 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A General Model of Conversational Dynamics and an Example Application in Serious Illness Communication
Oct 11, 2020
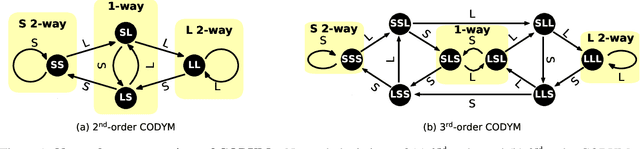

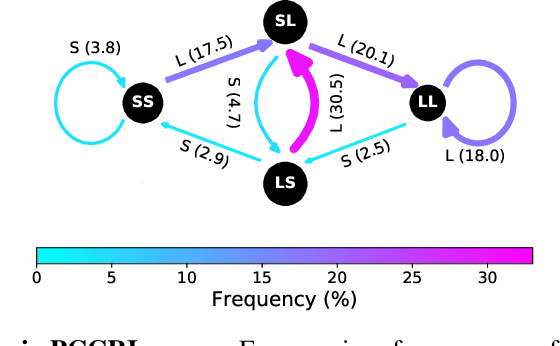
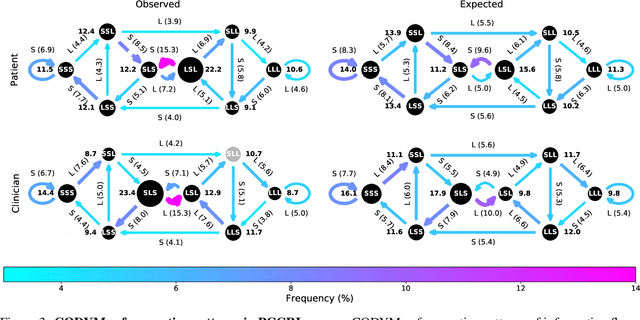
Conversation has been a primary means for the exchange of information since ancient times. Understanding patterns of information flow in conversations is a critical step in assessing and improving communication quality. In this paper, we describe COnversational DYnamics Model (CODYM) analysis, a novel approach for studying patterns of information flow in conversations. CODYMs are Markov Models that capture sequential dependencies in the lengths of speaker turns. The proposed method is automated and scalable, and preserves the privacy of the conversational participants. The primary function of CODYM analysis is to quantify and visualize patterns of information flow, concisely summarized over sequential turns from one or more conversations. Our approach is general and complements existing methods, providing a new tool for use in the analysis of any type of conversation. As an important first application, we demonstrate the model on transcribed conversations between palliative care clinicians and seriously ill patients. These conversations are dynamic and complex, taking place amidst heavy emotions, and include difficult topics such as end-of-life preferences and patient values. We perform a versatile set of CODYM analyses that (a) establish the validity of the model by confirming known patterns of conversational turn-taking and word usage, (b) identify normative patterns of information flow in serious illness conversations, and (c) show how these patterns vary across narrative time and differ under expressions of anger, fear and sadness. Potential applications of CODYMs range from assessment and training of effective healthcare communication to comparing conversational dynamics across language and culture, with the prospect of identifying universal similarities and unique "fingerprints" of information flow.
Exact Recovery of Mangled Clusters with Same-Cluster Queries
Jun 08, 2020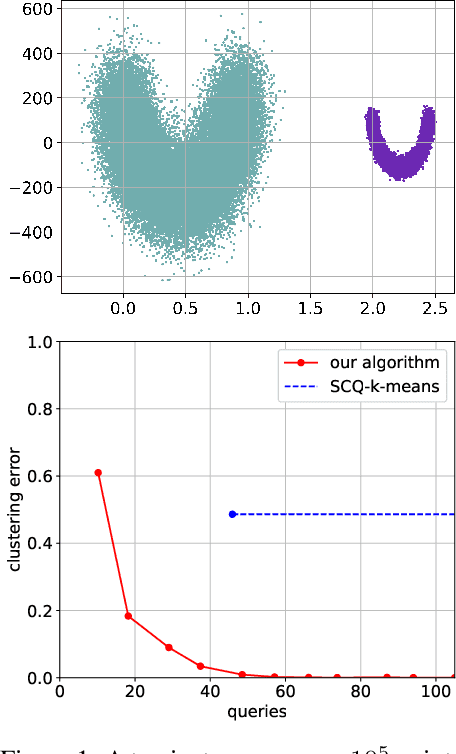
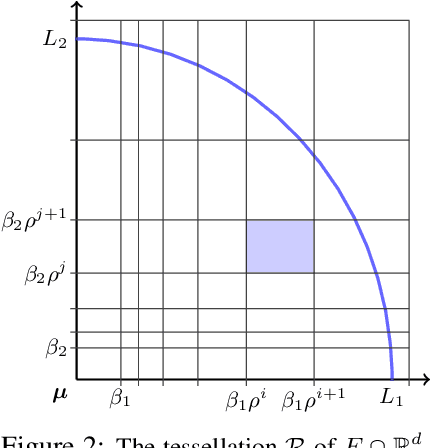
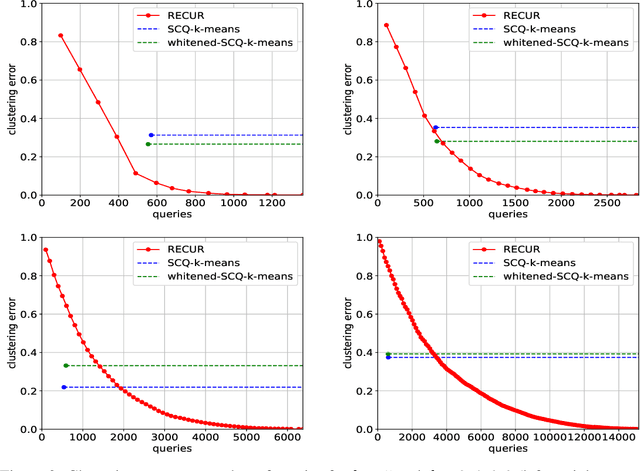
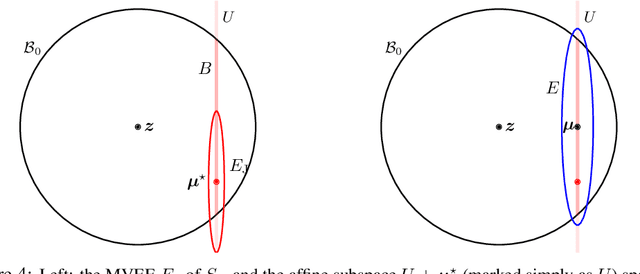
