 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic Multi-level Composition Optimization Algorithms with Level-Independent Convergence Rates
Aug 24, 2020

In this paper, we study smooth stochastic multi-level composition optimization problems, where the objective function is a nested composition of $T$ functions. We assume access to noisy evaluations of the functions and their gradients, through a stochastic first-order oracle. For solving this class of problems, we propose two algorithms using moving-average stochastic estimates, and analyze their convergence to an $\epsilon$-stationary point of the problem. We show that the first algorithm, which is a generalization of [22] to the $T$ level case, can achieve a sample complexity of $\mathcal{O}(1/\epsilon^6)$ by using mini-batches of samples in each iteration. By modifying this algorithm using linearized stochastic estimates of the function values, we improve the sample complexity to $\mathcal{O}(1/\epsilon^4)$. This modification also removes the requirement of having a mini-batch of samples in each iteration. To the best of our knowledge, this is the first time that such an online algorithm designed for the (un)constrained multi-level setting, obtains the same sample complexity of the smooth single-level setting, under mild assumptions on the stochastic first-order oracle.
Explainable, Stable, and Scalable Graph Convolutional Networks for Learning Graph Representation
Sep 22, 2020
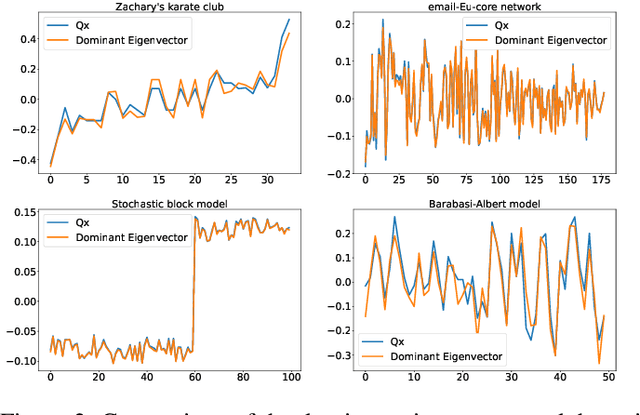
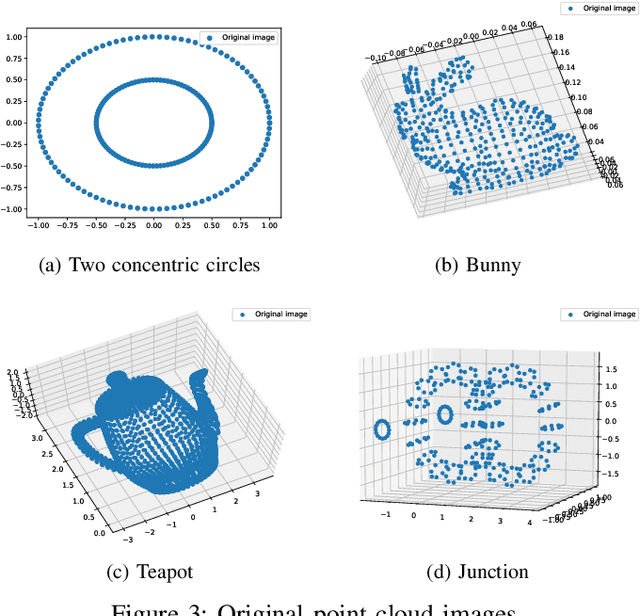
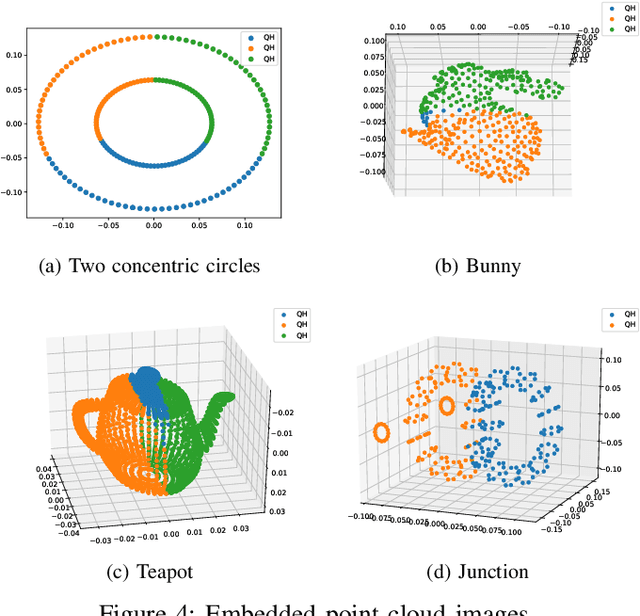
The network embedding problem that maps nodes in a graph to vectors in Euclidean space can be very useful for addressing several important tasks on a graph. Recently, graph neural networks (GNNs) have been proposed for solving such a problem. However, most embedding algorithms and GNNs are difficult to interpret and do not scale well to handle millions of nodes. In this paper, we tackle the problem from a new perspective based on the equivalence of three constrained optimization problems: the network embedding problem, the trace maximization problem of the modularity matrix in a sampled graph, and the matrix factorization problem of the modularity matrix in a sampled graph. The optimal solutions to these three problems are the dominant eigenvectors of the modularity matrix. We proposed two algorithms that belong to a special class of graph convolutional networks (GCNs) for solving these problems: (i) Clustering As Feature Embedding GCN (CAFE-GCN) and (ii) sphere-GCN. Both algorithms are stable trace maximization algorithms, and they yield good approximations