 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
When Machine Learning Meets Multiscale Modeling in Chemical Reactions
Jun 01, 2020
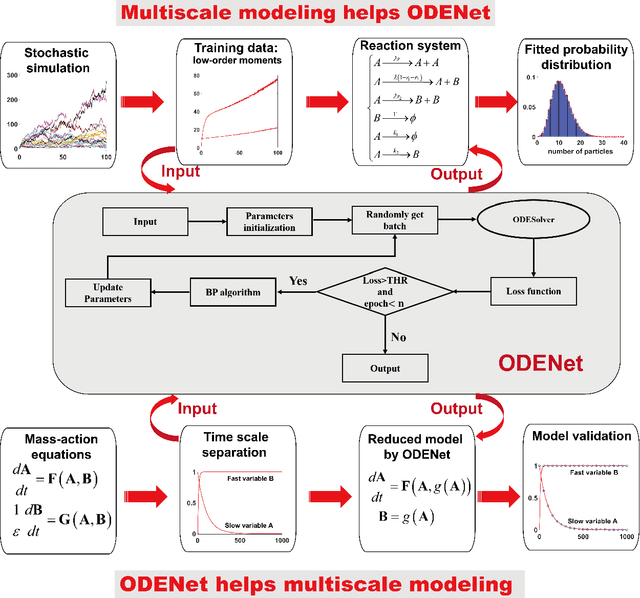
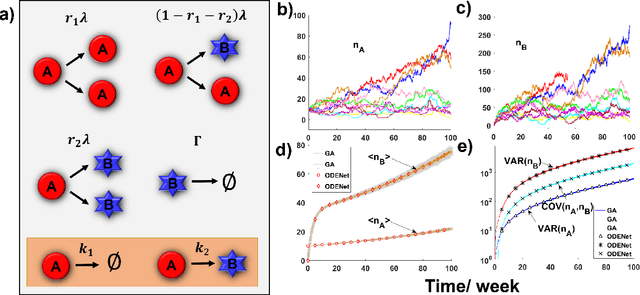
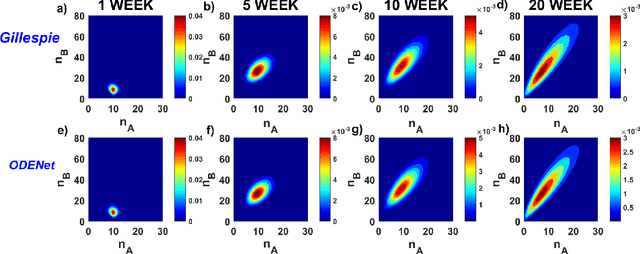
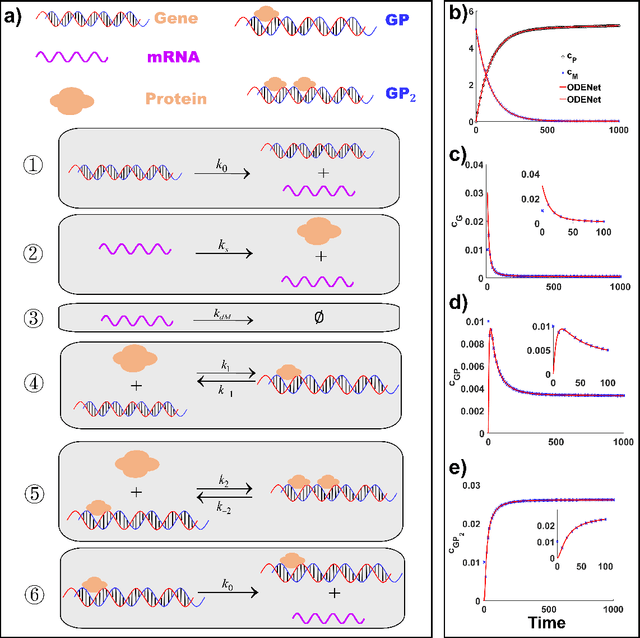
Due to the intrinsic complexity and nonlinearity of chemical reactions, direct applications of traditional machine learning algorithms may face with many difficulties. In this study, through two concrete examples with biological background, we illustrate how the key ideas of multiscale modeling can help to reduce the computational cost of machine learning a lot, as well as how machine learning algorithms perform model reduction automatically in a time-scale separated system. Our study highlights the necessity and effectiveness of an integration of machine learning algorithms and multiscale modeling during the study of chemical reactions.
