 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Community embeddings reveal large-scale cultural organization of online platforms
Oct 02, 2020

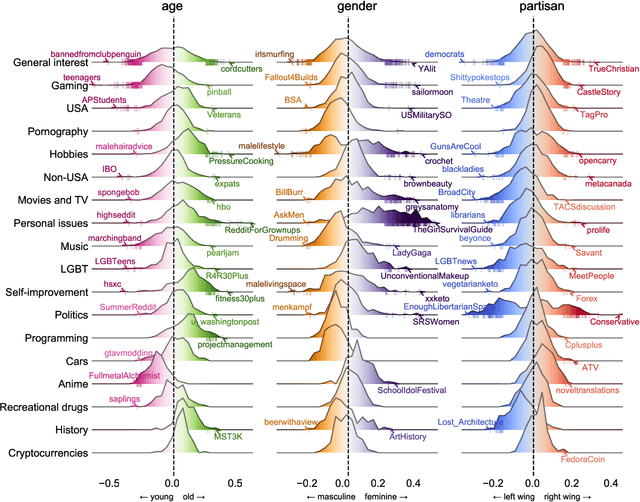
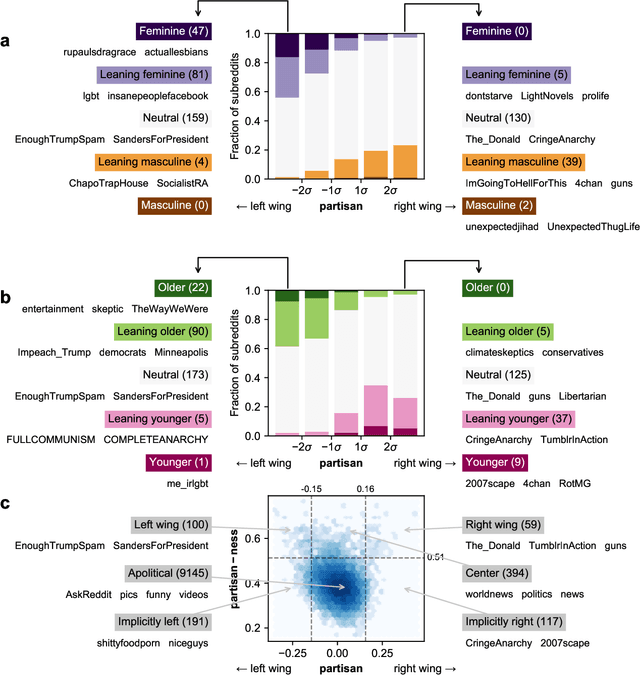
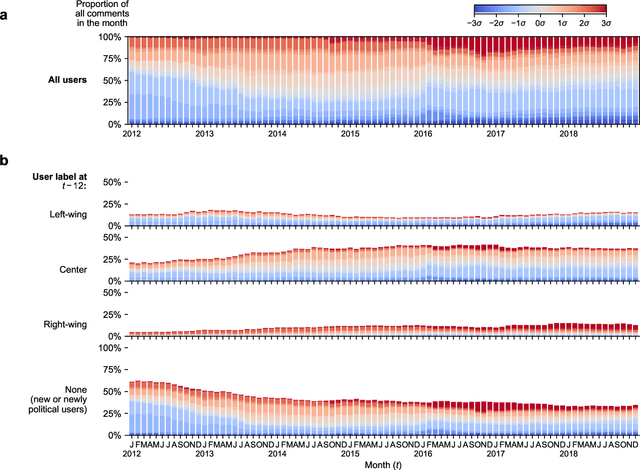
Optimism about the Internet's potential to bring the world together has been tempered by concerns about its role in inflaming the 'culture wars'. Via mass selection into like-minded groups, online society may be becoming more fragmented and polarized, particularly with respect to partisan differences. However, our ability to measure the cultural makeup of online communities, and in turn understand the cultural structure of online platforms, is limited by the pseudonymous, unstructured, and large-scale nature of digital discussion. Here we develop a neural embedding methodology to quantify the positioning of online communities along cultural dimensions by leveraging large-scale patterns of aggregate behaviour. Applying our methodology to 4.8B Reddit comments made in 10K communities over 14 years, we find that the macro-scale community structure is organized along cultural lines, and that relationships between online cultural concepts are more complex than simply reflecting their offline analogues. Examining political content, we show Reddit underwent a significant polarization event around the 2016 U.S. presidential election, and remained highly polarized for years afterward. Contrary to conventional wisdom, however, instances of individual users becoming more polarized over time are rare; the majority of platform-level polarization is driven by the arrival of new and newly political users. Our methodology is broadly applicable to the study of online culture, and our findings have implications for the design of online platforms, understanding the cultural contexts of online content, and quantifying cultural shifts in online behaviour.
