 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Off-Policy Estimation of Long-Term Average Outcomes with Applications to Mobile Health
Dec 30, 2019
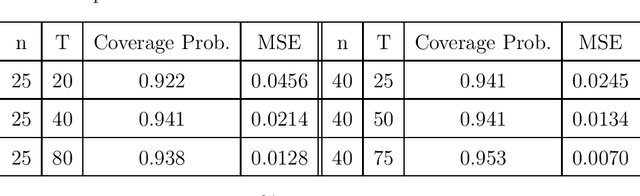
With the recent advancements in wearables and sensing technology, health scientists are increasingly developing mobile health (mHealth) interventions. In mHealth interventions, mobile devices are used to deliver treatment to individuals as they go about their daily lives, generally designed to impact a near time, proximal outcome such as stress or physical activity. The mHealth intervention policies, often called Just-In-time Adaptive Interventions, are decision rules that map a user's context to a particular treatment at each of many time points. The vast majority of current mHealth interventions deploy expert-derived policies. In this paper, we provide an approach for conducting inference about the performance of one or more such policies. In particular, we estimate the performance of a mHealth policy using historical data that are collected under a possibly different policy. Our measure of performance is the average of proximal outcomes (rewards) over a long time period should the particular mHealth policy be followed. We provide a semi-parametric efficient estimator as well as the confidence intervals. This work is motivated by HeartSteps, a mobile health physical activity intervention.
Linear-time Online Action Detection From 3D Skeletal Data Using Bags of Gesturelets
Dec 28, 2015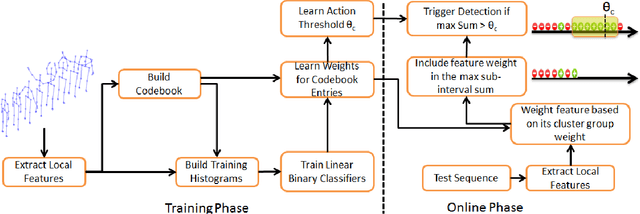
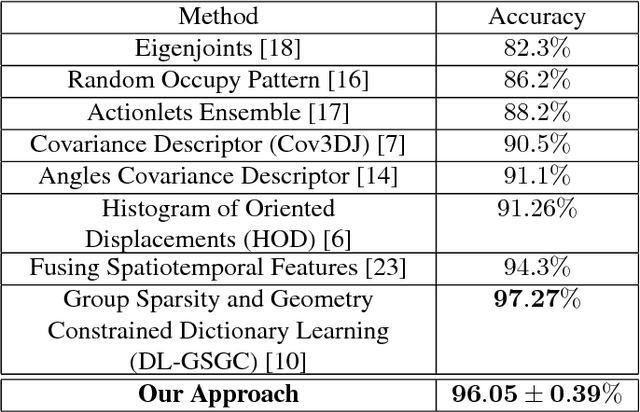
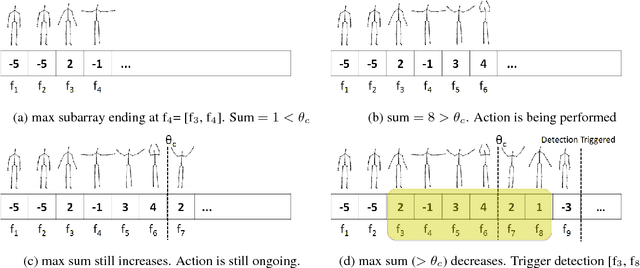

Sliding window is one direct way to extend a successful recognition system to handle the more challenging detection problem. While action recognition decides only whether or not an action is present in a pre-segmented video sequence, action detection identifies the time interval where the action occurred in an unsegmented video stream. Sliding window approaches for action detection can however be slow as they maximize a classifier score over all possible sub-intervals. Even though new schemes utilize dynamic programming to speed up the search for the optimal sub-interval, they require offline processing on the whole video sequence. In this paper, we propose a novel approach for online action detection based on 3D skeleton sequences extracted from depth data. It identifies the sub-interval with the maximum classifier score in linear time. Furthermore, it is invariant to temporal scale variations and is suitable for real-time applications with low latency.
