 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Labeling of Multilingual Breast MRI Reports
Jul 06, 2020
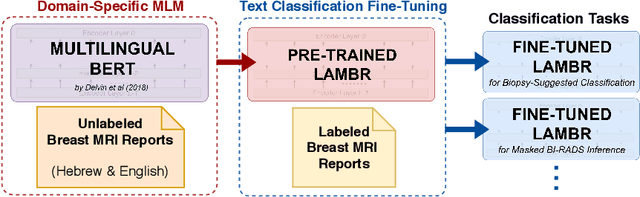
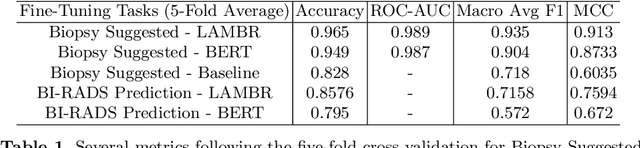
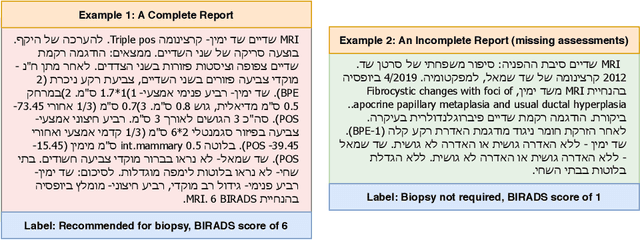
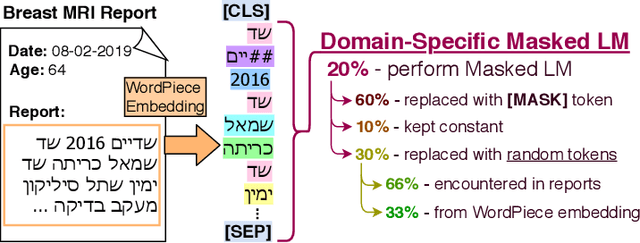
Medical reports are an essential medium in recording a patient's condition throughout a clinical trial. They contain valuable information that can be extracted to generate a large labeled dataset needed for the development of clinical tools. However, the majority of medical reports are stored in an unregularized format, and a trained human annotator (typically a doctor) must manually assess and label each case, resulting in an expensive and time consuming procedure. In this work, we present a framework for developing a multilingual breast MRI report classifier using a custom-built language representation called LAMBR. Our proposed method overcomes practical challenges faced in clinical settings, and we demonstrate improved performance in extracting labels from medical reports when compared with conventional approaches.
Customer Support Ticket Escalation Prediction using Feature Engineering
Oct 10, 2020Understanding and keeping the customer happy is a central tenet of requirements engineering. Strategies to gather, analyze, and negotiate requirements are complemented by efforts to manage customer input after products have been deployed. For the latter, support tickets are key in allowing customers to submit their issues, bug reports, and feature requests. If insufficient attention is given to support issues, however, their escalation to management becomes time-consuming and expensive, especially for large organizations managing hundreds of customers and thousands of support tickets. Our work provides a step towards simplifying the job of support analysts and managers, particularly in predicting the risk of escalating support tickets. In a field study at our large industrial partner, IBM, we used a design science research methodology to characterize the support process and data available to IBM analysts in managing escalations. We then implemented these features into a machine learning model to predict support ticket escalations. We trained and evaluated our machine learning model on over 2.5 million support tickets and 10,000 escalations, obtaining a recall of 87.36% and an 88.23% reduction in the workload for support analysts looking to identify support tickets at risk of escalation. Finally, in addition to these research evaluation activities, we compared the performance of our support ticket model with that of a model developed with no feature engineering; the support ticket model features outperformed the non-engineered model. The artifacts created in this research are designed to serve as a starting place for organizations interested in predicting support ticket escalations, and for future researchers to build on to advance research in escalation prediction.
