 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intermittent Demand Forecasting with Deep Renewal Processes
Nov 23, 2019
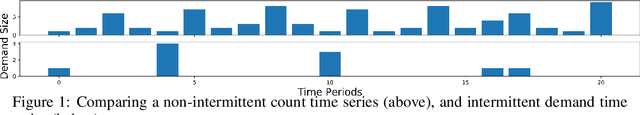


Intermittent demand, where demand occurrences appear sporadically in time, is a common and challenging problem in forecasting. In this paper, we first make the connections between renewal processes, and a collection of current models used for intermittent demand forecasting. We then develop a set of models that benefit from recurrent neural networks to parameterize conditional interdemand time and size distributions, building on the latest paradigm in "deep" temporal point processes. We present favorable empirical findings on discrete and continuous time intermittent demand data, validating the practical value of our approach.
Sampling possible reconstructions of undersampled acquisitions in MR imaging
Sep 30, 2020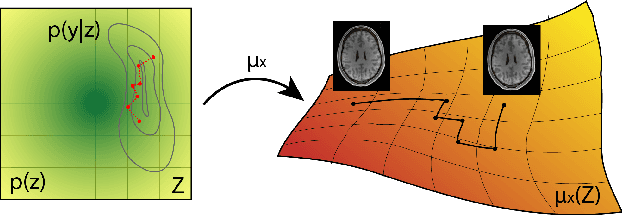
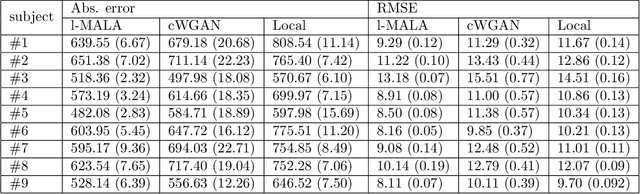
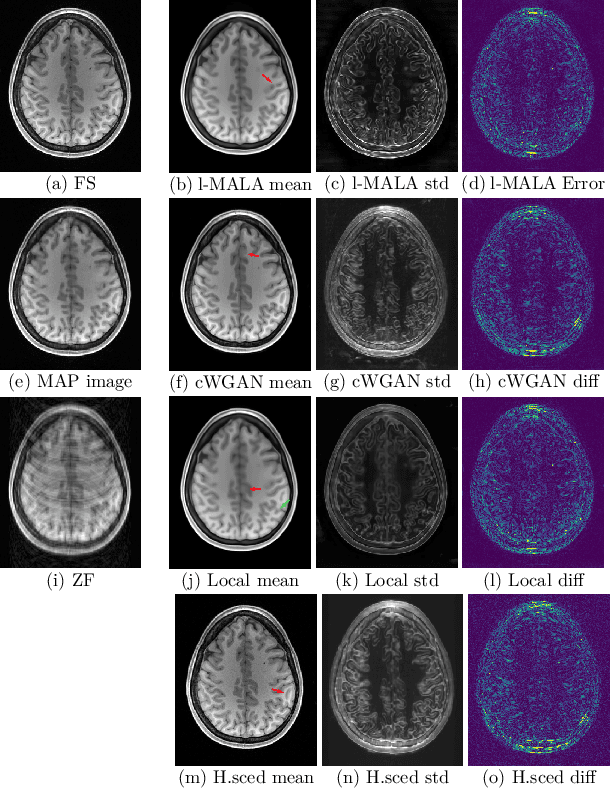
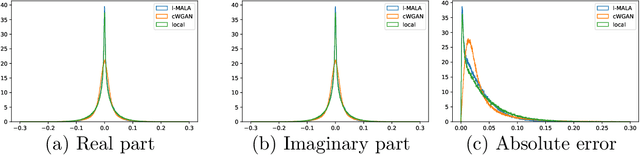
Undersampling the k-space during MR acquisitions saves time, however results in an ill-posed inversion problem, leading to an infinite set of images as possible solutions. Traditionally, this is tackled as a reconstruction problem by searching for a single "best" image out of this solution set according to some chosen regularization or prior. This approach, however, misses the possibility of other solutions and hence ignores the uncertainty in the inversion process. In this paper, we propose a method that instead returns multiple images which are possible under the acquisition model and the chosen prior. To this end, we introduce a low dimensional latent space and model the posterior distribution of the latent vectors given the acquisition data in k-space, from which we can sample in the latent space and obtain the corresponding images. We use a variational autoencoder for the latent model and the Metropolis adjusted Langevin algorithm for the sampling. This approach allows us to obtain multiple possible images and capture the uncertainty in the inversion process under the used prior. We evaluate our method on images from the Human Connectome Project dataset as well as in-house measured multi-coil images and compare to two different methods. The results indicate that the proposed method is capable of producing images that match the ground truth in regions where acquired k-space data is informative and construct different possible reconstructions, which show realistic structural variations, in regions where acquired k-space data is not informative. Keywords: Magnetic Resonance image reconstruction, uncertainty estimation, inverse problems, sampling, MCMC, deep learning, unsupervised learning.
