 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-Rank Reorganization via Proportional Hazards Non-negative Matrix Factorization Unveils Survival Associated Gene Clusters
Sep 17, 2020
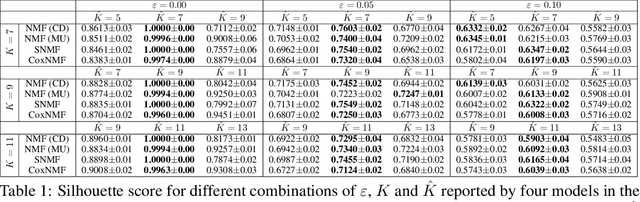
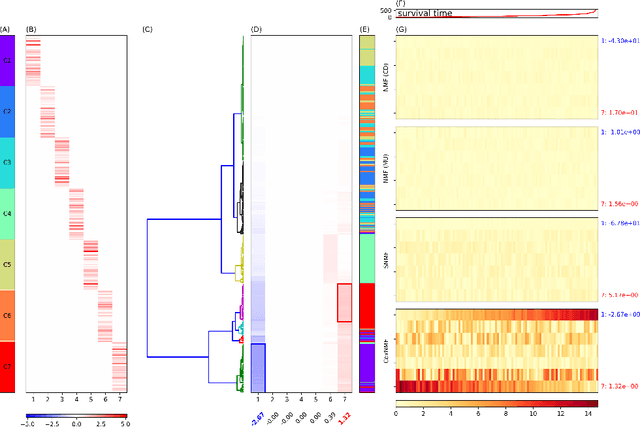
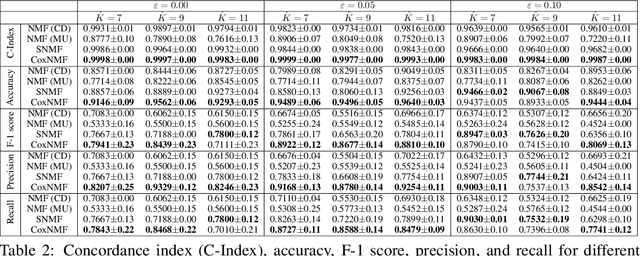
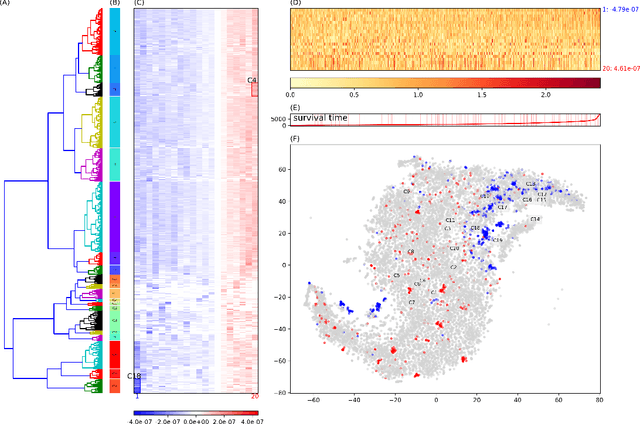
One of the central goals in precision health is the understanding and interpretation of high-dimensional biological data to identify genes and markers associated with disease initiation, development, and outcomes. Though significant effort has been committed to harness gene expression data for multiple analyses while accounting for time-to-event modeling by including survival times, many traditional analyses have focused separately on non-negative matrix factorization (NMF) of the gene expression data matrix and survival regression with Cox proportional hazards model. In this work, Cox proportional hazards regression is integrated with NMF by imposing survival constraints. This is accomplished by jointly optimizing the Frobenius norm and partial log likelihood for events such as death or relapse. Simulation results on synthetic data demonstrated the superiority of the proposed method, when compared to other algorithms, in finding survival associated gene clusters. In addition, using human cancer gene expression data, the proposed technique can unravel critical clusters of cancer genes. The discovered gene clusters reflect rich biological implications and can help identify survival-related biomarkers. Towards the goal of precision health and cancer treatments, the proposed algorithm can help understand and interpret high-dimensional heterogeneous genomics data with accurate identification of survival-associated gene clusters.
