 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024


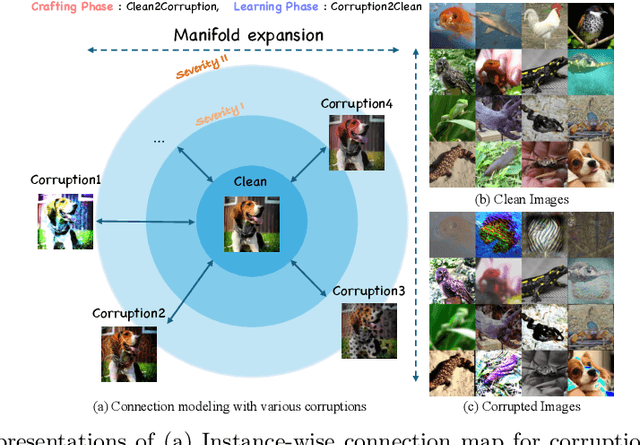

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
A High Order Solver for Signature Kernels
Apr 01, 2024Signature kernels are at the core of several machine learning algorithms for analysing multivariate time series. The kernel of two bounded variation paths (such as piecewise linear interpolations of time series data) is typically computed by solving a Goursat problem for a hyperbolic partial differential equation (PDE) in two independent time variables. However, this approach becomes considerably less practical for highly oscillatory input paths, as they have to be resolved at a fine enough scale to accurately recover their signature kernel, resulting in significant time and memory complexities. To mitigate this issue, we first show that the signature kernel of a broader class of paths, known as \emph{smooth rough paths}, also satisfies a PDE, albeit in the form of a system of coupled equations. We then use this result to introduce new algorithms for the numerical approximation of signature kernels. As bounded variation paths (and more generally geometric $p$-rough paths) can be approximated by piecewise smooth rough paths, one can replace the PDE with rapidly varying coefficients in the original Goursat problem by an explicit system of coupled equations with piecewise constant coefficients derived from the first few iterated integrals of the original input paths. While this approach requires solving more equations, they do not require looking back at the complex and fine structure of the initial paths, which significantly reduces the computational complexity associated with the analysis of highly oscillatory time series.
Carbon Footprint Reduction for Sustainable Data Centers in Real-Time
Mar 21, 2024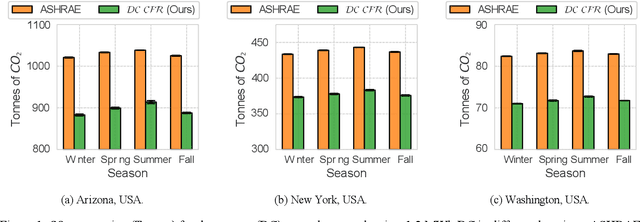

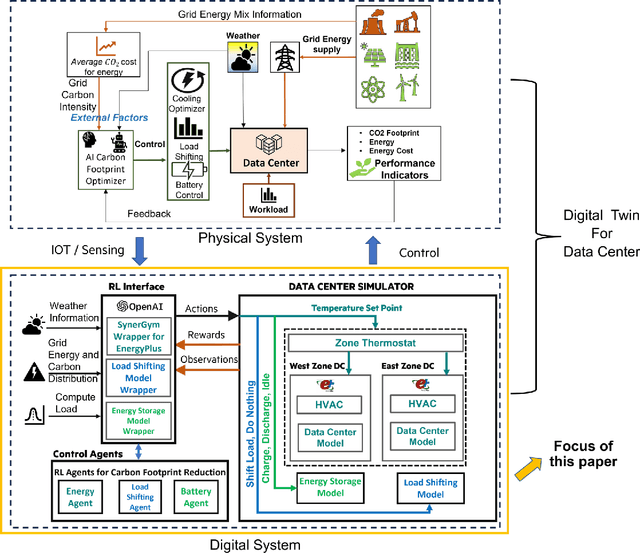
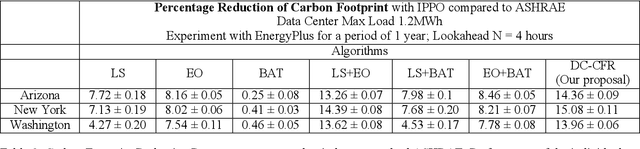
As machine learning workloads significantly increase energy consumption, sustainable data centers with low carbon emissions are becoming a top priority for governments and corporations worldwide. This requires a paradigm shift in optimizing power consumption in cooling and IT loads, shifting flexible loads based on the availability of renewable energy in the power grid, and leveraging battery storage from the uninterrupted power supply in data centers, using collaborative agents. The complex association between these optimization strategies and their dependencies on variable external factors like weather and the power grid carbon intensity makes this a hard problem. Currently, a real-time controller to optimize all these goals simultaneously in a dynamic real-world setting is lacking. We propose a Data Center Carbon Footprint Reduction (DC-CFR) multi-agent Reinforcement Learning (MARL) framework that optimizes data centers for the multiple objectives of carbon footprint reduction, energy consumption, and energy cost. The results show that the DC-CFR MARL agents effectively resolved the complex interdependencies in optimizing cooling, load shifting, and energy storage in real-time for various locations under real-world dynamic weather and grid carbon intensity conditions. DC-CFR significantly outperformed the industry standard ASHRAE controller with a considerable reduction in carbon emissions (14.5%), energy usage (14.4%), and energy cost (13.7%) when evaluated over one year across multiple geographical regions.