Estimating Blood Pressure from Photoplethysmogram Signal and Demographic Features using Machine Learning Techniques
May 07, 2020Hypertension is a potentially unsafe health ailment, which can be indicated directly from the Blood pressure (BP). Hypertension always leads to other health complications. Continuous monitoring of BP is very important; however, cuff-based BP measurements are discrete and uncomfortable to the user. To address this need, a cuff-less, continuous and a non-invasive BP measurement system is proposed using Photoplethysmogram (PPG) signal and demographic features using machine learning (ML) algorithms. PPG signals were acquired from 219 subjects, which undergo pre-processing and feature extraction steps. Time, frequency and time-frequency domain features were extracted from the PPG and their derivative signals. Feature selection techniques were used to reduce the computational complexity and to decrease the chance of over-fitting the ML algorithms. The features were then used to train and evaluate ML algorithms. The best regression models were selected for Systolic BP (SBP) and Diastolic BP (DBP) estimation individually. Gaussian Process Regression (GPR) along with ReliefF feature selection algorithm outperforms other algorithms in estimating SBP and DBP with a root-mean-square error (RMSE) of 6.74 and 3.59 respectively. This ML model can be implemented in hardware systems to continuously monitor BP and avoid any critical health conditions due to sudden changes.
Context-Dependent Implicit Authentication for Wearable Device User
Aug 25, 2020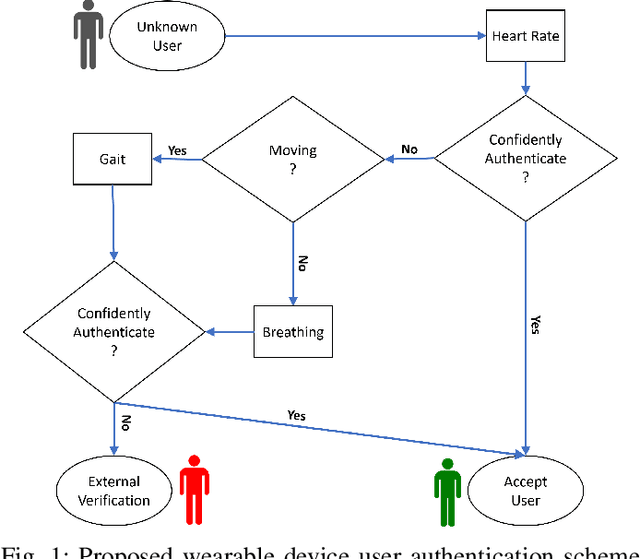
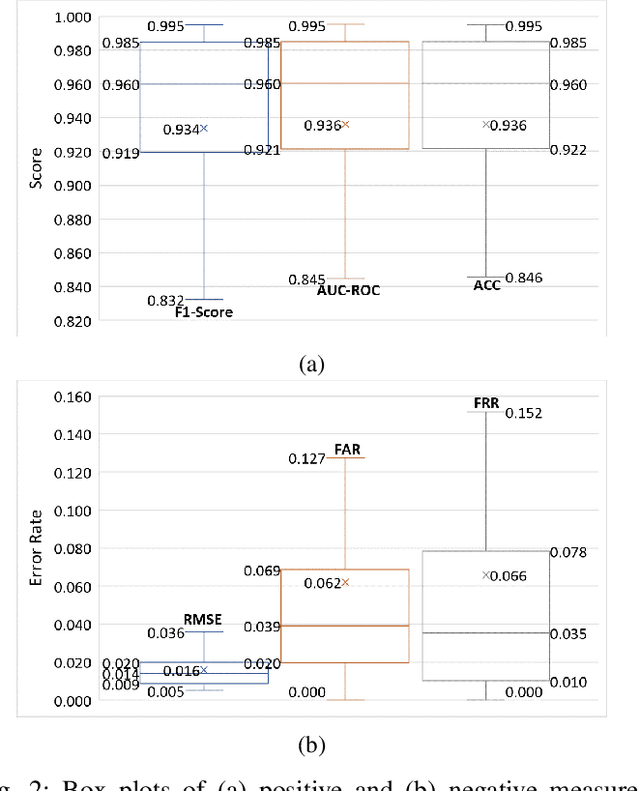
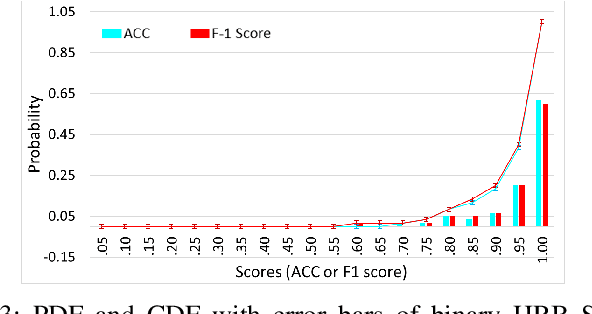
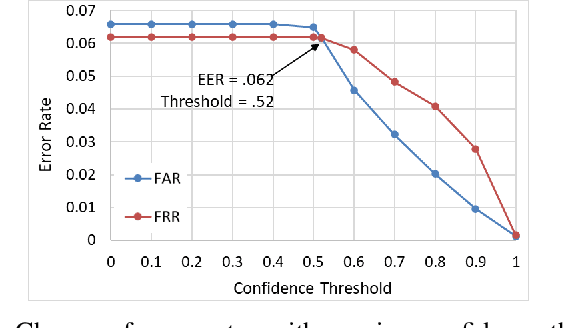
As market wearables are becoming popular with a range of services, including making financial transactions, accessing cars, etc. that they provide based on various private information of a user, security of this information is becoming very important. However, users are often flooded with PINs and passwords in this internet of things (IoT) world. Additionally, hard-biometric, such as facial or finger recognition, based authentications are not adaptable for market wearables due to their limited sensing and computation capabilities. Therefore, it is a time demand to develop a burden-free implicit authentication mechanism for wearables using the less-informative soft-biometric data that are easily obtainable from the market wearables. In this work, we present a context-dependent soft-biometric-based wearable authentication system utilizing the heart rate, gait, and breathing audio signals. From our detailed analysis, we find that a binary support vector machine (SVM) with radial basis function (RBF) kernel can achieve an average accuracy of $0.94 \pm 0.07$, $F_1$ score of $0.93 \pm 0.08$, an equal error rate (EER) of about $0.06$ at a lower confidence threshold of 0.52, which shows the promise of this work.
