 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable, Stable, and Scalable Graph Convolutional Networks for Learning Graph Representation
Sep 22, 2020
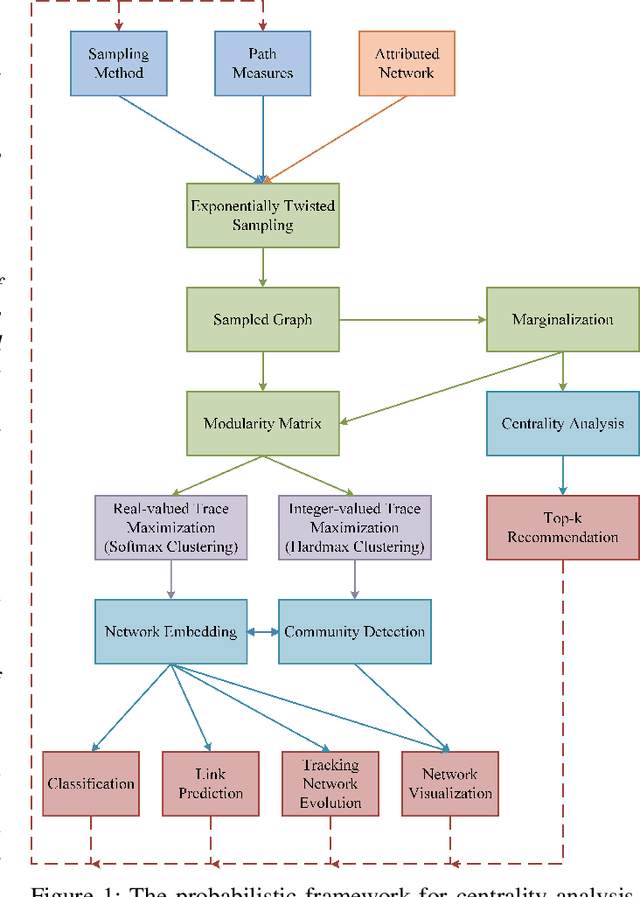
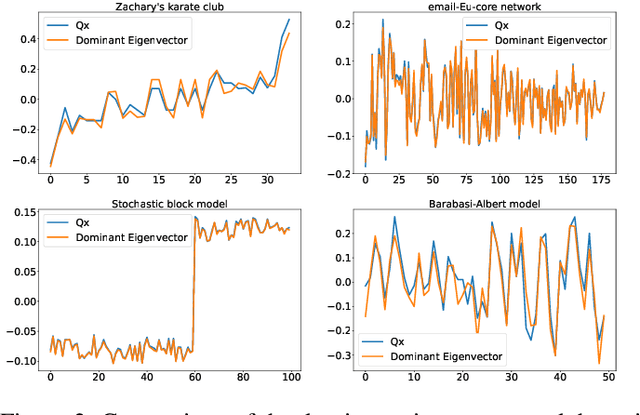
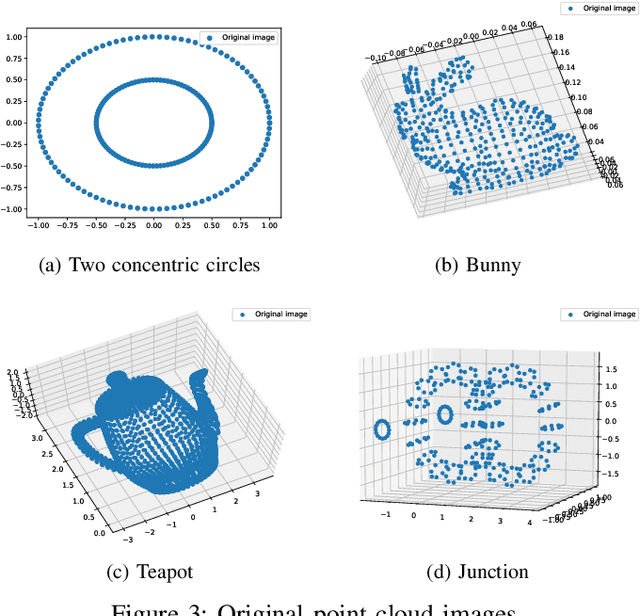
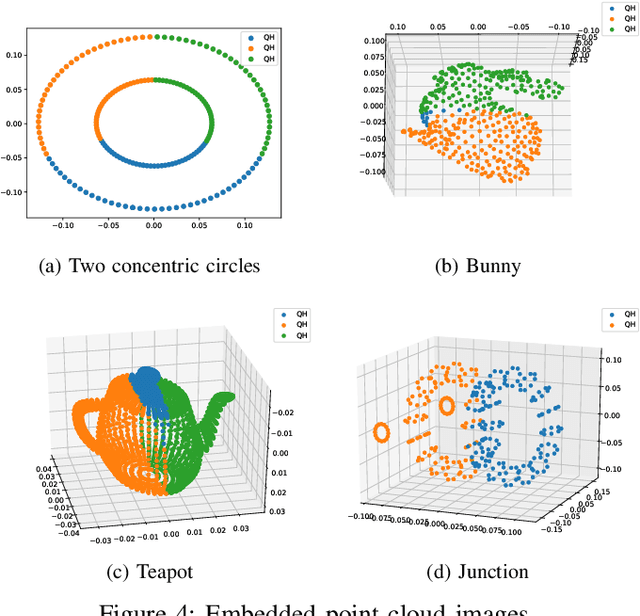
The network embedding problem that maps nodes in a graph to vectors in Euclidean space can be very useful for addressing several important tasks on a graph. Recently, graph neural networks (GNNs) have been proposed for solving such a problem. However, most embedding algorithms and GNNs are difficult to interpret and do not scale well to handle millions of nodes. In this paper, we tackle the problem from a new perspective based on the equivalence of three constrained optimization problems: the network embedding problem, the trace maximization problem of the modularity matrix in a sampled graph, and the matrix factorization problem of the modularity matrix in a sampled graph. The optimal solutions to these three problems are the dominant eigenvectors of the modularity matrix. We proposed two algorithms that belong to a special class of graph convolutional networks (GCNs) for solving these problems: (i) Clustering As Feature Embedding GCN (CAFE-GCN) and (ii) sphere-GCN. Both algorithms are stable trace maximization algorithms, and they yield good approximations of dominant eigenvectors. Moreover, there are linear-time implementations for sparse graphs. In addition to solving the network embedding problem, both proposed GCNs are capable of performing dimensionality