* 19 pages, 9 figures, published in Springer Requirements Engineering Journal. arXiv admin note: substantial text overlap with arXiv:1901.01092
Online Regulation of Unstable LTI Systems from a Single Trajectory
Jun 09, 2020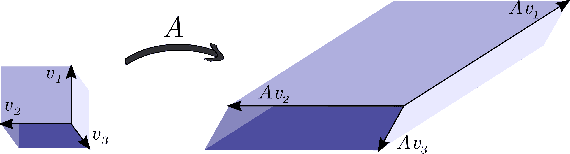
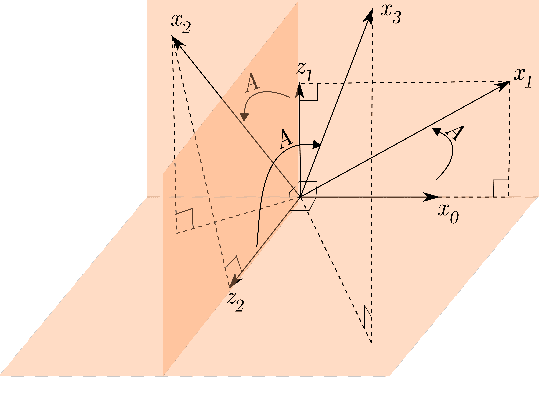
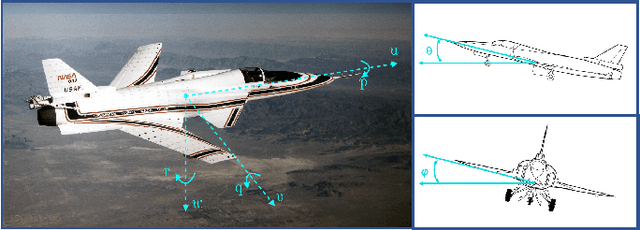
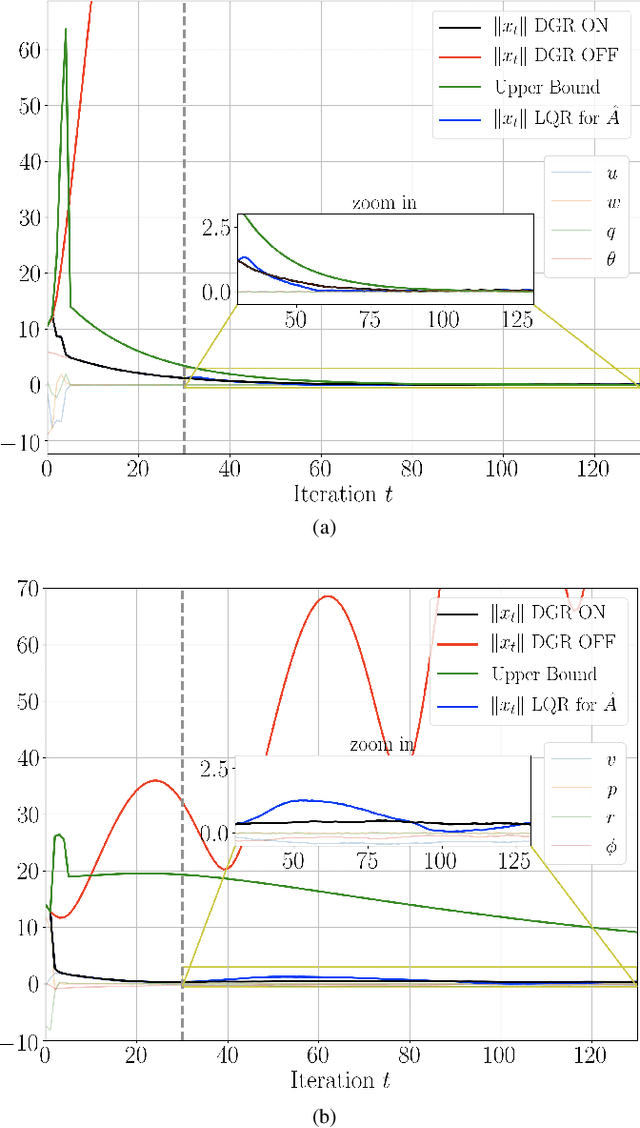
Recently, data-driven methods for control of dynamic systems have received considerable attention in system theory and machine learning as they provide a mechanism for feedback synthesis from the observed time-series data. However learning, say through direct policy updates, often requires assumptions such as knowing a priori that the initial policy (gain) is stabilizing, e.g., when the open-loop system is stable. In this paper, we examine online regulation of (possibly unstable) partially unknown linear systems with no a priori assumptions on the initial controller. First, we introduce and characterize the notion of ''regularizability'' for linear systems that gauges the capacity of a system to be regulated in finite-time in contrast to its asymptotic behavior (commonly characterized by stabilizability/controllability). Next, having access only to the input matrix, we propose the Data-GuidedRegulation (DGR) synthesis that--as its name suggests--regulates the underlying states while also generating informative data that can subsequently be used for data-driven stabilization or system identification (sysID). The analysis is also related in spirit, to thespectrum and the ''instability number'' of the underlying linear system, a novel geometric property studied in this work. We further elucidate our results by considering special structures for system parameters as well as boosting the performance of the algorithm via a rank-one matrix update using the discrete nature of data collection in the problem setup. Finally, we demonstrate the utility of the proposed approach via an example involving direct (online) regulation of the X-29 aircraft.
TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
Apr 16, 2020
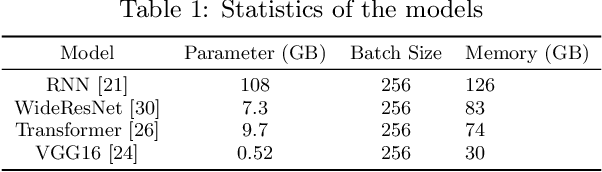
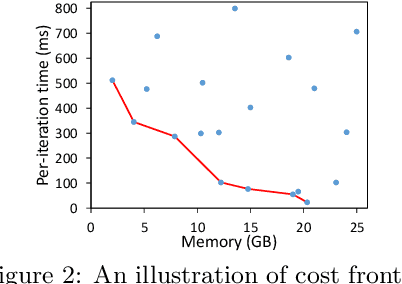

A good parallelization strategy can significantly improve the efficiency or reduce the cost for the distributed training of deep neural networks (DNNs). Recently, several methods have been proposed to find efficient parallelization strategies but they all optimize a single objective (e.g., execution time, memory consumption) and produce only one strategy. We propose FT, an efficient algorithm that searches for an optimal set of parallelization strategies to allow the trade-off among different objectives. FT can adapt to different scenarios by minimizing the memory consumption when the number of devices is limited and fully utilize additional resources to reduce the execution time. For popular DNN models (e.g., vision, language), an in-depth analysis is conducted to understand the trade-offs among different objectives and their influence on the parallelization strategies. We also develop a user-friendly system, called TensorOpt, which allows users to run their distributed DNN training jobs without caring the details of parallelization strategies. Experimental results show that FT runs efficiently and provides accurate estimation of runtime costs, and TensorOpt is more flexible in adapting to resource availability compared with existing frameworks.
Model-Agnostic Interpretable and Data-driven suRRogates suited for highly regulated industries
Jul 14, 2020


Highly regulated industries, like banking and insurance, ask for transparent decision-making algorithms. At the same time, competitive markets push for sophisticated black box models. We therefore present a procedure to develop a Model-Agnostic Interpretable Data-driven suRRogate, suited for structured tabular data. Insights are extracted from a black box via partial dependence effects. These are used to group feature values, resulting in a segmentation of the feature space with automatic feature selection. A transparent generalized linear model (GLM) is fit to the features in categorical format and their relevant interactions. We demonstrate our R package maidrr with a case study on general insurance claim frequency modeling for six public datasets. Our maidrr GLM closely approximates a gradient boosting machine (GBM) and outperforms both a linear and tree surrogate as benchmarks.
Maximum Entropy Gain Exploration for Long Horizon Multi-goal Reinforcement Learning
Jul 06, 2020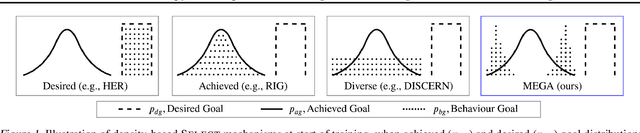
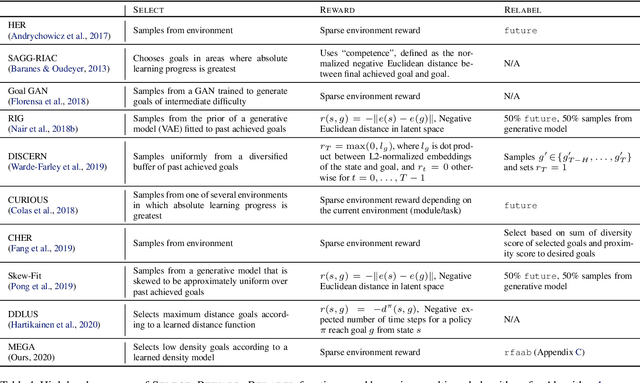
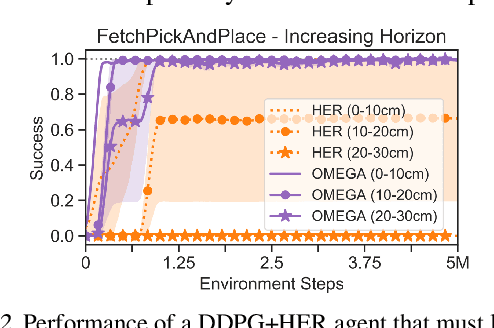

What goals should a multi-goal reinforcement learning agent pursue during training in long-horizon tasks? When the desired (test time) goal distribution is too distant to offer a useful learning signal, we argue that the agent should not pursue unobtainable goals. Instead, it should set its own intrinsic goals that maximize the entropy of the historical achieved goal distribution. We propose to optimize this objective by having the agent pursue past achieved goals in sparsely explored areas of the goal space, which focuses exploration on the frontier of the achievable goal set. We show that our strategy achieves an order of magnitude better sample efficiency than the prior state of the art on long-horizon multi-goal tasks including maze navigation and block stacking.