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
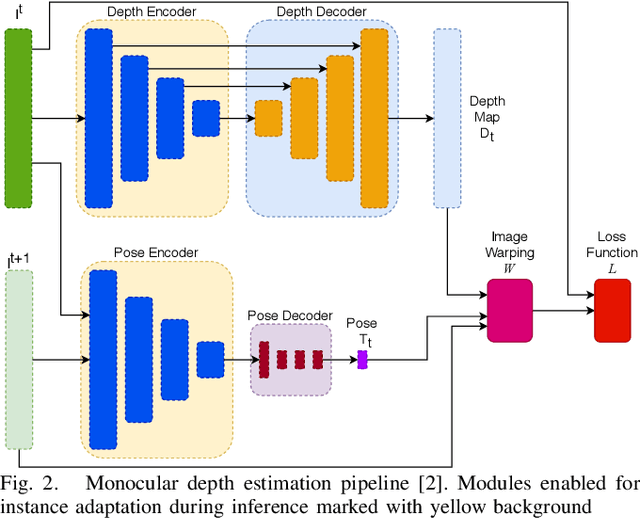
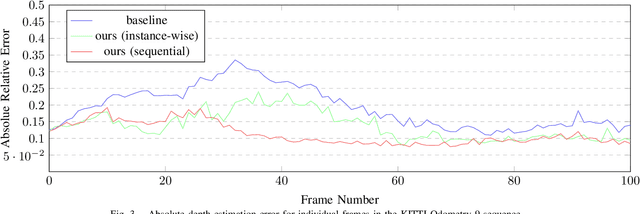
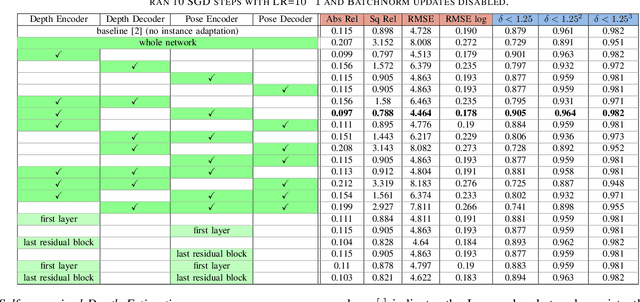
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
GraphXCOVID: Explainable Deep Graph Diffusion Pseudo-Labelling for Identifying COVID-19 on Chest X-rays
Sep 30, 2020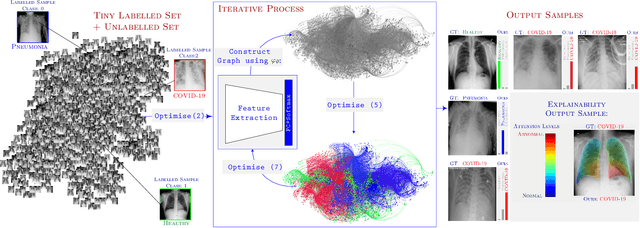
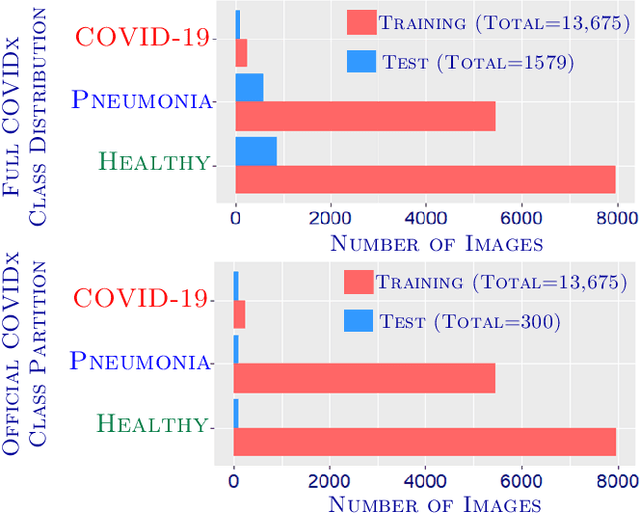
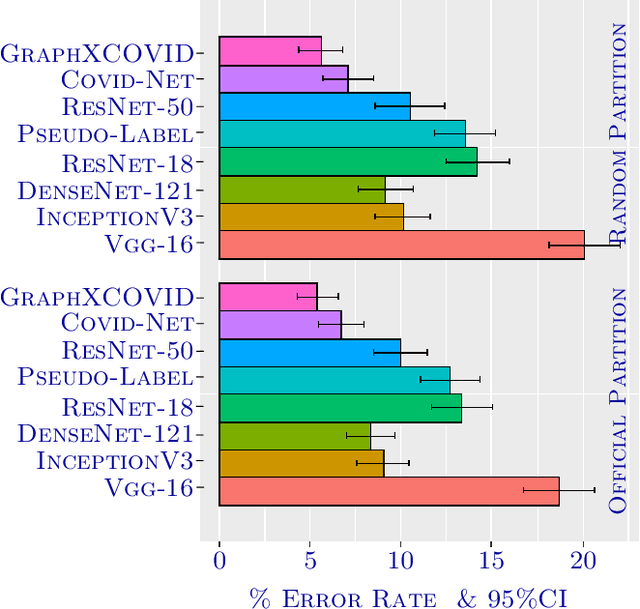
Can one learn to diagnose COVID-19 under extreme minimal supervision? Since the outbreak of the novel COVID-19 there has been a rush for developing Artificial Intelligence techniques for expert-level disease identification on Chest X-ray data. In particular, the use of deep supervised learning has become the go-to paradigm. However, the performance of such models is heavily dependent on the availability of a large and representative labelled dataset. The creation of which is a heavily expensive and time consuming task, and especially imposes a great challenge for a novel disease. Semi-supervised learning has shown the ability to match the incredible performance of supervised models whilst requiring a small fraction of the labelled examples. This makes the semi-supervised paradigm an attractive option for identifying COVID-19. In this work, we introduce a graph based deep semi-supervised framework for classifying COVID-19 from chest X-rays. Our framework introduces an optimisation model for graph diffusion that reinforces the natural relation among the tiny labelled set and the vast unlabelled data. We