reduction. Various experiments are conducted to evaluate our proposed GCNs and show that our proposed GCNs outperform almost all the baseline methods. Moreover, CAFE-GCN could be benefited from the labeled data and have tremendous improvements in various performance metrics.
HMOR: Hierarchical Multi-Person Ordinal Relations for Monocular Multi-Person 3D Pose Estimation
Aug 01, 2020
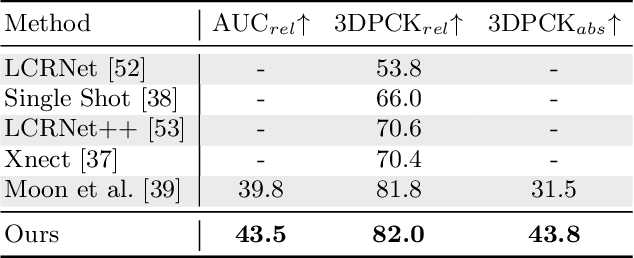
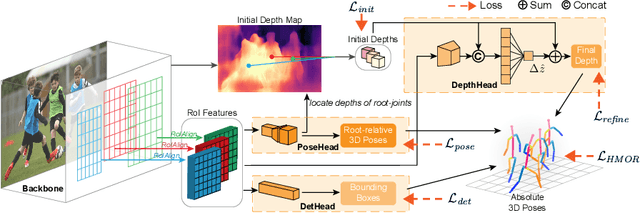
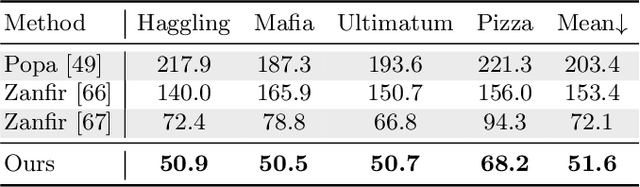
Remarkable progress has been made in 3D human pose estimation from a monocular RGB camera. However, only a few studies explored 3D multi-person cases. In this paper, we attempt to address the lack of a global perspective of the top-down approaches by introducing a novel form of supervision - Hierarchical Multi-person Ordinal Relations (HMOR). The HMOR encodes interaction information as the ordinal relations of depths and angles hierarchically, which captures the body-part and joint level semantic and maintains global consistency at the same time. In our approach, an integrated top-down model is designed to leverage these ordinal relations in the learning process. The integrated model estimates human bounding boxes, human depths, and root-relative 3D poses simultaneously, with a coarse-to-fine architecture to improve the accuracy of depth estimation. The proposed method significantly outperforms state-of-the-art methods on publicly available multi-person 3D pose datasets. In addition to superior performance, our method costs lower computation complexity and fewer model parameters.