We study the problem of recovering distorted clusters in the semi-supervised active clustering framework. Given an oracle revealing whether any two points lie in the same cluster, we are interested in designing algorithms that recover all clusters exactly, in polynomial time, and using as few queries as possible. Towards this end, we extend the notion of center-based clustering with margin introduced by Ashtiani et al.\ to clusters with arbitrary linear distortions and arbitrary centers. This includes all those cases where the original dataset is transformed by any combination of rotations, axis scalings, and point deletions. We show that, even in this significantly more challenging setting, it is possible to recover the underlying clustering exactly while using only a small number of oracle queries. To this end we design an algorithm that, given $n$ points to be partitioned into $k$ clusters, uses $O(k^3 \ln k \ln n)$ oracle queries and $\tilde{O}(kn + k^3)$ time to recover the exact clustering structure of the underlying instance (even when the instance is NP-hard to solve without oracle access). The $O(\cdot)$ notation hides an exponential dependence on the dimensionality of the clusters, which we show to be necessary. Our algorithm is simple, easy to implement, and can also learn the clusters using low-stretch separators, a class of ellipsoids with additional theoretical guarantees. Experiments on large synthetic datasets confirm that we can reconstruct the latent clustering exactly and efficiently.
Column $\ell_{2,0}$-norm regularized factorization model of low-rank matrix recovery and its computation
Aug 24, 2020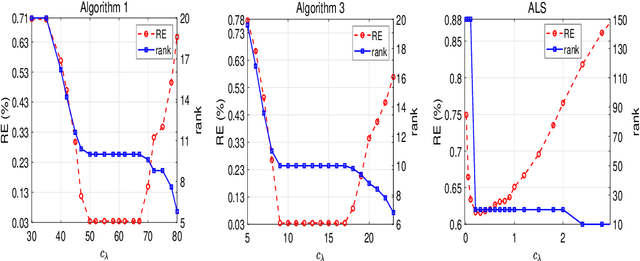
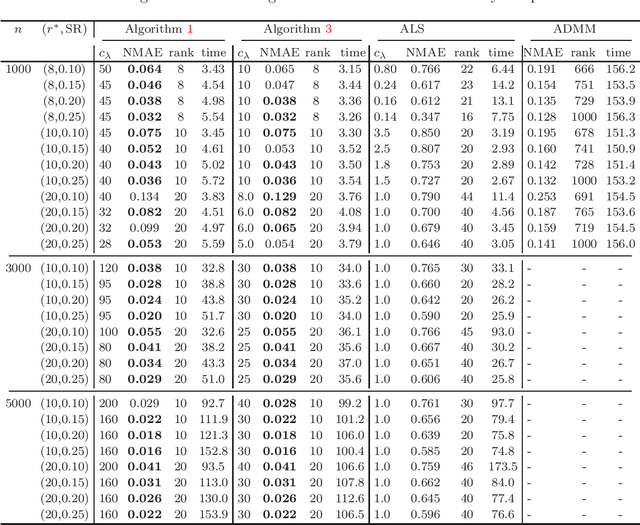
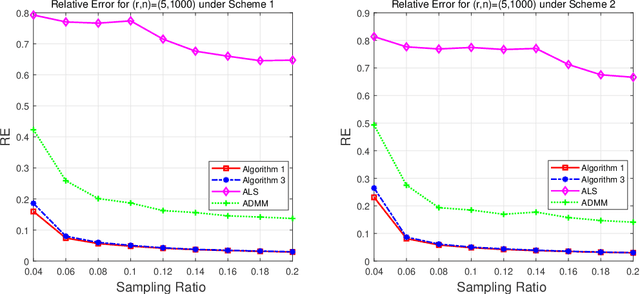
This paper is concerned with the column $\ell_{2,0}$-regularized factorization model of low-rank matrix recovery problems and its computation. The column $\ell_{2,0}$-norm of factor matrices is introduced to promote column sparsity of factors and lower rank solutions. For this nonconvex nonsmooth and non-Lipschitz problem, we develop an alternating majorization-minimization (AMM) method with extrapolation, and a hybrid AMM in which a majorized alternating proximal method is first proposed to seek an initial factor pair with less nonzero columns and then the AMM with extrapolation is applied to the minimization of smooth nonconvex loss. We provide the global convergence analysis for the proposed AMM methods and apply them to the matrix completion problem with non-uniform sampling schemes. Numerical experiments are conducted with synthetic and real data examples, and comparison results with the nuclear-norm regularized factorization model and the max-norm regularized convex model demonstrate that the column $\ell_{2,0}$-regularized factorization model has an advantage in offering solutions of lower error and rank within less time.