Anomaly Detection in Cloud Components
May 18, 2020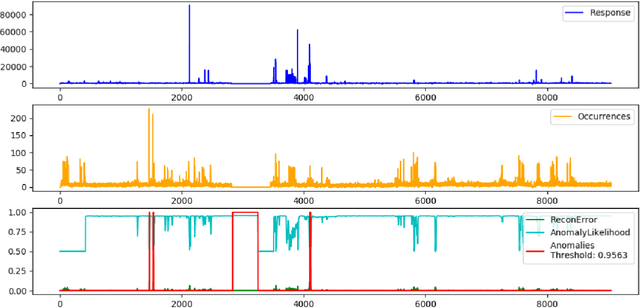
Cloud platforms, under the hood, consist of a complex inter-connected stack of hardware and software components. Each of these components can fail which may lead to an outage. Our goal is to improve the quality of Cloud services through early detection of such failures by analyzing resource utilization metrics. We tested Gated-Recurrent-Unit-based autoencoder with a likelihood function to detect anomalies in various multi-dimensional time series and achieved high performance.
On the study of the Beran estimator for generalized censoring indicators
Sep 03, 2020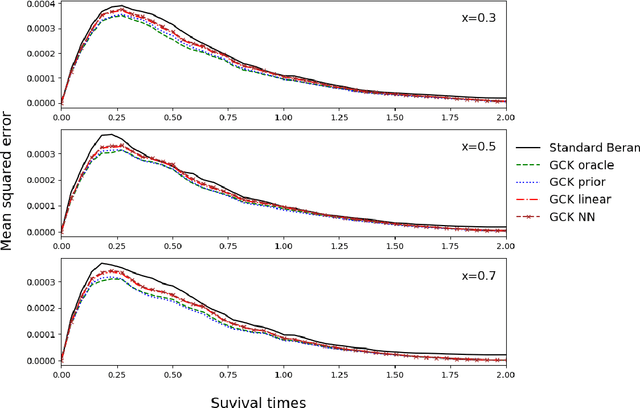

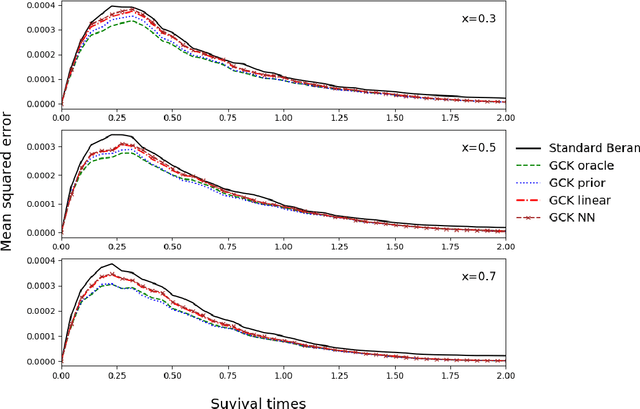

Along with the analysis of time-to-event data, it is common to assume that only partial information is given at hand. In the presence of right-censored data with covariates, the conditional Kaplan-Meier estimator (also referred as the Beran estimator) is known to propose a consistent estimate for the lifetimes conditional survival function. However, a necessary condition is the clear knowledge of whether each individual is censored or not, although, this information might be incomplete or even totally absent in practice. We thus propose a study on the Beran estimator when the censoring indicator is not clearly specified. From this, we provide a new estimator for the conditional survival function and establish its asymptotic normality under mild conditions. We further study the supervised learning problem where the conditional survival function is to be predicted with no censorship indicators. To this aim, we investigate various approaches estimating the conditional expectation for the censoring indicator. Along with the theoretical results, we illustrate how the estimators work for small samples by means of a simulation study and show their practical applicability with the analysis of synthetic data and the study of real data for the prognosis of monoclonal gammopathy.
MAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Sep 23, 2020

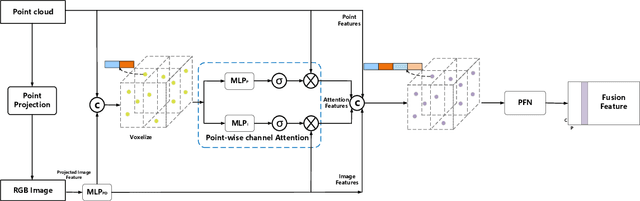
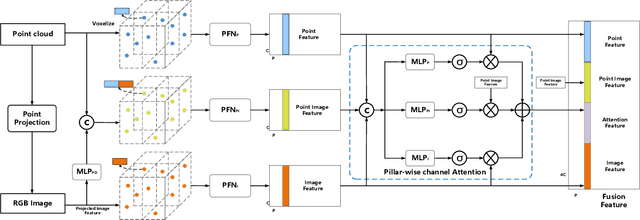
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
A divide-and-conquer algorithm for quantum state preparation
Aug 04, 2020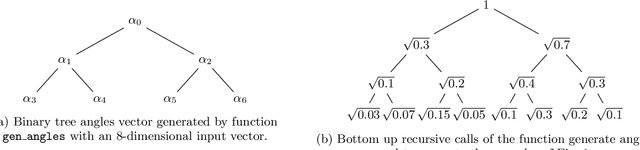
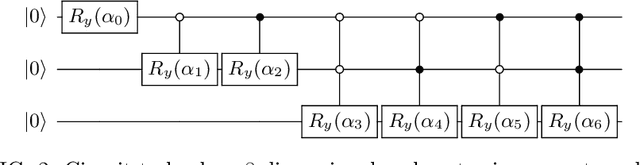
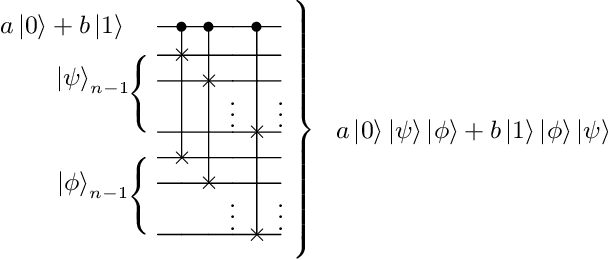
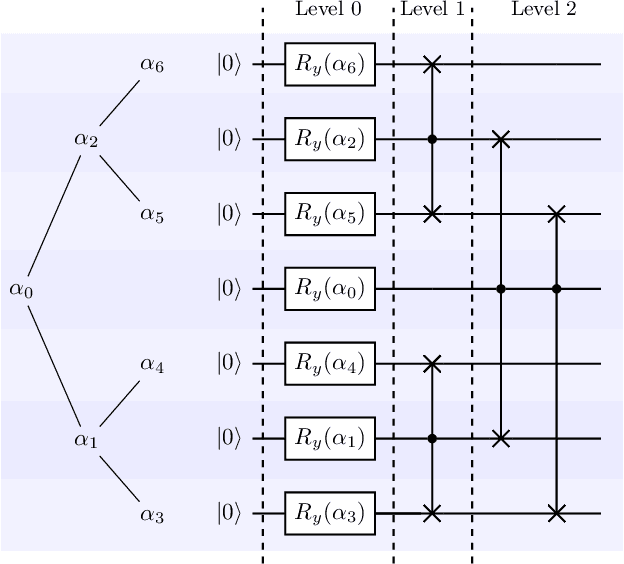
Advantages in several fields of research and industry are expected with the rise of quantum computers. However, the computational cost to load classical data in quantum computers can impose restrictions on possible quantum speedups. Known algorithms to create arbitrary quantum states require quantum circuits with depth O(N) to load an N-dimensional vector. Here, we show that it is possible to load an N-dimensional vector with a quantum circuit with polylogarithmic depth and entangled information in ancillary qubits. Results show that we can efficiently load data in quantum devices using a divide-and-conquer strategy to exchange computational time for space. We demonstrate a proof of concept on a real quantum device and present two applications for quantum machine learning. We expect that this new loading strategy allows the quantum speedup of tasks that require to load a significant volume of information to quantum devices.