Score-informed Networks for Music Performance Assessment
Aug 01, 2020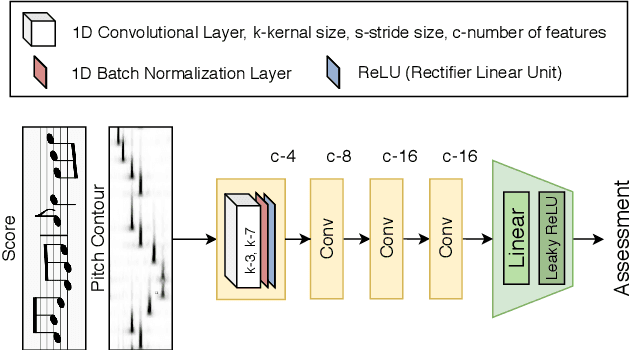
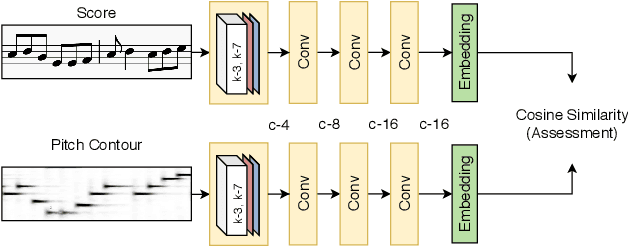
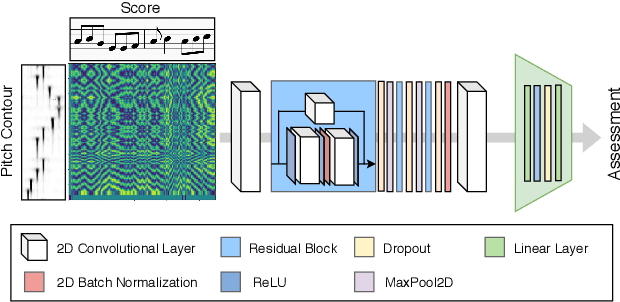
The assessment of music performances in most cases takes into account the underlying musical score being performed. While there have been several automatic approaches for objective music performance assessment (MPA) based on extracted features from both the performance audio and the score, deep neural network-based methods incorporating score information into MPA models have not yet been investigated. In this paper, we introduce three different models capable of score-informed performance assessment. These are (i) a convolutional neural network that utilizes a simple time-series input comprising of aligned pitch contours and score, (ii) a joint embedding model which learns a joint latent space for pitch contours and scores, and (iii) a distance matrix-based convolutional neural network which utilizes patterns in the distance matrix between pitch contours and musical score to predict assessment ratings. Our results provide insights into the suitability of different architectures and input representations and demonstrate the benefits of score-informed models as compared to score-independent models.
