 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Paraphrase Generation as Zero-Shot Multilingual Translation: Disentangling Semantic Similarity from Lexical and Syntactic Diversity
Aug 11, 2020

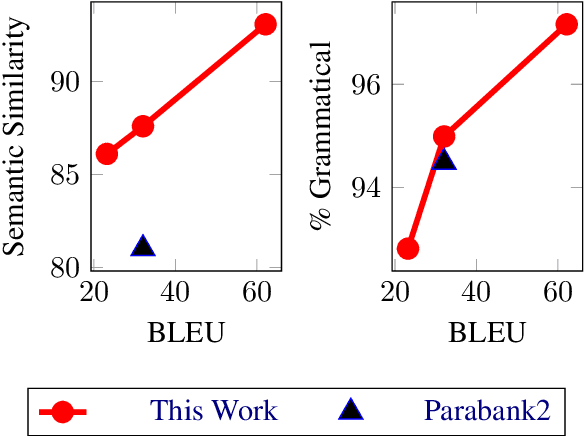
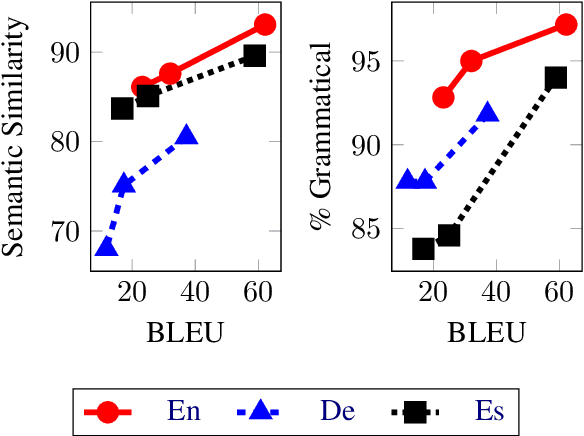
Recent work has shown that a multilingual neural machine translation (NMT) model can be used to judge how well a sentence paraphrases another sentence in the same language; however, attempting to generate paraphrases from the model using beam search produces trivial copies or near copies. We introduce a simple paraphrase generation algorithm which discourages the production of n-grams that are present in the input. Our approach enables paraphrase generation in many languages from a single multilingual NMT model. Furthermore, the trade-off between semantic similarity and lexical/syntactic diversity between the input and output can be controlled at generation time. We conduct human evaluation to compare our method to a paraphraser trained on a large English synthetic paraphrase database and find that our model produces paraphrases that better preserve semantic meaning and grammatically, for the same level of lexical/syntactic diversity. Additional smaller human assessments demonstrate our approach also works in non-English languages.
Variance Reduced EXTRA and DIGing and Their Optimal Acceleration for Strongly Convex Decentralized Optimization
Oct 10, 2020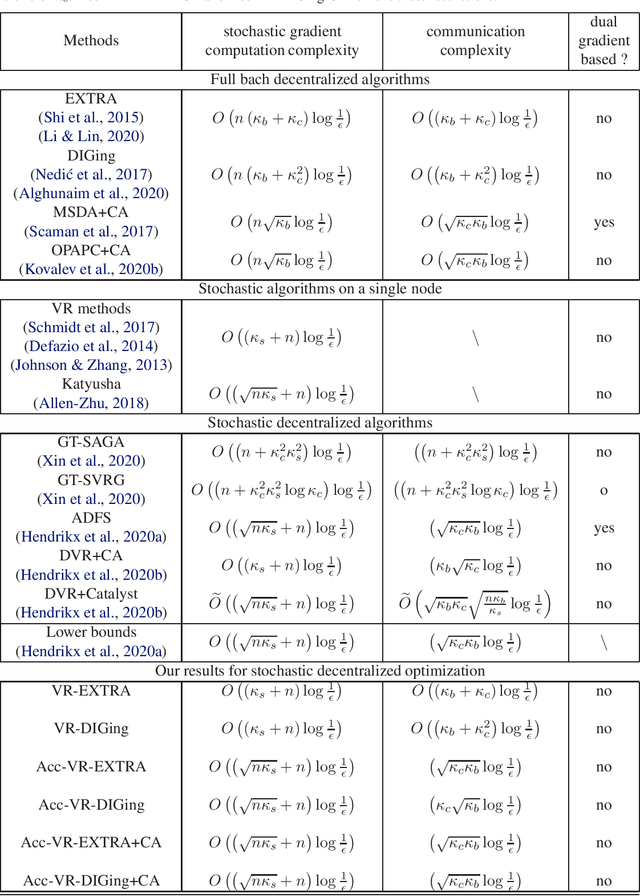
We study stochastic decentralized optimization for the problem of training machine learning models with large-scale distributed data. We extend the widely used EXTRA and DIGing methods with variance reduction (VR), and propose two methods: VR-EXTRA and VR-DIGing. The proposed VR-EXTRA requires the time of $O((\kappa_s+n)\log\frac{1}{\epsilon})$ stochastic gradient evaluations and $O((\kappa_b+\kappa_c)\log\frac{1}{\epsilon})$ communication rounds to reach precision $\epsilon$, where $\kappa_s$ and $\kappa_b$ are the stochastic condition number and batch condition number for strongly convex and smooth problems, respectively, $\kappa_c$ is the condition number of the communication network, and $n$ is the sample size on each distributed node. The proposed VR-DIGing has a little higher communication cost