then connect the diffusion prediction output as pseudo-labels that are used in an iterative scheme in a deep net. We demonstrate, through our experiments, that our model is able to outperform the current leading supervised model with a tiny fraction of the labelled examples. Finally, we provide attention maps to accommodate the radiologist's mental model, better fitting their perceptual and cognitive abilities. These visualisation aims to assist the radiologist in judging whether the diagnostic is correct or not, and in consequence to accelerate the decision.
Brain Emotional Learning-based Prediction Model For the Prediction of Geomagnetic Storms
Aug 01, 2020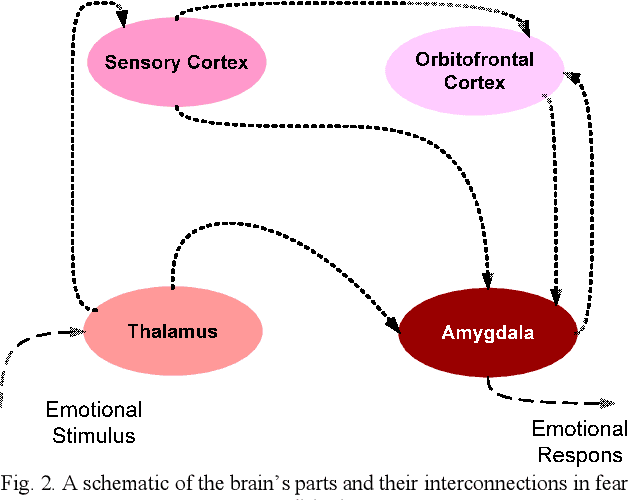
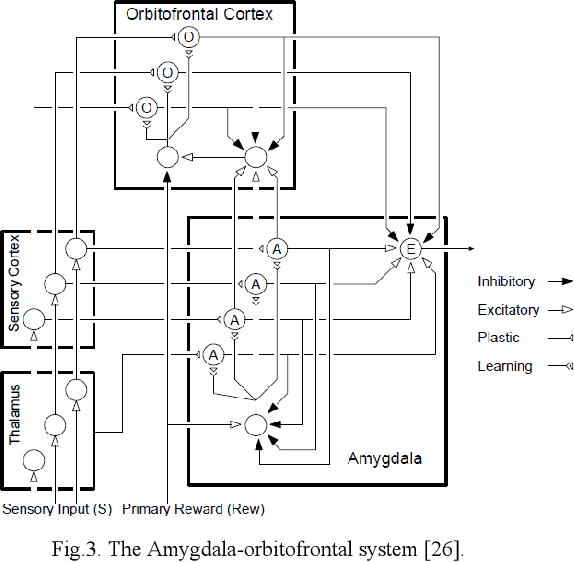
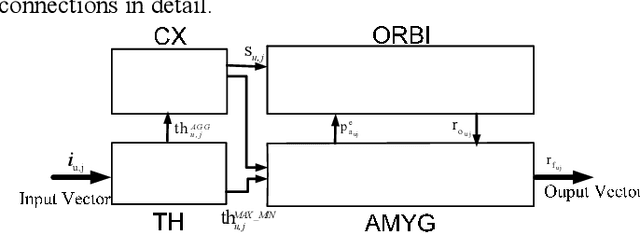
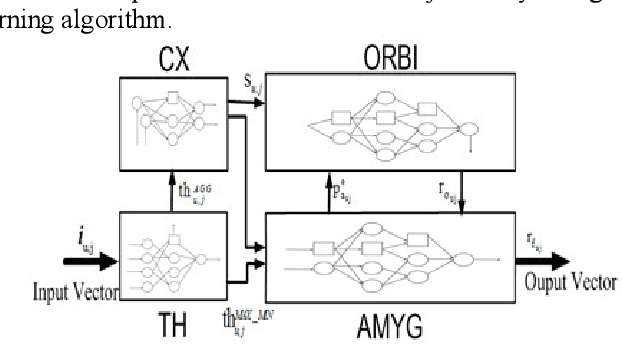
This study suggests a new data-driven model for the prediction of geomagnetic storm. The model which is an instance of Brain Emotional Learning Inspired Models (BELIMs), is known as the Brain Emotional Learning-based Prediction Model (BELPM). BELPM consists of four main subsystems; the connection between these subsystems has been mimicked by the corresponding regions of the emotional system. The functions of these subsystems are explained using adaptive networks. The learning algorithm of BELPM is defined using the steepest descent (SD) and the least square estimator (LSE). BELPM is employed to predict geomagnetic storms using two geomagnetic indices, Auroral Electrojet (AE) Index and Disturbance Time (Dst) Index. To evaluate the performance of