Reconfigurable Behavior Trees: Towards an Executive Framework Meeting High-level Decision Making and Control Layer Features
Jul 21, 2020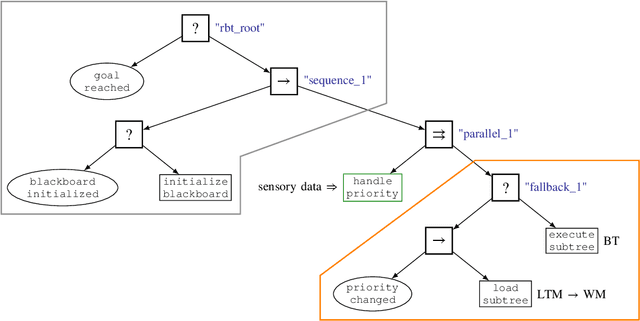
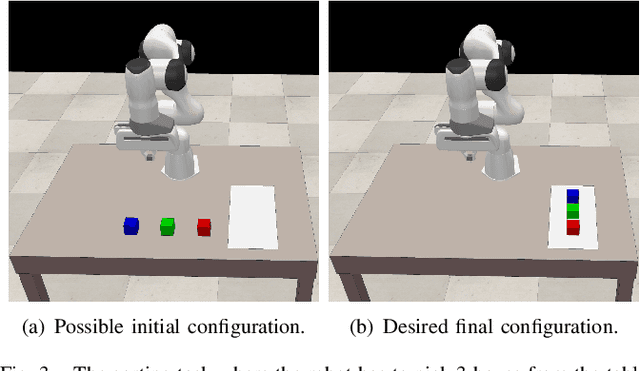
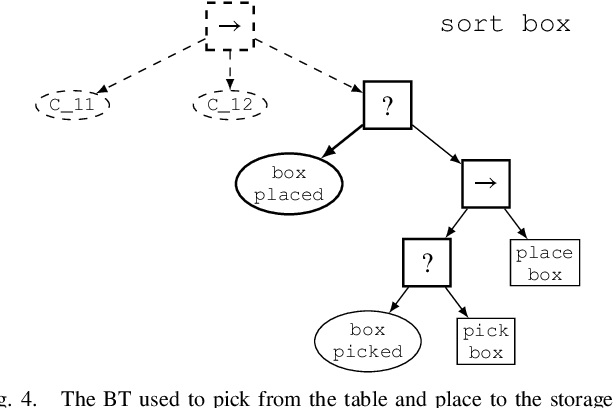
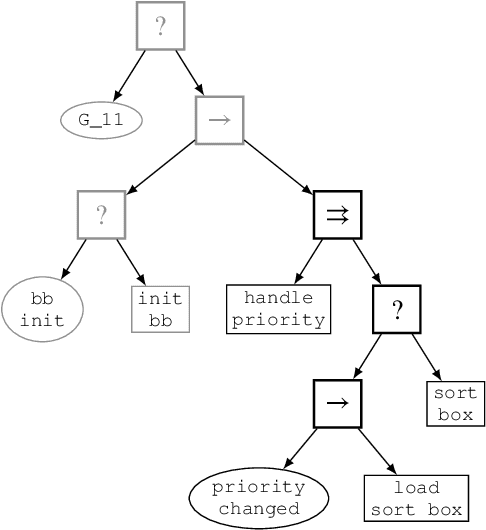
Behavior Trees constitute a widespread AI tool which has been successfully spun out in robotics. Their advantages include simplicity, modularity, and reusability of code. However, Behavior Trees remain a high-level decision making engine; control features cannot be easily integrated. This paper proposes the Reconfigurable Behavior Trees (RBTs), an extension of the traditional BTs that considers physical constraints from the robotic environment in the decision making process. We endow RBTs with continuous sensory information that permits the online monitoring of the task execution. The resulting stimulus-driven architecture is capable of dynamically handling changes in the executive context while keeping the execution time low. The proposed framework is evaluated on a set of robotic experiments. The results show that RBTs are a promising approach for robotic task representation, monitoring, and execution.
