 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Question Identification in Arabic Language Using Emotional Based Features
Aug 10, 2020
With the growth of content on social media networks, enterprises and services providers have become interested in identifying the questions of their customers. Tracking these questions become very challenging with the growth of text that grows directly proportional to the increase of Arabic users thus making it very difficult to be tracked manually. By automatic identifying the questions seeking answers on the social media networks and defining their category, we can automatically answer them by finding an existing answer or even routing them to those responsible for answering those questions in the customer service. This will result in saving the time and the effort and enhancing the customer feedback and improving the business. In this paper, we have implemented a binary classifier to classify Arabic text to either question seeking answer or not. We have added emotional based features to the state of the art features. Experimental evaluation has done and showed that these emotional features have improved the accuracy of the classifier.
Stage-wise Conservative Linear Bandits
Sep 30, 2020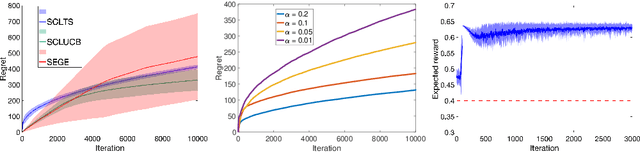
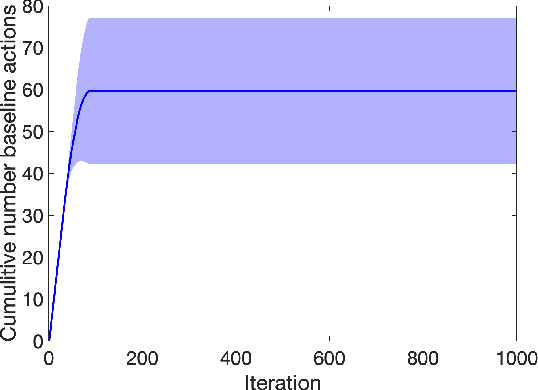
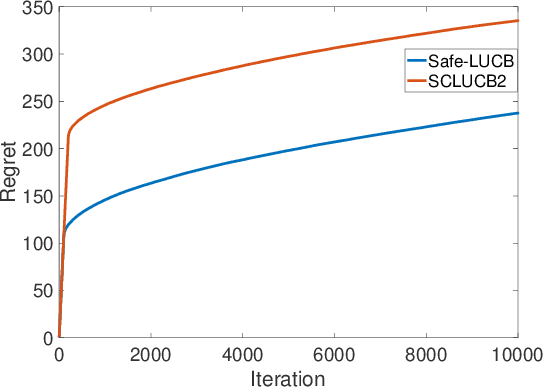
We study stage-wise conservative linear stochastic bandits: an instance of bandit optimization, which accounts for (unknown) safety constraints that appear in applications such as online advertising and medical trials. At each stage, the learner must choose actions that not only maximize cumulative reward across the entire time horizon but further satisfy a linear baseline constraint that takes the form of a lower bound on the instantaneous reward. For this problem, we present two novel algorithms, stage-wise conservative linear Thompson Sampling (SCLTS) and stage-wise conservative linear UCB (SCLUCB), that respect the baseline constraints and enjoy probabilistic regret bounds of order O(\sqrt{T} \log^{3/2}T) and O(\sqrt{T} \log T), respectively. Notably, the proposed algorithms can be adjusted with only minor modifications to tackle different problem variations, such as constraints with bandit-feedback, or an unknown sequence of baseline actions. We discuss these and other improvements over the state-of-the-art. For instance, compared to existing solutions, we show that SCLTS plays the (non-optimal) baseline action at most O(\log{T}) times (compared to O(\sqrt{T})). Finally, we make connections to another studied form of safety constraints that takes the form of an upper bound on the instantaneous reward. While this incurs additional complexity to the learning process as the optimal action is not guaranteed to belong to the safe set at each round, we show that SCLUCB can properly adjust in this setting via a simple modification.