of $O((\kappa_b+\kappa_c^2)\log\frac{1}{\epsilon})$. Our stochastic gradient computation complexities are the same as the ones of single-machine VR methods, such as SAG, SAGA, and SVRG, and our communication complexities keep the same as those of EXTRA and DIGing, respectively. To further speed up the convergence, we also propose the accelerated VR-EXTRA and VR-DIGing with both the optimal $O((\sqrt{n\kappa_s}+n)\log\frac{1}{\epsilon})$ stochastic gradient computation complexity and $O(\sqrt{\kappa_b\kappa_c}\log\frac{1}{\epsilon})$ communication complexity. Our stochastic gradient computation complexity is also the same as the ones of single-machine accelerated VR methods, such as Katyusha, and our communication complexity keeps the same as those of accelerated full batch decentralized methods, such as MSDA.
Motion Planning for Collision-resilient Mobile Robots in Obstacle-cluttered Unknown Environments with Risk Reward Trade-offs
Sep 04, 2020
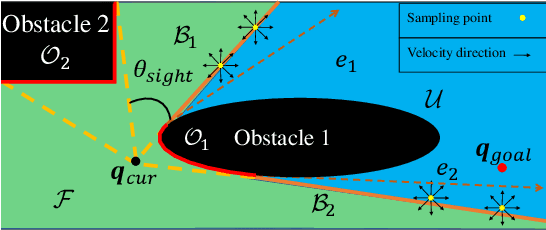
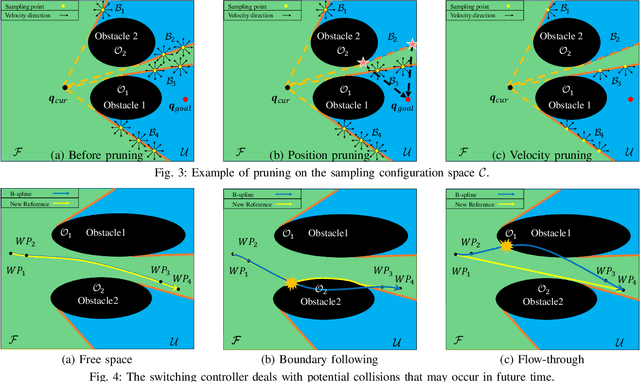

Collision avoidance in unknown obstacle-cluttered environments may not always be feasible. This paper focuses on an emerging paradigm shift in which potential collisions with the environment can be harnessed instead of being avoided altogether. To this end, we introduce a new sampling-based online planning algorithm that can explicitly handle the risk of colliding with the environment and can switch between collision avoidance and collision exploitation. Central to the planner's capabilities is a novel joint optimization function that evaluates the effect of possible collisions using a reflection model. This way, the planner can make deliberate decisions to collide with the environment if such collision is expected to help the robot make progress toward its goal. To make the algorithm online, we present a state expansion pruning technique that significantly reduces the search space while ensuring completeness. The proposed algorithm is evaluated experimentally with a built-in-house holonomic wheeled robot that can withstand collisions. We perform an extensive parametric study to investigate trade-offs between (user-tuned) levels of risk, deliberate collision decision making, and trajectory statistics such as time to reach the goal and path length.