Weakly Supervised Construction of ASR Systems with Massive Video Data
Aug 04, 2020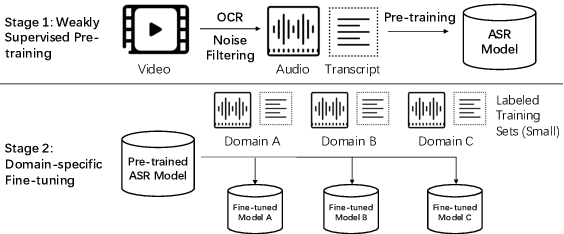
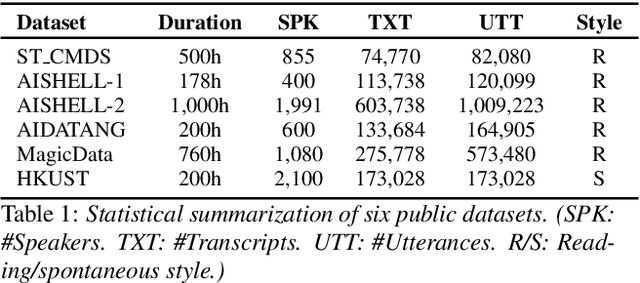
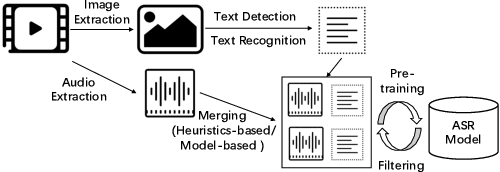
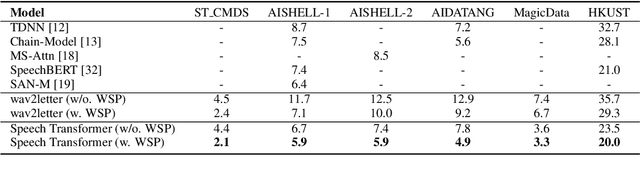
Building Automatic Speech Recognition (ASR) systems from scratch is significantly challenging, mostly due to the time-consuming and financially-expensive process of annotating a large amount of audio data with transcripts. Although several unsupervised pre-training models have been proposed, applying such models directly might still be sub-optimal if more labeled, training data could be obtained without a large cost. In this paper, we present a weakly supervised framework for constructing ASR systems with massive video data. As videos often contain human-speech audios aligned with subtitles, we consider videos as an important knowledge source, and propose an effective approach to extract high-quality audios aligned with transcripts from videos based on Optical Character Recognition (OCR). The underlying ASR model can be fine-tuned to fit any domain-specific target training datasets after weakly supervised pre-training. Extensive experiments show that our framework can easily produce state-of-the-art results on six public datasets for Mandarin speech recognition.