* 28 pages, 5 figures
Self-Supervised Monocular Scene Flow Estimation
Apr 08, 2020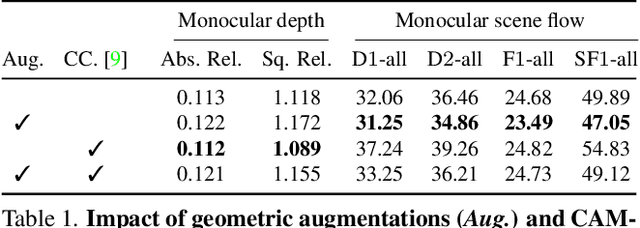
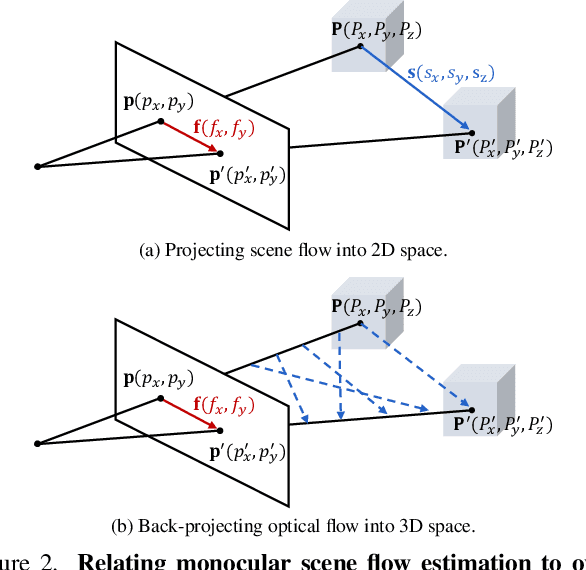
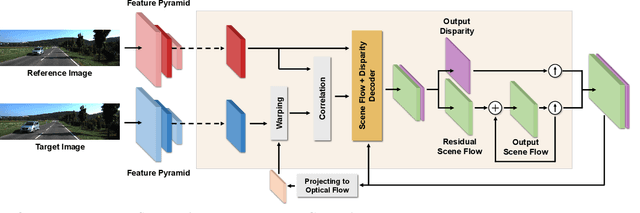
Scene flow estimation has been receiving increasing attention for 3D environment perception. Monocular scene flow estimation -- obtaining 3D structure and 3D motion from two temporally consecutive images -- is a highly ill-posed problem, and practical solutions are lacking to date. We propose a novel monocular scene flow method that yields competitive accuracy and real-time performance. By taking an inverse problem view, we design a single convolutional neural network (CNN) that successfully estimates depth and 3D motion simultaneously from a classical optical flow cost volume. We adopt self-supervised learning with 3D loss functions and occlusion reasoning to leverage unlabeled data. We validate our design choices, including the proxy loss and augmentation setup. Our model achieves state-of-the-art accuracy among unsupervised/self-supervised learning approaches to monocular scene flow, and yields competitive results for the optical flow and monocular depth estimation sub-tasks. Semi-supervised fine-tuning further improves the accuracy and yields promising results in real-time.