Training with reduced precision of a support vector machine model for text classification
Jul 17, 2020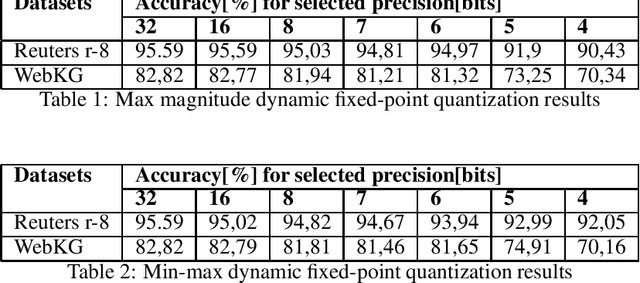
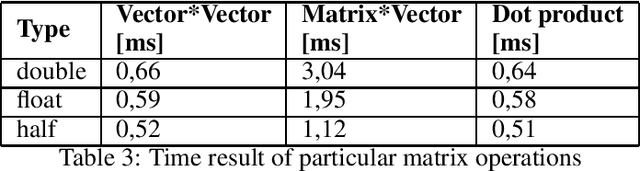
This paper presents the impact of using quantization on the efficiency of multi-class text classification in the training process of a support vector machine (SVM). This work is focused on comparing the efficiency of SVM model trained using reduced precision with its original form. The main advantage of using quantization is decrease in computation time and in memory footprint on the dedicated hardware platform which supports low precision computation like GPU (16-bit) or FPGA (any bit-width). The paper presents the impact of a precision reduction of the SVM training process on text classification accuracy. The implementation of the CPU was performed using the OpenMP library. Additionally, the results of the implementation of the GPU using double, single and half precision are presented.
Nearly Bounded Regret of Re-solving Heuristics in Price-based Revenue Management
Sep 07, 2020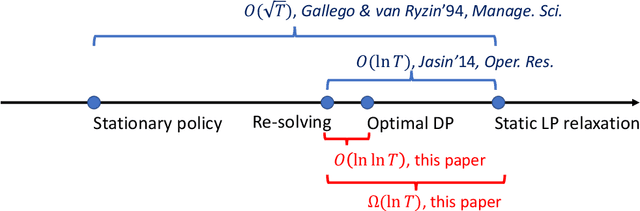

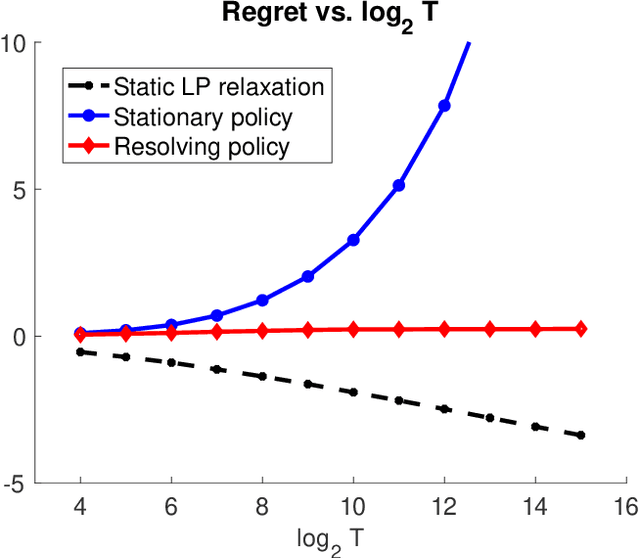
Price-based revenue management is a class of important questions in operations management. In its simplest form, a retailer sells a single product over $T$ consecutive time periods and is subject to constraints on the initial inventory levels. While the optimal pricing policy over $T$ periods could be obtained via dynamic programming, such an approach is sometimes undesirable because of its enormous computational costs. Approximately optimal policies, such as the re-solving heuristic, is often applied as a computationally tractable alternative. In this paper, we prove the following results: 1. We prove that a popular and commonly used re-solving heuristic attains an $O(\ln\ln T)$ regret compared to the value of the optimal DP pricing policy. This improves the $O(\ln T)$ regret upper bound established in the prior work of (Jasin 2014). 2. We prove that there is an $\Omega(\ln T)$ gap between the value of the optimal DP pricing policy and that of a static LP relaxation. This complements our upper bound results in showing that the static LP relaxation is not an adequate information-relaxed benchmark when analyzing price-based revenue management algorithms.
