 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Vulnerability In Large Codebases With Deep Code Representation
Apr 24, 2020
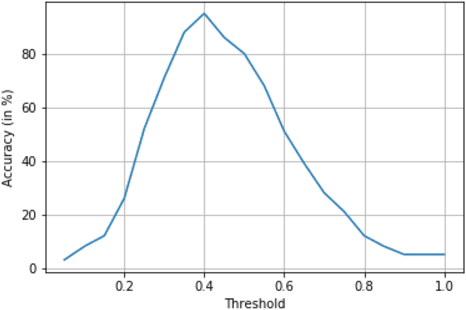
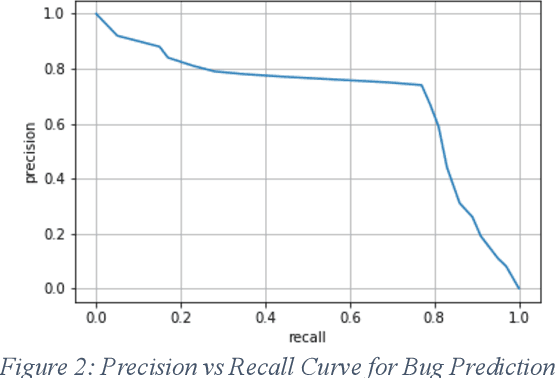
Currently, while software engineers write code for various modules, quite often, various types of errors - coding, logic, semantic, and others (most of which are not caught by compilation and other tools) get introduced. Some of these bugs might be found in the later stage of testing, and many times it is reported by customers on production code. Companies have to spend many resources, both money and time in finding and fixing the bugs which would have been avoided if coding was done right. Also, concealed flaws in software can lead to security vulnerabilities that potentially allow attackers to compromise systems and applications. Interestingly, same or similar issues/bugs, which were fixed in the past (although in different modules), tend to get introduced in production code again. We developed a novel AI-based system which uses the deep representation of Abstract Syntax Tree (AST) created from the source code and also the active feedback loop to identify and alert the potential bugs that could be caused at the time of development itself i.e. as the developer is writing new code (logic and/or function). This tool integrated with IDE as a plugin would work in the background, point out existing similar functions/code-segments and any associated bugs in those functions. The tool would enable the developer to incorporate suggestions right at the time of development, rather than waiting for UT/QA/customer to raise a defect. We assessed our tool on both open-source code and also on Cisco codebase for C and C++ programing language. Our results confirm that deep representation of source code and the active feedback loop is an assuring approach for predicting security and other vulnerabilities present in the code.
Free View Synthesis
Aug 12, 2020
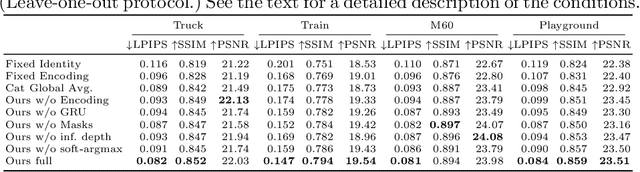

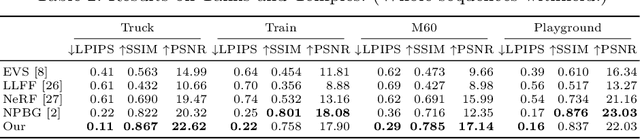
We present a method for novel view synthesis from input images that are freely distributed around a scene. Our method does not rely on a regular arrangement of input views, can synthesize images for free camera movement through the scene, and works for general scenes with unconstrained geometric layouts. We calibrate the input images via SfM and erect a coarse geometric scaffold via MVS. This scaffold is used to create a proxy depth map for a novel view of the scene. Based on this depth map, a recurrent encoder-decoder network processes reprojected features from nearby views and synthesizes the new view. Our network does not need to be optimized for a given scene. After training on a dataset, it works in previously unseen environments with no fine-tuning or per-scene optimization. We evaluate the presented approach on challenging real-world datasets, including Tanks and Temples, where we demonstrate successful view synthesis for the first time and substantially outperform prior and concurrent work.