of dominant eigenvectors. Moreover, there are linear-time implementations for sparse graphs. In addition to solving the network embedding problem, both proposed GCNs are capable of performing dimensionality reduction. Various experiments are conducted to evaluate our proposed GCNs and show that our proposed GCNs outperform almost all the baseline methods. Moreover, CAFE-GCN could be benefited from the labeled data and have tremendous improvements in various performance metrics.
Implementation of a FPGA-Based Feature Detection and Networking System for Real-time Traffic Monitoring
Mar 22, 2016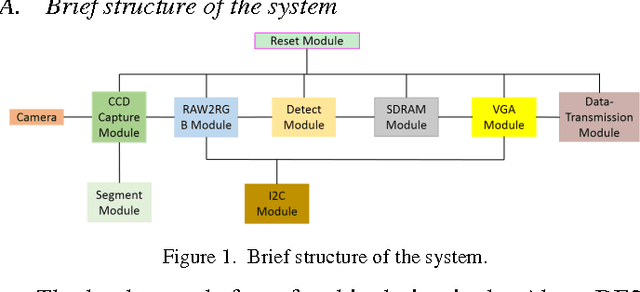
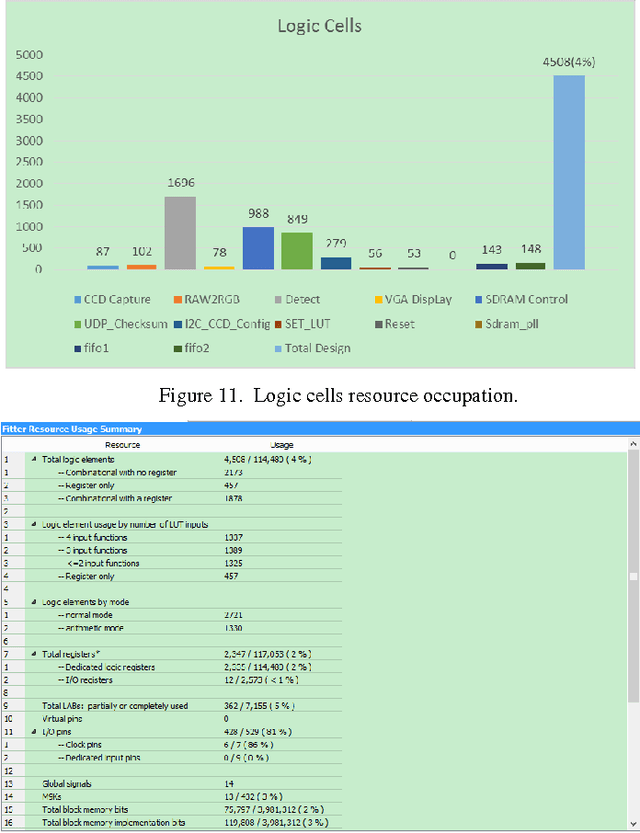
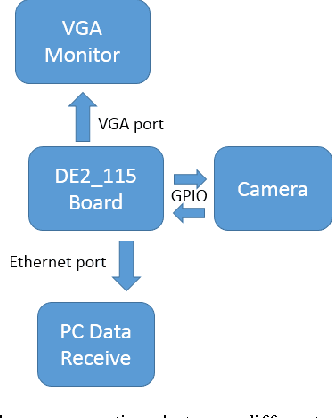
With the growing demand of real-time traffic monitoring nowadays, software-based image processing can hardly meet the real-time data processing requirement due to the serial data processing nature. In this paper, the implementation of a hardware-based feature detection and networking system prototype for real-time traffic monitoring as well as data transmission is presented. The hardware architecture of the proposed system is mainly composed of three parts: data collection, feature detection, and data transmission. Overall, the presented prototype can tolerate a high data rate of about 60 frames