SLAYER: Spike Layer Error Reassignment in Time
Sep 05, 2018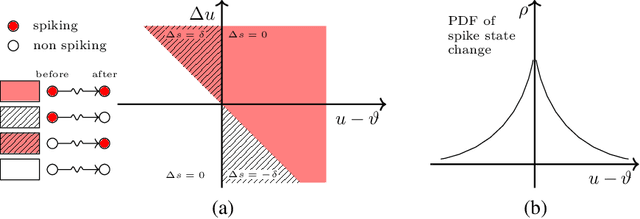
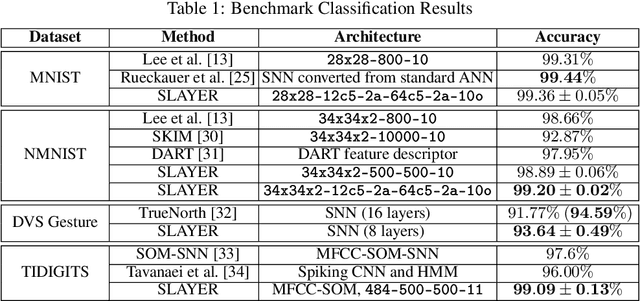
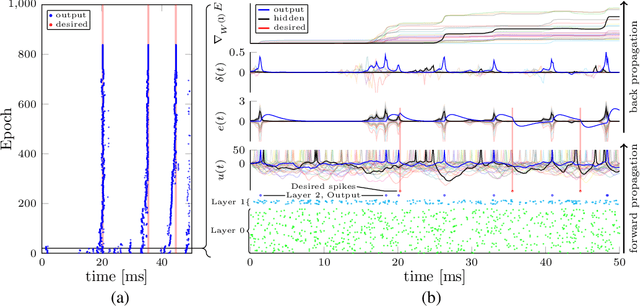
Configuring deep Spiking Neural Networks (SNNs) is an exciting research avenue for low power spike event based computation. However, the spike generation function is non-differentiable and therefore not directly compatible with the standard error backpropagation algorithm. In this paper, we introduce a new general backpropagation mechanism for learning synaptic weights and axonal delays which overcomes the problem of non-differentiability of the spike function and uses a temporal credit assignment policy for backpropagating error to preceding layers. We describe and release a GPU accelerated software implementation of our method which allows training both fully connected and convolutional neural network (CNN) architectures. Using our software, we compare our method against existing SNN based learning approaches and standard ANN to SNN conversion techniques and show that our method achieves state of the art performance for an SNN on the MNIST, NMNIST, DVS Gesture, and TIDIGITS datasets.
A Novel Twitter Sentiment Analysis Model with Baseline Correlation for Financial Market Prediction with Improved Efficiency