Faster Binary Embeddings for Preserving Euclidean Distances
Oct 01, 2020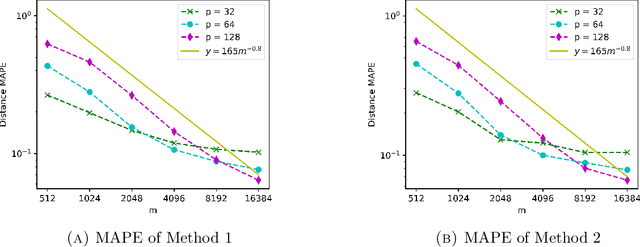
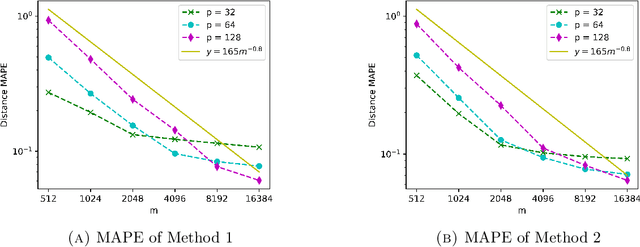
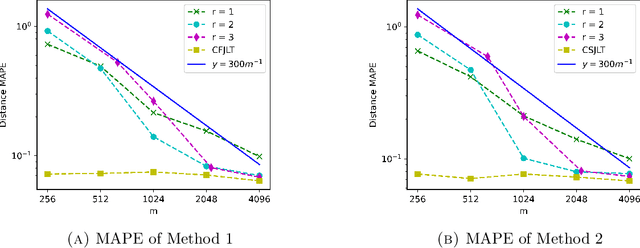
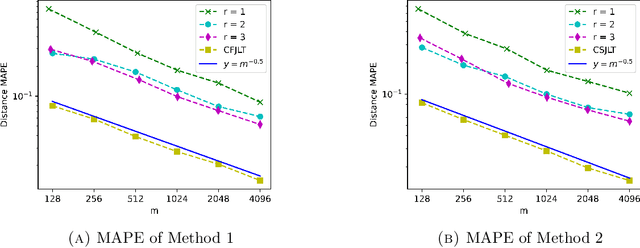
We propose a fast, distance-preserving, binary embedding algorithm to transform a high-dimensional dataset $\mathcal{T}\subseteq\mathbb{R}^n$ into binary sequences in the cube $\{\pm 1\}^m$. When $\mathcal{T}$ consists of well-spread (i.e., non-sparse) vectors, our embedding method applies a stable noise-shaping quantization scheme to $A x$ where $A\in\mathbb{R}^{m\times n}$ is a sparse Gaussian random matrix. This contrasts with most binary embedding methods, which usually use $x\mapsto \mathrm{sign}(Ax)$ for the embedding. Moreover, we show that Euclidean distances among the elements of $\mathcal{T}$ are approximated by the $\ell_1$ norm on the images of $\{\pm 1\}^m$ under a fast linear transformation. This again contrasts with standard methods, where the Hamming distance is used instead. Our method is both fast and memory efficient, with time complexity $O(m)$ and space complexity $O(m)$. Further, we prove that the method is accurate and its associated error is comparable to that of a continuous valued Johnson-Lindenstrauss embedding plus a quantization error that admits a polynomial decay as the embedding dimension $m$ increases. Thus the length of the binary codes required to achieve a desired accuracy is quite small, and we show it can even be compressed further without compromising the accuracy. To illustrate our results, we test the proposed method on natural images and show that it achieves strong performance.