Paying Per-label Attention for Multi-label Extraction from Radiology Reports
Aug 07, 2020Training medical image analysis models requires large amounts of expertly annotated data which is time-consuming and expensive to obtain. Images are often accompanied by free-text radiology reports which are a rich source of information. In this paper, we tackle the automated extraction of structured labels from head CT reports for imaging of suspected stroke patients, using deep learning. Firstly, we propose a set of 31 labels which correspond to radiographic findings (e.g. hyperdensity) and clinical impressions (e.g. haemorrhage) related to neurological abnormalities. Secondly, inspired by previous work, we extend existing state-of-the-art neural network models with a label-dependent attention mechanism. Using this mechanism and simple synthetic data augmentation, we are able to robustly extract many labels with a single model, classified according to the radiologist's reporting (positive, uncertain, negative). This approach can be used in further research to effectively extract many labels from medical text.
High-dimensional mixed-frequency IV regression
Mar 30, 2020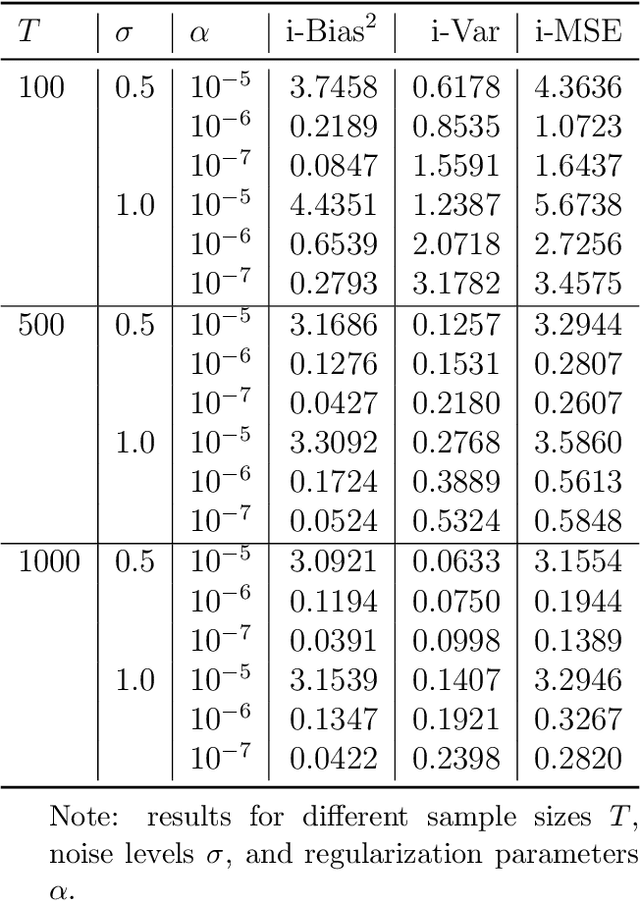
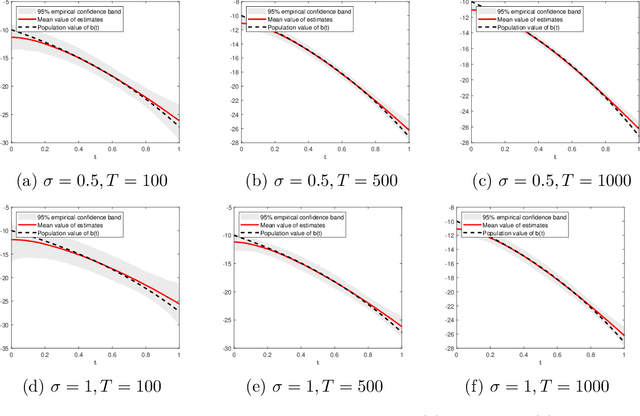
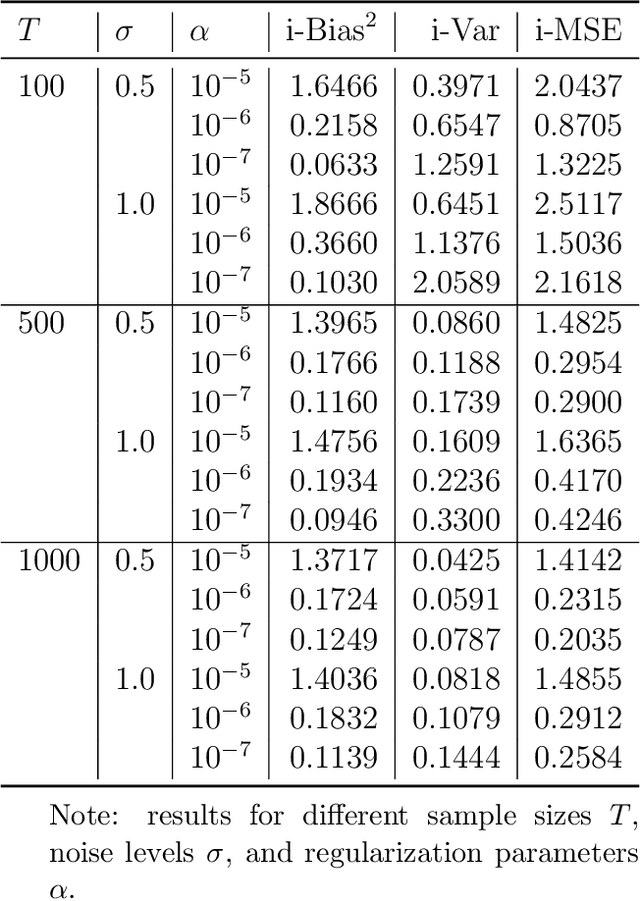
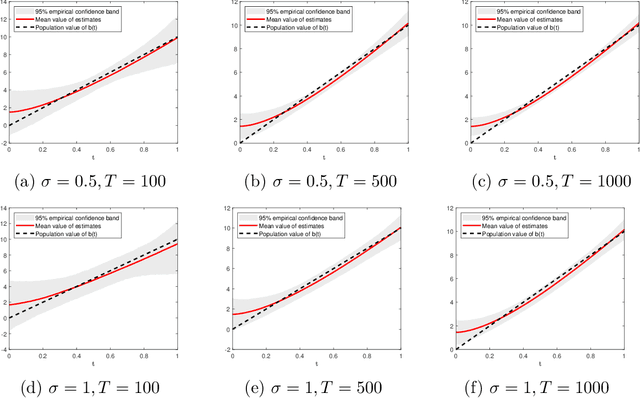
This paper introduces a high-dimensional linear IV regression for the data sampled at mixed frequencies. We show that the high-dimensional slope parameter of a high-frequency covariate can be identified and accurately estimated leveraging on a low-frequency instrumental variable. The distinguishing feature of the model is that it allows handing high-dimensional datasets without imposing the approximate sparsity restrictions. We propose a Tikhonov-regularized estimator and derive the convergence rate of its mean-integrated squared error for time series data. The estimator has a closed-form expression that