per second. By integrating the feature detection and data transmission functions, the presented system can be further developed for various VANET application scenarios to improve road safety and traffic efficiency. For example, detection of vehicles that violate traffic rules, parking enforcement, etc.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jul 02, 2020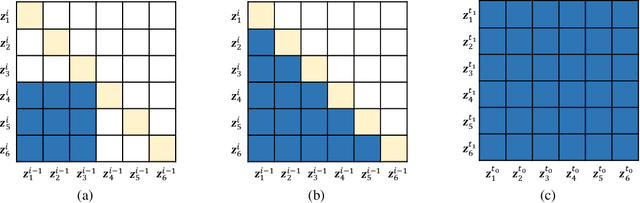
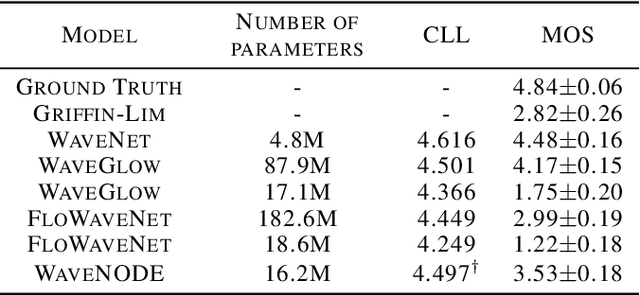
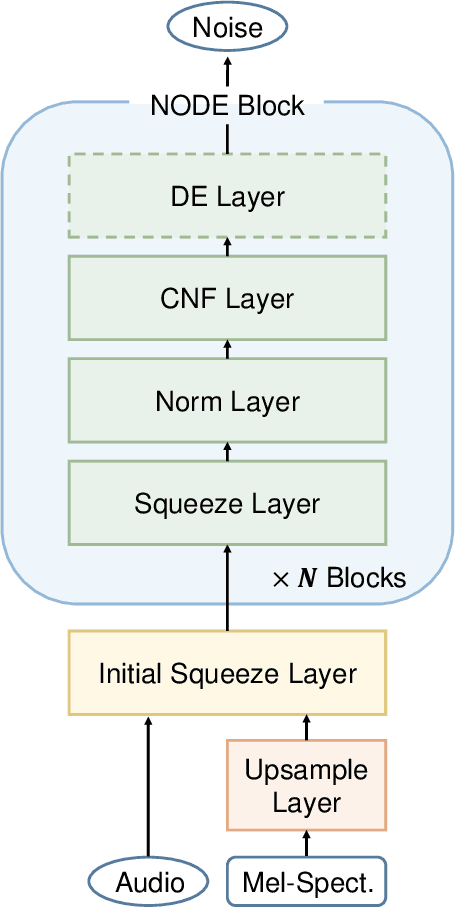

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
A Hybrid Approach to Temporal Pattern Matching
Jan 24, 2020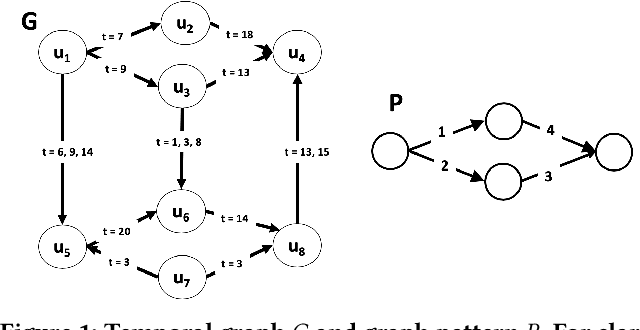
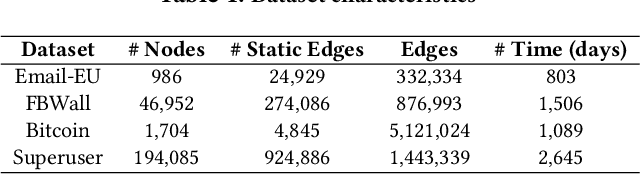
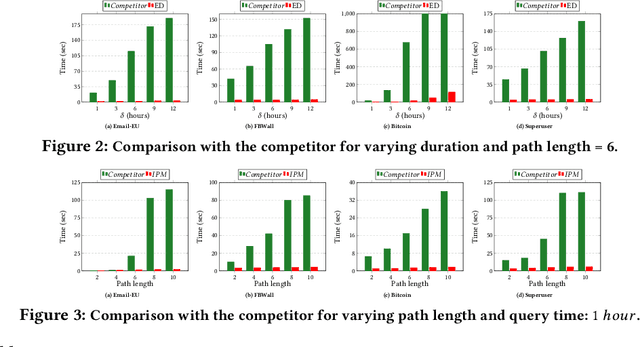
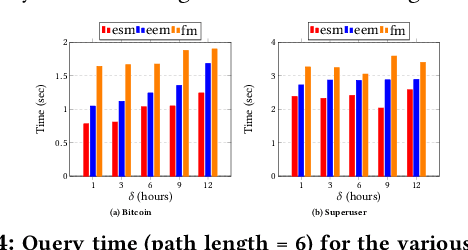
The primary objective of graph pattern matching is to find all appearances of an input graph pattern query in a large data graph. Such appearances are called matches. In this paper, we are interested in finding matches of interaction patterns in temporal graphs. To this end, we propose a hybrid approach that achieves effective filtering of potential matches based both on structure and time. Our approach exploits a graph representation where edges are ordered by time. We present experiments with real datasets that illustrate the efficiency of our approach.