Decoder Modulation for Indoor Depth Completion
May 18, 2020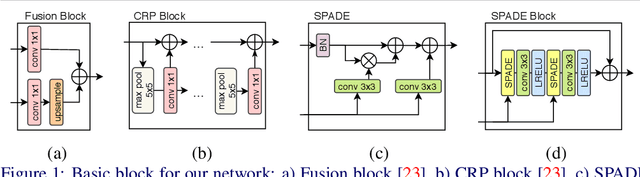
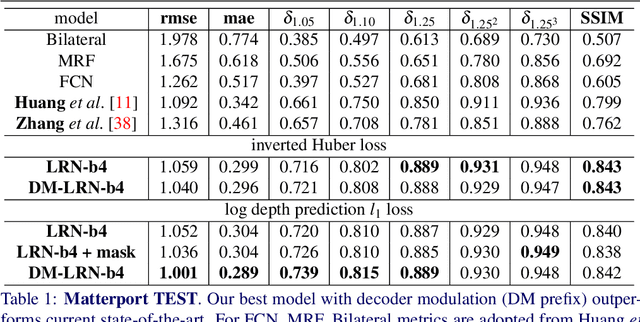

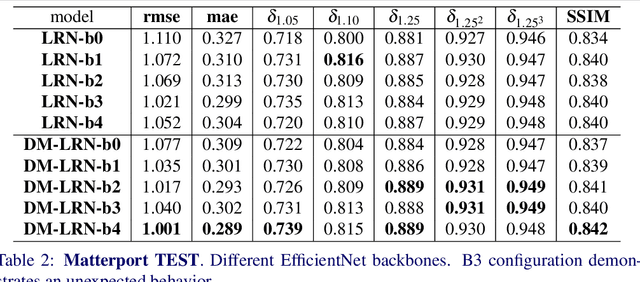
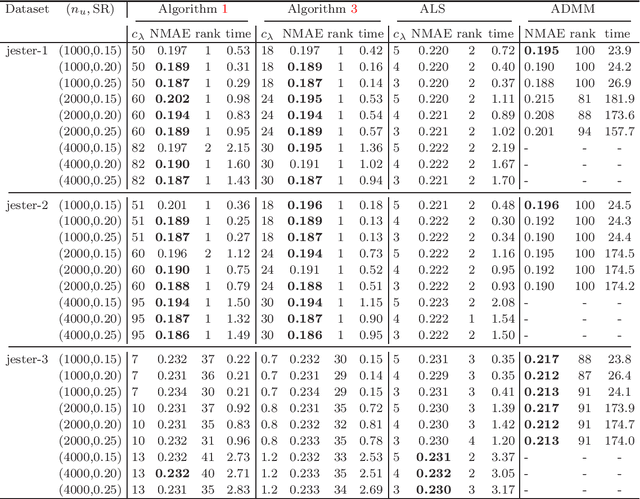
Accurate depth map estimation is an essential step in scene spatial mapping for AR applications and 3D modeling. Current depth sensors provide time-synchronized depth and color images in real-time, but have limited range and suffer from missing and erroneous depth values on transparent or glossy surfaces. We investigate the task of depth completion that aims at improving the accuracy of depth measurements and recovering the missing depth values using additional information from corresponding color images. Surprisingly, we find that a simple baseline model based on modern encoder-decoder architecture for semantic segmentation achieves state-of-the-art accuracy on standard depth completion benchmarks. Then, we show that the accuracy can be further improved by taking into account a mask of missing depth values. The main contributions of our work are two-fold. First, we propose a modified decoder architecture, where features from raw depth and color are modulated by features from the mask via Spatially-Adaptive Denormalization (SPADE). Second, we introduce a new loss function for depth estimation based on a direct comparison of log depth prediction with ground truth values. The resulting model outperforms current state-of-the-art by a large margin on the challenging Matterport3D dataset.