is easy to compute and demonstrates excellent performance in our Monte Carlo experiments. We estimate the real-time price elasticity of supply on the Australian electricity spot market. Our estimates suggest that the supply is relatively inelastic and that its elasticity is heterogeneous throughout the day.
Deep Low-Shot Learning for Biological Image Classification and Visualization from Limited Training Samples
Oct 20, 2020
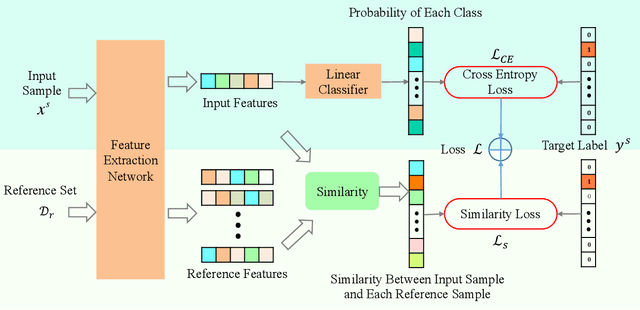
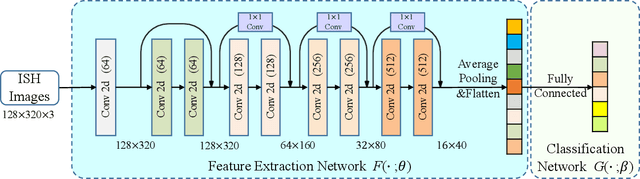
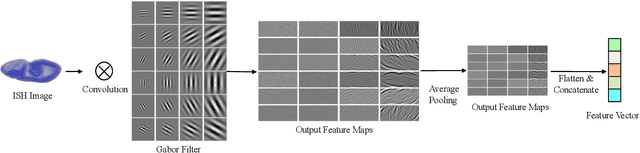
Predictive modeling is useful but very challenging in biological image analysis due to the high cost of obtaining and labeling training data. For example, in the study of gene interaction and regulation in Drosophila embryogenesis, the analysis is most biologically meaningful when in situ hybridization (ISH) gene expression pattern images from the same developmental stage are compared. However, labeling training data with precise stages is very time-consuming even for evelopmental biologists. Thus, a critical challenge is how to build accurate computational models for precise developmental stage classification from limited training samples. In addition, identification and visualization of developmental landmarks are required to enable biologists to interpret prediction results and calibrate models. To address these challenges, we propose a deep two-step low-shot learning framework to accurately classify ISH images using limited training images. Specifically, to enable accurate model training on limited training samples, we formulate the task as a deep low-shot learning problem and develop a novel two-step learning approach, including data-level learning and feature-level learning. We use a deep residual network as our base model and achieve improved performance in the precise stage prediction task of ISH images. Furthermore, the deep model can be interpreted by computing