Multi-stream RNN for Merchant Transaction Prediction
Jul 25, 2020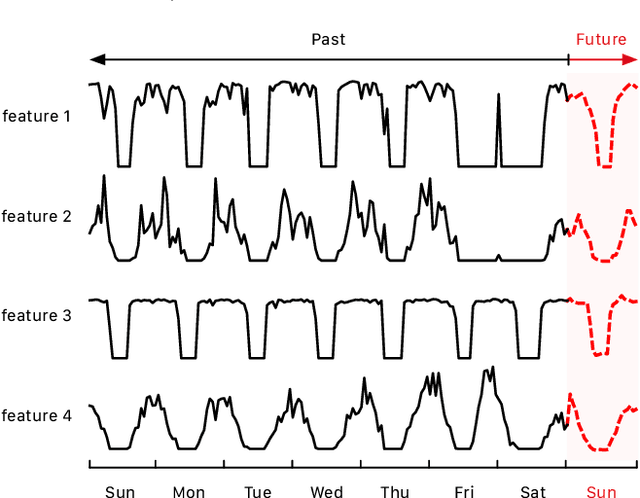
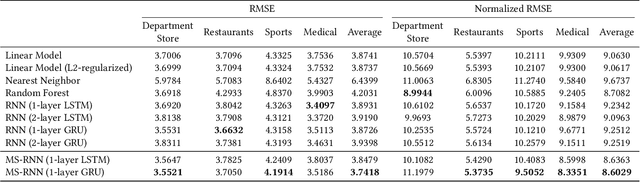
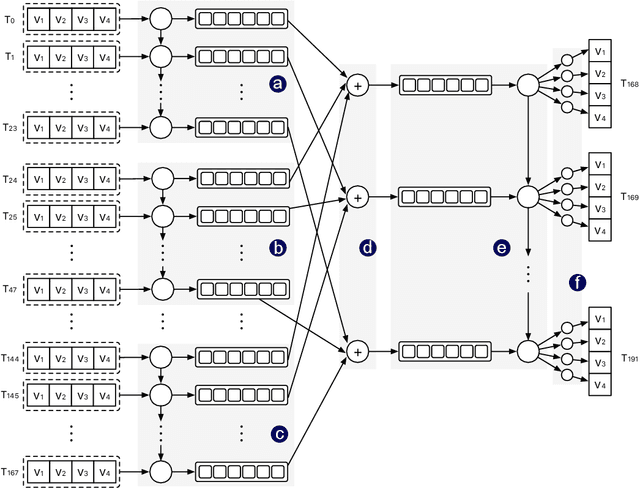
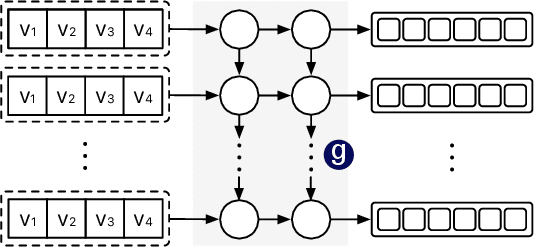
Recently, digital payment systems have significantly changed people's lifestyles. New challenges have surfaced in monitoring and guaranteeing the integrity of payment processing systems. One important task is to predict the future transaction statistics of each merchant. These predictions can thus be used to steer other tasks, ranging from fraud detection to recommendation. This problem is challenging as we need to predict not only multivariate time series but also multi-steps into the future. In this work, we propose a multi-stream RNN model for multi-step merchant transaction predictions tailored to these requirements. The proposed multi-stream RNN summarizes transaction data in different granularity and makes predictions for multiple steps in the future. Our extensive experimental results have demonstrated that the proposed model is capable of outperforming existing state-of-the-art methods.