Scene-Adaptive Video Frame Interpolation via Meta-Learning
Apr 02, 2020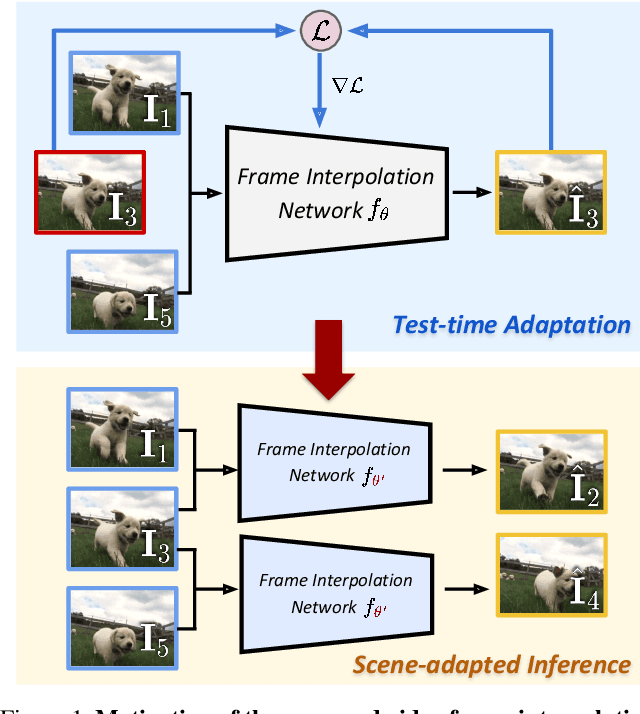

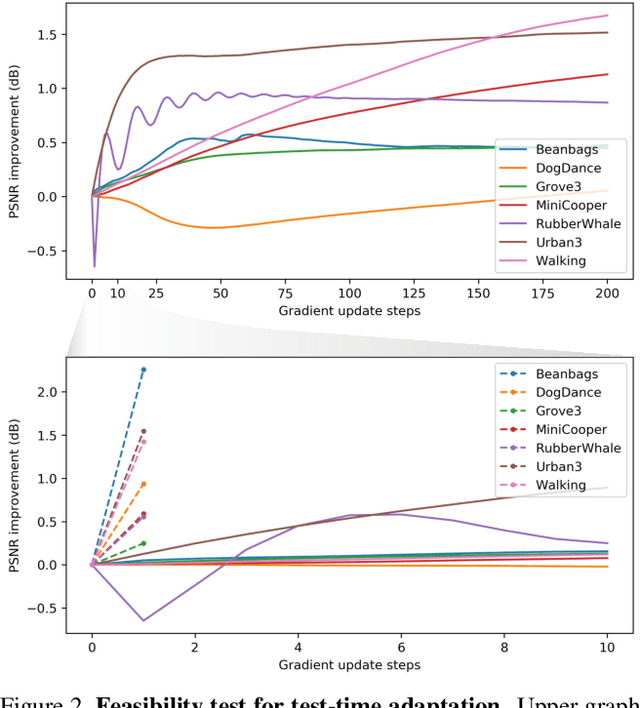

Video frame interpolation is a challenging problem because there are different scenarios for each video depending on the variety of foreground and background motion, frame rate, and occlusion. It is therefore difficult for a single network with fixed parameters to generalize across different videos. Ideally, one could have a different network for each scenario, but this is computationally infeasible for practical applications. In this work, we propose to adapt the model to each video by making use of additional information that is readily available at test time and yet has not been exploited in previous works. We first show the benefits of `test-time adaptation' through simple fine-tuning of a network, then we greatly improve its efficiency by incorporating meta-learning. We obtain significant performance gains with only a single gradient update without any additional parameters. Finally, we show that our meta-learning framework can be easily employed to any video frame interpolation network and can consistently improve its performance on multiple benchmark datasets.
Online nonnegative tensor factorization and CP-dictionary learning for Markovian data
Sep 16, 2020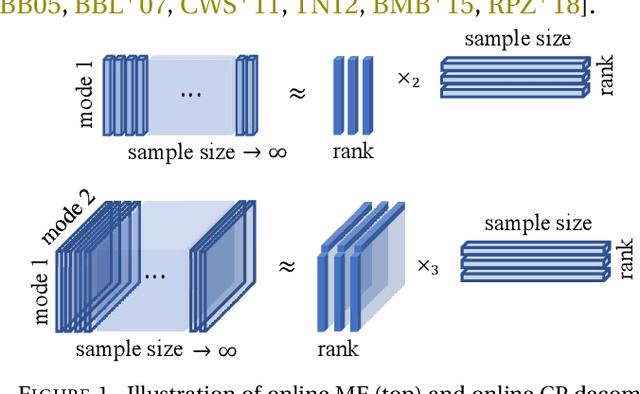
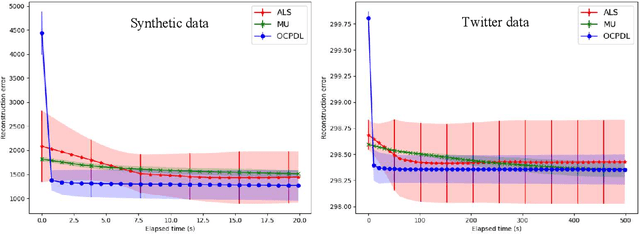

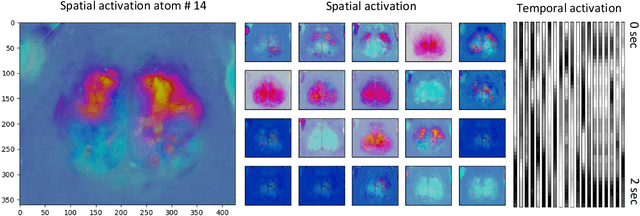
Nonnegative Matrix Factorization (NMF) algorithms are fundamental tools in learning low-dimensional features from vector-valued data, Nonnegative Tensor Factorization (NTF) algorithms serve a similar role for dictionary learning problems for multi-modal data. Also, there is often a critical interest in \textit{online} versions of such factorization algorithms to learn progressively from minibatches, without requiring the full data as in conventional algorithms. However, the current theory of Online NTF algorithms is quite nascent, especially compared to the comprehensive literature on online NMF algorithms. In this work, we introduce a novel online NTF algorithm that learns a CP basis from a