A simulation environment for drone cinematography
Oct 03, 2020
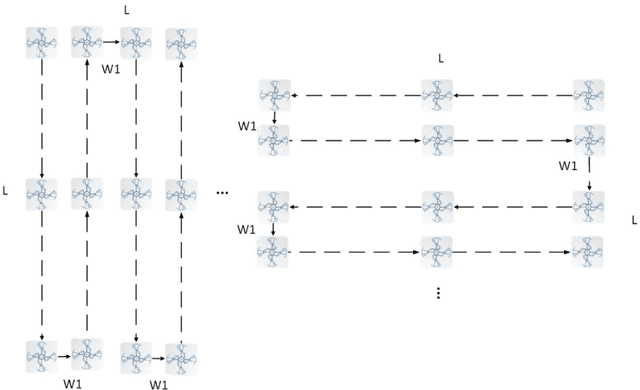
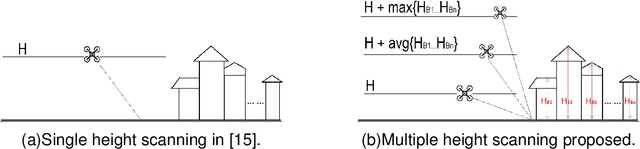

In this paper, we present a workflow for the simulation of drone operations exploiting realistic background environments constructed within Unreal Engine 4 (UE4). Methods for environmental image capture, 3D reconstruction (photogrammetry) and the creation of foreground assets are presented along with a flexible and user-friendly simulation interface. Given the geographical location of the selected area and the camera parameters employed, the scanning strategy and its associated flight parameters are first determined for image capture. Source imagery can be extracted from virtual globe software or obtained through aerial photography of the scene (e.g. using drones). The latter case is clearly more time consuming but can provide enhanced detail, particularly where coverage of virtual globe software is limited. The captured images are then used to generate 3D background environment models employing photogrammetry software. The reconstructed 3D models are then imported into the simulation interface as background environment assets together with appropriate foreground object models as a basis for shot planning and rehearsal. The tool supports both free-flight and parameterisable standard shot types along with programmable scenarios associated with foreground assets and event dynamics. It also supports the exporting of flight plans. Camera shots can also be designed to provide suitable coverage of any landmarks which need to appear in-shot. This simulation tool will contribute to enhanced productivity, improved safety (awareness and mitigations for crowds and buildings), improved confidence of operators and directors and ultimately enhanced quality of viewer experience.
