 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-driven Crop Growth Simulation on Time-varying Generated Images using Multi-conditional Generative Adversarial Networks
Dec 06, 2023
Image-based crop growth modeling can substantially contribute to precision agriculture by revealing spatial crop development over time, which allows an early and location-specific estimation of relevant future plant traits, such as leaf area or biomass. A prerequisite for realistic and sharp crop image generation is the integration of multiple growth-influencing conditions in a model, such as an image of an initial growth stage, the associated growth time, and further information about the field treatment. We present a two-stage framework consisting first of an image prediction model and second of a growth estimation model, which both are independently trained. The image prediction model is a conditional Wasserstein generative adversarial network (CWGAN). In the generator of this model, conditional batch normalization (CBN) is used to integrate different conditions along with the input image. This allows the model to generate time-varying artificial images dependent on multiple influencing factors of different kinds. These images are used by the second part of the framework for plant phenotyping by deriving plant-specific traits and comparing them with those of non-artificial (real) reference images. For various crop datasets, the framework allows realistic, sharp image predictions with a slight loss of quality from short-term to long-term predictions. Simulations of varying growth-influencing conditions performed with the trained framework provide valuable insights into how such factors relate to crop appearances, which is particularly useful in complex, less explored crop mixture systems. Further results show that adding process-based simulated biomass as a condition increases the accuracy of the derived phenotypic traits from the predicted images. This demonstrates the potential of our framework to serve as an interface between an image- and process-based crop growth model.
Improving Diffusion-Based Image Synthesis with Context Prediction
Jan 04, 2024Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
A novel method to enhance pneumonia detection via a model-level ensembling of CNN and vision transformer
Jan 04, 2024Pneumonia remains a leading cause of morbidity and mortality worldwide. Chest X-ray (CXR) imaging is a fundamental diagnostic tool, but traditional analysis relies on time-intensive expert evaluation. Recently, deep learning has shown immense potential for automating pneumonia detection from CXRs. This paper explores applying neural networks to improve CXR-based pneumonia diagnosis. We developed a novel model fusing Convolution Neural networks (CNN) and Vision Transformer networks via model-level ensembling. Our fusion architecture combines a ResNet34 variant and a Multi-Axis Vision Transformer small model. Both base models are initialized with ImageNet pre-trained weights. The output layers are removed, and features are combined using a flattening layer before final classification. Experiments used the Kaggle pediatric pneumonia dataset containing 1,341 normal and 3,875 pneumonia CXR images. We compared our model against standalone ResNet34, Vision Transformer, and Swin Transformer Tiny baseline models using identical training procedures. Extensive data augmentation, Adam optimization, learning rate warmup, and decay were employed. The fusion model achieved a state-of-the-art accuracy of 94.87%, surpassing the baselines. We also attained excellent sensitivity, specificity, kappa score, and positive predictive value. Confusion matrix analysis confirms fewer misclassifications. The ResNet34 and Vision Transformer combination enables jointly learning robust features from CNNs and Transformer paradigms. This model-level ensemble technique effectively integrates their complementary strengths for enhanced pneumonia classification.
Inherently robust suboptimal MPC for autonomous racing with anytime feasible SQP
Jan 04, 2024
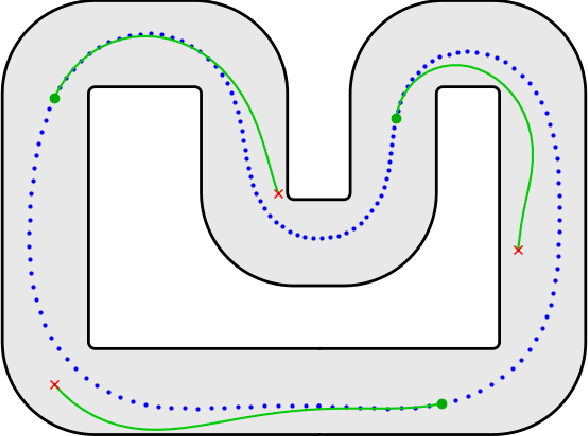
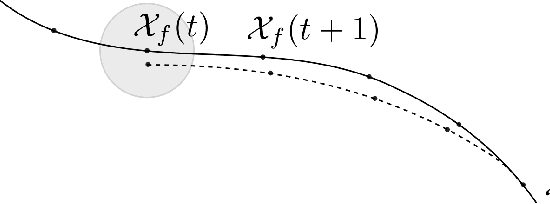
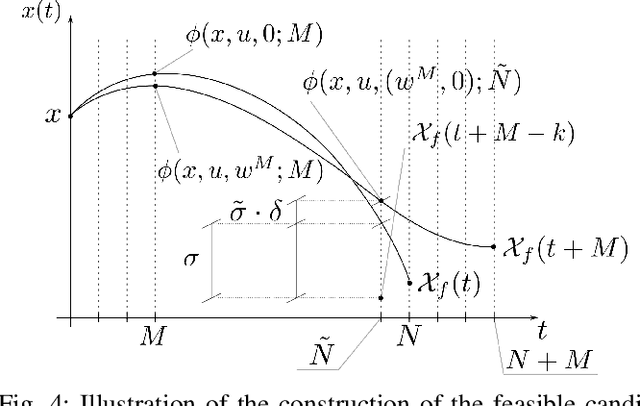