Learning Event-triggered Control from Data through Joint Optimization
Aug 11, 2020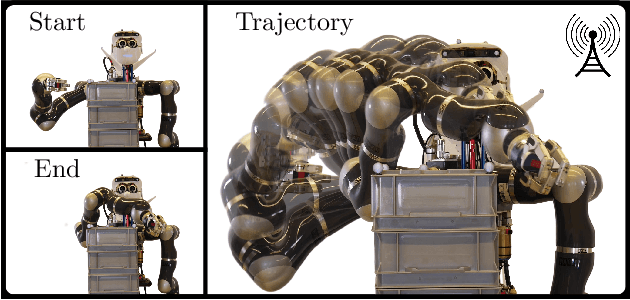
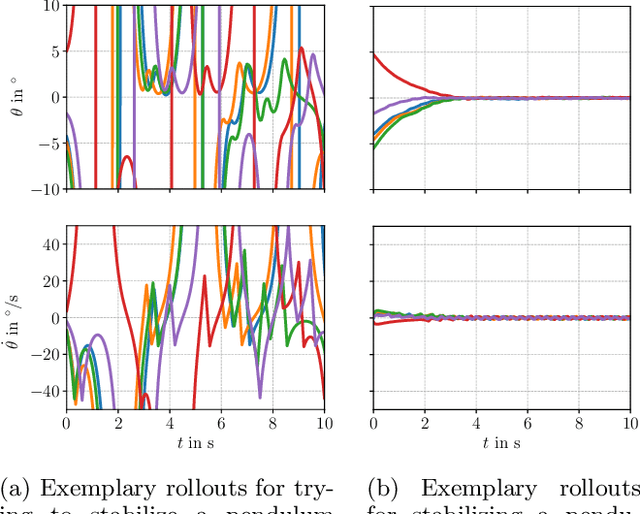
We present a framework for model-free learning of event-triggered control strategies. Event-triggered methods aim to achieve high control performance while only closing the feedback loop when needed. This enables resource savings, e.g., network bandwidth if control commands are sent via communication networks, as in networked control systems. Event-triggered controllers consist of a communication policy, determining when to communicate, and a control policy, deciding what to communicate. It is essential to jointly optimize the two policies since individual optimization does not necessarily yield the overall optimal solution. To address this need for joint optimization, we propose a novel algorithm based on hierarchical reinforcement learning. The resulting algorithm is shown to accomplish high-performance control in line with resource savings and scales seamlessly to nonlinear and high-dimensional systems. The method's applicability to real-world scenarios is demonstrated through experiments on a six degrees of freedom real-time controlled manipulator. Further, we propose an approach towards evaluating the stability of the learned neural network policies.
An Index-based Deterministic Asymptotically Optimal Algorithm for Constrained Multi-armed Bandit Problems
Jul 29, 2020For the model of constrained multi-armed bandit, we show that by construction there exists an index-based deterministic asymptotically optimal algorithm. The optimality is achieved by the convergence of the probability of choosing an optimal feasible arm to one over infinite horizon. The algorithm is built upon Locatelli et al.'s "anytime parameter-free thresholding" algorithm under the assumption that the optimal value is known. We provide a finite-time bound to the probability of the asymptotic optimality given as 1-O(|A|Te^{-T}) where T is the horizon size and A is the set of the arms in the bandit. We then study a relaxed-version of the algorithm in a general form that estimates the optimal value and discuss the asymptotic optimality of the algorithm after a sufficiently large T with examples.