ProSelfLC: Progressive Self Label Correction for Training Robust Deep Neural Networks
Jun 08, 2020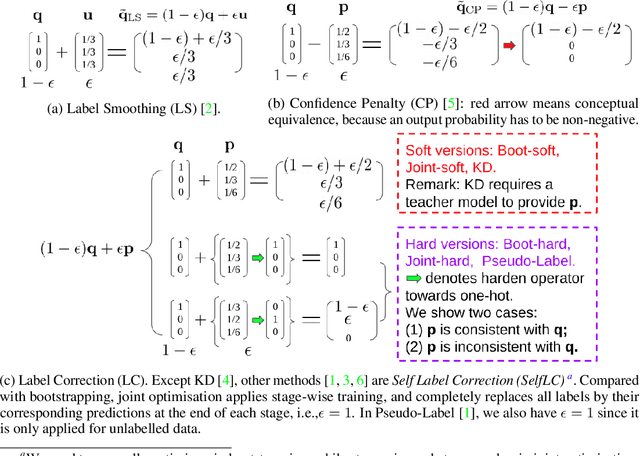

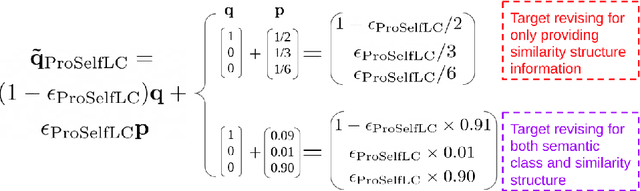
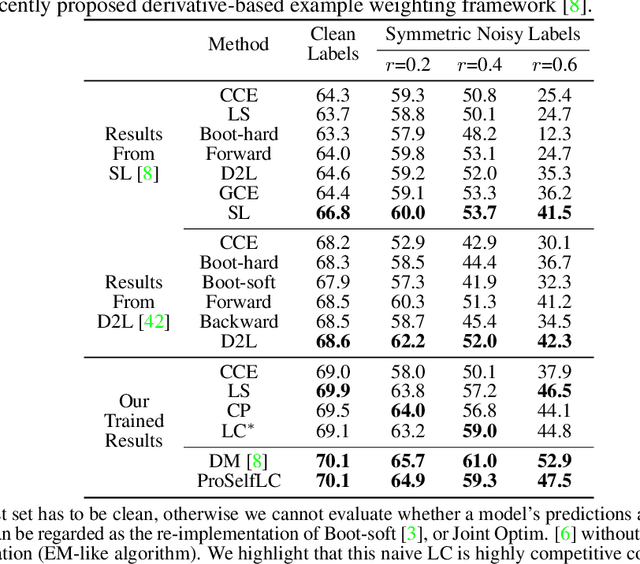
We systematically study popular target modification approaches in supervised learning. We show that they can be connected mathematically through entropy and KL divergence. This uncovers that some methods penalise while the others reward low entropy. Additionally, some of them are suboptimal because they do not leverage the knowledge of a model itself; some rely on extra learners or stage-wise training that may require a human intervention thus being difficult to optimise; most importantly, there does not exist an automatic way to decide how much we trust a predicted label distribution, let alone exploiting it. To resolve these issues, taking two well-accepted expertise: deep neural networks learn meaningful patterns before fitting noise [1] and minimum entropy regularisation principle [2], we propose a simple end-to-end method named ProSelfLC, which is endorsed by long learning time and high prediction confidence. Specifically, given a data point, we progressively trust more its predicted label distribution than its annotated one if a model has been trained for a long time and outputs a highly confident prediction (low entropy). By extensive experiments, we show: (1) ProSelfLC can revise an example's one-hot label distribution by adding the perceptual similarity structure information so that its learning target becomes structured and soft; (2) When being applied to noisy labels, it can correct their semantic classes; (3) It outperforms existing methods with the lowest entropy, which indicates it is right for a learner to be confident in correct patterns.