Apr 21, 2020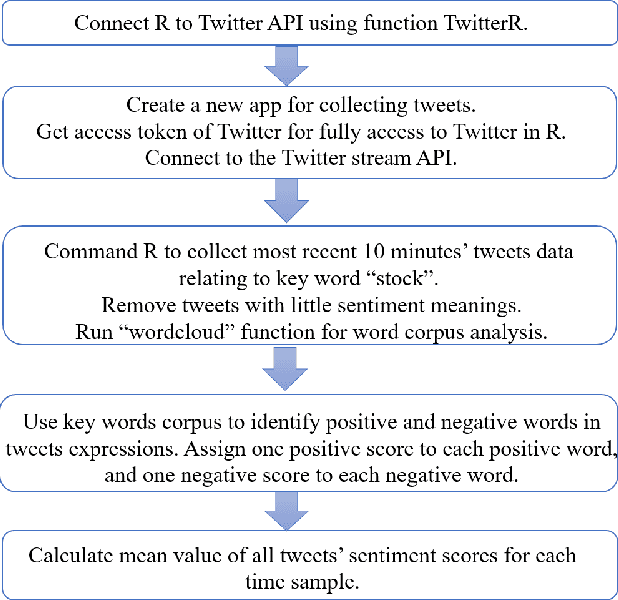
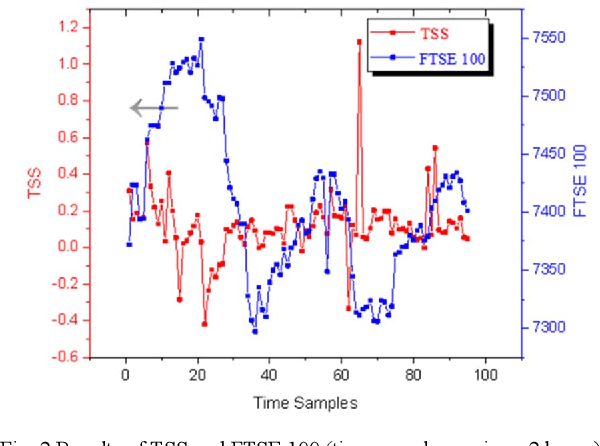
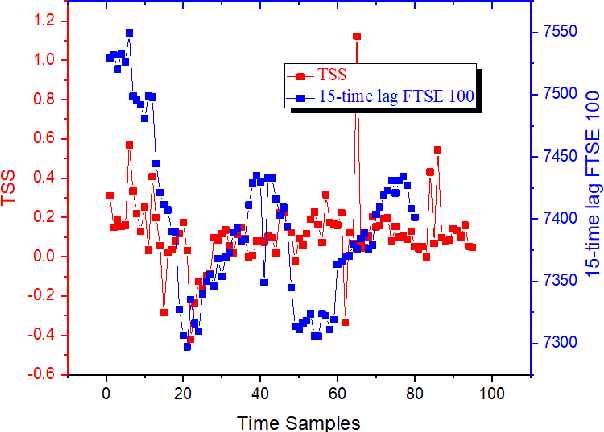
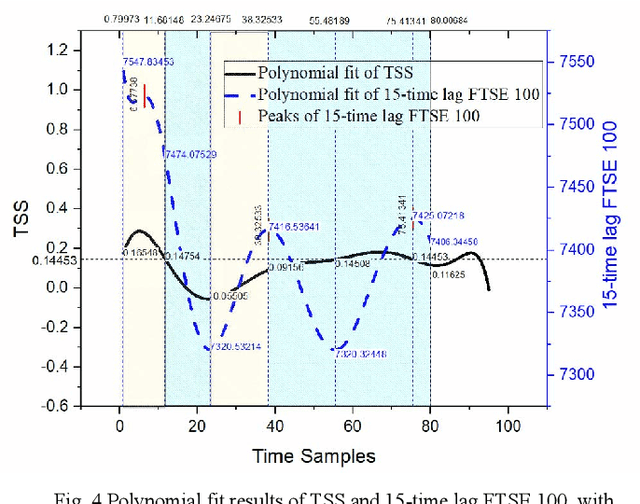
A novel social networks sentiment analysis model is proposed based on Twitter sentiment score (TSS) for real-time prediction of the future stock market price FTSE 100, as compared with conventional econometric models of investor sentiment based on closed-end fund discount (CEFD). The proposed TSS model features a new baseline correlation approach, which not only exhibits a decent prediction accuracy, but also reduces the computation burden and enables a fast decision making without the knowledge of historical data. Polynomial regression, classification modelling and lexicon-based sentiment analysis are performed using R. The obtained TSS predicts the future stock market trend in advance by 15 time samples (30 working hours) with an accuracy of 67.22% using the proposed baseline criterion without referring to historical TSS or market data. Specifically, TSS's prediction performance of an upward market is found far better than that of a downward market. Under the logistic regression and linear discriminant analysis, the accuracy of TSS in predicting the upward trend of the future market achieves 97.87%.