Synchronization in 5G: a Bayesian Approach
Feb 28, 2020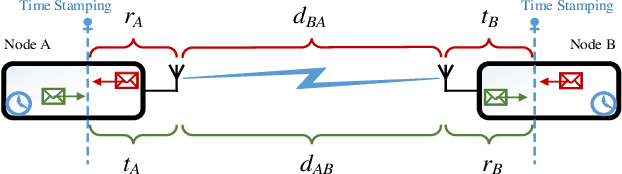
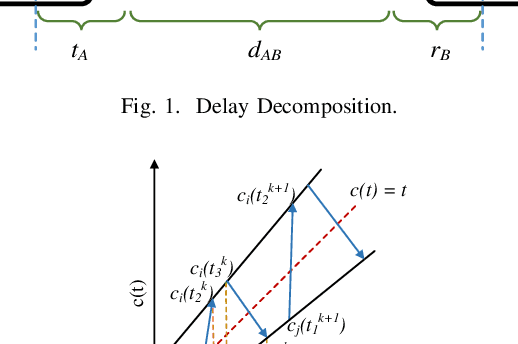
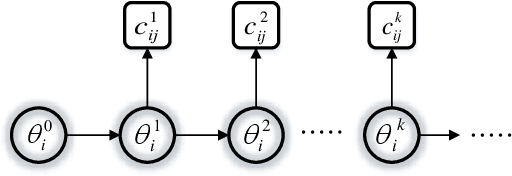
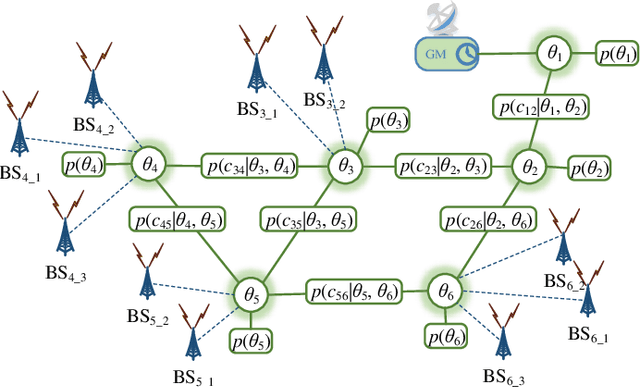
In this work, we propose a hybrid approach to synchronize large scale networks. In particular, we draw on Kalman Filtering (KF) along with time-stamps generated by the Precision Time Protocol (PTP) for pairwise node synchronization. Furthermore, we investigate the merit of Factor Graphs (FGs) along with Belief Propagation (BP) algorithm in achieving high precision end-to-end network synchronization. Finally, we present the idea of dividing the large-scale network into local synchronization domains, for each of which a suitable sync algorithm is utilized. The simulation results indicate that, despite the simplifications in the hybrid approach, the error in the offset estimation remains below 5 ns.
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC
Feb 27, 2020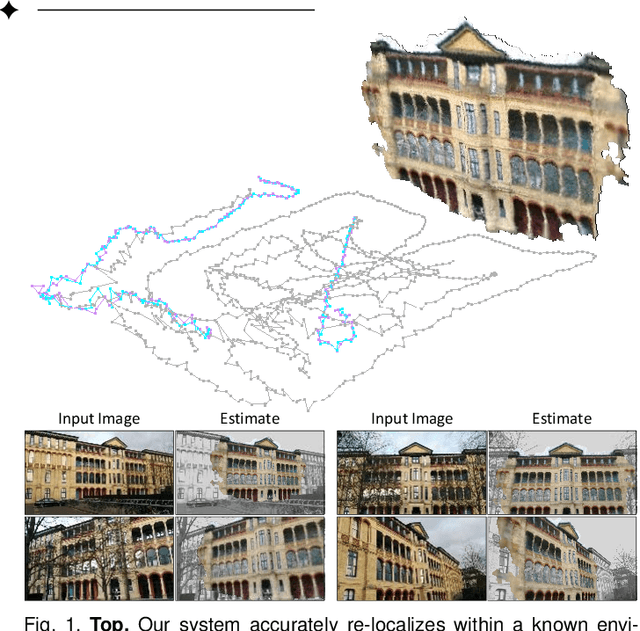

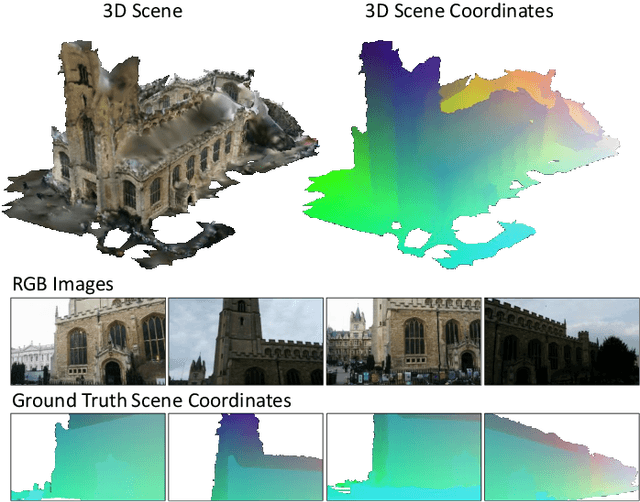
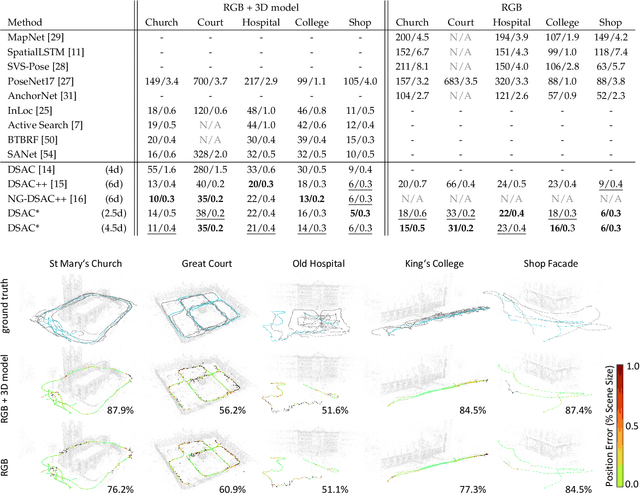
We describe a learning-based system that estimates the camera position and orientation from a single input image relative to a known environment. The system is flexible w.r.t. the amount of information available at test and at training time, catering to different applications. Input images can be RGB-D or RGB, and a 3D model of the environment can be utilized for training but is not necessary. In the minimal case, our system requires only RGB images and ground truth poses at training time, and it requires only a single RGB image at test time. The framework consists of a deep neural network and fully differentiable pose optimization. The