Reliable Feature Selection for Adversarially Robust Cyber-Attack Detection
Apr 05, 2024The growing cybersecurity threats make it essential to use high-quality data to train Machine Learning (ML) models for network traffic analysis, without noisy or missing data. By selecting the most relevant features for cyber-attack detection, it is possible to improve both the robustness and computational efficiency of the models used in a cybersecurity system. This work presents a feature selection and consensus process that combines multiple methods and applies them to several network datasets. Two different feature sets were selected and were used to train multiple ML models with regular and adversarial training. Finally, an adversarial evasion robustness benchmark was performed to analyze the reliability of the different feature sets and their impact on the susceptibility of the models to adversarial examples. By using an improved dataset with more data diversity, selecting the best time-related features and a more specific feature set, and performing adversarial training, the ML models were able to achieve a better adversarially robust generalization. The robustness of the models was significantly improved without their generalization to regular traffic flows being affected, without increases of false alarms, and without requiring too many computational resources, which enables a reliable detection of suspicious activity and perturbed traffic flows in enterprise computer networks.
Vision-language models for decoding provider attention during neonatal resuscitation
Apr 01, 2024Neonatal resuscitations demand an exceptional level of attentiveness from providers, who must process multiple streams of information simultaneously. Gaze strongly influences decision making; thus, understanding where a provider is looking during neonatal resuscitations could inform provider training, enhance real-time decision support, and improve the design of delivery rooms and neonatal intensive care units (NICUs). Current approaches to quantifying neonatal providers' gaze rely on manual coding or simulations, which limit scalability and utility. Here, we introduce an automated, real-time, deep learning approach capable of decoding provider gaze into semantic classes directly from first-person point-of-view videos recorded during live resuscitations. Combining state-of-the-art, real-time segmentation with vision-language models (CLIP), our low-shot pipeline attains 91\% classification accuracy in identifying gaze targets without training. Upon fine-tuning, the performance of our gaze-guided vision transformer exceeds 98\% accuracy in gaze classification, approaching human-level precision. This system, capable of real-time inference, enables objective quantification of provider attention dynamics during live neonatal resuscitation. Our approach offers a scalable solution that seamlessly integrates with existing infrastructure for data-scarce gaze analysis, thereby offering new opportunities for understanding and refining clinical decision making.
PointInfinity: Resolution-Invariant Point Diffusion Models
Apr 04, 2024We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.