Optimal Assistance for Object-Rearrangement Tasks in Augmented Reality
Oct 14, 2020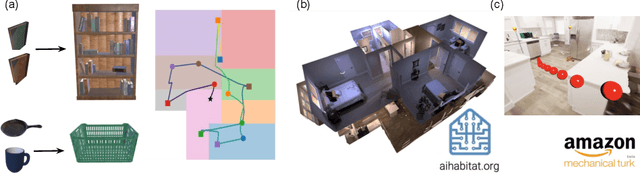
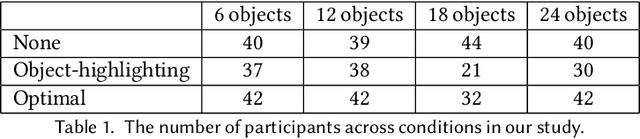
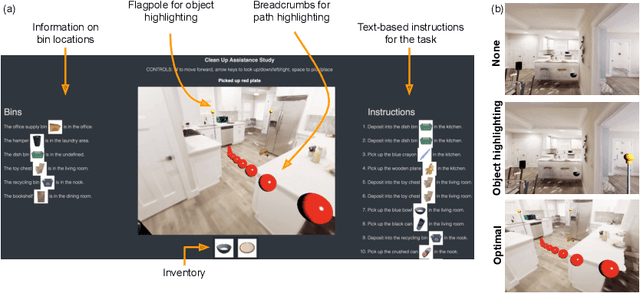
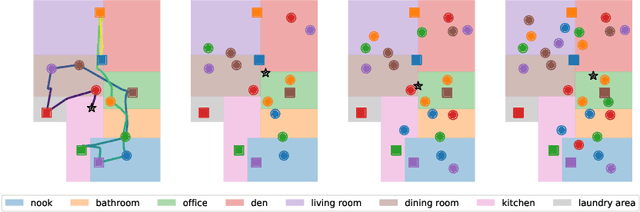
Augmented-reality (AR) glasses that will have access to onboard sensors and an ability to display relevant information to the user present an opportunity to provide user assistance in quotidian tasks. Many such tasks can be characterized as object-rearrangement tasks. We introduce a novel framework for computing and displaying AR assistance that consists of (1) associating an optimal action sequence with the policy of an embodied agent and (2) presenting this sequence to the user as suggestions in the AR system's heads-up display. The embodied agent comprises a "hybrid" between the AR system and the user, with the AR system's observation space (i.e., sensors) and the user's action space (i.e., task-execution actions); its policy is learned by minimizing the task-completion time. In this initial study, we assume that the AR system's observations include the environment's map and localization of the objects and the user. These choices allow us to formalize the problem of computing AR assistance for any object-rearrangement task as a planning problem, specifically as a capacitated vehicle-routing problem. Further, we introduce a novel AR simulator that can enable web-based evaluation of AR-like assistance and associated at-scale data collection via the Habitat simulator for embodied artificial intelligence. Finally, we perform a study that evaluates user response to the proposed form of AR assistance on a specific quotidian object-rearrangement task, house cleaning, using our proposed AR simulator on mechanical turk. In particular, we study the effect of the proposed AR assistance on users' task performance and sense of agency over a range of task difficulties. Our results indicate that providing users with such assistance improves their overall performance and while users report a negative impact to their agency, they may still prefer the proposed assistance to having no assistance at all.
A general approach to bridge the reality-gap
Sep 03, 2020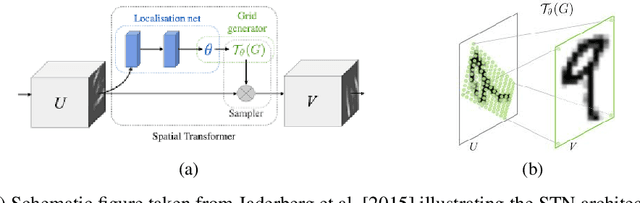

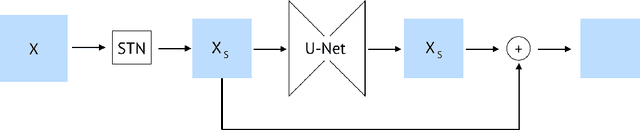
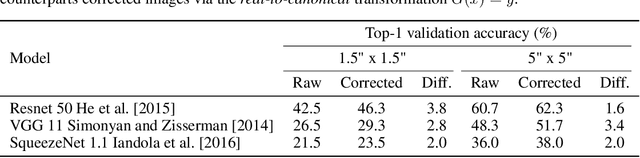
Employing machine learning models in the real world requires collecting large amounts of data, which is both time consuming and costly to collect. A common approach to circumvent this is to leverage existing, similar data-sets with large amounts of labelled data. However, models trained on these canonical distributions do not readily transfer to real-world ones. Domain adaptation and transfer learning are often used to breach this "reality gap", though both require a substantial amount of real-world data. In this paper we discuss a more general approach: we propose learning a general transformation to bring arbitrary images towards a canonical distribution where we can naively apply the trained machine learning models. This transformation is trained in an unsupervised regime, leveraging data augmentation to generate off-canonical examples of images and training a Deep Learning model to recover their original counterpart. We quantify the performance of this transformation using pre-trained ImageNet classifiers, demonstrating that this procedure can recover half of the loss in performance on the distorted data-set. We then validate the effectiveness of this approach on a series of pre-trained ImageNet models on a real world data set collected by printing and photographing images in different lighting conditions.