neural network predicts so called scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment. The pose optimization implements robust fitting of pose parameters using differentiable RANSAC (DSAC) to facilitate end-to-end training. The system, an extension of DSAC++ and referred to as DSAC*, achieves state-of-the-art accuracy an various public datasets for RGB-based re-localization, and competitive accuracy for RGB-D based re-localization.
Efficient hyperparameter optimization by way of PAC-Bayes bound minimization
Aug 14, 2020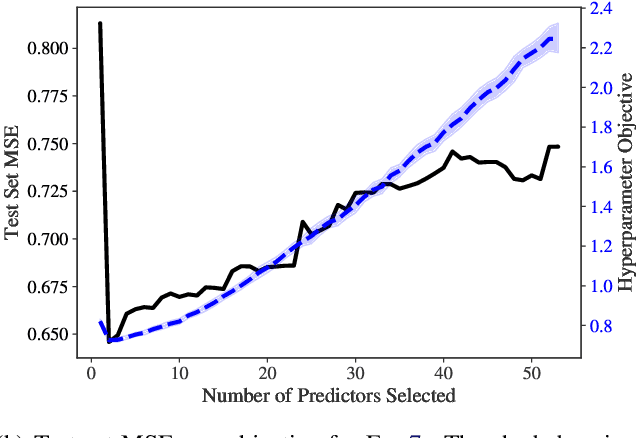
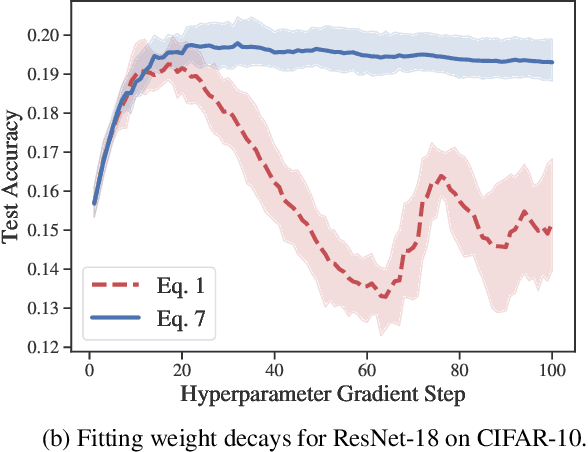
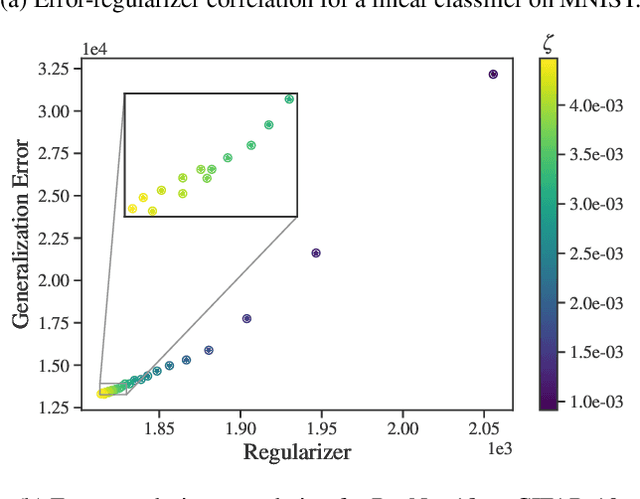
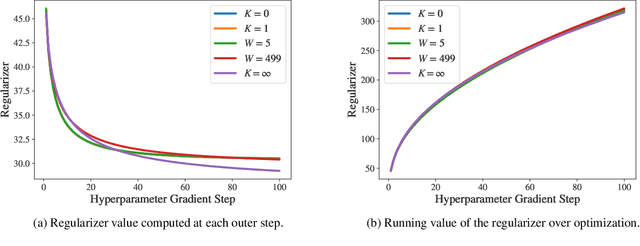
Identifying optimal values for a high-dimensional set of hyperparameters is a problem that has received growing attention given its importance to large-scale machine learning applications such as neural architecture search. Recently developed optimization methods can be used to select thousands or even millions of hyperparameters. Such methods often yield overfit models, however, leading to poor performance on unseen data. We argue that this overfitting results from using the standard hyperparameter optimization objective function. Here we present an alternative objective that is equivalent to a Probably Approximately Correct-Bayes (PAC-Bayes) bound on the expected out-of-sample error. We then devise an efficient gradient-based algorithm to minimize this objective; the proposed method has asymptotic space and time complexity equal to or better than other gradient-based hyperparameter optimization methods. We show that this new method significantly reduces out-of-sample error when applied to hyperparameter optimization problems known to be prone to overfitting.