saliency maps, which consist of pixel-wise contributions of an image to its prediction result. In our task, saliency maps are used to assist the identification and visualization of developmental landmarks. Our experimental results show that the proposed model can not only make accurate predictions, but also yield biologically meaningful interpretations. We anticipate our methods to be easily generalizable to other biological image classification tasks with small training datasets.
The Right Tool for the Job: Matching Model and Instance Complexities
May 09, 2020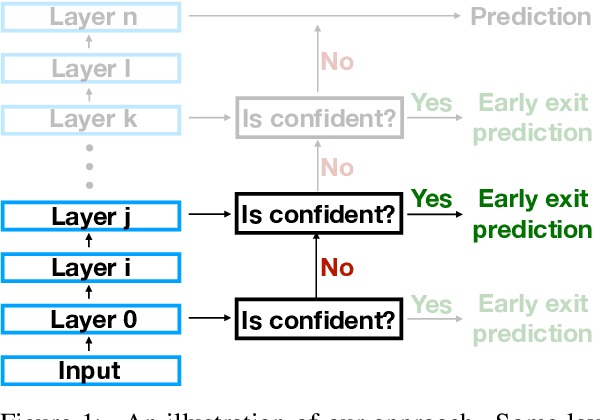
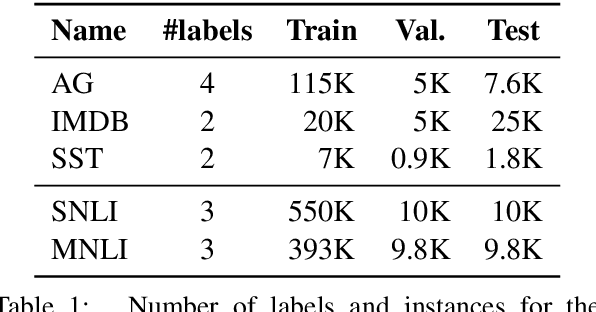
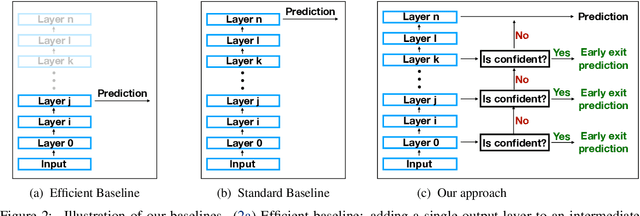
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and environmental costs. To better respect a given inference budget, we propose a modification to contextual representation fine-tuning which, during inference, allows for an early (and fast) "exit" from neural network calculations for simple instances, and late (and accurate) exit for hard instances. To achieve this, we add classifiers to different layers of BERT and use their calibrated confidence scores to make early exit decisions. We test our proposed modification on five different datasets in two tasks: three text classification datasets and two natural language inference benchmarks. Our method presents a favorable speed/accuracy tradeoff in almost all cases, producing models which are up to five times faster than the state of the art, while preserving their accuracy. Our method also requires almost no additional training resources (in either time or parameters) compared to the baseline BERT model. Finally, our method alleviates the need for costly retraining of multiple models at different levels of efficiency; we allow users to control the inference speed/accuracy tradeoff using a single trained model, by setting a single variable at inference time. We publicly release our code.