Efficient Pig Counting in Crowds with Keypoints Tracking and Spatial-aware Temporal Response Filtering
May 27, 2020

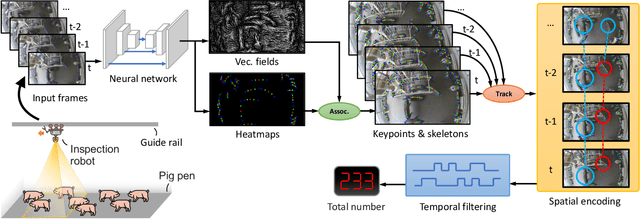
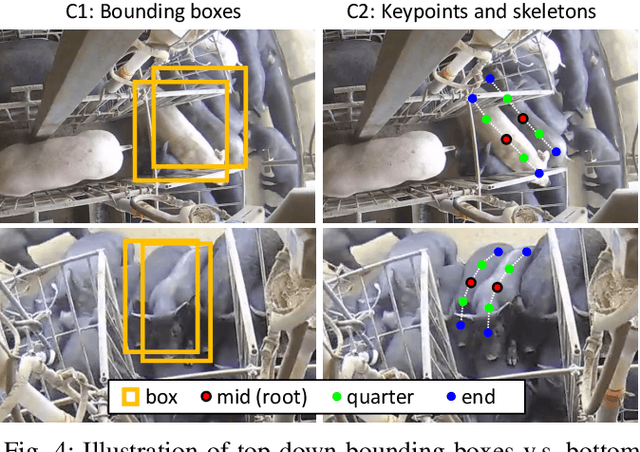
Pig counting is a crucial task for large-scale pig farming, which is usually completed by human visually. But this process is very time-consuming and error-prone. Few studies in literature developed automated pig counting method. Existing methods only focused on pig counting using single image, and its accuracy is challenged by several factors, including pig movements, occlusion and overlapping. Especially, the field of view of a single image is very limited, and could not meet the requirements of pig counting for large pig grouping houses. To that end, we presented a real-time automated pig counting system in crowds using only one monocular fisheye camera with an inspection robot. Our system showed that it produces accurate results surpassing human. Our pipeline began with a novel bottom-up pig detection algorithm to avoid false negatives due to overlapping, occlusion and deformation of pigs. A deep convolution neural network (CNN) is designed to detect keypoints of pig body part and associate the keypoints to identify individual pigs. After that, an efficient on-line tracking method is used to associate pigs across video frames. Finally, a novel spatial-aware temporal response filtering (STRF) method is proposed to predict the counts of pigs, which is effective to suppress false positives caused by pig or camera movements or tracking failures. The whole pipeline has been deployed in an edge computing device, and demonstrated the effectiveness.