A Partial Regularization Method for Network Compression
Sep 04, 2020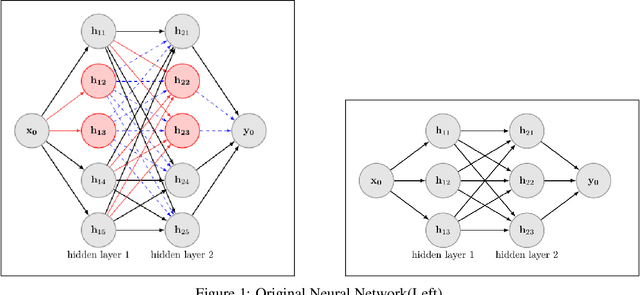
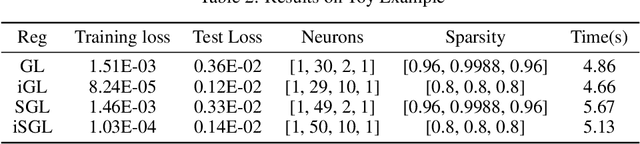
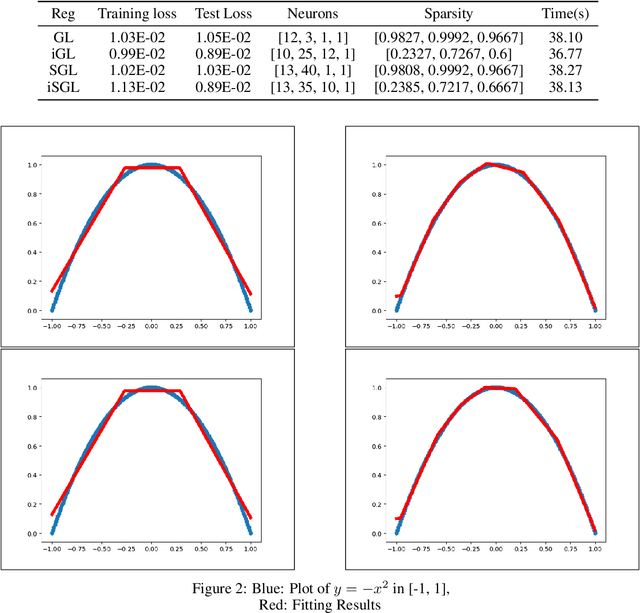
Deep Neural Networks have achieved remarkable success relying on the developing availability of GPUs and large-scale datasets with increasing network depth and width. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in order to make them practical for constrained platforms. In this paper, we propose an approach of partial regularization rather than the original form of penalizing all parameters, which is said to be full regularization, to conduct model compression at a higher speed. It is reasonable and feasible according to the existence of the permutation invariant property of neural networks. Experimental results show that as we expected, the computational complexity is reduced by observing less running time in almost all situations. It should be owing to the fact that partial regularization method invovles a lower number of elements for calculation. Surprisingly, it helps to improve some important metrics such as regression fitting results and classification accuracy in both training and test phases on multiple datasets, telling us that the pruned models have better performance and generalization ability. What's more, we analyze the results and draw a conclusion that an optimal network structure must exist and depend on the input data.
Backward Feature Correction: How Deep Learning Performs Deep Learning
Jan 13, 2020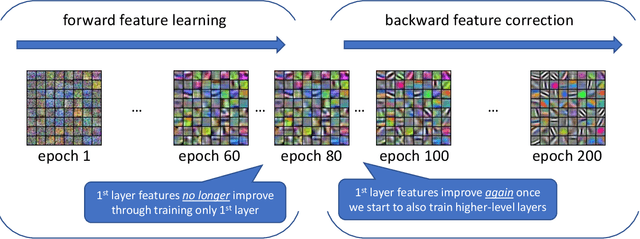

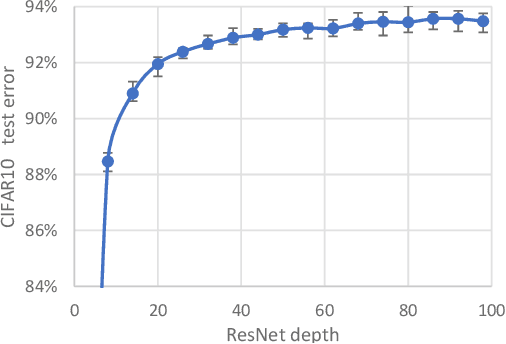
How does a 110-layer ResNet learn a high-complexity classifier using relatively few training examples and short training time? We present a theory towards explaining this in terms of $\textit{hierarchical learning}$. We refer hierarchical learning as the learner learns to represent a complicated target function by decomposing it into a sequence of simpler functions to reduce sample and time complexity. This paper formally analyzes how multi-layer neural networks can perform such hierarchical learning efficiently and automatically simply by applying stochastic gradient descent (SGD). On the conceptual side, we present, to the best of our knowledge, the FIRST theory result indicating how very deep neural networks can still be sample and time efficient on certain hierarchical learning tasks, when NO KNOWN non-hierarchical algorithms (such as kernel method, linear regression over feature mappings, tensor decomposition, sparse coding) are efficient. We establish a new principle called "backward feature correction", which we believe is the key to understand the hierarchical learning in multi-layer neural networks. On the technical side, we show for regression and even for binary classification, for every input dimension $d > 0$, there is a concept class consisting of degree $\omega(1)$ multi-variate polynomials so that, using $\omega(1)$-layer neural networks as learners, SGD can learn any target function from this class in $\mathsf{poly}(d)$ time using $\mathsf{poly}(d)$ samples to any $\frac{1}{\mathsf{poly}(d)}$ error, through learning to represent it as a composition of $\omega(1)$ layers of quadratic functions. In contrast, we present lower bounds stating that several non-hierarchical learners, including any kernel methods, neural tangent kernels, must suffer from $d^{\omega(1)}$ sample or time complexity to learn functions in this concept class even to any $d^{-0.01}$ error.