Toward Enabling a Reliable Quality Monitoring System for Additive Manufacturing Process using Deep Convolutional Neural Networks
Mar 06, 2020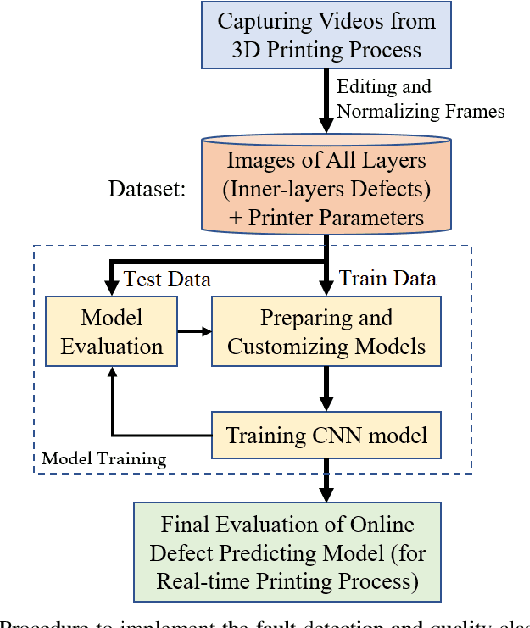
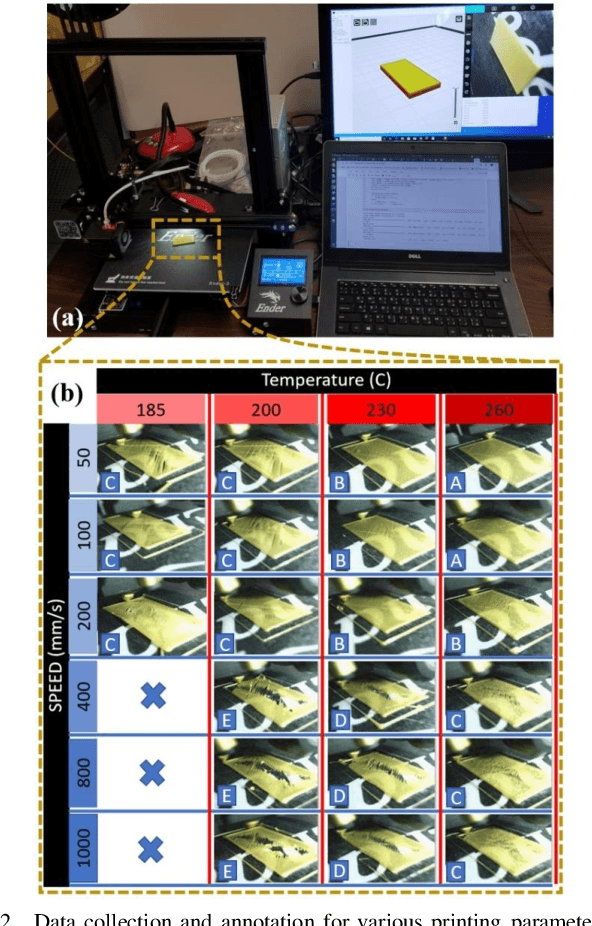
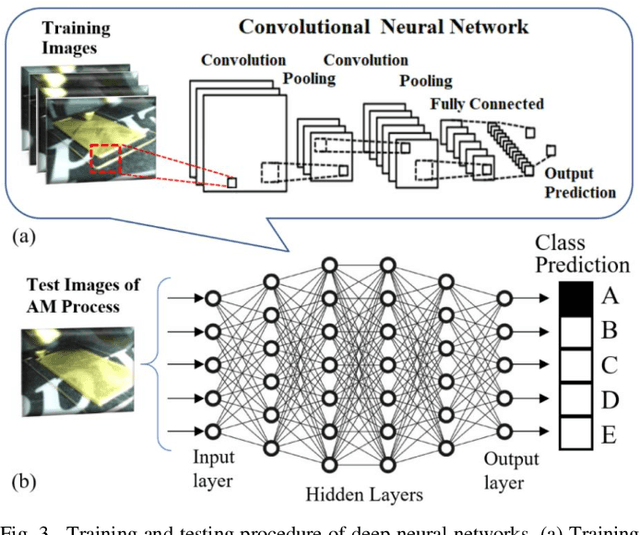
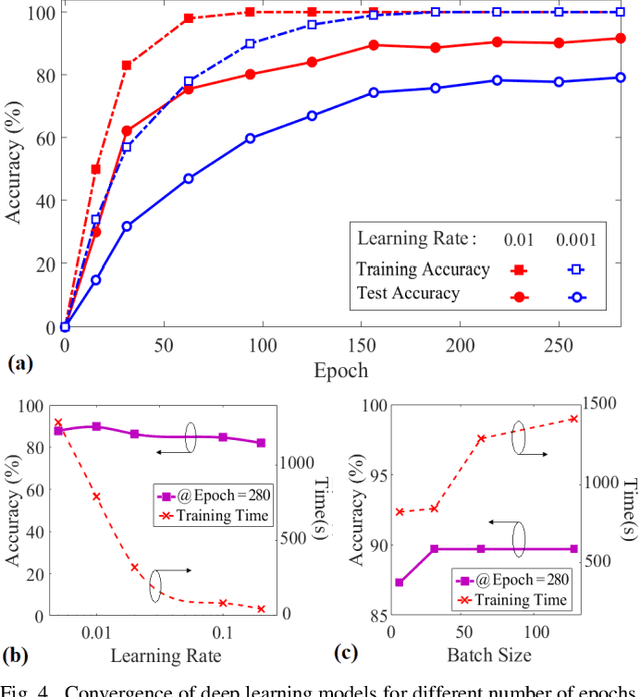
Additive Manufacturing (AM) is a crucial component of the smart industry. In this paper, we propose an automated quality grading system for the AM process using a deep convolutional neural network (CNN) model. The CNN model is trained offline using the images of the internal and surface defects in the layer-by-layer deposition of materials and tested online by studying the performance of detecting and classifying the failure in AM process at different extruder speeds and temperatures. The model demonstrates the accuracy of 94% and specificity of 96%, as well as above 75% in three classifier measures of the Fscore, the sensitivity, and precision for classifying the quality of the printing process in five grades in real-time. The proposed online model adds an automated, consistent, and non-contact quality control signal to the AM process that eliminates the manual inspection of parts after they are entirely built. The quality monitoring signal can also be used by the machine to suggest remedial actions by adjusting the parameters in real-time. The proposed quality predictive model serves as a proof-of-concept for any type of AM machines to produce reliable parts with fewer quality hiccups while limiting the waste of both time and materials.