given stream of tensor-valued data under general constraints. In particular, using nonnegativity constraints, the learned CP modes also give localized dictionary atoms that respect the tensor structure in multi-model data. On the application side, we demonstrate the utility of our algorithm on a diverse set of examples from image, video, and time series data, illustrating how one may learn qualitatively different CP-dictionaries by not needing to reshape tensor data before the learning process. On the theoretical side, we prove that our algorithm converges to the set of stationary points of the objective function under the hypothesis that the sequence of data tensors have functional Markovian dependence. This assumption covers a wide range of application contexts including data streams generated by independent or MCMC sampling.
LSTM-Assisted Evolutionary Self-Expressive Subspace Clustering
Oct 19, 2019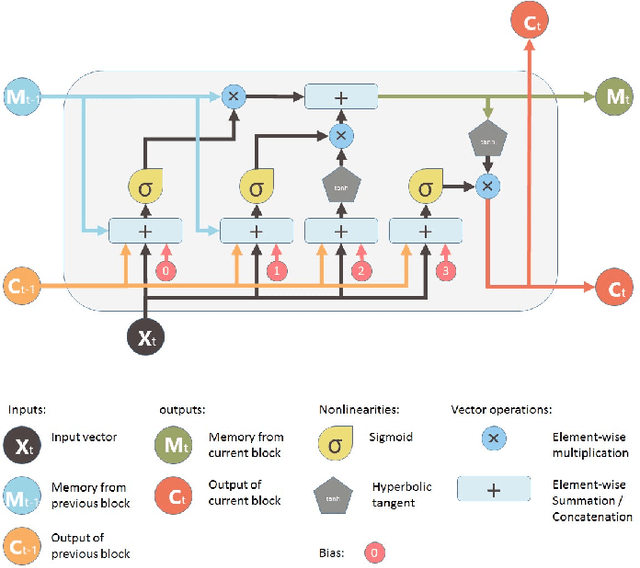

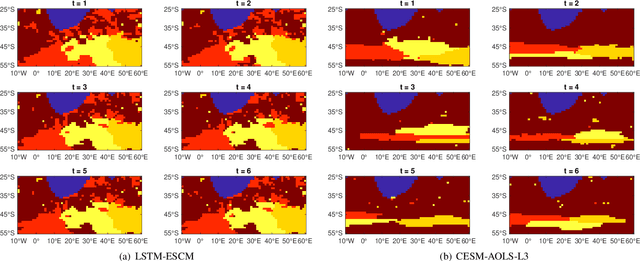
Massive volumes of high-dimensional data that evolves over time is continuously collected by contemporary information processing systems, which brings up the problem of organizing this data into clusters, i.e. achieve the purpose of dimensional deduction, and meanwhile learning its temporal evolution patterns. In this paper, a framework for evolutionary subspace clustering, referred to as LSTM-ESCM, is introduced, which aims at clustering a set of evolving high-dimensional data points that lie in a union of low-dimensional evolving subspaces. In order to obtain the parsimonious data representation at each time step, we propose to exploit the so-called self-expressive trait of the data at each time point. At the same time, LSTM networks are implemented to extract the inherited temporal patterns behind data in an overall time frame. An efficient algorithm has been proposed based on MATLAB. Next, experiments are carried out on real-world datasets to demonstrate the effectiveness of our proposed approach. And the results show that the suggested algorithm dramatically outperforms other known similar approaches in terms of both run time and accuracy.