Deep Learning based Person Re-identification
May 07, 2020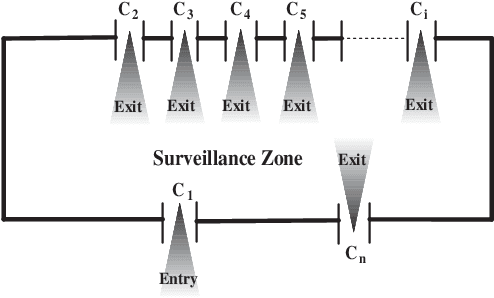
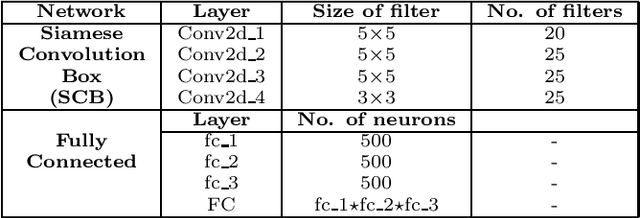
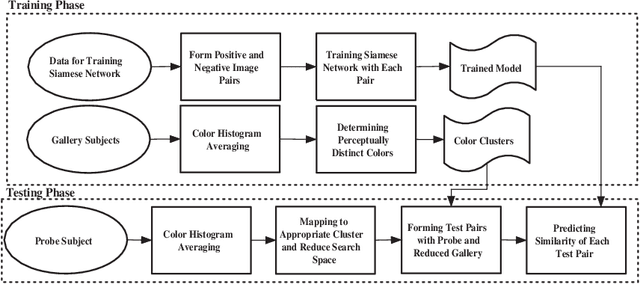
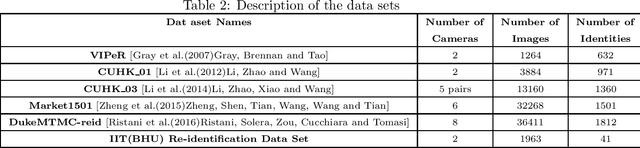
Automated person re-identification in a multi-camera surveillance setup is very important for effective tracking and monitoring crowd movement. In the recent years, few deep learning based re-identification approaches have been developed which are quite accurate but time-intensive, and hence not very suitable for practical purposes. In this paper, we propose an efficient hierarchical re-identification approach in which color histogram based comparison is first employed to find the closest matches in the gallery set, and next deep feature based comparison is carried out using Siamese network. Reduction in search space after the first level of matching helps in achieving a fast response time as well as improving the accuracy of prediction by the Siamese network by eliminating vastly dissimilar elements. A silhouette part-based feature extraction scheme is adopted in each level of hierarchy to preserve the relative locations of the different body structures and make the appearance descriptors more discriminating in nature. The proposed approach has been evaluated on five public data sets and also a new data set captured by our team in our laboratory. Results reveal that it outperforms most state-of-the-art approaches in terms of overall accuracy.