nnAudio: An on-the-fly GPU Audio to Spectrogram Conversion Toolbox Using 1D Convolution Neural Networks
Dec 27, 2019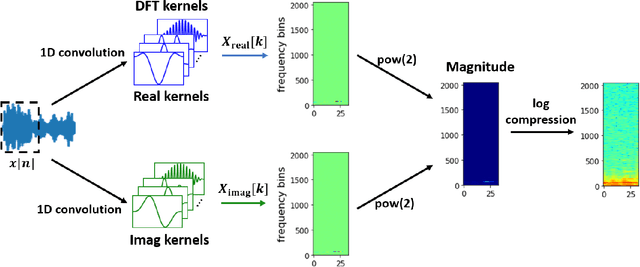

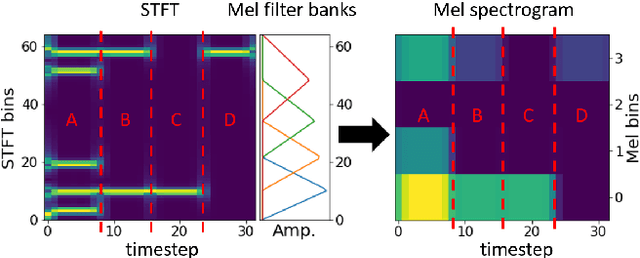
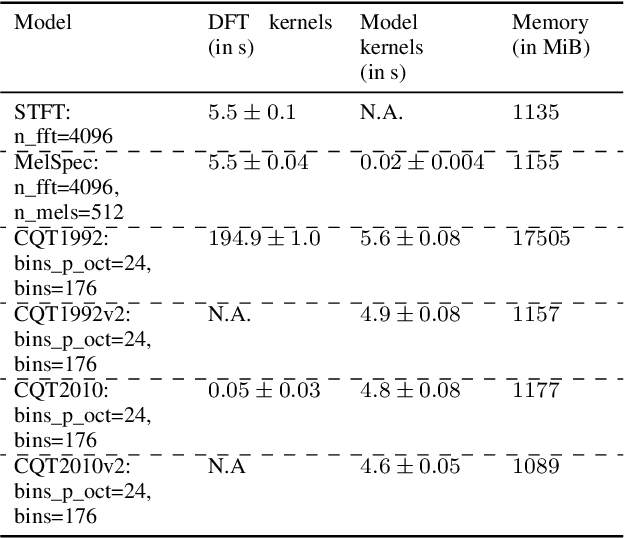
Converting time domain waveforms to frequency domain spectrograms is typically considered to be a prepossessing step done before model training. This approach, however, has several drawbacks. First, it takes a lot of hard disk space to store different frequency domain representations. This is especially true during the model development and tuning process, when exploring various types of spectrograms for optimal performance. Second, if another dataset is used, one must process all the audio clips again before the network can be retrained. In this paper, we integrate the time domain to frequency domain conversion as part of the model structure, and propose a neural network based toolbox, nnAudio, which leverages 1D convolutional neural networks to perform time domain to frequency domain conversion during feed-forward. It allows on-the-fly spectrogram generation without the need to store any spectrograms on the disk. This approach also allows back-propagation on the waveforms-to-spectrograms transformation layer, which implies that this transformation process can be made trainable, and hence further optimized by gradient descent. nnAudio reduces the waveforms-to-spectrograms conversion time for 1,770 waveforms (from the MAPS dataset) from $10.64$ seconds with librosa to only $0.001$ seconds for Short-Time Fourier Transform (STFT), 18.3 seconds to 0.015 seconds for Mel spectrogram, $103.4$ seconds to 0.258 for constant-Q transform (CQT), when using GPU on our DGX work station with CPU: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz Tesla v100 32Gb GPUs. (Only 1 GPU is being used for all the experiments.) We also further optimize the existing CQT algorithm, so that the CQT spectrogram can be obtained without aliasing in a much faster computation time (from $0.258$ seconds to only 0.001 seconds).