Deep vs. Deep Bayesian: Reinforcement Learning on a Multi-Robot Competitive Experiment
Jul 21, 2020
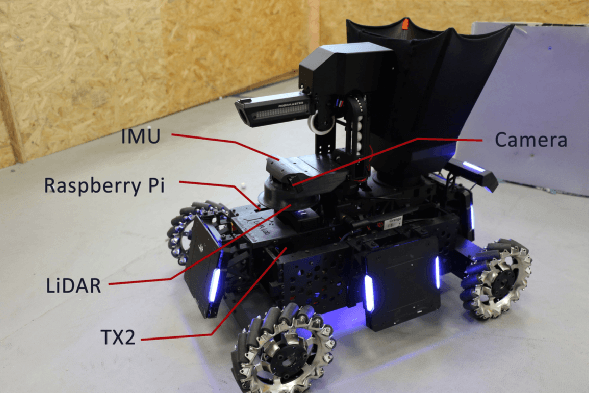
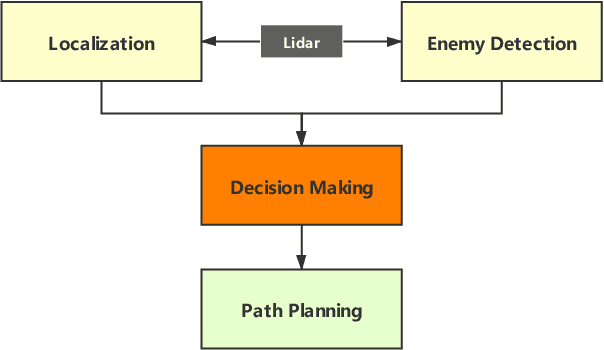
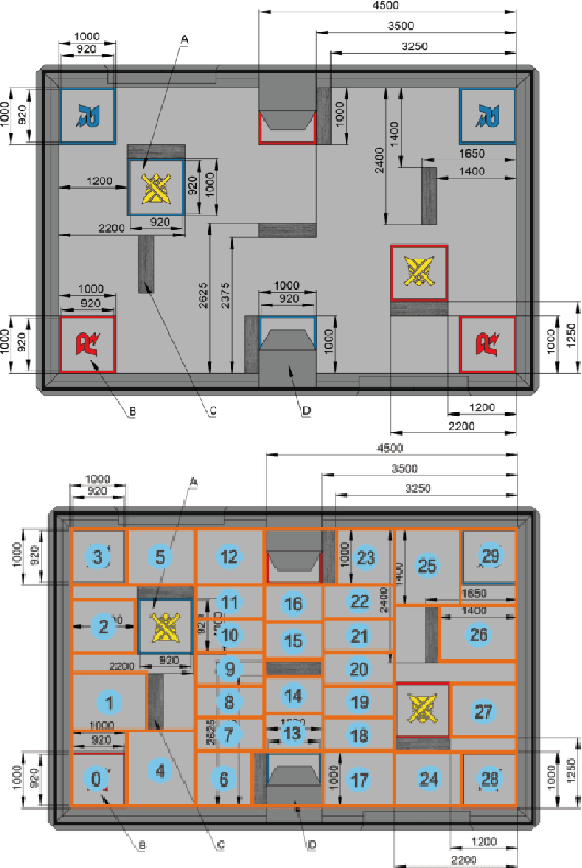
Deep Reinforcement Learning (RL) experiments are commonly performed in simulated environment, due to the tremendous training sample demand from deep neural networks. However, model-based Deep Bayesian RL, such as Deep PILCO, allows a robot to learn good policies within few trials in the real world. Although Deep PILCO has been applied on many single-robot tasks, in here we propose, for the first time, an application of Deep PILCO on a multi-robot confrontation game, and compare the algorithm with a model-free Deep RL algorithm, Deep Q-Learning. Our experiments show that Deep PILCO significantly outperforms Deep Q-Learning in learning efficiency and scalability. We conclude that sample-efficient Deep Bayesian learning algorithms have great prospects on competitive games where the agent aims to win the opponents in the real world, as opposed to simulated applications.