Enhancing reinforcement learning by a finite reward response filter with a case study in intelligent structural control
Oct 25, 2020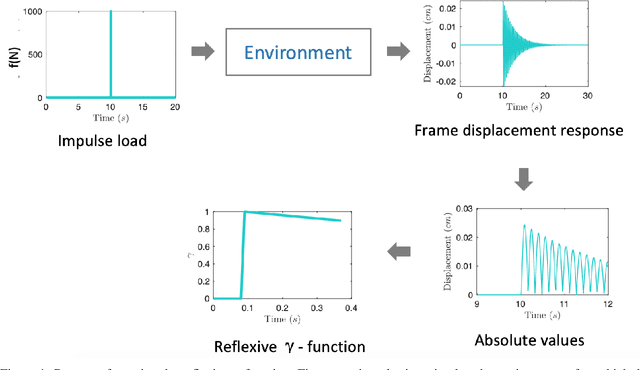

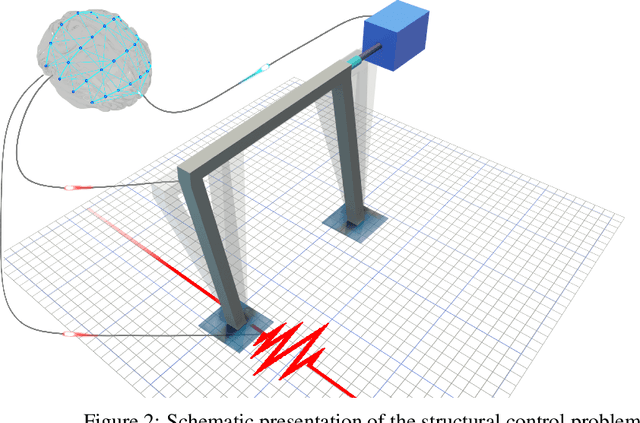
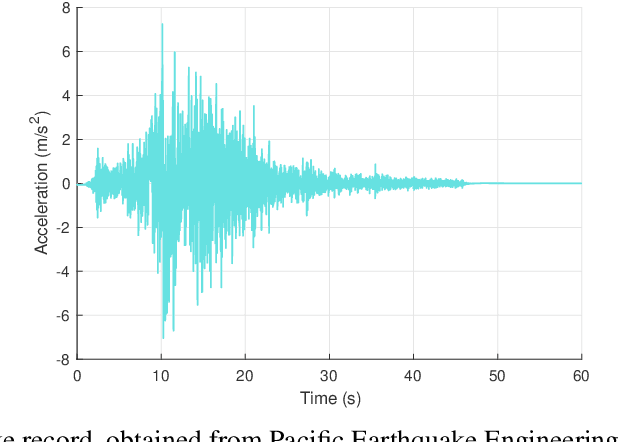
In many reinforcement learning (RL) problems, it takes some time until a taken action by the agent reaches its maximum effect on the environment and consequently the agent receives the reward corresponding to that action by a delay called action-effect delay. Such delays reduce the performance of the learning algorithm and increase the computational costs, as the reinforcement learning agent values the immediate rewards more than the future reward that is more related to the taken action. This paper addresses this issue by introducing an applicable enhanced Q-learning method in which at the beginning of the learning phase, the agent takes a single action and builds a function that reflects the environments response to that action, called the reflexive $\gamma$ - function. During the training phase, the agent utilizes the created reflexive $\gamma$- function to update the Q-values. We have applied the developed method to a structural control problem in which the goal of the agent is to reduce the vibrations of a building subjected to earthquake excitations with a specified delay. Seismic control problems are considered as a complex task in structural engineering because of the stochastic and unpredictable nature of earthquakes and the complex behavior of the structure. Three scenarios are presented to study the effects of zero, medium, and long action-effect delays and