Deep Learning for Detecting Multiple Space-Time Action Tubes in Videos
Aug 04, 2016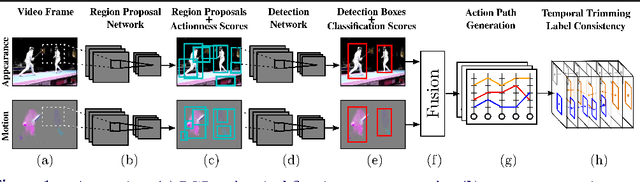
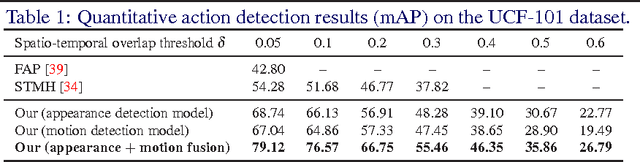
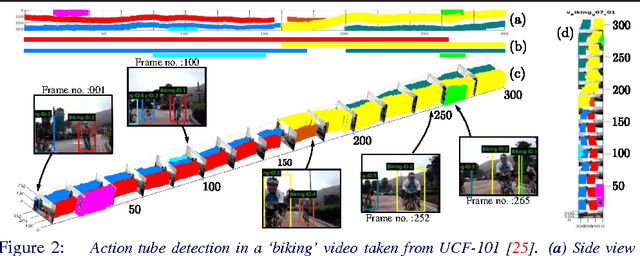
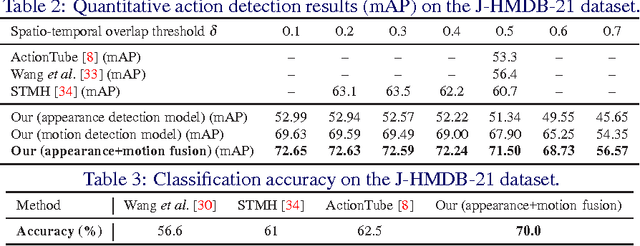
In this work, we propose an approach to the spatiotemporal localisation (detection) and classification of multiple concurrent actions within temporally untrimmed videos. Our framework is composed of three stages. In stage 1, appearance and motion detection networks are employed to localise and score actions from colour images and optical flow. In stage 2, the appearance network detections are boosted by combining them with the motion detection scores, in proportion to their respective spatial overlap. In stage 3, sequences of detection boxes most likely to be associated with a single action instance, called action tubes, are constructed by solving two energy maximisation problems via dynamic programming. While in the first pass, action paths spanning the whole video are built by linking detection boxes over time using their class-specific scores and their spatial overlap, in the second pass, temporal trimming is performed by ensuring label consistency for all constituting detection boxes. We demonstrate the performance of our algorithm on the challenging UCF101, J-HMDB-21 and LIRIS-HARL datasets, achieving new state-of-the-art results across the board and significantly increasing detection speed at test time. We achieve a huge leap forward in action detection performance and report a 20% and 11% gain in mAP (mean average precision) on UCF-101 and J-HMDB-21 datasets respectively when compared to the state-of-the-art.
Capturing Evolution in Word Usage: Just Add More Clusters?
Jan 18, 2020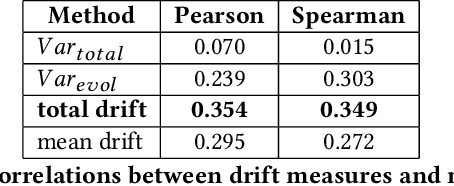
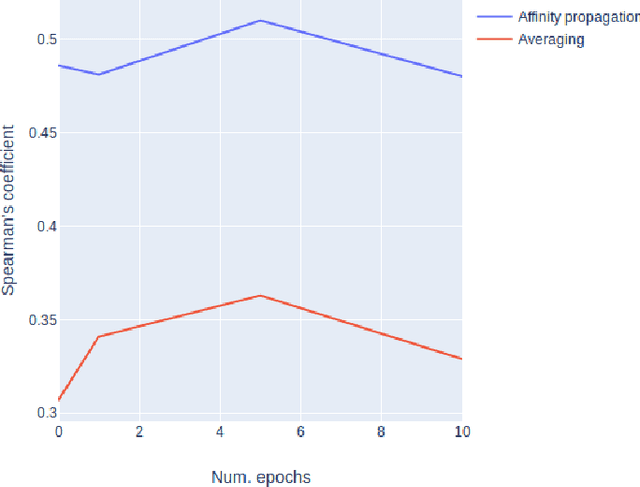
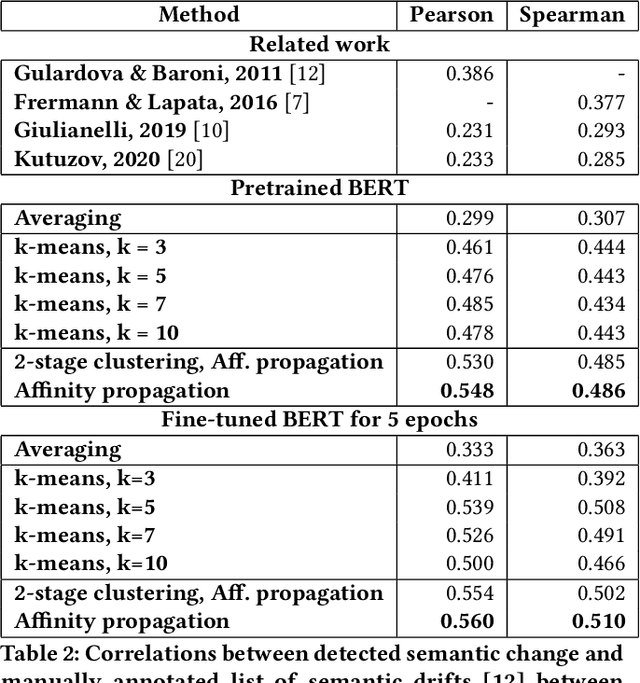
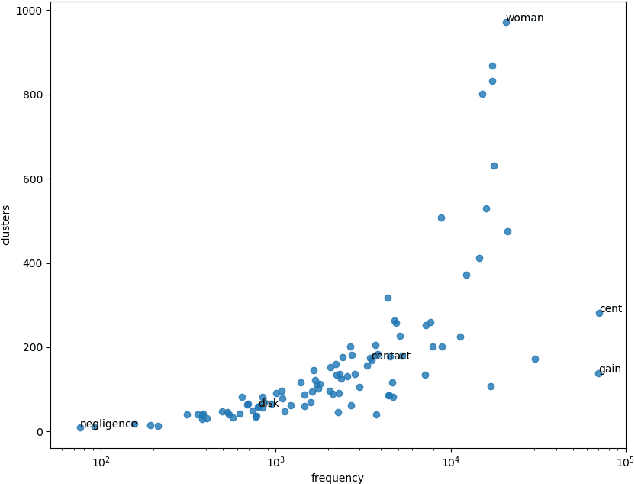