On Efficient Connectivity-Preserving Transformations in a Grid
May 17, 2020
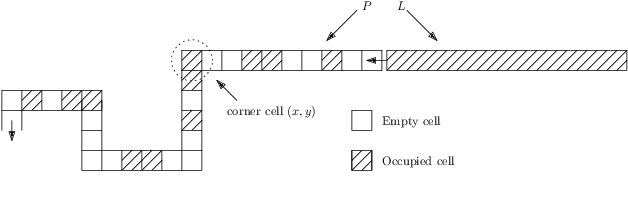
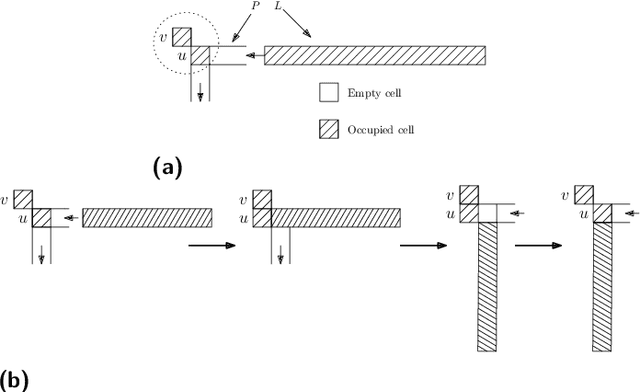
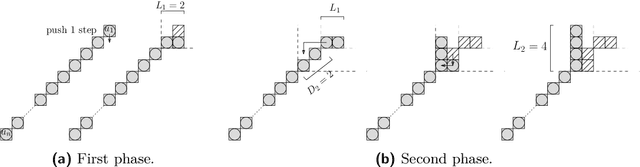
We consider a discrete system of $n$ devices lying on a 2-dimensional square grid and forming an initial connected shape $S_I$. Each device is equipped with a linear-strength mechanism which enables it to move a whole line of consecutive devices in a single time-step. We study the problem of transforming $S_I$ into a given connected target shape $S_F$ of the same number of devices, via a finite sequence of \emph{line moves}. Our focus is on designing \emph{centralised} transformations aiming at \emph{minimising the total number of moves} subject to the constraint of \emph{preserving connectivity} of the shape throughout the course of the transformation. We first give very fast connectivity-preserving transformations for the case in which the \emph{associated graphs} of $ S_I $ and $ S_F $ are isomorphic to a Hamiltonian line. In particular, our transformations make $ O(n \log n $) moves, which is asymptotically equal to the best known running time of connectivity-breaking transformations. Our most general result is then a connectivity-preserving \emph{universal transformation} that can transform any initial connected shape $ S_I $ into any target connected shape $ S_F $, through a sequence of $O(n\sqrt{n})$ moves. Finally, we establish $\Omega(n \log n)$ lower bounds for two restricted sets of transformations. These are the first lower bounds for this model and are matching the best known $ O(n \log n) $ upper bounds.