the performance of the Enhanced method is compared to the standard Q-learning method. Both RL methods use neural network to learn to estimate the state-action value function that is used to control the structure. The results show that the enhanced method significantly outperforms the performance of the original method in all cases, and also improves the stability of the algorithm in dealing with action-effect delays.
A Visual Analytics Framework for Explaining and Diagnosing Transfer Learning Processes
Sep 15, 2020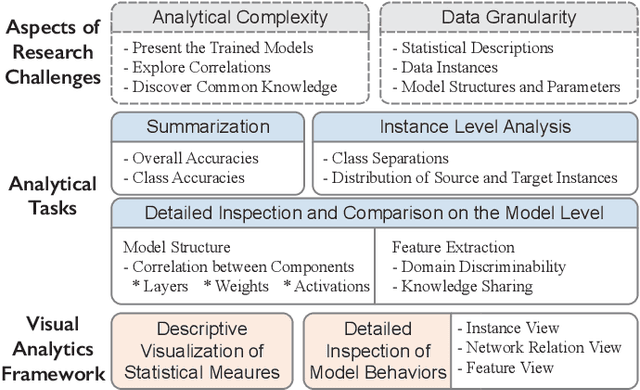
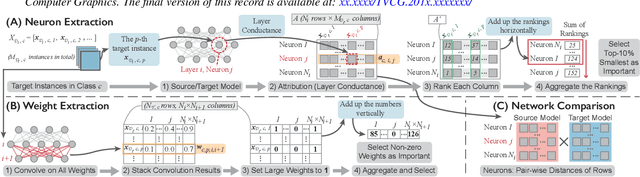
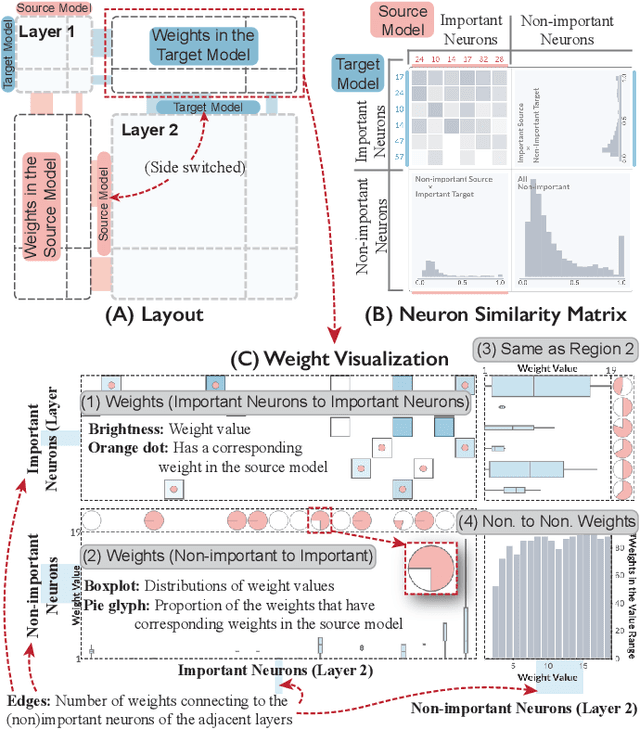

Many statistical learning models hold an assumption that the training data and the future unlabeled data are drawn from the same distribution. However, this assumption is difficult to fulfill in real-world scenarios and creates barriers in reusing existing labels from similar application domains. Transfer Learning is intended to relax this assumption by modeling relationships between domains, and is often applied in deep learning applications to reduce the demand for labeled data and training time. Despite recent advances in exploring deep learning models with visual analytics tools, little work has explored the issue of explaining and diagnosing the knowledge transfer process between deep learning models. In this paper, we present a visual analytics framework for the multi-level exploration of the transfer learning processes when training deep neural networks. Our framework establishes a multi-aspect design to explain how the learned knowledge from the existing model is transferred into the new