Weakly Supervised Construction of ASR Systems with Massive Video Data
Aug 04, 2020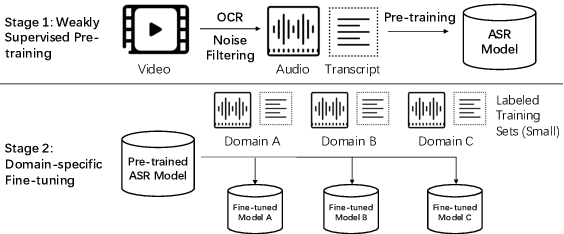
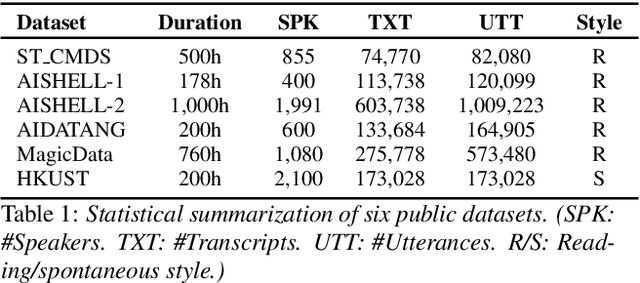
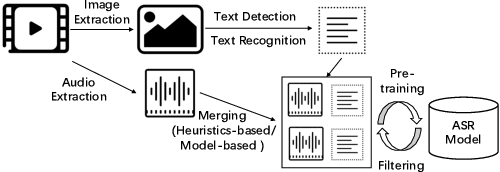
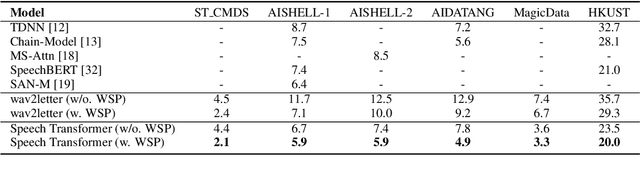
Building Automatic Speech Recognition (ASR) systems from scratch is significantly challenging, mostly due to the time-consuming and financially-expensive process of annotating a large amount of audio data with transcripts. Although several unsupervised pre-training models have been proposed, applying such models directly might still be sub-optimal if more labeled, training data could be obtained without a large cost. In this paper, we present a weakly supervised framework for constructing ASR systems with massive video data. As videos often contain human-speech audios aligned with subtitles, we consider videos as an important knowledge source, and propose an effective approach to extract high-quality audios aligned with transcripts from videos based on Optical Character Recognition (OCR). The underlying ASR model can be fine-tuned to fit any domain-specific target training datasets after weakly supervised pre-training. Extensive experiments show that our framework can easily produce state-of-the-art results on six public datasets for Mandarin speech recognition.