The way the words are used evolves through time, mirroring cultural or technological evolution of society. Semantic change detection is the task of detecting and analysing word evolution in textual data, even in short periods of time. This task has recently become a popular task in the NLP community. In this paper we focus on a new set of methods relying on contextualised embedding, a type of semantic modelling that revolutionised the field recently. We leverage the ability of the transformer-based BERT model to generate contextualised embeddings suitable to detect semantic change of words across time. We compare our results to other approaches from the literature in a common setting in order to establish strengths and weaknesses for each of them. We also propose several ideas for improvements, managing to drastically improve the performance of existing approaches.
Project to Adapt: Domain Adaptation for Depth Completion from Noisy and Sparse Sensor Data
Aug 05, 2020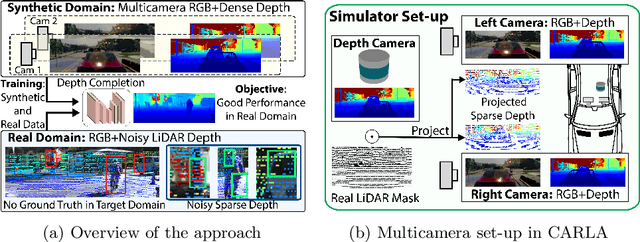
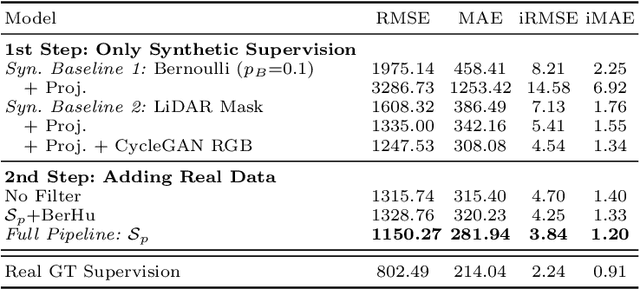
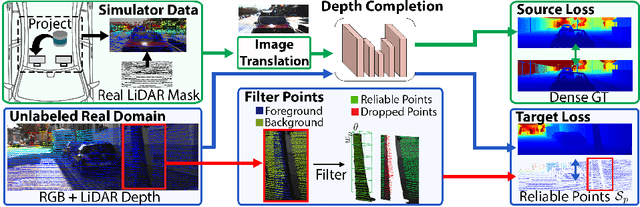
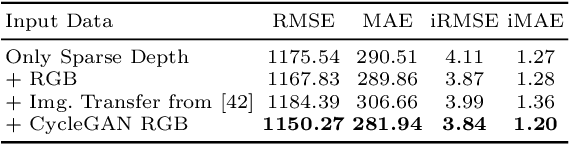
Depth completion aims to predict a dense depth map from a sparse depth input. The acquisition of dense ground truth annotations for depth completion settings can be difficult and, at the same time, a significant domain gap between real LiDAR measurements and synthetic data has prevented from successful training of models in virtual settings. We propose a domain adaptation approach for sparse-to-dense depth completion that is trained from synthetic data, without annotations in the real domain or additional sensors. Our approach simulates the real sensor noise in an RGB+LiDAR set-up, and consists of three modules: simulating the real LiDAR input in the synthetic domain via projections, filtering the real noisy LiDAR for supervision and adapting the synthetic RGB image using a CycleGAN approach. We extensively evaluate these modules against the state-of-the-art in the KITTI depth completion benchmark, showing significant improvements.