Customer Support Ticket Escalation Prediction using Feature Engineering
Oct 10, 2020Understanding and keeping the customer happy is a central tenet of requirements engineering. Strategies to gather, analyze, and negotiate requirements are complemented by efforts to manage customer input after products have been deployed. For the latter, support tickets are key in allowing customers to submit their issues, bug reports, and feature requests. If insufficient attention is given to support issues, however, their escalation to management becomes time-consuming and expensive, especially for large organizations managing hundreds of customers and thousands of support tickets. Our work provides a step towards simplifying the job of support analysts and managers, particularly in predicting the risk of escalating support tickets. In a field study at our large industrial partner, IBM, we used a design science research methodology to characterize the support process and data available to IBM analysts in managing escalations. We then implemented these features into a machine learning model to predict support ticket escalations. We trained and evaluated our machine learning model on over 2.5 million support tickets and 10,000 escalations, obtaining a recall of 87.36% and an 88.23% reduction in the workload for support analysts looking to identify support tickets at risk of escalation. Finally, in addition to these research evaluation activities, we compared the performance of our support ticket model with that of a model developed with no feature engineering; the support ticket model features outperformed the non-engineered model. The artifacts created in this research are designed to serve as a starting place for organizations interested in predicting support ticket escalations, and for future researchers to build on to advance research in escalation prediction.
* 19 pages, 9 figures, published in Springer Requirements Engineering Journal. arXiv admin note: substantial text overlap with arXiv:1901.01092
Wavelet Denoising and Attention-based RNN-ARIMA Model to Predict Forex Price
Aug 16, 2020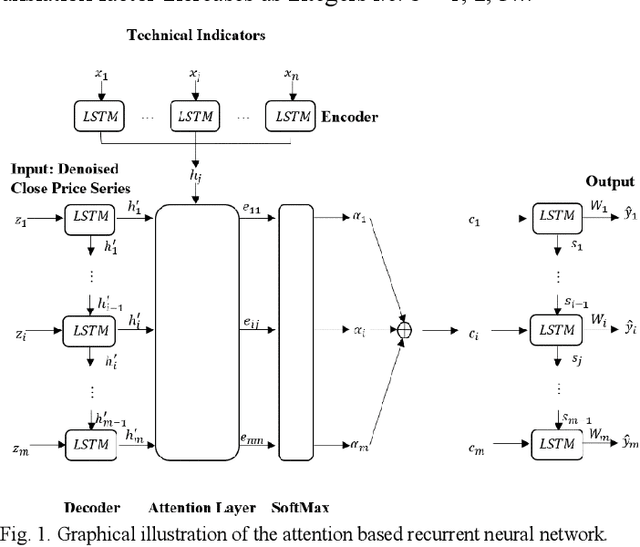
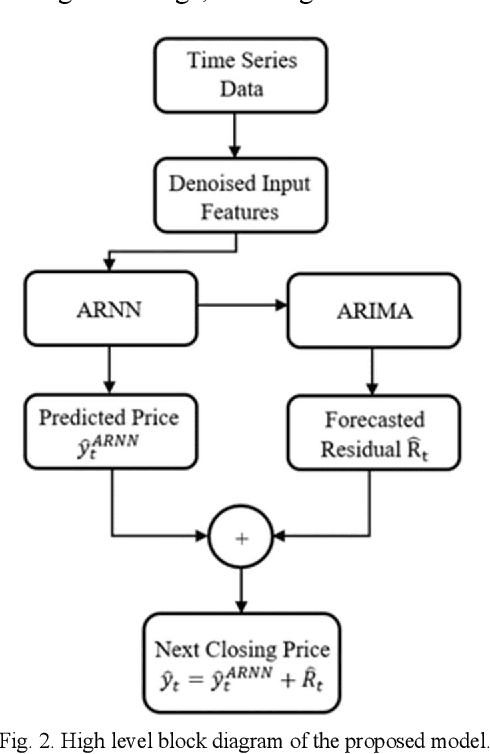
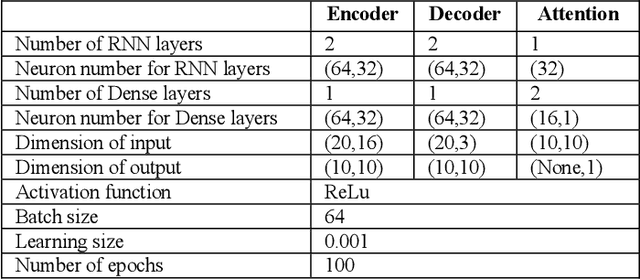
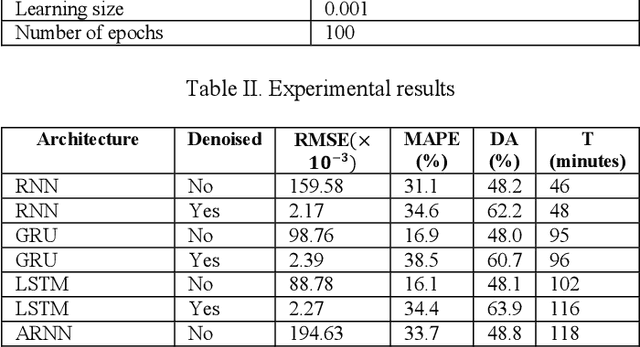