BELPM, the obtained results have been compared with ANFIS, WKNN and other instances of BELIMs. The results verify that BELPM has the capability to achieve a reasonable accuracy for both the short-term and the long-term geomagnetic storms prediction.
Synthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild
Sep 22, 2020
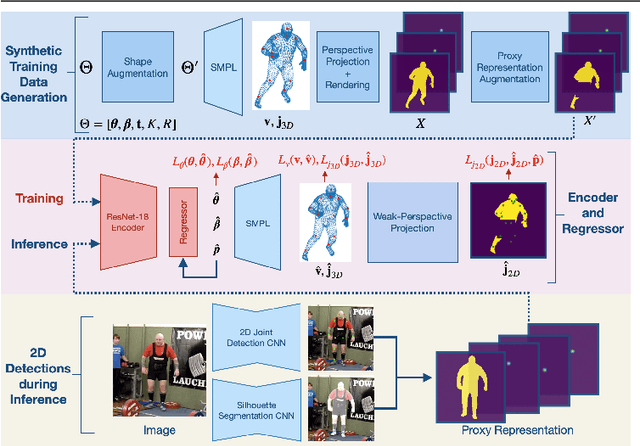
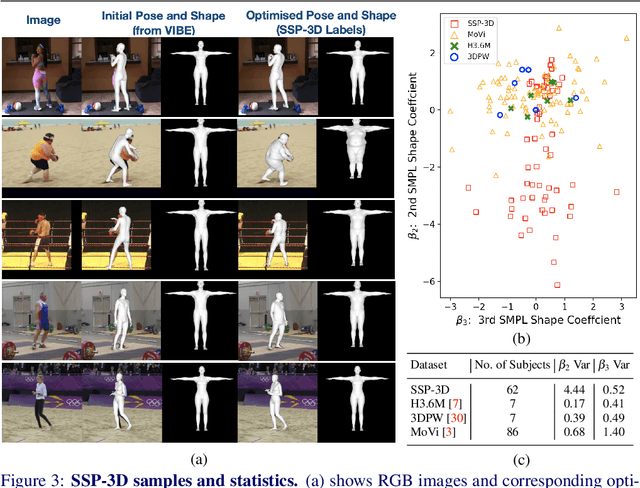

This paper addresses the problem of monocular 3D human shape and pose estimation from an RGB image. Despite great progress in this field in terms of pose prediction accuracy, state-of-the-art methods often predict inaccurate body shapes. We suggest that this is primarily due to the scarcity of in-the-wild training data with diverse and accurate body shape labels. Thus, we propose STRAPS (Synthetic Training for Real Accurate Pose and Shape), a system that utilises proxy representations, such as silhouettes and 2D joints, as inputs to a shape and pose regression neural network, which is trained with synthetic training data (generated on-the-fly during training using the SMPL statistical body model) to overcome data scarcity. We bridge the gap between synthetic training inputs and noisy real inputs, which are predicted by keypoint detection and segmentation CNNs at test-time, by using data augmentation and corruption during training. In order to evaluate our approach, we curate and provide a challenging evaluation dataset for monocular human shape estimation, Sports Shape and Pose 3D (SSP-3D). It consists of RGB images of tightly-clothed sports-persons with a variety