Optimal Assistance for Object-Rearrangement Tasks in Augmented Reality
Oct 14, 2020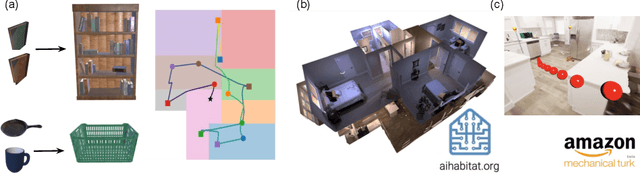
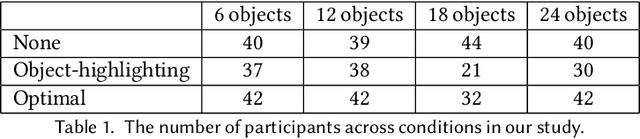
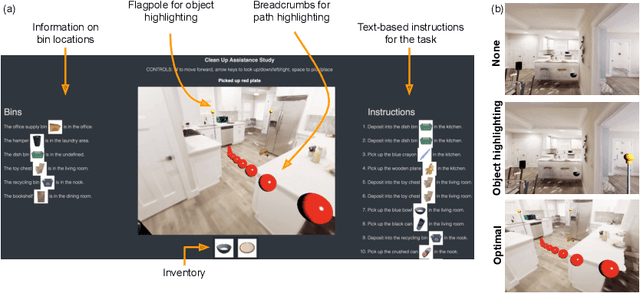
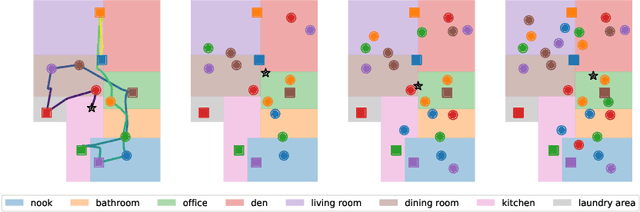
Augmented-reality (AR) glasses that will have access to onboard sensors and an ability to display relevant information to the user present an opportunity to provide user assistance in quotidian tasks. Many such tasks can be characterized as object-rearrangement tasks. We introduce a novel framework for computing and displaying AR assistance that consists of (1) associating an optimal action sequence with the policy of an embodied agent and (2) presenting this sequence to the user as suggestions in the AR system's heads-up display. The embodied agent comprises a "hybrid" between the AR system and the user, with the AR system's observation space (i.e., sensors) and the user's action space (i.e., task-execution actions); its policy is learned by minimizing the task-completion time. In this initial study, we assume that the AR system's observations include the environment's map and localization of the objects and the user. These choices allow us to formalize the problem of computing AR assistance for any object-rearrangement task as a planning problem, specifically as a capacitated vehicle-routing problem. Further, we introduce a novel AR simulator that can enable web-based evaluation of AR-like assistance and associated at-scale data collection via the Habitat simulator for embodied artificial intelligence. Finally, we perform a study that evaluates user response to the proposed form of AR assistance on a specific quotidian object-rearrangement task, house cleaning, using our proposed AR simulator on mechanical turk. In particular, we study the effect of the proposed AR assistance on users' task performance and sense of agency over a range of task difficulties. Our results indicate that providing users with such assistance improves their overall performance and while users report a negative impact to their agency, they may still prefer the proposed assistance to having no assistance at all.
Automatic Classification of Irregularly Sampled Time Series with Unequal Lengths: A Case Study on Estimated Glomerular Filtration Rate
May 17, 2016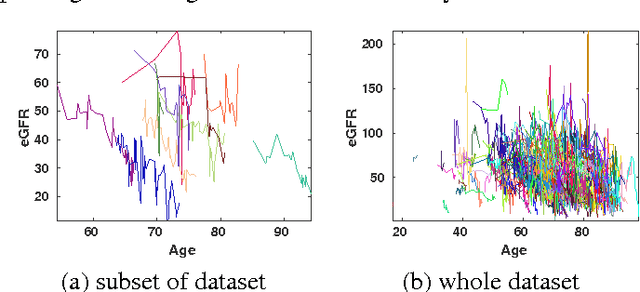

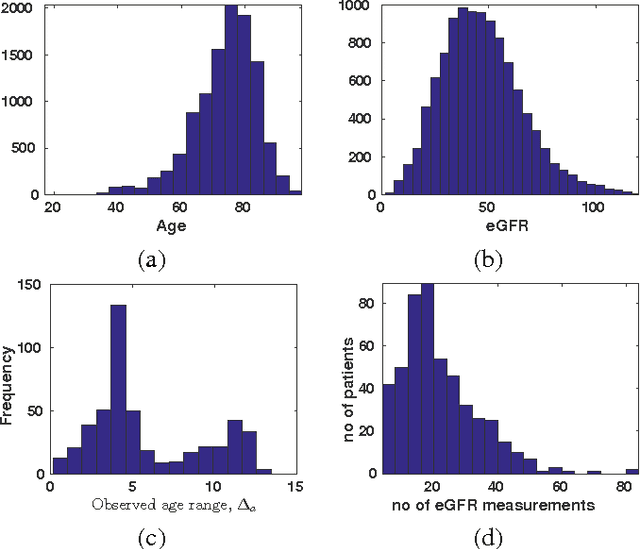
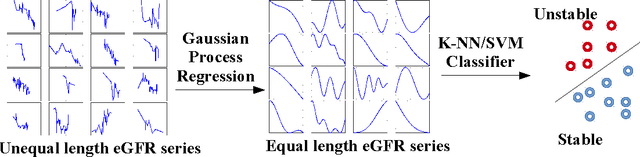
A patient's estimated glomerular filtration rate (eGFR) can provide important information about disease progression and kidney function. Traditionally, an eGFR time series is interpreted by a human expert labelling it as stable or unstable. While this approach works for individual patients, the time consuming nature of it precludes the quick evaluation of risk in large numbers of patients. However, automating this process poses significant challenges as eGFR measurements are usually recorded at irregular intervals and the series of measurements differs in length between patients. Here we present a two-tier system to automatically classify an eGFR trend. First, we model the time series using Gaussian process regression (GPR) to fill in `gaps' by resampling a fixed size vector of fifty time-dependent observations. Second, we classify the resampled eGFR time series using a K-NN/SVM classifier, and evaluate its performance via 5-fold cross validation. Using this approach we achieved an F-score of 0.90, compared to 0.96 for 5 human experts when scored amongst themselves.