Compositional Video Synthesis with Action Graphs
Jun 27, 2020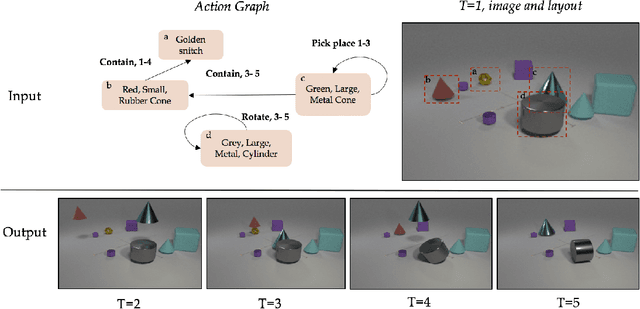
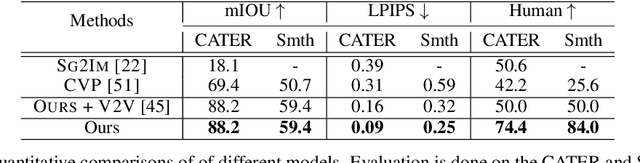
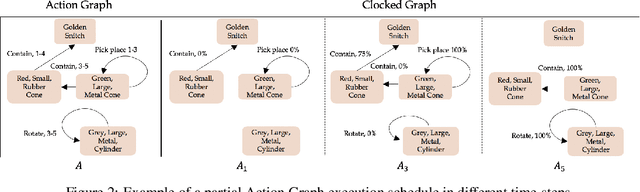
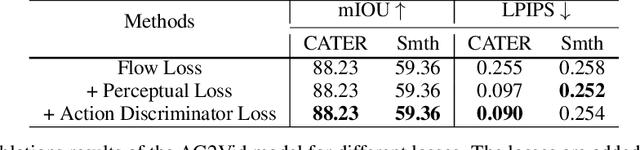
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
Tensor Decompositions for temporal knowledge base completion
Apr 10, 2020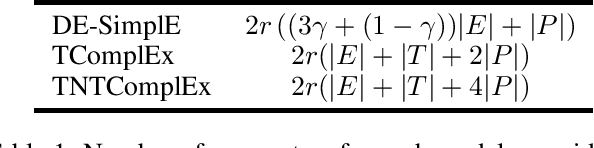
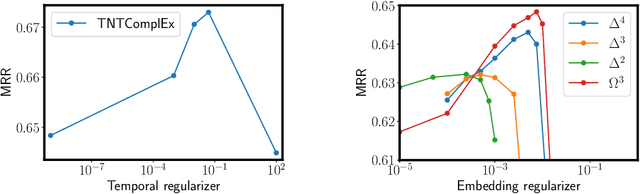
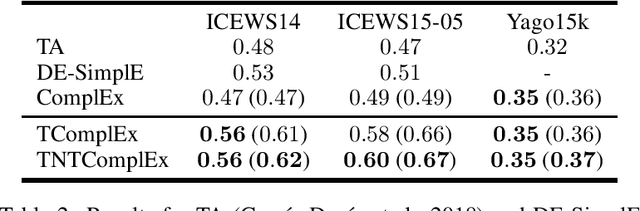
Most algorithms for representation learning and link prediction in relational data have been designed for static data. However, the data they are applied to usually evolves with time, such as friend graphs in social networks or user interactions with items in recommender systems. This is also the case for knowledge bases, which contain facts such as (US, has president, B. Obama, [2009-2017]) that are valid only at certain points in time. For the problem of link prediction under temporal constraints, i.e., answering queries such as (US, has president, ?, 2012), we propose a solution inspired by the canonical decomposition of tensors of order 4. We introduce new regularization schemes and present an extension of ComplEx (Trouillon et al., 2016) that achieves state-of-the-art performance. Additionally, we propose a new dataset for knowledge base completion constructed from Wikidata, larger than previous benchmarks by an order of magnitude, as a new reference for evaluating temporal and non-temporal link prediction methods.