In recent years, the increasing need for high-performance controllers in applications like autonomous driving has motivated the development of optimization routines tailored to specific control problems. In this paper, we propose an efficient inexact model predictive control (MPC) strategy for autonomous miniature racing with inherent robustness properties. We rely on a feasible sequential quadratic programming (SQP) algorithm capable of generating feasible intermediate iterates such that the solver can be stopped after any number of iterations, without jeopardizing recursive feasibility. In this way, we provide a strategy that computes suboptimal and yet feasible solutions with a computational footprint that is much lower than state-of-the-art methods based on the computation of locally optimal solutions. Under suitable assumptions on the terminal set and on the controllability properties of the system, we can state that, for any sufficiently small disturbance affecting the system's dynamics, recursive feasibility can be guaranteed. We validate the effectiveness of the proposed strategy in simulation and by deploying it onto a physical experiment with autonomous miniature race cars. Both the simulation and experimental results demonstrate that, using the feasible SQP method, a feasible solution can be obtained with moderate additional computational effort compared to strategies that resort to early termination without providing a feasible solution. At the same time, the proposed method is significantly faster than the state-of-the-art solver Ipopt.
OptFlow: Fast Optimization-based Scene Flow Estimation without Supervision
Jan 04, 2024Scene flow estimation is a crucial component in the development of autonomous driving and 3D robotics, providing valuable information for environment perception and navigation. Despite the advantages of learning-based scene flow estimation techniques, their domain specificity and limited generalizability across varied scenarios pose challenges. In contrast, non-learning optimization-based methods, incorporating robust priors or regularization, offer competitive scene flow estimation performance, require no training, and show extensive applicability across datasets, but suffer from lengthy inference times. In this paper, we present OptFlow, a fast optimization-based scene flow estimation method. Without relying on learning or any labeled datasets, OptFlow achieves state-of-the-art performance for scene flow estimation on popular autonomous driving benchmarks. It integrates a local correlation weight matrix for correspondence matching, an adaptive correspondence threshold limit for nearest-neighbor search, and graph prior rigidity constraints, resulting in expedited convergence and improved point correspondence identification. Moreover, we demonstrate how integrating a point cloud registration function within our objective function bolsters accuracy and differentiates between static and dynamic points without relying on external odometry data. Consequently, OptFlow outperforms the baseline graph-prior method by approximately 20% and the Neural Scene Flow Prior method by 5%-7% in accuracy, all while offering the fastest inference time among all non-learning scene flow estimation methods.
HAAQI-Net: A non-intrusive neural music quality assessment model for hearing aids
Jan 02, 2024This paper introduces HAAQI-Net, a non-intrusive deep learning model for music quality assessment tailored to hearing aid users. In contrast to traditional methods like the Hearing Aid Audio Quality Index (HAAQI), HAAQI-Net utilizes a Bidirectional Long Short-Term Memory (BLSTM) with attention. It takes an assessed music sample and a hearing loss pattern as input, generating a predicted HAAQI score. The model employs the pre-trained Bidirectional Encoder representation from Audio Transformers (BEATs) for acoustic feature extraction. Comparing predicted scores with ground truth, HAAQI-Net achieves a Longitudinal Concordance Correlation (LCC) of 0.9257, Spearman's Rank Correlation Coefficient (SRCC) of 0.9394, and Mean Squared Error (MSE) of 0.0080. Notably, this high performance comes with a substantial reduction in inference time: from 62.52 seconds (by HAAQI) to 2.71 seconds (by HAAQI-Net), serving as an efficient music quality assessment model for hearing aid users.