* 2019 Sixth IEEE International Conference on Social Networks Analysis, Management and Security (SNAMS)
Overcoming Negative Transfer: A Survey
Sep 02, 2020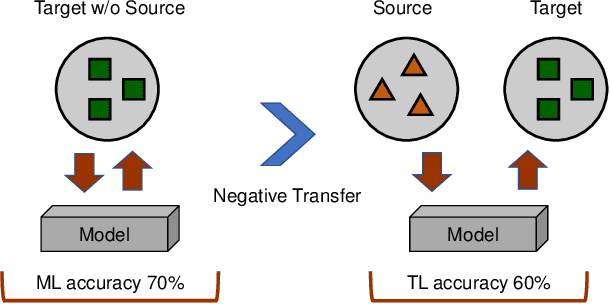
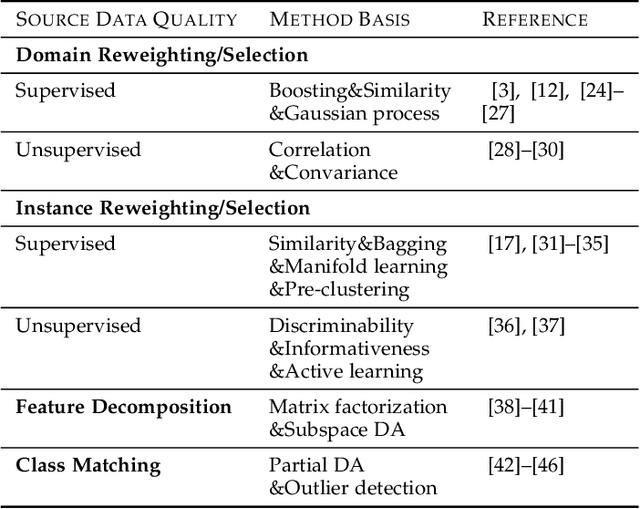
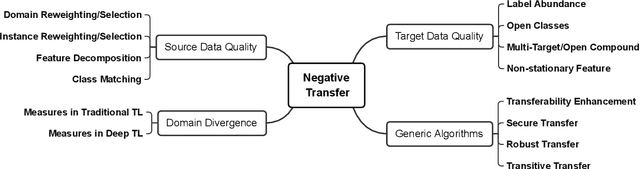
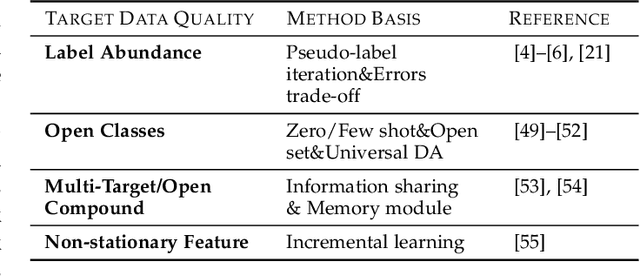
Transfer learning aims to help the target task with little or no training data by leveraging knowledge from one or multi-related auxiliary tasks. In practice, the success of transfer learning is not always guaranteed, negative transfer is a long-standing problem in transfer learning literature, which has been well recognized within the transfer learning community. How to overcome negative transfer has been studied for a long time and has raised increasing attention in recent years. Thus, it is both necessary and challenging to comprehensively review the relevant researches. This survey attempts to analyze the factors related to negative transfer and summarizes the theories and advances of overcoming negative transfer from four crucial aspects: source data quality, target data quality, domain divergence and generic algorithms, which may provide the readers an insight into the current research status and ideas. Additionally, we provided some general guidelines on how to detect and overcome negative transfer on real data, including the negative transfer detection, datasets, baselines, and general routines. The survey provides researchers a framework for better understanding and identifying the research status, fundamental questions, open challenges and future directions of the field.