ISTA-NAS: Efficient and Consistent Neural Architecture Search by Sparse Coding
Oct 13, 2020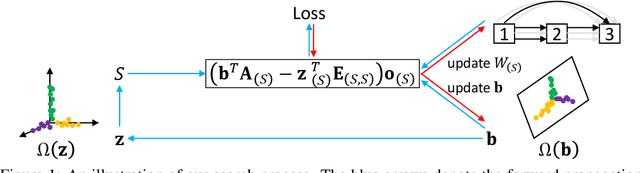
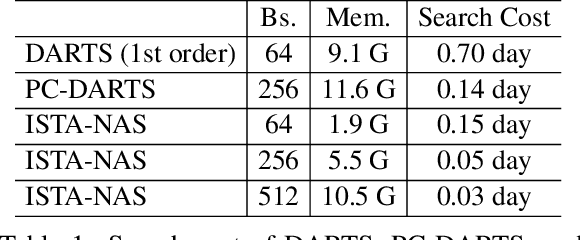

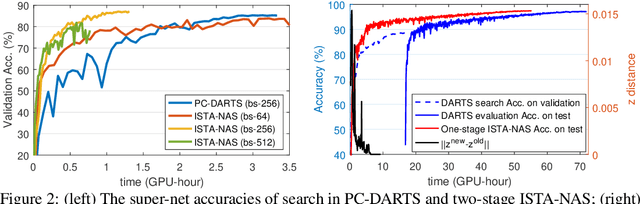
Neural architecture search (NAS) aims to produce the optimal sparse solution from a high-dimensional space spanned by all candidate connections. Current gradient-based NAS methods commonly ignore the constraint of sparsity in the search phase, but project the optimized solution onto a sparse one by post-processing. As a result, the dense super-net for search is inefficient to train and has a gap with the projected architecture for evaluation. In this paper, we formulate neural architecture search as a sparse coding problem. We perform the differentiable search on a compressed lower-dimensional space that has the same validation loss as the original sparse solution space, and recover an architecture by solving the sparse coding problem. The differentiable search and architecture recovery are optimized in an alternate manner. By doing so, our network for search at each update satisfies the sparsity constraint and is efficient to train. In order to also eliminate the depth and width gap between the network in search and the target-net in evaluation, we further propose a method to search and evaluate in one stage under the target-net settings. When training finishes, architecture variables are absorbed into network weights. Thus we get the searched architecture and optimized parameters in a single run. In experiments, our two-stage method on CIFAR-10 requires only 0.05 GPU-day for search. Our one-stage method produces state-of-the-art performances on both CIFAR-10 and ImageNet at the cost of only evaluation time.