of body shapes and corresponding pseudo-ground-truth SMPL shape and pose parameters, obtained via multi-frame optimisation. We show that STRAPS outperforms other state-of-the-art methods on SSP-3D in terms of shape prediction accuracy, while remaining competitive with the state-of-the-art on pose-centric datasets and metrics.
Enabling Incremental Knowledge Transfer for Object Detection at the Edge
Apr 13, 2020
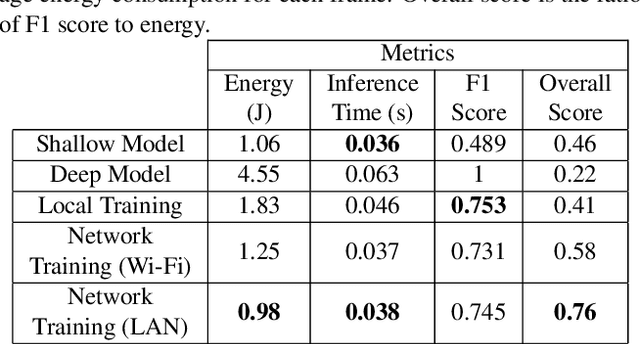
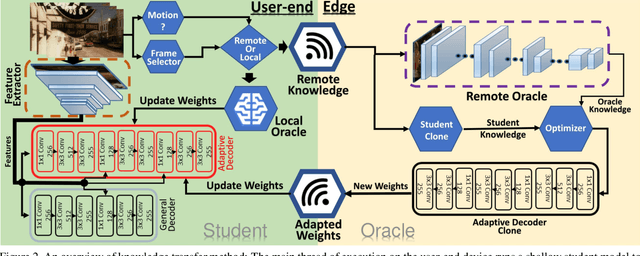

Object detection using deep neural networks (DNNs) involves a huge amount of computation which impedes its implementation on resource/energy-limited user-end devices. The reason for the success of DNNs is due to having knowledge over all different domains of observed environments. However, we need a limited knowledge of the observed environment at inference time which can be learned using a shallow neural network (SHNN). In this paper, a system-level design is proposed to improve the energy consumption of object detection on the user-end device. An SHNN is deployed on the user-end device to detect objects in the observing environment. Also, a knowledge transfer mechanism is implemented to update the SHNN model using the DNN knowledge when there is a change in the object domain. DNN knowledge can be obtained from a powerful edge device connected to the user-end device through LAN or Wi-Fi. Experiments demonstrate that the energy consumption of the user-end device and the inference time can be improved by 78% and 40% compared with running the deep model on the user-end device.