Leveraging Organizational Resources to Adapt Models to New Data Modalities
Aug 23, 2020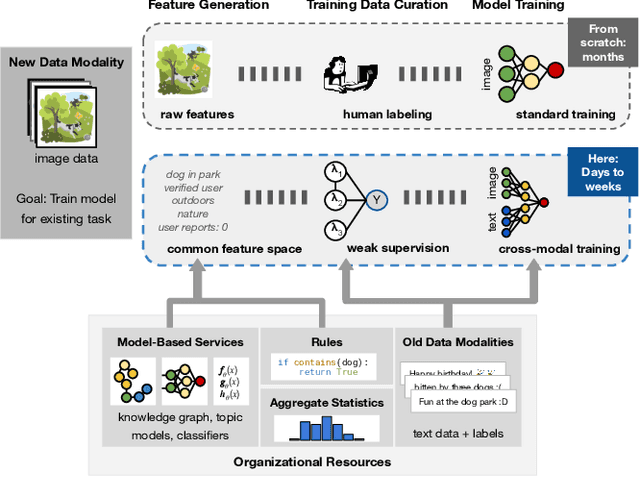

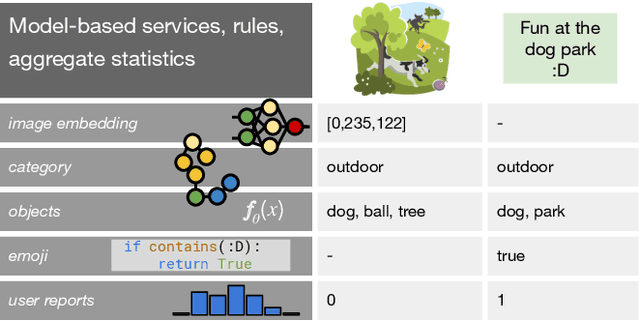
As applications in large organizations evolve, the machine learning (ML) models that power them must adapt the same predictive tasks to newly arising data modalities (e.g., a new video content launch in a social media application requires existing text or image models to extend to video). To solve this problem, organizations typically create ML pipelines from scratch. However, this fails to utilize the domain expertise and data they have cultivated from developing tasks for existing modalities. We demonstrate how organizational resources, in the form of aggregate statistics, knowledge bases, and existing services that operate over related tasks, enable teams to construct a common feature space that connects new and existing data modalities. This allows teams to apply methods for training data curation (e.g., weak supervision and label propagation) and model training (e.g., forms of multi-modal learning) across these different data modalities. We study how this use of organizational resources composes at production scale in over 5 classification tasks at Google, and demonstrate how it reduces the time needed to develop models for new modalities from months to weeks to days.
Designing GANs: A Likelihood Ratio Approach
Feb 06, 2020
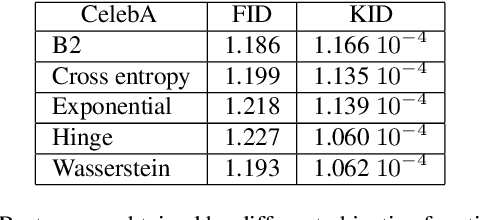
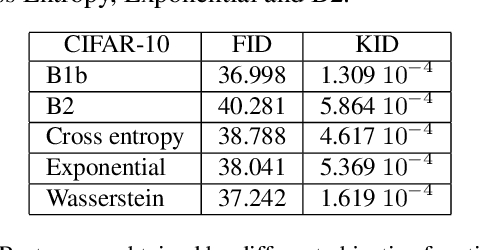

We are interested in the design of generative adversarial networks. The training of these mathematical structures requires the definition of proper min-max optimization problems. We propose a simple methodology for constructing such problems assuring, at the same time, that they provide the correct answer. We give characteristic examples developed by our method, some of which can be recognized from other applications and some introduced for the first time. We compare various possibilities by applying them to well known datasets using neural networks of different configurations and sizes.