Every change of trend in the forex market presents a great opportunity as well as a risk for investors. Accurate forecasting of forex prices is a crucial element in any effective hedging or speculation strategy. However, the complex nature of the forex market makes the predicting problem challenging, which has prompted extensive research from various academic disciplines. In this paper, a novel approach that integrates the wavelet denoising, Attention-based Recurrent Neural Network (ARNN), and Autoregressive Integrated Moving Average (ARIMA) are proposed. Wavelet transform removes the noise from the time series to stabilize the data structure. ARNN model captures the robust and non-linear relationships in the sequence and ARIMA can well fit the linear correlation of the sequential information. By hybridization of the three models, the methodology is capable of modelling dynamic systems such as the forex market. Our experiments on USD/JPY five-minute data outperforms the baseline methods. Root-Mean-Squared-Error (RMSE) of the hybrid approach was found to be 1.65 with a directional accuracy of ~76%.
A Change-Detection Based Thompson Sampling Framework for Non-Stationary Bandits
Sep 06, 2020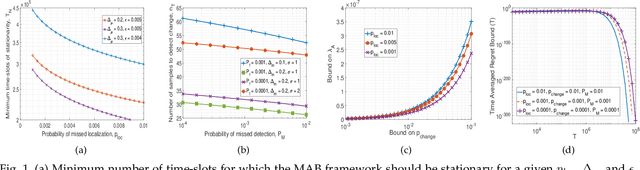
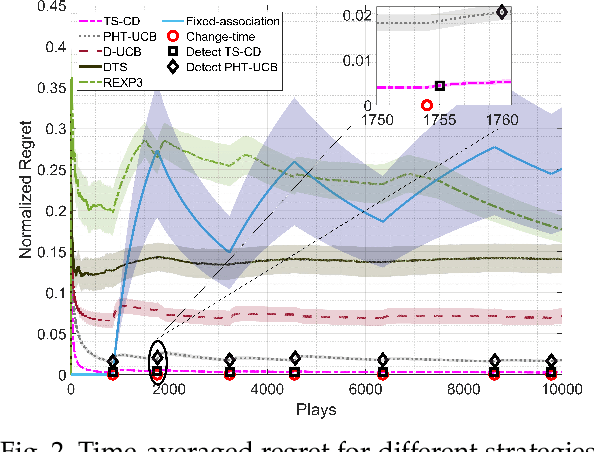
We consider a non-stationary two-armed bandit framework and propose a change-detection based Thompson sampling (TS) algorithm, named TS with change-detection (TS-CD), to keep track of the dynamic environment. The non-stationarity is modeled using a Poisson arrival process, which changes the mean of the rewards on each arrival. The proposed strategy compares the empirical mean of the recent rewards of an arm with the estimate of the mean of the rewards from its history. It detects a change when the empirical mean deviates from the mean estimate by a value larger than a threshold. Then, we characterize the lower bound on the duration of the time-window for which the bandit framework must remain stationary for TS-CD to successfully detect a change when it occurs. Consequently, our results highlight an upper bound on the parameter for the Poisson arrival process, for which the TS-CD achieves asymptotic regret optimality with high probability. Finally, we validate the efficacy of TS-CD by testing it for edge-control of radio access technique (RAT)-selection in a wireless network. Our results show that TS-CD not only outperforms the classical max-power RAT selection strategy but also other actively adaptive and passively adaptive bandit algorithms that are designed for non-stationary environments.