Model-Free State Estimation Using Low-Rank Canonical Polyadic Decomposition
Apr 13, 2020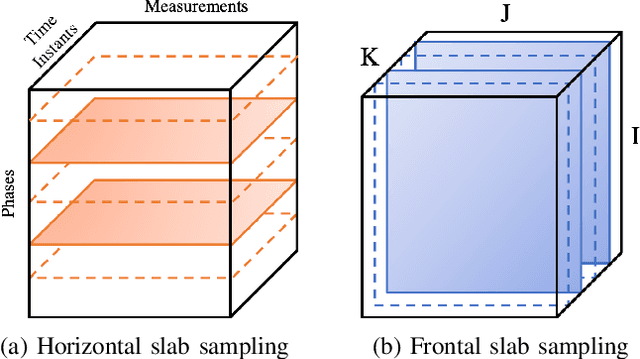
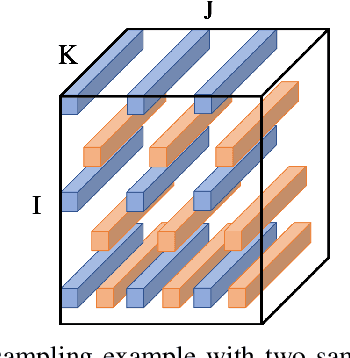
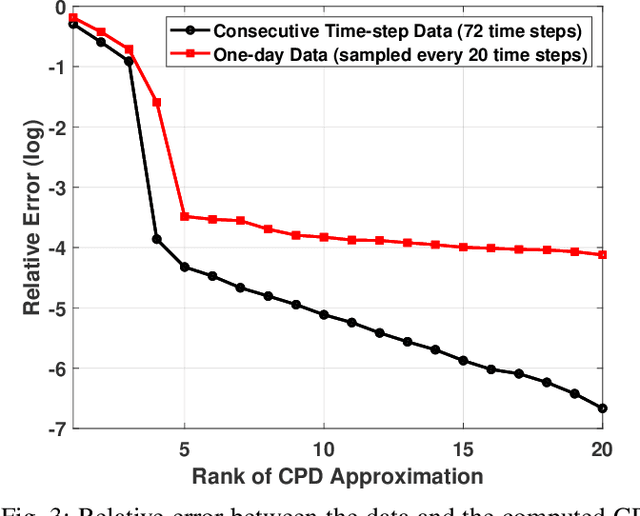
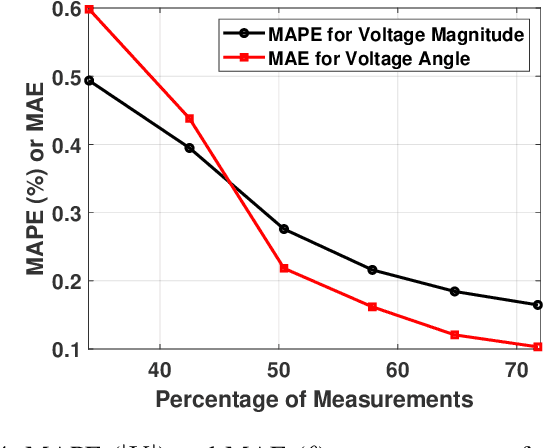
As electric grids experience high penetration levels of renewable generation, fundamental changes are required to address real-time situational awareness. This paper uses unique traits of tensors to devise a model-free situational awareness and energy forecasting framework for distribution networks. This work formulates the state of the network at multiple time instants as a three-way tensor; hence, recovering full state information of the network is tantamount to estimating all the values of the tensor. Given measurements received from $\mu$phasor measurement units and/or smart meters, the recovery of unobserved quantities is carried out using the low-rank canonical polyadic decomposition of the state tensor---that is, the state estimation task is posed as a tensor imputation problem utilizing observed patterns in measured quantities. Two structured sampling schemes are considered: slab sampling and fiber sampling. For both schemes, we present sufficient conditions on the number of sampled slabs and fibers that guarantee identifiability of the factors of the state tensor. Numerical results demonstrate the ability of the proposed framework to achieve high estimation accuracy in multiple sampling scenarios.