Cable Estimation-Based Control for Wire-Borne Underactuated Brachiating Robots: A Combined Direct-Indirect Adaptive Robust Approach
Aug 11, 2020
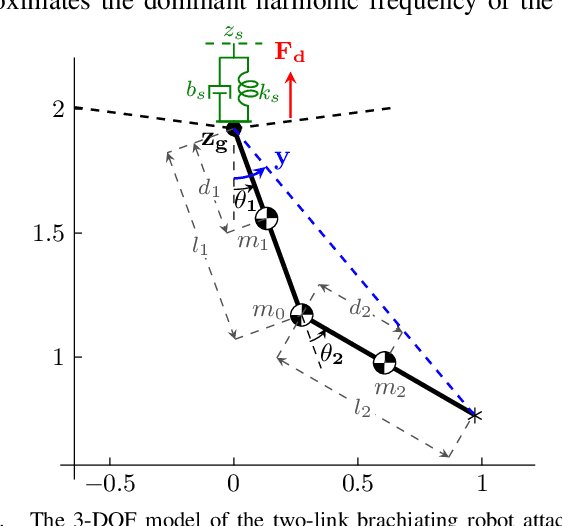
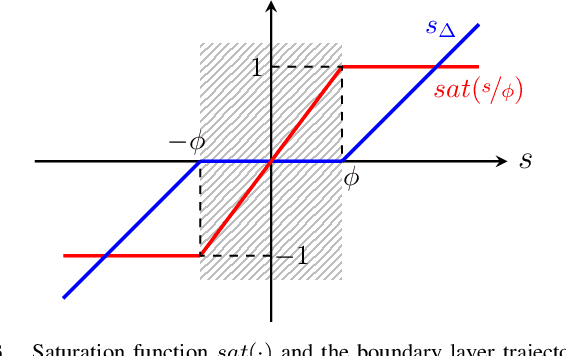
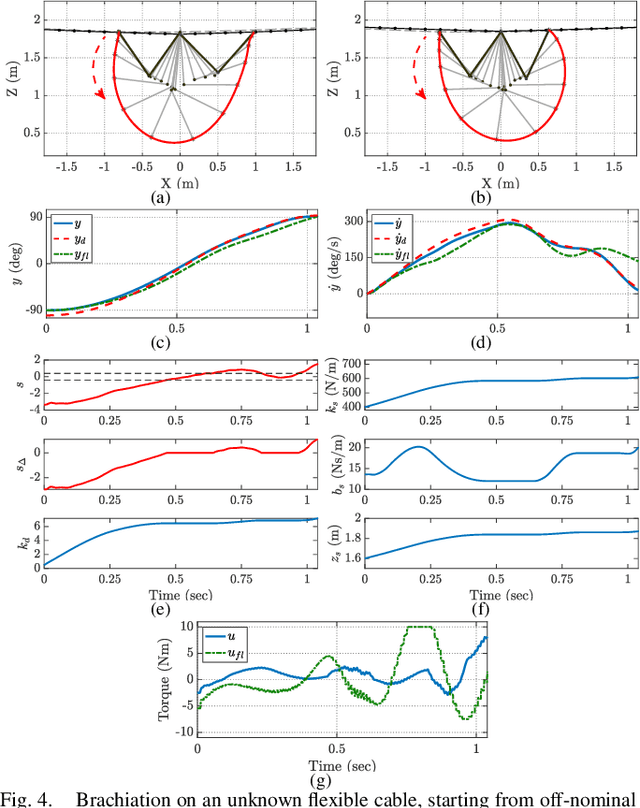
In this paper, we present an online adaptive robust control framework for underactuated brachiating robots traversing flexible cables. Since the dynamic model of a flexible body is unknown in practice, we propose an indirect adaptive estimation scheme to approximate the unknown dynamic effects of the flexible cable as an external force with parametric uncertainties. A boundary layer-based sliding mode control is then designed to compensate for the residual unmodeled dynamics and time-varying disturbances, in which the control gain is updated by an auxiliary direct adaptive control mechanism. Stability analysis and derivation of adaptation laws are carried out through a Lyapunov approach, which formally guarantees the stability and tracking performance of the robot-cable system. Simulation experiments and comparison with a baseline controller show that the combined direct-indirect adaptive robust control framework achieves reliable tracking performance and adaptive system identification, enabling the robot to traverse flexible cables in the presence of unmodeled dynamics, parametric uncertainties and unstructured disturbances.