Making Good on LSTMs' Unfulfilled Promise
Dec 01, 2019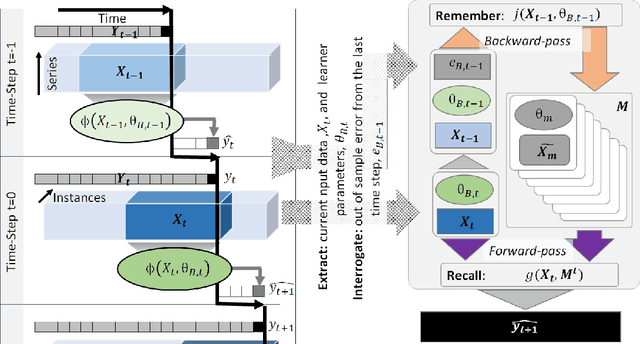
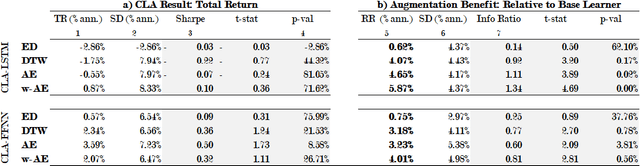
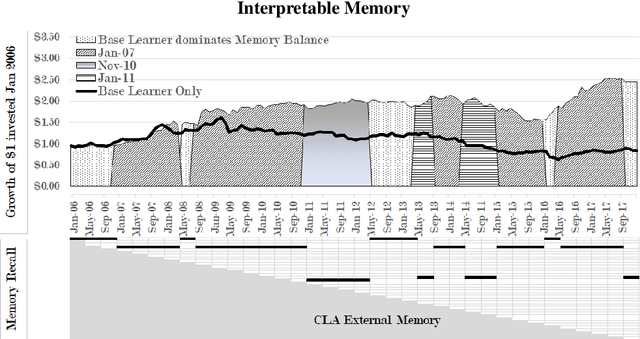
LSTMs promise much to financial time-series analysis, temporal and cross-sectional inference, but we find that they do not deliver in a real-world financial management task. We examine an alternative called Continual Learning (CL), a memory-augmented approach, which can provide transparent explanations, i.e. which memory did what and when. This work has implications for many financial applications including credit, time-varying fairness in decision making and more. We make three important new observations. Firstly, as well as being more explainable, time-series CL approaches outperform LSTMs as well as a simple sliding window learner using feed-forward neural networks (FFNN). Secondly, we show that CL based on a sliding window learner (FFNN) is more effective than CL based on a sequential learner (LSTM). Thirdly, we examine how real-world, time-series noise impacts several similarity approaches used in CL memory addressing. We provide these insights using an approach called Continual Learning Augmentation (CLA) tested on a complex real-world problem, emerging market equities investment decision making. CLA provides a test-bed as it can be based on different types of time-series learners, allowing testing of LSTM and FFNN learners side by side. CLA is also used to test several distance approaches used in a memory recall-gate: Euclidean distance (ED), dynamic time warping (DTW), auto-encoders (AE) and a novel hybrid approach, warp-AE. We find that ED under-performs DTW and AE but warp-AE shows the best overall performance in a real-world financial task.