Q-Refine: A Perceptual Quality Refiner for AI-Generated Image
Jan 02, 2024With the rapid evolution of the Text-to-Image (T2I) model in recent years, their unsatisfactory generation result has become a challenge. However, uniformly refining AI-Generated Images (AIGIs) of different qualities not only limited optimization capabilities for low-quality AIGIs but also brought negative optimization to high-quality AIGIs. To address this issue, a quality-award refiner named Q-Refine is proposed. Based on the preference of the Human Visual System (HVS), Q-Refine uses the Image Quality Assessment (IQA) metric to guide the refining process for the first time, and modify images of different qualities through three adaptive pipelines. Experimental shows that for mainstream T2I models, Q-Refine can perform effective optimization to AIGIs of different qualities. It can be a general refiner to optimize AIGIs from both fidelity and aesthetic quality levels, thus expanding the application of the T2I generation models.
Concurrent Brainstorming & Hypothesis Satisfying: An Iterative Framework for Enhanced Retrieval-Augmented Generation (R2CBR3H-SR)
Jan 03, 2024Addressing the complexity of comprehensive information retrieval, this study introduces an innovative, iterative retrieval-augmented generation system. Our approach uniquely integrates a vector-space driven re-ranking mechanism with concurrent brainstorming to expedite the retrieval of highly relevant documents, thereby streamlining the generation of potential queries. This sets the stage for our novel hybrid process, which synergistically combines hypothesis formulation with satisfying decision-making strategy to determine content adequacy, leveraging a chain of thought-based prompting technique. This unified hypothesize-satisfied phase intelligently distills information to ascertain whether user queries have been satisfactorily addressed. Upon reaching this criterion, the system refines its output into a concise representation, maximizing conceptual density with minimal verbosity. The iterative nature of the workflow enhances process efficiency and accuracy. Crucially, the concurrency within the brainstorming phase significantly accelerates recursive operations, facilitating rapid convergence to solution satisfaction. Compared to conventional methods, our system demonstrates a marked improvement in computational time and cost-effectiveness. This research advances the state-of-the-art in intelligent retrieval systems, setting a new benchmark for resource-efficient information extraction and abstraction in knowledge-intensive applications.
Physics-informed appliance signatures generator for energy disaggregation
Jan 03, 2024Energy disaggregation is a promising solution to access detailed information on energy consumption in a household, by itemizing its total energy consumption. However, in real-world applications, overfitting remains a challenging problem for data-driven disaggregation methods. First, the available real-world datasets are biased towards the most frequently used appliances. Second, both real and synthetic publicly-available datasets are limited in number of appliances, which may not be sufficient for a disaggregation algorithm to learn complex relations among different types of appliances and their states. To address the lack of appliance data, we propose two physics-informed data generators: one for high sampling rate signals (kHz) and another for low sampling rate signals (Hz). These generators rely on prior knowledge of the physics of appliance energy consumption, and are capable of simulating a virtually unlimited number of different appliances and their corresponding signatures for any time period. Both methods involve defining a mathematical model, selecting centroids corresponding to individual appliances, sampling model parameters around each centroid, and finally substituting the obtained parameters into the mathematical model. Additionally, by using Principal Component Analysis and Kullback-Leibler divergence, we demonstrate that our methods significantly outperform the previous approaches.
Deep learning the Hurst parameter of linear fractional processes and assessing its reliability
Jan 03, 2024This research explores the reliability of deep learning, specifically Long Short-Term Memory (LSTM) networks, for estimating the Hurst parameter in fractional stochastic processes. The study focuses on three types of processes: fractional Brownian motion (fBm), fractional Ornstein-Uhlenbeck (fOU) process, and linear fractional stable motions (lfsm). The work involves a fast generation of extensive datasets for fBm and fOU to train the LSTM network on a large volume of data in a feasible time. The study analyses the accuracy of the LSTM network's Hurst parameter estimation regarding various performance measures like RMSE, MAE, MRE, and quantiles of the absolute and relative errors. It finds that LSTM outperforms the traditional statistical methods in the case of fBm and fOU processes; however, it has limited accuracy on lfsm processes. The research also delves into the implications of training length and valuation sequence length on the LSTM's performance. The methodology is applied by estimating the Hurst parameter in Li-ion battery degradation data and obtaining confidence bounds for the estimation. The study concludes that while deep learning methods show promise in parameter estimation of fractional processes, their effectiveness is contingent on the process type and the quality of training data.