Online NEAT for Credit Evaluation -- a Dynamic Problem with Sequential Data
Jul 06, 2020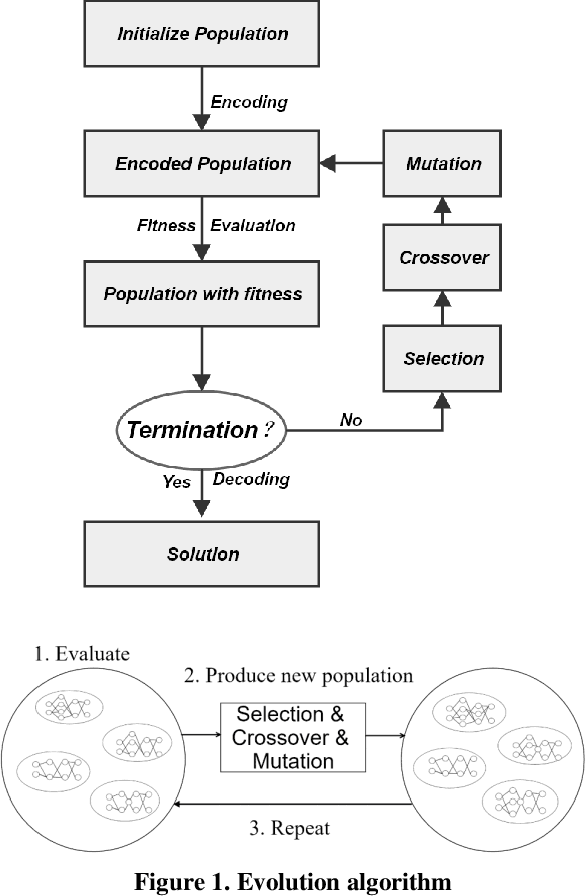


In this paper, we describe application of Neuroevolution to a P2P lending problem in which a credit evaluation model is updated based on streaming data. We apply the algorithm Neuroevolution of Augmenting Topologies (NEAT) which has not been widely applied generally in the credit evaluation domain. In addition to comparing the methodology with other widely applied machine learning techniques, we develop and evaluate several enhancements to the algorithm which make it suitable for the particular aspects of online learning that are relevant in the problem. These include handling unbalanced streaming data, high computation costs, and maintaining model similarity over time, that is training the stochastic learning algorithm with new data but minimizing model change except where there is a clear benefit for model performance
A Change-Detection Based Thompson Sampling Framework for Non-Stationary Bandits
Sep 06, 2020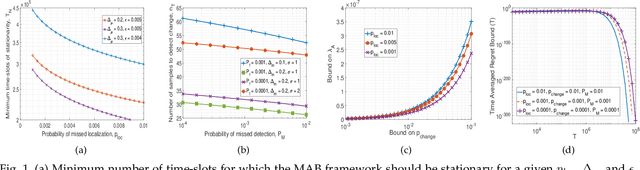
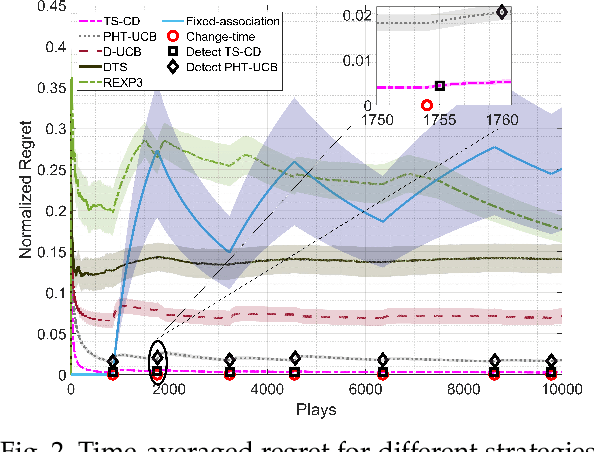
We consider a non-stationary two-armed bandit framework and propose a change-detection based Thompson sampling (TS) algorithm, named TS with change-detection (TS-CD), to keep track of the dynamic environment. The non-stationarity is modeled using a Poisson arrival process, which changes the mean of the rewards on each arrival. The proposed strategy compares the empirical mean of the recent rewards of an arm with the estimate of the mean of the rewards from its history. It detects a change when the empirical mean deviates from the mean estimate by a value larger than a threshold. Then, we characterize the lower bound on the duration of the time-window for which the bandit framework must remain stationary for TS-CD to successfully detect a change when it occurs. Consequently, our results highlight an upper bound on the parameter for the Poisson arrival process, for which the TS-CD achieves asymptotic regret optimality with high probability. Finally, we validate the efficacy of TS-CD by testing it for edge-control of radio access technique (RAT)-selection in a wireless network. Our results show that TS-CD not only outperforms the classical max-power RAT selection strategy but also other actively adaptive and passively adaptive bandit algorithms that are designed for non-stationary environments.