Extending Answer Set Programs with Neural Networks
Sep 22, 2020
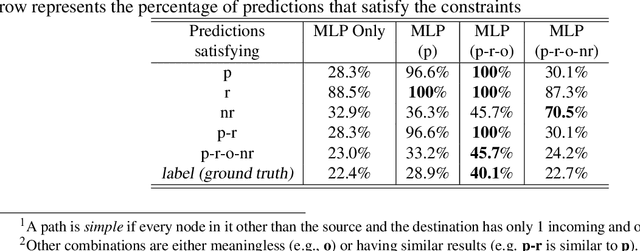
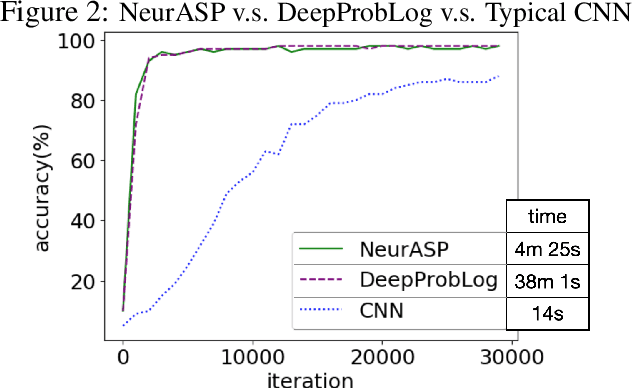
The integration of low-level perception with high-level reasoning is one of the oldest problems in Artificial Intelligence. Recently, several proposals were made to implement the reasoning process in complex neural network architectures. While these works aim at extending neural networks with the capability of reasoning, a natural question that we consider is: can we extend answer set programs with neural networks to allow complex and high-level reasoning on neural network outputs? As a preliminary result, we propose NeurASP -- a simple extension of answer set programs by embracing neural networks where neural network outputs are treated as probability distributions over atomic facts in answer set programs. We show that NeurASP can not only improve the perception accuracy of a pre-trained neural network, but also help to train a neural network better by giving restrictions through logic rules. However, training with NeurASP would take much more time than pure neural network training due to the internal use of a symbolic reasoning engine. For future work, we plan to investigate the potential ways to solve the scalability issue of NeurASP. One potential way is to embed logic programs directly in neural networks. On this route, we plan to first design a SAT solver using neural networks, then extend such a solver to allow logic programs.
* In Proceedings ICLP 2020, arXiv:2009.09158
ConcealNet: An End-to-end Neural Network for Packet Loss Concealment in Deep Speech Emotion Recognition
May 15, 2020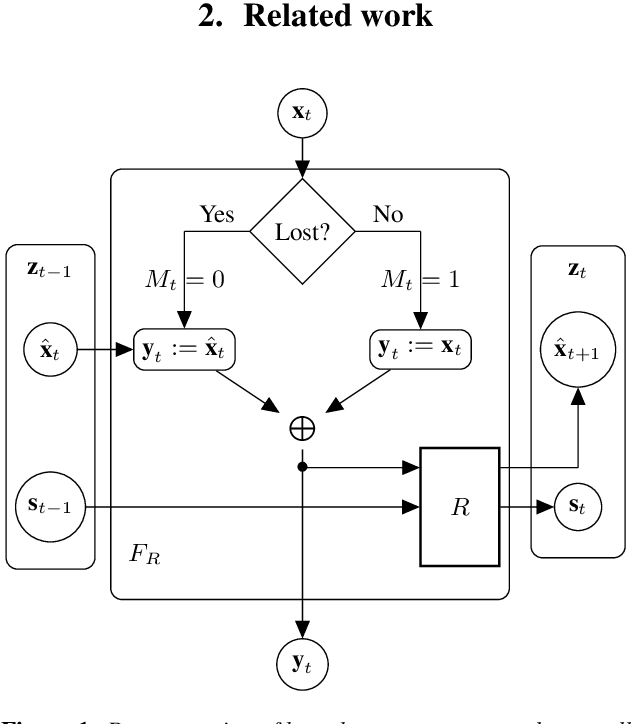
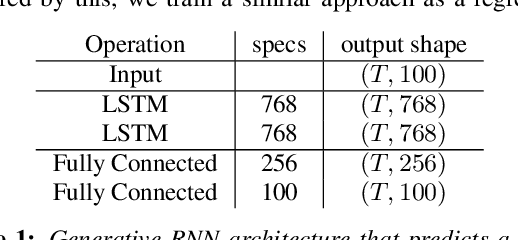
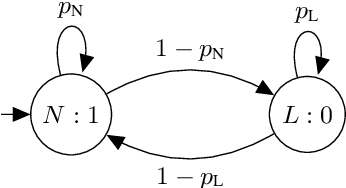
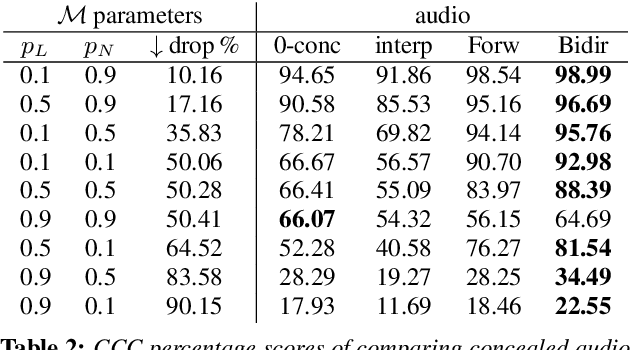
Packet loss is a common problem in data transmission, including speech data transmission. This may affect a wide range of applications that stream audio data, like streaming applications or speech emotion recognition (SER). Packet Loss Concealment (PLC) is any technique of facing packet loss. Simple PLC baselines are 0-substitution or linear interpolation. In this paper, we present a concealment wrapper, which can be used with stacked recurrent neural cells. The concealment cell can provide a recurrent neural network (ConcealNet), that performs real-time step-wise end-to-end PLC at inference time. Additionally, extending this with an end-to-end emotion prediction neural network provides a network that performs SER from audio