Safe Reinforcement Learning for Constrained Markov Decision Processes with Stochastic Stopping Time
Mar 23, 2024In this paper, we present an online reinforcement learning algorithm for constrained Markov decision processes with a safety constraint. Despite the necessary attention of the scientific community, considering stochastic stopping time, the problem of learning optimal policy without violating safety constraints during the learning phase is yet to be addressed. To this end, we propose an algorithm based on linear programming that does not require a process model. We show that the learned policy is safe with high confidence. We also propose a method to compute a safe baseline policy, which is central in developing algorithms that do not violate the safety constraints. Finally, we provide simulation results to show the efficacy of the proposed algorithm. Further, we demonstrate that efficient exploration can be achieved by defining a subset of the state-space called proxy set.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024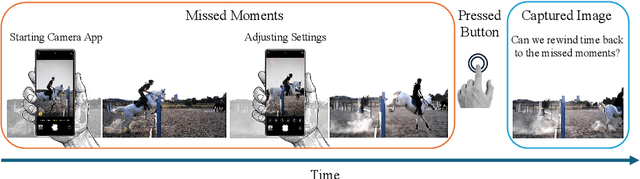

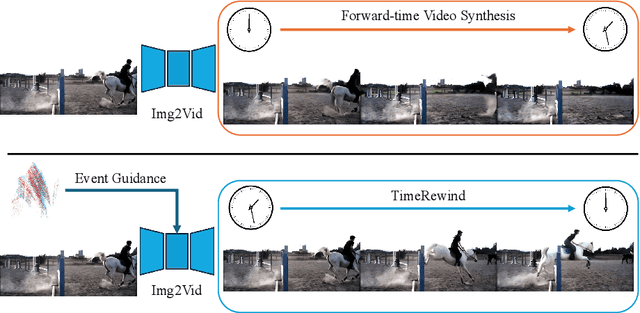
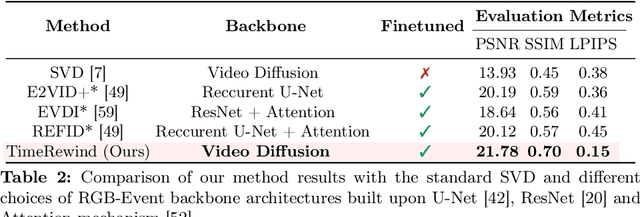
This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
A Ground Mobile Robot for Autonomous Terrestrial Laser Scanning-Based Field Phenotyping
Apr 05, 2024Traditional field phenotyping methods are often manual, time-consuming, and destructive, posing a challenge for breeding progress. To address this bottleneck, robotics and automation technologies offer efficient sensing tools to monitor field evolution and crop development throughout the season. This study aimed to develop an autonomous ground robotic system for LiDAR-based field phenotyping in plant breeding trials. A Husky platform was equipped with a high-resolution three-dimensional (3D) laser scanner to collect in-field terrestrial laser scanning (TLS) data without human intervention. To automate the TLS process, a 3D ray casting analysis was implemented for optimal TLS site planning, and a route optimization algorithm was utilized to minimize travel distance during data collection. The platform was deployed in two cotton breeding fields for evaluation, where it autonomously collected TLS data. The system provided accurate pose information through RTK-GNSS positioning and sensor fusion techniques, with average errors of less than 0.6 cm for location and 0.38$^{\circ}$ for heading. The achieved localization accuracy allowed point cloud registration with mean point errors of approximately 2 cm, comparable to traditional TLS methods that rely on artificial targets and manual sensor deployment. This work presents an autonomous phenotyping platform that facilitates the quantitative assessment of plant traits under field conditions of both large agricultural fields and small breeding trials to contribute to the advancement of plant phenomics and breeding programs.
Agnostic Tomography of Stabilizer Product States
Apr 04, 2024We define a quantum learning task called agnostic tomography, where given copies of an arbitrary state $\rho$ and a class of quantum states $\mathcal{C}$, the goal is to output a succinct description of a state that approximates $\rho$ at least as well as any state in $\mathcal{C}$ (up to some small error $\varepsilon$). This task generalizes ordinary quantum tomography of states in $\mathcal{C}$ and is more challenging because the learning algorithm must be robust to perturbations of $\rho$. We give an efficient agnostic tomography algorithm for the class $\mathcal{C}$ of $n$-qubit stabilizer product states. Assuming $\rho$ has fidelity at least $\tau$ with a stabilizer product state, the algorithm runs in time $n^{O(1 + \log(1/\tau))} / \varepsilon^2$. This runtime is quasipolynomial in all parameters, and polynomial if $\tau$ is a constant.