The Effect of Spectrogram Reconstruction on Automatic Music Transcription: An Alternative Approach to Improve Transcription Accuracy
Oct 20, 2020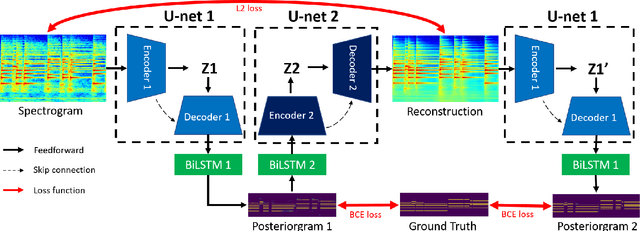

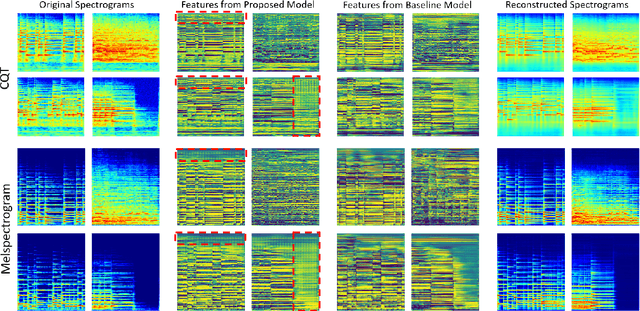

Most of the state-of-the-art automatic music transcription (AMT) models break down the main transcription task into sub-tasks such as onset prediction and offset prediction and train them with onset and offset labels. These predictions are then concatenated together and used as the input to train another model with the pitch labels to obtain the final transcription. We attempt to use only the pitch labels (together with spectrogram reconstruction loss) and explore how far this model can go without introducing supervised sub-tasks. In this paper, we do not aim at achieving state-of-the-art transcription accuracy, instead, we explore the effect that spectrogram reconstruction has on our AMT model. Our proposed model consists of two U-nets: the first U-net transcribes the spectrogram into a posteriorgram, and a second U-net transforms the posteriorgram back into a spectrogram. A reconstruction loss is applied between the original spectrogram and the reconstructed spectrogram to constrain the second U-net to focus only on reconstruction. We train our model on three different datasets: MAPS, MAESTRO, and MusicNet. Our experiments show that adding the reconstruction loss can generally improve the note-level transcription accuracy when compared to the same model without the reconstruction part. Moreover, it can also boost the frame-level precision to be higher than the state-of-the-art models. The feature maps learned by our U-net contain gridlike structures (not present in the baseline model) which implies that with the presence of the reconstruction loss, the model is probably trying to count along both the time and frequency axis, resulting in a higher note-level transcription accuracy.
Gravitational Wave Detection and Information Extraction via Neural Networks
Mar 22, 2020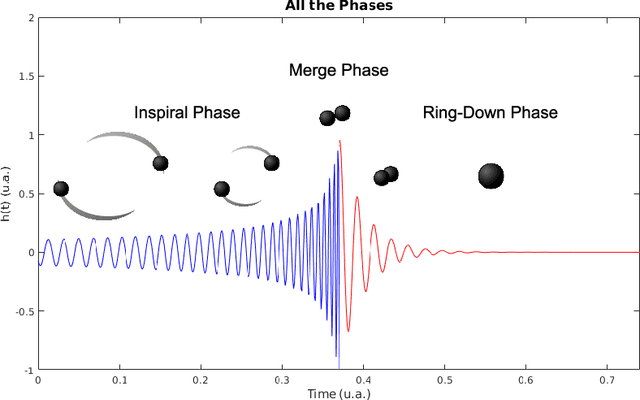
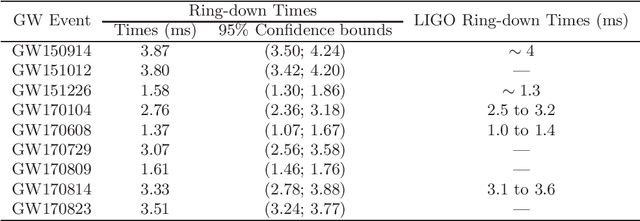
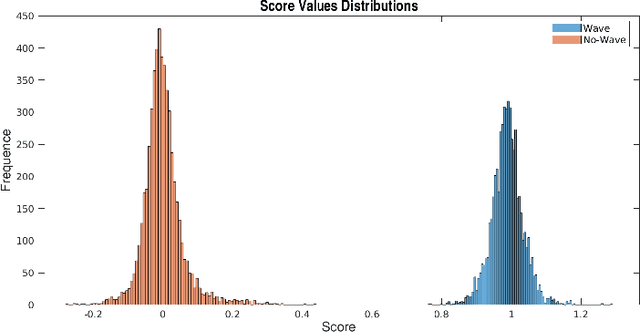
Laser Interferometer Gravitational-Wave Observatory (LIGO) was the first laboratory to measure the gravitational waves. It was needed an exceptional experimental design to measure distance changes much less than a radius of a proton. In the same way, the data analyses to confirm and extract information is a tremendously hard task. Here, it is shown a computational procedure base on artificial neural networks to detect a gravitation wave event and extract the knowledge of its ring-down time from the LIGO data. With this proposal, it is possible to make a probabilistic thermometer for gravitational wave detection and obtain physical information about the astronomical body system that created the phenomenon. Here, the ring-down time is determined with a direct data measure, without the need to use numerical relativity techniques and high computational power.