with lost frames, end-to-end. The proposed model is compared against the fore-mentioned baselines. Additionally, a bidirectional variant with better performance is utilised. For evaluation, we chose the public RECOLA dataset given its long audio tracks with continuous emotion labels. ConcealNet is evaluated on the reconstruction of the audio and the quality of corresponding emotions predicted after that. The proposed ConcealNet model has shown considerable improvement, for both audio reconstruction and the corresponding emotion prediction, in environments that do not have losses with long duration, even when the losses occur frequently.
SceneGen: Generative Contextual Scene Augmentation using Scene Graph Priors
Sep 30, 2020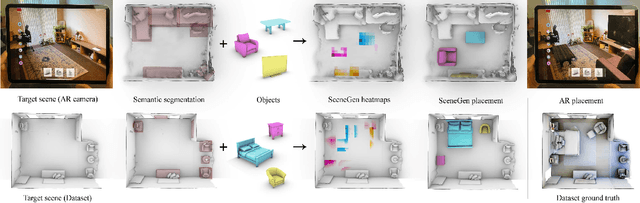

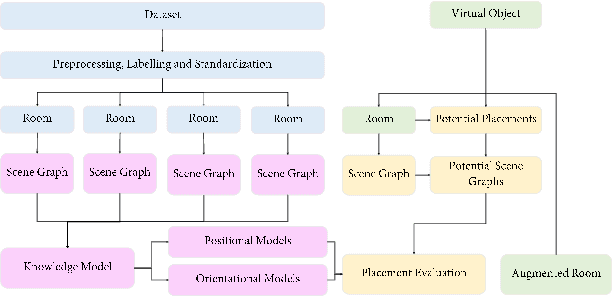
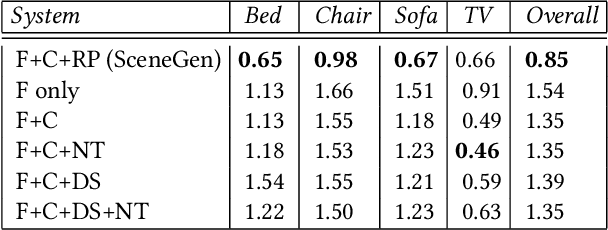
Spatial computing experiences are constrained by the real-world surroundings of the user. In such experiences, augmenting virtual objects to existing scenes require a contextual approach, where geometrical conflicts are avoided, and functional and plausible relationships to other objects are maintained in the target environment. Yet, due to the complexity and diversity of user environments, automatically calculating ideal positions of virtual content that is adaptive to the context of the scene is considered a challenging task. Motivated by this problem, in this paper we introduce SceneGen, a generative contextual augmentation framework that predicts virtual object positions and orientations within existing scenes. SceneGen takes a semantically segmented scene as input, and outputs positional and orientational probability maps for placing virtual content. We formulate a novel spatial Scene Graph representation, which encapsulates explicit topological properties between objects, object groups, and the room. We believe providing explicit and intuitive features plays an important role in informative content creation and user interaction of spatial computing settings, a quality that is not captured in implicit models. We use kernel density estimation (KDE) to build a multivariate conditional knowledge model trained using prior spatial Scene Graphs extracted from real-world 3D scanned data. To further capture orientational properties, we develop a fast pose annotation tool to extend current real-world datasets with orientational labels. Finally, to demonstrate our system in action, we develop an Augmented Reality application, in which objects can be contextually augmented in real-time.