Wavelet Denoising and Attention-based RNN-ARIMA Model to Predict Forex Price
Aug 16, 2020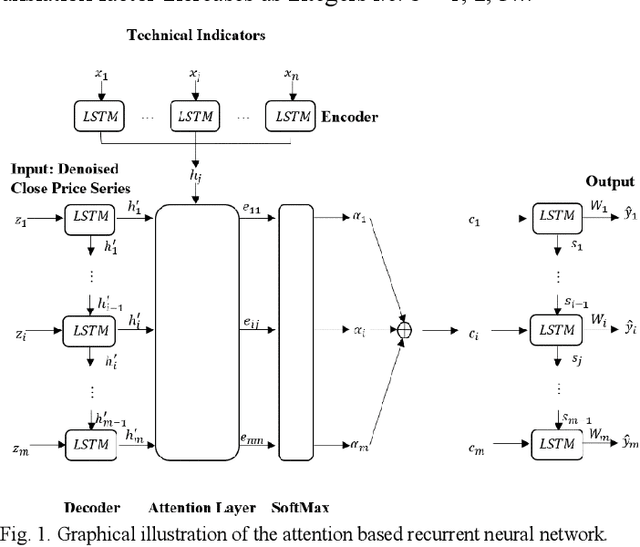
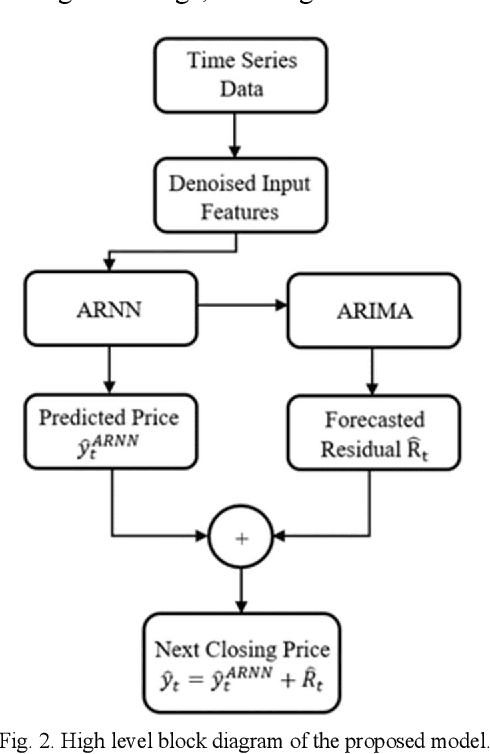
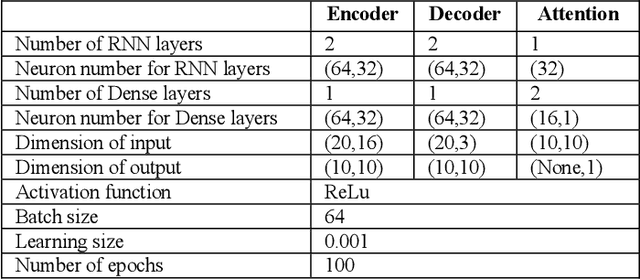
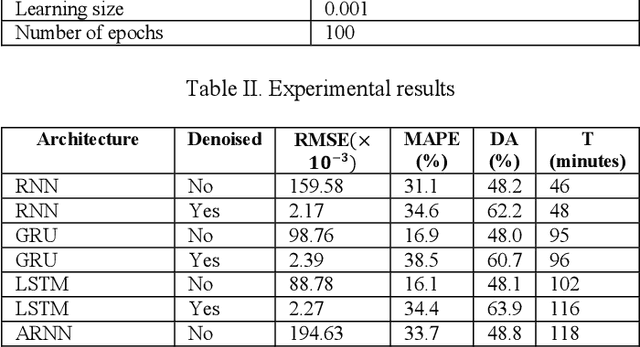
Every change of trend in the forex market presents a great opportunity as well as a risk for investors. Accurate forecasting of forex prices is a crucial element in any effective hedging or speculation strategy. However, the complex nature of the forex market makes the predicting problem challenging, which has prompted extensive research from various academic disciplines. In this paper, a novel approach that integrates the wavelet denoising, Attention-based Recurrent Neural Network (ARNN), and Autoregressive Integrated Moving Average (ARIMA) are proposed. Wavelet transform removes the noise from the time series to stabilize the data structure. ARNN model captures the robust and non-linear relationships in the sequence and ARIMA can well fit the linear correlation of the sequential information. By hybridization of the three models, the methodology is capable of modelling dynamic systems such as the forex market. Our experiments on USD/JPY five-minute data outperforms the baseline methods. Root-Mean-Squared-Error (RMSE) of the hybrid approach was found to be 1.65 with a directional accuracy of ~76%.