A Multifactorial Optimization Paradigm for Linkage Tree Genetic Algorithm
May 06, 2020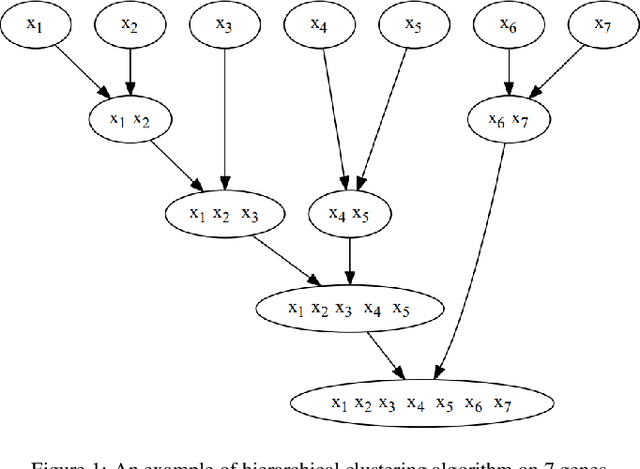
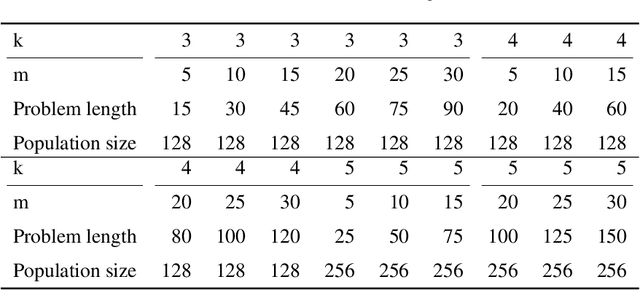
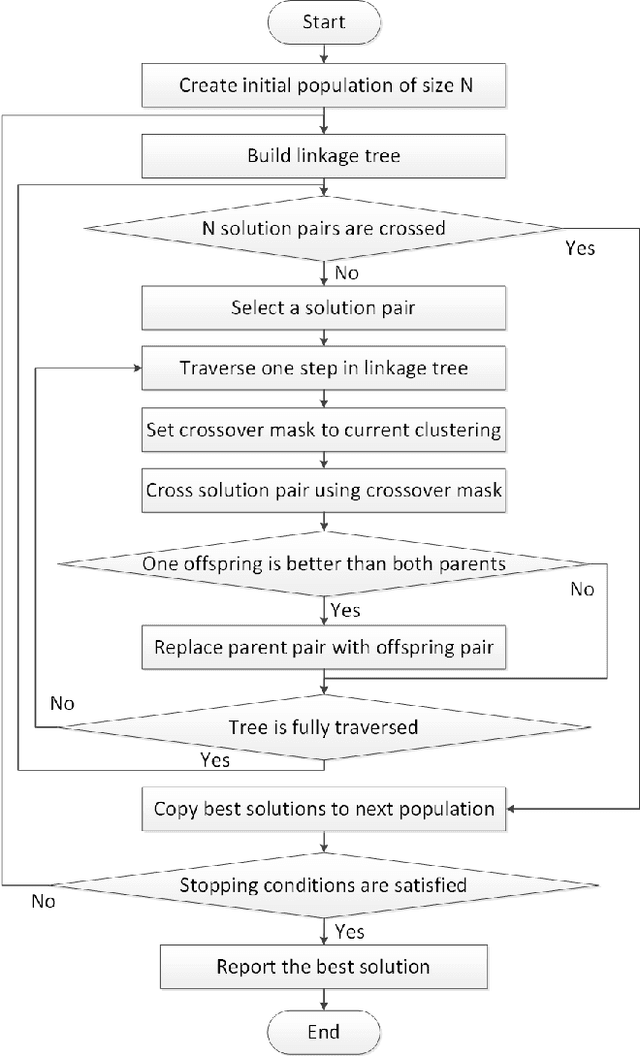
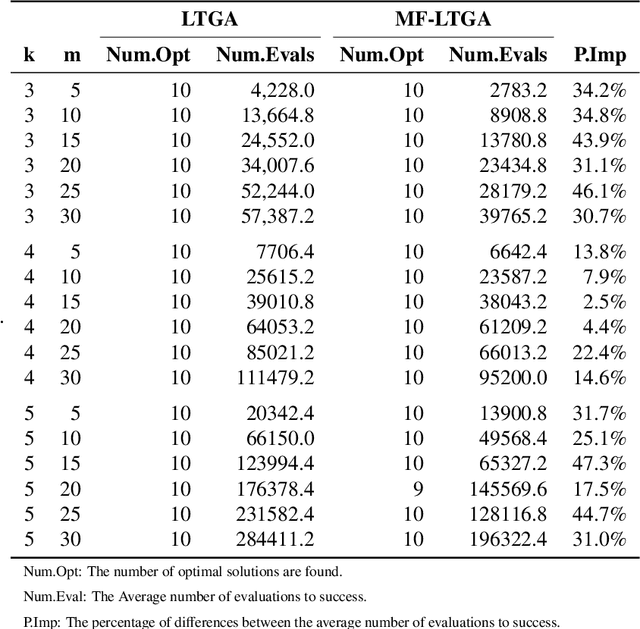
Linkage Tree Genetic Algorithm (LTGA) is an effective Evolutionary Algorithm (EA) to solve complex problems using the linkage information between problem variables. LTGA performs well in various kinds of single-task optimization and yields promising results in comparison with the canonical genetic algorithm. However, LTGA is an unsuitable method for dealing with multi-task optimization problems. On the other hand, Multifactorial Optimization (MFO) can simultaneously solve independent optimization problems, which are encoded in a unified representation to take advantage of the process of knowledge transfer. In this paper, we introduce Multifactorial Linkage Tree Genetic Algorithm (MF-LTGA) by combining the main features of both LTGA and MFO. MF-LTGA is able to tackle multiple optimization tasks at the same time, each task learns the dependency between problem variables from the shared representation. This knowledge serves to determine the high-quality partial solutions for supporting other tasks in exploring the search space. Moreover, MF-LTGA speeds up convergence because of knowledge transfer of relevant problems. We demonstrate the effectiveness of the proposed algorithm on two benchmark problems: Clustered Shortest-Path Tree Problem and Deceptive Trap Function. In comparison to LTGA and existing methods, MF-LTGA outperforms in quality of the solution or in computation time.