Bandwidth-Agile Image Transmission with Deep Joint Source-Channel Coding
Sep 26, 2020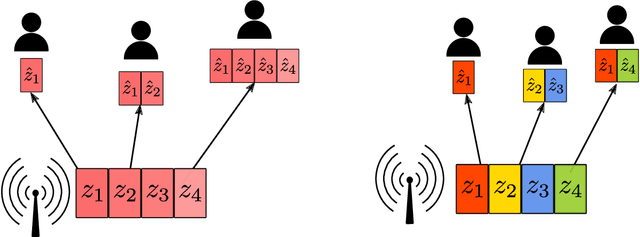
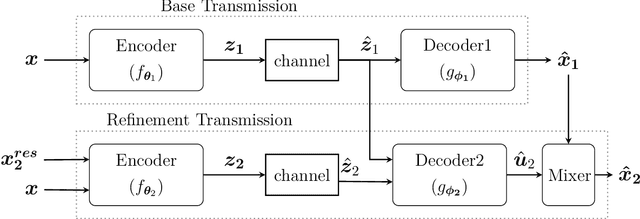
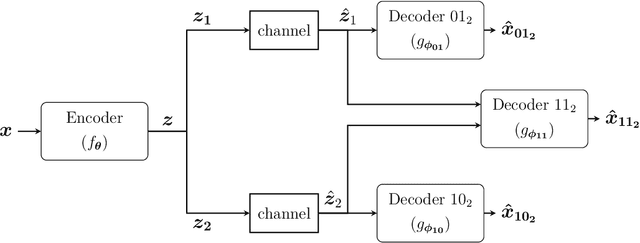
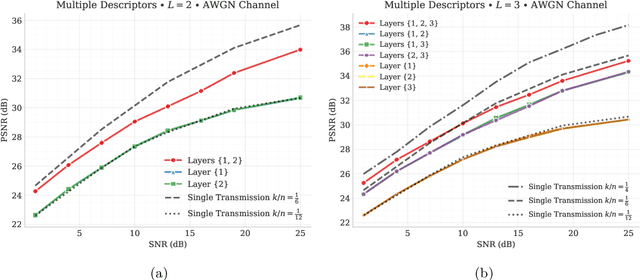
We introduce deep learning based communication methods for adaptive-bandwidth transmission of images over wireless channels. We consider the scenario in which images are transmitted progressively in discrete layers over time or frequency, and such layers can be aggregated by receivers in order to increase the quality of their reconstructions. We investigate two scenarios, one in which the layers are sent sequentially, and incrementally contribute to the refinement of a reconstruction, and another in which the layers are independent and can be retrieved in any order. Those scenarios correspond to the well known problems of successive refinement and multiple descriptions, respectively, in the context of joint source-channel coding (JSCC). We propose DeepJSCC-$l$, an innovative solution that uses convolutional autoencoders, and present three different architectures with different complexity trade-offs. To the best of our knowledge, this is the first practical multiple-description JSCC scheme developed and tested for practical information sources and channels. Numerical results show that DeepJSCC-$l$ can learn different strategies to divide the sources into a layered representation with negligible losses to the end-to-end performance when compared to a single transmission. Moreover, compared to state-of-the-art digital communication schemes, DeepJSCC-$l$ performs well in the challenging low signal-to-noise ratio (SNR) and small bandwidth regimes, and provides graceful degradation with channel SNR.