Live Anomaly Detection based on Machine Learning Techniques SAD-F: Spark Based Anomaly Detection Framework
Jan 21, 2020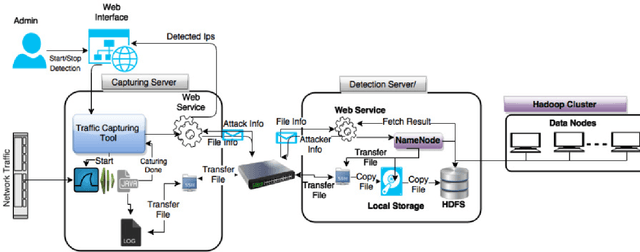
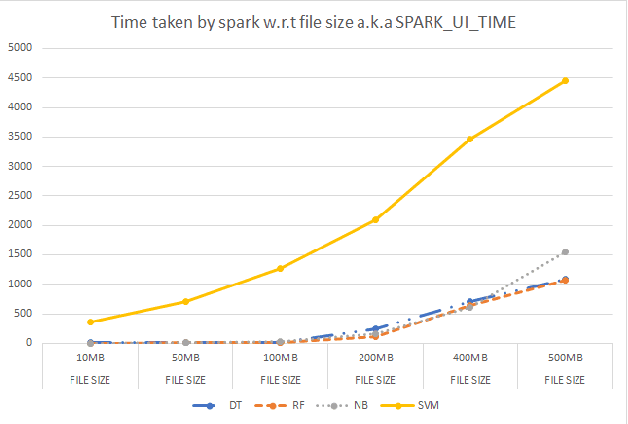
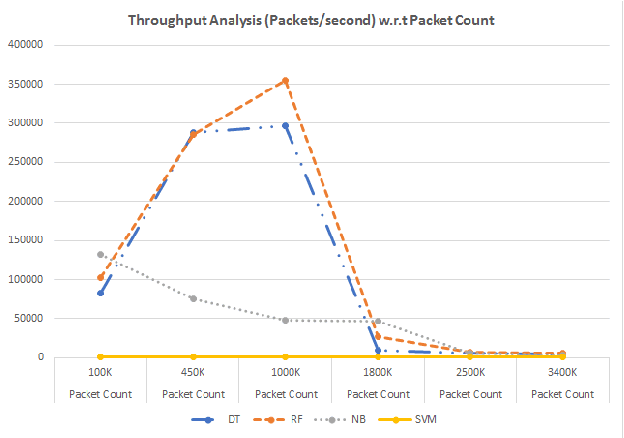
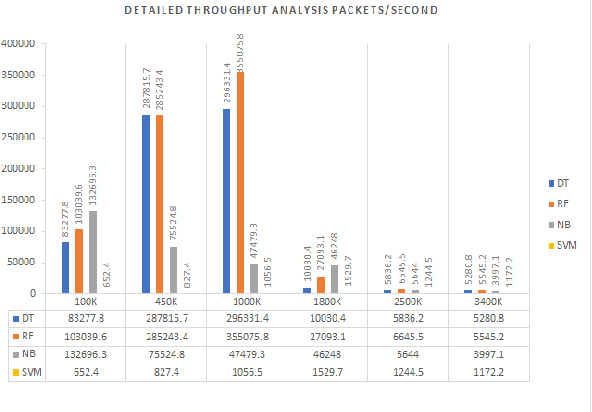
Anomaly detection is a crucial step for preventing malicious activities in the network and keeping resources available all the time for legitimate users. It is noticed from various studies that classical anomaly detectors work well with small and sampled data, but the chances of failures increase with real-time (non-sampled data) traffic data. In this paper, we will be exploring security analytic techniques for DDoS anomaly detection using different machine learning techniques. In this paper, we are proposing a novel approach which deals with real traffic as input to the system. Further, we study and compare the performance factor of our proposed framework on three different testbeds including normal commodity hardware, low-end system, and high-end system. Hardware details of testbeds are discussed in the respective section. Further in this paper, we investigate the performance of the classifiers in (near) real-time detection of anomalies attacks. This study also focused on the feature selection process that is as important for the anomaly detection process as it is for general modeling problems. Several techniques have been studied for feature selection and it is observed that proper feature selection can increase performance in terms of model's execution time - which totally depends upon the traffic file or traffic capturing process.