learning task when training deep neural networks. Based on a comprehensive requirement and task analysis, we employ descriptive visualization with performance measures and detailed inspections of model behaviors from the statistical, instance, feature, and model structure levels. We demonstrate our framework through two case studies on image classification by fine-tuning AlexNets to illustrate how analysts can utilize our framework.
Darwin's Neural Network: AI-based Strategies for Rapid and Scalable Cell and Coronavirus Screening
Jul 22, 2020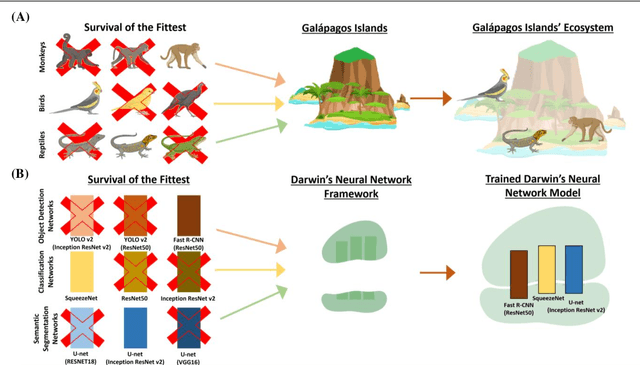
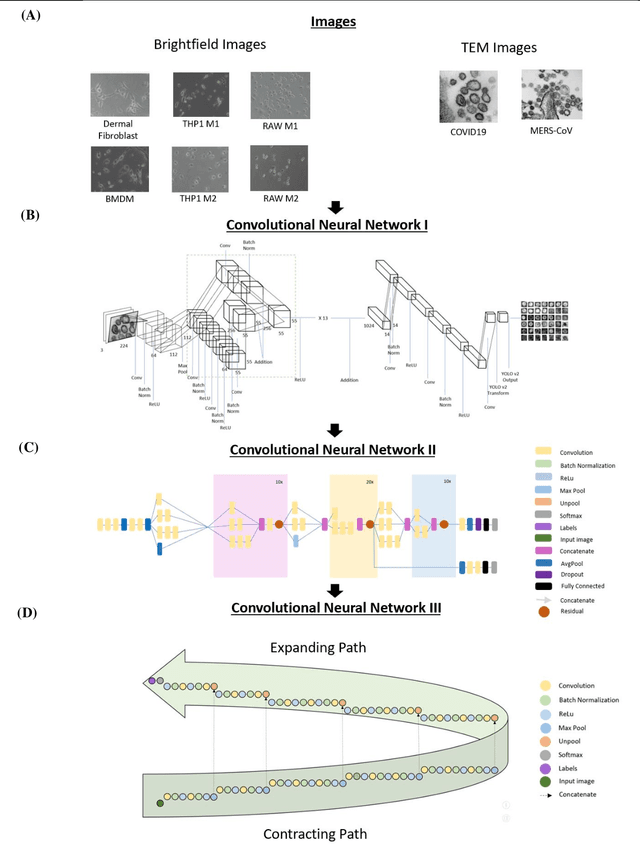
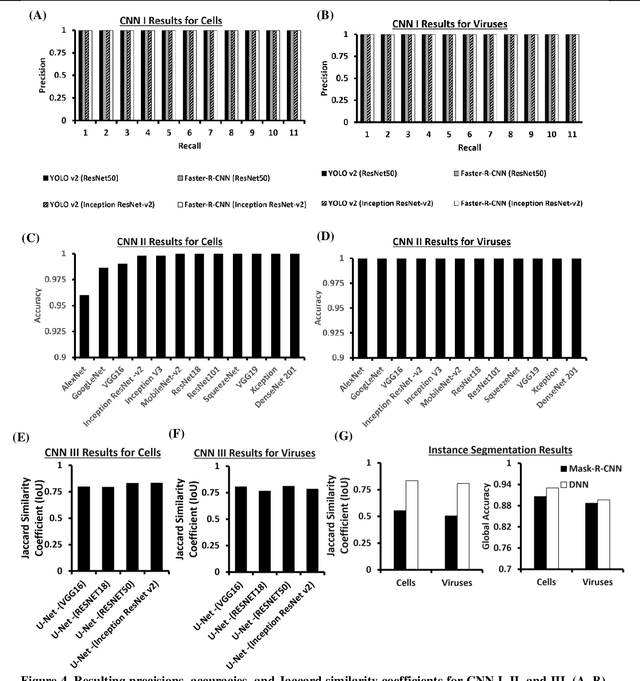
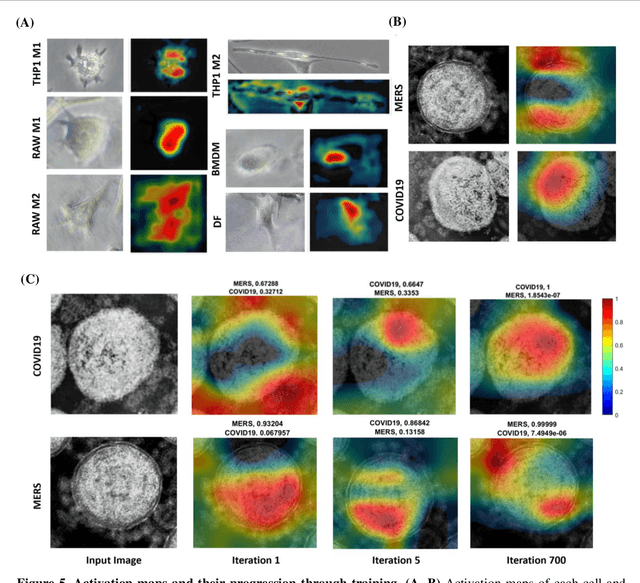
Recent advances in the interdisciplinary scientific field of machine perception, computer vision, and biomedical engineering underpin a collection of machine learning algorithms with a remarkable ability to decipher the contents of microscope and nanoscope images. Machine learning algorithms are transforming the interpretation and analysis of microscope and nanoscope imaging data through use in conjunction with biological imaging modalities. These advances are enabling researchers to carry out real-time experiments that were previously thought to be computationally impossible. Here we adapt the theory of survival of the fittest in the field of computer vision and machine perception to introduce a new framework of multi-class instance segmentation deep learning, Darwin's Neural Network (DNN), to carry out morphometric analysis and classification of COVID19 and MERS-CoV collected in vivo and of multiple mammalian cell types in vitro.