Dynamic time warping distance for message propagation classification in Twitter
Jan 26, 2017
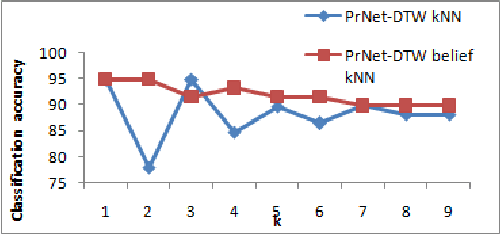
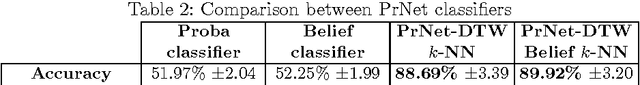
Social messages classification is a research domain that has attracted the attention of many researchers in these last years. Indeed, the social message is different from ordinary text because it has some special characteristics like its shortness. Then the development of new approaches for the processing of the social message is now essential to make its classification more efficient. In this paper, we are mainly interested in the classification of social messages based on their spreading on online social networks (OSN). We proposed a new distance metric based on the Dynamic Time Warping distance and we use it with the probabilistic and the evidential k Nearest Neighbors (k-NN) classifiers to classify propagation networks (PrNets) of messages. The propagation network is a directed acyclic graph (DAG) that is used to record propagation traces of the message, the traversed links and their types. We tested the proposed metric with the chosen k-NN classifiers on real world propagation traces that were collected from Twitter social network and we got good classification accuracies.