Pretrained Generalized Autoregressive Model with Adaptive Probabilistic Label Clusters for Extreme Multi-label Text Classification
Jul 05, 2020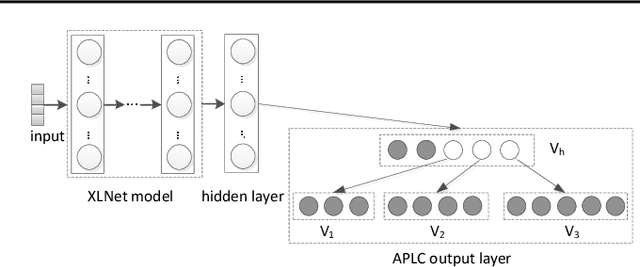
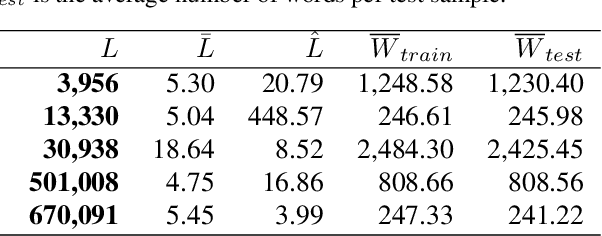
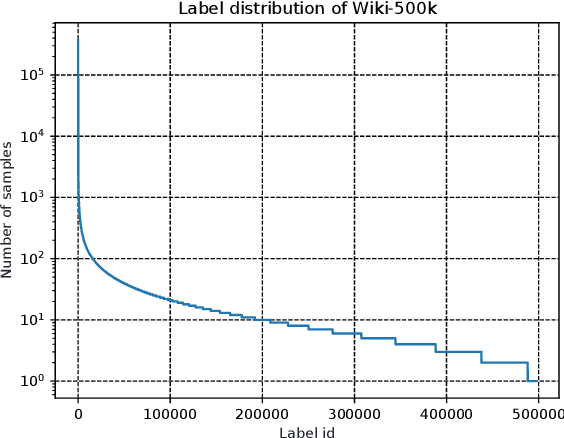
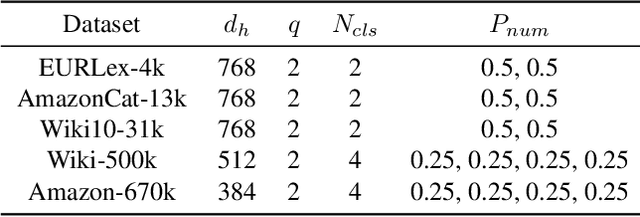
Extreme multi-label text classification (XMTC) is a task for tagging a given text with the most relevant labels from an extremely large label set. We propose a novel deep learning method called APLC-XLNet. Our approach fine-tunes the recently released generalized autoregressive pretrained model (XLNet) to learn a dense representation for the input text. We propose Adaptive Probabilistic Label Clusters (APLC) to approximate the cross entropy loss by exploiting the unbalanced label distribution to form clusters that explicitly reduce the computational time. Our experiments, carried out on five benchmark datasets, show that our approach significantly outperforms existing state-of-the-art methods. Our source code is available publicly at https://github.com/huiyegit/APLC_XLNet.
Real-Time Hand Tracking Using a Sum of Anisotropic Gaussians Model
Feb 11, 2016


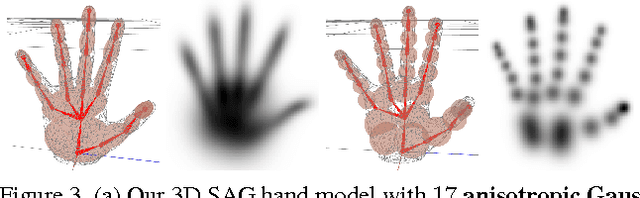
Real-time marker-less hand tracking is of increasing importance in human-computer interaction. Robust and accurate tracking of arbitrary hand motion is a challenging problem due to the many degrees of freedom, frequent self-occlusions, fast motions, and uniform skin color. In this paper, we propose a new approach that tracks the full skeleton motion of the hand from multiple RGB cameras in real-time. The main contributions include a new generative tracking method which employs an implicit hand shape representation based on Sum of Anisotropic Gaussians (SAG), and a pose fitting energy that is smooth and analytically differentiable making fast gradient based pose optimization possible. This shape representation, together with a full perspective projection model, enables more accurate hand modeling than a related baseline method from literature. Our method achieves better accuracy than previous methods and runs at 25 fps. We show these improvements both qualitatively and quantitatively on publicly available datasets.
* 8 pages, Accepted version of paper published at 3DV 2014
Paying Per-label Attention for Multi-label Extraction from Radiology Reports
Aug 04, 2020Training medical image analysis models requires large amounts of expertly annotated data which is time-consuming and expensive to obtain. Images are often accompanied by free-text radiology reports which are a rich source of information. In this paper, we tackle the automated extraction of structured labels from head CT reports for imaging of suspected stroke patients, using deep learning. Firstly, we propose a set of 31 labels which correspond to radiographic findings (e.g. hyperdensity) and clinical impressions (e.g. haemorrhage) related to neurological abnormalities. Secondly, inspired by previous work, we extend existing state-of-the-art neural network models with a label-dependent attention mechanism. Using this mechanism and simple synthetic data augmentation, we are able to robustly extract many labels with a single model, classified according to the radiologist's reporting (positive, uncertain, negative). This approach can be used in further research to effectively extract many labels from medical text.