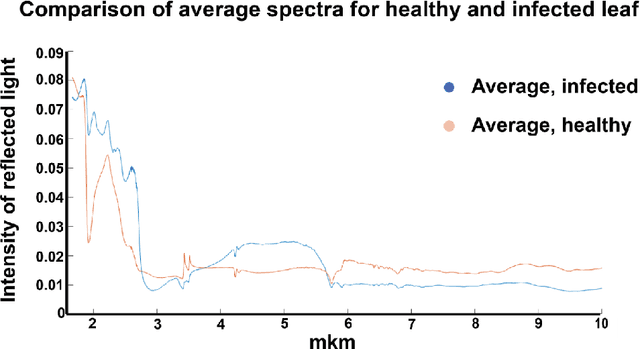
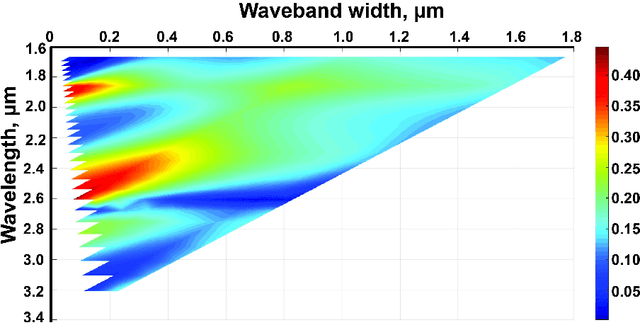
Plants diseases can lead to dramatic losses in yield and quality of food, becoming a problem of high priority for farmers. Apple scab, moniliasis, and powdery mildew are the most significant apple trees diseases worldwide and may cause between 50% and 60% in yield losses annually; they are controlled by fungicide use with huge financial and time expenses. This research proposes a modern approach for analysing spectral data in Near-Infrared and Mid-Infrared ranges of the apple trees diseases on different stages. Using the obtained spectra, we found optimal spectra bands for detecting particular disease and discriminating it from other diseases and from healthy trees. The proposed instrument will provide farmers with accurate, real-time information on different stages of apple trees diseases enabling more effective timing and selection of fungicide application, resulting in better control and increasing yield. The obtained dataset as well as scripts in Matlab for processing data and finding optimal spectral bands are available via the link: https://yadi.sk/d/ZqfGaNlYVR3TUA
Data-driven Identification of Number of Unreported Cases for COVID-19: Bounds and Limitations
Jun 03, 2020
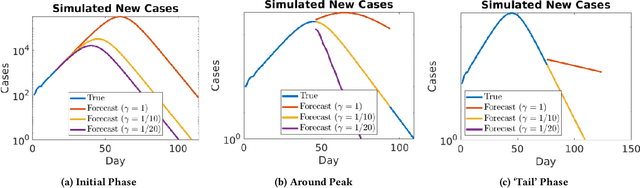

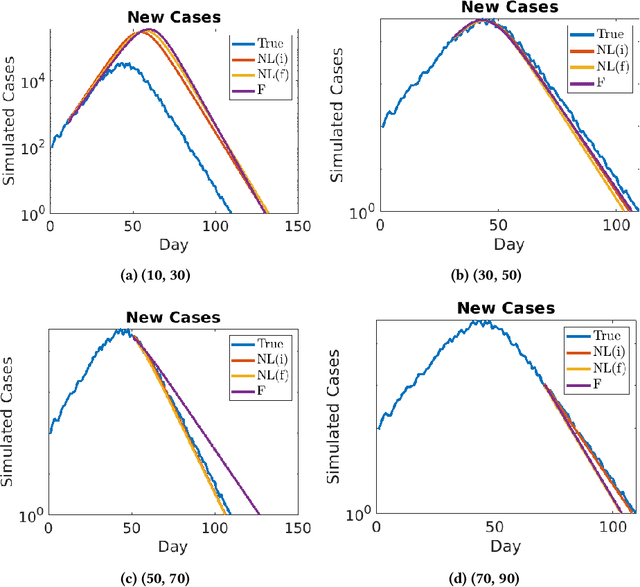
Accurate forecasts for COVID-19 are necessary for better preparedness and resource management. Specifically, deciding the response over months or several months requires accurate long-term forecasts which is particularly challenging as the model errors accumulate with time. A critical factor that can hinder accurate long-term forecasts, is the number of unreported/asymptomatic cases. While there have been early serology tests to estimate this number, more tests need to be conducted for more reliable results. To identify the number of unreported/asymptomatic cases, we take an epidemiology data-driven approach. We show that we can identify lower bounds on this ratio or upper bound on actual cases as a factor of total cases. To do so, we propose an extension of our prior heterogeneous infection rate model, incorporating unreported/asymptomatic cases. We prove that the number of unreported cases can be reliably estimated only from a certain time period of the epidemic data. In doing so, we identify tests that can indicate if the learned ratio is reliable. We propose three approaches to learn this ratio and show their effectiveness on simulated data. We use our approaches to identify the lower bounds on the ratio of reported to actual cases for New York City and several US states. Our results demonstrate that the actual number of cases are unlikely to be more than 25 times in New York, 34 times in Illinois, 33 times in Massachusetts and 17 times in New Jersey, than the reported cases.
Spacecraft Collision Avoidance Challenge: design and results of a machine learning competition
Aug 07, 2020
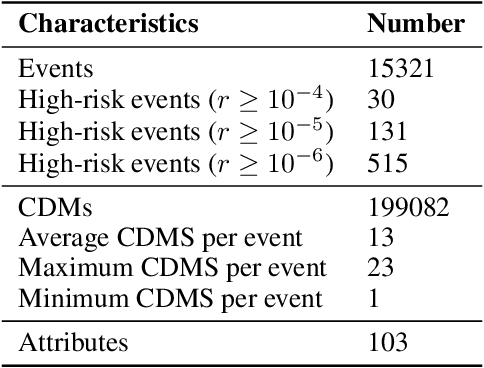
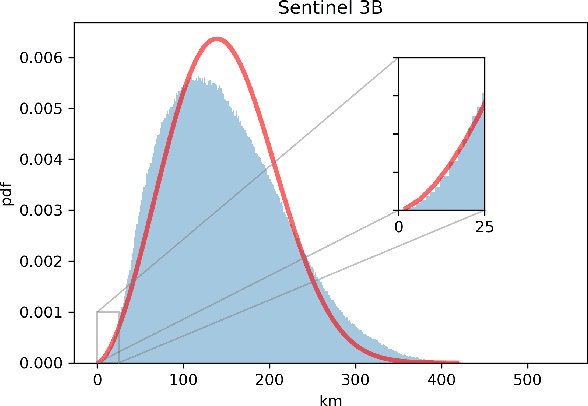

Spacecraft collision avoidance procedures have become an essential part of satellite operations. Complex and constantly updated estimates of the collision risk between orbiting objects inform the various operators who can then plan risk mitigation measures. Such measures could be aided by the development of suitable machine learning models predicting, for example, the evolution of the collision risk in time. In an attempt to study this opportunity, the European Space Agency released, in October 2019, a large curated dataset containing information about close approach events, in the form of Conjunction Data Messages (CDMs), collected from 2015 to 2019. This dataset was used in the Spacecraft Collision Avoidance Challenge, a machine learning competition where participants had to build models to predict the final collision risk between orbiting objects. This paper describes the design and results of the competition and discusses the challenges and lessons learned when applying machine learning methods to this problem domain.