A General Framework for Fairness in Multistakeholder Recommendations
Sep 04, 2020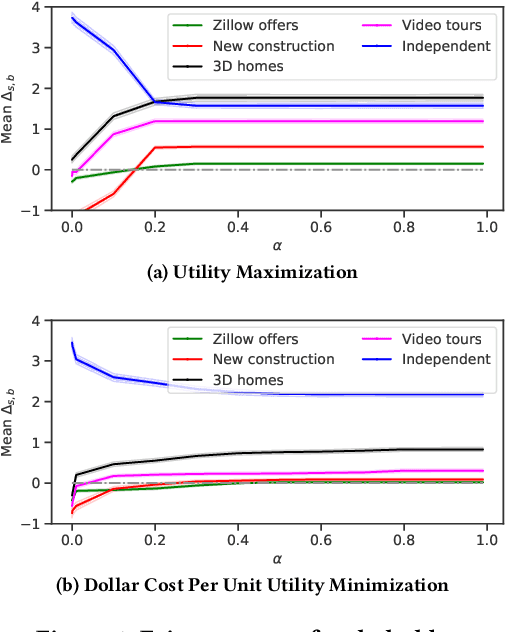
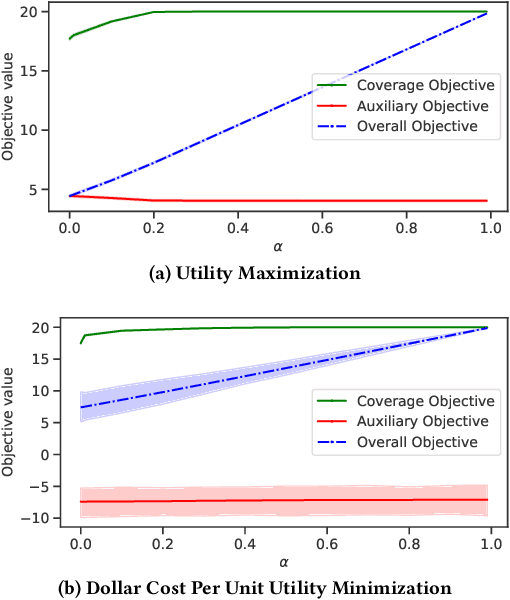
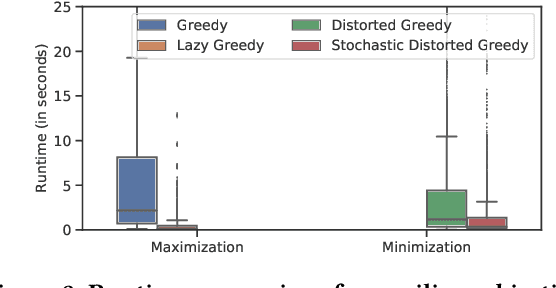
Contemporary recommender systems act as intermediaries on multi-sided platforms serving high utility recommendations from sellers to buyers. Such systems attempt to balance the objectives of multiple stakeholders including sellers, buyers, and the platform itself. The difficulty in providing recommendations that maximize the utility for a buyer, while simultaneously representing all the sellers on the platform has lead to many interesting research problems.Traditionally, they have been formulated as integer linear programs which compute recommendations for all the buyers together in an \emph{offline} fashion, by incorporating coverage constraints so that the individual sellers are proportionally represented across all the recommended items. Such approaches can lead to unforeseen biases wherein certain buyers consistently receive low utility recommendations in order to meet the global seller coverage constraints. To remedy this situation, we propose a general formulation that incorporates seller coverage objectives alongside individual buyer objectives in a real-time personalized recommender system. In addition, we leverage highly scalable submodular optimization algorithms to provide recommendations to each buyer with provable theoretical quality bounds. Furthermore, we empirically evaluate the efficacy of our approach using data from an online real-estate marketplace.