Traditional and accelerated gradient descent for neural architecture search
Jul 02, 2020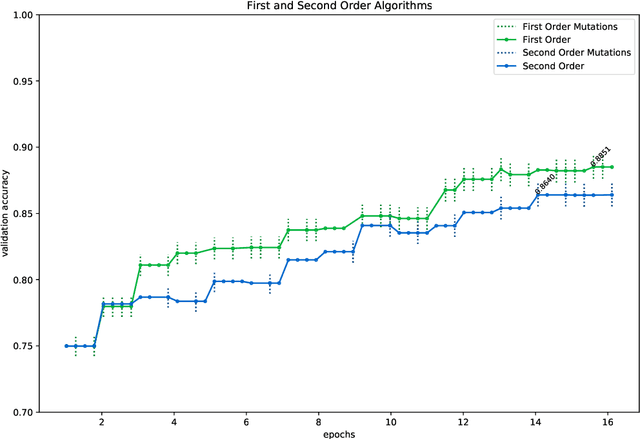
In this paper, we introduce two algorithms for neural architecture search (NASGD and NASAGD) following the theoretical work by two of the authors [4], which aimed at introducing the conceptual basis for new notions of traditional and accelerated gradient descent algorithms for the optimization of a function on a semi-discrete space using ideas from optimal transport theory. Our methods, which use the network morphism framework introduced in [3] as a baseline, can analyze forty times as many architectures as the hill climbing methods [3,11] while using the same computational resources and time and achieving comparable levels of accuracy. For example, using NASGD on CIFAR-10, our method designs and trains networks with an error rate of 4.06 in only 12 hours on a single GPU.
Real-Time Background Subtraction Using Adaptive Sampling and Cascade of Gaussians
May 25, 2017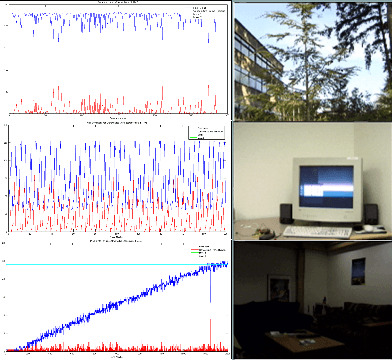

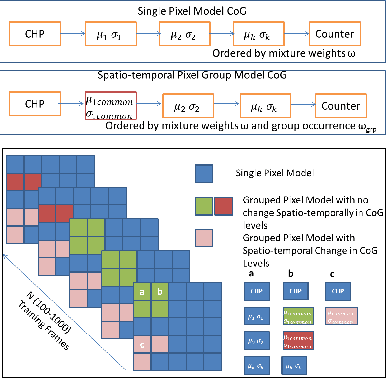
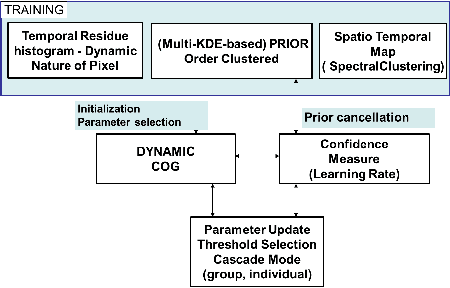
Background-Foreground classification is a fundamental well-studied problem in computer vision. Due to the pixel-wise nature of modeling and processing in the algorithm, it is usually difficult to satisfy real-time constraints. There is a trade-off between the speed (because of model complexity) and accuracy. Inspired by the rejection cascade of Viola-Jones classifier, we decompose the Gaussian Mixture Model (GMM) into an adaptive cascade of classifiers. This way we achieve a good improvement in speed without compensating for accuracy. In the training phase, we learn multiple KDEs for different durations to be used as strong prior distribution and detect probable oscillating pixels which usually results in misclassifications. We propose a confidence measure for the classifier based on temporal consistency and the prior distribution. The confidence measure thus derived is used to adapt the learning rate and the thresholds of the model, to improve accuracy. The confidence measure is also employed to perform temporal and spatial sampling in a principled way. We demonstrate a speed-up factor of 5x to 10x and 17 percent average improvement in accuracy over several standard videos.