Exploring Efficient Volumetric Medical Image Segmentation Using 2.5D Method: An Empirical Study
Oct 13, 2020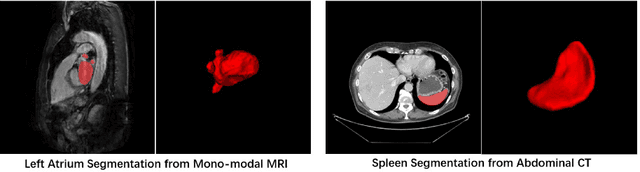
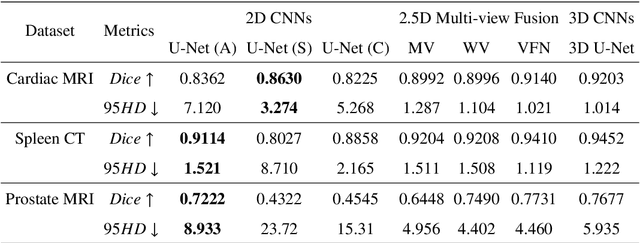
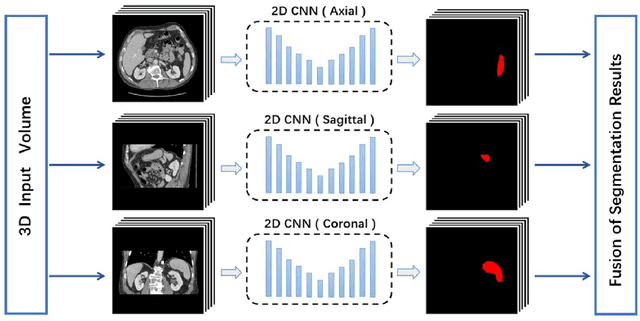
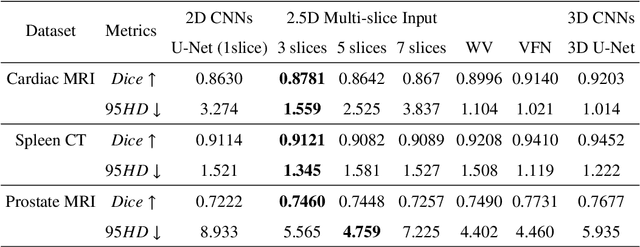
With the unprecedented developments in deep learning, many methods are proposed and have achieved great success for medical image segmentation. However, unlike segmentation of natural images, most medical images such as MRI and CT are volumetric data. In order to make full use of volumetric information, 3D CNNs are widely used. However, 3D CNNs suffer from higher inference time and computation cost, which hinders their further clinical applications. Additionally, with the increased number of parameters, the risk of overfitting is higher, especially for medical images where data and annotations are expensive to acquire. To issue this problem, many 2.5D segmentation methods have been proposed to make use of volumetric spatial information with less computation cost. Despite these works lead to improvements on a variety of segmentation tasks, to the best of our knowledge, there has not previously been a large-scale empirical comparison of these methods. In this paper, we aim to present a review of the latest developments of 2.5D methods for volumetric medical image segmentation. Additionally, to compare the performance and effectiveness of these methods, we provide an empirical study of these methods on three representative segmentation tasks involving different modalities and targets. Our experimental results highlight that 3D CNNs may not always be the best choice. Besides, although all these 2.5D methods can bring performance gains to 2D baseline, not all the methods hold the benefits on different datasets. We hope the results and conclusions of our study will prove useful for the community on exploring and developing efficient volumetric medical image segmentation methods.