Online Adaptive Learning for Runtime Resource Management of Heterogeneous SoCs
Aug 22, 2020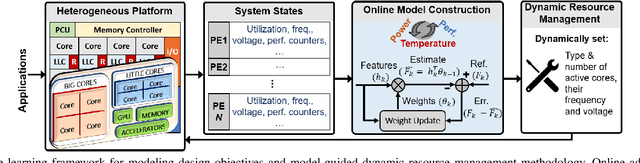
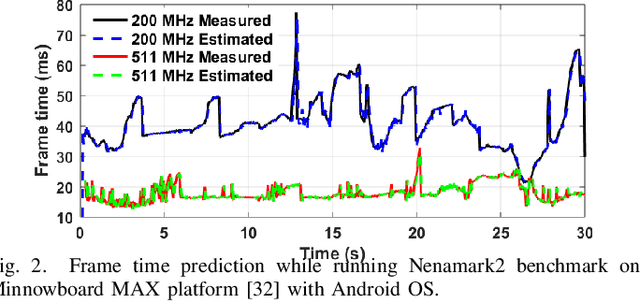
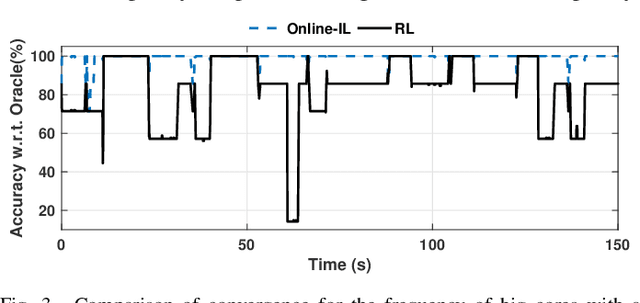
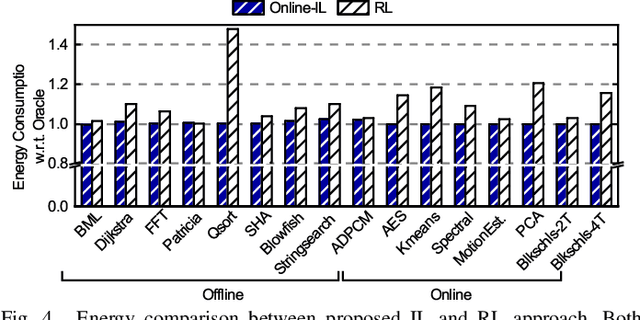
Dynamic resource management has become one of the major areas of research in modern computer and communication system design due to lower power consumption and higher performance demands. The number of integrated cores, level of heterogeneity and amount of control knobs increase steadily. As a result, the system complexity is increasing faster than our ability to optimize and dynamically manage the resources. Moreover, offline approaches are sub-optimal due to workload variations and large volume of new applications unknown at design time. This paper first reviews recent online learning techniques for predicting system performance, power, and temperature. Then, we describe the use of predictive models for online control using two modern approaches: imitation learning (IL) and an explicit nonlinear model predictive control (NMPC). Evaluations on a commercial mobile platform with 16 benchmarks show that the IL approach successfully adapts the control policy to unknown applications. The explicit NMPC provides 25% energy savings compared to a state-of-the-art algorithm for multi-variable power management of modern GPU sub-systems.