Domain-invariant Similarity Activation Map Metric Learning for Retrieval-based Long-term Visual Localization
Sep 16, 2020
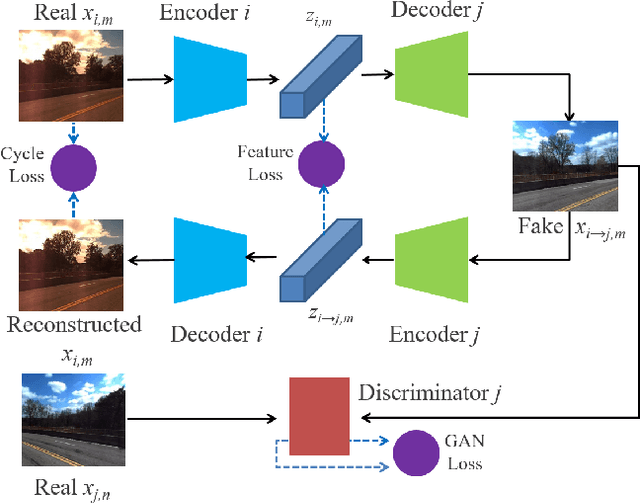
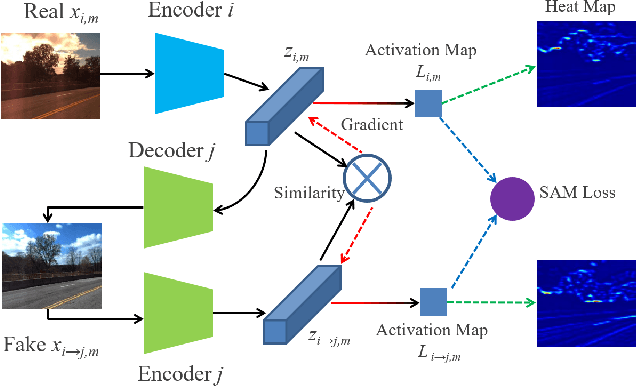
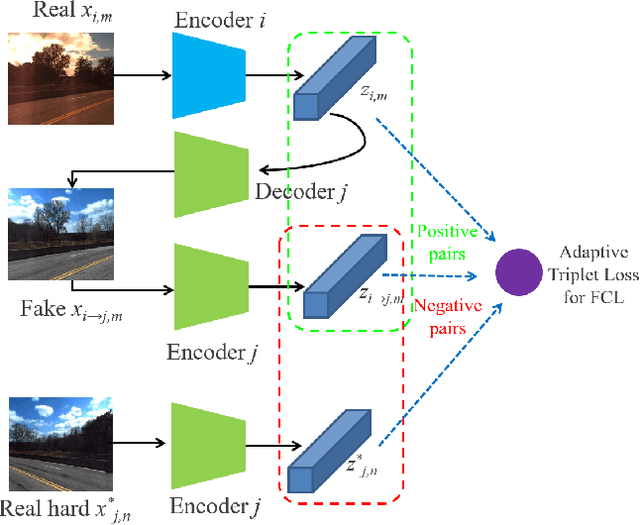
Visual localization is a crucial component in the application of mobile robot and autonomous driving. Image retrieval is an efficient and effective technique in image-based localization methods. Due to the drastic variability of environmental conditions, e.g.Su illumination, seasonal and weather changes, retrieval-based visual localization is severely affected and becomes a challenging problem. In this work, a general architecture is first formulated probabilistically to extract domain-invariant feature through multi-domain image translation. And then a novel gradient-weighted similarity activation mapping loss (Grad-SAM) is incorporated for finer localization with high accuracy. We also propose a new adaptive triplet loss to boost the metric learning of the embedding in a self-supervised manner. The final coarse-to-fine image retrieval pipeline is implemented as the sequential combination of models without and with Grad-SAM loss. Extensive experiments have been conducted to validate the effectiveness of the proposed approach on the CMU-Seasons dataset. The strong generalization ability of our approach is verified on RobotCar dataset using models pre-trained on urban part of CMU-Seasons dataset. Our performance is on par with or even outperforms the state-of-the-art image-based localization baselines in medium or high precision, especially under the challenging environments with illumination variance, vegetation and night-time images.