Efficient MDI Adaptation for n-gram Language Models
Aug 05, 2020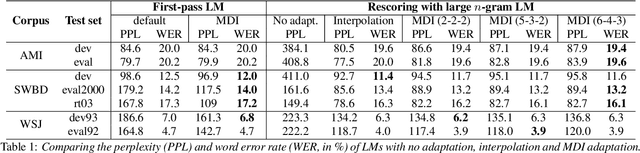
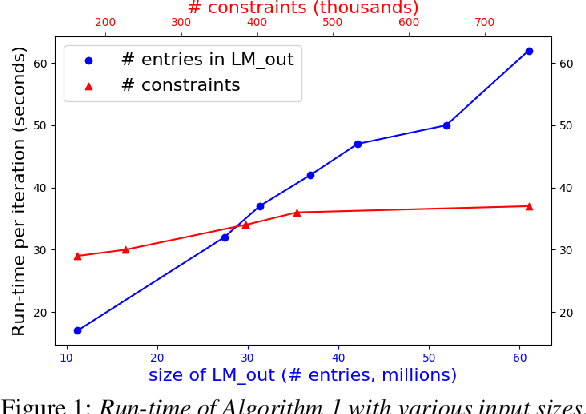
This paper presents an efficient algorithm for n-gram language model adaptation under the minimum discrimination information (MDI) principle, where an out-of-domain language model is adapted to satisfy the constraints of marginal probabilities of the in-domain data. The challenge for MDI language model adaptation is its computational complexity. By taking advantage of the backoff structure of n-gram model and the idea of hierarchical training method, originally proposed for maximum entropy (ME) language models, we show that MDI adaptation can be computed in linear-time complexity to the inputs in each iteration. The complexity remains the same as ME models, although MDI is more general than ME. This makes MDI adaptation practical for large corpus and vocabulary. Experimental results confirm the scalability of our algorithm on very large datasets, while MDI adaptation gets slightly worse perplexity but better word error rate results compared to simple linear interpolation.
The Bethe and Sinkhorn Permanents of Low Rank Matrices and Implications for Profile Maximum Likelihood
Apr 06, 2020In this paper we consider the problem of computing the likelihood of the profile of a discrete distribution, i.e., the probability of observing the multiset of element frequencies, and computing a profile maximum likelihood (PML) distribution, i.e., a distribution with the maximum profile likelihood. For each problem we provide polynomial time algorithms that given $n$ i.i.d.\ samples from a discrete distribution, achieve an approximation factor of $\exp\left(-O(\sqrt{n} \log n) \right)$, improving upon the previous best-known bound achievable in polynomial time of $\exp(-O(n^{2/3} \log n))$ (Charikar, Shiragur and Sidford, 2019). Through the work of Acharya, Das, Orlitsky and Suresh (2016), this implies a polynomial time universal estimator for symmetric properties of discrete distributions in a broader range of error parameter. We achieve these results by providing new bounds on the quality of approximation of the Bethe and Sinkhorn permanents (Vontobel, 2012 and 2014). We show that each of these are $\exp(O(k \log(N/k)))$ approximations to the permanent of $N \times N$ matrices with non-negative rank at most $k$, improving upon the previous known bounds of $\exp(O(N))$. To obtain our results on PML, we exploit the fact that the PML objective is proportional to the permanent of a certain Vandermonde matrix with $\sqrt{n}$ distinct columns, i.e. with non-negative rank at most $\sqrt{n}$. As a by-product of our work we establish a surprising connection between the convex relaxation in prior work (CSS19) and the well-studied Bethe and Sinkhorn approximations.